爬虫实战入门级教学(数据爬取->数据分析->数据存储)
爬虫实战入门级教学1.0(数据爬取->数据分析->数据存储)
天天刷题好累哦,来一期简单舒适的爬虫学习,小试牛刀(仅供学习交流,不足之处还请指正)
文章讲的比较细比较啰嗦,适合未接触过爬虫的新手,需要源码可直接跳转到文章末尾
完整源码在文章末尾,本期代码已经被官方修复,不过在第二期教程中又被我们突破啦,见第二期教程
强烈建议先观看完第一期在观看第二期!!!
目标
主角:两步路官网(仅作学习交流使用)
爬取旅行轨迹页面数据,以湖北武汉东湖数据为例,按照时间顺序,爬取2010-2022年旅行轨迹数据,并将爬取的页面数据存到xlsx文件,即我们熟知的excel文件,搜索步骤如下图、包括地区:湖北-武汉、搜索轨迹:东湖、按照时间顺序。
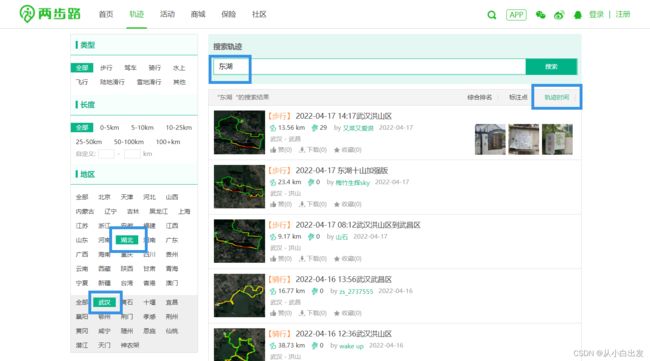
爬取的数据如下图所示,包括出行方式、标题、出行距离、作者名称、出行时间以及起点和终点(还有一条数据:下级页面的URL,后续会有展示)

步骤
一、研究网页
本次测试使用谷歌浏览器,进入开发者工具,找到网络,选择XHR、本网页只有4条数据,因此逐条寻找,直到预览出现网页即可,如下图所示

接着打开标头,如下图所示、虽然我们访问的是 初始URL,
![]()
但是实际上,下图所示的 真实URL 才是我们所需要的。


但是如果我们直接复制并访问 真实URL ,其结果如下,405错误
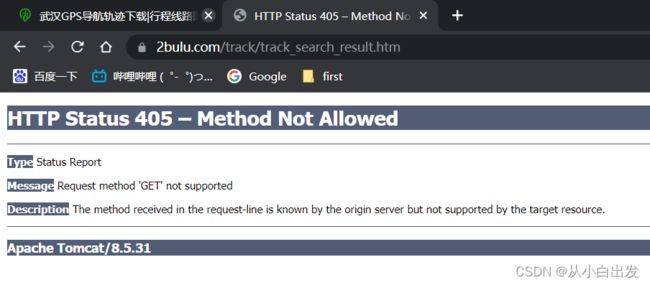
问题出在哪呢?实际上返回的 真实URL 只是原网页的一部分,如下图所示,预览看到的页面,只有搜索的结果。那么我们就知道了, 真实URL 是根据我们的搜索内容返回给我们的。

既然我们知道了, 真实URL 是我们搜索的结果,那么我们到底搜索了什么呢?打开荷载,下图所示就是我们搜索的内容

再研究一下我们的 初始URL,如下图所示,我将其分为4块,本别对应上图的key(东湖的汉字应该是被加密了)、areaId(15728,代表武汉)、pageNumber(1,代表搜索到的数据中的第一页)、sortType(2,代表按时间排序),看来是我们 初始URL 中包含了达到 真实URL 的钥匙。

二、访问网页(编写spider)
spider代码如下(相关依赖不做展示,自行导包即可),因为我们要爬的数据是搜索得到的,所有要通过POST请求,发送搜索数据(data),访问的URL就是上文提到的 真实URL ,不过我们把按时间顺序放入到URL中了,放在data中也可。
# -*- coding = utf-8 -*-
# @Time : 2022/4/16 22:47
# @Author : 从小白出发
# @File : test.py
# @Software : PyCharm
# 真实URL
url = 'https://www.2bulu.com/track/track_search_result.htm?sortType=2'
# 请求头,可以自行百度一下,有很多,也可在开发者工具中复制
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/100.0.4896.88 Safari/537.36', }
# i 代表 pageNumber,从第1页到524页
for i in range(1, 525):
#设置定时3秒访问一次,防止被封ip,实测并不需要,该网页没有针对访问频率的反爬
time.sleep(3)
# 这里就是上文中提到的 荷载 ,即搜索数据
data = {'key': '东湖', 'pageNumber': i, 'areaId': '15728', 'parentId': '15727'}
#发送post请求
resp = requests.post(url=url, headers=head, data=data, timeout=1)
#服务端返回状态码200代表正常
if resp.status_code == 200:
#打印网页结果
print(resp.text)
如下图所示,我们仅展示一部分打印结果
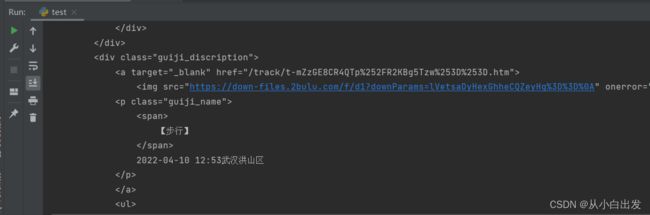
三、网页源码分析
如下图所示,即为我们爬到的网页代码,我并没有展开,因为太多了,那么我们需要对所需数据进一步去提取。
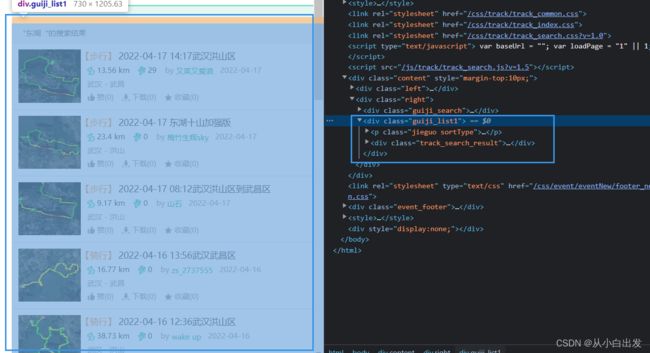
下面我们以起点和终点为例,分析如何通过xpath获取数据
如下图所示,点击中上部分的小图标,再点击网页中我们需要的数据,即可迅速找到其源码(小技巧)

接着在源码中右键复制xpath /html/body/div[3]/div[2]/div[2]/div/div[1]/ul/li[2]
但是 真实URL 返回的并不是整个网页,而是搜索的结果,xpath并不需要从头开始,而是从div开始,即/html/body/div[3]/div[2]/div[2]/div/div[1]这一段xpath是不需要的
直接从/div[1]/ul/li[2]即可,而我们的搜索结果每页有10条,所以xpath为/div[1到10]/ul/li[2]
具体的数据提取见下一节,代码部分(已添加注解)

四、数据提取(编写xpath)
xpath如何获取我们搞明白了,开始提取数据
# 因为每一页仅展示10条数据 因此我们从1到10,j代表每一条
for j in range(1, 11):
# 遍历j并放到div中
# 提取下一级链接, a是超链接, @href可以获取到url
semi_link = h.xpath('//div[' + str(j) + ']//a/@href')
link = 'https://www.2bulu.com' + semi_link[0]
# 提取出行方式, text()可以获取文本内容
way = h.xpath('//div[' + str(j) + ']//p/span[1]/text()')
# 去除数据头和尾部的空格(\t\n)
way = way[0].strip()
# 提取标题
title = h.xpath('//div[' + str(j) + ']//p[1]/text()')
title = title[1].strip()
# 提取出行距离
distance = h.xpath('//div[' + str(j) + ']//li[1]/span[1]/text()')
distance = distance[0].strip()
# 去除数据中间的空格(\t\n)
distance = re.sub('\t', '', distance)
distance = re.sub('\n', '', distance)
# 提取作者名称
author = h.xpath('//div[' + str(j) + ']//li[1]/span[3]/a/text()')
author = author[0].strip()
# 提取起点和终点
travel = h.xpath('//div[' + str(j) + ']//li[2]/text()')
travel = travel[0].strip()
travel = re.sub('\t', '', travel)
travel = re.sub('\n', '', travel)
# 提取出行时间
tim = h.xpath('//div[' + str(j) + ']//li[1]/span[3]/text()')
# 该网页中有的用户名存在特殊字符,比如包含'<'符号,在xpath中被误认为html元素的一部分,因此提取会出现问题
# 本应该提取的作者名称, 实际提取成了出行时间
# 但是在提取出行时间的时候,因为提取不到数据,因此报越界的错误
# 所以这里做一个try catch操作,如果越界,则把作者名称赋值给出行时间,同时将作者名称赋值为'未知字符'
try:
tim = tim[1].strip()
except IndexError as e:
tim = author
author = '未知字符'
# 打印结果
print(str(i - 1) + str(j - 1), link, way, title, distance, author, tim, travel)
部分打印结果展示
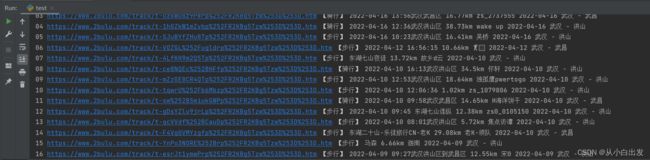
五、数据存储(写入excel)
先判断xlsx文件是否存在,存在直接打开就行,否则创建xlsx文件。
# 数据存储到excel
if not pathlib.Path('myexcel.xlsx').exists():
# 无则创建
book = openpyxl.Workbook()
else:
# 有则打开
book = openpyxl.load_workbook('myexcel.xlsx')
# 激活当前sheet
sheet = book.active
# 行号
row = (i-1)*10+j
# 向单元格插入数据
# 第一行第一列
sheet.cell(row, 1).value = row
# 第一行第二列
sheet.cell(row, 2).value = link
# 依此类推
sheet.cell(row, 3).value = way
sheet.cell(row, 4).value = title
sheet.cell(row, 5).value = distance
sheet.cell(row, 6).value = author
sheet.cell(row, 7).value = tim
sheet.cell(row, 8).value = travel
# 保存文件
book.save("myexcel.xlsx")
结果展示

源码展示(无注解)
源码干净无注解,不懂之处可见上文步骤,欢迎学习交流 ^ - ^
# -*- coding = utf-8 -*-
# @Time : 2022/4/18 11:04
# @Author : 从小白出发
# @File : test.py
# @Software : PyCharm
import pathlib
import re
import time
import openpyxl
import requests
from lxml import etree
url = 'https://www.2bulu.com/track/track_search_result.htm?sortType=2'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/100.0.4896.88 Safari/537.36', }
for i in range(1, 2):
time.sleep(3)
data = {'key': '东湖', 'pageNumber': i, 'areaId': '15728', 'parentId': '15727'}
resp = requests.post(url=url, headers=head, data=data, timeout=1)
if resp.status_code == 200:
h = etree.HTML(resp.text)
for j in range(1, 11):
semi_link = h.xpath('//div[' + str(j) + ']//a/@href')
link = 'https://www.2bulu.com' + semi_link[0]
way = h.xpath('//div[' + str(j) + ']//p/span[1]/text()')
way = way[0].strip()
title = h.xpath('//div[' + str(j) + ']//p[1]/text()')
title = title[1].strip()
distance = h.xpath('//div[' + str(j) + ']//li[1]/span[1]/text()')
distance = distance[0].strip()
distance = re.sub('\t', '', distance)
distance = re.sub('\n', '', distance)
author = h.xpath('//div[' + str(j) + ']//li[1]/span[3]/a/text()')
author = author[0].strip()
travel = h.xpath('//div[' + str(j) + ']//li[2]/text()')
travel = travel[0].strip()
travel = re.sub('\t', '', travel)
travel = re.sub('\n', '', travel)
tim = h.xpath('//div[' + str(j) + ']//li[1]/span[3]/text()')
try:
tim = tim[1].strip()
except IndexError as e:
tim = author
author = '未知字符'
print(str(i - 1) + str(j - 1), link, way, title, distance, author, tim, travel)
if not pathlib.Path('myexcel.xlsx').exists():
book = openpyxl.Workbook()
else:
book = openpyxl.load_workbook('myexcel.xlsx')
sheet = book.active
row = (i-1)*10+j
sheet.cell(row, 1).value = row
sheet.cell(row, 2).value = link
sheet.cell(row, 3).value = way
sheet.cell(row, 4).value = title
sheet.cell(row, 5).value = distance
sheet.cell(row, 6).value = author
sheet.cell(row, 7).value = tim
sheet.cell(row, 8).value = travel
book.save("myexcel.xlsx")
谢谢观 ^ - ^