Linux文件及磁盘管理系统
安装流程
- 一、总结Linux安全模型
- 二、总结学过的权限,属性及ACL相关命令及选项
- 三、结合vim几种模式,学会使用vim几个常用操作
- 四、总结学过的文本处理工具,文本查找工具,文本处理三剑客,文本格式化命令(printf)的相关命令及选项,示例
- 五、总结文本处理的grep命令相关的基本正则和扩展正则表达式
- 六、总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用
- 七、通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,总共有几只鸡,几只兔
- 八、结合编程的for循环,条件测试,条件组合,完成批量创建100个用户
- 九、磁盘存储术语总结:head,track,sector,sylinder
- 十、总结学过的分区,文件系统管理,SWAP管理的相关命令及选项,实例:fdisk,parted,mkfs,tune2fs,xfs_info,fsck,mount,unmount,swapon,swappoff
- 十一、总结MBR,GPT结构
- 十二、总结raid0,1,5,10,01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现
- 十三、完成不影响业务下对LVM磁盘扩容以及缩容实例
提示:以下是本篇文章正文内容,下面案例可供参考
一、总结Linux安全模型
Linux安全模式:
1、用户使用账号和口令登录Linux。
2、 Linux中每个用户是通过UID来唯一标识。
3、 Linux中一个或多个用户加入用户组中,用户组是通过GID来唯一标识的。
4、 Linux使用user和group来控制使用者对文件的权限。
5、 Linux中运行的程序,进程,以发起者身份运行,访问的资源权限取决于进程运行者的身份。
二、总结学过的权限,属性及ACL相关命令及选项
1、一般权限
使用命令 ll 查看,可以看到权限,用户,用户组,文件大小,创建日期,时间和文件名:

权限中第一位标记了文件的类型,其后每三位,分别代表了用户,用户组和other的权限

其中读权限 r,对应数值是4;写权限w,对应数值是2;执行权限x,对应数值是1。
使用chmod命令来修改文件的权限:

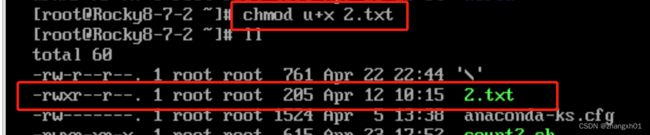
2、特殊权限
SUID:作用于二进制可执行程序文件上,用户执行该文件时继承该文件所有者的权限。它的常用命令如下:
chmod u+s 文件
chmod u-s 文件
chmod 4755 文件


SGID:作用于二进制可执行程序文件上,用户执行该文件时继承该文件所有用户组的权。它的常用命令如下:
chmod g+s 文件
chmod g-s 文件
chmod 2755 文件


SGID在作用于目录上时,此目录中新建的文件的所属组将自动从此目录继承(新建文件自动继承所属目录所属的组)
chmod g+s 目录
chmod g-s 目录
chmod 2755 目录

STICKY:粘滞位,作用于目录上,此目录中的文件只能由所有者来进行删除(root例外)。它的常用命令如下:
chmod o+t 目录
chmod o-t 目录
chmod 1755 目录
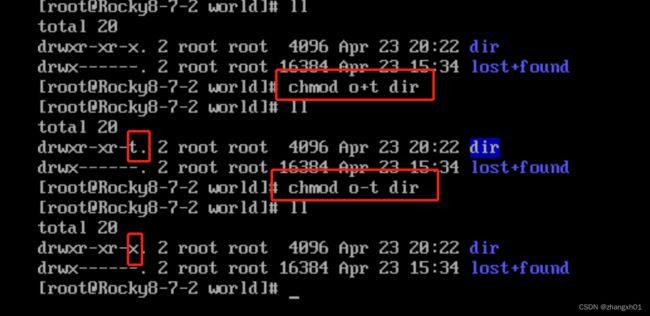
3、ACL权限
除了这2类权限以外,还有一种控制文件访问权限的权限ACL。它的常用命令如下:
getfacl 文件
setfacl -m u:用户名:权限(0|rw) 文件
setfacl -m g:用户组:权限 文件
setfacl -m o:权限 文件

4、还有文件/目录自身的权限控制attr,它的命令如下:
chattr +i 文件/目录 锁定文件
chattr -i 文件/目录 解锁文件

chattr +a 文件/目录 只开启文件追加,其他锁定
chattr -a 文件/目录 删除锁定
lsattr 文件/目录

三、结合vim几种模式,学会使用vim几个常用操作
1)命令行输入:vim vim.txt 即可进入vim界面,处于命令模式下:


在命令模式下输入:q/:wq/:q!即可退出vim界面。

2) 重新输入vim vim.txt进入命令模式界面,输入(i/I/o/O/a/A)即可进入插入模式。
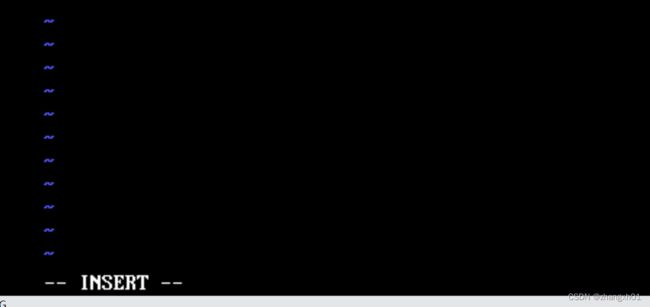
点击键盘的esc键即可退出插入模式,回到命令模式。
在命令模式下输入:q/:wq/:q!即可退出vim界面
3) 重新输入vim vim.txt进入命令模式界面,输入(i/I/o/O/a/A)即可进入插入模式。
输入内容。
点击esc键,回到命令模式
在命令模式下输入:wq写入文件然后退出vim界面

4)使用cat验证输入是否成功

5)命令模式下,光标在单词,句子上进行前后,上下跳转。行复制粘贴。行删除。
可以按:
h 光标左移一格
l 光标右移一格
j 光标下移一行
k 光标上移一行
w 光标移动到下一个单词头部
b 光标移动到上一个单词头部
e 光标移动到下一个单词尾部
gg 光标移动到文件第一行开始
G 光标移动到文件最后一行开始
y 复制选中的内容
p 粘贴复制内容
d 删除选中的内功
yy 复制光标所在行
dd 删除光标所在行

四、总结学过的文本处理工具,文本查找工具,文本处理三剑客,文本格式化命令(printf)的相关命令及选项,示例
1、文本处理工具
1)cat:获取文件内容

获取多个文件的内容,并纵向合并 
tac:自下向上获取文件内容

rev:自右向左获取文件内容
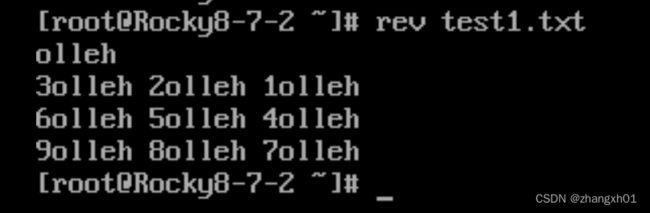
paste:获取多个文件的内容,并横向合并

2)head:从文档头部开始读取

tail:从文件尾部开始读取

3)cut:按照分隔符对内容进行切割

4)wc:统计数量
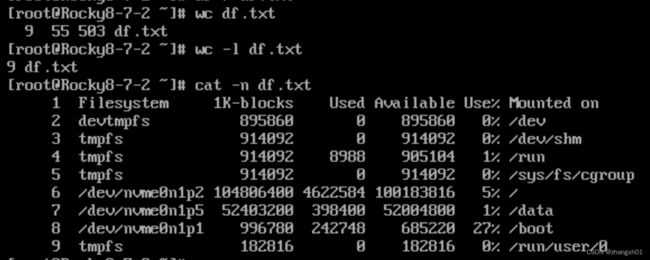
5)sort :排序


6)uniq:获取或统计文件中重复/不重复的内容/重复个数
-d 显示重复的内容
-u 去除相邻重复的内容
-c 统计各行内容重复的次数

2、文本查找工具
1)非实时查找工具locate
2)实时查找工具find
find -depth 先处理文件在处理文件夹

支持通配符查找

3、文本处理三剑客
1)grep 文本内容过滤 。grep命令通常逐行处理并打印/统计结果的。
常用参数:
-b 在搜索到的行的前面打印该行所在的块号码。
-c 只显示有多少行匹配 ,而不具体显示匹配的行
-h 不显示文件名
-i 在与字符串比较的时候忽略大小写
-l 只显示包含匹配模板的行的文件名清单,不同项目之间用换行符分隔
-L 打印不匹配模板的文件名清单
-n 在每一行前面打印该行在文件中的行数
-s 静默工作,除非出现错误信息否则不打印任何信息,该功能在检测退出状态的时候有用
-v 反检索,只显示不匹配的行
查找文件中包含Filesystem的行:
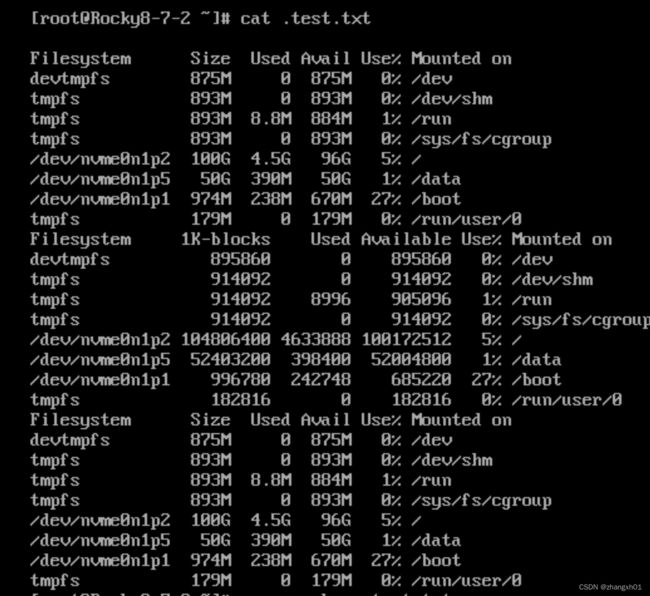

统计文件中tmpfs出现的次数

2)sed 实现批量文本编辑。sed在
r: 追加文本。
w: 保存模式匹配的行到指定文件。
-n:禁止sed编辑器输出,但可以与p命令一起使用完成输出。
-i: 直接修改目标文本文件。
取出特定行

命令修改目标文件内容


3)awk用于报告生成,格式化输出,在处理文本的时候逐行读取读入信息,并将一行分成多个"字段"然后再进行处理。执行结果可以通过print的功能将字段数据打印显示。
在使用awk命令的过程中,可以使用逻辑操作符"&&"表示"与"、"||"表示"或"、"!"表示"非";还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
用法:
awk [POSIX or GNU style options] -f progfile [--] file ...
awk [POSIX or GNU style options] [--] 'program' file ...
常见选项
-F"分隔符"指明输入时用到的字段分割符,默认为若干个连续空白符
-v var=value 变量赋值
可以实现运算:

在使用df命令读取其中的列:

使用连续分隔符,获取需要的数据:

4、格式化输出printf
printf命令主要作用是输出文本,按照用户指定的格式格式化文本并输出文本。命令echo在输出文本时,会自动换行。printf命令不会对输出文本进行换行,换行时需要使用 \n 。
命令格式:
printf [-v var] format [arguments]
格式替代符
%s 字符串
%f 浮点型
%b 相对应参数中包含转义字符时,可以使用此替换符进行替换,对应的转义字符被转义。
%c ASCII字符,显示想对应参数的第一个字符。
%d, %i 十进制整数
%o 不带正负号的八进制值
%u 不带正负号的十进制值
%x 不带正负号的十六进制值,使用a至f表示10到15
%X 不带正负号的十六进制值,使用A至F表示10到15
%% 表示 % 本身
![]()
五、总结文本处理的grep命令相关的基本正则和扩展正则表达式
grep命令是文本搜索工具,它可以根据用户指定的"模式(过滤条件)"对目标文本逐行进行匹配检查,打印匹配到的行内容。
1)grep模式与选项:由正则表达式的元字符及文本字符所编写出的过滤条件。
-i: 忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v: 显示不能被模式匹配到额行;
-E: 扩展的正则表达式元字符;
-q:–quiet,–slient:安静模式
-A#:after:匹配本行及后#行
-B#:before:匹配本行和前#行
-C#:context,本行和前后各#行
2)基本正则表达式元字符:
a、字符匹配:
.:匹配任意单个字符
grep "r..t" /etc/passwd
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
[:digit:]、[:lower:]、[:upper:]、[:alpha:]、[:alnum:]、[:punct:]、[:space:]
b、匹配次数:用在要指定其出现的次数的字符的后面,用于限制其前面的字符出现的次数
*:匹配其前面的字符人一次;0,1,多次
.*:匹配任意长度的任意字符
\?:匹配其前面的字符0次或1次;即前面的字符是可有可无的;
\+:匹配其前面的字符1次或多次;即前面的字符要出现至少1次;
\{m\}:匹配前面的字符m次
\{m,n\}:匹配其前面的字符至少m次,至多n次;
\{0,n\}:至多n次
\{m,\}:至少m次
注意使用的时候,某些场合需要"\"转义?,+,{,}等特殊字符
c、位置锚定:
^:行首锚定,用于模式的最左侧
$:行尾锚定;用于模式的最右侧
^PATTERN$:用于PATTERN来匹配整行
^$:空白行;
^[[:space:]]*$:空行或包含空白字符的行;
单词:非特殊字符组成的连续字符串(字符串)都称为单词;
\<或\b:词首锚定,用于单词模式的左侧
3)扩展正则表达式:
egrep:同;grep -E
egrep [options] pattern [file..]
选项:
-i,-o,-q,-A,-B,-C
-G:支持基本正则表达式
扩展正则表达式的元字符:
字符匹配:
.:任意单个字符
[]:指定范围内的任意单个字符
[^]:指定范围外的任意单个字符
次数匹配:
*:任意次,0,1或多次;
?:0次或1次,其前的字符是可有可无的;
+:其前字符至少1次
{m}:其前的字符m次
{m.n}:至少m次,至多n次;
{0,n}
{m,}
位置锚定:
^:行首锚定;
$:行尾锚定;
\<,\b:词尾锚定;
>\,\b:词尾锚定
分组及引用:
():分组;括号内的模式匹配的字符会被记录于正则表达式引擎的内部变量中
后向引用:\1,\2,…
或
a|b:a或者b
C|cat:C或cat
(c|C)at:cat或Cat
六、总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用
shell编程中变量的命名只能使用字母数字下划线,不能使用-横线。在命名变量的时候,需要遵循大小驼峰的格式。
在shell编程中存在一下5种变量类型,分别是:
1)环境变量,
export/declare -x 环境变量

printenv 环境变量

env
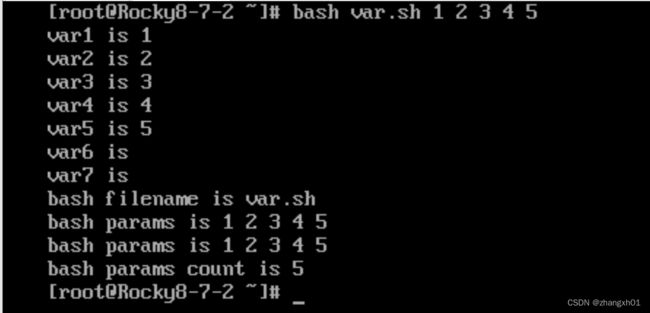
2)位置变量,
$1....$n 位置变量 格式${n}
$0 脚本名
$* 所有参数,所有参数作为整体
$@ 所有参数,每个参数独立
$# 参量个数

3)只读变量(常量)
readonly/declare -r 常量

4)局部变量,
用户自定义的变量就是局部变量。在定义好变量后,如果需要访问变量,需要在变量名前加一个$。如图:

5)状态变量
$? 保存最近一个命令的结果是正确还是错误。如果值大于0,就说明失败或者错误了;如果值等于0,说明成功。


七、通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,总共有几只鸡,几只兔


#!/bin/bash
set -e
read -p "Please enter legs,heads:" legs heads
[[ "$legs" =~ ^([0-9]+)$ ]] || { echo $legs "is not a number,please insert a number";exit; }
[[ "$heads" =~ ^([0-9]+)$ ]] || { echo $heads "is not a number,please insert a number";exit;}
rabbit=0
rabbit=0
chicken=$heads
leg=0
if [ $legs -lt $heads ]
then
echo "data error";exit;
fi
while [ $leg -ne $legs ]
do
leg=$((chicken*2+rabbit*4))
if [ $leg -eq $legs ]
then
break
fi
let rabbit+=1
chicken=$(($heads-$rabbit))
done
[ $(( $chickens + $rabbit )) -ne $heads ] || { echo "data is wrong";exit; }
echo "rabbit num is" $rabbit
echo "chicken num is" $chicken
八、结合编程的for循环,条件测试,条件组合,完成批量创建100个用户

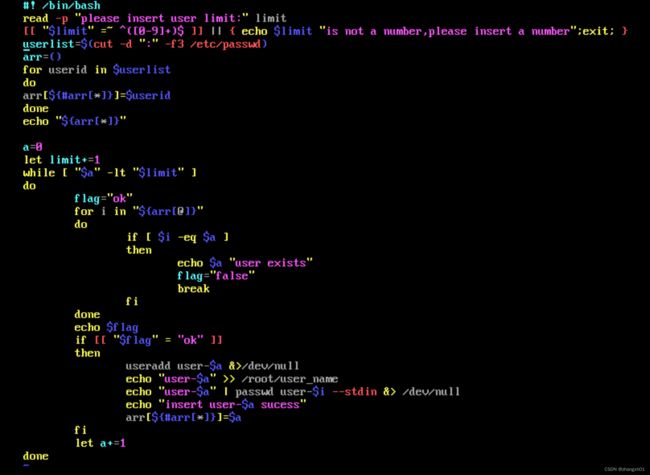
#! /bin/bash
read -p "please insert user limit:" limit
[[ "$limit" =~ ^([0-9]+)$ ]] || { echo $limit "is not a number,please insert a number";exit; }
userlist=$(cut -d ":" -f3 /etc/passwd)
arr=()
for userid in $userlist
do
arr[${#arr[*]}]=$userid
done
echo "${arr[*]}"
a=0
let limit+=1
while [ "$a" -lt "$limit" ]
do
flag="ok"
for i in "${arr[@]}"
do
if [ $i -eq $a ]
then
echo $a "user exists"
flag="false"
break
fi
done
echo $flag
if [[ "$flag" = "ok" ]]
then
useradd user-$a &>/dev/null
echo "user-$a" >> /root/user_name
echo "user-$a" | passwd user-$i --stdin &> /dev/null
echo "insert user-$a sucess"
arr[${#arr[*]}]=$a
fi
let a+=1
done
九、磁盘存储术语总结:head,track,sector,sylinder
head:磁头。机械硬盘中的机械结构,每个盘有两个面,每个盘面上有一个读写磁头,盘面号即磁头号。所有磁头在磁头臂作用下同时内外移动。所以所有磁头所处的磁道号是相同的。
track:磁道。机械硬盘中每个盘面被划分成许多同心圆,这些同心圆轨迹叫做磁道;磁道从外向内从0开始顺序编号。
cylinder:柱面。所有盘面上的同一磁道构成一个圆柱,称作柱面。数据的读/写按柱面从外向内进行,而不是按盘面进行。定位时,首先确定柱面,再确定盘面,然后确定扇区。之后所有磁头一起定位到指定柱面,再旋转盘面使指定扇区位于磁头之下。
sector:扇面。将一个盘面划分为若干内角相同的扇形,这样盘面上的每个磁道就被分为若干段圆弧,每段圆弧叫做一个扇区。每个扇区中的数据作为一个单元同时读出或写入。硬盘的第一个扇区,叫做引导扇区。
十、总结学过的分区,文件系统管理,SWAP管理的相关命令及选项,实例:fdisk,parted,mkfs,tune2fs,xfs_info,fsck,mount,unmount,swapon,swappoff
1)查看分区
lsblk
echo '- - -' > /sys/class/scsi_host/host32/scan

2) 创建磁盘分区
a、parted
交互式分区:


非交互式分区:

b、fdisk
开始分区
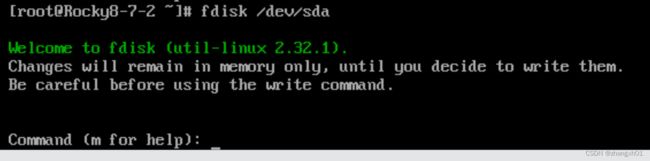

打印分区

保存划分分区

删除分区


3)创建文件系统:mkfs
mkfs.ext4
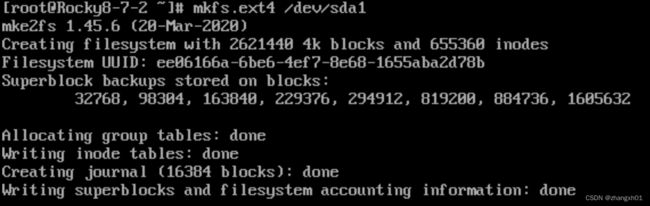
mkfs.xfs

4)查看文件系统
ext4:tune2fs -l /dev/sda1


xfs:xfs_infop /dev/sda2

5)查看分区块信息
dumpe2fs:dumpe2fs /dev/sda1

6)查看分区id
blkid

7)分区检查工具
fsck:fsck.ext4 /dev/sda1

xfs_repair:xfs_repair -n /dev/sda2

8)挂载分区
a、临时挂载
mount:mount 分区 挂载点
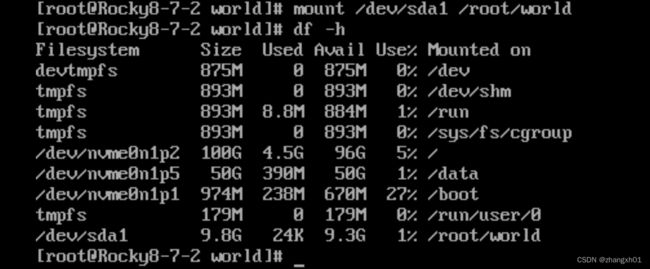
b、永久挂载
vim /etc/fstab




9)取消挂载分区
a、对临时挂载的处理
umount:umount 挂载点
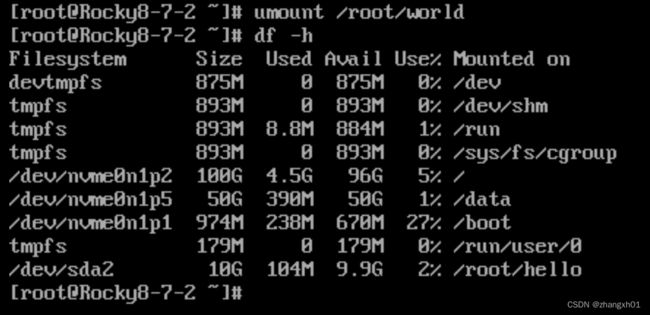
b、对永久挂载的处理
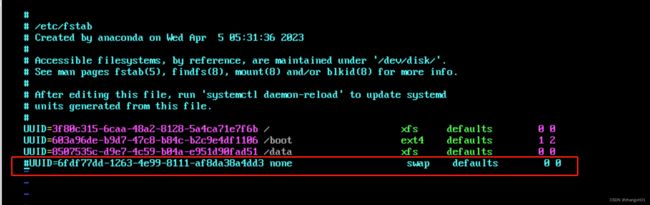
删除/etc/fstab中的挂载配置
umount 挂载点
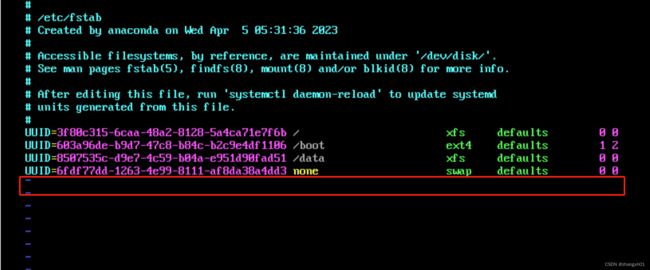

10)swapon
查看swap的使用情况:
swapon -s
开启swapon:
swapon -a

11)swapoff
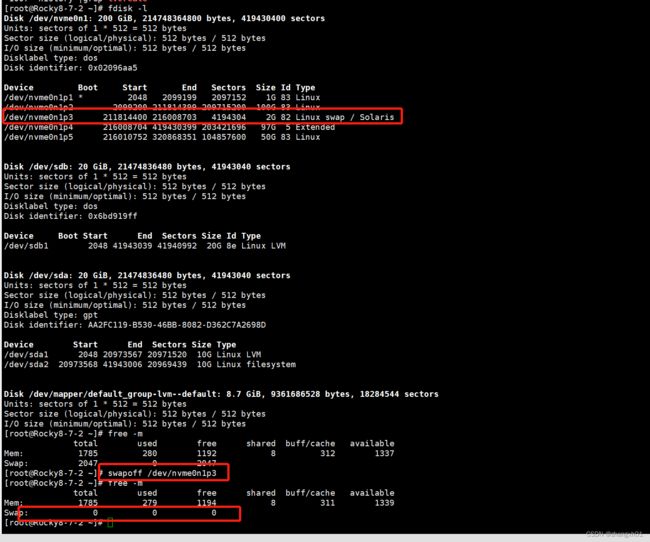
停止swap挂载:
poff 挂载点

永久停止swap挂载:
修改/etc/fstab ,删除或注销里面的swap项

十一、总结MBR,GPT结构
MBR是master boot record的缩写,是比较老的分区模式。在传统硬盘的分区模式中,引导扇区是每个分区的第一个扇区,而主引导扇区是硬盘的第一个扇区。在MBR中,分区表大小是固定的,一共可容纳4个主分区或者3个主分区+1个扩展分区,而MBR分区表中逻辑块地址采用32位二进制,一共只有2^32个逻辑块地址。如果一个扇区大小是512字节,则MBR最大分区容量只支持2TB,大于2TB的容量无法识别导致了浪费。
GPT是global unique indentifiers的缩写,是比较新的分区模式。与MBR 不同,在GPT的分区表头中可以自定义分区数量的最大值(windows中,微软设置个GPT最大分区数量是128个)。而且GPT分区方案中逻辑块地址(LBA)采用64位二进制表示,即2^64个逻辑块地址,这使得GPT比起MBR可以在分区中识别更多的磁盘容量。同时,GPT方案中在硬盘的末端还有一个备份的分区表,保证分区信息不容易丢失。
十二、总结raid0,1,5,10,01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现
1)RAID0:条带化,将数据分割并分别保存在每个磁盘中,提升了存储性能和空间。随机读写性能提升,利用率100%,无冗余容错,至少1个或1个以上硬盘来实现
2)RAID1:无校验镜像化,将数据存储在一个硬盘上时会自动再将数据复制到其他磁盘上,实现数据的备份。牺牲了读写性能,提升了安全性。随机读写性能下降,利用率 <=50%,安全可靠性高,至少2个或2个以上磁盘来实现
3)RAID5:分布式校验条带存储。在写入数据时,会将校验数据分布到各个磁盘上,在一个磁盘出现故障离线时,会根据校验数据修复因磁盘故障导致的数据丢失。随机读写性能下降,利用率(N-1)/N,性价比高有一定容错,允许最多一个磁盘损坏或离线,至少3或3个以上磁盘来实现
4)RAID10 镜像与条带存储。先创建2个RAID1,再将2个RAID1组合为RAID10。随机读写性能下降,利用率<=50%,有一定的冗余容错,每个RAID1中允许最多一个磁盘损坏,至少4个或4个以上磁盘来实现
5)RAID01:条带与镜像存储。先创建2个RAID0,再将2个RAID0组合为RAID01。随机读写性能下降,利用率<=50%,有一定的冗余容错,只要保证最少一个RAID0正常即可保证RAID01正常,至少4或4个以上磁盘来实现。
十三、完成不影响业务下对LVM磁盘扩容以及缩容实例
计算机系统中使用的多种进制:二进制,八进制,十六进制等等,现实中使用的多十进制。这就需要在使用的时候对进制进行转换。
1)创建物理卷
pvcreate -y 分区1,分区2

检查翻去是否是Linux LVM
fdisk -l 分区

如果不是Linux LVM,需要使用fdisk修改

2)查看物理卷
pvs
pvdisplay

3)创建卷组
vgcreate 组名 物理卷1 物理卷2 物理卷3...

4)查看卷组
vgs
vgdisplay

5)从卷组中创建逻辑卷
lvcreate -r -L 卷大小 -n 逻辑卷名 卷组名


6)扩容
lvextend -r -L +容量 逻辑卷名

7)缩容
如果存在挂载,需要先取消挂载
同时缩容前务必要备份逻辑卷中的数据,缩容的时候有一定概率会导致文件数据损坏。
缩容:lvreduce -r -L -容量 逻辑卷名

