ceph 代码分析 读_BlueStore源码分析之BlockDevice
前言
Ceph新的存储引擎BlueStore已成为默认的存储引擎,抛弃了对传统文件系统的依赖,直接管理裸设备,通过Libaio的方式进行读写。抽象出了BlockDevice基类,提供统一的操作接口,后端对应不同的设备类型的实现(Kernel、NVME、NVRAM)等。除此之外,还引入了支持NVME的spdk,完全通过用户态操作NVME磁盘,提升IOPS缩短延迟。目前Ceph进一步的工作计划是基于SeaStore(基于seastar的框架)来重构OSD,相信性能会有质的飞跃。
目录
- 数据结构
- 初始化设备
- 同步IO
- 异步IO
- Sync
- Discard
数据结构
目前线上环境大多数还是使用HDD和Sata SSD,其派生的类为KernelDevice:
class KernelDevice : public BlockDevice {
// 裸设备以direct、buffered两种方式打开的fd
int fd_direct, fd_buffered;
// 设备总大小
uint64_t size;
// 块大小
uint64_t block_size;
// 设备路径
std::string path;
// 是否启用Libaio
bool aio, dio;
// interval_set是offset+length
// discard_queued 存放需要做Discard的Extent。
interval_set discard_queued;
// discard_finishing 和 discard_queued 交换值,存放完成Discard的Extent
interval_set discard_finishing;
// Libaio线程,收割完成的事件
struct AioCompletionThread : public Thread {
KernelDevice *bdev;
explicit AioCompletionThread(KernelDevice *b) : bdev(b) {}
void *entry() override {
bdev->_aio_thread();
return NULL;
}
} aio_thread;
// Discard线程,用于SSD的Trim
struct DiscardThread : public Thread {
KernelDevice *bdev;
explicit DiscardThread(KernelDevice *b) : bdev(b) {}
void *entry() override {
bdev->_discard_thread();
return NULL;
}
} discard_thread;
// 同步IO
int read(uint64_t off, uint64_t len, bufferlist *pbl, IOContext *ioc,
bool buffered) override;
int write(uint64_t off, bufferlist &bl, bool buffered) override;
// 异步IO
int aio_read(uint64_t off, uint64_t len, bufferlist *pbl,
IOContext *ioc) override;
int aio_read(uint64_t off, uint64_t len, bufferlist *pbl,
IOContext *ioc) override;
void aio_submit(IOContext *ioc) override;
// sync数据
int flush() override;
// 对SSD指定offset、len的数据做Trim
int discard(uint64_t offset, uint64_t len) override;
};
初始化设备
BlueFS会使用BlockDevice存放RocksDB的WAL以及SStable,同样BlueStore也会使用BlockDevice来存放对象的数据。创建的时候根据不同的设备类型然后创建不同的设备。
BlockDevice *BlockDevice::create(CephContext* cct, const string& path,
aio_callback_t cb, void *cbpriv) {
string type = "kernel";
char buf[PATH_MAX + 1];
int r = ::readlink(path.c_str(), buf, sizeof(buf) - 1);
if (r >= 0) {
buf[r] = '0';
char *bname = ::basename(buf);
if (strncmp(bname, SPDK_PREFIX, sizeof(SPDK_PREFIX)-1) == 0)
type = "ust-nvme";
}
......
if (type == "pmem") {
return new PMEMDevice(cct, cb, cbpriv);
}
......
if (type == "kernel") {
return new KernelDevice(cct, cb, cbpriv); // kernel
}
......
if (type == "ust-nvme") {
return new NVMEDevice(cct, cb, cbpriv); // nvme
}
......
}
设备创建完成之后,需要对设备进行打开并初始化。
int KernelDevice::open(const string& p)
{
fd_direct = ::open(path.c_str(), O_RDWR | O_DIRECT);
fd_buffered = ::open(path.c_str(), O_RDWR);
block_size = cct->_conf->bdev_block_size;
......
r = _aio_start();
......
}
此时设备以及可以进行IO;设备的空间管理以及使用由BlueFS和BlueStore决定,BlockDevice仅仅提供同步IO和异步IO的操作接口。
同步IO
read会调用pread进行数据读取,比较简单,不做分析。write会调用_sync_write进行同步写入。
关于sync分析的文章可见:浅谈分布式存储之sync详解
int KernelDevice::_sync_write(uint64_t off, bufferlist &bl, bool buffered) {
uint64_t len = bl.length();
vector iov;
bl.prepare_iov(&iov);
// 调用pwritev写入PageCache
int r = ::pwritev(buffered ? fd_buffered : fd_direct, &iov[0], iov.size(), off);
if (buffered) {
// initiate IO (but do not wait)
// 仅仅加 SYNC_FILE_RANGE_WRITE 并不会保证数据落到磁盘上。
// 新版本已经改成使用 3个参数了,强制数据落盘才返回。
// r = ::sync_file_range(fd_buffereds, off, len, SYNC_FILE_RANGE_WRITE|SYNC_FILE_RANGE_WAIT_AFTER|SYNC_FILE_RANGE_WAIT_BEFORE);
r = ::sync_file_range(fd_buffered, off, len, SYNC_FILE_RANGE_WRITE);
}
io_since_flush.store(true);
}
异步IO
BlueStore通过Libaio来实现异步IO,而其通常使用的IO模式也是异步IO。前面的BlueStore源码分析之架构设计文章分析过写我们通常是异步写,但是所有的读操作都是同步的,也就是除非命中缓存,否则必须从磁盘上读到指定的数据才能返回。但是这往往也是制约着读的性能,而基于BlockDevice提供的异步读的接口,我们上层可以相对容易的实现异步读,从而提升读的性能。
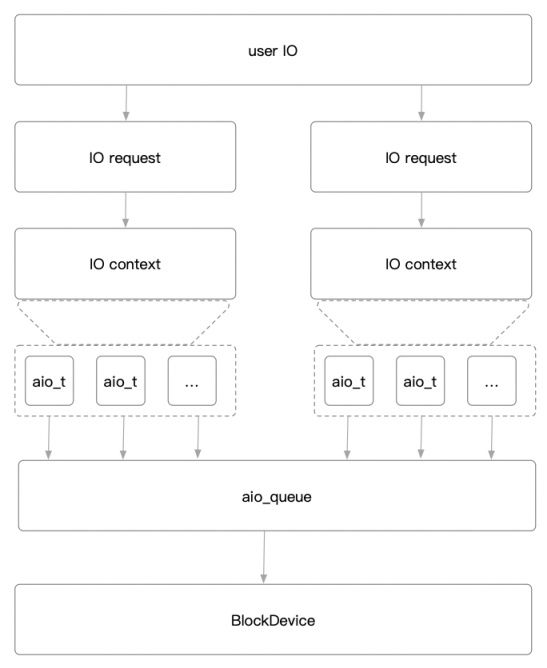
AIO架构
我们需要看四个数据结构:aio_t、IOContext、aio_queue_t、BlockDevice。
- aio_t:封装了Libaio的操作,IO的最小结构体。
- IOContext:每个IO请求都会生成一个IO上下文,里面包含多个aio_t。
- aio_queue_t:用于初始化、提交、收割IO,一个裸设备一个aio队列。
- BlockDevice:裸设备对应结构体,aio队列会提交IO到裸设备。
struct aio_t {
// libaio 相关结构体
struct iocb iocb;
......
void pwritev(uint64_t _offset, uint64_t len);
void pwritev(uint64_t _offset, uint64_t len);
......
};
struct IOContext {
public:
void *priv;
// 待执行的aio
std::list pending_aios;
// 正在执行的aio
std::list running_aios;
};
struct aio_queue_t {
// libaio max io depth
int max_iodepth;
// libaio io_context
io_context_t ctx;
int init();
void shutdown();
// 提交IO
int submit_batch(aio_iter begin, aio_iter end, uint16_t aios_size,
void *priv, int *retries);
// 收割完成的IO
int get_next_completed(int timeout_ms, aio_t **paio, int max);
}
class BlockDevice {
typedef void (*aio_callback_t)(void *handle, void *aio);
......
// 参考KernelDevice
......
}
AIO读写
AIO读写比较简单,实际是在IOContext结构体的成员变量pending_aios中追加了一个和libaio相关的aio_t结构。
写:调用io_prep_pwritev将写的数据放入buf中,此时还在内存,没有写入磁盘。
读:调用io_prep_pread,并开辟一块block对齐的内存,准备读数据,还没有从磁盘读。
提交:准备完读写之后,就需要调用aio_submit提交准备的IO了。
void KernelDevice::aio_submit(IOContext *ioc)
{
......
// 获取pending的aio
list::iterator e = ioc->running_aios.begin();
ioc->running_aios.splice(e, ioc->pending_aios);
......
// 批量提交aio
r = aio_queue.submit_batch(ioc->running_aios.begin(), e,
ioc->num_running.load(), priv, &retries);
}
int aio_queue_t::submit_batch(aio_iter begin, aio_iter end,
uint16_t aios_size, void *priv,
int *retries)
{
......
while (left > 0) {
// 调用libaio相关的api提交io
int r = io_submit(ctx, left, piocb + done);
}
......
}
AIO线程
IO提交之后就可以返回了,BlueStore起了一个单独的线程检查IO的完成情况,当真正完成的时候,执行回调函数通知调用方。
void KernelDevice::_aio_thread()
{
......
while (!aio_stop) {
// 最终调用libaio的io_getevents api,检查io是否完成。
int r = aio_queue.get_next_completed(cct->_conf->bdev_aio_poll_ms,
aio, max);
// 设置 io_since_flush 为true,等待元数据写完的时候一起做 fdatasync。
io_since_flush.store(true);
if (ioc->priv) {
if (--ioc->num_running == 0) {
aio_callback(aio_callback_priv, ioc->priv); // 执行回调
}
}
}
......
}
int aio_queue_t::get_next_completed(int timeout_ms, aio_t **paio, int max)
{
......
do {
// 调用libaio相关的api,获取已经完成aio请求
r = io_getevents(ctx, 1, max, event, &t);
} while (r == -EINTR);
}
Sync
BlueStore往往采用异步IO,同步数据到磁盘上调用flush函数。
先通过Libaio写入数据,然后在kv_sync_thread里面调用flush函数,把数据和元数据同步到磁盘上。
int KernelDevice::flush() {
// protect flush with a mutex. note that we are not really protecting
// data here. instead, we're ensuring that if any flush() caller
// sees that io_since_flush is true, they block any racing callers
// until the flush is observed. that allows racing threads to be
// calling flush while still ensuring that *any* of them that got an
// aio completion notification will not return before that aio is
// stable on disk: whichever thread sees the flag first will block
// followers until the aio is stable.
// 保证并发性
std::lock_guard l(flush_mutex);
// 如果 io_since_flush 为false,则没有要sync的数据,直接退出
bool expect = true;
if (!io_since_flush.compare_exchange_strong(expect, false)) {
dout(10) << __func__ << " no-op (no ios since last flush), flag is "
<< (int)io_since_flush.load() << dendl;
return 0;
}
// 调用 fdatasync 同步数据到磁盘
......
int r = ::fdatasync(fd_direct);
......
return r;
}
Discard
BlueStore针对SSD的优化之一就是添加了Discard操作。Discard(Trim)的主要作用是提高GC效率以及减小写入放大。具体可参考:浅谈分布式存储之SSD基本原理
KernelDevice会启动一个Discard线程,不断的从discard_queued里面取出Extent,然后做Discard。
Discard线程
void KernelDevice::_discard_thread() {
std::unique_lock l(discard_lock);
......
while (true) {
// 如果没有需要做Discard的Extent就等待
if (discard_queued.empty()) {
if (discard_stop) break;
......
} else {
discard_finishing.swap(discard_queued);
.....
// 对需要做Discard的Extent依次调用discard函数
for (auto p = discard_finishing.begin();
p != discard_finishing.end(); ++p) {
discard(p.get_start(), p.get_len());
}
discard_callback(discard_callback_priv,
static_cast(&discard_finishing));
discard_finishing.clear();
......
}
}
}
Discard函数
int KernelDevice::discard(uint64_t offset, uint64_t len) {
int r = 0;
if (!rotational) {
......
r = block_device_discard(fd_direct, (int64_t)offset, (int64_t)len);
}
return r;
}
int block_device_discard(int fd, int64_t offset, int64_t len)
{
uint64_t range[2] = {(uint64_t)offset, (uint64_t)len};
return ioctl(fd, BLKDISCARD, range);
}
使用时机
由BlueFS和BlueStore在涉及到数据删除的时候调用queue_discard将需要做Discard的Extent传入discard_queued。
int KernelDevice::queue_discard(interval_set &to_release) {
if (rotational) return -1;
if (to_release.empty()) return 0;
std::lock_guard l(discard_lock);
// 插入需要做Discard的Extent
discard_queued.insert(to_release);
discard_cond.notify_all();
return 0;
}
参考资源
- Ceph BlueStore BlockDevice
- 浅谈分布式存储之SSD基本原理
- 浅谈分布式存储之sync详解