Kubernetes集群+Keepalived+Nginx+防火墙 实例
目录
实验前期规划
1.拓扑图结构
2.实验要求
3.实验环境规划
一.kubeadm 部署 K8S 集群架构
1.环境准备
2.三个节点安装docker
3.三个节点安装kubeadm,kubelet和kubectl
4.部署K8S集群
(1)初始化
4.部署K8S集群
(1)初始化
(2)部署网络插件flannel
(3)测试创建 pod 资源
二.创建两个自主式的Pod资源
三.创建service资源
四、搭建负载均衡层
1.两台负载均衡器配置nginx(lb01、lb02)
2.两台负载均衡器配置keepalived(lb01、lb02)
3.关闭主调度器的nginx服务,模拟故障,测试keepalived
五、配置防火墙服务器(test6)
1.两台负载均衡器,将网关地址修改为防火墙服务器的内网IP地址(lb01、lb02)
2.配置防火墙服务器(test6:192.168.198.16)
(1)关闭防火墙和selinux
(2)配置客户端地址外网
(2)开启路由转发功能
(3)配置iptables策略
六.客户端机器配置(test7)
实验前期规划
1.拓扑图结构

2.实验要求
(1)Kubernetes 区域可采用 Kubeadm 方式进行安装。(kubectl get pods -o wide)
(2)要求在 Kubernetes 环境中,通过yaml文件的方式,创建2个Nginx Pod分别放置在两个不同的节点上,Pod使用hostPath类型的存储卷挂载,节点本地目录共享使用 /data,2个Pod副本测试页面二者要不同,以做区分,测试页面可自己定义。(node 节点查看:cat /data/index.html)
(3)编写service对应的yaml文件,使用NodePort类型和TCP 30000端口将Nginx服务发布出去。(master上查看node节点的端口curl 192.168.198.12:30000)
(4)负载均衡区域配置Keepalived+Nginx,实现负载均衡高可用,通过VIP 192.168.198.100和自定义的端口号即可访问K8S发布出来的服务。(在lb01上查看虚拟VIP+监听端口:curl 192.168.198.100:3344)
(5)iptables防火墙服务器,设置双网卡,并且配置SNAT和DNAT转换实现外网客户端可以通过12.0.0.1访问内网的Web服务。查看策略:iptables -t nat -nL;并且客户端访问12.0.0.1:3344)
3.实验环境规划
| 节点 | IP地址 | 安装的软件 |
| master(4C/4G,cpu核心数要求大于4) | 192.168.198.11 | docker、kubeadm、kubelet、kubectl、flannel |
| node01(2C/2G) | 192.168.198.12 | docker、kubeadm、kubelet、kubectl、flannel |
| node02(2C/2G) | 192.168.198.13 | docker、kubeadm、kubelet、kubectl、flannel |
| lb01 | 192.168.198.14 | nginx,keepalived |
| lb02 | 192.168.198.15 | nginx,keepalived |
| 网关服务器test6 | 内网网卡ens33:192.168.198.16,外网网卡ens36:192.168.198.100 | iptables |
| 客户端test7 | 12.0.0.12 |
一.kubeadm 部署 K8S 集群架构
1.环境准备
所有节点操作
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a #交换分区必须要关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭swap分区,&符号在sed命令中代表上次匹配的结果
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#修改主机名
hostnamectl set-hostname master
hostnamectl set-hostname node01
hostnamectl set-hostname node02
#所有节点修改hosts文件
vim /etc/hosts
192.168.198.11 master
192.168.198.12 node01
192.168.198.13 node02
#调整内核参数
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
#生效参数
sysctl --system2.三个节点安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
mkdir /etc/docker
cat > /etc/docker/daemon.json <3.三个节点安装kubeadm,kubelet和kubectl
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum install -y kubelet-1.15.1 kubeadm-1.15.1 kubectl-1.15.1
#开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
4.部署K8S集群
(1)初始化
所有节点
#查看初始化需要的镜像
kubeadm config images list
#开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启
4.部署K8S集群
(1)初始化
所有节点
#查看初始化需要的镜像
kubeadm config images list
master 节点上操作
#在 master 节点上传 v1.20.11.zip 压缩包至 /opt 目录
cd /opt/
unzip v1.20.11.zip -d /opt/k8s
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
node01节点上操作
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
node02节点上操作
cd /opt/k8s/v1.20.11
for i in $(ls *.tar); do docker load -i $i; done
master 节点上操作此处选用方法二的命令
#初始化kubeadm,有两种方式方法二命令和方法一配置文件,此处选用方法二的命令
方法一:
kubeadm config print init-defaults > /opt/kubeadm-config.yaml
cd /opt/
vim kubeadm-config.yaml
......
11 localAPIEndpoint:
12 advertiseAddress: 192.168.198.11 #指定master节点的IP地址
13 bindPort: 6443
......
34 kubernetesVersion: v1.20.11 #指定kubernetes版本号
35 networking:
36 dnsDomain: cluster.local
37 podSubnet: "10.244.0.0/16" #指定pod网段,10.244.0.0/16用于匹配flannel默认网段
38 serviceSubnet: 10.96.0.0/16 #指定service网段
39 scheduler: {}
#末尾再添加以下内容
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #把默认的kube-proxy调度方式改为ipvs模式
kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log
#--experimental-upload-certs 参数可以在后续执行加入节点时自动分发证书文件,K8S V1.16版本开始替换为 --upload-certs
#tee kubeadm-init.log 用以输出日志
#查看 kubeadm-init 日志
less kubeadm-init.log
#kubernetes配置文件目录
ls /etc/kubernetes/
#存放ca等证书和密码的目录
ls /etc/kubernetes/pki
方法二:
方法二:
kubeadm init \
--apiserver-advertise-address=192.168.198.11 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.11 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl=0
初始化集群需使用kubeadm init命令,可以指定具体参数初始化,也可以指定配置文件初始化。
可选参数:
–apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址
–apiserver-bind-port:apiserver的监听端口,默认是6443
–cert-dir:通讯的ssl证书文件,默认/etc/kubernetes/pki
–control-plane-endpoint:控制台平面的共享终端,可以是负载均衡的ip地址或者dns域名,高可用集群时需要添加
–image-repository:拉取镜像的镜像仓库,默认是k8s.gcr.io
–kubernetes-version:指定kubernetes版本
–pod-network-cidr:pod资源的网段,需与pod网络插件的值设置一致。Flannel网络插件的默认为10.244.0.0/16,Calico插件的默认值为192.168.0.0/16;
–service-cidr:service资源的网段
–service-dns-domain:service全域名的后缀,默认是cluster.local–token-ttl=0:默认token的有效期为24小时,如果不想过期,可以加上 --token-ttl=0 这个参数
#方法二初始化后需要修改 kube-proxy 的 configmap,开启 ipvs
kubectl edit cm kube-proxy -n=kube-system
#此处执行完会提示以下,则我们需要进一步操作设定
The connection to the server localhost:8080 was refused - did you specify the right host or port?
#设定kubectl,kubectl需经由API server认证及授权后方能执行相应的管理操作,kubeadm 部署的集群为其生成了一个具有管理员权限的认证配置文件 /etc/kubernetes/admin.conf,它可由 kubectl 通过默认的 “$HOME/.kube/config” 的路径进行加载。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
#显示已存在
ll /root/.kube/
chown $(id -u):$(id -g) $HOME/.kube/config
#授权结束即可以查看生成的相关信息配置,查看后即退出
vim /root/.kube/config
#再次初始化,就可看到相关信息,并修改第44行修改mode: "ipvs"
[root@master01 ~]# kubectl edit cm kube-proxy -n=kube-system
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 49m v1.20.11
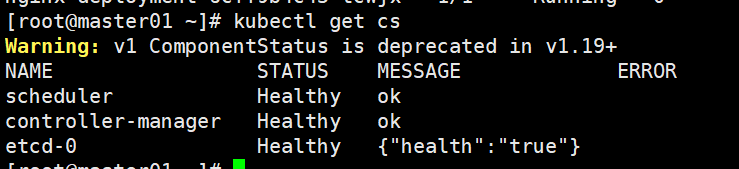
[root@master01 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"} #如果 kubectl get cs 发现集群不健康,更改以下两个文件
vim /etc/kubernetes/manifests/kube-scheduler.yaml
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
修改如下内容
把--bind-address=127.0.0.1变成--bind-address=192.168.198.11 #行修改成k8s的控制节点master01的ip
把httpGet:字段下的hosts由127.0.0.1变成192.168.198.11(有两处)
#- --port=0 # 搜索port=0,把这一行注释掉
systemctl restart kubelet
systemctl enable kubelet
#再次查看健康状态
kubectl get cs
(2)部署网络插件flannel
node01操作
方法一此文使用的是此方法:
#所有节点上传flannel镜像 flannel.tar 到 /opt 目录,master节点上传 kube-flannel.yml 文件
cd /opt
scp kuadmin-flannel.zip node02:/opt/
#解压
unzip kuadmin-flannel.zip
#加载
docker load -i flannel-cni-v1.2.0.tar
docker load -i flannel-v0.22.2.tar
#创建并解压到相关目录
mv cni cni_bak
mkdir cni/bin -p
tar zxvf cni-plugins-linux-amd64-v1.2.0.tgz -C cni/bin
#查看新的文件
ll cni/bin/
node02操作
cd /opt
unzip kuadmin-flannel.zip
docker load -i flannel-cni-v1.2.0.tar
docker load -i flannel-v0.22.2.tar
mv cni cni_bak
mkdir cni/bin -p
tar zxvf cni-plugins-linux-amd64-v1.2.0.tgz -C cni/bin
#查看新的文件
ll cni/bin/
scp kube-flannel.yml master01:/opt/
node01和node02节点操作
#执行 kubeadm join 命令加入群集
#复制master中执行过这个命令的kubeadm init \在node节点操作
kubeadm join 192.168.198.11:6443 --token 41u9qh.bku8bq9t8ibxejxs \
--discovery-token-ca-cert-hash sha256:0f128acf6bec78b03810ea3f6cb5c0bb10da0adeb2bc8a1dcffe385a12bb3293
在master节点操作
#在master节点查看节点状态
kubectl get nodes
#在 master 节点创建 flannel 资源
kubectl apply -f kube-flannel.yml
#再次查看节点状态
kubectl get nodes
kubectl get pods -n kube-system
kubectl get pods -n kube-flannel
如执行kubectl get pods -n kube-flannel发现有不是running或者查看节点状态 kubectl get
nodes出现NoReady解决方法:查看所有的机器防火墙等是否关闭
执行:
删除再次生成
kubectl delete -f kube-flannel.yml
kubectl apply -f kube-flannel.yml
执行后需等待可再次查看状态
kubectl get pods -n kube-flannel
(3)测试创建 pod 资源
在master节点操作
#创建 pod 资源创建
kubectl create deployment nginx --image=nginx
#查看创建的资源,需等待
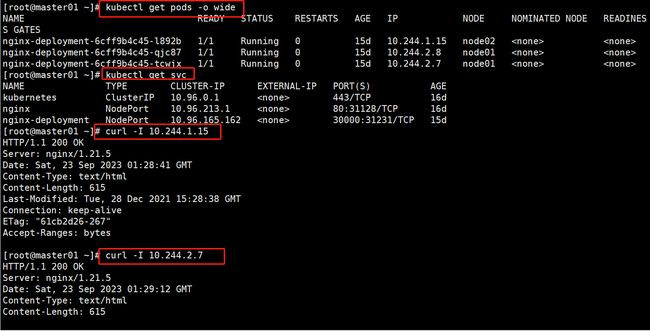
kubectl get pods -o wide

#暴露端口提供服务
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get svc
或kubectl get service
curl -I 10.244.1.15
curl -I 10.244.2.7
#扩展3个副本
kubectl scale deployment nginx --replicas=3
kubectl get pods -o wide

二.创建两个自主式的Pod资源
要求在 Kubernetes 环境中,通过yaml文件的方式,创建2个Nginx Pod分别放置在两个不同的节点上,Pod使用hostPath类型的存储卷挂载,节点本地目录共享使用 /data,2个Pod副本测试页面二者要不同,以做区分,测试页面可自己定义。
①空跑生成nginx的yaml模板文件
kubectl run mynginx --image=nginx:1.14 --port=80 --dry-run=client -o yaml > mynginx.yaml
②进入模板修改
vim mynginx.yaml
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: mcl-nginx #pod的标签
name: mcl-nginx01
spec:
nodeName: node01 #指定该pod调度到node01节点
containers:
- image: nginx:1.14
name: mynginx
ports:
- containerPort: 80 #定义容器的端口
volumeMounts: #挂载存储卷
- name: page01 #名称需要与下方定义的存储卷的名称一致
mountPath: /usr/share/nginx/html #容器中的挂载点,设置为nginx服务的网页根目录
readOnly: false #可读可写
volumes: #定义一个存储卷
- name: page01 #存储卷的名称
hostPath: #存储卷的类型为 hostPath
path: /data #node节点的共享目录
type: DirectoryOrCreate #该类型表示如果共享目录不存在,则系统会自动创建该目录
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: mcl-nginx #pod的标签
name: mcl-nginx02
spec:
nodeName: node02 #指定该pod调度到node02节点
containers:
- name: mynginx
image: nginx:1.14
ports:
- containerPort: 80 #定义容器的端口
volumeMounts: #挂载存储卷
- name: page02 #名称需要与下方定义的存储卷的名称一致
mountPath: /usr/share/nginx/html #容器中的挂载点
readOnly: false
volumes: #定义一个存储卷
- name: page02 #存储卷的名称
hostPath: #存储卷类型为 hostPath
path: /data #node节点的共享目录
type: DirectoryOrCreate #该类型表示如果共享目录不存在,则系统会自动创建该目录
#使用yaml文件创建自主式Pod资源
kubectl apply -f mynginx.yaml
#查看创建的两个pod,被调度到了不同的node节点
kubectl get pods -owide

③两个node节点的存储卷,写入不同的html文件内容,验证访问网页
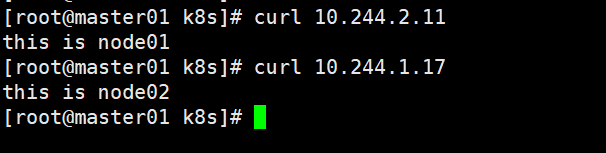
#node01节点
echo "this is node01" > /data/index.html
#node02节点
echo "this is node02 " > /data/index.html
#master节点
curl 10.244.2.11 #访问Node01节点的Pod的IP
curl 10.244.1.17 #访问Node02节点的Pod的IP
三.创建service资源
编写service对应的yaml文件,使用NodePort类型和TCP 30000端口将Nginx服务发布出去。
①编写service对应的yaml文件
vim myservice.yaml
apiVersion: v1
kind: Service
metadata:
name: mcl-nginx-svc
namespace: default
spec:
type: NodePort #service类型设置为NodePort
ports:
- port: 80 #service使用的端口号,ClusterIP后面跟的端口号。
targetPort: 80 #需要转发到的后端Pod的端口号
nodePort: 30000 #指定映射到物理机的端口号,k8s集群外部可以使用nodeIP:nodePort访问service
selector:
app: mcl-nginx #标签选择器要和上一步创建的pod的标签保持一致
#创建service资源
kubectl apply -f myservice.yaml
②查看service资源
kubectl get svc

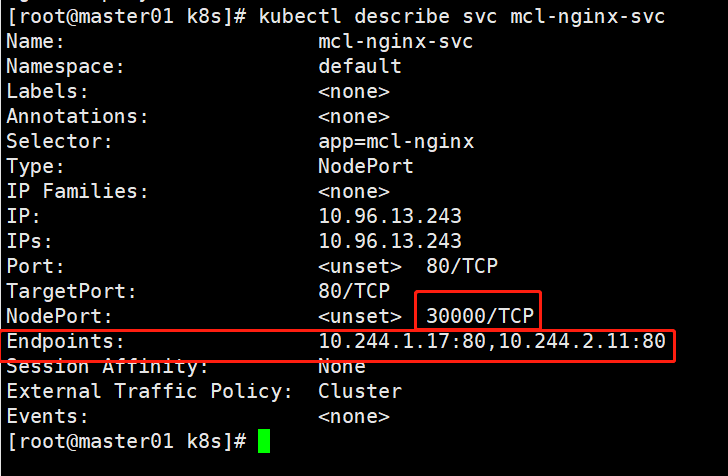
#查看service资源的详细信息
kubectl describe svc yuji-nginx-svc
③测试使用nodeIP:nodePort访问nginx网页
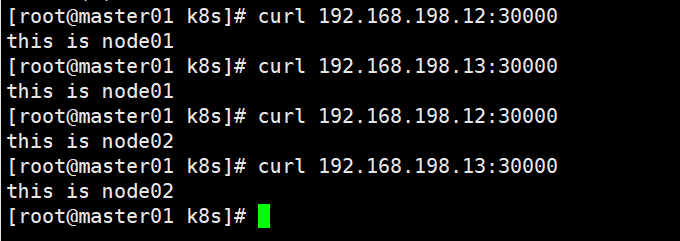
curl 192.168.198.12:30000 #node01
curl 192.168.198.13:30000 #node02
四、搭建负载均衡层
负载均衡区域配置Keepalived+Nginx,实现负载均衡高可用,通过VIP 192.168.198.100和自定义的端口号即可访问K8S发布出来的服务。
1.两台负载均衡器配置nginx(lb01、lb02)
①配置准备
#关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#设置主机名
hostnamectl set-hostname lb01
su
hostnamectl set-hostname lb02
su
#配置nginx的官方在线yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y
#修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台node的节点ip和30000端口
vim /etc/nginx/nginx.conf
events {
worker_connections 1024;
}
#在http块上方,添加stream块
stream {
upstream k8s-nodes {
server 192.168.198.12:30000; #node01IP:nodePort
server 192.168.198.13:30000; #node02IP:nodePort
}
server {
listen 3344; #自定义监听端口
proxy_pass k8s-nodes;
}
}
http {
......
#include /etc/nginx/conf.d/*.conf; #建议将这一行注释掉,否则会同时加载/etc/nginx/conf.d/default.conf文件中的内容,nginx会同时监听80端口。
}
#检查配置文件语法是否正确
nginx -t
#启动nginx服务,查看到已监听3344端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx


2.两台负载均衡器配置keepalived(lb01、lb02)
#安装keepalived服务
yum install keepalived -y
#修改keepalived配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
# 接收邮件地址
notification_email {
[email protected]
[email protected]
[email protected]
}
# 邮件发送地址
notification_email_from [email protected]
smtp_server 127.0.0.1 #修改为本机回环地址
smtp_connect_timeout 30
router_id LB01 #lb01节点的为LB01,lb02节点的为LB02
}
#添加一个周期性执行的脚本
vrrp_script check_nginx {
script "/etc/nginx/check_nginx.sh" #指定检查nginx存活的脚本路径
}
vrrp_instance VI_1 {
state MASTER #lb01节点的为 MASTER,lb02节点的为 BACKUP
interface ens33 #指定网卡名称 ens33
virtual_router_id 51 #指定组ID,两个节点要一致
priority 100 #设置优先级,lb01节点设置为 100,lb02节点设置为 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.198.100 #指定VIP地址
}
}
track_script { #追踪脚本
check_nginx #指定vrrp_script配置的脚本
}
}
#将配置文件中剩余的内容全都删除
#主调度器lb01创建nginx状态检查脚本
vim /etc/nginx/check_nginx.sh
#!/bin/bash
#egrep -cv "grep|$$" 用于过滤掉包含grep 或者 $$ 表示的当前Shell进程ID
count=$(ps -ef | grep nginx | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
systemctl stop keepalived
fi
chmod +x /etc/nginx/check_nginx.sh #为脚本增加执行权限
#启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务,否则keepalived检测到nginx没有启动,会杀死自己)
systemctl start keepalived
systemctl enable keepalived
ip addr #查看主节点的VIP是否生成
#测试使用VIP:3344访问web网页
curl 192.168.198.100:3344

3.关闭主调度器的nginx服务,模拟故障,测试keepalived
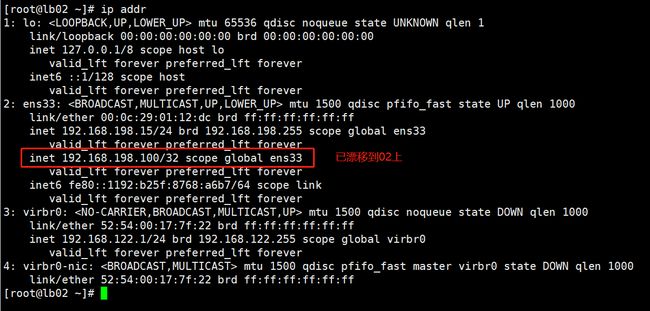
#关闭主调度器lb01的Nginx服务,模拟宕机,观察VIP是否漂移到备节点
systemctl stop nginx
systemctl stop keepalived
systemctl status keepalived #此时keepalived被脚本杀掉了
ip addr
#备节点查看是否生成了VIP
ip addr #此时VIP漂移到备节点lb02

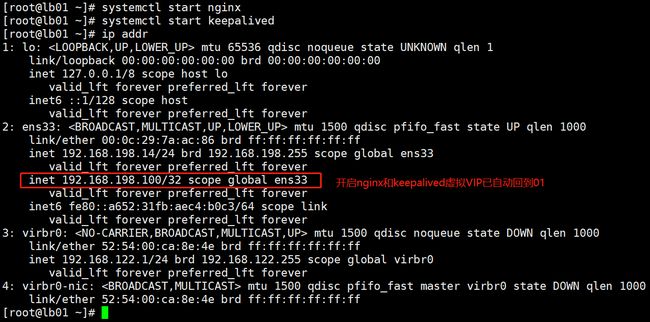
#恢复主节点
systemctl start nginx #先启动nginx
systemctl start keepalived #再启动keepalived
ip addr
五、配置防火墙服务器(test6)
iptables防火墙服务器,设置双网卡,并且配置SNAT和DNAT转换实现外网客户端可以通过12.0.0.1访问内网的Web服务。提前新建一张网卡,
内网网卡ens33:192.168.198.16
外网网卡ens37:12.0.0.1
1.两台负载均衡器,将网关地址修改为防火墙服务器的内网IP地址(lb01、lb02)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
GATEWAY=192.168.198.16 #防火墙的内网本身IP地址
systemctl restart network #重启网络
systemctl restart keepalived #如果VIP丢失,需要重启一下keepalived
2.配置防火墙服务器(test6:192.168.198.16)
(1)关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
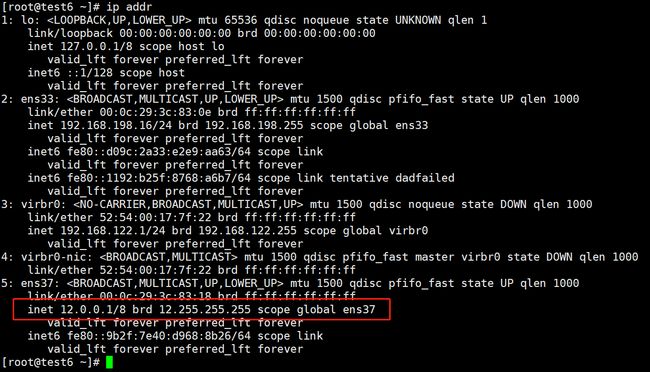
(2)配置客户端地址外网
#添加一个网络适配器ens37网络模式NAT默认即可
cp /etc/sysconfig/network-scripts/ifcfg-ens33 /etc/sysconfig/network-scripts/ifcfg-ens37
vim /etc/sysconfig/network-scripts/ifcfg-ens37
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens37
DEVICE=ens37
ONBOOT=yes
IPADDR=12.0.0.1
NETWASK=255.255.255.0
#下面的网关和DNS注释
systemctl restart network
#如果重启network报错,可以将配置里面的UUID注释
(2)开启路由转发功能
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1 //在文件中增加这一行,开启路由转发功能
sysctl -p //加载修改后的配置

(3)配置iptables策略
#先将原有的规则清除
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#设置SNAT服务,解析源地址。修改nat表中的POSTROUTING链。
#将源地址192.168.198.100转换为为12.0.0.1
iptables -t nat -A POSTROUTING -s 192.168.198.100/24 -j SNAT --to 12.0.0.1
#-t nat //指定nat表
#-A POSTROUTING //在POSTROUTING链中添加规则
#-s 192.168.160.100/24 //数据包的源地址
#-o ens36 //出站网卡
#-j SNAT --to 12.0.0.1 //使用SNAT服务,将源地址转换成公网IP地址。
#设置DNAT服务,解析目的地址。修改nat表中的PRETROUTING链。
#将目的地址12.0.0.1:3344 转换成 192.168.198.100:3344
iptables -t nat -A PREROUTING -d 12.0.0.1 -p tcp --dport 3344 -j DNAT --to 192.168.198.100:3344
#-A PREROUTING //在PREROUTING链中添加规则
#-i ens36 //入站网卡
#-d 12.0.0.254 //数据包的目的地址
#-p tcp --dport 3344 //数据包的目的端口
#-j DNAT --to 192.168.198.100:3344 //使用DNAT功能,将目的地址和端口转换成192.168.198.100:3344
iptables -t nat -nL #查看策略
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 12.0.0.1 tcp dpt:3344 to:192.168.198.100:3344
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
SNAT all -- 192.168.198.0/24 0.0.0.0/0 to:12.0.0.1
六.客户端机器配置(test7)
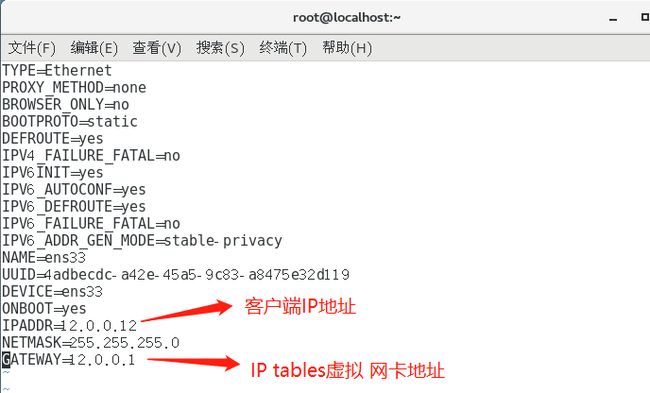
##客户端修改网关配置文件,测试访问内网的Web服务
客户端IP地址:12.0.0.12,将网关地址设置为防火墙服务器的外网网卡地址:12.0.0.1
浏览器输入 http://12.0.0.1:3344 进行访问
systemctl stop firewalld
setenforce 0
vim /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
curl 12.0.0.1:3344
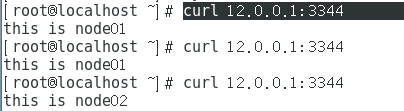
http://12.0.0.1:3344/


排错思路
搭建K8S和Keepalived+Nginx后先试试互相是否通信,如果通就是防火墙那台的策略等问题
防火墙配置中需要注意添加的那台网卡的地址是配置SNAT和DNAT转换实现外网客户端可以通过的地址,在配置之前需要将防火墙地址在lb01、lb02上的网关设置
客户端配置网卡是指定的网址,网关是配置SNAT和DNAT转换实现外网客户端可以通过的地址