平均负载案例分析
我的案例运行在CentOS 7.6.1810,内核是3.10.0-957.el7.x86_64。

grep 'model name' /proc/cpuinfo | wc -l可以看到CPU个数为4,free -h可以看到内存是15G。

需要参考《CentOS 7.6使用yum安装stress,源码安装stress-ng 0.15.06,源码安装sysstat 12.7.2》安装软件。
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的CPU、内存、I/O 以及上下文切换等性能指标。
每个案例都需要打开三个终端,我分别起名A、B和C,在命令行中以#开头的内容是注释,在每个命令执行时就使用#开头的注释做好终端标注,比如ls # A就代表在A终端执行ls命令,而pwd # B表示在B终端执行pwd。
场景一:CPU 密集型进程
在A终端执行uptime # A看一下当前的平均负载。
![]()
stress --cpu 1 --timeout 600 &> output.log & # A在A终端上执行这条命令,模拟一个 CPU 使用率 100% 的场景,注意这里使用&在后台运行了。
![]()
watch -d uptime # B在B终端运行 uptime 查看平均负载的变化情况,-d 参数表示高亮显示变化的区域。
![]()
mpstat -P ALL 5 # C在C终端查看CPU使用率的变化情况。

从B终端中可以看到,1 分钟的平均负载会慢慢增加到 0.08,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。
pidstat -u 5 1 # A在A终端运行查看使用进程的CPU、内存、I/O 以及上下文切换等性能指标。
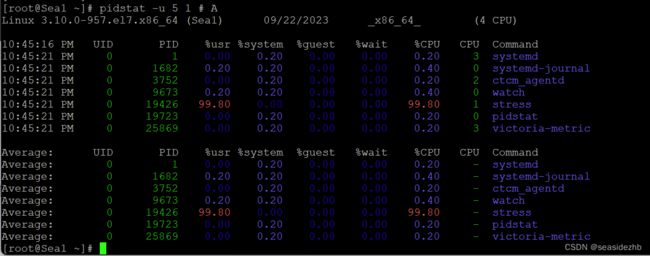
在A执行pidstat -u 5 1 # A之后可以明显看到,stress进程的 CPU 使用率为 99.80%。
kill -9 19425 # A把19425进程给杀掉。
![]()
场景二:I/O 密集型进程
在A终端执行uptime # A看一下当前的平均负载。
![]()
stress-ng -i 1 --hdd 1 --timeout 600 &> output.log & # A在A终端后台中模拟大量读写动作。
![]()
watch -d uptime # B在B终端运行 uptime 查看平均负载的变化情况,-d 参数表示高亮显示变化的区域。
![]()
mpstat -P ALL 5 # C在C终端查看CPU使用率的变化情况。

从这里可以看到,1 分钟的平均负载会慢慢增加到 2.37,其中一个 CPU 的系统 CPU 使用率升高到 3.61%,而iowait高达 50.70%。这说明,平均负载的升高是由于 iowait 的升高。
那么到底是哪个进程,导致 iowait 这么高呢?我们还是用pidstat -u 5 1 # A在A终端运行查看使用进程的CPU、内存、I/O 以及上下文切换等性能指标。
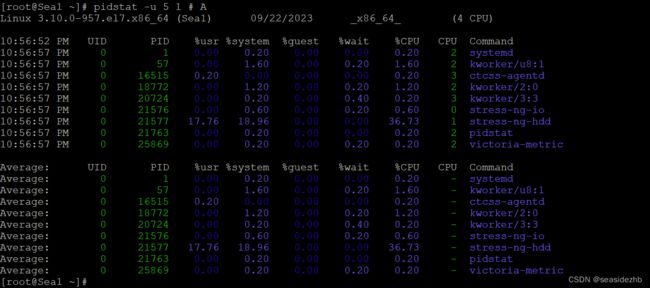
可以看出,stress-ng-hdd进程导致iowait升高。
kill -9 21575把21575进程给杀掉。
![]()
场景三:大量进程的场景
在A终端执行uptime # A看一下当前的平均负载。
![]()
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
stress -c 16 --timeout 600 &> output.log & # A模拟的是 16 个进程,只有4个CPU,故而有等待的进程。
![]()
watch -d uptime # B在B终端运行 uptime 查看平均负载的变化情况,-d 参数表示高亮显示变化的区域,可以看到平均负载一下子就从4.87升到了10.29。

mpstat -P ALL 5 # C在C终端查看CPU使用率的变化情况。

pidstat -u 5 1 # A在A终端运行查看使用进程的CPU、内存、I/O 以及上下文切换等性能指标。

可以看出,16个进程在争抢 4 个 CPU,每个进程等待 CPU 的时间(也就是图片中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
kill -9 24620 24621 24622 24623 24624 24625 24626 24627 24628 24629 24630 24631 24632 24633 24634 24635在A终端中执行,可以把16个进程杀掉。
![]()
分析完这三个案例,再来归纳一下平均负载的理解。
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。
但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
此文章为9月Day 22学习笔记,内容来源于极客时间《Linux 性能优化实战》