ElasticSearch - 分布式搜索引擎底层实现——倒排索引
目录
一、ElasticSearch
1.1、ElasticSearch 是什么?
1.2、ElasticStack 是什么?
1.3、正向索引和倒排索引
1.3.1、正向索引
1.3.2、倒排索引
a)倒排索引的创建过程:
b)倒排索引的查询过程:
c)分析总结:
1.3.3、倒排索引的适用场景
一、ElasticSearch
1.1、ElasticSearch 是什么?
ElasticSearch 是一个非常强大的搜索引擎,可以帮助我们从海量的数据中,快速的找到所需要的内容.
就比如说,咱们大家去淘宝上买东西,你输入了一个商品信息,他是不是立马就搜索出跟你输入关键字有关的信息,例如你输入的关键词是 "IPhone",就可以看到会搜索出各式各样的信息,“IPhone 13 特惠”、"IPhone 10 二手出售".... 甚至还可以看到 IPhone 这个关键字,还变成红色的了,这就叫做高亮显示,是为了更清晰醒目一些.
1.2、ElasticStack 是什么?
这里实际上还有几个组件是和 ElasticSearch 一起搭配使用的,分别是 Kibana、Logstash、Beats,他们结合就是 ElasticStack 技术栈.
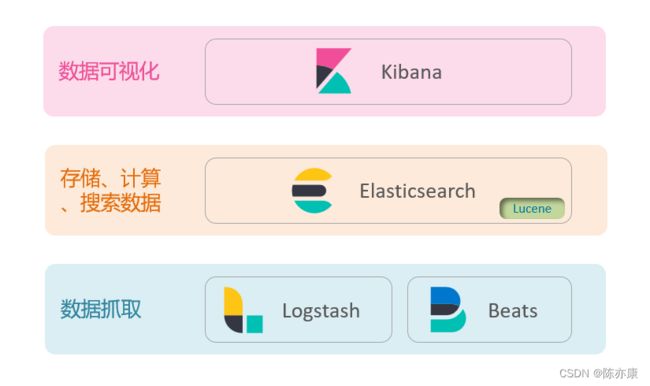
这套东西,被广泛的应用在微服务的日志数据分析和实时监控.
日志数据分析:我们项目在运行的过程中,会产生海量的日志信息,这些大家平常也不少见~ 这些日志信息,就是方便我们去定位系统出现的问题,假设你系统报错了,在线上运行的时候,你总不可能去打断点 debug 吧,那一般就是通过先通过 Logstash 进行日志数据的抓取,elasticsearch 存储、计算、搜索数据,最后通过 Kibana 进行数据可视化给你展示处理,这样,你将来去作日志分析的时候,就非常方便了.
实时监控:在项目运行的时候,他的运行状态也是数据,比如 cpu 、内存情况、访问的频率等等,这些信息也会被 es 管理起来,然后通过可视化给你展示处理啊,这样你就能清除的知道项目的运行情况了.
但实际上,在 ElasticStack 中,Kibana 、Logstash、Beats 这三个组件都是可以替换的,官方提供给你,想用就用,不用也没关系,就比如 淘宝在展示搜索结果的时候,都是有自己的网页自己去展示,就不一定是通过 Kibana 生成的数据报表来展示.但是不可替代的就是 elasticsearch 这个核心(也是之后讲解的重点).
1.3、正向索引和倒排索引
1.3.1、正向索引
传统数据库(比如 mysql)就是采用正向索引.

假如我这里有一张数据库表,一般都会基于 id 去创建一个索引,形成一个 b+ 树,那么根据 id 进行检索的速度就会非常快,那么这种方式就是正向索引. 但是如果现在搜索的字段不是 id,是一个普通的标题字段(一般内容会比较长),所以你不会给他加索引.
那就算你给他加了索引,如果我现在要搜索的不是一个精确的标题值,我只搜其中的一部分,这时候你怎么办?你不是要来一个 select * from 表 where 标题 like 什么... 一旦使用了这样的模糊匹配,即使这个字段有索引,将来也是不生效的,最终导致数据库就会采用逐条扫描的方式,判断每一行数据中是否包含 标题关键字 ,如果不包含就抛弃,如果包含就放到结果集中. 这样一来,假如你有 10亿 条数据,就意味着要扫描 10 亿次啊!性能可想而知. 这也便是正排索引.
1.3.2、倒排索引
elasticsearch 的底层就是采用倒排索引,并且这里涉及到两个概念:
- 文档:每条数据就是一个文档(例如 mysql 表中的一行数据,比如商品表中,一个商品就是一个文档,用户表中一个用户就是一条数据).
- 词条:文档按照语义分成的词语,比如 “华为手机” 这四个字,就可以分成 “华为”和 “手机” .
a)倒排索引的创建过程:
假设有一张商品表:
1. 为 商品表 中 商品名称 倒创建倒排索引时候,会把 商品名称 中的内容分成词条去存储,比如商品名称是 “小米手机” ,那么就把这个标题进行分词得到两个词语 “小米” 和 “手机” 去存储起来.
2. 此时,比如把 “小米” 拿过来存储时,同时也会把他的 id 记录到他的文档中,而 “手机” 这个词就会存到一个新的文档,同时记录他的 id.
3. 如果下一条数据的 商品名称 被分词后又得到了 "手机" 这个词条,就会把他的 id 存到词条相同的文档中.
4. 以此类推,最后数据组织完成了,就可以给得到的所有词条创建索引了,这样,将来根据词条查询的速度是不是就更快了.

b)倒排索引的查询过程:
1. 比如现在来搜索一下 “华为手机”,首先会将他进行分词,得到得到两个词条,“华为”和“手机”.
2. 接下来拿着词条去倒排索引中进行查询,由于刚才就是根据 词条 建立的索引,所以一查就能立刻查到,词条 "华为" 所包含的文档 id(假设 id 有 2,3) ,以及“手机” 所包含的文档 id(假设 id 有 1,2),这时候也就相当于知道了 “华为手机” 包含的所有文档(1,2,3).
3. 其中 id = 2 的商品信息存在于两个文档中,也就是说 id = 2 的商品名称更符合你的搜索的信息,那么将来还会按照这个匹配程度给你排序.
4. 此时,拿着这些 id 就可以去正向索引里查询文档了,而正向索引这边不就是根据 id 建立的索引么,那么拿着 id 就可以快速定位到文档了,将查询到的数据按照排序的 id 放到结果集中.
c)分析总结:
根据上述过程,我们可以看到,搜索的过程经历了两次检索:
- 第一次是根据用户输入的内容的词条,去找到对应的文档 id.
- 第二次是拿着文档 id 来找文档.
这样的查询效率,相比于正向索引中搜索 包含手机关键字的 数据,一行一行去查找就要快的多了.
倒那么这里也能够看出,排索索引为什么是倒排了,因为正向索引中,得一行一行找,找到匹配的放到结果集中,而倒排索引就是反过来,基于词条创建索引,搜多的时候,就是根据词找到对应的文档(正向索引就是根据文档来找词).
1.3.3、倒排索引的适用场景
倒排索引更擅长查询文档的部分内容,比如你去浏览器里搜索内容的一部分关键词,或者是搜索商品信息之类的等等.
这也就是为什么 elasticsearch 是基于 倒排索引 实现的搜索引擎了~~
