【深度学习】计算机视觉(11)——Faster RCNN(工具篇)
文章目录
- 1 gcc编译报错
-
- 1.1 错误提示“ld: cannot find -lm/-lc/-lpthread”
- 1.2 解决方法:安装glibc工具
- 1.3 解决方法:修改sources.list
- 1.4 解决方法:软连接
- 2 Permission denied
- 3 运行报错
-
-
- 3.1 module 'tensorflow' has no attribute '×××'
- 3.2 No module named 'tensorflow.contrib'
- 3.3 补充module 'tensorflow' has no attribute '×××'
- 3.4 assert (boxes[:, 2] >= boxes[:, 0]).all()
- 3.5 ResourceExhaustedError: OOM
-
- 4. 数据集制作
-
- 数据集格式-YOLOv5
- 数据集格式-VOC2007
-
-
- ① Annotations
- ② ImageSets
- ③ 注意事项
-
- YOLO → VOC
- 划分VOC数据集
本文针对tensorflow版本Faster R-CNN,为前文提供相关技术支持。
(因为二位数用大写实在是不好看,所以标题换成阿拉伯计数了)
我的系统:Ubuntu 20.04.3 LTS (GNU/Linux 5.4.0-131-generic x86_64)
1 gcc编译报错
这里主要附上我在解决gcc/g++编译报错时的办法。
1.1 错误提示“ld: cannot find -lm/-lc/-lpthread”
出现如下报错:
/root/miniconda3/compiler_compat/ld: cannot find -lm
/root/miniconda3/compiler_compat/ld: cannot find -lc
/root/miniconda3/compiler_compat/ld: cannot find -lpthread
collect2: error: ld returned 1 exit status
error: command 'g++' failed with exit status 1
下面的解决方法可以直接跳至第三步,如果未解决再回到第一步挨个做,因为我做的步骤太多了,不知道前几步是否也很关键。
1.2 解决方法:安装glibc工具
第一步,根据查阅到的教程,似乎是缺少glibc工具,需要下载。我分别使用命令:
sudo apt-get update
sudo apt-get install --reinstall build-essential
sudo apt-get upgrade
上述命令是为了更新本地的各种包,接下来准备安装glibc-static,使用命令:
sudo apt-get install glibc-static
但是一直提示找不到这个路径,显示错误提示如下:
E:unable to locate package
1.3 解决方法:修改sources.list
第二步,为了解决unable to locate package,首先进入目录/etc/apt,查看当前目录下是否有sources.list文件,改写文件内容。使用ls命令可查看当前目录下的所有内容,具体演示如下:

使用命令vi sources.list进入文件编辑器,粘贴以下内容:
# deb cdrom:[Debian GNU/Linux 7.0 _Kali_ - Official Snapshot i386 LIVE/INSTALL $
# deb cdrom:[Debian GNU/Linux 7.0 _Kali_ - Official Snapshot i386 LIVE/INSTALL $
## Security updates
deb http://http.kali.org/ /kali main contrib non-free
deb http://http.kali.org/ /wheezy main contrib non-free
deb http://http.kali.org/kali kali-dev main contrib non-free
deb http://http.kali.org/kali kali-dev main/debian-installer
deb-src http://http.kali.org/kali kali-dev main contrib non-free
deb http://http.kali.org/kali kali main contrib non-free
deb http://http.kali.org/kali kali main/debian-installer
deb-src http://http.kali.org/kali kali main contrib non-free
deb http://security.kali.org/kali-security kali/updates main contrib non-free
deb-src http://security.kali.org/kali-security kali/updates main contrib non-fr$
(按i键进行编辑操作,按ESC键退出编辑进入命令操作,命令操作输入:wq即可保存并退出)
然后像依次使用命令再次进行安装:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install glibc-static
但是仍然无法安装glibc-static。因此我又重新查找针对解决cannot find -lxxx问题的教程。
1.4 解决方法:软连接
在此之前我忘记了软连接的存在,因为除了上课学过之后再也没用过。软连接在Linux里通俗讲就是windows系统的快捷方式,我在学习的过程中有很多地方都用到了软连接。简单来说,使用命令`ln -sv a路径/x文件 b路径/y文件`可以在b路径建立一个x文件的软连接,重命名为y。
回到正题,第三步,建立软连接。
首先要明确一点,以cannot find -lm为例,lm的全称指libm(省略了ib),类似地,lc指libc、lpthread指libpthread。报错提示/usr/lib目录下找不到对应文件,因此需要在该目录下创建,我们对于每个错误逐个去解决。下面的方案仍以lm为例。
首先需要找到libm.so文件,使用命令:
find / -name "*libm.so"
找到libm.so文件的绝对路径为:/usr/lib/x86_64-linux-gnu/libm.so,然后需要进入/usr/lib目录,建立/usr/lib下的libm.so,分别使用命令:
cd /usr/lib
ln -sv /usr/lib/x86_64-linux-gnu/libm.so libm.so
显示'libm.so' -> '/usr/lib/x86_64-linux-gnu/libm.so'即为成功。其他同理,再次运行setup.py即可解决。
注意一定要进入/usr/lib下生成软连接,否则还是会报错。如果目录进入错误,可以先进入错误目录使用unlink libm.so删除错误的软连接。
这里关于软连接的问题补充一个用法,我在测试tensorflow能否使用GPU的时候提示libstdc++.so.6中缺少CXXABI 1.3.8,通过查找发现libstdc++.so.6.0.28中有我们需要的CXXABI 1.3.8,此处也是通过删除原目录的libstdc++.so.6文件,建立libstdc++.so.6.0.28的软连接给libstdc++.so.6。
2 Permission denied
在执行.sh文件时遇到报错提示Permission denied。可以先使用命令ls -al查看当前目录下的所有文件的详细信息。每个文件都包含10个参数----------(“-“用于占位)。例如-rwxr-xr-x表示第2、5、8位参数为"r”;第3位参数为"w”;第4、7、10位参数为"x"。每位参数都有其具体的含义:
- 第1位(与解决方案无关,暂不关心);
- 第2、3、4位:属于角色user的权限;
- 第5、6、7位:属于group的权限;
- 第8、9、10位:属于others的权限。
每三位分为1组,三个字母排列类似于二进制位,每组字母从左到右分别为r、w、x,表示:
- r:可读(对应10进制为4);
- w:可写(对应10进制为2);
- x:可执行(对应10进制为1)。
使用chmod给fetch_faster_rcnn_models.sh文件重新设置权限:
chmod 755 fetch_faster_rcnn_models.sh
那么"755"就分别对应user、group、other的权限。
7 = 4 + 2 + 1 = r + w + x,表示user拥有全部权限;5 = 4 + 0 + 1 = r + 0 + x,表示group拥有读和执行权;5 = 4 + 0 + 1 = r + 0 + x,表示others拥有读和执行权;
比如我在执行时遇到问题:-bash: ./tools/demo.py: Permission denied。先进入tools中使用ls -all查看目录详情,发现用户没有执行demo的权利,使用命令chmod 755 demo.py后再次用ls -all查看,两次结果分别为:
-rw-r--r-- 1 root root 5309 Sep 27 2021 demo.py
-rwxr-xr-x 1 root root 5309 Sep 27 2021 demo.py
3 运行报错
3.1 module ‘tensorflow’ has no attribute ‘×××’
这是由于tensorflow2.0与1.0存在差异出现的问题。
解决方法:
如果遇到类似本题目的报错,直接将import tensorflow as tf改成import tensorflow.compat.v1 as tf(忽略红线报错),即可使用1.0版本的tensorflow。然后必须再在所有import结束后添加tf.disable_v2_behavior()表示忽略2.0版本,不然还会有别的错误。
3.2 No module named ‘tensorflow.contrib’
运行时遇到报错:No module named 'tensorflow.contrib',因为tensorflow新版本已经没有contrib了,但是提供了替代contrib的包ty-slim。
解决方法:
使用命令pip install tf-slim下载。将代码中所有from tensorflow.contrib import ...都改成from tf_slim import ...,即可解决无tensorflow.contrib的问题。
注意有时候不是从tensorflow.contrib引其他包,而是先引了tensorflow再从tensorflow中引contrib,会报错 module ‘tensorflow’ has no attribute ‘contrib’。诸如这类情况不要落下,先import tf_slim as slim,再将代码中的tf.contrib全部改为slim。
关于contrib还存在一些特殊情况,引包的方式存在额外变化,例如下面的代码不仅替换了tf.contrib还删除了.layers。在遇到类似报错但无法解决的情况可自行查阅。
# 修改前
weights_regularizer = tf.contrib.layers.l2_regularizer(cfg.FLAGS.weight_decay)
# 修改后
weights_regularizer = slim.l2_regularizer(cfg.FLAGS.weight_decay)
还比如from tensorflow.contrib.slim.nets import resnet_v1 改为from tf-slim.nets import resnet_v1。
3.3 补充module ‘tensorflow’ has no attribute ‘×××’
关于tensorflow版本问题的报错还有另一种情况。
from tensorflow.python import pywrap_tensorflow
XXX = pywrap_tensorflow.NewCheckpointReader(XXX)
改为:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
XXX = tf.train.NewCheckpointReader(XXX)
3.4 assert (boxes[:, 2] >= boxes[:, 0]).all()
这里解释的代码是CPU版本的,和GPU版本原理大致相同,具体文件结构不影响理解。
这部分代码的目的是旋转图片已经对应的框,是一个数据增强的做法。boxes是标注的bounding box,这里是要检查右下角坐标是否大于左上角坐标,只要检查到不符合就报错,当出现assert (boxes[:, 2] >= boxes[:, 0]).all()问题时,可能是自己的数据集标注出现矩形越界,导致后面的计算溢出。点击报错提示定位到报错代码,如图:

在assert (boxes[:, 2] >= boxes[:, 0]).all()上一行添加print(self.image_index[i]),可以输出当前正在处理的图片,查看出错的图片是哪一张。找到输出的最后一行,即是出错图片的文件名,例如我这里最后一行输出的是717_0148,则图片717_0148.jpg有问题。(再次强调我这里图片命名不符合标准)
- 如果不放心自己的数据,先检查Annotations中每个xmax和ymax是否超出图片边界,可查看该图片Annotations文件中的size标签找到图片尺寸。
- 如果数据出错的可能性比较小,则先检查Annotations中左上角坐标(x,y)有没有为0的情况,同时Faster-RCNN在处理数据集时,为了使像素以0为起点,每个bbox的坐标都减1有没有修改,如果数据里有坐标为0,这时由于
0 -1 = 65535,就会出现上述问题。
可以再添加if判断语句,输出该图片经调整后的所有bounding box值。
print(self.image_index[i])
"""
# 找到报错图片后,添加判断语句:
if self.image_index[i] == '717_0148':
print(boxes[:, :])
"""
assert (boxes[:, 2] >= boxes[:, 0]).all()
查看所有的boxes[ : , : ]输出,boxes[ : , 0 ] 至 boxes[ : , 3 ] 分别是xmin、ymin、xmax、ymax,果然我发现出现了xmin为65535的情况。我规范了所有文件的坐标起点设置,ymin出现65535的情况已经全部解决,但是xmin依然存在65535,可能是因为计算的过程中存在误差。
解决方案:
可以在boxes[:, 2] = widths[i] - oldx1 - 1下加入代码:
for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
注意,关于为什么0-1=-1在这里是65535的问题,我通过debug查看了boxes的数据类型,是unit16(无符号整数),之前“明明python可以处理负数”的疑问解决。
3.5 ResourceExhaustedError: OOM
解决完所有的报错后,发生了一个非常尴尬的事情,显卡内存不足报错。即使换成小的batch_size也无法解决。
解决办法:更换实验环境。
4. 数据集制作
项目指定了复杂的文件路径以及文件夹命名规则,其中的VOC是一种数据集的格式,我们要把自己的数据按照VOC指定的格式设置。
数据集格式-YOLOv5
由于在学习Faster R-CNN时用到的是VOC2007格式的数据集,所以以我目前的学习任务为中心简单介绍一下其他的内容,便于更好地理解和使用,可能有不全或者不准确的地方。
YOLO格式的数据集直观地看比较简单。数据集文件夹共有两个子文件夹,一个是 images ,一个是 labels ,分别存放图片与标签txt文件,并且 images与labels的目录结构需要对应,因为yolo是先读取images图片路径,随后直接将images替换为labels来查找标签文件 。如下所示:
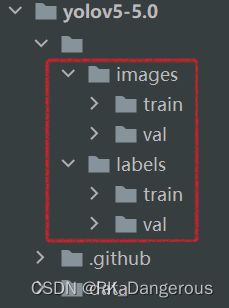
labels中的文件为每张图片对应的txt文件,其中的数据格式是:cls_id x y w h 其中坐标(x,y)是中心点坐标,注意是相对于图片宽高的比例值 ,而非绝对坐标。另外,labels中还有一个classes.txt文件,按行排列了n个分类对应从0到n-1的类标号(我也不知道是不是yolo的标准,反正我获得的labels文件夹中有classes.txt,如果你没有,那后面相关内容自己动态调整)。
数据集格式-VOC2007
VOC数据是 PASCAL VOC Challenge 用到的数据集,PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,主要包括以下几类:图像分类(Object Classification)、目标检测(Object Detection)、目标分割(Object Segmentation)、行为识别(Action Classification) 等。
训练集的文件结构大致如下(测试集同理,使用test.txt文件):
VOC_ROOT #根目录
├── JPEGImages # 存放源图片
│ ├── aaaa.jpg
│ ├── bbbb.jpg
│ └── cccc.jpg
├── Annotations # 存放xml文件,与JPEGImages中的图片对应,包含图片的label信息
│ ├── aaaa.xml
│ ├── bbbb.xml
│ └── cccc.xml
├── ImageSets
│ ├── Layout
│ ├── Segmentation
│ └── Main
│ ├── train.txt # txt文件中每一行包含一个图片的名称
│ ├── val.txt
│ └── trainval.txt
├── SegmentationClass
└── SegmentationObject
其中SegmentationObject和SegmentationClass都是专门为 Segmentation任务做的一个文件夹,此处暂时不作详解。由于JEPEImages中存放源图片,所以也没必要细述,下面会详细讲解Annotations和ImageSets。
① Annotations
Annotations目录中存放的是标注数据,VOC的标注是xml格式的,文件名与JPEGImages中的图片一一对应。
每个xml对应JPEGImage中的一张图片,并且每个xml中存放的是标记的各个目标的位置和类别信息,以(x,y)的格式保存坐标点。
xml文件格式如下:
<annotation>
<folder>VOC2007folder>
<filename>2007_000392.jpgfilename> //文件名
<source> //图像来源(不重要,可以省略)
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
source>
<size> //图像尺寸(宽长以及通道数)
<width>500width>
<height>332height>
<depth>3depth>
size>
<segmented>1segmented> //是否用于分割(在图像物体识别中是0还是1都无所谓)
<object> //检测到的第1个物体
<name>horsename> //物体类别
<pose>Rightpose> //拍摄角度,如果是自己的数据集就Unspecified
<truncated>0truncated> //是否被截断(默认为0表示完整)
<difficult>0difficult> //目标是否难以识别(默认为0表示容易识别)
<bndbox> //bounding-box坐标
<xmin>100xmin>
<ymin>96ymin>
<xmax>355xmax>
<ymax>324ymax>
bndbox>
object>
<object> //检测到的第2个物体
<name>personname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>198xmin>
<ymin>58ymin>
<xmax>286xmax>
<ymax>197ymax>
bndbox>
object>
......
annotation>
② ImageSets
这个文件夹是图像集合,其中的三个文件夹Layout 、 Main、 Segmentation对应VOC3 challenge 3类不同的任务,在Main中包含分类和检测任务要用到的图像集合,即我此时主要的关注点(其他两个目前用不到,可以为空),显然train表示的是训练集,val表示的是验证集,trainval是前两者的集合。每个txt文件中,有若干行,每行对应JPEGImages一个图片的文件名(不包含图片后缀),表示要训练的图片。
Main文件夹中,除了可以包含train.txt、val.txt、trainval.txt三个文件外,还可以包含按照类别进行的训练任务文件,例如猫狗二分类问题中包含9个文件,分别为:cat_train.txt、cat_val.txt、cat_trainval.txt、dog_train.txt、dog_val.txt、dog_trainval.txt、train.txt、val.txt、trainval.txt。注意带有分类的6个txt文件中每一行除了包含图像ID外,后面还跟了一个数字(有-1、1、0三种选择),-1表示当前图像中没有该类物体、1 表示当前图像中有该类物体、0 表示当前图像中没有或只有一部分。
③ 注意事项
需要注意的是图片和xml文件都要为000001.jpg,000001.xml的六位数命名格式,一一对应,所有类别放在一起。
YOLO → VOC
当我已经获得YOLO格式的数据集,想办法如何建立VOC格式的数据集。一个一个标可能要不吃不喝标好久。可以使用代码:
from xml.dom.minidom import Document
import os
import cv2
def makexml(picPath, txtPath, xmlPath):
"""
此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
picPath:图片所在的文件夹路径
txtPath:txt文件所在的文件夹路径
xmlPath:xml文件保存路径
"""
dic = {'0': "cat",
'1': "dog"
} # 创建字典用来对类型进行转换
# 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
files = os.listdir(txtPath) # 打开txt所在文件夹
for i, name in enumerate(files): # i为序号,name为txt文件名字(包括后缀)
if name == "classes.txt":
break # 因为label文件夹里还有一个classes.txt文件,所以要跳过
# 每一次files循环对应一个label信息
txtFile = open(txtPath + '\\' + name) # 打开第i个txt文件
txtList = txtFile.readlines() # 获取文件中的内容,按照换行分割并存储
# 每一次files循环对应一张图片
for root, dirs, filename in os.walk(picPath): # 获取对应的图片,因为这里没有子文件夹,所以for只循环一次
"""
os.walk(path)会遍历path路径以及path路径目录下所有的子目录,类似深度优先搜索的遍历方式
os.walk(path)返回三个参数,用now_path表示目前所在的位置(第一次遍历时now_path = path):
root:now_path的绝对路径
dirs:now_path中包含的文件夹,存储在数组中
filename:now_path中包含的文件,存储在数组中
"""
img = cv2.imread(root + '\\' + filename[i])
# 每一次循环对应一个annotation
xmlBuilder = Document() # 新建一个Document对象
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签对象
xmlBuilder.appendChild(annotation) # 在文件里添加annotation作为子对象
folder = xmlBuilder.createElement("folder") # 创建folder标签对象
foldercontent = xmlBuilder.createTextNode("Annotations") # 创建foldercontent文本对象,此处为xml所在文件夹名字
folder.appendChild(foldercontent) # 在folder对象里添加子对象foldercontent
annotation.appendChild(folder) # 在annotation对象里添加子对象folder
filename = xmlBuilder.createElement("filename")
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg") # name取从0开始至倒数第4个位置左闭右开
filename.appendChild(filenamecontent)
annotation.appendChild(filename)
size = xmlBuilder.createElement("size") # size标签
Pheight, Pwidth, Pdepth = img.shape # 先获取img图片信息
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width)
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height)
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth)
annotation.appendChild(size)
for j in txtList:
oneline = j.strip().split(" ") # 用空格分隔一行中的几个数据
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose)
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult)
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth) # 应该也可以不+1
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
f = open(xmlPath + '\\' + name[0:-4] + ".xml", 'w') # 新建.xml文件
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8') # 将xmlBuilder写入
"""
writexml(writer, indent, addindent, newl, encoding)参数说明:
1、writer是文件对象
2、indent是每个tag前填充的字符
3、addindent是每个子结点的缩近字符
4、newl是每个tag后填充的字符
5、encoding是生成的XML信息头中的encoding属性值
"""
f.close()
if __name__ == "__main__":
picPath = r"E:\images" # 图片所在文件夹路径
txtPath = r"E:\labels" # txt所在文件夹路径
xmlPath = r"E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\Annotations" # xml文件保存路径
makexml(picPath, txtPath, xmlPath)
因为Faster RCNN需要Annotations文件夹,所以我这里直接把生成的xml文件都放在指定目录里了。
上述代码里有一个疑问我刚开始没有解决,如下图。

第29行这里,因为for只循环一次就可以获得pic文件夹里所有filename,两个for循环嵌套似乎没什么必要,那么我们可不可以为了节省时间或者说修改逻辑,把这个语句放在上层for循环的外面?(因为python在for循环里面定义的变量在for循环外面也是可以用的)即进入makexml方法后先遍历一次picPath,后续都使用之前提取出的root、filename获取每一张img。我尝试这样写但总是报错,我不知道为什么。后来找到了原因,这里的filename与后面创建filename标签时使用的变量是一样的,修改其中一个即可实现我的逻辑。直接看代码可能直观一点,原代码第19行至38行改为:
files = os.listdir(txtPath) # 打开txt所在文件夹
for root, dirs, filenames in os.walk(picPath):
print(root, " ", len(filenames))
# 只是为了给root和filenames赋值,这里将原来的filename改为filenames
for i, name in enumerate(files): # i为序号,name为txt文件名字(包括后缀)
if name == "classes.txt":
break # 因为label文件夹里还有一个classes.txt文件,所以要跳过
# 每一次files循环对应一个label信息
txtFile = open(txtPath + '\\' + name) # 打开第i个txt文件
txtList = txtFile.readlines() # 获取文件中的内容,按照换行分割并存储
# 每一次files循环对应一张图片
img = cv2.imread(root + '\\' + filenames[i])
划分VOC数据集
Faster RCNN要求的数据集格式如下(下图VOCDevkit2007命名错误,应改为VOCdevkit2007):

首先要创建JPEGImages和Annotations并将两个文件夹需要的内容放进去,现在只需生成Main中的四个.txt文件。代码如下:
import os
import random
# 设置数据集比例为 train : val : test = 8 : 1 : 1
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\Annotations'
txtsavepath = r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\ImageSets\Main'
total_xml = os.listdir(xmlfilepath) # 打开xmlfilepath路径,将xml全部文件放在list里
num = len(total_xml) # 文件总数
list = range(num) # 给文件添加序号
tv = int(num * trainval_percent) # 根据总数和百分比计算tr+v和tr的数量
tr = int(tv * train_percent)
trainval = random.sample(list, tv) # 打乱顺序:在list里取任意tv个序号
train = random.sample(trainval, tr) # 打乱顺序:在tv里再取任意tr个序号,剩下的序号即为val
ftrainval = open(r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\ImageSets\Main\trainval.txt', 'w')
ftest = open(r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\ImageSets\Main\test.txt', 'w')
ftrain = open(r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\ImageSets\Main\train.txt', 'w')
fval = open(r'E:\Faster-RCNN\data\VOCdevkit2007\VOC2007\ImageSets\Main\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n' # write()不会自动换行
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
至此,数据集制作完毕。