初识 Elasticsearch
初识 Elasticsearch
-
- 一、Elasticsearch 简介
- 二、Elastic Stack
- 三、Elasticsearch 高级特性
- 四、Elasticsearch 安装部署
- 五、Spring 集成
-
- 5.1 pom 依赖
- 5.2 yml 配置
- 5.3 Configuration 类
- 5.4 RestHighLevelClient
- 5.5 查询
-
- 5.5.1 QueryBuilder
-
- 5.5.1.1 常用的 QueryBuilder
- 5.5.2 SearchSourceBuilder
- 5.5.3 示例
一、Elasticsearch 简介
Elasticsearch是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的 全文搜索引擎,基于 RESTful web 接口,它目前被广泛地使用于各个 IT 公司。
Elasticsearch 是由 Elastic 公司创建,使用 Java 语言开发的,并作为 Apache 许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
目前,Elasticsearch 是一个免费及开放(free and open)的项目。同时,Elastic 公司也拥有 Logstash 及 Kibana 开源项目。这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。
- Logstash 负责数据的采集,处理(丰富数据,数据转换等)
- Kibana 负责数据展示,分析,管理,监督及应用。
- Elasticsearch 处于最核心的位置,它可以帮我们对数据进行快速地搜索及分析。

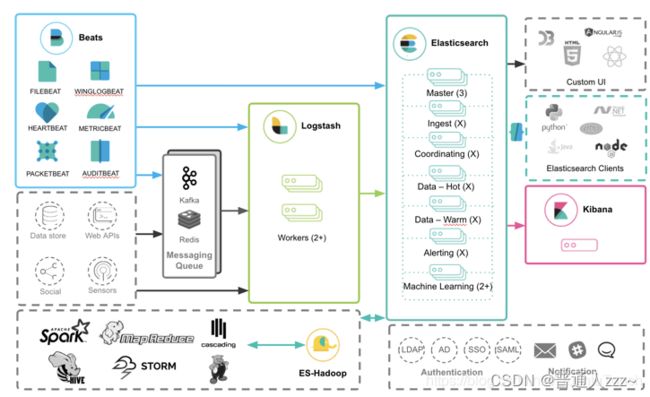
二、Elastic Stack
事实上 Elastic Stack 的完整栈有如下的几个:
-
Beats:Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。官网地址 Beats:Elasticsearch 的数据采集器 | Elastic。
Beats 是数据采集的得力工具。将 Beats 和您的容器一起置于服务器上,或者将 Beats 作为功能加以部署,然后便可在 Elasticsearch 中集中处理数据。Beats 能够采集符合 Elastic Common Schema (ECS) 要求的数据,如果您希望拥有更加强大的处理能力,Beats 能够将数据转发至 Logstash 进行转换和解析。Beats 系列如下:
- FileBeat:日志文件采集器
- Metricbeat:指标采集器
- Packetbeat:网络数据采集器
- Winlogbeat:Windows 事件日志采集器
- Auditbeat:审计数据采集器
- Heartbeat:运行时间监控采集器
- Functionbeat:无需服务器的采集器
-
Logstash:Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。官网地址 Logstash:收集、解析和转换日志 | Elastic。
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
-
Elasticsearch:Elastic Stack 的核心。Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。官网地址 Elasticsearch:官方分布式搜索和分析引擎 | Elastic。
-
Kibana:Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。官网地址 Kibana:数据的探索、可视化和分析 | Elastic。
整体架构
三、Elasticsearch 高级特性
- 分布式及高可用的搜索引擎,AP 特性,最终一致性
- 每个索引(index)都使用配置数量的分片进行分片
- 每个分片可以拥有一个或多个副本(数据备份)
- 任何副本分片上可执行读取/搜索操作
- 多租户:支持多个索引
- 可靠、异步写入,(近)实时搜索
四、Elasticsearch 安装部署
- 单机部署:百度
- 集群部署:百度
五、Spring 集成
使用 elasticsearch-rest-high-level-client 客户端与 Spring 进行集成。
5.1 pom 依赖
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>${elasticsearch.version}version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>${elasticsearch.version}version>
<exclusions>
<exclusion>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
exclusion>
exclusions>
dependency>
注意检查是否存在依赖冲突!!!
5.2 yml 配置
elasticSearch:
hosts: ip1:9200,ip2:9200,ip3:9200
userName: elastic
password: elastic
5.3 Configuration 类
@Configuration
public class EsConfiguration {
@Value("${elasticSearch.hosts}")
String hosts;
@Value("${elasticSearch.userName}")
private String userName;
@Value("${elasticSearch.password}")
private String password;
public static final RequestOptions COMMON_OPTIONS;
static {
// RequestOptions类保存了请求的部分,这些部分应该在同一个应用程序中的许多请求之间共享。
// 创建一个singqleton实例,并在所有请求之间共享它。可以设置请求头之类的一些配置
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN); //增加需要的请求 头
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 *1024));
COMMON_OPTIONS = builder.build();
}
@Bean(name = "highLevelClient")
public RestHighLevelClient highLevelClient() {
String[] hosts = this.hosts.split(",");
HttpHost[] httpHosts = new HttpHost[hosts.length];
for (int i = 0; i < hosts.length; i++) {
String host = hosts[i].split(":")[0];
int port = Integer.parseInt(hosts[i].split(":")[1]);
httpHosts[i] = new HttpHost(host, port, "http");
}
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(userName, password));
RestClientBuilder builder = RestClient.builder(httpHosts).setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) {
requestConfigBuilder.setConnectTimeout(-1);
requestConfigBuilder.setSocketTimeout(-1);
requestConfigBuilder.setConnectionRequestTimeout(-1);
return requestConfigBuilder;
}
}).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
httpClientBuilder.disableAuthCaching();
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
5.4 RestHighLevelClient
@Autowired
private RestHighLevelClient highLevelClient;
# 创建索引
CreateIndexRequest request = new CreateIndexRequest(indexName);
CreateIndexResponse response = highLevelClient.indices().create(request, EsConfiguration.COMMON_OPTIONS);
# 判断索引是否存在
GetIndexRequest request = new GetIndexRequest(indexName);
boolean exists = highLevelClient.indices().exists(request, EsConfiguration.COMMON_OPTIONS);
# 删除索引
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(indexName);
AcknowledgedResponse delete = highLevelClient.indices().delete(deleteIndexRequest, EsConfiguration.COMMON_OPTIONS);
# 添加文档
public RestStatus addDocument(String indexName, String id, Map<String, ?> data, Long timeout) {
try {
IndexRequest request = new IndexRequest(indexName);
// 设置id:id为空会随机生产
request.id(id);
// 超时时间
request.timeout(TimeValue.timeValueSeconds(timeout));
// 将我们的数据放入请求
request.source(data);
// 客服端发送请求
IndexResponse response = highLevelClient.index(request, EsConfiguration.COMMON_OPTIONS);
log.info("addDocument>>>>>indexName={}, id={}, data={}, timeout={}, response={}", indexName, id, JSON.toJSONString(data), timeout, JSON.toJSONString(response));
return response.status();
} catch (Exception e) {
log.error("deleteIndex>>>>>exception indexName={}, id={}, data={}, timeout={}", indexName, id, JSON.toJSONString(data), timeout, e);
}
return RestStatus.EXPECTATION_FAILED;
}
# 批量插入
public RestStatus batchAddDocument(String indexName, Map<String, Object> datas, Long timeout) {
try {
//构建批量插入的请求
BulkRequest request = new BulkRequest();
// 超时时间
request.timeout(TimeValue.timeValueSeconds(timeout));
//批量插入请求设置
Iterator<Map.Entry<String, Object>> iterator = datas.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> data = iterator.next();
request.add(new IndexRequest(indexName) // 设置索引
.id(data.getKey()) // 设置文档的id,如果没有指定,会随机生成,自己测试
.source(data.getValue(), XContentType.JSON) // 设置要添加的资源,类型为JSON
);
}
// 客服端发送请求
BulkResponse response = highLevelClient.bulk(request, EsConfiguration.COMMON_OPTIONS);
log.info("batchAddDocument>>>>>indexName={}, datas={}, timeout={}, response={}", indexName, JSON.toJSONString(datas), timeout, JSON.toJSONString(response));
return response.status();
} catch (Exception e) {
log.error("batchAddDocument>>>>>indexName={}, datas={}, timeout={}", indexName, JSON.toJSONString(datas), timeout, e);
}
return RestStatus.EXPECTATION_FAILED;
}
# 获取文档信息
GetRequest getRequest = new GetRequest(indexName, id);
GetResponse response = highLevelClient.get(getRequest, EsConfiguration.COMMON_OPTIONS);
response.getSourceAsString(); // 返回String
response.getSourceAsMap(); // 返回Map
# 更新文档
public RestStatus updateDocument(String indexName, String id, Map<String, ?> data, Long timeout) {
try {
UpdateRequest updateRequest = new UpdateRequest(indexName, id);
// 超时时间
updateRequest.timeout(TimeValue.timeValueSeconds(timeout));
updateRequest.doc(data, XContentType.JSON);
UpdateResponse response = highLevelClient.update(updateRequest, EsConfiguration.COMMON_OPTIONS);
log.info("updateDocument>>>>>indexName={}, id={}, data={}, timeout={}, response={}", indexName, id, JSON.toJSONString(data), timeout, JSON.toJSONString(response));
return response.status();
} catch (Exception e) {
log.error("updateDocument>>>>>exception indexName={}, id={}, data={}, timeout={}", indexName, id, JSON.toJSONString(data), timeout, e);
}
return RestStatus.EXPECTATION_FAILED;
}
# 删除文档
DeleteRequest deleteRequest = new DeleteRequest(indexName, id);
// 超时时间
deleteRequest.timeout(TimeValue.timeValueSeconds(timeout));
DeleteResponse response = highLevelClient.delete(deleteRequest, EsConfiguration.COMMON_OPTIONS);
5.5 查询
5.5.1 QueryBuilder
Elasticsearch 提供非常多的查询构造器,集中在 elasticsearch 包中的 org.elasticsearch.index.query 目录下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6gTgev7k-1652083708728)(.\ES QueryBuilder.jpg)]
可选用不同 QueryBuilder 进行查询条件构建,进而进行搜索。
5.5.1.1 常用的 QueryBuilder
-
MatchAllQueryBuilder:
QueryBuilders.matchAllQuery();匹配全部文档。
-
MatchQueryBuilder:
QueryBuilders.matchQuery(String name, Object text);会将搜索词分词,再与目标查询字段进行匹配,若分词中的任意一个词与目标字段匹配上,则可查询到。
-
MultiMatchQueryBuilder:
QueryBuilders.multiMatchQuery(Object text, String... fieldNames)模糊匹配多个字段(只要有一个字段名在fieldNames中的值与text一致,匹配成功)
-
MatchPhraseQueryBuilder:
QueryBuilders.matchPhraseQuery(String name, Object text);精确匹配查询的短语,需要全部单词和顺序要完全一样,标点符号除外。 -
MatchPhrasePrefixQueryBuilder:
QueryBuilders.matchPhrasePrefixQuery(String name, Object text);和 MatchPhraseQueryBuilder 用法是一样的,区别就在于它允许对最后一个词条前缀匹配。 -
TermQueryBuilder:
QueryBuilders.termQuery(String name, String value)输入的查询内容是什么,就会按照什么去查询,并不会解析查询内容,对它分词。
-
TermsQueryBuilder:
QueryBuilders.termsQuery(String name, String... values)多Term查询
-
RangeQueryBuilder:
QueryBuilders.rangeQuery(String name)范围查询。
QueryBuilders.rangeQuery("age") .gt("50") // 大于 50 .lt("100") // 小于 100 .includeLower(true) // 包括下界 .includeUpper(false); // 包括上界 -
ExistsQueryBuilder:
QueryBuilders.existsQuery(String name)查询字段不为null的文档
-
PrefixQueryBuilder:
QueryBuilders.prefixQuery(String name, String prefix)匹配分词前缀,如果字段没分词,就匹配整个字段前缀
-
WildcardQueryBuilder:
QueryBuilders.wildcardQuery(String name, String query)通配符查询
- * :任意字符串
- ?:任意一个字符
QueryBuilders.wildcardQuery("name","li*"); QueryBuilders.wildcardQuery("name","li?") -
RegexpQueryBuilder:
QueryBuilders.regexpQuery(String name, String regexp)正则表达式匹配分词
-
FuzzyQueryBuilder:
QueryBuilders.fuzzyQuery(String name, Object value)分词模糊查询,通过增加fuzziness 模糊属性,来查询。
- 输入的name 会被分词,.
- fuzziness参数会指定编辑次数,fuzziness.zone 为绝对匹配,fuzziness.one为编辑一次,fuzziness.two为编辑两次,fuzziness.auto 为默认推荐的方式
fuzziness 是用来度量把一个单词转换为另一个单词需要的单字符编辑次数。单字符编辑方式如下:
- 替换 一个字符到另一个字符: _f_ox -> _b_ox
- 插入 一个新字符: sic -> sick
- 删除 一个字符:: b_l_ack -> back
- 换位 调整字符: _st_ar -> _ts_ar
当然, 一个字符串的单次编辑次数依赖于它的长度。对 hat 进行两次编辑可以得到 mad,所以允许对长度为3的字符串进行两次修改就太过了,fuzziness 参数可以被设置成 AUTO,结果会在下面的最大编辑距离中:
- fuzziness.zone:1或2个字符的字符串
- fuzziness.one:3、4或5个字符的字符串
- fuzziness.two:多于5个字符的字符串
当然, 你可能发现编辑距离为2 仍然是太过了,返回的结果好像并没有什么关联,把 fuzziness 设置为 fuzziness.one ,你可能会获得更好的结果和性能.
-
IdsQueryBuilder:
QueryBuilders.idsQuery().addIds("1","2")根据ID查询
-
BoolQueryBuilder :
QueryBuilders.boolQuery();用于组合查询。
- must:AND
- mustNot:NOT
- should:OR
queryBuilder.must(QueryBuilders.termQuery("user", "zhansan")) .mustNot(QueryBuilders.termQuery("message", "lisi")) .should(QueryBuilders.termQuery("gender", "wangwu"));
5.5.2 SearchSourceBuilder
用于构造查询请求体,可进行分页查询、请求超时时间、返回字段、排序等设置。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构造QueryBuilder
sourceBuilder.query(QueryBuilders.termQuery("age", 24));
// 分页查询
sourceBuilder.from(0);
sourceBuilder.size(10);
// 请求超时时间
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 是否返回_source字段
// sourceBuilder.fetchSource(false);
// 设置返回哪些字段
String[] includeFields = new String[]{"title", "user"};
String[] excludeFields = new String[]{"_type"};
sourceBuilder.fetchSource(includeFields, excludeFields);
// 指定排序
sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));
// sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC));
// 设置返回 profile
sourceBuilder.profile(true);
5.5.3 示例
@Autowired
private RestHighLevelClient highLevelClient;
public void testQuery() throws Exception {
SearchRequest searchRequest = new SearchRequest("indexName");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();
boolBuilder.must(QueryBuilders.termQuery("code1", "234332432432"));
boolBuilder.must(QueryBuilders.termQuery("code2", "2342342343"));
BoolQueryBuilder boolQuery1 = QueryBuilders.boolQuery();
boolQuery1.should(QueryBuilders.matchQuery("name1", "0012"));
boolQuery1.should(QueryBuilders.matchQuery("name2", "测试0012"));
boolBuilder.must(boolQuery1);
// 查询size
sourceBuilder.size(100);
sourceBuilder.from(0);
// 应用bool构造器
sourceBuilder.query(boolBuilder);
searchRequest.source(sourceBuilder);
SearchResponse response = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
log.info("-------------------------------hits size={}", hits.length);
for (SearchHit hit : hits) {
float score = hit.getScore();
String sourceAsString = hit.getSourceAsString();
log.info("-------------------------------score={}, sourceAsString={}", score, sourceAsString);
}
}
参考:
https://blog.csdn.net/UbuntuTouch/article/details/98871531
https://www.elastic.co/cn/