django——视图层,模板层
文章目录
- 网页伪静态
- 视图层
-
- 视图函数的返回值
- 视图函数返回json格式数据
- 接收文件数据
- FBV与CBV
- 模板层
-
- 模板语法传值
- 模板语法之过滤器
- 模板语法之标签(类似于流程控制)
- 自定义标签函数、过滤器、inclusion_tag
- 模板的继承
- 模块的导入
网页伪静态
什么是伪静态?
伪静态页面是指动态网页通过重写URL的方法实现去掉动态网页的参数,但在实际的网页目录中并没有必要实现存在重写的页面。
作用:将动态网页伪装成静态网页 从而提升网页被搜索引擎收录的概率
表现形式就是网址看着像一个具体的文件路径
举例说明:
path('index.html', view.index)
视图层
视图函数的返回值
视图函数其实都必须返回一个HttpResponse对象
当浏览器向服务器发起数据请求的时候,那么服务器用来响应的视图函数的返回值的种类有两种,分别是HTML响应(HttpResponse、render、redirect)和JsonResponse(前后端分离)
其实HTML的三种响应方式返回的都是一个HttpResponse对象(可以查看源码)
注意:HttpResponse是一个类(可以查看源码)
-
HttpResponse
不使用模板,直接HttpResponse()
例如:创建一个视图函数def testResponse(request): response = HttpResponse() response.content = '加油' response.status_code = 404 # 直接写出文本 response.write('lzq') # 一次性读取剩余字节,冲刷缓存区 response.flush() return response
效果图:

-
render
render方法的返回值类型也是一个HttpResponsedef testRender(request): response = render(request,'testRender.html') print(type(response)) return response 输出结果:<class 'django.http.response.HttpResponse'> -
Redirect
重定向
其是HttpResponse的子类,响应重定向:可以实现服务器内部跳转
视图函数返回json格式数据
-
方法一
json序列化形式def index(request): user_dict = {'name': 'jason', 'age': 123} data = json.dumps(user_dict) return HttpResponse(data)如果字典数据中存在中文字,输出的结果会进行编码,所以我们可以加参数
ensure_ascii,这个参数默认情况下为Ture,我们让这个参数等于False即可 -
方法二
JsonResponse序列化形式def index(request): # 视图函数返回json格式数据 user_dict = {'name': 'jason', 'age': 123} return JsonResponse(user_dict)如果字典数据中存在中文字,输出的结果会进行编码,所以这里的处理方式需要我们看一看JsonResponse的源码:

我们可以看到,如果json_dumps_params如果为None的话,就是一个空字典;然后又根据关键字形参的知识我们可以加
json_dumps_params={'ensure_ascii': False}补充:
JsonResponse这个类是HttpRespon的子类,它主要和父类的区别在于:
1.它的默认Content-Type 被设置为: application/json
2.第一个参数,data应该是一个字典类型,当 safe 这个参数被设置为:False ,那data可以填入任何能被转换为JSON格式的对象,比如list, tuple, set。 默认的safe 参数是 True. 如果你传入的data数据类型不是字典类型,那么它就会抛出 TypeError的异常。
序列化非字典类型的数据还需要指定safe参数为False
接收文件数据
注意事项:
-
enctype属性需要由默认的urlencoded变成form/data(
enctype="multipart/form-data") -
method属性需要由默认的get变成post
(目前还需要考虑的是 提交post请求需要将配置文件中的csrf中间件注释)
-
如果form表单上传文件 后端需要在request.FILES获取文件数据 而不再是POST里面
举例说明:
views.py
def file(request): # 文件数据的读取
if request.method == 'POST':
file_info = request.FILES.get('file')
with open(file_info.name, 'wb') as f:
for line in file_info:
f.write(line)
return render(request, 'json.html')
print(request.POST) # ]}>
print(file_info.name) # 今日考题.md
HTML
FBV与CBV
FBV(Function Based View):基于函数的视图
CBV(Class Based View):基于类的视图
CBV和FBV在路由匹配上,规则都是一样的,都是路由后面跟的函数的内存地址
举例说明(CBV)
class MyView(views.View):
def get(self, request):
return HttpResponse('我是get')
def post(self, request):
return HttpResponse('我是post')
这个时候我们运行起来可以发现,我们类里面的函数自动调用了,我们感到疑惑;这个时候就需要我们去源码里面查找原因了。
- 如果请求方式是GET 则会自动执行类里面的get方法
- 如果请求方式是POST 则会自动执行类里面的post方法
查看CBV源码步骤:
- CBV路由层
path('view/',views.MyView.as_view()) # 在这必须调用自己写的MyReg类中的as_view方法
# as_view的源码
@classonlymethod
def as_view(cls, **initkwargs):
def view(request, *args, **kwargs):
self = cls(**initkwargs) # cls就是我们自己的写的MyView类
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
# 上面的一通操作 就是给我们自己写的类的对象赋值
return self.dispatch(request, *args, **kwargs)
# 对象在查找属性或方法的时候 顺序是什么? 先从自己找 再从产生对象的类中找 再去类的父类中找...
"""也就意味着你在看源码的时候 你一定要牢记上面的话"""
return view
- 视图层views.py中写上继承view的类
class MyView(views.View):
def get(self, request):
return HttpResponse('我是get')
def post(self, request):
return HttpResponse('我是post')
- 在前端发送请求的时候就会进到CBV源码的dispatch方法判断请求方式在不在默认的八个请求方式中
"""CBV源码最精髓的部分"""
def dispatch(self, request, *args, **kwargs):
if request.method.lower() in self.http_method_names: # 判断当前请求方式在不在默认的八个请求方式中
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
# handler = getattr(自己写的类产生的对象,'小写的请求方法(get\post)','获取不到对应的方法就报错')
# handler就是我们自己定义的跟请求方法相对应的方法的函数内存地址
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs) # 再调用获取到的方法
八个请求方式:http_method_names = [‘get’, ‘post’, ‘put’, ‘patch’, ‘delete’, ‘head’, ‘options’, ‘trace’]
模板层
模板语法传值
-
方法一(指名道姓的传)
不会浪费空间return render(request, 'modal.html', {'name':name}) -
方法二(关键字:locals)
将整个局部名称空间中的名字全部传入;简单快捷return render(request,'modal.html',locals())
强调:
django提供的模板语法只有两个符号
{{}}:主要用于变量相关操作(引用)
{%%}:主要用于逻辑相关操作(循环、判断)
传值的范围
-
基本数据类型都可以
-
函数名
模板语法会自动加括号执行并将函数的返回值展示到页面上
不支持传参(模板语法会自动忽略有参函数) -
文件名
直接显示文件IO对象 -
类名
类名的传递也会自动加括号产生对象并展示到页面上
自动加括号实例化成对象 -
对象名
直接显示对象的地址 并且具备调用属性和方法的能力
注意:
模板语法会判断每一个名字是否可调用 如果可以则调用!!!
django模板语法针对容器类型的取值 只有一种方式>>>:句点符
既可以点key也可以点索引 django内部自动识别
HTML文件
Title
{{ msg.upper }}
{{ dic.k1 }}
{{ obj.name }}
{{ li.1.upper }}
{{ li.2.age }}
模板语法之过滤器
优点:类似于内置函数
特点:会将|左边的当做过滤器的第一个参数,将右边的当做过滤器第二个参数。
过滤器类似于python的内置函数,用来把视图传入的变量值加以修饰后再显示,具体语法如下:
{{ 变量名|过滤器名:传给过滤器的参数 }}
常见内置过滤器
1、default
#作用:如果一个变量值是False或者为空,使用default后指定的默认值,否则,使用变量本身的值,如果value=’‘则输出“nothing”
{{ value|default:"nothing" }}
2、length
#作用:返回值的长度。它对字符串、列表、字典等容器类型都起作用,如果value是 ['a', 'b', 'c', 'd'],那么输出是4
{{ value|length }}
3、filesizeformat
#作用:将值的格式化为一个"人类可读的"文件尺寸(如13KB、4.1 MB、102bytes等等),如果 value 是 12312312321,输出将会是 11.5 GB
{{ value|filesizeformat }}
4、date
#作用:将日期按照指定的格式输出,如果value=datetime.datetime.now(),按照格式Y-m-d则输出2019-02-02
{{ value|date:"Y-m-d" }}
5、slice
#作用:对输出的字符串进行切片操作,顾头不顾尾,如果value=“egon“,则输出"eg"
{{ value|slice:"0:2" }}
6、truncatechars
#作用:如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾,如果value=”hello world egon 嘎嘎“,则输出"hello...",注意8个字符也包含末尾的3个点
{{ value|truncatechars:8 }}
7、truncatewords
#作用:同truncatechars,但truncatewords是按照单词截断,注意末尾的3个点不算作单词,如果value=”hello world egon 嘎嘎“,则输出"hello world ..."
{{ value|truncatewords:2 }}
8、safe
#作用:出于安全考虑,Django的模板会对HTML标签、JS等语法标签进行自动转义,例如value="",模板变量{{ value }}会被渲染成交给浏览器后会被解析成普通字符”“,失去了js代码的语法意义,但如果我们就想让模板变量{{ value }}被渲染的结果又语法意义,那么就用到了过滤器safe,比如value='点我啊',在被safe过滤器处理后就成为了真正的超链接,不加safe过滤器则会当做普通字符显示’点我啊‘
{{ value|safe }}
内置过滤器safe用来前后端取消转义(前端代码并不一定非要在前端写,也可以在后端写好,传递给前端页面)
前端取消转义:|safe
后端取消转义:要先导一个模块:
from django.utils.safestring import mark_safe
sss = "渡我不渡她"
res = mark_safe(sss)
# 再把这个res传到前端
{{ res }} # 前端就能识别a标签了
9、add
给value加上一个add后面的数值
eg:给前端传个n=123,`{{ n|add:100 }}`这个过滤器结果就是n+100,在页面上显示的结果就是223.
补充:

续表:
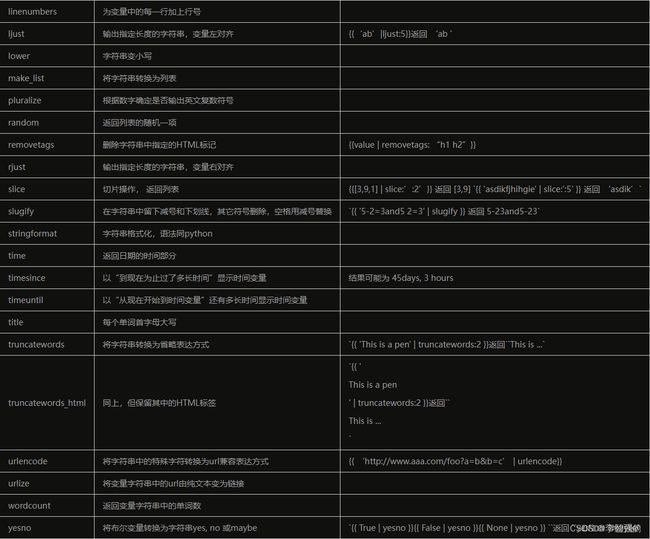
模板语法之标签(类似于流程控制)
标签语法结构:
{% 标签名字 ...%}
{% end名字 %}
常见使用:if判断,for循环、with标签等。
if 判断
{% if 条件 %} 条件一般是模板语法传过来的数据 直接写名字使用即可
条件成立执行的代码
{% elif 条件1 %}
条件1成立执行的代码
{% else %}
条件都不成立执行的代码
{% endif %}
for 循环
{% for i in l1 %}
{% if i == 1 %}
我是
{{ i }}
{% elif i == 2 %}
我是
{{ i }}
{% else %}
我是3
{% endif %}
{% endfor %}
with标签
# with标签用来为一个复杂的变量名起别名,如果变量的值来自于数据库,在起别名后只需要使用别名即可,无需每次都向数据库发送请求来重新获取变量的值
{% with li.1.upper as v %}
{{ v }}
{% endwith %}
自定义标签函数、过滤器、inclusion_tag
步骤:
-
在应用名下面新建一个templatetags文件夹(必须叫这个名字)
-
在该文件夹下,新建一个任意名称的py文件
-
在该py文件内,固定先写两行代码:
from django.template import Library
register = Library()
自定义标签函数
视图层
py文件
from django.template import Library
register = Library()
@register.simple_tag(name='mysm')
def login(a, b, c, d):
return '%s/%s/%/%s'%(a, b, c, d)
模板层
HTML文件
{% load my_tag %}
{% mysm 1 2 3 4 %}
前端显示结果:1/2/3/4
自定义过滤器
视图层
py文件
from django.template import Library
register = Library()
@register.filter(name='myplus')
def index(a, b):
return a+b
模板层
HTML文件
{% load my_tag %}
{{ 123|myplus:123 }}
前端显示结果:246
自定义过滤器和标签的区别
#1、自定义过滤器只能传两个参数,而自定义标签却可以传多个参数
#2、过滤器可以用于if判断,而标签不能
{% if salary|my_multi_filter:12 > 200 %}
优秀
{% else %}
垃圾
{% endif %}
自定义inclusion_tag
视图层
py文件
@register.inclusion_tag(filename='it.html')
def index(n):
html = []
for i in range(n):
html.append('第%s页'%i)
return locals()
模板层
HTML文件
{% for foo in l1 %}
{{ foo }}
{% endfor %}
'''该方法需要先作用于一个局部html页面 之后将渲染的结果放到调用的位置'''
模板的继承
extends标签和block标签
实现需要在要继承的模板中,通过block划定区域
{% block 区域名字 %}
{% endblock %}
子模版如何使用
# include有的功能extends全都有,但是extends可以搭配一个block标签,用于在继承的基础上定制新的内容
{% extends '想要继承的模板' %}
{% block 区域名字 %}
登录页面
{% endblock %}
一个页面上block块越多,页面的扩展性越高,通常情况下,都应该有三片区域
{% block content %}
{% endblock %}
{% block css %}
{% endblock %}
{% block js%}
{% endblock %}
总结:
1、标签extends必须放在首行,base.html中block越多可定制性越强
2、include仅仅只是完全引用其他模板文件,而extends却可以搭配block在引用的基础上进行扩写
3、子模板中变量{{ block.super }} 可以重用父类的内容,然后在父类基础上增加新内容,而不是完全覆盖
4、为了提升可读性,我们可以给标签{% endblock %} 起一个名字 。例如:
{% block content %}
...
{% endblock content %}
5、在一个模版中不能出现重名的block标签。
模块的导入
类似于将html页面上的局部页面做成模块的形式 哪个地方想要直接导入即可展示
eg:有一个非常好看的获取用户数据的页面 需要在网站的多个页面上使用
策略1:拷贝多份即可
策略2:模板的导入
使用方式
{% include 'menu.html' %}
作用:在一个模板文件中,引入/重用另外一个模板文件的内容