Spring注解源码解析三
上一节,我们已经分析了通过注解来配置bean,也就是通过@Coponent注解来配置bean,Spring容器启动时就会到指定的路径下扫描,如果发现某个类上标注了@Component注解,就会像扫描xml中的bean标签一样,将类中的信息封装为BeanDefinition并注册Spring容器中。接下来我们学习通过注解@Configuration和注解@Bean来配置bean。
我们先通过一个案例演示一下:
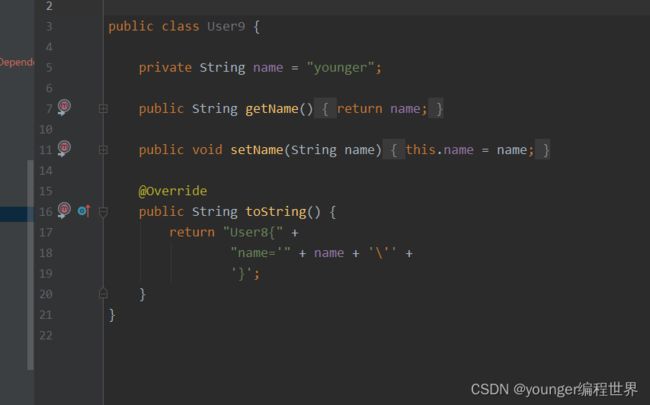
我们创建一个User9的类,接着我们创建一个User9的注解配置类UserConfig:
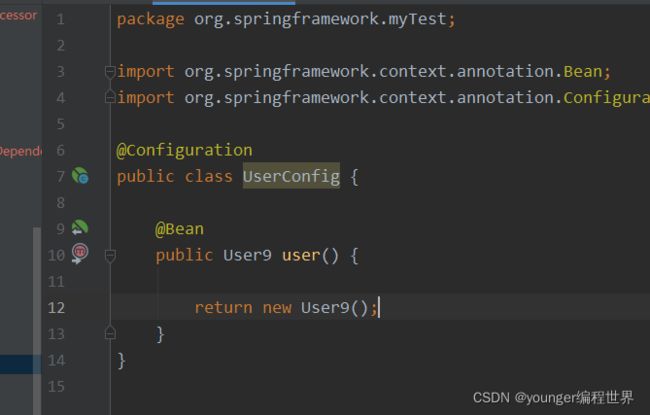
可以看到,在UserConfig类上添加了注解@Configuration,还添加了方法user,在方法user上添加了注解@Bean,然后通过new关键字创建了一个Use9对象并返回。我们可以把添加了注解@Configuration的类,理解为是之前的xml配置文件,而添加了注解@Bean的方法,可以理解为是xml配置文件中的bean标签。我们可以通过注解@Bean在某个方法上面,来配置我们想要的bean,而且,通过添加注解@Bean来配置bean的方式相比于xml而言更加的灵活,因为可以在方法中自定义bean的实例化方式。
我们测试运行一下:
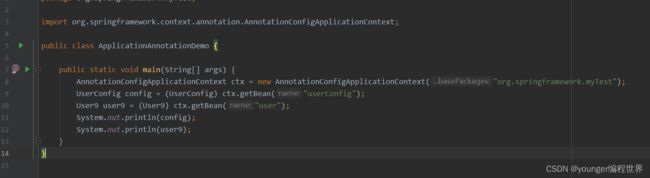
运行结果:

可以看到,添加了注解@Configuration和@Bean相应的bean都加载出来了。我们发现打印的信息,UserConfig类对应的bean的信息后缀中,包含了字符串“EnhancerBySpringCGLIB$$”。我们现在可以知道,Spring底层其实就是通过cglib动态代理的方式,来实例化添加@Configuration注解类的bean的,而注解@Bean标注的方法对应的bean实例,默认是按照我们在方法中实例化bean的方式创建的。为什么这两个注解创建出来的bean实例,会有这么大的不同呢?接下来,我们深入到这两个注解的底层源码来一探究竟。
通过上面的案例我们可以知道,我们依然可以像扫描注解@Component一样,到指定相应的包路径去扫描被注解@Configuration标注的类。那注解@Configuration和注解Component之间有什么关系呢?我们可以到注解@Configuration中看下:
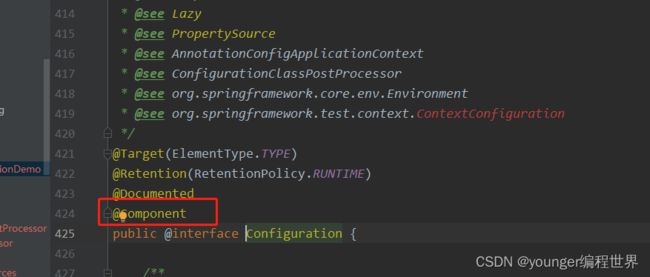
可以看到,注解@Configuration上面也添加了@Component注解,所以添加了注解@Configuration的bean也可以被Spring扫描到,走的其实就是我们上一节分析的逻辑。
我们既然要分析@Configuration,我们就要先找到这块源码的入口,因为这一切都是围绕注解@Configuration展开的,所以,我们可以到注解@Configuration对应的类中看下:
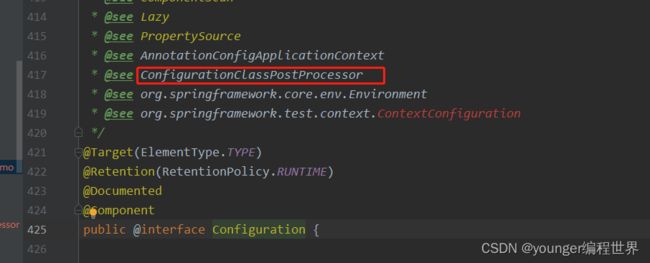
我们发现一个ConfigurationClassPostProcessor类,通过类的名称我们可以知道,它应该和后置处理器是有关系的。我们在之前的源码分析已经知道处理器总共分为工厂级别的后处理器BeanFactoryPostProcessor和Bean的后处理器BeanPostProcessor这两种,这个ConfigurationClassPostProcessor是属于哪一种呢?我们看下ConfigurationClassPostProcessor它的继承关系:
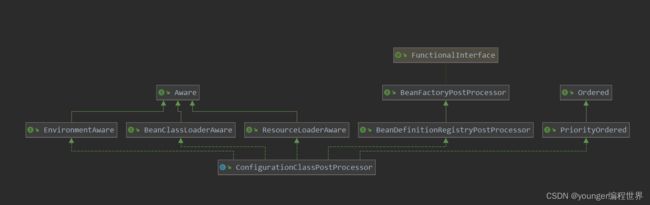
可以看到ConfigurationClassPostProcessor是接口BeanFactoryPostProcessor的实现类,也就是说ConfigurationClassPostProcessor本质上来说就是一个工厂级别的后处理器BeanFactoryPostProcessor。我们发现ConfigurationClassPostProcessor,同时也是实现了接口BeanDefinitionRegistryPostProcessor的,之前我们在分析高级容器ApplicationContext初始化时,已经看到了。如果实现了接口BeanDefinitionRegistryPostProcessor,Spring容器在初始化的refresh方法中,会先执行接口BeanDefinitionRegistryPostProcessor中的postProcessBeanDefinitionRegistry方法,最后统一执行接口BeanFactoryPostProcessor中的postProcessBeanFactory方法。因为ConfigurationClassPostProcessor还实现了接口PriorityOrdered和Ordered,所以在具体执行时,还会根据优先级进行排序。
我们已经知道ConfigurationClassPostProcessor类是什么,并且它是在什么时候执行的,那现在还有一个问题,ConfigurationClassPostProcessor这个工厂后处理器,是在什么时候注册到Spring容器中的呢?还记得我们上一篇分析的AnnotatedBeanDefinitionReader这个类吗? 我们在它的构造方法分时候会执行下面的逻辑:
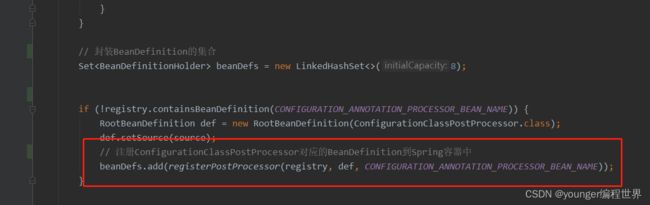
ConfigurationClassPostProcessor类就是在这个时候注入的。
也就是说在Spring容器初始化,首先会执行ConfigurationClassPostProcessor中,接口BeanDefinitionRegistryPostProcessor中的方法postProcessBeanDefinitionRegistry,然后再执行BeanFactoryPostProcessor中的方法postProcessBeanFactory。我们先从ConfigurationClassPostProcessor中接口BeanDefinitionRegistryPostProcessor中的方法postProcessBeanDefinitionRegistry开始入手分析:
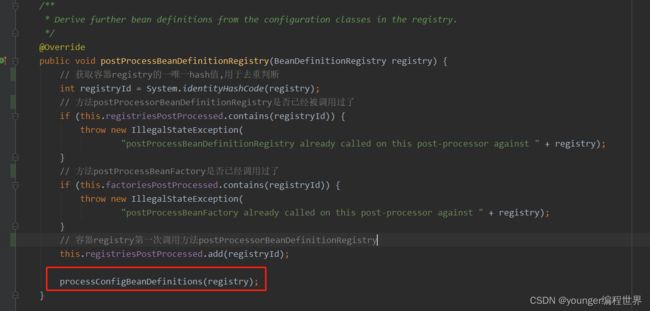
可以看到,方法最开始先通过System的方法identityHashCode,获取容器registry对应的hash code,接下来再判断一下集合registriesPostProcessed以及集合factoriesPostProcessed中是否存在该hash code。其实是在判断方法postProcessBeanDefinitionRegistry和方法postProcessBeanFactory是否已经被执行过了,而这两个集合的作用主要就是用来避免这两个方法被重复执行的。接下来,我们到方法processConfigBeanDefinitions中看下:
/**
* Build and validate a configuration model based on the registry of
* {@link Configuration} classes.
*/
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 存放Spring容器中已经注册的,并且符合候选条件的配置类的BeanDefinitionHolder
List configCandidates = new ArrayList<>();
// 获取Spring容器中,已经注册BeanDefinition的名称
String[] candidateNames = registry.getBeanDefinitionNames();
// 遍历这BeanDefinition的名称
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
//BeanDefinition 中是否存在属性名称为 org.springframework.context.annotation.ConfigurationClassPostProcessor.configurationClass
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
// 检查当前的BeanDefinition 是否满足配置类的候选条件
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
// 如果BeanDefinition满足候选条件,就将BeanDefinition封装到哦BeanDefinitionHolder中同时将 BeanDefinitionHolder 条件到集合 configCandidates
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
// 如果没有符合条件的BeanDefinition就直接返回
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
// 如果这些 BeanDefinition 对应的类上添加了@Order注解,就对它们进行排序,属性值越小优先级越高
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
// 看下Spring容器中是否注册了自定义的bean名称生成策略的组件
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
// Bean名称生成策略的一个组件,默认为空
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
// 初始化环境变量
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
// 解析添加了注解@Configuration的配置类的解析器
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
// 存放符合条件的BeanDefinitionHolder
Set candidates = new LinkedHashSet<>(configCandidates);
// 存放已经解析完毕的 ConfigurationClass
Set alreadyParsed = new HashSet<>(configCandidates.size());
do {
// 解析配置类
parser.parse(candidates);
parser.validate();
// 临时存放candidates 解析完毕后,封装得到的 Configuration 集合
Set configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
// 移除上一轮while循环中,已经解析全部解析处理的元素
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 为解析配置类解析后的configClass 注册新的BeanDefinition,主要就是配置类中,标注了注解@Bean的方法需要注册新的BeanDefinition
this.reader.loadBeanDefinitions(configClasses);
// 将解析完毕的configClass,添加到集合alreadyParsed中
alreadyParsed.addAll(configClasses);
candidates.clear();
// 如果Spring容器中的BeanDefinition数量已经大于之前容器的数量
if (registry.getBeanDefinitionCount() > candidateNames.length) {
// 获取容器当前已经注册的bean的名称集合
String[] newCandidateNames = registry.getBeanDefinitionNames();
// 方法执行前容器中的bean名称集合
Set oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
// 注册解析配置类过程中,新注册的那些bean的名称 比如从添加了注解@Bean上解析来的BeanDefinition
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
// 将这些解析过程中新添加的BeanDefinition作为下一轮while循环中处理的候选类
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
// 如果在解析的过程中,已经解析并注册了名称为org.springframework.context.annotation.ConfigurationClassPostProcessor的单例对象
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
// 清除缓存
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}
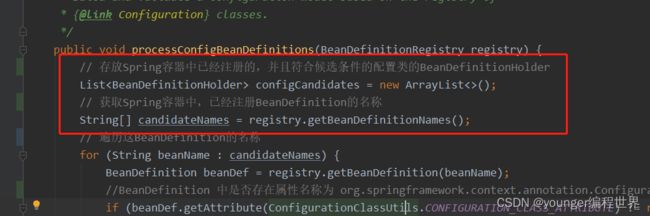
首先通过方法getBeanDefinitionNames,从Spring容器registry中,获取已经注册到Spring容器的BeanDefinition的名称,然后在for循环中遍历这些BeanDefinition。
我们继续往下看:
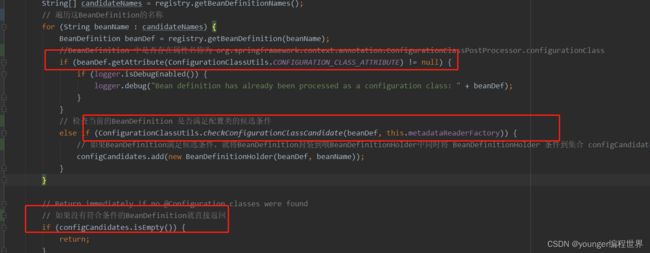
可以看到,在for循环的第一个分支中,如果发现BeanDefinition中不存在属性“org.springframework.context.annotation.ConfigurationClassPostProcessor.configurationClass”的值时,这就意味着注解配置类的BeanDefinition并没有被处理过。第一次执行该方法时,默认是没有这个属性值的,所以接下来就会到else if分支中,通过ConfigurationClassUtils的方法checkConfigurationClassCandidate,看下当前的BeanDefinition是否满足候选条件,也就是判断是否属于添加了注解@Component的注解配置类。为什么要筛选出符合条件的BeanDefinition呢?因为我们在指定路径下,不仅会扫描到添加了注解@Configuration的类,而且也会扫描到其他添加了注解@Component的类。所以方法checkConfigurationClassCandidate中,只会筛选出添加了注解@Configration的注解配置类的BeanDefinition。我们到方法checkConfigurationClassCandidate中看下:
public static boolean checkConfigurationClassCandidate(
BeanDefinition beanDef, MetadataReaderFactory metadataReaderFactory) {
// 获取类的名称
String className = beanDef.getBeanClassName();
//如果类的名称为空或者当前的类已经指定了工厂方法的属性,这个就说明当前BeanDefinition肯定就不是添加了注解@Configuration的配置了
if (className == null || beanDef.getFactoryMethodName() != null) {
// 直接返回,不符合配置类的候选条件
return false;
}
AnnotationMetadata metadata;
// 如果当前 beanDef 是注解类型的,且注解元数据中包含可bean类的全限定类名
if (beanDef instanceof AnnotatedBeanDefinition &&
className.equals(((AnnotatedBeanDefinition) beanDef).getMetadata().getClassName())) {
// Can reuse the pre-parsed metadata from the given BeanDefinition...
// 获取BeanDefinition上注解的元数据信息
metadata = ((AnnotatedBeanDefinition) beanDef).getMetadata();
}
// BeanDefinition 是 AbstractBeanDefinition的实例并且存在类的名称
else if (beanDef instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) beanDef).hasBeanClass()) {
// Check already loaded Class if present...
// since we possibly can't even load the class file for this Class.
Class beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();
/**
* 如果当前要处理 BeanDefinition 是Spring内部组件类 BeanFactoryPostProcessor或
* BeanPostProcessor 或 AopInfrastructureBean 或 EventListenerFactory 此时当然就不符合候选条件了
*/
if (BeanFactoryPostProcessor.class.isAssignableFrom(beanClass) ||
BeanPostProcessor.class.isAssignableFrom(beanClass) ||
AopInfrastructureBean.class.isAssignableFrom(beanClass) ||
EventListenerFactory.class.isAssignableFrom(beanClass)) {
return false;
}
// 将 BeanDefinition 中得到的类名,封装为注解的元数据metadata
metadata = AnnotationMetadata.introspect(beanClass);
}
else {
try {
// 通过 MetadataReader根据类的名称得到注解的元数据
MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);
metadata = metadataReader.getAnnotationMetadata();
}
catch (IOException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Could not find class file for introspecting configuration annotations: " +
className, ex);
}
return false;
}
}
// 从类的注解元数据中,获取注解@Confiuration的元数据配置信息
Map config = metadata.getAnnotationAttributes(Configuration.class.getName());
if (config != null && !Boolean.FALSE.equals(config.get("proxyBeanMethods"))) {
// 如果注解Configuration在的属性 proxyBeanMethods值为true
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);
}
// 判断注解元数据信息是否符合筛选条件
else if (config != null || isConfigurationCandidate(metadata)) {
beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);
}
else {
return false;
}
// It's a full or lite configuration candidate... Let's determine the order value, if any.
// 获取注解中的@Order注解值并设置到BeanDefinition中
Integer order = getOrder(metadata);
if (order != null) {
beanDef.setAttribute(ORDER_ATTRIBUTE, order);
}
return true;
}
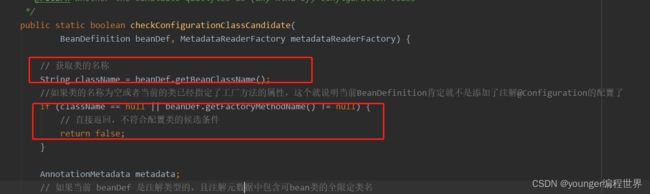
如果BeanDefinition中的类名称都为null,或者当前BeanDefinition中配置了工厂方法。根据我们前面的学习,我们知道配置工厂方法,就意味着当前BeanDefinition定义了实例化对象的逻辑了,所以,在这两种情况下都意味着当前的BeanDefinition,都不符合成为注解配置类BeanDefinition的条件,此时会直接返回false。
我们继续往后看:
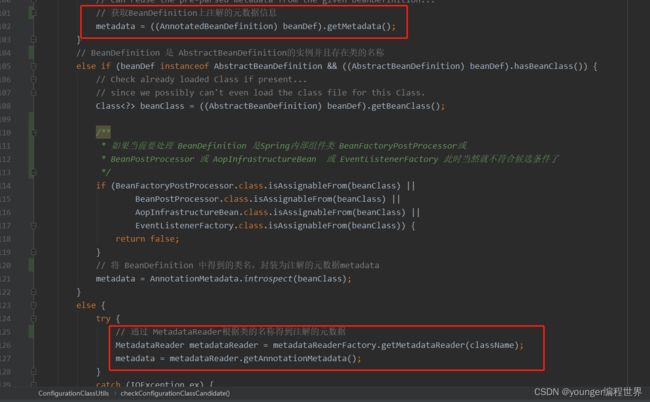
接下来会获取BeanDefinition中,所有注解的元数据metadata,可以看到,不管你当前的BeanDefinition是注解AnnotatedBeanDefinition类型的实例,还是普通的类型AbstractBeanDefinition的实例,最终都要获取到BeanDefinition中所有注解的信息。如果BeanDefinition不是注解类型的,就会通过AnnotationMetadata或MetadataReader来辅助加载注解的元数据metadata,不管怎样,这些逻辑都是在想尽办法来获取注解元数据。我们继续往后看:
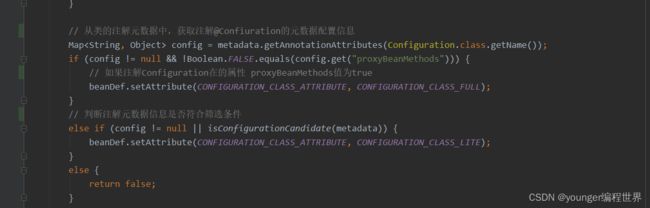
接下来就会从注解元数据中,尝试获取注解@Configuration的信息,并将信息封装在config中。如果config不为空,且注解@Configuration中的属性proxyBeanMethods值为true,此时第一个if分支条件成立,就会将BeanDefinition中将属性“org.springframework.context.annotation.ConfigurationClassPostProcessor.configurationClass”的值设置为CONFIGURATION_CLASS_FULL,也就是“full”。而注解@Configuration中的属性proxyBeanMethods的值,默认就是true,所以,这里默认会将该属性值设置为CONFIGURATION_CLASS_FULL,也就是“full”,最后就是通过getOrder方法,获取注解元数据中注解@Order的属性值,并设置到BeanDefinition中。可以看到,方法checkConfigurationClassCandidate就是通过是否存在@Configuration注解,且该注解中的属性proxyBeanMethods的值是否为默认的true,以此来判断当前的BeanDefinition是符合条件的注解配置类。
获取到了符合条件的注解配置类之后,我们回到方法processConfigBeanDefinitions中:
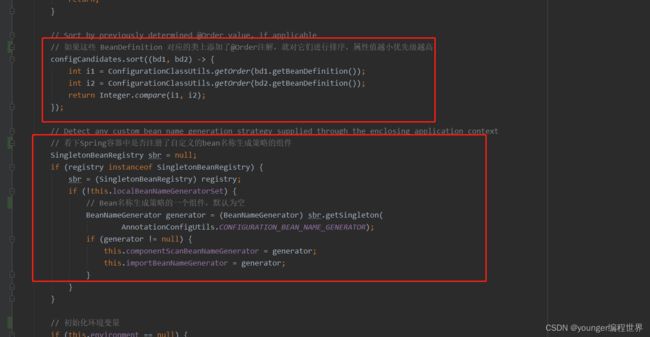
接下来集合configCandidates通过sort方法,对集合内的元素进行一个排序,排序的规则也比较简单,就是通过解析到的注解@Order中的属性值来排序,值越小优先级越大。然后判断registry是否是SingletonBeanRegistry的实例,默认registry是SingletonBeanRegistry的实例,接下来会初始化一个组件BeanNameGenerator,主要负责生成bean的名称,这里默认获取到的generator为null。
我们继续往后看:
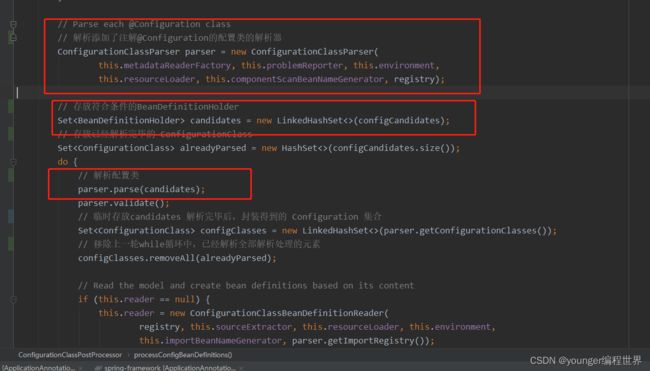
可以看到,这里初始化了一个组件ConfigurationClassParser,根据名称我们可以知道,它应该就是解析注解配置类的一个解析器。我们从接下来的代码可以看到,首先将我们获取到的注解配置类configCandidates,先封装到集合candidates中,然后交给解析器parser解析。
我们到解析器ConfigurationClassParser中的方法parser中看下:
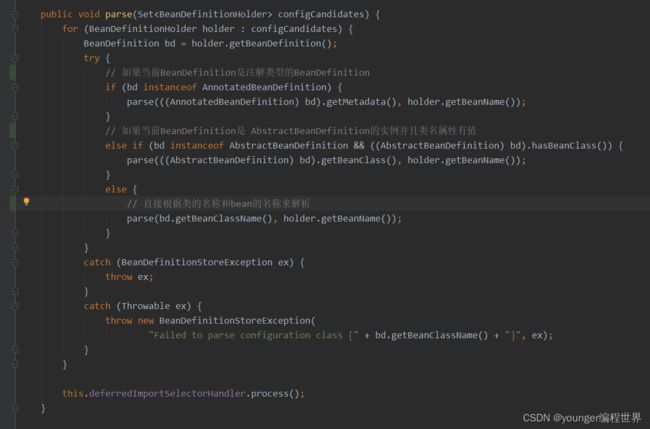
可以看到,方法parser中的逻辑还是挺清晰的,可以看到在if分支中,分别对注解类型的AnnotatedBeanDefinition、普通类型的AbstractBeanDefinition都有相应的解析逻辑。当然,我们这里当然是注解类型的AnnotatedBeanDefinition,所以调用的是第一个if分支中的parse方法,可以看到,接下来会将刚才解析到的注解元数据作为参数,传到parse方法中。我们跟进到方法parse中看下:

在方法parse中,首先将注解元数据metadata以及bean的名称,都封装到了组件ConfigurationClass中,我们继续跟进看下:
protected void processConfigurationClass(ConfigurationClass configClass, Predicate filter) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
// 第一次执行 existingClass是为null的
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
// 对封装好的参数configClass也就是注解配置类上的注解信息进行深度解析
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
// 解析完毕后,将configClass添加到Map configurationClass中
this.configurationClasses.put(configClass, configClass);
}
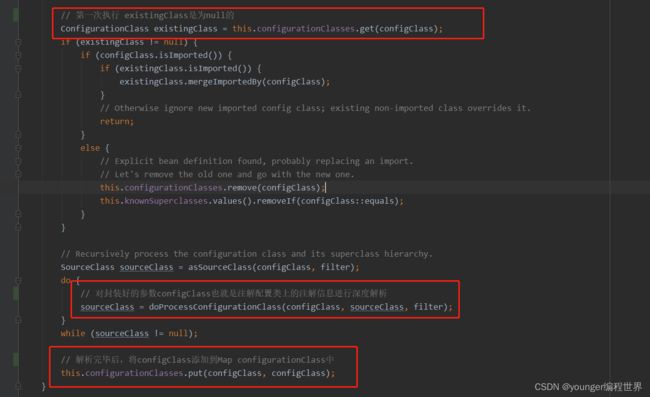
在方法processConfigurationClass中,首选从Map类型的configurationClasses中,根据参数configClass获取value值,初次执行该方法existingClass肯定是为null的。接下来会执行方法doProcessConfigurationClass,对注解配置类信息configClass进行深度的解析,然后将解析完毕的configClass缓存到configurationClasses中。我们可以到方法doProcessConfigurationClass中简单看一下:
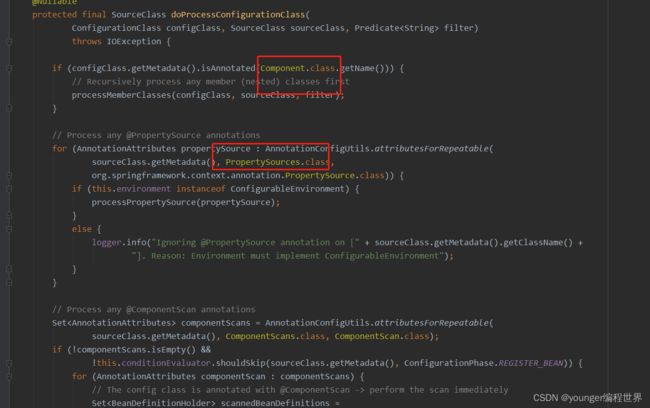
方法doProcessConfigurationClass中的逻辑,主要就是对注解配置类中的各种其他注解进行解析,毕竟添加了注解@Configuration的类当中,可能还会添加其他的注解。比如,在方法doProcessConfigurationClass中会解析注解@PropertySource、@ComponentScans、@ImportResource等。我们继续往后面看:
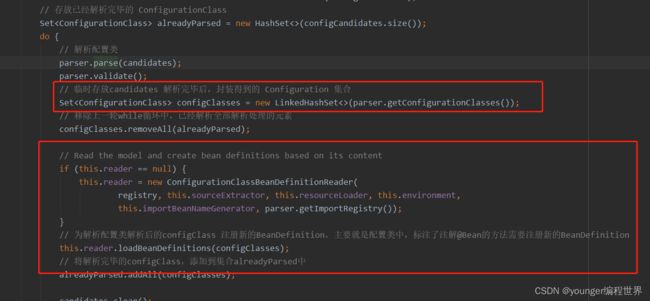
我们可以看到,接下来会获取解析器parser中configurationClasses中的元素,并放到集合configClasses中。同时还初始化了一个组件ConfigurationClassBeanDefinitionReader来解析它们,接下来调用的是reader中的方法loadBeanDefinitions。看到方法loadBeanDefinitions我们就需要想一下,添加了注解@Configuration的类肯定早就已经被扫描到,并封装成BeanDefinition注册到Spring容器中了,那现在还有什么类需要注册BeanDefinition吗?大家可别忘了,添加了注解@Configuration的类,可是相当于一个xml配置文件的,在这个配置类中是可以配置很多其他bean的。比如,我们前面讲过的添加了注解@Bean的方法,这些方法可都是相当于一个个的bean,而这些添加注解@Bean的方法,理应也要注册相应的BeanDefinition,而方法loadBeanDefinitions是不是在为方法注册BeanDefinition呢?我们都到方法loadBeanDefinitions中看下:
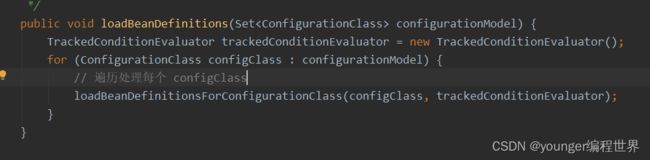
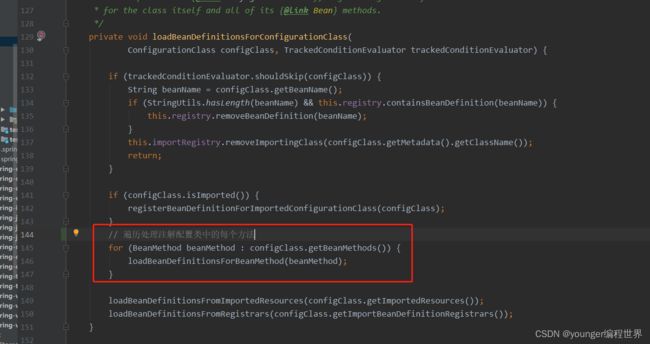
在方法loadBeanDefinitionsForConfigurationClass中,就开始处理注解配置类中的每个方法,我们再到方法loadBeanDefinitionsForBeanMethod中看下:
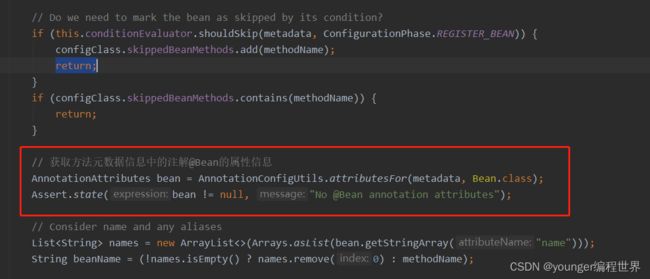
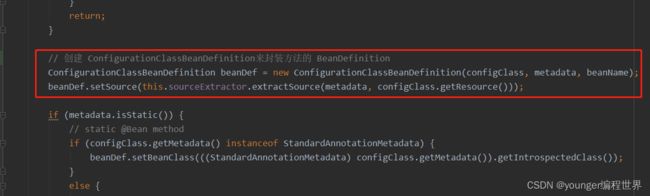

在方法中,和我们前面猜想的一样开始解析方法上的注解@Bean,然后为方法创建一个ConfigurationClassBeanDefinition类型的BeanDefinition。接下来就是为BeanDefinition填充各种各样的属性信息,这些属性大部分我们应该都很熟悉了,最后通过registry将BeanDefinition注入到Spring容器中。
我们们接着往下看:
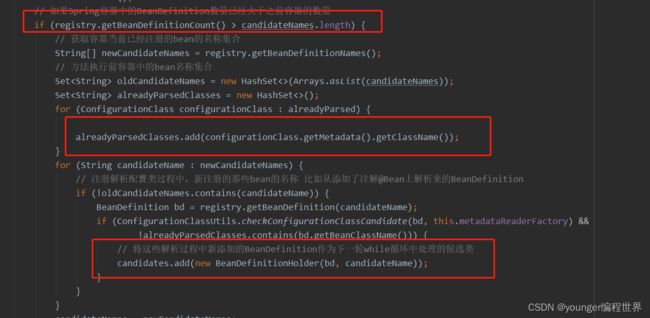
接下来,如果发现当前Spring容器中注册的BeanDefinition数量,大于candidateNames中的数量,candidateNames其实就是当前方法刚执行时,Spring容器中注册BeanDefinition的数量。我们解析了注解配置类之后,又为每个添加了注解@Bean的方法封装了BeanDefinition,此时Spring容器中的BeanDefinition数量,肯定是大于之前容器中BeanDefinition的数量啊,所以,接下来我们看下if分支中的逻辑。可以看到,接下来会将已经解析完毕的configClasses,添加到集合alreadyParsedClasses中,然后在for循环中遍历集合newCandidateNames,也就是当前Spring容器中已经注册的那些BeanDefinition的名称。目的也是很简单,就是想要看下注解@Bean对应的这些方法解析到的BeanDefinition,是否也存在添加了注解@Configuration的注解配置类,如果存在的话,也是需要添加到集合candidates中,准备开始下一轮while循环的解析的,保证不放过任何一个符合候选条件的注解配置类。从while循环的条件中可以发现,直到某一刻candidates为空,也就是没有需要解析处理的注解配置类了,while循环才会退出。我们再来看下最后的一些逻辑:
最后这里也没什么东西,就是注册一些单例对象并且清除一些缓存信息。
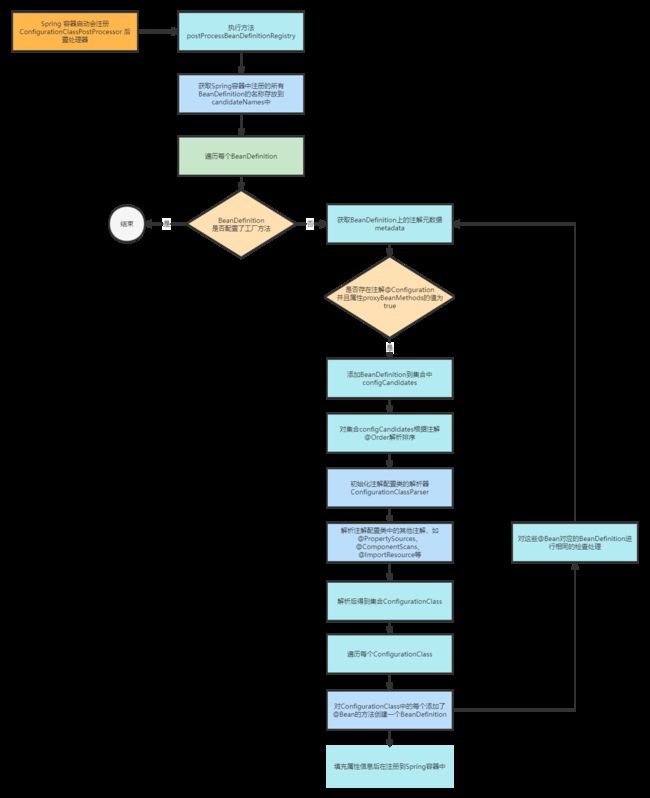
我们通过流程图梳理一下: