SQL Server索引进阶:第三级,聚集索引
原文地址:
Stairway to SQL Server Indexes: Level 3, Clustered Indexes
本文是SQL Server索引进阶系列(Stairway to SQL Server Indexes)的一部分。
在这个进阶系列的前一级中介绍了索引的大概信息,以及详细介绍了nonclustered indexes非聚集索引。SQL Server的索引包含一些关键的概念。
当一个请求到达数据库的时候,有可能是select,或者insert,或者update,或者delete,SQL Server只有三种访问数据的方式:
- 访问非聚集索引,避免访问表。这只发生在索引包含了请求中的所有数据。
- 通过索引键访问非聚集索引,然后使用标签访问表中的行数据。
- 忽略非聚集索引,扫描表找到请求的行数据。
本篇文章将从上面列表中的第三条开始介绍:扫描表。我们来讨论一下clustered indexes聚集索引,一个在第二级中提到但是没有展开的概念。
今天的例子使用的是AdventureWorks数据库的SalesOrderDetail表,有121317行数据,足够用来显示在一张表中包含聚集索引是多么的好。表中有两个主键,足够复杂,来证明你在使用聚集索引的时候的一些设计取舍。
示例数据库
贯穿整个进阶系列,我们都会使用实例来阐述关键的理念。这些例子使用的是微软的 AdventureWorks 示例数据库。我们主要使用销售订单部门。包含5张表:Customer, SalesPerson, Product, SalesOrderHeader, SalesOrderDetail。为了保持注意力的集中,我们使用部分的列。
AdventureWorks 设计的很规范,销售人的信息在三张表中都有:SalesPerson,Employee,Contact。在某些情况下,我们会把他们看成是一张表。下图是这些表之间的关系。
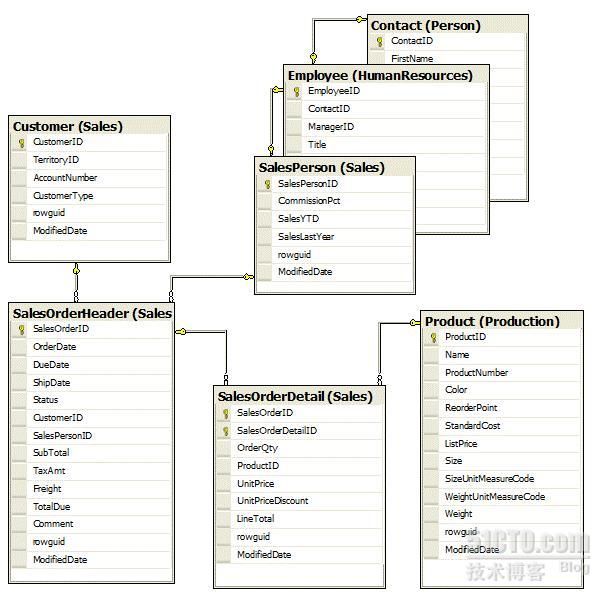
聚集索引
我们首先提出下面的问题:如果没有用到非聚集索引,找到表中的一行数据需要做多少工作?在一个没有排序的表中,是不是就需要扫描每一行来查找数据呢?又或者SQL Server的表中的行永远都是有序的,方便快速的定位要查询的数据,就像使用非聚集索引那样通过入口来快速定位数据呢?
答案依赖于你是否在SQL Server的表中建立了聚集索引。
不像非聚集索引,非聚集索引是独立的对象,有自己的存储空间,聚集索引和表是同一个。创建一个聚集索引的时候,你已经告诉SQL Server用key对表进行排序,并且在修改数据的时候维护排序。后面的级别或介绍到聚集索引的内部数据结构。现在,把聚集索引看做是一个排序的表。通过一行数据库的key,SQL Server可以快速的访问行数据,进而通过行来访问表。
为了证明我们创建SalesOrderDetail表的两份拷贝,一张表没有索引,一张表包含一个聚集索引。
IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID('dbo.SalesOrderDetail_index')) DROP TABLE dbo.SalesOrderDetail_index; GO IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID('dbo.SalesOrderDetail_noindex')) DROP TABLE dbo.SalesOrderDetail_noindex; GO SELECT * INTO dbo.SalesOrderDetail_index FROM Sales.SalesOrderDetail; SELECT * INTO dbo.SalesOrderDetail_noindex FROM Sales.SalesOrderDetail; GO CREATE CLUSTERED INDEX IX_SalesOrderDetail ON dbo.SalesOrderDetail_index (SalesOrderID, SalesOrderDetailID) GO
使用索引之前的数据是下面的样子
SalesOrderID SalesOrderDetailID ProductID OrderQty UnitPrice
69389 102201 864 3 38.10
56658 59519 711 1 34.99
59044 70000 956 2 1430.442
48299 22652 853 4 44.994
50218 31427 854 8 44.994
53713 50716 711 1 34.99
50299 32777 739 1 744.2727
45321 6303 775 6 2024.994
72644 115325 873 1 2.29
48306 22705 824 4 141.615
69134 101554 876 1 120.00
48361 23556 760 3 469.794
53605 50098 888 1 602.346
48317 22901 722 1 183.9382
66430 93291 872 1 8.99
65281 90265 889 2 602.346
52248 43812 871 1 9.99
47978 20189 794 2 1308.9375
使用索引之后的数据是下面的样子
SalesOrderID SalesOrderDetailID ProductID OrderQty UnitPrice
43668 106 722 3 178.58
43668 107 708 1 20.19
43668 108 733 3 356.90
43668 109 763 3 419.46
43669 110 747 1 714.70
43670 111 710 1 5.70
43670 112 709 2 5.70
43670 113 773 2 2,039.99
43670 114 776 1 2,024.99
43671 115 753 1 2,146.96
43671 116 714 2 28.84
43671 117 756 1 874.79
43671 118 768 2 419.46
43671 119 732 2 356.90
43671 120 763 2 419.46
43671 121 755 2 874.79
43671 122 764 2 419.46
43671 123 716 1 28.84
43671 124 711 1 20.19
43671 125 708 1 20.19
43672 126 709 6 5.70
43672 127 776 2 2,024.99
43672 128 774 1 2,039.99
43673 129 754 1 874.79
43673 130 715 3 28.84
43673 131 729 1 183.94
我们注意到SalesOrderDetailID是唯一的,不用疑惑,SalesOrderDetailID不是主键,SalesOrderID和SalesOrderDetailID是联合主键,也是聚集索引。
理解聚集索引的基础
聚集索引的键可以包含你选中的任意列,可以不是表的主键。在我们的例子中,SalesOrderID是外键,因此,一个订单的detail在SalesOrderDetail表中都是连续的。
记住下面的关于SQL Server聚集索引的几个点:
- 因为聚集索引的入口就是表的行,在聚集索引的入口上没有标签信息。当SQL Server已经定位到一行的时候,不需要额外的信息来定位行数据。
- 聚集索引总是覆盖查询,因为聚集索引和表是同一个东西,表的每一列都在索引中。
- 表包含聚集索引,不影响你在表中建立非聚集索引的选择。
聚集索引列的选择
每张表只能有一个聚集索引,因为表只能按照一个顺序来排列。你需要决定如何排序更好,最好是在表中包含数据之前就创建一个聚集索引。在创建聚集索引的时候,谨记顺序不只是排序,同样意味着分组。就像SalesOrderDetail中同一张订单的item一样。
这就是为什么SalesOrderDetail选择SalesOrderID和SalesOrderDetailID作为聚集索引的列,使得item可以很自然的排在一起。
举例来说,我们查询一条订单信息,通常也会请求订单的items的信息。
堆
如果一张表上没有聚集索引,表也被叫做堆。每张表要么是一个堆,要么是一个聚集索引。因此,尽管我们会描述索引的类型:聚集索引和非聚集索引。其实更重要的是,表有两种类型:聚集索引表和堆表。开发者经常会说一张表有或者没有聚集索引,更有意义的说法是,一张表是否是聚集索引表。
SQL Server在一张堆表中查询数据(除去使用非聚集索引)只有一个办法,从第一行开始,直到找到目标行。没有顺序,没有查询键,没有办法快速的定位要找的行。
比较聚集索引表和堆表
为了评估聚集索引表和堆表的性能,我们拷贝了两份SalesOrderDetail表。一张表是堆表,一张表创建了聚集索引。两张表都没有非聚集索引。
在两张表中我们会执行三个相同的查询:一个是获取单行数据,一个是获取单个订单的所有数据,一个是获取同一个产品的所有数据。
获取单行数据。
| SQL语句 | SELECT * FROM SalesOrderDetail WHERE SalesOrderID = 43671 AND SalesOrderDetailID = 120 |
| Heap堆表 | (1 row(s) affected) Table 'SalesOrderDetail_noindex'. Scan count 1, logical reads 1495. |
| Clustered Index聚集索引表 | (1 row(s) affected) Table 'SalesOrderDetail_noindex'. Scan count 1, logical reads 3. |
| Impact of having the Clustered Index包含聚集索引产生的影响 | IO reduced from 1495 reads to 3 reads. |
| Comments | No surprise. Table scanning 121,317 rows to find just one is not very efficient. |
获取单个订单的所有数据。
| SQL | SELECT * FROM SalesOrderDetail WHERE SalesOrderID = 43671 |
| Heap | (11 row(s) affected) Table 'SalesOrderDetail_noindex'. Scan count 1, logical reads 1495. |
| Clustered Index | (11 row(s) affected) Table 'SalesOrderDetail_noindex'. Scan count 1, logical reads 3. |
| Impact of having the Clustered Index | IO reduced from 1495 reads to 3 reads. |
| Comments | 和当一个查询的统计是一样的。堆表需要扫描表,聚集索引表的11条记录是一组的,获取这11条记录和获取一条记录几乎是相同的效率。后面的级别中将会介绍,为什么获取额外的10条记录,却没有产生额外的读取IO。 |
查询同一个产品的所有数据
| SQL | SELECT *
|
| Heap | (228 row(s) affected)
|
| Clustered Index | (228 row(s) affected) Table 'SalesOrderDetail_index'. Scan count 1, logical reads 1513. |
| Impact of having the Clustered Index | IO读取方面,聚集索引表反而更多次数。 |
| Comments | Without a nonclustered index on the ProductID column to help find the rows for a single Product, both versions had to be scanned. Because of the overhead of having a clustered index, the clustered index version is the slightly larger table; therefore scanning it required a few more reads than scanning the heap. 在ProductID列没有非聚集索引来帮助查询同一个产品的数据行,两种表都进行了表扫描。因为包含了聚集索引,聚集索引表更大,所以扫描了更多的次数。 |
我们的前两个查询很好的证明了聚集索引的好处。聚集索引有可能带来IO次数增加的坏处吗?答案是肯定的,和insert,update,delete都有关系。和在本文中遇到的其他聚集索引问题一样,我们将在后面的级别中介绍。
通常来说,聚集索引给查询带来的好处,要大于给维护带来的坏处。聚集索引表比堆表更可取。如果你是在使用云数据库,你不用选择,每张表必须包含聚集索引。
结论
聚集索引表的顺序在你创建聚集索引的时候已经指定了,SQL Server负责维护它。表中的任意行都可以通过键来快速的定位。任意的多行,都可以通过键的范围来快速的定位。
每张表只能有一个聚集索引。哪些列作为聚集索引的键,在创建索引的时候是一个重要的决定。
在第四级中我们的重点会从逻辑转到物理,介绍页和分区,以及索引的物理结构。