手把手教你用Python搭建IP代理池,轻松破解请求频率限制反爬虫~

我们所写的爬虫,它对服务器发出的网络请求频率要比正常用户的高的多,从而开发者可以将请求频率过高的用户视为爬虫程序,从而来限制爬虫程序。
今天志斌就来给大家分享一下,如何用Python搭建一个IP代理池,来破解服务器通过对用户请求频率进行限制的反爬虫。
01
原理
因为客户端的IP地址是唯一的,所以开发者便将IP地址作为客户端的身份标识。
服务器可以根据客户端的IP的访问次数来标识记录,从而计算出它的请求频率。然后,对于请求频率过高的客户端进行反爬虫限制。
02
破解
其实破解请求频率限制反爬虫是十分简单的,因为Requests库中就有一个proxies参数,就是专门为使用IP来准备的,具体使用方法如下:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "https://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
03
搭建IP代理池
搭建一个IP代理池分为三个模块,分别是爬取模块、检测模块、存储模块。下面让我们来看看这三个模块要怎么写吧。
01
爬取模块
我们此次是在百度上搜索的一个免费的IP代理网站对其代理IP进行爬取。
我们打开开发者模式,然后输入对网页进行观察,我们发现数据存储在源网页中。
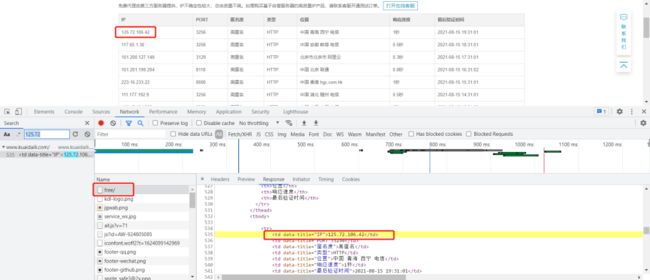
既然我们已经发现数据的存储位置和存储形式了,那么就可以发起请求,提取数据了,代码如下:
import requests
import re
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Referer': 'https://www.kuaidaili.com/free/inha/1/',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
for page in range(1,50):
response = requests.get(f'https://www.kuaidaili.com/free/inha/{page}/', headers=headers, cookies=cookies)
ip_list = re.findall('data-title="IP">(.*?)',response.text)
02
检测模块
因为我们是爬取的免费的IP,所以我们要对其进行检测,看看是否失效了,毕竟便宜没好货,好货不便宜么~ 检测代码如下:
list = []
for ip in ip_list:
try:
response = requests.get('https://www.baidu.com', proxies=ip, timeout=2)
if response.status_code == 200:
list.append(ip)
except:
pass
else:
print(ip, '检测通过')
03
存储模块
我这里是将检测出来可以使用的IP代理存到了csv文件中去,大家也可以尝试使用其他类型的存储,代码如下:
import csv
with open('ip.csv','a',newline='') as f:
writer = csv.writer(f)
writer.writerow(list)
03
小结
1. 本文详细介绍了如何破解请求频率限制的反爬虫,并教大家搭建一个自己的IP代理池。
2. 使用代理IP来进行爬虫是当前一种非常流行的方式,因为每个用户端的IP是唯一的,一旦被认为是爬虫给限制或者是封禁了,那么对于用户来说会造成很大的损失。
3. 免费的IP代理质量不如付费的,如果有大量的需求还是需要购买一下专业的。
4. 本文仅供学习参考,不做它用。
福利
入门Python的最强三件套《ThinkPython》、《简明Python教程》、《Python进阶》的PDF电子版已打包提供给大家,关注下方公众号,在后台回复关键字「P3」即可获取。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片
点阅读原文,领AI全套资料!