ClickHouse面向列的数据库管理系统(原理简略理解)
目录
官网
什么是Clickhouse
什么是OLAP
面向列的数据库与面向行的数据库
特点
为什么面向列的数据库在OLAP场景中工作得更好
为什么ClickHouse这么快
真实的处理分析查询
OLAP场景的关键属性
引擎作用
ClickHouse引擎
输入/输出
CPU
官网
https://clickhouse.com/
什么是Clickhouse
ClickHouse®是一个高性能、面向列的SQL数据库管理系统(DBMS),用于在线分析处理(OLAP)。它可以作为开源软件和云服务提供。
什么是OLAP
OLAP方案要求在大型数据集上实时响应,以满足具有以下特征的复杂分析查询:
- 数据集可以是巨大的-数十亿或数万亿行
- 数据是在包含许多列的表中组织的
- 仅选择少数几列来回答任何特定查询
- 结果必须以毫秒或秒为单位返回
面向列的数据库与面向行的数据库
在面向行的DBMS中,数据存储在行中,与行相关的所有值物理上彼此相邻地存储。
在面向列的DBMS中,数据存储在列中,来自相同列的值存储在一起。
特点
1、列式存储:
行式存储的好处:
想查找某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以;但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
列式存储的好处
- 对于列的聚合、计数、求和等统计操作优于行式存储
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重
- 数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间
- 列式存储不支持事务
2、DBMS功能:几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML、,以及配套的各种函数;用户管理及权限管理、数据的备份与恢复
3、多样化引擎:目前包括合并树、日志、接口和其他四大类20多种引擎。
4、高吞吐写入能力:
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类 LSM tree的结构, ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力。
5、数据分区与线程及并行:
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下, 单条 Query 就能利用整机所有 CPU。 极致的并行处理能力,极大的降低了查询延时。
所以, ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务并不是强项。
6、ClickHouse 像很多 OLAP 数据库一样,单表查询速度优于关联查询,而且 ClickHouse的两者差距更为明显。
关联查询:clickhouse会将右表加载到内存。
为什么面向列的数据库在OLAP场景中工作得更好
面向列的数据库更适合OLAP场景:它们在处理大多数查询时至少快100倍。下面详细解释了原因,但事实更容易直观地展示:
面向行的DBMS
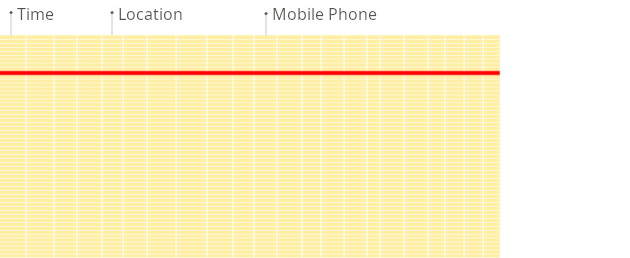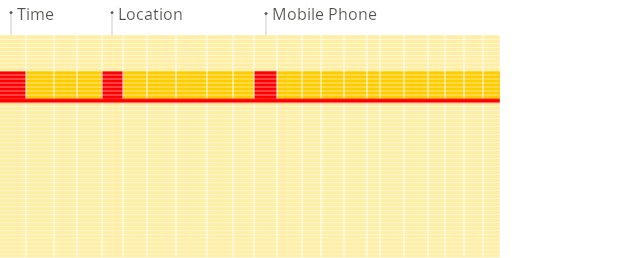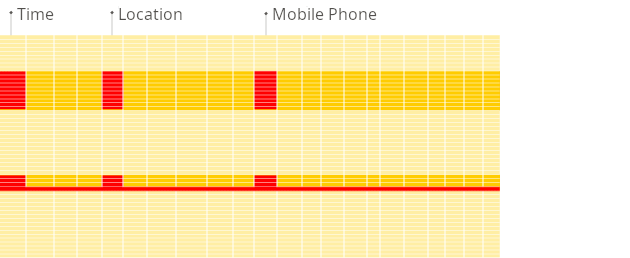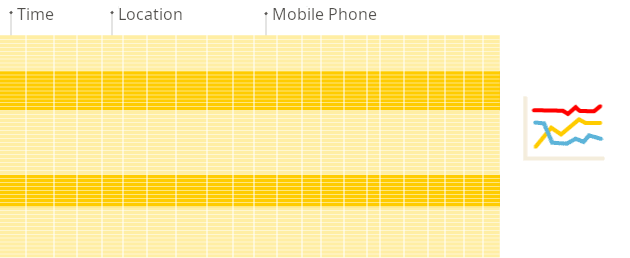
面向列的DBMS
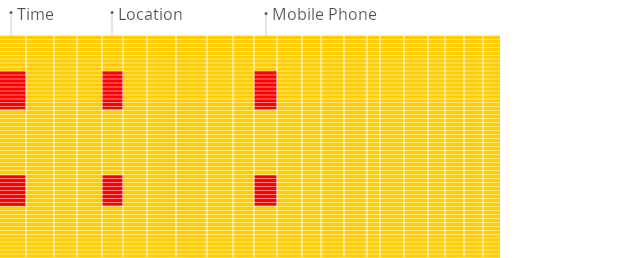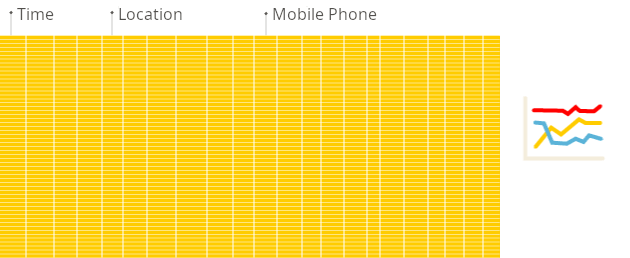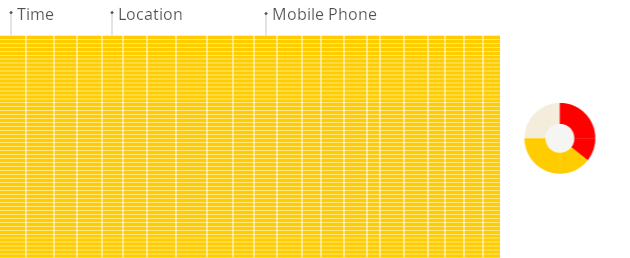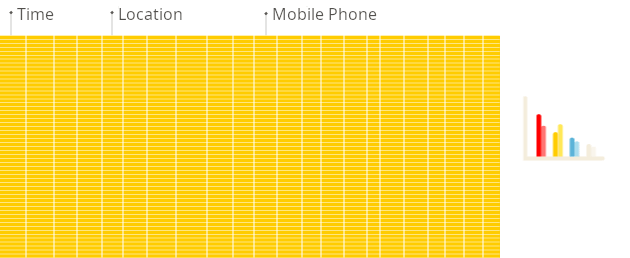
看到区别了吗?
本文的其余部分将解释为什么面向列的数据库在这些场景中工作得很好,以及为什么ClickHouse在这一类别中表现得特别好。
为什么ClickHouse这么快
ClickHouse充分利用所有可用的系统资源,尽可能快地处理每个分析查询。这是由于分析能力和关注实现最快OLAP数据库所需的低级细节的独特组合而成为可能。
- C++可以利用硬件优势
- 摒弃了hadoop生态
- 数据底层以列式存储
- 利用单节点的多核并行处理
- 为数据建立索引一级、二级、稀疏索引
- 使用大量的算法处理数据
- 支持向量化处理
- 预先设计运算模型-预先计算
- 分布式处理数据
真实的处理分析查询
在面向行的DBMS中,数据按以下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
换句话说,与行相关的所有值在物理上彼此相邻地存储。
面向行的DBMS的示例是MySQL、Postgres和MS SQL Server。
在面向列的DBMS中,数据是这样存储的:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
这些示例仅显示数据的排列顺序。不同列中的值单独存储,而同一列中的数据存储在一起。
列式DBMS示例:Vertica、Paraccel(Actian Matrix和Amazon Redshift)、Sybase IQ、Exasol、Infobright、InfiniDB、MonetDB(VectorWise和Actian Vector)、LucidDB、SAP HANA、Google Dremel、Google PowerDrill、Druid和kdb+。
存储数据的不同顺序更适合不同的场景。数据访问场景指的是进行什么查询、多久查询一次、占多大比例;每种类型查询读取的数据量-行、列和字节;阅读和更新数据之间的关系;数据的工作大小以及如何在本地使用它;是否使用事务,以及它们的隔离程度;数据复制和逻辑完整性要求;对于每种类型的查询的等待时间和吞吐量的要求,等等。
系统上的负载越高,定制系统设置以匹配使用场景的需求就越重要,并且这种定制变得越细粒度。没有一个系统同样适合于显著不同的场景。如果一个系统适用于一组广泛的场景,在高负载下,该系统将同样糟糕地处理所有场景,或者将仅对一个或几个可能的场景工作良好。
OLAP场景的关键属性
- 表是“宽”的,这意味着它们包含大量的列。
- 数据集很大,查询在处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)。
- 列值相当小:数字和短字符串(例如,每个URL 60个字节)。
- 查询提取大量的行,但只提取列的一小部分。
- 对于简单查询,允许大约50ms的延迟。
- 每个查询有一个大表;所有的桌子都很小,除了一个。
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合单个服务器的RAM。
- 查询相对较少(通常每台服务器有数百个查询或每秒更少)。
- 插入是以相当大的批量(1000行)进行的,而不是以单行进行的。
- 交易是不必要的。
很容易看出,OLAP场景与其他流行场景(如OLTP或键值访问)有很大不同。因此,如果您想获得良好的性能,那么尝试使用OLTP或键值数据库来处理分析查询是没有意义的。例如,如果您尝试使用MongoDB或Redis进行分析,与OLAP数据库相比,您将获得非常差的性能。
引擎作用
表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以执行多线性请求
- 数据复制参数
ClickHouse引擎
引擎决定了数据的存储位置、存储结构、表的特征(是否修改操作DDL、DDL、是否支持并发操作)
1、数据库引擎:数据库引擎 | ClickHouse文档
目前支持的数据库引擎有5种:
- Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引擎。
- Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表
- Memory:内存引擎,用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除
- Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎
- MySQL:MySQL引擎,将远程的MySQL服务器中的表映射到ClickHouse中,常用语数据的合并。
- MaterializeMySQL:MySQL数据同步;将MySQL数据全量或增量方式同步到clickhouse中,解决mysql服务并发访问压力过大的问题
2、表引擎:表引擎 | ClickHouse文档

输入/输出
- 对于分析查询,只需要读取少量的表列。在面向列的数据库中,可以只读取所需的数据。例如,如果您需要100列中的5列,则可以预期I/O减少20倍。
- 由于数据是以包的形式读取的,因此更容易压缩。列中的数据也更容易压缩。这进一步减少了I/O量。
- 由于减少了I/O,系统缓存中可以容纳更多数据。
例如,查询“统计每个广告平台的记录数”需要阅读一个“广告平台ID”列,该列未压缩时占用1个字节。如果大部分流量不是来自广告平台,那么您可以预期此列的压缩至少为10倍。当使用快速压缩算法时,数据解压缩可以以每秒至少几千兆字节的未压缩数据的速度进行。换句话说,在单个服务器上可以以每秒大约几十亿行的速度处理该查询。这个速度在实践中实际上是可以实现的。
CPU
由于执行查询需要处理大量的行,因此将所有操作分派给整个向量而不是单独的行,或者实现查询引擎,以便几乎没有分派成本。如果不这样做,那么对于任何不太好的磁盘子系统,查询解释器都不可避免地会使CPU停止工作。将数据存储在列中并在可能的情况下按列处理数据是有意义的。
有两种方法可以做到这一点:
-
矢量引擎。所有操作都是针对向量而不是针对单独的值编写的。这意味着您不需要经常调用操作,并且调度成本可以忽略不计。操作代码包含优化的内部循环。
-
代码生成。为查询生成的代码中包含所有间接调用。
这在面向行的数据库中是不可能的,因为在运行简单查询时这是没有意义的。然而,也有例外。例如,MemSQL使用代码生成来减少处理SQL查询时的延迟。(For相比之下,分析型DBMS需要优化吞吐量,而不是延迟。)
请注意,为了提高CPU效率,查询语言必须是声明性的(SQL或MDX),或者至少是向量(J,K)。查询应该只包含隐式循环,以便进行优化。