【Python基础】Python正则表达式入门到入魔

关于正则表达式,很多人认为,使用的时候查询下就可以,没必要深入学习,但是知识与应用永远都是螺旋辩证的关系,有需要查询也无可厚非,但是先掌握知识,可以让应用更创新,更深入,超越他人,必须要先掌握大量的深刻的知识。
如果正则学的好,你会发现它功能强大、妙用无穷。对于很多实际工作来讲,正则表达式简直是灵丹妙药,能够成百倍地提高开发效率和程序质量。
但是学习正则并非易事:知识点琐碎、记忆点多、符号乱,难记忆、难描述、广而深且,为此,我做了一个全面的整理,希望能帮助到大家。
正则表达式是一个复杂的主题,因此本文非常长,作者能力有限,错误之处,恳请指正,为了方便阅读,先看文章目录:
一、起源发展
1、20世纪40年代
2、20世纪50年代
3、20世纪60年代
4、20世纪80年代
二、学习资料
1、re模块官方文档(中文版)
2、Python内置模块
3、re模块库源代码
4、正则表达HOWTO
5、学习网站
三、re模块简介
四、语法原理
1、基本元字符
2、数量元字符
3、位置元字符
4、特殊元字符
5、前后查找
6、回溯引用
7、大小写转换
五、常量模块
1、IGNORECASE
2、ASCII
3、DOTALL
4、MULTILINE
5、VERBOSE
6、LOCALE
7、UNICODE
8、DEBUG
9、TEMPLATE
10、常量总结
六、函数模块
1、查找一个匹配项
1)search()
2)match()
3)fullmatch()
2、查找多个匹配项
1)findall()
2)finditer()
3、匹配项分割
1)split()
4、匹配项替换
1)sub()
2)subn()
5、编译正则对象
6、转义函数
7、缓存清除函数
六、异常模块
一、起源发展
我们在学习一门技术的时候有必要简单的了解其起源与发展过程,这对学习知识有一定的帮助。
1、20世纪40年代
正则表达式最初的想法来自两位神经学家:沃尔特·皮茨与麦卡洛克,他们研究出了一种用数学方式来描述神经网络的模型。
2、20世纪50年代
一位名叫Stephen Kleene的数学科学家发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。
3、20世纪60年代
C语言之父、UNIX之父肯·汤普森把这个“正则表达式”的理论成果用于做一些搜索算法的研究,他描述了一种正则表达式的编译器,于是出现了应该算是最早的正则表达式的编译器qed(这也就成为后来的grep编辑器)。
Unix使用正则之后,正则表达式不断的发展壮大,然后大规模应用于各种领域,根据这些领域各自的条件需要,又发展出了许多版本的正则表达式,出现了许多的分支。我们把这些分支叫做“流派”。
4、20世纪80年代
Perl语言诞生了,它综合了其他的语言,用正则表达式作为基础,开创了一个新的流派,Perl流派。之后很多编程语言如:Python、Java、Ruby、.Net、PHP等等在设计正则式支持的时候都参考Perl正则表达式。到这里我们也就知道为什么众多编程语言的正则表达式基本一样,因为他们都师从Perl。注:Perl语言是一种擅长处理文本的语言,Larry在1987年创建,Practical Extraction and Report Language,实用报表提取语言,但因晦涩语法和古怪符号不利于理解和记忆导致很多开发者并不喜欢。
二、学习资料
Python对正则表达式的支持,主要是re库,这是一个Python的标准库。也就是该库是一个内置模块(Python大概300个内置模块),不需要额外的下载,使用的时候,直接 import re 加载即可。下面是一些常用的学习资料链接。
1、re模块官方文档(中文版)
https://docs.python.org/zh-cn/3.7/library/re.html
2、Python内置模块
https://docs.python.org/3/py-modindex.html#cap-r
3、re模块库源代码
https://github.com/python/cpython/blob/3.8/Lib/re.py
4、正则表达HOWTO
https://docs.python.org/zh-cn/3.7/howto/regex.html#regex-howto
5、学习网站
https://www.runoob.com/python/python-reg-expressions.html
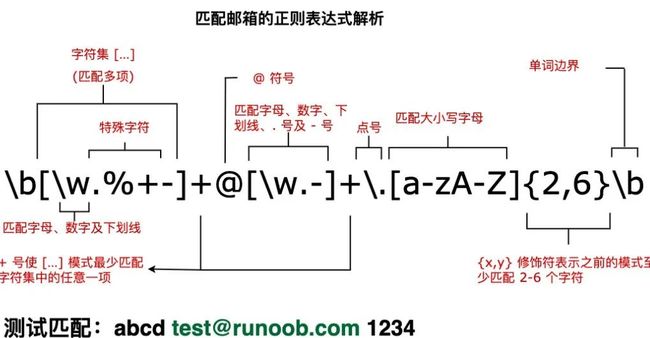
三、re模块简介
Python的re模块主要定义了9个常量、12个函数、1个异常,下面先讲一些基本原理后,慢慢介绍具体的函数用法。
import re
print(dir(re))
['A', 'ASCII', 'DEBUG', 'DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'Match',
'Pattern', 'RegexFlag', 'S', 'Scanner', 'T', 'TEMPLATE', 'U', 'UNICODE', 'VERBOSE', 'X', ...,
'compile', 'copyreg', 'enum', 'error', 'escape', 'findall', 'finditer', 'fullmatch', 'functools',
'match', 'purge', 'search', 'split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']
四、语法原理
完整的正则表达式由两种字符构成:特殊字符(元字符)和普通字符。元字符表示正则表达式功能的最小单位,如* ^ $ \d等
1、基本元字符
.
在默认模式,匹配除了换行的任意字符。如果指定了标签re.DOTALL,它将匹配包括换行符的任意字符。
import re
#除了换行符\n,其他都匹配出来了
re.findall(r'.','小伍哥\n真帅')
['小', '伍', '哥', '真', '帅']
#加了条件,都匹配出来了
re.findall(r'.','小伍哥\n真帅',re.DOTALL)
['小', '伍', '哥', '\n', '真', '帅']
#匹配'd...c',三个点表示中间三个字符
re.findall(r'd...c','abd9匹配cdd')
['d9匹配c']
\
转义特殊字符(允许你匹配'*','?', 或者此类其他特殊字符),或者表示一个特殊序列;如果你没有使用原始字符串(r'raw')来表达样式,要牢记Python也使用反斜杠\作为转义序列;如果转义序列不被Python的分析器识别,反斜杠和字符才能出现在字符串中。如果Python可以识别这个序列,那么反斜杠就应该重复两次。这将导致理解障碍,所以高度推荐,就算是最简单的表达式,也要使用原始字符串。
[]
用于表示一个字符集合。在一个集合中:
1)字符可以单独列出,比如[amk]匹配'a','m',或者'k'。
re.findall(r'[小帅]','小伍哥真帅')
['小', '帅']
2)可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。如果-进行了转义(比如[a\-z])或者它的位置在首位或者末尾(如[-a]或[a-]),它就只表示普通字符'-'。
#匹配从00到59的两位数字
re.findall(r'[0-5][0-9]','012234456789')
['01', '22', '34', '45']
3)特殊字符在集合中,失去它的特殊含义。如[(+*)]只会匹配这几个文法字符'(', '+', '*', 或')'。
4)字符类如\w或者\S(如下定义) 在集合内可以接受,它们可以匹配的字符由ASCII或LOCALE模式决定。
5)不在集合范围内的字符可以通过取反来进行匹配。如果集合首字符是'^',所有不在集合内的字符将会被匹配,比如[^5] 将匹配所有字符,除了'5',[^^]将匹配所有字符,除了'^'.^如果不在集合首位,就没有特殊含义。
#除了TM,都匹配出来
re.findall(r'[^TM]','小伍哥真TM帅')
['小', '伍', '哥', '真', '帅']
|
A|B,A和B可以是任意正则表达式,创建一个正则表达式,匹配A或者B.,任意个正则表达式可以用'|'连接。它也可以在组合(见下列)内使用。扫描目标字符串时,'|'分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时,这个分支就被接受。意思就是,一旦A匹配成功,B就不再进行匹配,即便它能产生一个更好的匹配。或者说'|'操作符绝不贪婪。如果要匹配'|'字符,使用\|,或者把它包含在字符集里,比如[|]。
-
可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。
re.findall(r'[1-3]','012234456789')#查找所有1-3之间的自然数
['1', '2', '2', '3']
()
匹配器整体为一个原子,即模式单元可以理解为多个原子组成的大原子
2、数量元字符
*
对它前面的正则式匹配0到任意次重复,ab*会匹配 'a','ab','abbb...',注意只重复b,尽量多的匹配字符串。
re.findall(r'ab*','ababbbbaabbcaacb')
['ab', 'abbbb', 'a', 'abb', 'a', 'a']
#重复.0到任意次,.有代表任意字符,所有d.*c能匹配dc之间包含任意字符
re.findall(r'd.*c','abd9我爱学习cdd')
['d9我爱学习c']
+
对它前面的正则式匹配1到任意次重复。ab+会匹配'a'后面跟随1个以上到任意个'b',它不会匹配'a'。
re.findall(r'ab+','ababbbbaabbcaacb')
['ab', 'abbbb', 'abb']
?
对它前面的正则式匹配0到1次重复。ab?会匹配'a'或者'ab'。
re.findall(r'ab?','ababbbbaabbcaacb')
['ab', 'ab', 'a', 'ab', 'a', 'a']
*?, +?, ??
'*','+',和'?'的懒惰模式,'*','+','?'修饰符都是贪婪的,它们在字符串进行尽可能多的匹配。有时候并不需要这种行为。在修饰符之后添加'?'将使样式以非贪婪方式或者dfn最小方式进行匹配,尽量少的字符将会被匹配。
#看结果,确实有点太懒惰了,只匹配了a
re.findall(r'ab*?','ababbbbaabbcaacb')
['a', 'a', 'a', 'a', 'a', 'a']
{m}
对其之前的正则式指定匹配m个重复,少于m的话就会导致匹配失败。比如,a{6}将匹配6个'a', 但是不能是5个。
#a后面2个b
re.findall(r'ab{2}','ababbbbaabbcaacb')
['abb', 'abb']
{m,n}
对正则式进行m到n次匹配,在m和n之间取尽量多,比如a{3,5}将匹配3到5个'a'。忽略m意为指定下界为0,忽略n指定上界为无限次。比如a{4,}b将匹配'aaaab'或者10000000个'a'尾随一个'b',但不能匹配'aaab'。逗号不能省略,否则无法辨别修饰符应该忽略哪个边界。
re.findall(r'ab{2,4}','ababbbbaabbcaacb')
['abbbb', 'abb']
re.findall(r'a{2}b{2,4}','ababbbbaabbcaacb')
['aabb']
{m,}
匹配前一个字符(或者子表达式至少m次)
re.findall(r'ab{2,}','ababbbbaabbcaacb')
['abbbb', 'abb']
{m,n}?
上一个修饰符的非贪婪模式,只匹配尽量少的字符次数。比如对于'aaaaaa',a{3,5}匹配5个'a',而a{3,5}?只匹配3个'a'。
re.findall(r'ab{2,4}?','ababbbbaabbcaacb')
['abb', 'abb']
re.findall(r'a{3,5}','aaaaaa')
['aaaaa']
re.findall(r'a{3,5}?','aaaaaa')
['aaa', 'aaa'
3、位置元字符
^
匹配字符串的开头是否包含正则表达式, 并且在MULTILINE模式也匹配换行后的首个符号。
#匹配字符串开头是否包含emrT
re.findall(r'^[emrT]','He was carefully')
[]
#匹配开头是否包含emrH
re.findall(r'^[emrH]','He was carefully')
['H']
#匹配开头是否包含2个以上的a
re.findall(r'^a{2,}','aaabc'
$
匹配字符串尾或者在字符串尾的换行符的前一个字符,在MULTILINE模式下也会匹配换行符之前的文本。foo匹配 'foo' 和 'foobar',但正则表达式foo$只匹配 'foo'。在'foo1\nfoo2\n'中搜索 foo.$,通常匹配 'foo2',但在MULTILINE模式下可以匹配到 'foo1';在 'foo\n'中搜索$会找到两个(空的)匹配:一个在换行符之前,一个在字符串的末尾。
re.findall(r'foo','foo')
['foo']
re.findall(r'foo','foobar')
['foo']
re.findall(r'foo$','foo')
['foo']
re.findall(r'foo$','foobar')
[]
re.findall(r'[ey]','He was carefully')
['e', 'e', 'y']
re.findall(r'[ey]$','He was carefully')
['y']
\A
只匹配字符串开始。
\Z
只匹配字符串尾。
\b
匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。注意,通常\b定义为\w和\W字符之间,或者\w和字符串开始/结尾的边界,意思就是r'\bfoo\b'匹配'foo','foo.','(foo)','bar foo baz'但不匹配'foobar'或者'foo3'。
默认情况下,Unicode字母和数字是在Unicode样式中使用的,但是可以用ASCII标记来更改。如果 LOCALE 标记被设置的话,词的边界是由当前语言区域设置决定的,\b 表示退格字符,以便与Python字符串文本兼容。
\B
匹配空字符串,但不能在词的开头或者结尾。意思就是r'py\B'匹配'python','py3','py2', 但不匹配'py','py.', 或者'py!'.\B是\b的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成的,虽然可以用ASCII标志来改变。如果使用了LOCALE标志,则词的边界由当前语言区域设置。
4、特殊元字符
\d
对于Unicode (str) 样式:匹配任何Unicode十进制数(就是在Unicode字符目录[Nd]里的字符)。这包括了[0-9],和很多其他的数字字符。如果设置了ASCII标志,就只匹配[0-9] 。
对于8位(bytes)样式:匹配任何十进制数,就是[0-9]。
re.findall(r'\d','chi13putao14butu520putaopi666')
['1', '3', '1', '4', '5', '2', '0', '6', '6', '6']
re.findall(r'\d+','chi13putao14butu520putaopi666')
['13', '14', '520', '666']
\D
匹配任何非十进制数字的字符。就是\d取非。如果设置了ASCII标志,就相当于[^0-9] 。
re.findall(r'\D','chi13putao14butu520putaopi666')
['c', 'h', 'i', 'p', 'u', 't', 'a', 'o', 'b', 'u', 't', 'u',
'p', 'u', 't', 'a', 'o', 'p', 'i']
re.findall(r'\D+','chi13putao14butu520putaopi666')
['chi', 'putao', 'butu', 'putaopi']
\s
对于 Unicode (str) 样式:匹配任何Unicode空白字符(包括[ \t\n\r\f\v] ,还有很多其他字符,比如不同语言排版规则约定的不换行空格)。如果ASCII被设置,就只匹配 [ \t\n\r\f\v] 。
对于8位(bytes)样式:匹配ASCII中的空白字符,就是[ \t\n\r\f\v] 。
\S
匹配任何非空白字符。就是\s取非。如果设置了ASCII标志,就相当于[^ \t\n\r\f\v] 。
re.findall(r'\S+','chi putao14butu putaopi666')
['chi', 'putao14butu', 'putaopi666']
\w
对于Unicode (str) 样式:匹配Unicode词语的字符,包含了可以构成词语的绝大部分字符,也包括数字和下划线。如果设置了ASCII标志,就只匹配[a-zA-Z0-9_] 。
对于8位(bytes)样式:匹配ASCII字符中的数字和字母和下划线,就是[a-zA-Z0-9_]。如果设置了LOCALE标记,就匹配当前语言区域的数字和字母和下划线。
#未设置,全部匹配
re.findall(r'\w+','chi小伍哥putao14butu真putaopi帅666')
['chi小伍哥putao14butu真putaopi帅666']
#设置了re.ASCII,只匹配数字和字母
re.findall(r'\w+','chi小伍哥putao14butu真putaopi帅666', re.ASCII)
['chi', 'putao14butu', 'putaopi', '666']
\W
匹配任何不是单词字符的字符。这与\w正相反。如果使用了ASCII旗标,这就等价于[^a-zA-Z0-9_]。如果使用了LOCALE旗标,则会匹配在当前区域设置中不是字母数字又不是下划线的字符。
re.findall(r'\W+','chi小伍哥putao14butu真putaopi帅666', re.ASCII)
['小伍哥', '真', '帅']
[\b]
它只在字符集合内表示退格,比如[\b]
5、前后查找
import re
from urllib import request
#爬虫爬取百度首页内容
data=request.urlopen("http://www.baidu.com/").read().decode()
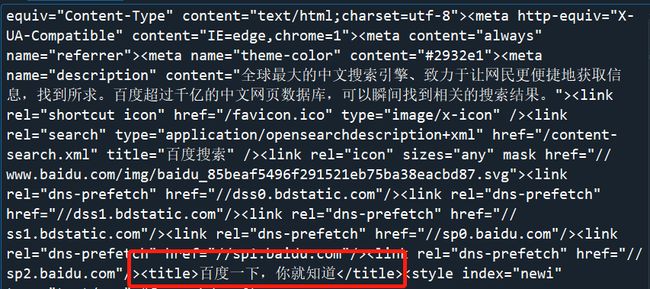
#分析网页,确定正则表达式
pat=r'(.*?) '
result=re.search(pat,data)
print(result)
百度一下,你就知道'>
result.group() # 百度一下,你就知道
'百度一下,你就知道 '
在爬取的HTML页面中,要匹配出一对标签之间的文本,'
#正则表达式
re.findall(r'<[Tt][Ii][Tt][Ll][Ee]>.*?','welcome to my page ')
#结果
['welcome to my page ']
分析:<[Tt][Ii][Tt][Ll][Ee]>表示不区分大小写,这个模式匹配到了title标签以及它们之间的文本,但是并不完美,因为我们只想要title标签之间的文本,而不包括标签本身。为了解决类似的问题,我们就需要用到前后查找的方法。
1)向前查找
向前查找指定了一个必须匹配但不在结果中返回的模式。向前查找实际上就是一个子表达式,它以?=开头,需要匹配的文本跟在=的后面。
#使用向前查找
re.findall(r'<[Tt][Ii][Tt][Ll][Ee]>.*?(?=)','welcome to my page ')
#返回结果
['welcome to my page']
#可以看大,后面个 已经没有了,但是前面个还在,那要用到我们的向后查找
#看一个提取http的例子
re.findall(r'.+(?=:)','http://blog.csdn.net/mhmyqn')
['http']
'''分析:URL地址中协议部分是在:之前的部分,模式.+匹配任意文本,子表达式(
?=:)匹配:,但是被匹配到的:并没有出现在结果中。我们使用?=向正则表达式引擎表明
,只要找到:就行了,但不包括在最终的返回结果里。这里如果不使用向前匹配(?=:)
,而是直接使用(:),那么匹配结果就会是http:了,它包括了:,并不是我们想要的。'''
2)向后查找
向后查找操作符是?<=。并不是所有的语言都支持向后查找,JavaScript就不支持,java语言支持向后查找。
比如要查找文本当中的价格(以$开头,后面跟数字),结果不包含货币符号:
文本:category1:$136.25,category2:$28,category3:$88.60
正则表达式:(?<=\$)\d+(\.\d+)?
结果:category1:$【136.25】,category2:$【28】,category3:$【88.60】
分析:(?<=\$)模式匹配$,\d+(\.\d+)?模式匹配整数或小数。从结果可以看出,结果不没有包括货币符号,只匹配出了价格。如果不使用向后查找,情况会是什么样呢?使用模式$\d+(\.\d+)?,这样会把$包含在结果中。使用模式\d+(\.\d+)?,又会把categery1(23)中的数字也匹配出来,都不是我们想要的。
注意:向前查找模式的长度是可变的,它们可以包含.、*、+之类的元字符;而向后查找模式只能是固定长度,不能包含.、*、+之类的元字符。
3)前后查找
把向前查找和向后查找结合起来使用,即可解决前面HTML标签之间的文本的问题:
#正则表达
re.findall(r'(?<=<[Tt][Ii][Tt][Ll][Ee]>).*?(?=)','welcome to my page ')
#结果
['welcome to my page']
分析:从结果可以看出,问题完美的解决了。(?<=<[Tt][Ii][Tt][Ll][Ee]>)是一个向后操作,它匹配
4)前后查找取非
前面说到的向前查找和向后查找通常都是用来匹配文本,其目的是为了确定将被返回的匹配结果的文本的位置(通过指定匹配结果的前后必须是哪些文本)。这种用法叫正向前查找和正向后查找。还有一种负向前查找和负向后查找,是查找那些不与给定模式相匹配的文本。
比如一段文本中即有价格(以$开头,后面跟数字)和数量,我们要找出价格和数量,先来看查找价格:
文本:I paid $30 for 10 apples, 15 oranges, and 10 pears. I saved $5 onthis order.
正则表达式:(?<=\$)\d+
结果:I paid 【$30】 for 10 apples, 15 oranges, and 10 pears. I saved 【$5】 on thisorder.
re.findall(r'(?<=\$)\d+','I paid $30 for 10 apples, 15 oranges, and 10 pears. I saved $5 onthis order.')
['30', '5']
查找数量:
文本:I paid $30 for 10 apples, 15 oranges, and 10 pears. I saved $5 onthis order.
正则表达式:\b(?
结果:I paid $30 for 【10】 apples, 【15】 oranges, and 【10】pears. I saved $5 on this order.
分析:(?
5)小结
前后查找的操作符:
(?=) |
正向前查找 |
(?!) |
负向前查找 |
(?<=) |
正向后查找 |
(? |
负向后查找 |
有了前后查找,就可以对最终的匹配结果包含哪些内容做出精确的控制。前后查找操作使我们可以利用子表达式来指定文本匹配操作发生的位置,并收到只匹配不消费的效果。
6、回溯引用
回溯引用是正则表达式内的一个“动态”的正则表达式,让你根据实际的情况变化进行匹配。说白了,就是一个根据你的需要,动态变化的表达式。
举个栗子:
你原本要匹配
之间的内容,现在你知道HTML有多级标题,你想把每一级的标题内容都提取出来。你也许会这样写:p = r".*? "
这样一来,你就可以将HTML页面内所有的标题内容全部匹配出来。即
到的内容都可以被提取出来。但是我们之前说过,写正则表达式困难的不是匹配到想要的内容,而是尽可能的不匹配到不想要的内容。在这个例子中,很有可能你就会被下面这样的用例玩坏。比方说
hello world
发现后面的了吗?我们不管是怎么写出来这样的标题的,但实实在在的是我们的正则表达式同样会把这里面的hello world匹配出来。这时候就是回溯引用的重要作用。下面就是一个示例:
import re
key = r"hello world"
p1 = r".*?"
pattern1 = re.compile(p1)
m1 = re.search(pattern1,key)
print m1.group(0)#这里是会报错的,因为匹配不到,你如果将源字符串改成
#结尾就能看出效果
看到\1了吗?原本那个位置应该是[1-6],但是我们写的是\1,我们之前说过,转义符\干的活就是把特殊的字符转成一般的字符,把一般的字符转成特殊字符。普普通通的数字1被转移成什么了呢?在这里1表示第一个子表达式,也就是说,它是动态的,是随着前面第一个子表达式的匹配到的东西而变化的。比方说前面的子表达式内是[1-6],在实际字符串中找到了1,那么后面的\1就是1,如果前面的子表达式在实际字符串中找到了2,那么后面的\1就是2。
类似的,\2,\3,....就代表第二个第三个子表达式。
所以回溯引用是正则表达式内的一个“动态”的正则表达式,让你根据实际的情况变化进行匹配。
7、大小写转换
\E end,表示大小写转换的结束范围
\l low,表示把下一个字符转为小写
\L Low,表示把\L与\E之间的字符转为小写
\u up,表示把下一个字符转为大写
\U Up,表示把\U与\E之间的字符转为大写
五、常量模块
下面我们来快速学习这些常量的作用及如何使用他们,按常用度排序!
1、IGNORECASE
语法: re.IGNORECASE 或简写为 re.I
含义: 进行忽略大小写匹配。
re.findall(r'TM','小伍哥tm真帅')
[]
re.findall(r'TM','小伍哥tm真帅',re.IGNORECASE)
['tm']
在默认匹配模式下小写字母tm无法匹配大写字母TM的,而在忽略大小写模式下就可以匹配了。
2、ASCII
语法: re.ASCII 或简写为 re.A
作用: 顾名思义,ASCII表示ASCII码的意思,让 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII,而不是Unicode。
re.findall(r'\w+','小伍哥tm真帅')
['小伍哥tm真帅']#w匹配所有字符
re.findall(r'\w+','小伍哥tm真帅',re.ASCII)#w匹配字母和数字
['tm']
在默认匹配模式下'\w+'匹配到了所有字符串,而在ASCII模式下,只匹配到了a、b、c(也就是指匹配ASCII编码支持的字符)。注意:这只对字符串匹配模式有效,对字节匹配模式无效。
3、DOTALL
语法: re.DOTALL 或简写为 re.S
作用: DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。默认模式下.是不能匹配行符\n的。
print('小伍哥\n真帅')#文本中间包含换行符,打印的时候会换行
小伍哥
真帅
re.findall(r'.*','小伍哥\n真帅')
['小伍哥', '', '真帅', '']
re.findall(r'.*','小伍哥\n真帅',re.DOTALL )
['小伍哥\n真帅', '']
在默认匹配模式下.并没有匹配换行符\n,而是将字符串分开匹配;而在re.DOTALL模式下,换行符\n与字符串一起被匹配到。
4、MULTILINE
语法: re.MULTILINE 或简写为 re.M
含义: 多行模式,当某字符串中有换行符\n,默认模式下是不支持换行符特性的,比如:行开头和行结尾,而多行模式下是支持匹配行开头的。
print('小伍哥\n真帅')#文本中间包含换行符,打印的时候会换行
小伍哥
真帅
re.findall(r'^真帅','小伍哥\n真帅')
[]
re.findall(r'^真帅','小伍哥\n真帅',re.MULTILINE)
['真帅']
正则表达式中^表示匹配行的开头,默认模式下它只能匹配字符串的开头;而在多行模式下,它还可以匹配 换行符\n后面的字符。
注意:正则语法中^匹配行开头、\A匹配字符串开头,单行模式下它两效果一致,多行模式下\A不能识别\n。
5、VERBOSE
语法: re.VERBOSE 或简写为 re.X
作用: 详细模式,可以在正则表达式中加注解!
text = '小伍哥tm帅'
pat = '''小伍哥 # 人名,本文作者
tm # 强调程度
帅 # 形容词
'''
re.findall(pat,text)
[]
re.findall(pat,text,re.VERBOSE)
['小伍哥tm帅']
可以看到,默认模式下无法识别正则表达式中的注释,而详细模式是可以识别的。当一个正则表达式十分复杂的时候,详细模式或许能为你提供另一种注释方式,但它不应该成为炫技的手段,建议谨慎使用!
6、LOCALE
语法: re.LOCALE 或简写为 re.L
作用: 由当前语言区域决定 \w, \W, \b, \B 和大小写敏感匹配,这个标记只能对byte样式有效,该标记官方已经不推荐使用,因为语言区域机制很不可靠,它一次只能处理一个 "习惯”,而且只对8位字节有效。
7、UNICODE
语法: re.UNICODE 或简写为 re.U
作用: 与 ASCII常量类似,匹配unicode编码支持的字符,但是Python3默认字符串已经是Unicode,所以显得有点多余。
8、DEBUG
语法: re.DEBUG
作用: 显示编译时的debug信息。
re.findall(r'tm','小伍哥tm真帅',re.DEBUG)
LITERAL 116
LITERAL 109
0. INFO 10 0b11 2 2 (to 11)
prefix_skip 2
prefix [0x74, 0x6d] ('tm')
overlap [0, 0]
11: LITERAL 0x74 ('t')
13. LITERAL 0x6d ('m')
15. SUCCESS
Out[97]: ['tm']
9、TEMPLATE
语法: re.TEMPLATE 或简写为 re.T
作用: disable backtracking(禁用回溯),也就是在正则匹配的过程中,匹配错误后不进行回溯处理。
re.findall(r'ab{1,3}c','abbc')
['abbc']
re.findall(r'ab{1,3}c','abbc',re.TEMPLATE)
error: internal: unsupported template operator MAX_REPEAT
我们看看正则一步一步分解匹配过程:
正则引擎先匹配 a。
正则引擎尽可能多地(贪婪)匹配 b{1,3}中的 b。
正则引擎去匹配 b,发现没 b 了,糟糕!赶紧回溯!所以第一个案例没禁止,能匹配,第二个案例有禁止,系统报错
返回 b{1,3}这一步,不能这么贪婪,少匹配个 b。
正则引擎去匹配 b。
正则引擎去匹配 c,完成匹配。
以上,就是一个简单的回溯过程,不进行回溯有可能匹配不到满足条件的匹配项
10、常量总结
1)9个常量中,前5个(IGNORECASE、ASCII、DOTALL、MULTILINE、VERBOSE)有用处,两个(LOCALE、UNICODE)官方不建议使用、两个(TEMPLATE、DEBUG)试验性功能,不能依赖。
2)常量在re常用函数中都可以使用,查看源码可得知。
3)常量可叠加使用,因为常量值都是2的幂次方,所以是可以叠加使用的,叠加时请使用 | 符号而不是+ 符号!
re.findall(r'TM','小伍哥\ntm真帅')
[]
re.findall(r'TM','小伍哥\ntm真帅',re.IGNORECASE|re.MULTILINE)
['tm']
六、函数模块
正则表达re模块共有12个函数,我将分类进行讲解,这样方便记忆与理解,先来看看概览:
search、match、fullmatch:查找一个匹配项
findall、finditer:查找多个匹配项
split: 分割
sub,subn:替换
compile函数、template函数: 将正则表达式的样式编译为一个 正则表达式对象
print(dir(re))
[...... 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall',
'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search',
'split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']
1、查找一个匹配项
查找并返回一个匹配项的函数有3个:search、match、fullmatch,他们的作用分别是:
search:查找任意位置的匹配项
match:必须从字符串开头匹配
fullmatch:整个字符串与正则完全匹配
1) search()
描述:在给定字符串中寻找第一个匹配正则表达式的子字符串,如果找到会返回一个Match对象,这个对象中的元素可以group()得到(之后将会介绍group的概念),如果没找到就会返回None。调用re.match,re.search方法或者对re.finditer结果进行遍历,输出的结果都是re.Match对象
语法:re.search(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式
re.search(r"(\w)(.\d)","as.21").group()
's.2'
假设返回的Match对象为m,m.group()来取某组的信息,group(1)返回与第一个子模式匹配的单个字符串,group(2)等等以此类推,start()方法得到对应组的开始索引,end()得到对应组的结束索引,span()以元组形式给出对应组的开始和结束位置,括号中填入组号,不填入组号时默认为0。
匹配对象m方法有很多,几个常用的方法如下:
m.start() 返回匹配到的字符串的起使字符在原始字符串的索引
m.end() 返回匹配到的字符串的结尾字符在原始字符串的索引
m.group() 返回指定组的匹配结果
m.groups() 返回所有组的匹配结果
m.span() 以元组形式给出对应组的开始和结束位置
其中的组,是指用()括号括起来的匹配到的对象,比如下列中的"(\w)(.\d)",就是两个组,第一个组匹配字母,第二个组匹配.+一个数字。
m = re.search(r"(\w)(.\d)","as.21")
m
m.group()
s.2
m.group(0)
's.2'
m.group(1) #根据要求返回特定子组
's'
m.group(2)
'.2'
m.start()
1
m.start(2)#第二个组匹配的索引位置
2
m.groups()
('s', '.21')
m.span()
(1, 5)
2) match()
描述:必须从字符串开头匹配,同样返回的是Match对象,对应的方法与search方法一致,此处不再赘述。
语法:re.match(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
#从头开始匹配,返回一个数字,发现报错,无法返回,因为不是数字开头的
text = 'chi13putao14butu520putaopi666'
pattern = r'\d+'
re.match(pattern,text).group()
AttributeError: 'NoneType' object has no attribute 'group'
#从头开始匹配,返回一个单词,正常返回了开头的单词
text = 'chi13putao14butu520putaopi666'
pattern = r'[a-z]+'
re.match(pattern,text).group()
'chi'
3) fullmatch()
描述:整个字符串与正则完全匹配,同样返回的是Match对象,对应的方法与search方法一致,此处不再赘述
语法:(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
#必须要全部符合条件才能匹配
re.fullmatch(r'[a-z]+','chiputao14').group()
AttributeError: 'NoneType' object has no attribute 'group'
re.fullmatch(r'[a-z]+','chiputao').group()
'chiputao'
2、查找多个匹配项
讲完查找一项,现在来看看查找多项吧,查找多项函数主要有:findall函数 与 finditer函数:
1)findall: 从字符串任意位置查找,返回一个列表
2)finditer:从字符串任意位置查找,返回一个迭代器
两个函数功能基本类似,只不过一个是返回列表,一个是返回迭代器。我们知道列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,运行时占用内存更小。如果存在大量的匹配项的话,建议使用finditer函数,一般情况使两个函数不会有太大的区别。
1)findall
描述:返回字符串里所有不重叠的模式串匹配,以字符串列表的形式出现。
语法:re.findall(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
import re
text = 'Python太强大,我爱学Python'
pattern = 'Python'
re.findall(pattern,text)
['Python', 'Python']
#找出下列字符串中的数字
text = 'chi13putao14butu520putaopi666'
#\d+表示匹配任意数字
pattern = r'\d+'
re.findall(pattern,text)
['13', '14', '666', '520']
text = 'ab-abc-a-cccc-d-aabbcc'
pattern = 'ab*'
re.findall(pattern,text)
['ab', 'ab', 'a', 'a', 'abb']
#找到所有副词
'''findall() 匹配样式 所有 的出现,不仅是像 search() 中的第一个匹配。比如,
如果一个作者希望找到文字中的所有副词,他可能会按照以下方法用 findall()'''
text = "He was carefully disguised but captured quickly by police."
re.findall(r"\w+ly", text)
['carefully', 'quickly']
2)finditer()
描述:返回一个产生匹配对象实体的迭代器,能产生字符串中所有RE模式串的非重叠匹配。
语法:re.finditer(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
m = re.finditer("Python","Python非常强大,我爱学习Python")
m
for i in m:
print(i.group(0))
Python
Python
#找到所有副词和位置
'''如果需要匹配样式的更多信息, finditer() 可以起到作用,它提供了
匹配对象 作为返回值,而不是字符串。继续上面的例子,
如果一个作者希望找到所有副词和它的位置,可以按照下面方法使用 finditer()'''
text = "He was carefully disguised but captured quickly by police."
for m in re.finditer(r"\w+ly", text):
print('%02d-%02d: %s' % (m.start(), m.end(), m.group(0)))
07-16: carefully
40-47: quic
3、匹配项分割
1)split()
描述:split能够按照所能匹配的字串将字符串进行切分,返回切分后的字符串列表
形式.切割功能非常强大
语法:re.split(pattern, string, maxsplit=0, flags=0)
pattern:匹配的字符串
string:需要切分的字符串
maxsplit:分隔次数,默认为0(即不限次数)
flags:标志位,用于控制正则表达式的匹配方式,flags表示模式,就是上面我们讲解的常量!支持正则及多个字符切割。
正则表达的分割函数与字符串的分割函数一样,都是split,只是前面的模块不一样,正则表达的函数为, ,用pattern分开string,maxsplit表示最多进行分割次数,
re.split(r";","var A;B;C:integer;")
['var A', 'B', 'C:integer', '']
re.split(r"[;:]","var A;B;C:integer;")
['var A', 'B', 'C', 'integer', '']
text = 'chi13putao14butu520putaopi666'
pattern = r'\d+'
re.split(pattern,text)
['chi', 'putao', 'butu', 'putaopi', '']
line = 'aac bba ccd;dde eef,fff'
#单字符切割
re.split(r';',line)
['aac bba ccd', 'dde eef,fff']
#两个字符以上切割需要放在 [ ] 中
re.split(r'[;,]',line)
['aac bba ccd', 'dde eef', 'fff']
#所有空白字符切割
re.split(r'[;,\s]',line)
['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']
#使用括号捕获分组,默认保留分割符
re.split(r'([;])',line)
['aac bba ccd', ';', 'dde eef,fff']
#不想保留分隔符,以(?:...)的形式指定
re.split(r'(?:[;])',line)
['aac bba ccd', 'dde eef,fff']
#不想保留分隔符,以(?:...)的形式指定
re.split(r'(?:[;,\s])',line)
['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']
注意:str模块也有一个split函数 ,那这两个函数该怎么选呢?str.split函数功能简单,不支持正则分割,而re.split支持正则。关于二者的速度如何?来实际测试一下,在相同数据量的情况下使用re.split函数与str.split函数执行次数 与 执行时间 对比图:
#运行时间统计 只计算了程序运行的CPU时间,且每次测试时间有所差异
import time
#统计次数
n = 1000
``start_t = time.perf_counter()
for i in range(n):
re.split(r';',line)##re.split
end_t = time.perf_counter()
print ('re.split: '+str(round(1000000*(end_t-start_t),2)))
start_t = time.perf_counter()
for i in range(n):
line.split(';')##str.split
end_t = time.perf_counter()
print ('str.split: '+str(round(1000000*(end_t-start_t),2)))
通过上图对比发现,5000次循环以内str.split函数和re.split函数执行时间差异不大,而循环次数1000次以上后str.split函数明显更快,而且次数越多差距越大!
所以结论是,在不需要正则支持的情况下使用str.split函数更合适,反之则使用re.split函数。具体执行时间与测试数据有关!且每次测试时间有所差异
4、匹配项替换
替换主要有sub函数与subn函数两个函数,他们功能类似,不同点在于sub只返回替换后的字符串,subn返回一个元组,包含替换后的字符串和替换次数。
python 里面可以用 replace 实现简单的替换字符串操作,如果要实现复杂一点的替换字符串操作,需用到正则表达式。
re.sub用于替换字符串中匹配项,返回一个替换后的字符串,subn方法与sub()相同, 但返回一个元组, 其中包含新字符串和替换次数。
sub是substitute表示替换。
1)sub
描述:它的作用是正则替换。
语法:re.sub(pattern, repl, string, count=0, flags=0)
pattern:该参数表示正则中的模式字符串;
repl:repl可以是字符串,也可以是可调用的函数对象;如果是字符串,则处理其中的反斜杠转义。如果它是可调用的函数对象,则传递match对象,并且必须返回要使用的替换字符串
string:该参数表示要被处理(查找替换)的原始字符串;
count:可选参数,表示是要替换的最大次数,而且必须是非负整数,该参数默认为0,即所有的匹配都会被替换;
flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
把字符串 aaa34bvsa56s中的数字替换为 *号
import re
re.sub('\d+','*','aaa34bvsa56s')#连续数字替换
'aaa*bvsa*s'
re.sub('\d','*','aaa34bvsa56s')#每个数字都替换一次
'aaa**bvsa**s'
#只天换一次count=1,第二次的数字没有被替换
re.sub('\d+','*','aaa34bvsa56s',count=1)
'aaa*bvsa56s'
把chi13putao14butu520putaopi666中的数字换成...
text = 'chi13putao14butu520putaopi666'
pattern = r'\d+'
re.sub(pattern,'...',text)
'chi...putao...butu...putaopi...'
关于第二个参数的用法,我们可以看看下面的内容
#定义一个函数
def refun(repl):
print(type(repl))
return('...')
re.sub('\d+',refun,'aaa34bvsa56s')
'aaa...bvsa...s'
从上面的例子看来,似乎没啥区别
原字符串中有多少项被匹配到,这个函数就会被调用几次。
至于传进来的这个match对象,我们调用它的.group()方法,就能获取到被匹配到的内容,如下所示:
def refun(repl):
print(type(repl),repl.group())
return('...')
re.sub('\d+',refun,'aaa34bvsa56s')
34
56
Out[113]: 'aaa...bvsa...s'
这个功能有什么用呢?我们设想有一个字符串moblie18123456794num123,这个字符串中有两段数字,并且长短是不一样的。第一个数字是11位的手机号。我想把字符串替换为:moblie[隐藏手机号]num***。不是手机号的数字,每一位数字逐位替换为星号。
def refun(repl):
if len(repl.group()) == 11:
return '[隐藏手机号]'
else:
return '*' * len(repl.group())
re.sub('\d+', refun, 'moblie18217052373num123')
'moblie[隐藏手机号]num***'
2)subn
描述:函数与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)。
语法:re.subn(pattern, repl, string, count=0, flags=0)
参数:同re.sub
re.subn('\d+','*','aaa34bvsa56s')#连续数字替换
('aaa*bvsa*s', 2)
re.subn('\d','*','aaa34bvsa56s')#每个数字都替换一次
('aaa**bvsa**s', 4)
text = 'chi13putao14butu520putaopi666'
pattern = r'\d+'
re.subn(pattern,'...',text)
('chi...putao...butu...putaopi...', 4)
5、编译正则对象
描述:将正则表达式的样式编译为一个正则表达式对象(正则对象),可以用于匹配
语法:re.compile(pattern, flags=0)
参数:
pattern:该参数表示正则中的模式字符串;
flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
prog = re.compile(pattern)
result = prog.match(string)
等价于
result = re.match(pattern, string)
如果需要多次使用这个正则表达式的话,使用re.compile()和保存这个正则对象以便复用,可以让程序更加高效。
6、转义函数
re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符,比如:. 或者 * re.escape(pattern) 看似非常好用省去了我们自己加转义,但是使用它很容易出现转义错误的问题,所以并不建议使用它转义,而建议大家自己手动转义!
7、缓存清除函数
re.purge()函数作用就是清除正则表达式缓存,清除后释放内存。
六、异常模块
re模块还包含了一个正则表达式的编译错误,当我们给出的正则表达式是一个无效的表达式(就是表达式本身有问题)时,就会raise一个异常。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: