Python+大数据-SQL 进阶-窗口函数
Python+大数据-SQL 进阶-窗口函数
1.窗口函数概述
1.1 什么是窗口函数
- 窗口函数是类似于可以返回聚合值的函数,例如SUM(),COUNT(),MAX()。但是窗口函数又与普通的聚合函数不同,它不会对结果进行分组,使得输出中的行数与输入中的行数相同。
- 窗口函数是对表中一组数据进行计算的函数,一组数据跟当前行相关
SELECT SUM() OVER(PARTITION BY ___ ORDER BY___) FROM Table
- 聚合功能:在上述例子中,我们用了SUM(),但是你也可以用COUNT(), AVG()之类的计算功能
- PARTITION BY:你只需将它看成GROUP BY子句,但是在窗口函数中,你要写PARTITION BY
- ORDER BY:ORDER BY和普通查询语句中的ORDER BY没什么不同。注意,输出的顺序要仔细考虑
2. 窗口函数OVER()子句详解
2.1 OVER()基本用法
- over()的意思是所有的数据都在窗口中 (将新增的数据在同一个窗口显示)
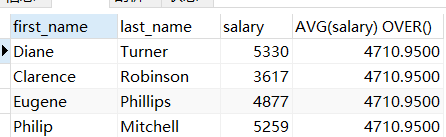
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER()
FROM employee;
-- `AVG(salary)` 意思是要计算平均工资,加上 `OVER()` 意味着对全部数据进行计算,所以就是在计算所有人的平均工资。
- 通常,
OVER()用于将当前行与一个聚合值进行比较
-- 需求:创建报表统计每个员工的工龄和平均工龄之间的差值。
SELECT
first_name,
last_name,
years_worked,
AVG(years_worked) over() as `avg`,
years_worked - AVG(years_worked) over() as `difference`
FROM employee;
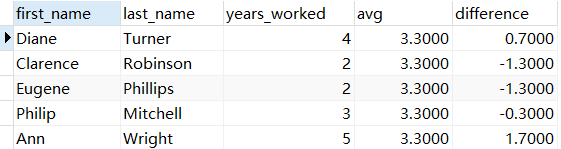
- over()和count()组合
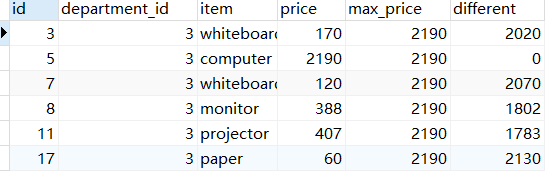
-- 需求:查询人力资源部(`department_id = 3`)的采购情况- 查询如下字段:
-- `id`,`department_id`,`item`,`price`,最高采购金额,最高采购金额和每项采购的金额差值
SELECT
id,
department_id,
item,
price,
MAX(price) over() as 'max_price',
MAX(price) over() - price as 'different'
FROM purchase
WHERE department_id=3;
- 窗口函数在
WHERE子句后执行!
-- 需求:查询部门id为1,2,3三个部门员工的姓名,薪水,和这三个部门员工的平均薪资
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() as avg
FROM employee
WHERE department_id IN (1, 2, 3);

- 小结
- 可以使用
OVER(),对全部查询结果进行聚合计算 - 在WHERE条件执行之后,才会执行窗口函数
- 窗口函数在执行聚合计算的同时还可以保留每行的其它原始信息
- 不能在WHERE子句中使用窗口函数
- 可以使用
2.2 OVER( PARTITION BY )的使用
OVER (PARTITION BY column1, column2 ... column_n)
`PARTITION BY` 的作用与 `GROUP BY`类似:将数据按照传入的列进行分组,与 `GROUP BY` 的区别是, `PARTITION BY` 不会改变结果的行数。
- PARTITION BY与GROUP BY区别
- group by是分组函数,partition by是分析函数
- 在执行顺序上:from > where > group by > having > order by,而partition by应用在以上关键字之后,可以简单理解为就是在执行完select之后,在所得结果集之上进行partition by分组
- partition by相比较于group by,能够在保留全部数据的基础上,只对其中某些字段做分组排序(类似excel中的操作),而group by则只保留参与分组的字段和聚合函数的结果(类似excel中的pivot透视表)
-- 需求:按车型分组,每组中满足一等座>30,二等座>180的有几条记录
SELECT
id,
model,
first_class_places,
second_class_places,
count(id) over(PARTITION BY model) as 'count'
FROM train
WHERE first_class_places>30
AND second_class_places>180;

- PARTITION BY传入多列
-- 需求:查询时刻表中的车次ID,运营车辆的生产日期(`production_year`),同一种车型的车次数量,同一线路的车次数量
SELECT
journey.id,
production_year,
COUNT(journey.id) OVER(PARTITION BY train_id) as count_train,
COUNT(journey.id) OVER (PARTITION BY route_id) as count_journey
FROM journey
JOIN train
ON journey.train_id = train.id;
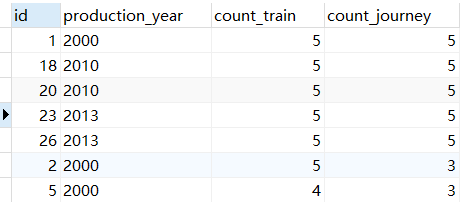
- 小结:
- OVER(PARTITION BY x)的工作方式与GROUP BY类似,将x列中,所有值相同的行分到一组中
- PARTITON BY 后面可以传入一列数据,也可以是多列(需要用逗号隔开列名)
3. 排序函数
OVER (ORDER BY )
`RANK()`会返回每一行的等级(序号)
`ORDER BY`对行进行排序将数据按升序或降序排列
` RANK()OVER(ORDER BY ...)`是一个函数,与`ORDER BY` 配合返回序号
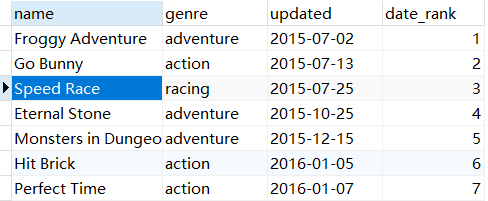
-- 需求:统计每个游戏的名字,分类,更新日期,更新日期序号
SELECT
`name`,
genre,
updated,
RANK() over(ORDER BY updated) as 'date_rank'
FROM game;
- DENSE_RANK()函数 返回 连续序号
-- 对游戏的安装包大小进行排序,使用`DENSE_RANK()`,返回游戏名称,包大小以及序号。
SELECT
`name`,
size,
DENSE_RANK() over(
FROM game;
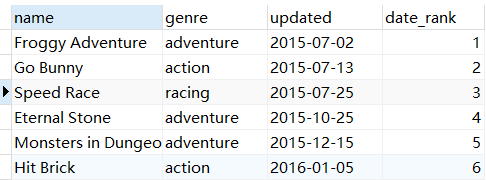
- ROW_NUMBER() 返回连续唯一的行号,与排序
ORDER BY配合返回的是连续不重复的序号
-- 需求:将游戏按发行时间排序,返回唯一序号
-- 需求:对比 `RANK()`, `DENSE_RANK()`, `ROW_NUMBER()` 之间的区别,对上面的案例同时使用三个函数
SELECT
`name`,
genre,
released,
RANK() over(ORDER BY released) as 'rank',
DENSE_RANK() over(ORDER BY released) as 'dense_rank',
ROW_NUMBER() over(ORDER BY released) as 'row_number'
FROM game;

- RANK() – 返回排序后的序号 rank ,有并列的情况出现时序号不连续
- DENSE_RANK() – 返回 连续 序号
- 3.ROW_NUMBER() – 返回连续唯一的行号,与排序
ORDER BY配合返回的是连续不重复的序号
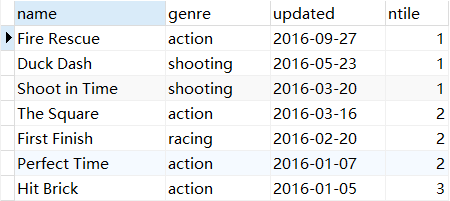
- NTILE(X)
-- 将所有的游戏按照升级日期降序排列分成4组,返回游戏名字,类别,更新日期,和分组序号
SELECT
`name`,
genre,
updated,
NTILE(4) over(ORDER BY updated DESC) as 'ntile'
FROM game;
-- 需求:查询最近更新的游戏中,时间第二近的游戏,返回游戏名称,运行平台,更新时间
WITH ranking AS(
SELECT
`name`,
platform,
updated,
RANK() over(ORDER BY updated DESC) as 'rank'
FROM game
)
SELECT
name,
platform,
updated
FROM ranking
WHERE `rank`=2;

-
小结
-
最基本的排序函数:
RANK() OVER(ORDER BY column1, column2...) -
通过排序获取序号的函数介绍了如下三个:
- RANK() – 返回排序后的序号 rank ,有并列的情况出现时序号不连续
- DENSE_RANK() – 返回 连续 序号
- ROW_NUMBER() – 返回连续唯一的行号,与排序
ORDER BY配合返回的是连续不重复的序号
-
NTILE(x) – 将数据分组,并为每组添加一个相同的序号
-
WITH 获取排序后,指定位置的数据(第一位,第二位)可以通过如下
WITH ranking AS (SELECT RANK() OVER (ORDER BY col2) AS RANK, col1 FROM table_name) SELECT col1 FROM ranking WHERE RANK = place1;
-
4.window frames 自定义窗口
- 窗口框架(Window frames) 可以以当前行为基准,精确的自定义要选取的数据范围(开窗大小)
4.1 ROWS方式
ROWS BETWEEN lower_bound AND upper_bound
- UNBOUNDED PRECEDING – 对上限无限制 (unbounded preceding)
- n PRECEDING – 当前行之前的第 n 行 ( n ,填入具体数字如:5 PRECEDING ) preceding
- CURRENT ROW – 仅当前行 (current row)
- n FOLLOWING –当前行之后的第 n 行 ( n ,填入具体数字如:5 FOLLOWING ) n following
- UNBOUNDED FOLLOWING – 对下限无限制 (unbounded following)
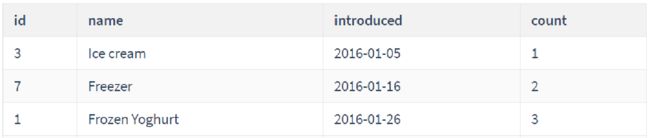
-- 需求:统计每件商品的上架日期,以及截至值该日期,上架商品种类数量
SELECT
id,
name,
introduced,
COUNT(id) OVER(
ORDER BY introduced
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM product;
- window frames 定义的简单写法
ROWS UNBOUNDED PRECEDING 等价于 `BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW`
ROWS n PRECEDING 等价于 `BETWEEN n PRECEDING AND CURRENT ROW`
ROWS CURRENT ROW 等价于 `BETWEEN CURRENT ROW AND CURRENT ROW
4.2 RANGE方式
和使用 `ROWS`一样,使用`RANGE` 一样可以通过 `BETWEEN ... AND...` 来自定义窗口
在使用`RANGE` 时,我们一般用
`RANGE UNBOUNDED PRECEDING`
`RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING`
`RANGE CURRENT ROW`
-
小结
-
我们可以在OVER(…)中定义一个窗口框架。 语法为:
- [ROWS | RANGE]
- ROWS 按行来处理数据(例如ROW_NUMBER()函数)
- RANGE按行值来处理数据(例如RANK()函数)
- [ROWS | RANGE]
-
` 按如下方式定义:
BETWEEN, 其中边界通过以下方式定义:AND - UNBOUNDED PRECEDING`
- n PRECEDING (ROWS only)
- CURRENT ROW
- n FOLLOWING (ROWS only)
- UNBOUNDED FOLLOWING
5. LEAD(X)函数
OVER (...)
与聚类函数不同的地方是,分析函数只引用窗口中的单个行
SELECT
name,
opened,
LEAD(name) OVER(ORDER BY opened)
FROM website;
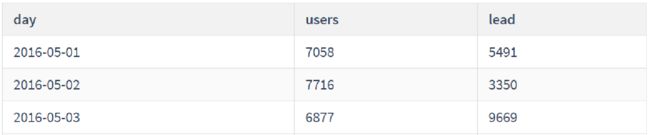
上面的SQL中,分析函数为LEAD(name)。 LEAD中传入name列作为参数,将以 `ORDER BY` 排序后的顺序,返回当前行的下一行`name` 列所对应的值,并在新列中显示,具体如下图所示:
-- 需求: 统计id 为1的网站,每天访问的人数以及下一天访问的人数- 返回字段:`day`日期,`users`访问人数,`lead` 下
-- 一天访问人数
SELECT
day,
users,
LEAD(users) OVER(ORDER BY day) AS `lead`
FROM statistics
WHERE website_id = 1;

5.1LEAD函数传入两个参数LEAD(x,y)
- 参数1 跟传入一个参数时的情况一样:一列的列名
- 参数2 代表了偏移量,如果传入2 就说明要以当前行为基准,向前移动两行作为返回值
-- 需求:统计id为2的网站,在2016年5月1日到5月14日之间,每天的用户访问数量以及7天后的用户访问数量
-- 需要注意,最后7行最后一列会返回NULL,因为最后7行没有7日后的数据。
SELECT
day,
users,
LEAD(users, 7) OVER(ORDER BY day) AS `lead`
FROM statistics
WHERE website_id = 2
AND day BETWEEN '2016-05-01' AND '2016-05-14';
6.LAG(x)函数
-
LAG(x)函数与LEAD(x)用法类似,区别是,LEAD返回当前行后面的值,LAG返回当前行之前的值
-
LEAD(…)
和LAG(…),之间可以互相替换,可以在ORDER BY的时候通过DESC来改变排序方式,使LEAD(…)和LAG(…)`返回相同结果
-- 与LEAD(x,y,z)一样,LAG(x,y,z) 最后一个参数是默认值,用来填补NULL值
-- 统计id = 3的网站每日广告收入以及三天前的广告收入
SELECT
day,
revenue,
LAG(revenue, 3, -1.00) OVER(ORDER BY day)
FROM statistics
WHERE website_id = 3;

7. FIRST_VALUE(x)与LAST_VALUE(x)
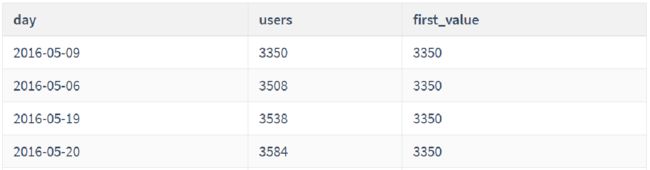
- FISRT_VALUE函数,从名字中能看出,返回指定列的第一个值
-- 需求:统计id为2的网站每天用户访问情况,以及最少用户访问人数。
SELECT
day,
users,
FIRST_VALUE(users) OVER(ORDER BY users) as `first_value`
FROM statistics
WHERE website_id = 2;
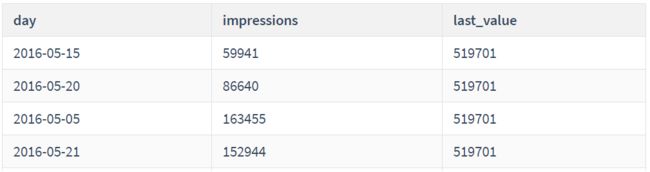
- FIRST_VALUE(x)返回第一个值,LAST_VALUE(x)返回最后一个值
-- 需求:统计id为1的网站的广告展示情况,返回每日日期,广告展示次数,以及访问用户最多的一天广告展示的次数
SELECT
day,
impressions,
LAST_VALUE(impressions) OVER(
ORDER BY users
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) AS `last_value`
FROM statistics
WHERE website_id = 1;
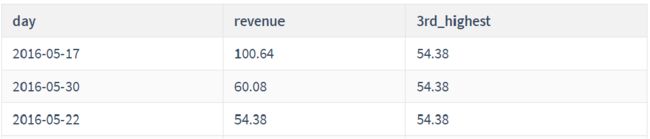
8.NTH_VALUE(x,n)函数
- 需求:NTH_VALUE(x,n) 函数返回 x列,按指定顺序的第n个值
-- 需求:统计id为2的网站的收入情况,在5月15和5月31日之间,每天的收入,以及这半个月内的第三高的日收入金额
SELECT
day,
revenue,
NTH_VALUE(revenue,3) OVER (
ORDER BY revenue DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING) `3rd_highest`
FROM statistics
WHERE website_id = 2
AND day BETWEEN '2016-05-15' AND '2016-05-31';
- 小结
- LEAD(x) 和 LAG(x) 分别返回传入的列x对于当前行的下一行/前一行的值
- LEAD(x,y) 和 LAG(x,y) 分别返回传入的列x对于当前行的后y行/前y行的值
- FIRST_VALUE(x) 和 LAST_VALUE(x) 分别返回列x 的第一个值/最后一个值
- NTH_VALUE(x,n) 返回 x 列的 第n个值
- LAST_VALUE 和 NTH_VALUE 通常要求把window frame修改成 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
9.PARTITION BY 与 ORDER BY
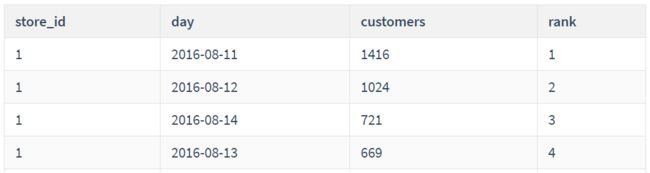
-- 需求:统计2016年8月10日至8月14日之间的销售情况,返回如下字段- `store_id`, `day`,顾客数量`customers`, 每个商店在该--- 段时间内按每日顾客数量排名(降序排列)
SELECT
store_id,
day,
customers,
RANK() OVER (PARTITION BY store_id ORDER BY customers DESC) AS `rank`
FROM sales
WHERE day BETWEEN '2016-08-10' AND '2016-08-14';
- PARTITION BY ORDER BY 和 window frames组合
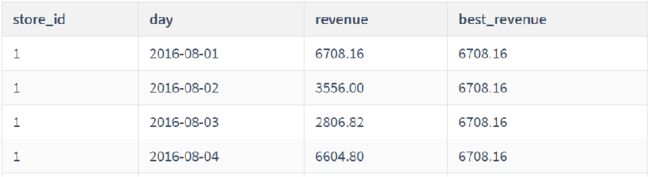
-- 需求:分析2016年8月1日到8月7日的销售数据,统计每个商店到当前日期为止的单日最高销售收入
返回字段:商店id`store_id`,日期 `day`,销售收入 `revenue` 和 最佳销售收入 best revenue
SELECT
store_id,
day,
revenue,
MAX(revenue) OVER(
PARTITION BY store_id
ORDER BY day
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as best_revenue
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-07';
10. 窗口函数必坑指南
- 不能在WHERE子句中使用窗口函数
执行顺序
FROM
WHERE
GROUP BY
聚合函数
HAVING
窗口函数
SELECT
DISTINCT
UNION
ORDER BY
OFFSET
LIMIT
- 不能在HAVING子句中使用窗口函数
- 不能在GROUP BY子句中使用窗口函数
11.在ORDER BY中使用窗口函数
-- 需求:将所有的拍卖按照浏览量降序排列,并均分成4组,最终结果再按照每组编号升序排列,返回字段: `id`, `views` 和 分组情况( `quartile`)
SELECT
id,
views,
NTILE(4) OVER(ORDER BY views DESC) AS quartile
FROM auction
ORDER BY NTILE(4) OVER(ORDER BY views DESC);

12.窗口函数与GROUP BY一起使用
-- 需求:将拍卖数据按国家分组,查询如下字段:
- 国家 `country`
- 每组最少参与人数 `min`
- 所有组最少参与人数的平均值 `avg`
SELECT
country,
MIN(participants) AS `min`,
AVG(MIN(participants)) OVER() AS `avg`
FROM auction
GROUP BY country;

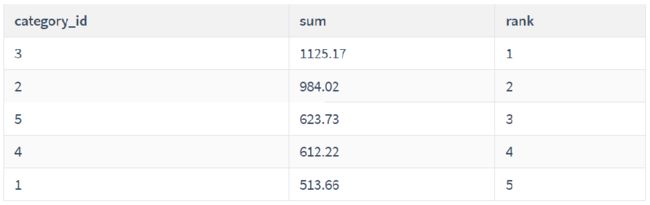
13.Rank时使用聚合函数
-- 需求: 按商品分类`category_id` 分组,对成交价格`final_price`求和`sum`,对所有类别按成交价格的总金额排序,返回序号`rank`
返回字段 `category_id` ,`sum`,`rank`
SELECT
category_id,
SUM(final_price) AS `sum`,
RANK() OVER(ORDER BY SUM(final_price) DESC) AS `rank`
FROM auction
GROUP BY category_id;
14.利用GROUP BY计算环比
需求:按拍卖结束日期`ended`分组分析所有拍卖的浏览数据`views`,返回如下字段:
每组的拍卖结束日期`ended`
每组的总浏览量 `sum`
每组的前一组总浏览量 `previous_day`
比较结束日期相邻两天浏览量的差值 `delta`
SELECT
ended,
SUM(views) AS `sum`,
LAG(SUM(views)) OVER(ORDER BY ended) AS previous_day,
SUM(views) - LAG(SUM(views)) OVER(ORDER BY ended) AS delta
FROM auction
GROUP BY ended
ORDER BY ended;

15 MySQL窗口函数小结
- 窗口函数只能出现在SELECT和ORDER BY子句中
- 如果查询的其他部分(WHERE,GROUP BY,HAVING)需要窗口函数,请使用子查询,然后在子查询中在使用窗口函数
- 如果查询使用聚合或GROUP BY,请记住窗口函数只能处理分组后的结果,而不是原始的表数据