Stream流式编程实现原理
Java8新特性系列:
- 《Lambda表达式你会吗》
- 《Stream流式编程知识总结》
- 《Stream流式编程实现原理》
上一篇《Stream流式编程知识总结》我们主要针对Stream流式编程的具体使用方法进行了深入的探讨,但是如果再来一个一问三连what?-why?-then?是不是又开始懵比了,哈哈,本文就运用一问三连的形式来进行争取不那么麻烦的解释Stream流式编程的实现原理。
Stream怎么用
其实上篇已经讲过,Stream没用之前我们针对集合的便利帅选等操作更多的是for-loop/while-loop,用了Stream后发现原来代码可以如此简洁,并且越发形似SQL语句。甚至可以做很多复杂的动作:
ap<Integer, List<String>> lowCaloricDishesNameGroup =
dishes.parallelStream() // 开启并行处理
.filter(d -> d.getCalories() < 400) // 按照热量值进行筛选
.sorted(comparing(Dish::getCalories)) // 按照热量进行排序
.collect(Collectors.groupingBy( // 将菜品名按照热量进行分组
Dish::getCalories,
Collectors.mapping(Dish::getName, Collectors.toList())
));

Stream的操作分类
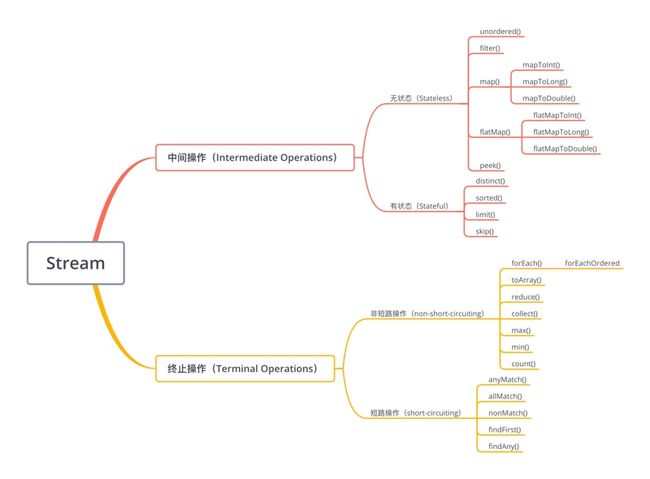
Stream使用一种类似SQL语句的方式,提供对集合运算的高阶抽象,可以将其处理的元素集合看做一种数据流,流在管道中传输,数据在管道节点上进行处理,比如筛选、排序、聚合等。
数据流在管道中经过中间操作(intermediate operation)处理,由终止操作(terminal operation)得到前面处理的结果。这些也在《Stream流式编程知识总结》有相应的说明。
Stream操作分为两类:
-
中间操作:将流一层层的进行处理,并向下一层进行传递,如 filter map sorted等。
中间操作又分为有状态(stateful)及无状态(stateless)- 有状态:必须等上一步操作完拿到全部元素后才可操作,如sorted
- 无状态:该操作的数据不收上一步操作的影响,如filter map
-
终止操作:触发数据的流动,并收集结果,如collect findFirst forEach等。终止操作又分为
短路操作(short-circuiting)及非短路操作(non-short-circuiting)- 短路操作:会在适当的时刻终止遍历,类似于break,如anyMatch findFirst等
- 非短路操作:会遍历所有元素,如collect max等
Stream的实现过程
Stream的实现使用流水线(pipelining)的方式巧妙的避免了多次迭代,其基本思想是在一次迭代中尽可能多的执行用户指定的操作。
Stream采用某种方式记录用户每一步的操作,中间操作会返回流对象,多个操作最终串联成一个管道,管道并不直接操作数据,当用户调用终止操作时将之前记录的操作叠加到一起,尽可能地在一次迭代中全部执行掉,面对如此简洁高效的API不由得使我们有所疑问:
- 用户的操作如何记录?
- 操作如何叠加?
- 叠加后的操作如何执行?
- 执行后的结果(如果有)在哪里?
操作如何记录
Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的PipelineHelper来代表Stage,将各Pipeline按照先后顺序连接到一起,就构成了整个流水线。
与Stream相关类和接口的继承关系如下图,其中蓝色表示继承关系,绿色表示接口实现:

Head用于表示第一个Stage,该Stage不包含任何操作。StatelessOp和StatefulOp分别表示无状态和有状态的Stage。

其中:
- Head记录Stream起始操作,将包装为Spliterator的原始数据存放在Stage中
- StatelessOp记录无状态的中间操作
- StatefulOp记录有状态的中间操作
- TerminalOp用于触发数据数据在各Stage间的流动及处理,并收集最终数据(如果有)
使用Collection.stream、Arrays.stream或Stream.of等接口会生成Head,其内部均采用StreamSupport.stream方法,将原始数据包装为Spliterator存放在Stage中。
Head、StatelessOp、StatefulOp三个操作实例化会指向其父类AbstractPipeline。
对于Head:
/**
* Constructor for the head of a stream pipeline.
*
* @param source {@code Spliterator} describing the stream source
* @param sourceFlags the source flags for the stream source, described in
* {@link StreamOpFlag}
* @param parallel {@code true} if the pipeline is parallel
*/
AbstractPipeline(Spliterator<?> source, int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
Head操作会将包装为Spliterator的原始数据存放在该Stage中,将自身存放sourceStage中,并把串并行操作也记录在内。Head的前期功能就是记录这些源数据。
对于StatelessOp及StatefulOp:
/**
* Constructor for appending an intermediate operation stage onto an
* existing pipeline.
*
* @param previousStage the upstream pipeline stage
* @param opFlags the operation flags for the new stage, described in
* {@link StreamOpFlag}
*/
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
中间操作通过previousStage及nextStage,将各Stage串联为一个双向链表,使得每一步都知道上一步与下一步的操作。
每一个中间操作Stage中的sourceStage都指向前一个Stage的soureStage,如此递归,最终指向Head。卧槽,似乎是不是明白些啥了,接着往下看吧,现在仅仅是第一阶段。

操作如何叠加
上一个问题解决了每一步操作数据源以及内部实现是怎么记录的,此时并没有执行,Stage只是保存了当前的操作,并不能确定下一个Stage需要何种操作,所以想要让pipeline运行起来,需要一种将所有操作叠加到一起的方案。
Stream类库采用了Sink接口来协调各Stage之间的关系:
interface Sink<T> extends Consumer<T> { /** * Resets the sink state to receive a fresh data set. This must be called * before sending any data to the sink. After calling {@link #end()}, * you may call this method to reset the sink for another calculation. * @param size The exact size of the data to be pushed downstream, if * known or {@code -1} if unknown or infinite. * *Prior to this call, the sink must be in the initial state, and after * this call it is in the active state. * * 开始遍历前调用,通知Sink做好准备 */ default void begin(long size) {} /** * Indicates that all elements have been pushed. If the {@code Sink} is * stateful, it should send any stored state downstream at this time, and * should clear any accumulated state (and associated resources). * *
Prior to this call, the sink must be in the active state, and after * this call it is returned to the initial state. * * 所有元素遍历完成后调用,通知Sink没有更多元素了 */ default void end() {} /** * Indicates that this {@code Sink} does not wish to receive any more data. * * @implSpec The default implementation always returns false. * * @return true if cancellation is requested * * 是否可以结束操作,可以让短路操作尽早结束 */ default boolean cancellationRequested() {} /** * Accepts a value. * * @implSpec The default implementation throws IllegalStateException. * * @throws IllegalStateException if this sink does not accept values * * 遍历时调用,接收的一个待处理元素,并对元素进行处理。 * Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前 * Stage.accept方法即可 */ default void accept(T value) {} }
其实Stream的各种操作实现的本质,就是如何重载Sink的这四个接口方法,各个操作通过Sink接口accept方法依次向下传递执行。
下面结合具体源码来理解Stage是如何将自身的操作包装成Sink,以及Sink是如何将处理结果转发给下一个Sink的。
无状态Stage(Stream.map):
// Stream.map 将生成一个新Stream
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
// 该方法将回调函数(处理逻辑)包装成Sink
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
// 接收数据,使用当前包装的回调函数处理数据,并传递给下游Sink
downstream.accept(mapper.apply(u));
}
};
}
};
}
有状态Stage(Stream.sorted):
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
// 存放用于排序的元素
private ArrayList<T> list;
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
// 创建用于存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
public void end() {
// 只有在接收到所有元素后才开始排序
list.sort(comparator);
downstream.begin(list.size());
// 排序完成后,将数据传递给下游Sink
if (!cancellationWasRequested) {
// 下游Sink不包含短路操作,将数据依次传递给下游Sink
list.forEach(downstream::accept);
}
else {
// 下游Sink包含短路操作
for (T t : list) {
// 对于每一个元素,都要询问是否可以结束处理
if (downstream.cancellationRequested()) break;
// 将元素传递给下游Sink
downstream.accept(t);
}
}
// 告知下游Sink数据传递完毕
downstream.end();
list = null;
}
@Override
public void accept(T t) {
// 依次将需要排序的元素加入到临时列表中
list.add(t);
}
}
Stream.sorted会在接收到所有元素之后再进行排序,之后才开始将数据依次传递给下游Sink。
两个操作之间通过Sink接口的accept方法进行挂钩,此时如果从第一个Sink开始执行accept方法便可以把整个管道流动起来,但是这个“如果”怎么实现呢?另外记着每一个操作中的opWrapSink是用于包装Sink的,也就是说只有包装后的Sink才具有条件使得整个管道流动起来。
叠加后的操作如何执行
终止操作(TerminalOp)之后不能再有别的操作,终止操作会创建一个包装了自己操作的Sink,这个Sink只处理数据而不会将数据传递到下游Sink(没有下游了)。
在调用Stream的终止操作时,会执行AbstractPipeline.evaluate:
/**
* Evaluate the pipeline with a terminal operation to produce a result.
*
* @param the type of result
* @param terminalOp the terminal operation to be applied to the pipeline.
* @return the result
*/
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp /* 各种终止操作 */) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) /* 并发执行 */
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); /* 串行执行 */
}
最终会根据并行还是串行执行TerminalOp中不同的的evaluate方法。如果是串行执行,接下来在TerminalOp的evaluate方法中会调用wrapAndCopyInto来包装、串联各层Sink,触发pipeline,并获取最终结果。
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink /* TerminalSink */, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
其中wrapSink(包装)实现:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// AbstractPipeline.this,最后一层Stage
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
// 从下游向上游遍历,不断包装Sink
sink = p.opWrapSink(p.previousStage.combinedFlags, sink /* 下一层Stage的Sink */);
}
return (Sink<P_IN>) sink;
}
wrapSink方法通过下游Stage的“opWrapSink”方法不断将下游Stage的Sink从下游向上游遍历包装,最终得到上文我说的第一个Sink。

有了第一个Sink,如何执行呢,还记的wrapAndCopyInto中的copyInto吧:
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
// 不包含短路操作
// 1. begin
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 2. 遍历调用 sink.accept
spliterator.forEachRemaining(wrappedSink);
// 3. end
wrappedSink.end();
}
else {
// 包含短路操作
copyIntoWithCancel(wrappedSink, spliterator);
}
}
final <P_IN> void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
// 1. begin
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 2. 遍历调用 sink.accept
// 每一次遍历都询问cancellationRequested结果
// 如果cancellationRequested为true,则中断遍历
p.forEachWithCancel(spliterator, wrappedSink);
// 3. end
wrappedSink.end();
}
copyInto会根据不同的情况依次调用:
- sink.bigin
- sink.accept(遍历调用,如果包含短路操作,则每次遍历都需要询问cancellationRequested,适时中断遍历)
- sink.end
执行结果在哪儿
每一种TerminalSink中均会提供一个获取最终结果的方法:

TerminalOp通过调用TerminalSink中的对应方法,获取最终的数据并返回,如ReduceOp中:
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
Stream并行执行原理
使用Collection.parallelStream或Stream.parallel等方法可以将当前的Stream流标记为并行执行。
上文提到在调用Stream的终止操作时,会执行AbstractPipeline.evaluate方法,根据paraller标识是执行并行操作还是串行操作:
...
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) /* 并发执行 */
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); /* 串行执行 */
如果被标记为sequential,则会调用TerminalOp.evaluateSequential,evaluateSequential的调用过程上文已经讲述的很清楚。
如果被标记为parallel,则会调用TerminalOp.evaluateParallel,对于该方法不同的TerminalOp会有不同的实现,但都使用了ForkJoin框架,将原始数据不断拆分为更小的单元,对每一个单元做上述evaluateSequential类似的动作,最后将每一个单元计算的结果依次整合,得到最终结果。
ForkJoin在《Stream流式编程知识总结》有所说明。默认情况下,ForkJoin的线程数即为机器的CPU核数,如果想自定义Stream并行执行的线程数,可以参考Custom Thread Pools In Java 8 Parallel Streams
最后
本文详细讲述了Stream流的实现原理,刚开始研究的时候也是云里雾里,弄懂后才知道原来是“一波三折”,用这个词再合适不过了:
- Head包装最初的数据源,它不属于Stream流中的任何操作,并且Stream流中每一个操作都会指向Head,用于将来数据源便捷取出。
- 每一个操作都是一个Stage,每一个Stage都有上下游指针,使得每一个Stage进行挂钩,形成双链表。
- 每一个Stage都会通过Sink接口协议使得两个Stage之间的操作进行挂钩,上游执行下游。
- 终止操作根据“从下游向上游”原则依次包装Sink,最终得到第一个Sink。
- 从第一个Sink执行使得整个管道的流动,得到最终结果。
我是i猩人,总结不易,转载注明出处,喜欢本篇文章的童鞋欢迎点赞、关注哦。
参考
- https://segmentfault.com/a/1190000018919146
- https://www.cnblogs.com/Dorae/p/7779246.html
- https://segmentfault.com/a/1190000019143092#