JavaScript 数据结构与算法(一) 数组、栈、队列、链表、集合和字典
本文参考文献:https://www.cnblogs.com/AhuntSun-blog/p/12636718.html
配套视频教程:https://www.bilibili.com/video/BV1r7411n7Pw?p=1&spm_id_from=pageDriver
目录
- 数据结构-一
-
-
- 栈 Stack
-
-
- 前置知识-执行上下文(函数执行栈/函数调用栈)
- 简介
- 常见例题
- 封装和实现
- 案例:十进制转二进制
-
- 队列 Queue
-
-
- 简介
- 封装和实现
- 案例:击鼓传花
-
- 优先队列
-
-
- 简介
- 封装和实现
- arr.splice() & arr.push()
-
- 链表(单向)
-
-
- 简介
- 链表的特点
- 封装和实现
-
- 元素添加 append()方法
- toString()方法
- 插入节点 inseret() 方法
- 获取指定位置的节点 get()方法
- 根据数据查索引位置 indexOf()
- 修改对应位置的节点内容 update()
- 删除指定位置的节点 removeAt()
- 其他方法
-
- 链表(双向)
-
-
- 简介
- 双向链表的特点
- 封装和实现
-
- append() 方法
- insert()方法
- get()方法和indexOf()方法
- removeAt()方法
- update() 方法
- remove()、isEmpty()、size()、getHead()、getTail()方法
-
- 集合 set
-
-
- 简介
- 封装和实现
- 集合间的操作
-
- 并集
- 交集
- 差集
- 子集
-
- 字典 map
-
-
- 简介
- 封装和实现
-
-
数据结构-一
栈 Stack
前置知识-执行上下文(函数执行栈/函数调用栈)
当一段 JavaScript 代码在运行的时候,它实际上是运行在执行上下文中。下面3种类型的代码会创建一个新的执行上下文:
- 全局上下文是为运行代码主体而创建的执行上下文,也就是说它是为那些存在于JavaScript 函数之外的任何代码而创建的。
- 每个函数会在执行的时候创建自己的执行上下文。这个上下文就是通常说的 “本地上下文”。
- 使用
eval()函数也会创建一个新的执行上下文。
每一个上下文在本质上都是一种作用域层级。每个代码段开始执行的时候都会创建一个新的上下文来运行它,并且在代码退出的时候销毁掉。看看下面这段 JavaScript 程序:
let outputElem = document.getElementById("output");
let userLanguages = {
"Mike": "en",
"Teresa": "es"
};
function greetUser(user) {
function localGreeting(user) {
let greeting;
let language = userLanguages[user];
switch(language) {
case "es":
greeting = `¡Hola, ${user}!`;
break;
case "en":
default:
greeting = `Hello, ${user}!`;
break;
}
return greeting;
}
outputElem.innerHTML += localGreeting(user) + "
\r";
}
greetUser("Mike");
greetUser("Teresa");
greetUser("Veronica");
这段程序代码包含了三个执行上下文,其中有些会在程序运行的过程中多次创建和销毁。每个上下文创建的时候会被推入执行上下文栈。当退出的时候,它会从上下文栈中移除。
- 程序开始运行时,全局上下文就会被创建好。
- 当执行到
greetUser("Mike")的时候会为greetUser()函数创建一个它的上下文。这个执行上下文会被推入执行上下文栈中。- 当
greetUser()调用localGreeting()的时候会为该方法创建一个新的上下文。并且在localGreeting()退出的时候它的上下文也会从执行栈中弹出并销毁。 程序会从栈中获取下一个上下文并恢复执行, 也就是从greetUser()剩下的部分开始执行。 greetUser()执行完毕并退出,其上下文也从栈中弹出并销毁。
- 当
- 当
greetUser("Teresa")开始执行时,程序又会为它创建一个上下文并推入栈顶。- 当
greetUser()调用localGreeting()的时候另一个上下文被创建并用于运行该函数。 当localGreeting()退出的时候它的上下文也从栈中弹出并销毁。greetUser()得到恢复并继续执行剩下的部分。 greetUser()执行完毕并退出,其上下文也从栈中弹出并销毁。
- 当
- 然后执行到
greetUser("Veronica")又再为它创建一个上下文并推入栈顶。- 当
greetUser()调用localGreeting()的时候,另一个上下文被创建用于执行该函数。当localGreeting()执行完毕,它的上下文也从栈中弹出并销毁。 greetUser()执行完毕退出,其上下文也从栈中弹出并销毁。
- 当
- 当执行到
- 主程序退出,全局执行上下文从执行栈中弹出。此时栈中所有的上下文都已经弹出,程序执行完毕。
以这种方式来使用执行上下文,使得每个程序和函数都能够拥有自己的变量和其他对象。每个上下文还能够额外的跟踪程序中下一行需要执行的代码以及一些对上下文非常重要的信息。以这种方式来使用上下文和上下文栈,使得我们可以对程序运行的一些基础部分进行管理,包括局部和全局变量、函数的调用与返回等。
关于递归函数——即多次调用自身的函数,需要特别注意:每次递归调用自身都会创建一个新的上下文。这使得 JavaScript 运行时能够追踪递归的层级以及从递归中得到的返回值,但这也意味着每次递归都会消耗内存来创建新的上下文。
简介
数组是一个线性结构,并且可以在数组的任意位置插入、删除元素。而栈和队列就是比较常见的受限的线性结构,如下图所示:

栈的特点为先进后出,后进先出(LIFO:last in first out)。
程序中的栈结构:
- 函数调用栈:
A(B(C(D())))该语句中,函数A中调用函数B,函数B中调用函数C,函数C中调用函数D。具体的栈的变化就是:在A执行的过程中会将A压入栈,随后B执行时B也被压入栈,函数C和D执行时也会被压入栈。所以当前栈的顺序为:A->B->C->D(栈顶);函数D执行完之后,会弹出栈被释放,弹出栈的顺序为D->C->B->A; - 递归:为什么没有停止条件限制的递归会导致栈溢出 Stack Overfloat错误?假设函数A为递归函数,在函数体内不断地调用自己,也就不断的在栈中压入新的函数上下文(因为函数还没有执行完,不会把函数弹出栈),最后就会造成栈溢出。
常见例题
题目:有6个元素6,5,4,3,2,1按顺序进栈,问下列哪一个不是合法的出栈顺序?
- A:5 4 3 6 1 2 (√)
- B:4 5 3 2 1 6 (√)
- C:3 4 6 5 2 1 (×)
- D:2 3 4 1 5 6 (√)
题目所说的按顺序进栈指的不是一次性全部进栈,而是可以有进有出,但是进栈顺序必须为6 -> 5 -> 4 -> 3 -> 2 -> 1。
解析:
- A答案:65进栈,5出栈,4进栈出栈,3进栈出栈,6出栈,21进栈,1出栈,2出栈(整体入栈顺序符合654321);
- B答案:654进栈,4出栈,5出栈,3进栈出栈,2进栈出栈,1进栈出栈,6出栈(整体的入栈顺序符合654321);
- C答案:6543进栈,3出栈,4出栈,之后应该5出栈而不是6,所以错误;
- D答案:65432进栈,2出栈,3出栈,4出栈,1进栈出栈,5出栈,6出栈。符合入栈顺序;
封装和实现
栈可以基于数组或链表实现。
实现目标:
封装一个栈类,可实现栈的结构,并能够进行六种常见的栈操作:
- push(element):添加一个新元素到栈顶位置;
- pop():移除栈顶的元素,同时返回被移除的元素;
- peek():返回栈顶的元素,不对栈做任何修改(该方法不会移除栈顶的元素,仅仅返回它);
- isEmpty():如果栈里没有任何元素就返回true,否则返回false;
- size():返回栈里的元素个数。这个方法和数组的length属性类似;
- toString():将栈结构的内容以大字符串的形式返回。
基于数组的实现:
class Stack {
constructor() {
this.items = []
}
push(element) {
this.items.push(element)
}
pop() {
return this.items.pop()
}
peek() {
return this.items[this.items.length - 1]
}
isEmpty() {
if (this.items.length === 0) {
return true
} else {
return false
}
}
size() {
return this.items.length
}
toString() {
return this.items.join(' ')
}
}
使用方式:
let s = new Stack()
s.push(20)
s.push(10)
s.push(100)
s.push(77)
console.log(s) // 20,10,100,77
console.log(s.pop());
console.log(s.pop());
console.log(s.peek()); // 10
console.log(s.isEmpty()); // false
console.log(s.size()); // 2
console.log(s.toString()); // '20 10'
案例:十进制转二进制
我们知道,十进制转二进制需要对数进行除二取余,完成后再从下往上讲余数拼凑成二进制结果,这一方式就可以利用栈结构的特点来实现。
function d2b(val) {
// 定义一个栈,保存余数
let s = new Stack();
// 进行循环的除法
while (val > 0) {
// 保存余数
s.push(val % 2);
// 修改被除数
val = Math.floor(val / 2);
}
let res = '';
// 拼装结果
while (!s.isEmpty()) {
res += s.pop()
}
return res
}
队列 Queue
简介
队列也是一种受限的线性表,它的特点为先进先出(FIFO:First In First Out)。
- 它只允许在队列的前端front进行删除操作
- 只运行在队列的后端rear进行插入操作

封装和实现
队列可以基于数组或链表实现。
实现目标:
封装一个队列的类,可实现队列的结构,并能够进行六种常见的队列操作:
- enqueue(element):向队列尾部添加一个(或多个)新的项;
- dequeue():移除队列的第一(即排在队列最前面的)项,并返回被移除的元素;
- front():返回队列中的第一个元素——最先被添加,也将是最先被移除的元素。队列不做任何变动(不移除元素,只返回元素信息与Stack类的peek方法非常类似);
- isEmpty():如果队列中不包含任何元素,返回true,否则返回false;
- size():返回队列包含的元素个数,与数组的length属性类似;
- toString():将队列中的内容,转成字符串形式;
基于数组的实现:
class Queue {
constructor() {
this.items = []
}
enqueue(element) {
this.items.push(element)
}
dequeue() {
return this.items.shift()
}
front() {
return this.items[0]
}
isEmpty() {
if (this.items.length === 0) {
return true
} else {
return false
}
}
size() {
return this.items.length
}
toString() {
return this.items.join(' ')
}
}
案例:击鼓传花
需实现的功能:
传入:一个数组与一个数组num
循环遍历这个数组num次,第num次遍历到的元素从数组中剔除,并从下一个元素开始再次遍历,以此类推直至数组中剩下一个元素,打印这个元素及其在原数组中的索引位置。
function jgch(arr, num) {
let que = new Queue();
for (let i in arr) {
que.enqueue(arr[i])
}
while (que.size() !== 1) {
for (let j = 0; j < num - 1; j++) {
que.enqueue(que.dequeue());
}
que.dequeue();
}
return que.front()
}
var x = jgch(['a', 'b', 'c', 'd', 'e'], 4) // 'd'
优先队列
简介
优先队列就是在原来的队列基础上,为每个元素添加一个优先级,队列在对元素排序时,需要更加优先级,将优先级高的元素排在队列的前端,考虑完优先级后,再根据添加的先后顺序排序。
优先级队列主要考虑的问题为:
- 每个元素不再只是一个数据,还包含数据的优先级;
- 在添加数据过程中,根据优先级放入到正确位置;
封装和实现
需要实现的方法和队列类似,基于数组实现。
// 封装优先级队列
function PriorityQueue() {
//内部类:在类里面再封装一个类;表示带优先级的数据
function QueueElement(element, priority) {
this.element = element;
this.priority = priority;
}
// 封装属性
this.items = []
// 1.实现按照优先级插入方法
PriorityQueue.prototype.enqueue = (element, priority) => {
// 1.1.创建QueueElement对象
let queueElement = new QueueElement(element, priority)
// 1.2.判断队列是否为空
if(this.items.length == 0){
this.items.push(queueElement)
}else{
// 定义一个变量记录是否成功添加了新元素
let added = false
for(let i of this.items){
// 让新插入的元素与原有元素进行优先级比较(priority越小,优先级越大)
if(queueElement.priority < i.priority){
this.items.splice(i, 0, queueElement)
added = true
// 新元素已经找到插入位置了可以使用break停止循环
break
}
}
// 新元素没有成功插入,就把它放在队列的最前面
if(!added){
this.items.push(queueElement)
}
}
}
// 2.dequeue():从队列中删除前端元素
PriorityQueue.prototype.dequeue = () => {
return this.items.shift()
}
// 3.front():查看前端的元素
PriorityQueue.prototype.front = () => {
return this.items[0]
}
// 4.isEmpty():查看队列是否为空
PriorityQueue.prototype.isEmpty = () => {
return this.items.length == 0;
}
// 5.size():查看队列中元素的个数
PriorityQueue.prototype.size = () => {
return this.items.length
}
// 6.toString():以字符串形式输出队列中的元素
PriorityQueue.prototype.toString = () => {
let resultString = ''
for (let i of this.items){
resultString += i.element + '-' + i.priority + ' '
}
return resultString
}
}
使用:
// 测试代码
let pq = new PriorityQueue();
pq.enqueue('Tom',111);
pq.enqueue('Hellen',200);
pq.enqueue('Mary',30);
pq.enqueue('Gogo',27);
// 打印修改过后的优先队列对象
console.log(pq);
// Gogo 27, Mary 30, Tom 111, Hellen 200
arr.splice() & arr.push()
关于数组方法splice用法:
-
splice(1,0,'Tom'):表示在索引为1的元素前面插入元素’Tom‘(也可以理解为从索引为1的元素开始删除,删除0个元素,再在索引为1的元素前面添加元素’Tom’); -
splice(1,1,'Tom'):表示从索引为1的元素开始删除(包括索引为1的元素),共删除1个元素,并添加元素’Tom’。即把索引为1的元素替换为元素’Tom’。
数组的push方法在数组、栈和队列中的形式:
- 数组:在数组[0,1,2]中,
push(3)结果为[0,1,2,3]; - 栈:执行
push(0),push(1),push(2),push(3),从栈底到栈顶的元素分别为:0,1,2,3;如果看成数组,可写为[0,1,2,3],但是索引为3的元素3其实是栈顶元素;所以说栈的push方法是向栈顶添加元素(但在数组的视角下为向数组尾部添加元素); - 队列:enqueue方法可以由数组的push方法实现,与数组相同,相当于在数组尾部添加元素。

链表(单向)
简介
链表和数组一样,可以用于存储一系列的元素,但是链表和数组的实现机制完全不同。链表的每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(有的语言称为指针或连接)组成。类似于火车头,一节车厢载着乘客(数据),通过节点连接另一节车厢。

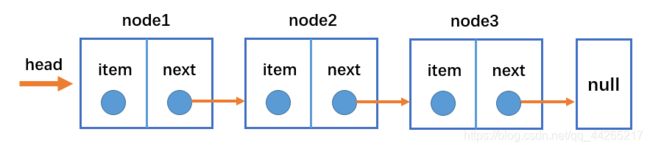
从上图可以看出,链表是有head属性和各个节点组成的:
- head属性指向链表的第一个节点;
- 链表中的最后一个节点指向null;
- 当链表中一个节点也没有的时候,head直接指向null;
链表的特点
数组是我们遇到的第一个也是最基本的数据结构,而数组也存在着部分缺点:
- 数组的创建通常需要申请一段连续的内存空间(一整块内存),并且大小是固定的。所以当原数组不能满足容量需求时,需要扩容(一般情况下是申请一个更大的数组,比如2倍,然后将原数组中的元素复制过去)。
- 在数组的开头或中间位置插入数据的时间成本很高,需要进行大量元素的位移。
而本节介绍的链表具有以下特点:
链表的优势:
- 链表中的元素在内存中不必是连续的空间,可以充分利用计算机的内存,实现灵活的内存动态管理。
- 链表不必在创建时就确定大小,并且大小可以无限地延伸下去。
- 链表在插入和删除数据时,时间复杂度可以达到O(1),相对数组效率高很多。
链表的缺点:
- 链表访问任何一个位置的元素时,都需要从头开始访问(无法跳过第一个元素访问任何一个元素)。
- 无法通过下标值直接访问元素,需要从头开始一个个访问,直到找到对应的元素。
- 虽然可以轻松地到达下一个节点,但是回到前一个节点是很难的。
封装和实现
链表中常见的操作(方法)有如下几种:
append(element):向链表尾部添加一个新的项;toString():由于链表项使用了Node类,就需要重写继承自JavaScript对象默认的toString方法,让其只输出元素的值;insert(position,element):向链表的特定位置插入一个新的项;get(position):获取对应位置的元素;indexOf(element):返回元素在链表中的索引。如果链表中没有该元素就返回-1;update(position,element):修改某个位置的元素;removeAt(position):从链表的特定位置移除一项;remove(element):从链表中移除一项;isEmpty():如果链表中不包含任何元素,返回true,如果链表长度大于0则返回false;size():返回链表包含的元素个数,与数组的length属性类似;
单向链表基本类的实现:
class Node {
constructor(element) {
this.data = element;
this.next = null;
}
}
class LinkedList {
constructor() {
this.length = 0;
this.head = null;
}
}
元素添加 append()方法
注意,以下方法均以ES6写法写在
LinkedList类中。
详细的方法理解和图解:https://www.cnblogs.com/AhuntSun-blog/p/12433173.html
传入数据,并将其添加到链表的最后一位。
append(data) {
let newNode = new Node(data);
// 情况一:判断第一个节点是否为空,如为空则直接将第一个节点head指向新节点即可
if (this.head === null) {
this.head = newNode;
} else { // 情况二:第一个节点不为空,需判断后续节点
let node = this.head;
// 判断下一个节点是否为空,如不为空则一直往下循环,直至没有节点
while (node.next !== null) {
node = node.next;
}
// 找到最后一个节点后,将其next指向新节点
node.next = newNode;
}
this.length += 1;
}
使用方式:
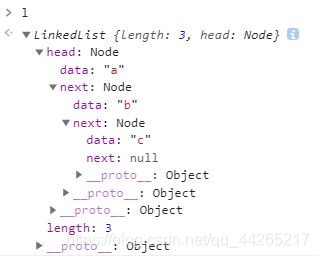
let l = new LinkedList();
l.append('a');
l.append('b');
l.append('c');
console.log(l)
此时,l的结构为:
toString()方法
将链表中所以节点的data取出并拼装成字符串。
toString() {
let result = "";
// 拿到第一个节点
let node = this.head;
// 循环往下搜索节点
while (node !== null) {
/ 取出每个节点的数据并拼接
result += node.data + " "
// node指向下一个节点
node = node.next
}
return result
}
插入节点 inseret() 方法
指定位置和数据,并插入到链表的指定位置处。
insert(position, data) {
// 边界条件判断,如果position超出范围则直接结束
if (position < 0 || position > this.length) return false
// 构建新节点
var newNode = new Node(data);
// 情况一:如果要将新节点插入到第一个,直接赋值即可
if (position == 0) {
// 把新节点指向原来的第一个节点
newNode.next = this.head;
// 把head头节点指向新节点
this.head = newNode;
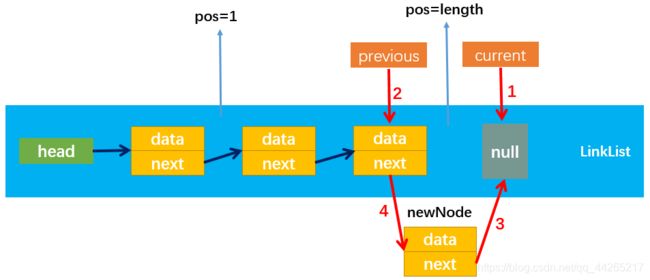
} else { // 情况二:新节点插入第二个及以后的位置
// 定义索引号、前一个节点、当前节点
let index = 0;
let previous = null;
let current = this.head;
// 通过循环使变量current不断指向下一个节点,直至指向了position位置的下一个节点
// 注意:第一次循环执行前,previous指向null,current指向第一个节点
// 第一次循环执行完成后,previous指向了第一个节点,而current指向了第二个节点
while (index++ < position) {
previous = current
current = current.next
}
// 当循环结束时,current指向了position位置的下一个节点,而previous则指向了position位置的节点
// 此时,让新节点的next指向current(连接新节点和后一个节点)
newNode.next = current
// 再让previous的next指向新节点,这样新节点就插入到两节点之间了(连接前一个节点和新节点)
previous.next = newNode
}
this.length += 1;
}
上述情况二中 存在一种特殊情况,即position = length,要插入的位置为最后一个节点的后面,此时current=null,previous为最后一个节点。
获取指定位置的节点 get()方法
获取链表指定位置处的数据。
get(position) {
// 边界条件判断
if (position < 0 || position >= this.length) return null
var current = this.head
var index = 0
// 循环至position处停止
while (index++ < position) {
current = current.next
}
// 取出position处的data并返回
return current.data
}
根据数据查索引位置 indexOf()
传入数据值,在链表中查找该数据,返回索引值,如没有相应数据则返回-1。
indexOf(data) {
var current = this.head;
var index = 0
// 循环读取每个节点的data,并判断是否为要找的元素
while (index < this.length) {
if (data === current.data) {
return index
} else {
index++;
current = current.next
}
}
return -1
}
修改对应位置的节点内容 update()
传入索引值和数据值,并修改索引值处的节点内容。
update(position, element) {
// 边界条件判断
if (position < 0 || position >= this.length) return null
var current = this.head
var index = 0
// 循环读取节点,直至找到position处的节点
while (index++ < position) {
current = current.next
}
// 修改该节点的值
current.data = element
return true
}
删除指定位置的节点 removeAt()
传入索引值,删除该位置的节点。
removeAt(position) {
// 边界条件判断,注意position不能等于length
if (position < 0 || position >= this.length) return null
// 绑定初始值
let current = this.head;
let previous = null;
let index = 0;
// 情况一:要删除的节点是第一个节点
if (position == 0) {
// 直接让head指向原来的第二个节点,第一个节点就被删除引用了
this.head = this.head.next;
} else { // 情况二:后续节点的删除
// 循环读取节点,直至找到position处的节点
while (index++ < position) {
// 此时,previous指向position处的前一个节点
previous = current
// current指向position处的节点
current = current.next
}
// 将position处的前一个节点的next(previous)指向position的下一个节点(current.next),即跳过position节点
previous.next = current.next
}
this.length--;
// 返回被删除节点的数据
return current.data
}
其他方法
删除指定数据的节点 remove():
传入数据值,删除链表中该数据的节点。
remove(data) {
// 用先前实现的方法来实现
let position = this.indexOf(data);
this.removeAt(position);
}
判断链表是否为空 isEmpty():
isEmpty() {
return this.length > 0 ? false : true
}
返回链表的节点个数 size():
size() {
return this.length
}
链表(双向)
简介
双向链表:既可以从头遍历到尾,又可以从尾遍历到头。也就是说链表连接的过程是双向的,它的实现原理是:一个节点既有向前连接的引用,也有一个向后连接的引用。
双向链表的结构:

- 双向链表不仅有
head指针指向第一个节点,而且有tail指针指向最后一个节点; - 每一个节点由三部分组成:
item储存数据、prev指向前一个节点、next指向后一个节点; - 双向链表的第一个节点的
prev指向null; - 双向链表的最后一个节点的
next指向null;
双向链表的特点
双向链表的缺点:
- 每次在插入或删除某个节点时,都需要处理四个引用,而不是两个,实现起来会困难些;
- 相对于单向链表,所占内存空间更大一些;
- 但是,相对于双向链表的便利性而言,这些缺点微不足道。
双向链表的优点:
- 解决了单向链表只能往下一个个的去访问节点的缺点
- 解决了单向链表只能往下访问,却不能往回访问的缺点
封装和实现
单向链表基本类的实现:
class Node {
constructor(element) {
this.data = element;
this.prev = null;
this.next = null;
}
}
class DoublyLinkedList {
constructor() {
this.length = 0;
this.head = null;
this.tail = null;
}
}
双向链表中常见的操作(方法)有如下几种:
append(element):向链表尾部添加一个新的项;inset(position,element):向链表的特定位置插入一个新的项;get(element):获取对应位置的元素;indexOf(element):返回元素在链表中的索引,如果链表中没有元素就返回-1;update(position,element):修改某个位置的元素;removeAt(position):从链表的特定位置移除一项;isEmpty():如果链表中不包含任何元素,返回trun,如果链表长度大于0则返回false;size():返回链表包含的元素个数,与数组的length属性类似;toString():由于链表项使用了Node类,就需要重写继承自JavaScript对象默认的toString方法,让其只输出元素的值;forwardString():返回正向遍历节点字符串形式;backwordString():返回反向遍历的节点的字符串形式;
append() 方法
append(element) {
const newNode = new Node(element);
// 情况一:链表中无节点
if (this.head === null) {
this.head = newNode;
this.tail = newNode;
} else { // 情况二:链表中已存在节点
// 需要修改原先最后一个节点的next指向、新节点的prev指向和this.tail的指向
this.tail.next = newNode;
newNode.prev = this.tail;
this.tail = newNode;
}
this.length++;
}
// 使用:(假设已有双向链表实例对象dll
dll.append('abc')

insert()方法
insert(position, element) {
const newNode = new Node(element);
// 边界条件判断
if (position < 0 || position > this.length) return false
// 情况一:插入到链表的开头
if (position == 0) {
// 情况一的情况一:当前链表中没有节点
if (this.head == null) {
this.head = newNode
this.tail = newNode
} else { // 情况一的情况二:链表已存在节点
// 此时需要考虑原先头节点的指向(this.head.prev)
this.head.prev = newNode
// 新节点的next指向
newNode.next = this.head
// this.head的指向
this.head = newNode
}
} else if (position == this.length) { // 情况二:插入到链表结尾处
// 需要考虑 新节点的prev、原末尾节点的next、this.tail
newNode.prev = this.tail
this.tail.next = newNode
this.tail = newNode
} else { // 情况三:插入到链表中间位置
let index = 0
let previous = null
let current = this.head
// 循环查找下一个节点,直至current为position处的节点,previous为current的前一个节点
while (index++ < position) {
previous = current
current = current.next
}
// 找到后,对插入节点的前后节点进行指向修改(共涉及到三个节点的修改)
previous.next = newNode
current.prev = newNode
newNode.next = current
newNode.prev = previous
}
this.length++
return true
}
}
// 使用:(假设已有双向链表实例对象dll
dll.insert(0, 'abc')
dll.insert(2, 'cba')
get()方法和indexOf()方法
直接继承单向链表的get和indexOf方法即可。
get(position) {
// 边界条件判断
if (position < 0 || position >= this.length) return null
var current = this.head
var index = 0
// 循环至position处停止
while (index++ < position) {
current = current.next
}
// 取出position处的data并返回
return current.data
}
// 使用:(假设已有双向链表实例对象dll
dll.get(1) // '元素值'
indexOf(data) {
var current = this.head;
var index = 0
// 循环读取每个节点的data,并判断是否为要找的元素
while (index < this.length) {
if (data === current.data) {
return index
} else {
index++;
current = current.next
}
}
return -1
}
// 使用:(假设已有双向链表实例对象dll
dll.indexOf('abc') // 索引位置
removeAt()方法
removeAt(position) {
if (position < 0 || position > this.length - 1) return false
// 为返回值而保存当前值
let current = this.head
// 情况一:删除第一个节点元素
if (position == 0) {
// 情况一的情况一:当前链表只有一个节点
if (this.length == 1) {
this.head = null
this.tail = null
} else { // 情况一的情况二:链表有多个节点
this.head = this.head.next
this.head.prev = null
}
} else if (position == this.length - 1) { // 情况二:删除链表的最后一个节点
current = this.tail
this.tail = this.tail.prev
this.tail.next = null
} else { // 情况三:删除链表的中间节点
let index = 0
while (index++ < position) {
current = current.next
}
// 修改 被删除节点的前后节点的指向
current.prev.next = current.next
current.next.prev = current.prev
}
this.length--;
// 返回被删除元素的值
return current.data
}
// 使用
dll.remoreAt(1) // 'data'
update() 方法
//update方法
update(position, newData) {
//1.越界判断
if (position < 0 || position >= this.length) {
return false
}
//2.寻找正确的节点
let current = this.head
let index = 0
//this.length / 2 > position:从头开始遍历
if (this.length / 2 > position) {
while(index++ < position){
current = current.next
}
//this.length / 2 =< position:从尾开始遍历
}else{
current = this.tail
index = this.length - 1
while (index -- > position) {
current = current.prev
}
}
//3.修改找到节点的data
current.data = newData
return true//表示成功修改
}
// 使用
dll.update(1, 'xxx') // true
remove()、isEmpty()、size()、getHead()、getTail()方法
/*--------------------其他方法-------------------*/
//remove方法
remove(data) {
//1.根据data获取下标值
let index = this.indexOf(data)
//2.根据index删除对应位置的节点
return this.removeAt(index)
}
//isEmpty方法
isEmpty() {
return this.length == 0
}
//size方法
size() {
return this.length
}
//getHead方法:获取链表的第一个元素
getHead() {
return this.head.data
}
//getTail方法:获取链表的最后一个元素
getTail() {
return this.tail.data
}
使用:
//测试代码
//1.创建双向链表
let list = new DoublyLinklist()
/*------------其他方法的测试--------------*/
list.append('a')
list.append('b')
list.append('c')
list.append('d')
//remove方法
console.log(list.remove('a'));
console.log(list);
//isEmpty方法
console.log(list.isEmpty());
//size方法
console.log(list.size());
//getHead方法
console.log(list.getHead());
//getTead方法
console.log(list.getTail());
集合 set
简介
集合通常是由一组无序的、不能重复的元素构成。
- 数学中常指的集合中的元素是可以重复的,但是计算机中集合的元素不能重复。
集合是特殊的数组:
- 特殊之处在于里面的元素没有顺序,也不能重复。
- 没有顺序意味着不能通过下标值进行访问,不能重复意味着相同的对象在集合中只会存在一份。
而在JavaScript的ES6中,已经新增了Set集合类,这次实现是为了了解这个数据结构的内部结构,从而有助于学习下面的哈希表。
封装和实现
集合比较常见的实现方式是哈希表,这里使用JavaScript的Object类进行封装。
因为Object.key()方法,就是类集合形式,Object的key是不可重复且无序的。
集合常见的操作(方法):
add(value):向集合添加一个新的项;remove(value):从集合中移除一个值;has(value):如果值在集合中,返回true,否则返回false;clear():移除集合中的所有项;size():返回集合所包含元素的数量,与数组的length属性相似;values():返回一个包含集合中所有值的数组;
// ES5写法
//封装集合类
function nSet() {
//属性
this.items = {}
//方法
//一.has方法
nSet.prototype.has = function (value) {
return this.items.hasOwnProperty(value)
}
//二.add方法
nSet.prototype.add = function (value) {
//判断集合中是否已经包含该元素
if (this.has(value)) {
return false
}
//将元素添加到集合中
this.items[value] = value//表示该属性键和值都为value
return true//表示添加成功
}
//三.remove方法
nSet.prototype.remove = function (value) {
//1.判断集合中是否包含该元素
if (!this.has(value)) {
return false
}
//2.将元素从属性中删除
delete this.items[value]
return true
}
//四.clear方法
nSet.prototype.clear = function () {
console.log(this)
//原来的对象没有引用指向,会被自动回收
this.items = {}
}
//五.size方法
nSet.prototype.size = function () {
console.log(this);
return Object.keys(this.items).length
}
//获取集合中所有的值
//六.values方法
nSet.prototype.values = function () {
return Object.keys(this.items)
}
集合间的操作
- 并集:对于给定的两个集合,返回一个包含两个集合中所有元素的新集合;
- 交集:对于给定的两个集合,返回一个包含两个集合中共有元素的新集合;
- 差集:对于给定的两个集合,返回一个包含所有存在于第一个集合且不存在于第二个集合的元素的新集合;
- 子集:验证一个给定集合是否是另一个集合的子集;

并集
并集就是包含两个集合的所有元素。
实现思路:创建一个集合C,把集合A的元素循环添加到C中,再把集合B的元素循环添加到C中,集合C就是A和B的并集了。
Set.prototype.union = function (otherSet) {
let unionSet = new Set();
let values = this.values();
for (let i = 0; i < values.length; i++) {
unionSet.add(values[i])
}
values = otherSet.values()
for (let i = 0; i < values.length; i++) {
unionSet.add(values[i])
}
return unionSet
}
// 使用方式:已有setA和setB
setC = setA.union(setB)
交集
实现思路:创建一个集合C,循环判断集合B中是否有集合A的每一个元素,如果有则加入到C中,此时集合C就是A和B的交集。
nSet.prototype.intersection = function (otherSet) {
let iSet = new nSet()
let values = this.values()
for (let i = 0; i < values.length; i++) {
if (otherSet.has(values[i])) {
iSet.add(values[i])
}
}
return iSet
}
// 使用方式:已有setA和setB
setC = setA.intersection(setB);
差集
实现思路:遍历集合A,当取得的元素不存在于集合B时,就把该元素添加到另一个集合C中。
nSet.prototype.differenceSet = function (otherSet) {
let iSet = new nSet()
let values = this.values()
for (let i = 0; i < values.length; i++) {
if (!otherSet.has(values[i])) {
iSet.add(values[i])
}
}
return iSet
}
子集
实现思路:遍历集合A,当取得的元素中有一个不存在于集合B时,就说明集合A不是集合B的子集,返回false,当循环结束后仍未false,则证明A是B的子集。
nSet.prototype.subSet = function (otherSet) {
let values = this.values();
for (let i = 0; i < values.length; i++) {
let item = values[i];
if (!otherSet.has(item)) {
return false
}
}
return true
}
字典 map
简介
字典的特点:
- 字典存储的是键值对,主要特点是一一对应;
- 比如保存一个人的信息:数组形式:
[19,‘Tom’,1.65],可通过下标值取出信息;字典形式:{"age":19,"name":"Tom","height":165},可以通过key取出value。 - 此外,在字典中key是不能重复且无序的(和set一样),而Value可以重复。
字典和映射的关系:
- 有些编程语言中称这种映射关系为字典,如Swift中的Dictonary,Python中的dict;
- 有些编程语言中称这种映射关系为Map,比如Java中的HashMap&TreeMap等;
封装和实现
字典类常见的操作:
set(key,value):向字典中添加新元素。remove(key):通过使用键值来从字典中移除键值对应的数据值。has(key):如果某个键值存在于这个字典中,则返回true,反之则返回false。get(key):通过键值查找特定的数值并返回。clear():将这个字典中的所有元素全部删除。size():返回字典所包含元素的数量。与数组的length属性类似。keys():将字典所包含的所有键名以数组形式返回。values():将字典所包含的所有数值以数组形式返回。
字典类可以基于JavaScript中的对象结构来实现(与set的封装方式类似),比较简单,这里直接实现字典类中的常用方法。
//封装字典类
function Dictionary(){
//字典属性
this.items = {}
//字典操作方法
//一.在字典中添加键值对
Dictionary.prototype.set = function(key, value){
this.items[key] = value
}
//二.判断字典中是否有某个key
Dictionary.prototype.has = function(key){
return this.items.hasOwnProperty(key)
}
//三.从字典中移除元素
Dictionary.prototype.remove = function(key){
//1.判断字典中是否有这个key
if(!this.has(key)) return false
//2.从字典中删除key
delete this.items[key]
return true
}
//四.根据key获取value
Dictionary.prototype.get = function(key){
return this.has(key) ? this.items[key] : undefined
}
//五.获取所有keys
Dictionary.prototype.keys = function(){
return Object.keys(this.items)
}
//六.size方法
Dictionary.prototype.keys = function(){
return this.keys().length
}
//七.clear方法
Dictionary.prototype.clear = function(){
this.items = {}
}
}