Comparator 接口使用方法,结合java8新特性及源码分析
目录
- 1 Comparator介绍
-
- 1.1 函数式声明
- 1.2 简单的小案例
- 2. Comparator中的方法
-
- 2.1 compare 抽象方法
-
- 例子
- 2.2 comparing方法
-
- 源码
-
- 参考解释
- 详细解释
- 讲解
- comparing代码样例
- 例子comparing中的方法源码分析
-
- 超类型是什么意思?
- 泛型增强灵活性性例子
-
- 方法的类型参数例子
- sorted 源码分析
- 为什么compare返回负数为升序,正数为降序
-
- 默认使用归并排序
- 数组小于32使用快排
- 总结
1 Comparator介绍
建议看英文文档
官方英文文档介绍
https://docs.oracle.com/en/java/javase/20/docs/api/java.base/java/util/Comparator.html
Comparator是一个函数式接口,因此可以用作 lambda 表达式或方法引用的赋值目标。它经常用于没有天然排序的集合进行排序,如 Collections.sort 或 Arrays.sort。或者对于某些有序数据结构的排序规则进行声明,如 TreeSet 、TreeMap 。也就是该接口主要用来进行集合排序。

1.1 函数式声明
函数式声明(Functional Declaration) 是指在Java中使用函数式编程的方式声明函数或方法。函数式编程是一种编程范式,它将计算视为函数应用的方式,强调了函数的纯粹性和不可变性。在Java中,函数式编程通常使用Lambda表达式、方法引用、函数接口等特性来实现。在你提供的代码中,Lambda表达式 (c1, c2) -> keyComparator.compare(keyExtractor.apply(c1), keyExtractor.apply(c2)) 就是一个函数式声明,它表示一个比较器的定义,将对象的比较规则抽象为一个函数。
总之,comparing 方法是一个函数式编程的示例,它接受函数和比较器作为参数,然后返回一个基于提取的键值和键比较器的比较器,用于对象的排序。这种方式使得你可以轻松地基于对象的属性进行比较,而无需编写大量的比较逻辑。
1.2 简单的小案例
List<People> peoples = new ArrayList<>();
// 中间省略
// 按照年龄从小到大排序
peoples.sort(Comparator.comparing(People::getAge));
2. Comparator中的方法
Comparator 作为一个函数式接口只有一个抽象方法,但是它有很多的默认方法,我们来认识一下这些方法们。
2.1 compare 抽象方法
作为Comparator 唯一的抽象方法,int compare(T o1,T o2) 比较两个参数的大小, 返回负整数,零,正整数 ,分别代表 o1
// 输入两个同类型的对象 ,输出一个比较结果的int数字
(x1,x2)-> int
例子
自己动动手
public class SortedDemo {
public static void main(String[] args) {
List<String> words = Arrays.asList("watermelon","apple", "banana", "cherry");
// 使用比较器按字符串长度升序排序
words.sort((str2, str1) -> Integer.compare(str1.length(), str2.length()));
// words.sort((str2, str1) -> Integer.compare(str1.length(), str2.length()));//降序
System.out.println(words); // 输出: [apple, banana, cherry]
}
}
2.2 comparing方法
从 Java 8 开始,Comparator 提供了一系列的静态方法,并通过函数式的风格赋予 Comparator 更加强大和方便的功能,我们暂且称它们为 comparing系列方法。
重点介绍一下
comparing方法,以及它的源码实现。注意comparing方法有很多个不同的重载方法,这个是传入参数最全的方法介绍。
源码
public static <T, U> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator<T> & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
参考解释
该方法是该系列方法的基本方法。是不是看上去很难懂的样子?我们来分析一下该方法。它一共两个参数都是函数式接口。
第一个参数 Function keyExtractor 表示输入一个是 T 类型对象,输出一个 U 类型的对象,举个例子,输入一个 People 对象返回其年龄 Integer 数值:
// people -> people.getAge(); 转换为下面方法引用
Function<People, Integer> getAge = People::getAge;
第二个参数 keyComparator就很好理解了,表示使用的比较规则。
对 c1,c2 按照 第一个参数 keyExtractor 提供的规则进行提取特征,然后第二个参数keyComparator对这两个特征进行比较。下面的式子其实可以概括为 3.1 的 (x1,x2)-> int
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2))
Comparator & Serializable 为 Java 8 新特性:同时满足这两个类型约束
理解了这个方法后,其它该系列的方法就好理解了,这里不再赘述。目前 comparing 系列方法使用更加广泛。我们举一些例子:
List<People> peoples = new ArrayList<>();
// ………………
// 按照年龄从低到高排序
peoples.sort(Comparator.comparing(People::getAge));
// 按照年龄从高到低排序
peoples.sort(Comparator.comparing(People::getAge, (x, y) -> -x.compareTo(y)));
同样你可以使用 java.util.Collections 或者 Stream 提供的排序方法来使用Comparator。
详细解释
这段源码是Java标准库中的一个方法,位于java.util.Comparator类中,它是一个静态方法,用于创建一个比较器(Comparator),该比较器基于给定的函数(Function)和键比较器(Comparator)来比较对象。
现在让我逐步解释这段源码:
-
T和U,用于表示要比较的元素类型和提取关键值的类型。 -
comparing方法接受两个参数:keyExtractor参数是一个函数,它接受类型为T的对象,并返回类型为U的键值。这个函数用于从对象中提取比较的关键值。keyComparator参数是一个比较器,它用于比较类型为U的键值。
-
Objects.requireNonNull(keyExtractor)和Objects.requireNonNull(keyComparator):这两行代码用于检查传入的keyExtractor和keyComparator参数是否为null,如果是null,则抛出NullPointerException。 -
返回值:该方法的返回值是一个比较器(
Comparator)。这个比较器基于传入的keyExtractor函数和keyComparator比较器来进行对象比较。(Comparator<T> & Serializable) (c1, c2) -> keyComparator.compare(keyExtractor.apply(c1), keyExtractor.apply(c2))(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1), keyExtractor.apply(c2)):这是一个Lambda表达式,表示一个比较器的具体实现。它接受两个对象c1和c2,首先使用keyExtractor函数从这两个对象中提取键值,然后使用keyComparator比较这两个键值,返回比较结果。这就实现了一个基于键值的对象比较器。(Comparator:这是一个类型转换,将Lambda表达式转换为& Serializable) Comparator类型,并且标记为Serializable,以便可以序列化该比较器。
这个方法的主要目的是创建一个比较器,该比较器可以基于提取的键值和键比较器来对对象进行排序。这种方式使得排序可以更加灵活,可以根据对象的某个属性进行比较,而不是直接比较对象本身。
讲解
通配符(wildcard)
-
? super T表示通配符的下界(Lower Bounded Wildcard),它的意思是可以接受类型为T或T的超类型的对象。这允许传递比T更一般的对象类型作为参数。例如,如果T是Number,那么? super T可以接受Number、Object或其他Number的超类型作为参数。 -
? extends U表示通配符的上界(Upper Bounded Wildcard),它的意思是可以接受类型为U或U的子类型的对象。这允许传递比U更具体的对象类型作为参数。例如,如果U是Integer,那么? extends U可以接受Integer、Number或其他Integer的子类型作为参数。
在 comparing 方法的源码中,keyExtractor 和 keyComparator 的类型使用了通配符的形式,是为了增加方法的灵活性。它们的类型参数分别为 ,其中 T 表示比较器的元素类型,U 表示要比较的键值类型。使用通配符可以让 comparing 方法接受更广泛的类型参数,从而更灵活地适应不同的使用情况。
comparing代码样例
comparing
package com.qfedu.Comparator;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
/**
* public static Comparator comparing(
* Function keyExtractor,
* Comparator keyComparator)
* {
* Objects.requireNonNull(keyExtractor);
* Objects.requireNonNull(keyComparator);
* return (Comparator & Serializable)
* (c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
* keyExtractor.apply(c2));
* }
*/
public class ComparatorDemo {
public static void main(String[] args) {
// 创建一个包含Person对象的列表
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
// 使用comparing方法按年龄升序排序Person对象
Comparator<Person> ageComparator = Comparator.comparing(
person -> person.getAge() // 提取比较的键值:年龄
);
// 对列表进行排序
List<Person> sortedPeople = people.stream()
.sorted(ageComparator)
.collect(Collectors.toList());
// 输出排序后的结果
sortedPeople.forEach(person -> System.out.println(person.getName() + ": " + person.getAge()));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
注释解释:
-
我们创建了一个
Person类,表示一个人,包括姓名和年龄属性。 -
在
main方法中,我们创建了一个包含Person对象的列表people。 -
使用
Comparator.comparing方法创建了一个比较器ageComparator,该比较器按照Person对象的年龄进行比较。这里的person -> person.getAge()是一个键提取函数,用于提取年龄作为比较的键值。 -
我们使用
sorted方法将people列表按照ageComparator进行排序,得到排序后的列表sortedPeople。 -
最后,我们遍历
sortedPeople列表,并输出排序后的结果,按照年龄升序排列。
这个示例演示了如何使用 comparing 方法创建一个比较器,以及如何基于键值对对象进行排序。通配符 使得 comparing 方法可以适应不同类型的对象和键值。在本例中,键值是年龄,对象是 Person。
例子comparing中的方法源码分析
例子中的comparing方法只有传入一个函数参数Function,方法的声明
- 方法或类接受两个泛型类型参数
T和U。 U必须是一个实现了Comparable接口的类型,但可以是Comparable接口的任何超类型。
// 使用comparing方法按年龄升序排序Person对象
Comparator<Person> ageComparator = Comparator.comparing(
person -> person.getAge() // 提取比较的键值:年龄
);
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
> 讲解
这个代码片段 T 和 U,并对泛型类型 U 进行了限定。
让我逐步解释这个代码片段的含义:
-
T和U,它们是在方法或类中使用的类型占位符。T通常表示某种对象的类型,而U表示另一种类型,用于在比较中作为键值。 -
U extends Comparable:这部分对泛型类型U进行了限定。它表示U必须是一个实现了Comparable接口的类型。Comparable接口是Java中用于比较对象的接口,它定义了compareTo方法,允许对象自定义比较逻辑。Comparable表示U必须直接实现Comparable接口,但我们使用来更加灵活地定义U。表示U可以是Comparable接口的任何超类型。这允许我们比较对象U的时候,也可以比较它的子类或父类对象。
综合起来,
- 方法或类接受两个泛型类型参数
T和U。 U必须是一个实现了Comparable接口的类型,但可以是Comparable接口的任何超类型。
这种声明的目的是使得方法或类更加通用和灵活,可以适应不同类型的对象,并且可以进行比较操作,而不仅限于特定的类型。这在编写通用的排序或比较逻辑时非常有用。
超类型是什么意思?
在Java中,一个类或接口可以实现另一个类或接口,而被实现的类或接口称为超类型(super type)。超类型是一个广义的概念,用于表示一个类或接口是另一个类或接口的父类或父接口。
当我们说 “U 可以是 Comparable 接口的任何超类型” 时,意思是泛型类型参数 U 可以是实现了 Comparable 接口的类或接口,而不仅仅限于直接实现 Comparable 接口的类。
这是非常有用的,因为它使得方法更加灵活,允许接受不仅仅是实现 Comparable 接口的类的对象,还可以接受那些实现了 Comparable 接口的类的子类的对象。这是因为子类也可以被视为超类型的一种,因为它们继承了超类型的行为。
举个例子,假设有一个 Fruit 类实现了 Comparable 接口,然后有一个 Apple 类,它是 Fruit 的子类。如果我们有一个方法要接受一个实现了 Comparable 接口的对象,那么这个方法的声明可以这样写:
public <U extends Comparable<? super U>> void someMethod(U obj) {
// 方法体
}
在这个方法中,U 表示可以是 Comparable 接口的任何超类型,因此可以接受 Fruit 或 Apple 对象作为参数,因为它们都实现了 Comparable 接口。这样,方法变得更加通用,可以接受不同类型的对象,只要它们实现了 Comparable 接口或其超类型。
泛型增强灵活性性例子
我不太能感受到它的通用和灵活,能用一个代码例子说明吗,最好有对比
当我们定义泛型方法或类时,我们希望它们能够处理各种类型的数据,而不仅仅是特定类型。通过使用 extends Comparable 这样的泛型类型参数限定,我们可以实现通用的比较方法,使其可以适用于不同类型的对象。
下面,我将为你提供一个例子,演示如何使用泛型和 Comparable 来创建通用的比较方法。首先,我们将创建一个普通的比较方法,然后通过泛型和 extends Comparable 来改进它,使其更加通用。
示例 1:普通的比较方法
public static int compareIntegers(int a, int b) {
if (a < b) {
return -1;
} else if (a > b) {
return 1;
} else {
return 0;
}
}
public static void main(String[] args) {
int result = compareIntegers(5, 3);
System.out.println(result); // 输出 1
}
在这个示例中,compareIntegers 方法只能比较整数类型,并且返回整数类型的结果。
示例 2:使用泛型和 Comparable 的通用比较方法
public static <T extends Comparable<? super T>> int compareObjects(T a, T b) {
return a.compareTo(b);
}
public static void main(String[] args) {
int result1 = compareObjects(5, 3); // 使用整数比较
System.out.println(result1); // 输出 1
String str1 = "apple";
String str2 = "banana";
int result2 = compareObjects(str1, str2); // 使用字符串比较
System.out.println(result2); // 输出 -1
}
在示例 2 中,我们定义了一个泛型方法 compareObjects,它接受两个泛型参数 T,这两个参数必须是实现了 Comparable 接口的类型,而且我们使用 extends Comparable 来表明泛型类型 T 或其超类型必须实现 Comparable 接口。
这使得 compareObjects 方法能够比较不同类型的对象,而不仅仅是整数。我们可以使用它来比较整数和字符串,它会根据对象的 compareTo 方法来进行比较,产生通用的比较结果。
通过泛型和 Comparable,我们实现了一个通用的比较方法,可以用于比较不同类型的对象,这增加了方法的通用性和灵活性。这是泛型和类型参数限定的一个强大之处。
方法的类型参数例子
类型参数声明用于指定在方法或类中使用的泛型类型参数,以使方法或类更通用,可以适应不同类型的数据。以下是一些示例,演示了方法的类型参数声明:
-
简单的泛型方法
public <T> T findMax(T[] arr) { T max = arr[0]; for (T element : arr) { if (element.compareTo(max) > 0) { max = element; } } return max; }在这个示例中,
T[],并返回数组中的最大元素。T是类型参数,可以是任何引用类型,例如整数、字符串、自定义对象等。 -
使用多个类型参数
public <T, U> boolean areEqual(T obj1, U obj2) { return obj1.equals(obj2); }这个示例中有两个类型参数
T的对象obj1,另一个是类型为U的对象obj2。该方法比较这两个对象是否相等。 -
泛型类的类型参数
public class Box<T> { private T value; public Box(T value) { this.value = value; } public T getValue() { return value; } }这是一个泛型类
Box的例子。T是类型参数,用于表示盒子中存储的值的类型。这个类可以用于存储不同类型的值。 -
泛型接口的类型参数
public interface List<T> { void add(T item); T get(int index); }这是一个泛型接口
List的示例,表示一个通用的列表接口。T是类型参数,表示列表中元素的类型。具体的列表实现可以指定T的具体类型。
这些示例展示了如何在方法和类中使用类型参数声明,以实现通用性和灵活性,以适应不同类型的数据。类型参数允许我们编写通用的代码,而不必在每次使用不同类型时都编写不同的方法或类。
sorted 源码分析
Stream<T> sorted(Comparator<? super T> comparator);
sorted 方法将使用传入的比较器来对 Stream 中的元素进行排序,然后生成一个新的 Stream,其中包含了按照比较器定义的顺序排列的元素。这个方法通常用于对集合中的元素进行排序操作
// 使用comparing方法按年龄升序排序Person对象
Comparator<Person> ageComparator = Comparator.comparing(
person -> person.getAge() // 提取比较的键值:年龄
);
//sort(Comparator.comparing(People::getAge)); 也可以这么写
// 对列表进行排序
List<Person> sortedPeople = people.stream()
.sorted(ageComparator)
.collect(Collectors.toList());
为什么compare返回负数为升序,正数为降序
在比较器中将两个类型的值进行compare计算后,会调用归并排序方法,上面的例子中将Integer转换为int后比较大小return (x < y) ? -1 : ((x == y) ? 0 : 1),然后调用归并排序算法,进行比较。

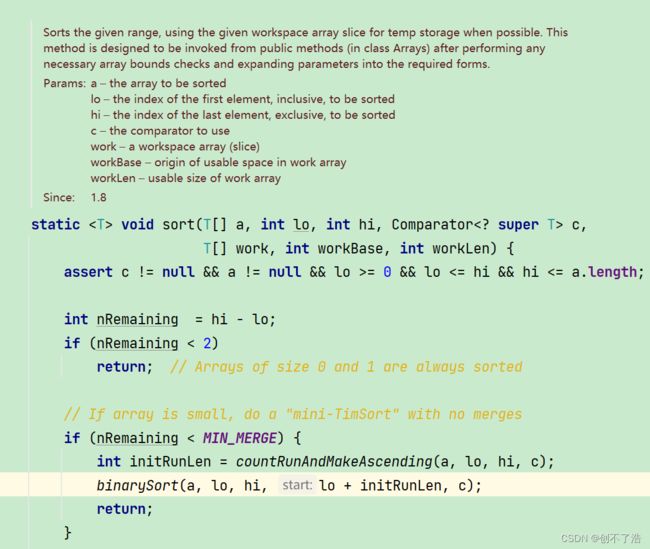
默认使用归并排序
这个归并排序的核心算法。
函数参数解释
该方法返回从指定位置开始的运行的长度,并且如果它是降序的话会将其反转(确保在方法返回时运行始终是升序的)。一个运行是具有以下特点的最长升序序列:
a[lo] <= a[lo + 1] <= a[lo + 2] <= ...或者具有以下特点的最长降序序列:a[lo] > a[lo + 1] >a[lo + 2] > ...对于它在稳定的合并排序中的预期用途,“降序”
的定义的严格性是必要的,以便调用可以安全地反转一个降序序列而不会破坏稳定性。
参数:
- a - 要计算并可能反转运行的数组
- lo - 运行中第一个元素的索引
- hi - 可能包含在运行中的最后一个元素之后的索引。要求 lo < hi。
- c - 用于排序的比较器
返回:
- 指定数组中指定位置开始的运行的长度。

详细的解释一下compare返回负数为升序,正数为降序,结合上面的归并排序算法。
在排序算法中,比较函数(例如 compare 方法)的返回值被用来确定两个元素的相对顺序,从而决定它们在排序结果中的位置。通常,比较函数的返回值规则如下:
- 如果返回负数,表示第一个元素应该在第二个元素之前,即升序排序。
- 如果返回零,表示两个元素相等,它们的相对顺序在排序中不变。
- 如果返回正数,表示第一个元素应该在第二个元素之后,即降序排序。
让我们结合归并排序算法的一部分来详细解释这个规则。归并排序是一种分治算法,它将待排序的数组分成多个子数组,然后将这些子数组合并为一个有序的结果数组。在合并的过程中,比较函数被用来确定两个子数组的合并顺序。
具体来说,考虑以下情况:
if (c.compare(a[runHi++], a[lo]) < 0) {
// Descending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else {
// Ascending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
这段代码用于确定一段子数组的排序顺序(升序或降序),并在需要时对子数组进行反转。
if(c.compare(a[runHi++], a[lo])<0) 用于比较当前元素runHi和前一个元素的大小。如果返回负数,表示当前元素小于前一个元素,这表示目前是降序排序,需要进行逆转操作。
反之,算法会继续向后比较,找到所有升序排列的元素,并将它们保持在原来的顺序。如果是降序排序,会有相应的逻辑处理来反转这段降序排列的元素。
这样,归并排序算法利用比较函数的返回值来确定子数组的排序顺序,并相应地调整子数组中元素的顺序,确保最终得到一个完整的升序排序结果。
总结:比较函数的返回值在排序算法中被用来控制元素的相对顺序,规定了负数为升序、正数为降序。这一规则确保排序算法可以根据指定的排序顺序正确地排列元素。
数组小于32使用快排
此时传入的数组a已经完成了0和1的排序
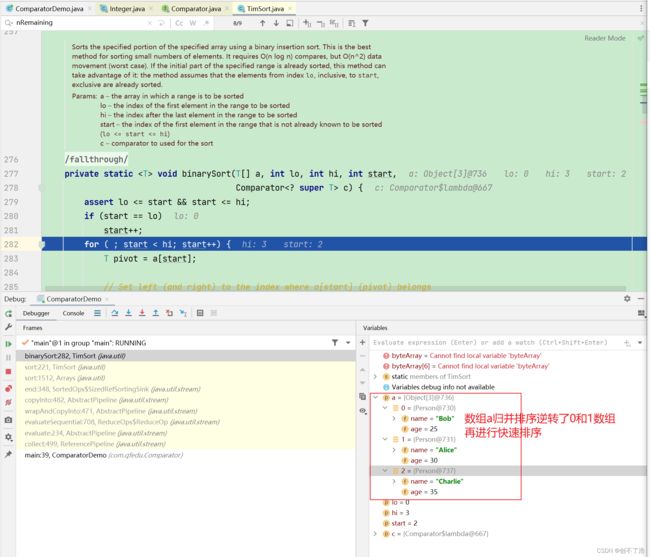
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
private static final int MIN_MERGE = 32;
总结
自定义对Person结构按照age排序的方式,调用了Comparator接口,分析了compare传入两个数,为什么返回负数为升序,正数为降序。了解了底层归并排序和快速排序的如何调用compare方法。