画图搞懂zookeeper的ZAB协议如何保证数据一致性
目录
1、zookeeper是什么?
2、zookeeper的架构?
3、ZAB是什么?
4、从启动到崩溃,ZAB协议做了啥?
5、数据不一致了,ZAB协议,咋办?
zookeeper能被各个牛逼的中间件项目中所依赖,已经说明了他的扫地僧地位。就是低调,低调,还是低调。来,左边跟我一起元数据管理,右边跟我一起分布式协调,中间我们一起画个分布式同心锁。
1、zookeeper是什么?
zookeeper能被各个牛逼的中间件项目中所依赖,已经说明了他的地位。一出手就是稳定的杀招。zookeeper是什么?官网中所说,zookeeper致力于开发和维护成为一个高度可靠的分布式协调器。
开局一张图,官网就是酷,(图片来自官网)。
zookeeper能干的事情很多:
分布式锁,zookeeper特殊的数据结构和watcher机制,让他也能高效的实现分布式锁的功能,参考Curactor这款框架,分布式锁开箱即用。
元数据管理,Kafka就是使用zookeeper存储核心元数据。
分布式协调,zookeeper的watcher机制可以让分布式系统中的各个节点监听某个数据的变化,并且zookeeper可以把数据变化反向推送给订阅了的节点,例如kafka里面的各个broker和controller之间的协调。
Master选举,HDFS就是用了zookeeper来保证Namenode的 HA高可用,可以保证只有一台成为主。
zookeeper提供了全方位的分布式场景下丰富的功能,分布式协调的王者不是虚名。
zookeeper一般是集群部署,单机不可能满足上面提到的这些功能的实现。我们一般都是用3-5台机器。每台机器都会在内存存储所有的元数据。划重点,zookeeper是基于内存存储的,这已经决定了他能实现高吞吐高性能。
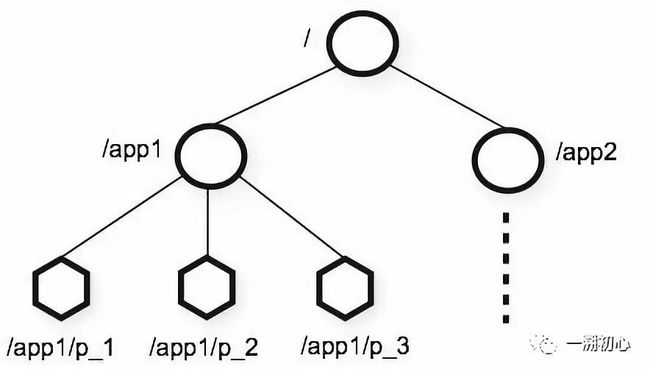
zookeeper的内存数据结构,就像linux系统的文件系统,是一种树形结构,每个节点我们叫做znode。zookeeper的节点大致分为三种类别,一个是临时节点,一个是持久节点,还有顺序节点。灵活运用,组合这些节点,我们在实际开发中能实现各种神奇的功能。
02 zookeeper的架构?
既然是分布式领域的一个王者,zookeeper具备哪些特性才让他立足呢?
集群部署,首先部署上肯定是集群部署,单机肯不靠谱的。
高可用,必须要保证高可用,一旦集群中的某台机器宕机,不能导致数据丢失
原子性,既然zookeeper走的CP,那么一定要保证每次数据写入,集群中所有机器必须要要么全部成功,要么就全部写入失败。
数据一致性,同(3)理,数据一致性也要保证,无论我客户端连接那一台机器,我get某个数据一定是一致的
顺序性,zookeeper的写入,实现了有序的写入,这也夯实了自己数据一致性的特性。
实时感知,zookeeper的watcher机制无疑是一个强大的功能,一旦某个数据发生变化,感知要实时,不然就失去意义了。
高性能,无论是做什么样的功能,超高的读写性能才是根本,zookeeper的数据是存储在内存中的,这本身就带来了超高的性能。并且同时也能带来超高的并发能力
要做到这些,架构设计上是绝对有很多亮点的,我们来看看zookeeper的架构设计。

首先我们先来认识一下zookeeper中的几个角色
leader,集群启动,一定会选择一个节点作为主节点。一个集群中只有一个主节点,并且只有主节点接收并处理写请求。
follower,从节点,首先从节点是不能处理写请求的,就算某个客户端连接到从节点提交写请求,最终也是转发到主节点leader处理。从节点只负责读请求。
当leader宕机的时候,并且当前集群中宕机的数量不超过一半,那么集群会重新发起选举,从follower中选举出新的leader。
Observer,顾名思义,观察者,一般我们接触zookeeper貌似都不怎么用到它,也注意不到他,如果你希望你的读并发能力能抗更多的请求,你可以选择挂载Observer。它只提供数据读取的服务。
当客户端和zookeeper建立起连接,是基于TCP的长连接,一个会话session,通过心跳机制,感知是否断开,如果断开,只要在sessionTimeout时间内重新连接,就能保持住长连接。
zookeeper的数据结构是znode树型结构,如上文一样,我们每次写入就是构建树节点下的叶子结点。并且创建的节点分为持久节点和临时节点。持久节点一旦创建,会持久化到磁盘,哪怕客户端断开,下次依然可以读取到。
临时节点则不一样,一旦客户端断开连接的话就不存在了。和持久节点和临时节点能够组合的还有是否有序,在zookeeper的客户端curactor框架中就是基于临时顺序节点实现了分布式锁。
znode的结构长什么样呢?我们执行一次get操作,可以得到如下这样子的数据结构。

上文说过zookeeper一个很重要的功能是分布式协调,这就要依赖于zookeeper的监听回调机制,watcher机制,当客户端监听一个节点,当节点发生变化的时候反向通知客户端,如此便可以实现对订阅数据变化的感知,并做出响应的处理。基于TCP,天然可以实现这样的功能。

03 ZAB是什么?
Zookeeper一般都是集群部署,那么集群之间各个节点是如何同步数据的呢?如何才能保证数据对外的一致性呢?
这里就引出了Zookeeper的自己参照一致性协议paxos实现的,独有的ZAB协议,zookeeper Atomic Broadcast,zookeeper原子广播协议。正是通过这个协议,zookeeper的集群之间进行数据同步,保证数据的强一致性。
首先我们来拍脑袋想一想哪些情况下数据会不一致呢?正如上文提到的,所有的写请求是转发给leader处理的,再加上同步给follower,这中间网络通信,会出现各种情况,甚至leader崩溃,follower崩溃,这些都会导致数据不一致。
那么ZAB协议是怎么起到保证一致性的作用呢?
首先明确的是整个zookeeper集群中的几个角色划分,只有leader负责写入数据,follower只负责从follower同步数据已经对外提供读取数据。可以说zookeeper实现的就是主备模型。
我们可以认为,一次写入就是一次分布式事务,从写入请求到leader,到follower的数据同步,到写入成功,返回客户端ACK。这就是分布式事务嘛。

当leader收到一条写入请求,这里我们称之为一次事务请求,就会将客户端事务请求转换成事务Proposal(提议,提案),并且将这个事务Proposal发送给所有的Follower节点,也就是向所有的follower节点发送数据广播请求。
广播事务Proposal之后leader就要等待所有的Follower服务器的返回,(ack请求),划重点,在ZAB协议中明确了只要有超过半数的Follower节点正确的返回了ACK,就认为本次提案是successful的。那么此时leader就会向所有的Follower服务器广播commit消息,对前一次的事务Proposal发起提交。这里我们敏锐的可以感觉到,脑海里浮现了一个词语 2PC。这个后面再说。

上面的过程我们可以理解为是一个2PC的过程,并且需要过半的机器成功接收到事务Proposal,并返回ACK,也就是过半写,2PC+过半写,这是ZAB协议的一个核心点。
我们再想想一个从leader哪里的问题?上面讨论的所有问题都是在唯一一台leader存在的情况下,那么leader是如何产生的?leader宕机了又该怎么办?这个是我们接下来要一点点分析的问题。
04 从启动到崩溃,ZAB协议做了什么?
我们来讨论leader从哪里来?既然是最有权势的一个leader,没有规矩,谁都能当?那肯定集群里面的节点都争着要当的,这时候我们就要自然是要选举出来的。怎么选,这也是ZAB协议里有规定的。
当一个ZK集群启动的时候,会进入崩溃恢复模式,直到选举出一个leader,并且只要过半的Follower机器都和leader机器同步完数据,就会退出崩溃恢复模式,对外提供服务,此时就进入了消息广播模式。
崩溃恢复模式和消息广播模式是zookeeper集群工作的主要俩个模式。
我们接着说leader选举的事情,ZAB协议规定leader选举只要过半的机器都投票给某一台机器,这台机器就成为leader,这里自己也可以投票给自己。如果leader突然宕机了,此时整个集群再次进入崩溃恢复模式,重新选举新的leader。
消息广播模式就是集群数据副本传递的主要的策略,上文我们也说到了2PC,但其实zookeeper还是为了性能做了优化,并不是要所有的follower都返回ACK,只要过半数返回ACK就认为本次事务Proposal是写入成功的,就可以发起commit请求了。
这里我们其实是有疑惑的,这样子,zookeeper还是强一致性么?毕竟在某个时间点,也不是所有的机器都拥有一致的副本啊,这么看来也不能说Zookeeper是实现了强一致性的CP模型,这里有个结论,最终所有的机器会实现数据副本一致性。
消息广播模式下,每次从客户端有一个事务请求过来,leader会转化为事务Proposal,并且写入本地磁盘,还会给每个事务Proposal分配一个全局唯一的Zxid。
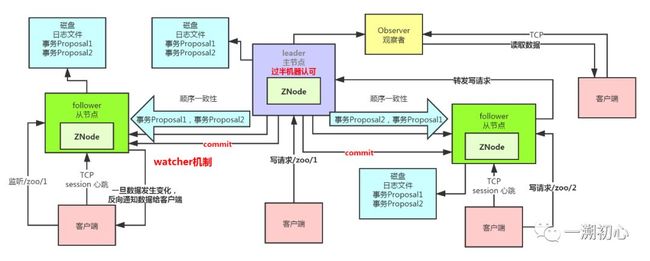
还有个细节,当leader向所有的Follower发起事务Proposal时,不是就随随便便发送的,leader为每一个Follower都维护了一个先进先出的队列,每一个事务Proposal都是按照顺序依次放入,保证有序性。当Follower接收到事务Proposal时,会将其写入本地磁盘。
这里还有异步解耦的功效,也一定程度上提高了事务Proposal的广播速度。那么这里我们还可以说zookeeper实现的是顺序一致性,这样看起来,更大程度的保证了数据的一致性。
05 数据不一致了,ZAB协议,咋办?
以上大概描述了ZAB协议下,zk集群中leader和follower之间数据副本的同步过程,我们在这里稍微消耗脑细胞地想一下,有没有什么情况,会导致数据不一致?
当一个客户端发过来的事务写请求,刚刚被leader写到本地,还没来得及发起Proposal就宕机了,这时候会数据不一致么?
如果一个事务Proposal写入是成功的,并且广播给所有的Follower机器,也受到了过半机器的ACK,此时leader节点挂了,并且此时可能leader已经本地commit了,那么新的leader选举出来之后,这台老的leader重新启动了之后,数据会不一致么?
细细一想,不经冷汗,这些也是问题啊,ZAB要保证自己说到的一致性就必须要解决这俩种情况,如何解决呢?那么这里就留一个悬念啦,各位码神大佬,如有结论,可以留言,把知识传播给更多的人,如果我写的有错误也欢迎指正,谢谢大家。