1、RocketMQ概述
第1章 RocketMQ概述
一、MQ概述
1、MQ简介
MQ,Message Queue,是一种提供消息队列服务的中间件,也称为消息中间件,是一套提供了消息生
产、存储、消费全过程API的软件系统。消息即数据。一般消息的体量不会很大。
2、MQ用途
从网上可以查看到很多的关于MQ用途的叙述,但总结起来其实就以下三点。
限流削峰
MQ可以将系统的超量请求暂存其中,以便系统后期可以慢慢进行处理,从而避免了请求的丢失或系统
被压垮。
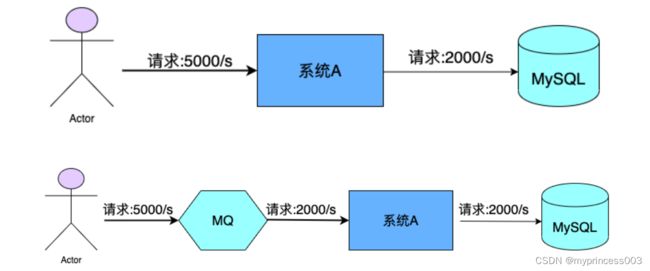
异步解耦
上游系统对下游系统的调用若为同步调用,则会大大降低系统的吞吐量与并发度,且系统耦合度太高。
而异步调用则会解决这些问题。所以两层之间若要实现由同步到异步的转化,一般性做法就是,在这两
层间添加一个MQ层。
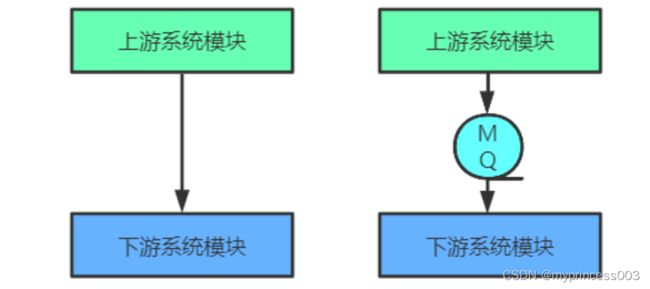
数据收集
分布式系统会产生海量级数据流,如:业务日志、监控数据、用户行为等。针对这些数据流进行实时或
批量采集汇总,然后对这些数据流进行大数据分析,这是当前互联网平台的必备技术。通过MQ完成此
类数据收集是最好的选择。
3、常见MQ产品
ActiveMQ
ActiveMQ是使用Java语言开发一款MQ产品。早期很多公司与项目中都在使用。但现在的社区活跃度已
经很低。现在的项目中已经很少使用了。
RabbitMQ
RabbitMQ是使用ErLang语言开发的一款MQ产品。其吞吐量较Kafka与RocketMQ要低,且由于其不是
Java语言开发,所以公司内部对其实现定制化开发难度较大。
Kafka
Kafka是使用Scala/Java语言开发的一款MQ产品。其最大的特点就是高吞吐率,常用于大数据领域的实
时计算、日志采集等场景。其没有遵循任何常见的MQ协议,而是使用自研协议。对于Spring Cloud
Netç ix,其仅支持RabbitMQ与Kafka。
RocketMQ
RocketMQ是使用Java语言开发的一款MQ产品。经过数年阿里双11的考验,性能与稳定性非常高。其
没有遵循任何常见的MQ协议,而是使用自研协议。对于Spring Cloud Alibaba,其支持RabbitMQ、
Kafka,但提倡使用RocketMQ。
二、RocketMQ概述
1、RocketMQ简介

RocketMQ是一个统一消息引擎、轻量级数据处理平台。
RocketMQ是⼀款阿⾥巴巴开源的消息中间件。2016年11⽉28⽇,阿⾥巴巴向 Apache 软件基⾦会捐赠
RocketMQ,成为 Apache 孵化项⽬。2017 年 9 ⽉ 25 ⽇,Apache 宣布 RocketMQ孵化成为 Apache 顶
级项⽬(TLP ),成为国内⾸个互联⽹中间件在 Apache 上的顶级项⽬。
2、RocketMQ发展历程

2007年,阿里开始五彩石项目,Notify作为项目中交易核心消息流转系统,应运而生。Notify系统是
RocketMQ的雏形。
2010年,B2B大规模使用ActiveMQ作为阿里的消息内核。阿里急需一个具有海量堆积能力的消息系
统。
2011年初,Kafka开源。淘宝中间件团队在对Kafka进行了深入研究后,开发了一款新的MQ,MetaQ。
2012年,MetaQ发展到了v3.0版本,在它基础上进行了进一步的抽象,形成了RocketMQ,然后就将其
进行了开源。
2015年,阿里在RocketMQ的基础上,又推出了一款专门针对阿里云上用户的消息系统Aliware MQ。
2016年双十一,RocketMQ承载了万亿级消息的流转,跨越了一个新的里程碑。11⽉28⽇,阿⾥巴巴
向 Apache 软件基⾦会捐赠 RocketMQ,成为 Apache 孵化项⽬。
2017 年 9 ⽉ 25 ⽇,Apache 宣布 RocketMQ孵化成为 Apache 顶级项⽬(TLP ),成为国内⾸个互联
⽹中间件在 Apache 上的顶级项⽬。
第2章 RocketMQ的基本概念
一、基本概念
1 消息(Message)
消息是指,消息系统所传输信息的物理载体,生产和消费数据的最小单位,每条消息必须属于一个主
题。
2 主题(Topic)

3 标签(Tag)
为消息设置的标签,用于同一主题下区分不同类型的消息。来自同一业务单元的消息,可以根据不同业
务目的在同一主题下设置不同标签。标签能够有效地保持代码的清晰度和连贯性,并优化RocketMQ提
供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
Topic是消息的一级分类,Tag是消息的二级分类。
Topic:货物
tag=上海
tag=江苏
tag=浙江
------- 消费者 -----
topic=货物 tag = 上海
topic=货物 tag = 上海|浙江
topic=货物 tag = *
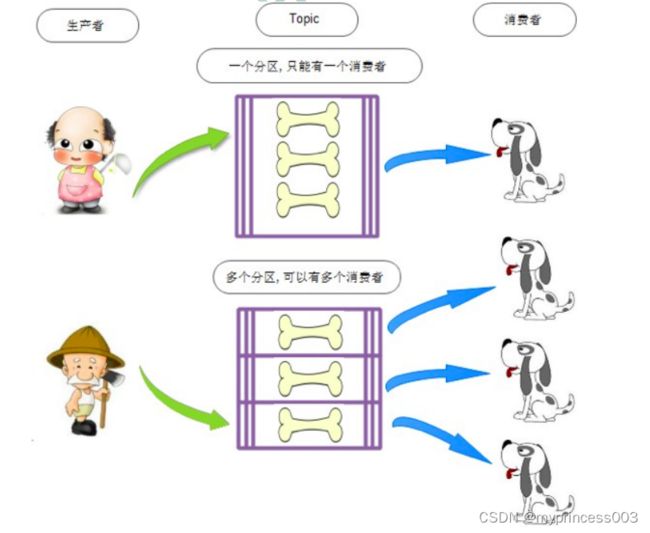
4 队列(Queue)
存储消息的物理实体。一个Topic中可以包含多个Queue,每个Queue中存放的就是该Topic的消息。一
个Topic的Queue也被称为一个Topic中消息的分区(Partition)。
一个Topic的Queue中的消息只能被一个消费者组中的一个消费者消费。一个Queue中的消息不允许同
一个消费者组中的多个消费者同时消费。
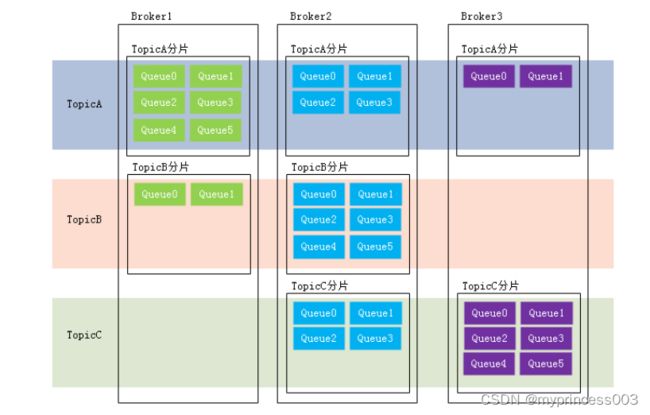
在学习参考其它相关资料时,还会看到一个概念:分片(Sharding)。分片不同于分区。在RocketMQ
中,分片指的是存放相应Topic的Broker。每个分片中会创建出相应数量的分区,即Queue,每个
Queue的大小都是相同的。
5 消息标识(MessageId/Key)
RocketMQ中每个消息拥有唯一的MessageId,且可以携带具有业务标识的Key,以方便对消息的查询。
不过需要注意的是,MessageId有两个:在生产者send()消息时会自动生成一个MessageId(msgId),
当消息到达Broker后,Broker也会自动生成一个MessageId(offsetMsgId)。msgId、offsetMsgId与key都
称为消息标识。
msgId:由producer端生成,其生成规则为:
producerIp + 进程pid + MessageClientIDSetter类的ClassLoader的hashCode +
当前时间 + AutomicInteger自增计数器
offsetMsgId:由broker端生成,其生成规则为:brokerIp + 物理分区的offset(Queue中的
偏移量)
key:由用户指定的业务相关的唯一标识
二、系统架构
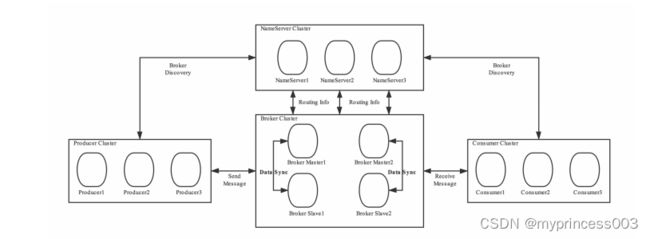
RocketMQ架构上主要分为四部分构成:
1 Producer
消息生产者,负责生产消息。Producer通过MQ的负载均衡模块选择相应的Broker集群队列进行消息投
递,投递的过程支持快速失败并且低延迟。
例如,业务系统产生的日志写入到MQ的过程,就是消息生产的过程
再如,电商平台中用户提交的秒杀请求写入到MQ的过程,就是消息生产的过程
RocketMQ中的消息生产者都是以生产者组(Producer Group)的形式出现的。生产者组是同一类生产
者的集合,这类Producer发送相同Topic类型的消息。一个生产者组可以同时发送多个主题的消息。
2 Consumer
消息消费者,负责消费消息。一个消息消费者会从Broker服务器中获取到消息,并对消息进行相关业务
处理。
例如,QoS系统从MQ中读取日志,并对日志进行解析处理的过程就是消息消费的过程。
再如,电商平台的业务系统从MQ中读取到秒杀请求,并对请求进行处理的过程就是消息消费的
过程。
RocketMQ中的消息消费者都是以消费者组(Consumer Group)的形式出现的。消费者组是同一类消
费者的集合,这类Consumer消费的是同一个Topic类型的消息。消费者组使得在消息消费方面,实现
负载均衡(将一个Topic中的不同的Queue平均分配给同一个Consumer Group的不同的Consumer,注
意,并不是将消息负载均衡)和容错(一个Consmer挂了,该Consumer Group中的其它Consumer可
以接着消费原Consumer消费的Queue)的目标变得非常容易。
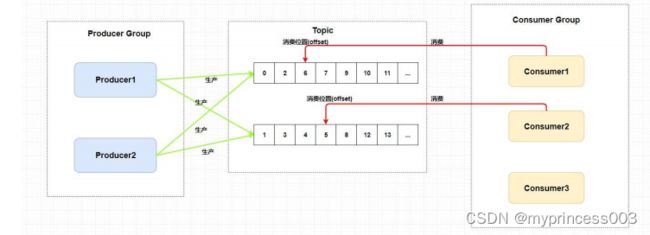
消费者组中Consumer的数量应该小于等于订阅Topic的Queue数量。如果超出Queue数量,则多出的
Consumer将不能消费消息。
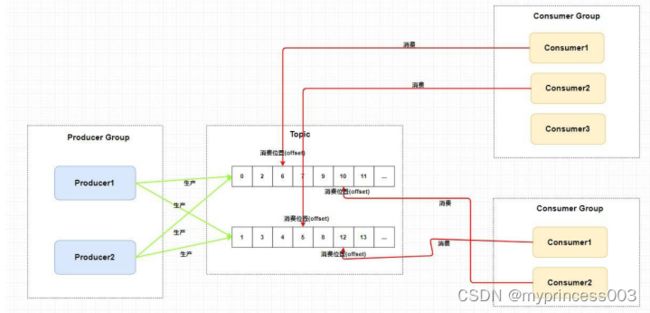
不过,一个Topic类型的消息可以被多个消费者组同时消费。
注意,
1)消费者组只能消费一个Topic的消息,不能同时消费多个Topic消息
2)一个消费者组中的消费者必须订阅完全相同的Topic
3 Name Server
功能介绍
NameServer是一个Broker与Topic路由的注册中心,支持Broker的动态注册与发现。
RocketMQ的思想来自于Kafka,而Kafka是依赖了Zookeeper的。所以,在RocketMQ的早期版本,即在
MetaQ v1.0与v2.0版本中,也是依赖于Zookeeper的。从MetaQ v3.0,即RocketMQ开始去掉了
Zookeeper依赖,使用了自己的NameServer。
主要包括两个功能:
Broker管理:接受Broker集群的注册信息并且保存下来作为路由信息的基本数据;提供心跳检测
机制,检查Broker是否还存活。
路由信息管理:每个NameServer中都保存着Broker集群的整个路由信息和用于客户端查询的队列
信息。Producer和Conumser通过NameServer可以获取整个Broker集群的路由信息,从而进行消
息的投递和消费。
路由注册
NameServer通常也是以集群的方式部署,不过,NameServer是无状态的,即NameServer集群中的各
个节点间是无差异的,各节点间相互不进行信息通讯。那各节点中的数据是如何进行数据同步的呢?在
Broker节点启动时,轮询NameServer列表,与每个NameServer节点建立长连接,发起注册请求。在
NameServer内部维护着⼀个Broker列表,用来动态存储Broker的信息。
注意,这是与其它像zk、Eureka、Nacos等注册中心不同的地方。
这种NameServer的无状态方式,有什么优缺点:
优点:NameServer集群搭建简单,扩容简单。
缺点:对于Broker,必须明确指出所有NameServer地址。否则未指出的将不会去注册。也正因
为如此,NameServer并不能随便扩容。因为,若Broker不重新配置,新增的NameServer对于
Broker来说是不可见的,其不会向这个NameServer进行注册。
Broker节点为了证明自己是活着的,为了维护与NameServer间的长连接,会将最新的信息以心跳包的
方式上报给NameServer,每30秒发送一次心跳。心跳包中包含 BrokerId、Broker地址(IP+Port)、
Broker名称、Broker所属集群名称等等。NameServer在接收到心跳包后,会更新心跳时间戳,记录这
个Broker的最新存活时间。
路由剔除
由于Broker关机、宕机或网络抖动等原因,NameServer没有收到Broker的心跳,NameServer可能会将
其从Broker列表中剔除。
NameServer中有⼀个定时任务,每隔10秒就会扫描⼀次Broker表,查看每一个Broker的最新心跳时间
戳距离当前时间是否超过120秒,如果超过,则会判定Broker失效,然后将其从Broker列表中剔除。
扩展:对于RocketMQ日常运维工作,例如Broker升级,需要停掉Broker的工作。OP需要怎么
做?
OP需要将Broker的读写权限禁掉。一旦client(Consumer或Producer)向broker发送请求,都会收
到broker的NO_PERMISSION响应,然后client会进行对其它Broker的重试。
当OP观察到这个Broker没有流量后,再关闭它,实现Broker从NameServer的移除。
OP:运维工程师
SRE:Site Reliability Engineer,现场可靠性工程师
路由发现
RocketMQ的路由发现采用的是Pull模型。当Topic路由信息出现变化时,NameServer不会主动推送给
客户端,而是客户端定时拉取主题最新的路由。默认客户端每30秒会拉取一次最新的路由。
扩展:
1)Push模型:推送模型。其实时性较好,是一个“发布-订阅”模型,需要维护一个长连接。而
长连接的维护是需要资源成本的。该模型适合于的场景:
实时性要求较高
Client数量不多,Server数据变化较频繁
2)Pull模型:拉取模型。存在的问题是,实时性较差。
3)Long Polling模型:长轮询模型。其是对Push与Pull模型的整合,充分利用了这两种模型的优
势,屏蔽了它们的劣势。
客户端NameServer选择策略
这里的客户端指的是Producer与Consumer
客户端在配置时必须要写上NameServer集群的地址,那么客户端到底连接的是哪个NameServer节点
呢?客户端首先会生产一个随机数,然后再与NameServer节点数量取模,此时得到的就是所要连接的
节点索引,然后就会进行连接。如果连接失败,则会采用round-robin策略,逐个尝试着去连接其它节
点。
首先采用的是随机策略进行的选择,失败后采用的是轮询策略。
扩展:Zookeeper Client是如何选择Zookeeper Server的?
简单来说就是,经过两次Shufæ e,然后选择第一台Zookeeper Server。
详细说就是,将配置文件中的zk server地址进行第一次shufæ e,然后随机选择一个。这个选择出
的一般都是一个hostname。然后获取到该hostname对应的所有ip,再对这些ip进行第二次
shufæ e,从shufæ e过的结果中取第一个server地址进行连接。
4 Broker
功能介绍
Broker充当着消息中转角色,负责存储消息、转发消息。Broker在RocketMQ系统中负责接收并存储从
生产者发送来的消息,同时为消费者的拉取请求作准备。Broker同时也存储着消息相关的元数据,包括
消费者组消费进度偏移offset、主题、队列等。
Kafka 0.8版本之后,offset是存放在Broker中的,之前版本是存放在Zookeeper中的。
模块构成
下图为Broker Server的功能模块示意图。

Remoting Module:整个Broker的实体,负责处理来自clients端的请求。而这个Broker实体则由以下模
块构成。
Client Manager:客户端管理器。负责接收、解析客户端(Producer/Consumer)请求,管理客户端。例
如,维护Consumer的Topic订阅信息
Store Service:存储服务。提供方便简单的API接口,处理消息存储到物理硬盘和消息查询功能。
HA Service:高可用服务,提供Master Broker 和 Slave Broker之间的数据同步功能。
Index Service:索引服务。根据特定的Message key,对投递到Broker的消息进行索引服务,同时也提
供根据Message Key对消息进行快速查询的功能。
集群部署
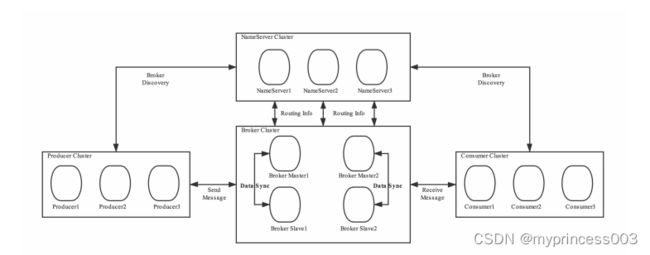
为了增强Broker性能与吞吐量,Broker一般都是以集群形式出现的。各集群节点中可能存放着相同
Topic的不同Queue。不过,这里有个问题,如果某Broker节点宕机,如何保证数据不丢失呢?其解决
方案是,将每个Broker集群节点进行横向扩展,即将Broker节点再建为一个HA集群,解决单点问题。
Broker节点集群是一个主从集群,即集群中具有Master与Slave两种角色。Master负责处理读写操作请
求,Slave负责对Master中的数据进行备份。当Master挂掉了,Slave则会自动切换为Master去工作。所
以这个Broker集群是主备集群。一个Master可以包含多个Slave,但一个Slave只能隶属于一个Master。
Master与Slave 的对应关系是通过指定相同的BrokerName、不同的BrokerId 来确定的。BrokerId为0表
示Master,非0表示Slave。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信
息到所有NameServer。
5 工作流程
具体流程
1)启动NameServer,NameServer启动后开始监听端口,等待Broker、Producer、Consumer连接。
2)启动Broker时,Broker会与所有的NameServer建立并保持长连接,然后每30秒向NameServer定时
发送心跳包。
3)发送消息前,可以先创建Topic,创建Topic时需要指定该Topic要存储在哪些Broker上,当然,在创
建Topic时也会将Topic与Broker的关系写入到NameServer中。不过,这步是可选的,也可以在发送消
息时自动创建Topic。
4)Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获
取路由信息,即当前发送的Topic消息的Queue与Broker的地址(IP+Port)的映射关系。然后根据算法
策略从队选择一个Queue,与队列所在的Broker建立长连接从而向Broker发消息。当然,在获取到路由
信息后,Producer会首先将路由信息缓存到本地,再每30秒从NameServer更新一次路由信息。
5)Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取其所订阅Topic的路由信息,
然后根据算法策略从路由信息中获取到其所要消费的Queue,然后直接跟Broker建立长连接,开始消费
其中的消息。Consumer在获取到路由信息后,同样也会每30秒从NameServer更新一次路由信息。不过
不同于Producer的是,Consumer还会向Broker发送心跳,以确保Broker的存活状态。
Topic的创建模式
手动创建Topic时,有两种模式:
集群模式:该模式下创建的Topic在该集群中,所有Broker中的Queue数量是相同的。
Broker模式:该模式下创建的Topic在该集群中,每个Broker中的Queue数量可以不同。
自动创建Topic时,默认采用的是Broker模式,会为每个Broker默认创建4个Queue。
读/写队列
从物理上来讲,读/写队列是同一个队列。所以,不存在读/写队列数据同步问题。读/写队列是逻辑上进
行区分的概念。一般情况下,读/写队列数量是相同的。
例如,创建Topic时设置的写队列数量为8,读队列数量为4,此时系统会创建8个Queue,分别是0 1 2 3
4 5 6 7。Producer会将消息写入到这8个队列,但Consumer只会消费0 1 2 3这4个队列中的消息,4 5 6
7中的消息是不会被消费到的。
再如,创建Topic时设置的写队列数量为4,读队列数量为8,此时系统会创建8个Queue,分别是0 1 2 3
4 5 6 7。Producer会将消息写入到0 1 2 3 这4个队列,但Consumer只会消费0 1 2 3 4 5 6 7这8个队列中
的消息,但是4 5 6 7中是没有消息的。此时假设Consumer Group中包含两个Consuer,Consumer1消
费0 1 2 3,而Consumer2消费4 5 6 7。但实际情况是,Consumer2是没有消息可消费的。
也就是说,当读/写队列数量设置不同时,总是有问题的。那么,为什么要这样设计呢?
其这样设计的目的是为了,方便Topic的Queue的缩容。
例如,原来创建的Topic中包含16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息?可以动
态修改写队列数量为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是
16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列数量动态设置为8。整
个缩容过程,没有丢失任何消息。
perm用于设置对当前创建Topic的操作权限:2表示只写,4表示只读,6表示读写。