JDK1.8新特性
JDK1.8新特性
-
- IDE环境调整
- lambda表达式
-
-
- 代码实现
- 常用内置函数式接口
-
- 接口新增方法
- Stream流
-
-
- reduce终结
- 并行流
-
IDE环境调整

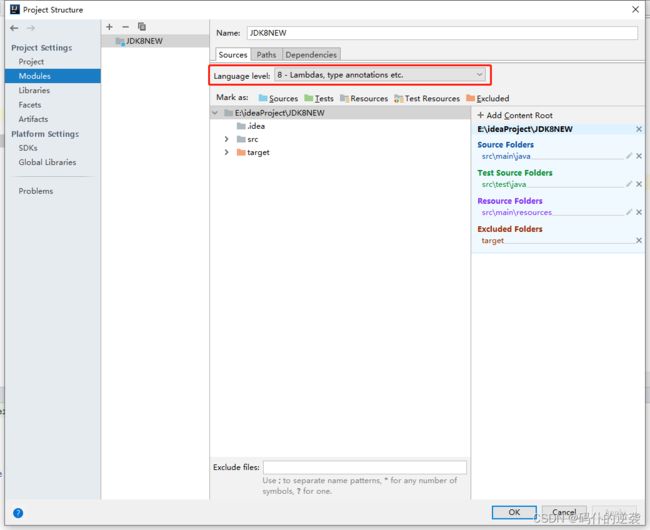
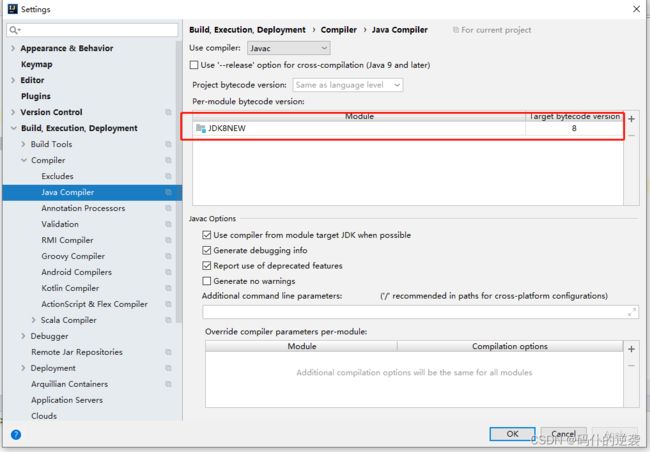
lambda表达式
-
⭐
lambda表达式的标准格式:(参数列表) -> { 函数体; } -
⭐
lambda表达式的省略规则:- 小括号内参数的类型可以省略
- 如果小括号内有且仅有一个参数,则小括号可以省略
- 如果大括号有且仅有一个语句,可以同时省略大括号、
return关键字和分号
-
⭐
lambda表达式应用的前提条件:- 方法的参数或局部变量的类型必须为接口
- 接口中有且仅有一个方法
-
⭐
lambda表达式与匿名内部类的区别:- 所需的类型不一样
匿名内部类,需要的类型可以是类,抽象类,接口
Lambda表达式,需要的类型必须是接口 - 抽象方法的数量不一样
匿名内部类所需的接口中抽象方法的数量随意
Lambda表达式所需的接口只能有一个抽象方法 - 实现原理不同
匿名内部类是在编译后会形成class
Lambda表达式是在程序运行的时候动态生成class
- 所需的类型不一样
代码实现
//以前匿名内部类的写法
new Thread(new Runnable() {
public void run() {
System.out.println("匿名内部类执行了");
}
}).start();
//使用lambda表达式
new Thread(() -> {
System.out.println("lambda表达式执行了");
}).start();
//lambda的省略格式
new Thread(() -> System.out.println("lambda省略表达式执行了")).start();
//lambda作为局部变量的值
Runnable run = () -> System.out.println("lambda省略表达式局部变量的值执行了");
run.run();
//匿名内部类写法十分冗余
//Lambda让我们只需要关注run方法里的逻辑代码即可
//Lambda就是一个匿名函数,我们只需将执行代码放到Lambda表达式即可
常用内置函数式接口
这些内置接口都属于java.util.function包中
//1. Supplier接口(无参带返回值)
@FunctionalInterface
public interface Supplier<T> {
public abstract T get();
}
//2. Consumer接口(有参不带返回值)
@FunctionalInterface
public interface Consumer<T> {
public abstract void accept(T t);
}
//3. Function接口(有参带返回值)
@FunctionalInterface
public interface Function<T, R> {
public abstract R apply(T t);
}
//4. Predicate接口(有参返回boolean值)
@FunctionalInterface
public interface Predicate<T> {
public abstract boolean test(T t);
}
接口新增方法
以前接口只有抽象方法,这不利于接口功能的拓展,一旦这个接口新增了一个方法,其下所有实现的子类都要去实现这个方法,JDK8之后,接口新增了默认方法和静态方法,增强了接口拓展功能的能力。
public interface Animal {
/**
* 默认方法
*/
default void eat(){
System.out.println("吃饭");
}
/**
* 静态方法
*/
static void dead(){
System.out.println("死亡");
}
}
默认方法和静态方法的区别:
- ⭐默认方法通过实例调用,静态方法通过接口名调用。
- ⭐默认方法可以被继承,实现类可以直接使用接口默认方法,也可以重写接口默认方法。
- ⭐静态方法不能被继承,实现类不能重写接口静态方法,只能使用接口名调用。
Stream流
| 方法名 | 中文注释 | 是否终结 |
|---|---|---|
filter |
过滤 | 否 |
limit |
获取集合前几个元素 | 否 |
skip |
跳过前面几个元素获取剩下的元素 | 否 |
distinct |
去重 | 否 |
concat |
两个流合成一个流 | 否 |
map |
类型转换 | 否 |
flatMap |
嵌套集合类型转换 | 否 |
sorted |
排序 | 否 |
parallel |
开启并行流 | 否 |
peek |
中间操作,没有任何输出,用于打印日志 | 否 |
count |
统计个数 | 是 |
anyMatch |
部分匹配 | 是 |
allMatch |
全量匹配 | 是 |
max |
最大值 | 是 |
min |
最小值 | 是 |
forEach |
遍历 | 是 |
toArray |
转为数组 | 是 |
collect |
转为集合 | 是 |
| collect | 中文注释 |
|---|---|
Collectors.toList() |
收集为List集合 |
Collectors.toSet() |
收集为Set集合 |
Collectors.toMap |
收集为Map集合 |
-
⭐集合过滤
public void listFilter() { List<String> list = Arrays.asList("张无忌", "周芷若", "张角", "赵敏", "张三丰"); //获取以张开头的集合 List<String> list1 = list.stream().filter(item -> item.startsWith("张")).collect(Collectors.toList()); System.out.println(list1); } -
⭐数组过滤
public void arrayFilter() { String[] arr = {"张无忌", "周芷若", "张角", "赵敏", "张三丰"}; String[] arr2 = Arrays.stream(arr).filter(item -> item.length() == 3).toArray(size -> new String[size]); Arrays.stream(arr2).forEach(item -> System.out.println(item)); } -
⭐零散数据过滤
public void streamFilter() { List<String> list = Stream.of("张无忌", "周芷若", "张角", "赵敏", "张三丰").filter(item -> item.length() == 2).collect(Collectors.toList()); System.out.println(list); } -
⭐集合遍历
public void foreachList() { List<String> list = Arrays.asList("张无忌", "周芷若", "张角", "赵敏", "张三丰"); list.stream().forEach(item -> System.out.println(item)); } -
⭐
map集合遍历public void streamMap() { Map<String, String> map = new HashMap<>(); map.put("name", "张三"); map.put("age", "23"); map.put("tel", "193321212312"); map.put("certId", "231231232143124"); map.put("address", "312131"); map.entrySet().stream().forEach(item -> System.out.println(item.getKey()+ "=====" + item.getValue())); } -
⭐获取前几个元素
public void listlimit() { List<String> list = Arrays.asList("张无忌", "周芷若", "张角", "赵敏", "张三丰"); //获取以张开头的集合 List<String> list1 = list.stream().limit(3).collect(Collectors.toList()); System.out.println(list1); } -
⭐跳过前几个元素
public void listskip() { List<String> list = Arrays.asList("张无忌", "周芷若", "张角", "赵敏", "张三丰"); //获取以张开头的集合 List<String> list1 = list.stream().skip(3).collect(Collectors.toList()); System.out.println(list1); } -
⭐去重,依赖
hashcode和equals方法,如果要给实体类去重,则必须重写hashcode和equals方法public void listDistinct() { List<String> list = Arrays.asList("张无忌", "周芷若", "张无忌", "赵敏", "张三丰"); //获取以张开头的集合 List<String> list1 = list.stream().distinct().collect(Collectors.toList()); System.out.println(list1); } -
⭐两个流合并为一个流
public void listConcat() { List<String> list1 = Arrays.asList("张无忌", "周芷若", "张无忌", "赵敏", "张三丰"); List<String> list2 = Arrays.asList("郭靖", "黄蓉", "梅超风", "杨康", "杨过", "杨铁心"); //获取以张开头的集合 List<String> list3 = Stream.concat(list1.stream(), list2.stream()).collect(Collectors.toList()); System.out.println(list3); } -
⭐计数
public void listCount() { List<String> list = Arrays.asList("张无忌", "周芷若", "张无忌", "赵敏", "张三丰"); long count = list.stream().count(); System.out.println(count); } -
⭐部分匹配
public void listAnyMatch() { List<String> list = Arrays.asList("张无忌", "周芷若", "张无忌", "赵敏", "张三丰"); //判断集合中是否有张姓人 boolean flag = list.stream().anyMatch(item -> item.startsWith("张")); System.out.println(flag); } -
⭐全部匹配
public void listAllMatch() { List<String> list = Arrays.asList("张无忌", "周芷若", "张恒", "赵敏", "张三丰"); //判断集合中是否全部姓张 boolean flag = list.stream().allMatch(item -> item.startsWith("张")); System.out.println(flag); } -
⭐排序
public void listOrder() { //正序 List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10); list.stream().sorted().forEach(item -> System.out.println(item)); System.out.println(); //倒序 list.stream().sorted((item1, item2) -> item2 - item1).forEach(item -> System.out.println(item)); } -
⭐嵌套集合遍历
public void flotMap() { List<String> manList = Arrays.asList("张无忌,23", "郭靖,25", "杨过,28", "赵子龙,33", "李小龙,38", "胡歌,34"); List<String> girlList = Arrays.asList("蔡依林,23", "杨颖,25", "杨紫,28", "赵灵儿,33", "杨雯婷,38", "黄悦,34"); List<List<String>> lists = new ArrayList<>(); lists.add(manList); lists.add(girlList); //flatMap适用于嵌套的集合转换类型 lists.stream().flatMap(item -> item.stream()).forEach(item -> System.out.println(item)); } -
⭐最值
public void maxAndmin() { List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10); Optional<Integer> max = list.stream().max((item1, item2) -> item1 - item2); System.out.println(max); Optional<Integer> min = list.stream().min((item1, item2) -> item1 - item2); System.out.println(min); }
reduce终结
- ⭐求和
public void sum() { List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10); //参数一初始值 参数二计算逻辑 Integer sum1 = list.stream().reduce(0, (item1, item2) -> item1 + item2); System.out.println(sum1); //参数一初始值 参数二计算逻辑 Integer sum2 = list.stream().reduce(0, Integer::sum); System.out.println(sum2); //初始值为集合第一个值 Optional<Integer> sum3 = list.stream().reduce(Integer::sum); System.out.println(sum3); } - ⭐最大值
public void max() { List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10); //参数一初始值 参数二计算逻辑 Integer max1 = list.stream().reduce(Integer.MIN_VALUE, (item1, item2) -> Integer.max(item1, item2)); System.out.println(max1); //参数一初始值 参数二计算逻辑 Integer max2 = list.stream().reduce(Integer.MIN_VALUE, Integer::max); System.out.println(max2); //计算逻辑,里面初始值为集合中第一个元素的值 Optional<Integer> max3 = list.stream().reduce((item1, item2) -> Integer.max(item1, item2)); System.out.println(max3); } - ⭐最小值
public void min() { List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10); //参数一初始值 参数二计算逻辑 Integer min1 = list.stream().reduce(Integer.MAX_VALUE, (item1, item2) -> Integer.min(item1, item2)); System.out.println(min1); //参数一初始值 参数二计算逻辑 Integer min2 = list.stream().reduce(Integer.MAX_VALUE, Integer::min); System.out.println(min2); //初始值为集合第一个值 Optional<Integer> min3 = list.stream().reduce(Integer::min); System.out.println(min3); }
并行流
Stream流默认是串形流,实现并行流请使用以下方法
public void bx() throws ExecutionException, InterruptedException {
List<Integer> list = Arrays.asList(11, 2, 32, 4, 15, 67, 7, 8, 9, 10);
//parallel()开启并行流
//第一种方式,会最大程度占用CPU线程,耗费资源, 不推荐
/*Optional max = list.stream().parallel()
.peek(item -> System.out.println(item.toString() + Thread.currentThread().getName()))
.max((item1, item2) -> item1 - item2);
System.out.println(max);*/
//第二种方式,线程数掌握在我们自己手中,可以避免服务器资源的占用
ForkJoinPool forkJoinPool2 = new ForkJoinPool(3);
ForkJoinTask<?> forkJoinTask = forkJoinPool2.submit(() -> {
Optional<Integer> max = list.stream().parallel()
.peek(item -> System.out.println(item.toString() + Thread.currentThread().getName()))
.max((item1, item2) -> item1 - item2);
System.out.println(max);
});
//阻塞
forkJoinTask.get();
System.out.println("主线程关闭");
}