做自动化的同事今天居然问我 k8s 中为什么我部署的 pod 会跑到你们开发的节点上来?我可以去控制它吗?
兄弟,自然是可以控制的,接下来我详细给你说一下关于 k8s 中节点污点,pod 对污点的容忍度,以及 亲缘性和非亲缘性✔✔
需求场景
首先我们要明确咱们的需求和场景
- 如果期望自己的 pod 需要部署到指定的 Node 上,那么可以在 pod 的 yaml 中加上 nodeSelector 节点标签选择器,或者在 pod 中加上节点亲缘性的配置
- 如果我们期望某一个节点不让别的 pod 的部署上来,只期望一些特定的 pod 部署到这个 Node 上,那么我们就可以使用节点的污点,和 pod 对污点的容忍度来进行实现
接下来我们就开始吧,看看什么是 nodeSelector,以及上述提到的各种名词,本次文章内容,需要有一点点 k8s 基础的同学看起来会更加友好,至少你得知道 Deployment 资源和 pod 资源的 yaml 清单
✔nodeSelector 节点标签选择器
nodeSelector 节点标签选择器, 用过K8S的我们都知道,如果想让 pod 指定部署到某一些节点上,那么我们可以通过这个字段来进行标识。
例如我们的 Pod 资源中 nodeSelector 字段标识的是 func=dev ,那么 pod 就会部署到 func=dev 的任意节点上,这是强制指定的
apiVersion: v1
kind: Pod
metadata:
name: test-node-selector
sepc:
nodeSelector:
fun: "dev"
...通过这里就可以看到节点标签选择器,它的使用局限性还是非常明显的,它只能用于你指定 pod 一定要部署到某一个指定标签节点上的时候,那如果这个时候没有这种标签的节点时,你这个 pod 就会部署不成功。
✔k8s 中节点污点和 pod 对污点的容忍度
我们一般会使用节点污点和 pod 对污点的容忍度来阻止 pod 被调度到特定的节点上
如果你期望某一个 pod 一定不能部署到某一个节点上的时候,你就可以使用节点污点和pod 对污点的容忍度
例如现在上了一个新的节点,但是还没有调试完整,你不期望你部署的 pod 会部署到这个新的节点上,那么这个时候,你就可以给这个节点加上污点。
那你测试这个新节点的时,你就可以在你将要部署的 pod 资源上面,加上 pod 对该污点的容忍度
先来看一下k8s master上默认的一个污点
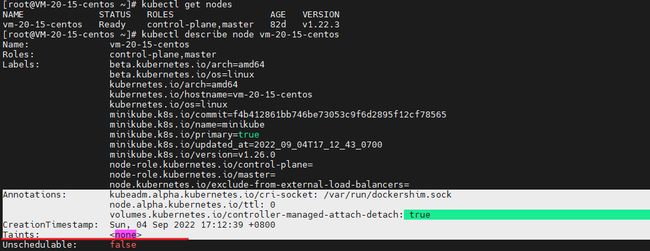
可以看到我们环境里面的 minikube,它的污点是空
因为它只有一个节点,它既是 master 又是worker,所以它部署的 pod 仍然可以在这个节点上进行正常部署
如果我们是在 K8S 集群中查看 master 节点的详情时,我们可以看到这样的污点
Taints: node-role.kubernetes.io/master:NoSchedule其中污点的
key 是 node-role.kubernetes.io/master
value 是 空的
effect 是 NoSchedule
表达的意思是这个污点会阻止 pod 调度到这个节点上面
一个 pod 只有容忍了节点上的污点,那么他才可以被调度到这个节点上
一般情况下,用于系统的 pod 会容忍 master 上的这个污点也,就是说这样的 pod 就可以部署到master上

对于污点 Taints ,我们需要注意这三类:
前两类(NoSchedule, PreferNoSchedule)污点都只作用于调度期间,后一类的污点(NoExecute),它会影响正在节点上运行的 pod
NoSchedule
表示如果 pod 无法容忍这个污点那么 pod 将不能调度到包含该污点的节点上
PreferNoSchedule
表示尽量阻止 pod 被调度到这个节点上,当然如果没有其他节点可以调度,那么 pod 仍然还是可以调度到当前有这种污点的节点上的
NoExecute
如果在一个节点上加入了这种类型的污点,那么在当前节点上已经运行的 pod,若不能容忍这个污点,则这些 pod 就会被干掉
如何操作
我们可以通过编辑的方式去修改节点的污点或者通过命令的方式给节点加上污点
- 通过 edit node 的方式修改
kubectl edit node [nodeName]找到 Taints 的位置,加上我们的 key,value,effect
修改完毕后,使用命令查看污点是否添加成功
kubectl describe node [nodeName]- 通过命令的方式修改
kubectl taint node [nodeName] key=value:effect
例如:
kubectl taint node vm-20-15-centos node-type=newNode:NoSchedule表达的意思是,给节点 vm-20-15-centos 加上一个污点:
Key 为 node-type
Value 为 newNode
Effect 为 NoSchedule
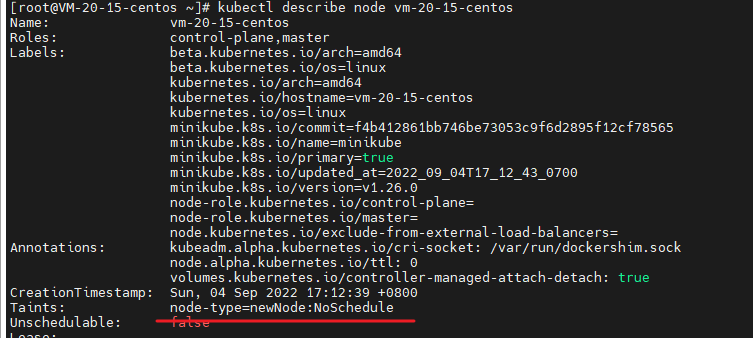
此时,只有容忍这个新节点上污点(node-type=newNode:NoSchedule) 的 pod 才可以部署上来,其他没有容忍度的 pod 就无法部署上来
我们可以这样在 pod 里面添加对污点的容忍度
直接在 pod 资源中,或者在 deployment 资源中的 spec.template.spec 下添加 tolerations 的配置
tolerations:
- effect: NoSchedule
key: node-type
operator: Equal
value: newNode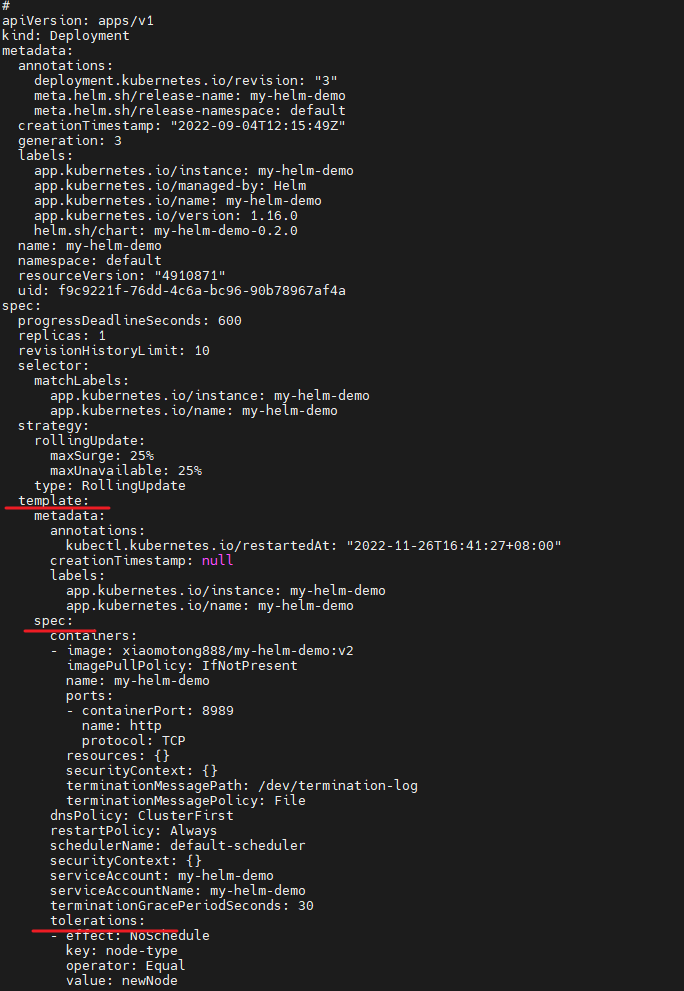
现在,咱们的刚修改的这个 pod 有了对这个污点的容忍度(node-type=newNode:NoSchedule),因此可以在上述节点上进行部署
简单理解
如果你能够容忍得了坏的生活,那么你也值得好的生活,好坏你都可以去感受去选择
如果你无法容忍坏的生活,那么你无法接近这片区域的
✔节点亲缘性
节点的亲缘性和节点标签选择器有点类似,但节点亲缘性能够表达的意思更多。
使用节点亲缘性,它可以让我们部署的 pod,更加倾向于调度到某一些节点上,在 K8S 中会尽量的将这个 pod 按照我们期望的节点进行部署,如果没办法实现的话,那也会把这些节点部署到其他节点上。
对于节点的亲源性,我们聊一聊如下三个重要的标签。
failure-domain.beta.kubernetes.io/region
表示节点所在地域
failure-domain.beta.kubernetes.io/zone
表示节点所在的可用性区域
kubernetes.io/hostname
表示节点的主机名
如何操作
第1步
自然是先将节点打上我们期望的标签,例如节点的标签是 func=dev,当然我们也可以不用自定义标签,可以使用系统的默认标签,例如 kubernetes.io/hostname 主机名
kubectl label nodes [nodeName] key=value
例如
kubectl label nodes vm-20-15-centos func=dev第2步
我们需要去修改 pod 资源中关于节点亲和性的位置,例如可以这样。
nodeSelectorTerms 标签下满足任意一个 matchExpressions 即可
matchExpressions 标签下需要全部满足
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: func
operator: Euqal
values:
- dev
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- dev这个时候,咱们部署的 pod ,就会去找有 func=dev 标签的节点进行部署,如果没有的话,那么就无法部署
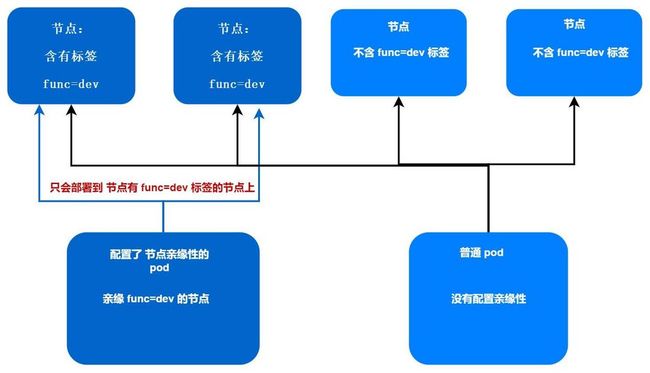
这里我们可以看到 nodeAffinity 下面有一长串单词 requiredDuringSchedulingIgnoredDuringExecution,此处详细解释一下。我们可以分开来看这一长串单词。
requiredDuringScheduling
此处的 required 表示的是必须包含,表示 pod 若要调度到该节点上,那么必须要指出该节点包含的标签。
IgnoredDuringExecution
根据单词名字我们可以看出。在调度过程中会忽略正在运行的 pod,也就是说对正在执行的 pod 不影响。
同样的道理,我们可以将上述的 required 换成 preferred ,对 K8S 来说就是尽可能的优先将 pod 调度到我们指定的节点上,如果没有这样的节点,那么它也是会将 pod 调度到其他节点上的。
可以这样写,尽量满足要求
spec:
affinity:
nodeAffinity:
prefferredDuringSchedulingIgnoredDuringExecution:
- weight 100
preference:
matchExpressions:
- key: func
operator: Euqal
values:
- dev看到此处你已经学会了,如何让 pod 部署到指定的节点上,同时你也可以让某一些节点拒绝 pod 部署上来。

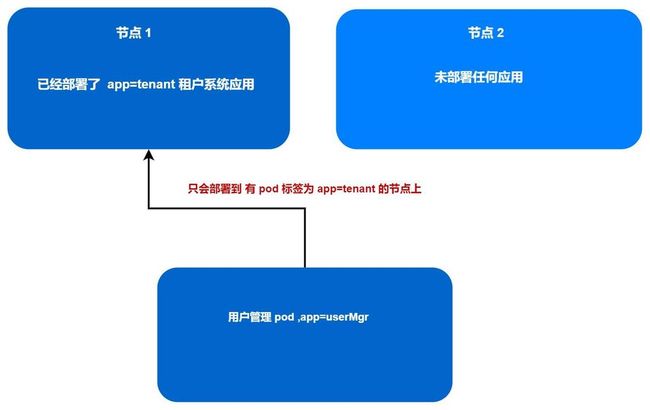
✔Pod 的亲缘性
这个时候我们会有另外的一些需求,我们希望将一些交互比较多的不同类型的 pod 部署到一个节点上,这样的话他们的网络通信性能会更好。
例如租户系统就会经常调用用户管理系统的接口。那么这两类 pod 就可以放到同一个节点进行部署。这个时候我们就可以使用 pod 的亲缘性来很好地处理。
对于 pod 亲缘性和节点的亲缘性来说,在写法上将 nodeAffinity 换成了 podAffinity
如何操作
例如,此处的 租户系统 pod 标签为 app=tenant , 那么 用户管理写 pod 亲和性的时候,就只需要去找这个标签的 pod 所在的节点进行部署即可
修改 pod / deployment 资源
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
masrchLabels:
app: tenant
...其中 topologyKey 指定 kubernetes.io/hostname ,含义是:要求 pod 将被调度到 包含 app=tenant 标签的 pod 所在的相同节点上面
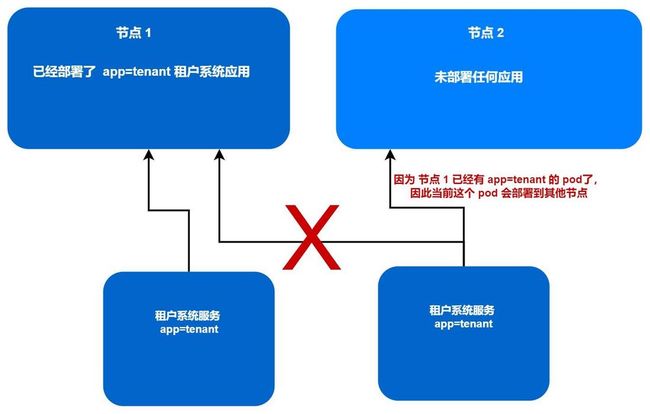
✔Pod 的非亲缘性
我们的需求总是无穷无尽的,现在我们为了服务更加的健壮,期望同一个应用,能够在 K8S上每一个节点都部署一个,而不是这一个应用全都部署在一个节点上。
这样是为了防止某一个节点出现故障之后,其他节点上仍然有这个应用提供服务。
那咱们可以如法炮制,既然有 pod 的亲缘性,那自然也有 pod 的非亲缘性
Pod 的非亲缘性,咱们一般用来去分开调度 pod ,让同一类型 pod 分别部署到不同的 节点上
如何操作
修改 pod / deployment 资源
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
masrchLabels:
app: tenant
...此处我们可以看到,使用的 podAntiAffinity 表示 pod 的反亲缘性, 此处不要弄错了
此处写的标签是 app=tenant ,表示的意思是,如果有一个 pod 标签为 app=tenant 在 节点 1 上,那么如果再部署这种类型的 pod 的时候,就不会再部署到节点1 上的,就会去部署到其他节点上
总结
至此,通过上面的知识,我们解决了这样几个场景问题
- 利用节点的亲缘性将 pod 指定部署到某些节点上,如果这样的节点不存在,那么也可以将他们的部署到别的节点上。
- 利用 pod 亲缘性将交互比较频繁的一些服务应用尽可能部署到同一个节点上。
- 利用 pod 的非亲缘性将 pod 分开调度到不同的节点上,更好的保证高可用
本次就是这样,如果有帮助到你,欢迎点赞,评论,留言哦
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
文中提到的技术点,感兴趣的可以查看这些文章: