黑马入门jvm总结
文章目录
- 1.jvm介绍
-
-
- 1.什么是jvm
- 2.基本介绍
-
- 2.内存结构
-
-
- 1.程序计数器
- 2.虚拟机栈
- 3.栈内存溢出
- 4.线程诊断
- 5.本地方法栈
- 6.堆
-
- 1.堆内存诊断
- 7.方法区
-
- 7.1定义
- 7.2组成
- 7.3方法区内存溢出
- 7.4运行时常量池
- 7.5StringTable
- 7.6StringTable的特性
- 7.7StringTable的位置
- 7.8StingTable的垃圾回收
- 7.9StringTable的桶优化
- 8.直接内存
-
- 8.1定义
- 8.2释放原理
-
- 3.垃圾回收
-
- 1.如何判断对象可以回收
-
- 1.1引用计数法
- 1.2可达性分析算法
- 1.3引用
- 2.标记清除算法
-
- 2.1标记清除
- 2.2标记整理
- 2.3复制
- 3.分代回收
-
- 3.1定义
- 3.2过程
- 3.3GC分析
- 4.垃圾回收器
-
- 类型
- 4.1串行
- 4.2吞吐量优先
- 4.3响应时间优先
- 4.4G1
- 5垃圾回收调优
-
- 5.1区域
- 5.2目标
- 5.3最快的GC是不发生GC
- 5.4新生代调优
- 5.5老年代调优
- 5.6案例
- 4.类加载和字节码
-
-
- 4.1类文件结构
- 4.2字节码指令
- 4.3运行流程
-
- (1)分析a++ + ++a + a--的值。这个时候a=10;
- (2)x++练习
- (3)构造方法
-
- ①cinit
- ②init
- (4)方法调用
- (5)多态原理
- (6)异常
-
- ①单个异常
- ②多个异常与muti-catch基本相似
- ③finally
- ④synchronized
- 4.4语法糖
-
-
- (1)默认构造器
- (2)自动装箱拆箱
- (3)List的add方法优化
- (4)泛型反射
- (5)可变参数
- (6)foreach
- (7)switch
- (8)switch enum
- (9)枚举
- (10)try() catch
- (11)桥接方法
- (12)匿名内部类
-
- 4.5类加载阶段
-
- (1)加载
- (2)连接
-
-
- 连接验证
- 连接准备
- 连接解析
-
- (3)类初始化阶段
- 4.6类加载器
-
- (1)分类
- (2)双亲委派的源码分析
- (3)打破双亲委派的Drivers
- (4)自定义类加载器
- 4.7运行期优化
-
- (1)逃逸分析
- (2)方法内联
- (3)字段优化
- (4)反射优化
-
- 5.JMM(java Memory model)
-
- 5.1JMM内存模型
-
- (1)JMM的原子性synchronized
- 5.2可见性
- 5.3有序性
-
- (1)诡异的结果
- (2)有序性的解决办法
- (3)有序性的理解
- 5.4CAS和原子性
-
- (1)CAS
- (2)原子操作类
- 5.5synchronize优化
-
- (1)轻量级锁
- (2)锁膨胀
- (3)自旋锁
- (4)偏向锁
- (5)其它优化
1.jvm介绍
1.什么是jvm
定义
jvm就是java virtual machine也就是java虚拟机,他其实是一个java运行环境,java二进制字节码的运行环境
好处
①一次编写,处处运行(屏蔽了java代码与操作系统之间的差异和细节)
②自动内存管理,垃圾回收机制(不需要我们手动回收)
③数组下标越界越界检查
④多态
jvm、jre、jdk的差异
jvm是java虚拟机,java运行环境
jre是java runtime environment也就是jvm+基本类库
jdk就是jvm+基本类库+编译工具
javase=jdk+ide工具
javaee=jdk+ide工具+服务器
2.基本介绍
类会通过类加载器加载进内存,内存的方法区通常是存放类,这里的堆存放的是类的实例化对象,其它就是当调用方法时候使用的。接着就是解释器来执行和解释代码,即时编译器是用于编译那些热热点代码的。

2.内存结构
1.程序计数器
作用
记住下一条指令的位置。然后通过解释器来读取程序计数器的数值,来获取下一条命令,并转换成机器码交给cpu执行。
①线程私有(每次切换线程的时候需要程序计数器来记录执行的位置)
②不会存在内存溢出
2.虚拟机栈
什么是虚拟机栈?
栈是线程运行所需要的内存
什么是栈帧?
栈帧就是一个方法运行所需要的内存。一个线程需要调用多个方法,也就是线程需要压入多个栈帧。
一个程序的运行测试
main中调用method1,首先出现的是main方法的栈帧,如果调用了method1那么就会创建一个method1的栈帧压栈。
问题辨析
①垃圾回收是否设置栈内存?
不会,因为栈里面的栈帧方法调用完之后会自动释放
②栈是不是越大越好?
当然不是,栈占用空间大只能调用更多次方法递归,但是线程数会变少。因为占用空间多,线程也就无法拓展更多了
③方法内部的局部变量是不是线程完全的
(1)变量逃离了方法范围,比如对象以参数传入,或者是以返回值返回,都有可能在外部再次被调用修改
(2)变量没有逃离,或者是一个基本变量。
3.栈内存溢出
原因
①栈帧过多
②栈帧过大
可以调整-Xss
出现这种问题的场景?
通常会出现在其他类库里面,而不是因为我们写错了。比如说员工需要依赖部门,部门也需要依赖,员工,那么他们进行json转换的时候就会没完没了。
public class Demo1_19 {
public static void main(String[] args) throws JsonProcessingException {
Dept d = new Dept();
d.setName("Market");
Emp e1 = new Emp();
e1.setName("zhang");
e1.setDept(d);
Emp e2 = new Emp();
e2.setName("li");
e2.setDept(d);
d.setEmps(Arrays.asList(e1, e2));
// { name: 'Market', emps: [{ name:'zhang', dept:{ name:'', emps: [ {}]} },] }
ObjectMapper mapper = new ObjectMapper();
System.out.println(mapper.writeValueAsString(d));
}
}
class Emp {
private String name;
// @JsonIgnore
private Dept dept;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Dept getDept() {
return dept;
}
public void setDept(Dept dept) {
this.dept = dept;
}
}
class Dept {
private String name;
private List<Emp> emps;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Emp> getEmps() {
return emps;
}
public void setEmps(List<Emp> emps) {
this.emps = emps;
}
}
4.线程诊断
思路
①运行一个java程序
②top查看哪个程序占用cpu资源多
③ps H -eo pid,tid,%cpu |grep xx过滤查看进程和线程占用的cpu
④然后jstack 进程id,并根据线程id找到对应占用cpu资源的那一行代码并且进行修改
5.本地方法栈
定义:本地方法其实就是与底层打交道,通常用c语言底层语言写的。java通过与本地方法打交道与os进行的间接交流
本地方法栈:也就是本地方法的存储栈
6.堆
定义
new的对象就存在堆
特定
①线程不安全,共享
②垃圾回收机制
堆内存溢出
之所以会溢出是因为对象一直被使用并且不断增加。导致堆内存不足。可以通过-Xmx来调整堆内存
1.堆内存诊断
实践1_4
①创建了10mb的byte。
②然后gc之后只剩下1.6mb
③可以使用jps查看线程的id,然后再用jmap -heap xxid来查看线程占用的堆空间
④可以直接使用jconsole来查看堆空间
1_13
①通过jvisualvm查看堆内存占用的情况。发现old部分占用多,而且没办法gc清理掉。原因就是这些student不断加入到list,并且一直被使用
7.方法区
7.1定义
定义
保存class结构(方法、属性、构造方法)、类加载器、常量池
7.2组成
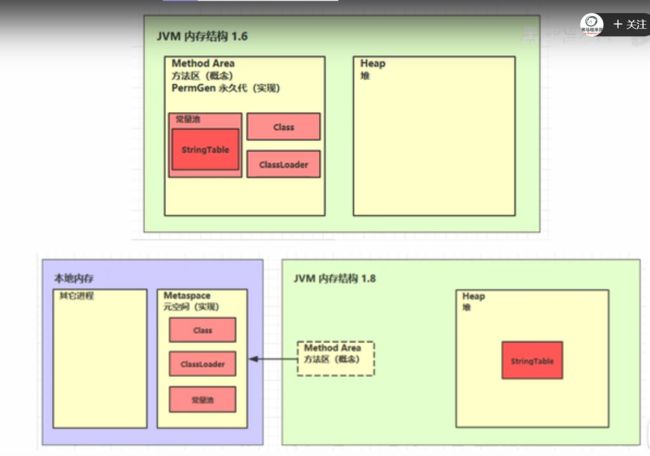
1.6它保存在堆,而且保存了常量池StringTable。但是1.8的时候交给了本地内存也就是操作系统来保存到内存的元空间里面。常量池、class、类加载器,但是StringTable放到了堆
7.3方法区内存溢出
①方法区内存溢出的原因是创建了太多类结构
②1.6是永久性内存溢出-XX:MaxPermSize=8m,1.8是元空间内存溢出需要加上-XX:MaxMetaspaceSize=8m
场景
①spring
②mybatis
他们的cglib代理类都是通过ClassWriter来完成的。也就是写了大量的类结构到方法区导致方法区内存溢出
7.4运行时常量池
①运行程序->生成字节码(包含常量池、方法以及虚拟机指令、类结构)->虚拟机指令通常都是有指向常量池的#x这样的序号,然后就去这些序号中查找对应的类,类的类型,取出的变量以及执行的方法和都需要传入的参数
②运行的常量池其实就是运行在内存中的表。并且根据表去获取类名、方法名、属性类型等
7.5StringTable
①先把常量池信息加载到运行中的常量池,实际上还只是符号。等到ldc指令执行的时候,才会把字符变成字符串对象,并且去到stringtable里面查询是否有这个字符串,如果没有那么就放进串池里
②这里的s3和s4(变量相加)不相等,原因是s4调用StringBuilder的toString实际上就是创建了一个新的对象进堆内存
③但是s3和s5相同,因为s5是两个常量,在javac编译期就能够编译结果出来,是确定的,并且在串池中找或者创建,但是s4是在运行期动态创建的,因为s1和s2都是未知对象
④只要是串池里面有的字符串,那么下次再创建同一个字符串的时候都会优先指向串池里面的字符串(避免重复创建串)
public static void main(String[] args) {
String s1 = "a"; // 懒惰的
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() new String("ab")
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5);
}
⑤1.8可以通过手动intern把新创建的串放入串池,但串池已经存在这个串,就会存入失败,并返回串池中的串。所以s!=x。但是s2获取的是串池中的串
public class StringTableTest {
public static void main(String[] args) {
String x="ab";
String s=new String("a")+new String("b");
String s2=s.intern();
System.out.println(s2==x);
System.out.println(s==x);
}
}
⑥加载字符串的时候是延迟加载,也就是如果StringTable里面有对应的字符串,那么就优先去找StringTable里面的。
public static void main(String[] args) {
int x = args.length;
System.out.println(); // 字符串个数 2275
System.out.print("1");
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print("1"); // 字符串个数 2285
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print(x); // 字符串个数
}
7.6StringTable的特性
- 常量池的字符串只是字符,第一次使用之后才是对象
- 串池机制避免重复创建
- 字符串拼接通过StringBuilder
- 拼接原理是编译期优化
- intern可以手动把字符串放入常量池。1.8如果已经放过了,那么再次intern就是无效,只能返回串池中的字符串。1.6会拷贝一份s放进去,但是s与串池的字符串对象并不相等。
7.7StringTable的位置
①1.6它是在PermGen永久代里面,但是如果大量字符串出现就会占用大量空间,永久代没有那么多空间。OutOfMemoryError: PermGen space
②1.8是放到了堆内存,解决空间问题,还有gc负责回收不使用的字符串对象java.lang.OutOfMemoryError: Java heap space
7.8StingTable的垃圾回收
只要是长期不使用,那么StringTable也会进行垃圾回收
7.9StringTable的桶优化
①实际上就是StringTable的结构是hashtable,如果大小太小,但是字符串很大,那么链表很长查询速度就很慢,但是如果大小比较大,总体稀疏那么查询速度就很快。也就是说,如果存入字符串很多,可以适当通过-XX:StringTableSize来调整桶的大小
public static void main(String[] args) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
②网上流传的案例,存入用户的地址,地址太多占用大量内存,但是串池可以把地址只保存一份,减少了大量的内存占用
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line);
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
8.直接内存
8.1定义
其实就是操作系统的内存,用于
- 数据缓冲
- 回收成本高,读写性能好
- 不受jvm垃圾回收管理
8.2释放原理
原本是使用java缓冲区和系统缓冲区的,但是问题就是这种类型需要把系统缓冲区的数据复制到java缓冲区,或者反过来,浪费了不必要的空间。但是直接内存相当于就是连接系统和java堆内存的中间商,大家都能够共享直接内存。而且直接内存是不受gc机制影响.java.lang.OutOfMemoryError: Direct buffer memory.但是底层可以使用unsafe来进行垃圾回收。也就是需要手动回收。
static int _100Mb = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
// 方法区是jvm规范, jdk6 中对方法区的实现称为永久代
// jdk8 对方法区的实现称为元空间
}


源码分析
Cleaner虚引用监视ByteBuffer对象,如果被回收那么立刻调用ReferenceHandler线程的Cleaner的clean方法进行释放直接内存
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
//用unsafe分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
//实际上是一个双向链表,并且被检测,如果发现java对象被回收,那么立刻可以调用Cleaner的clean方法
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
//Cleaner的clean方法本质也是unsafe的释放,这里的run其实就是一个线程任务被调用
public void clean() {
if (remove(this)) {
try {
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
//对应的任务处理类,这里的就是通过unsafe释放内存
private static class Deallocator
implements Runnable
{
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
//unsafe释放内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}
ReferenceHandler不断调用这个方法用于监听。一发现pending存在的时候就能够调用clean方法。
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
// 'instanceof' might throw OutOfMemoryError sometimes
// so do this before un-linking 'r' from the 'pending' chain...
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;
} else {
// The waiting on the lock may cause an OutOfMemoryError
// because it may try to allocate exception objects.
if (waitForNotify) {
lock.wait();
}
// retry if waited
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
// Give other threads CPU time so they hopefully drop some live references
// and GC reclaims some space.
// Also prevent CPU intensive spinning in case 'r instanceof Cleaner' above
// persistently throws OOME for some time...
Thread.yield();
// retry
return true;
} catch (InterruptedException x) {
// retry
return true;
}
// Fast path for cleaners
if (c != null) {
c.clean();
return true;
}
ReferenceQueue<? super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}

3.垃圾回收
1.如何判断对象可以回收
1.1引用计数法
其实就是每次被引用就加1,如果没有被引用且计数为0那么就被垃圾回收。但是无法解决循环引用的问题,A引用B,B引用A,但是没人引用他们两个,那么正常来说是需要被回收的。
1.2可达性分析算法
根对象也就是不能被回收的对象,如果被根对象引用那么就不能够进行垃圾回收,但是如果不被引用那么就要被回收。
有哪些是根对象?
- System Class
- Native Stack:压栈的方法
- Busy Monitor:锁,需要锁进行解锁,不能被回收
- Thread:线程以及栈帧的局部变量都是不能够被立刻回收的。
1.3引用
- 强引用:不能被回收
- 软引用:在内存不足的时候才会被回收(可配合引用队列释放内存)
- 弱引用:每次垃圾回收都需要被回收(可配合引用队列释放内存)
- 虚引用:相当于就是Cleaner,当垃圾回收byteBuffer的时候,那么虚引用就需要进入到引用队列,并且ReferenceHandler如果检测到队列存在Cleaner的时候就会调用clean来清除直接内存
- 终结引用:第一次gc进入引用队列,被线程监视到的时候才能够被回收。可能队列优先级很低导致迟迟不能回收。
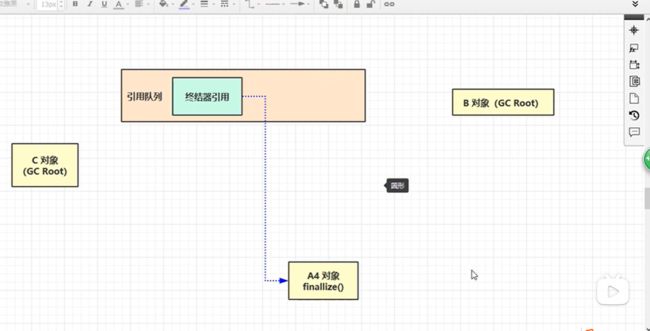

测试
如果是强引用那么如果内存不够就会溢出,软引用会进行一次垃圾回收,把软引用放到引用队列,并进行一次全面的垃圾回收还是发现没回收到空间。最后就只能回收软引用的空间。并且可以通过引用队列来删除那些已经为空的软引用对象。实际上这些对象已经被释放了。引用的原理其实是list->SoftReference->new byte[]
public class Demo2_3 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) throws IOException {
// List list = new ArrayList<>();
// for (int i = 0; i < 5; i++) {
// list.add(new byte[_4MB]);
// }
//
// System.in.read();
soft();
}
public static void soft() {
// list --> SoftReference --> byte[]
List<SoftReference<byte[]>> list = new ArrayList<>();
ReferenceQueue<byte[]> queue=new ReferenceQueue<>();
for (int i = 0; i < 5; i++) {
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB],queue);
System.out.println(ref.get());
list.add(ref);
System.out.println(list.size());
}
//删除在list的引用
Reference<? extends byte[]> poll = queue.poll();
while(poll!=null){
list.remove(poll);
poll=queue.poll();
}
System.out.println("循环结束:" + list.size());
for (SoftReference<byte[]> ref : list) {
System.out.println(ref.get());
}
}
}
弱引用测试
弱引用基本上是每次gc都会回收引用队列的最后一个引用的数据。并且在引用+数据都已经占满的情况下,需要进行一次全面的垃圾回收就是把前面所有引用的数据回收再加入新的引用。
/**
* 演示弱引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class Demo2_5 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// list --> WeakReference --> byte[]
List<WeakReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);
list.add(ref);
for (WeakReference<byte[]> w : list) {
System.out.print(w.get()+" ");
}
System.out.println();
}
System.out.println("循环结束:" + list.size());
}
}
2.标记清除算法
2.1标记清除
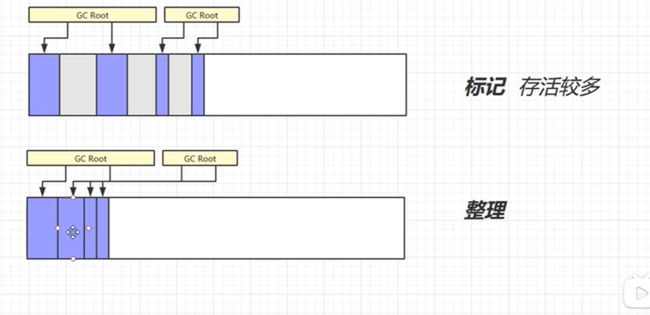
其实就是标记那些可以被清除的内存块,然后在gc的时候进行清除。通常root不能被清除。但是标记清除的问题就是造成很多内存碎片问题,导致新进来的数据无法存入。
-
速度快
-
有内存碎片

2.2标记整理
标记整理的思路就是标记那些需要清除的,然后清除之后把不能移除的内存紧紧靠在一起。问题就是这样的移动导致标记处理效率慢,需要处理转移内存块浪费很多时间,但是节省了内存
- 速度慢
- 没有内存碎片
2.3复制
标记之后,把不需要移除的内存块移动到另外一块空的内存块去,然后删除之前需要移除的内存块,最后交换from和to的内存块位置,这样好处是移动少,但是占用双倍空间.
- 没有内存碎片,速度相对较快
- 占用双倍空间

总结:垃圾回收机制会协同三种算法而不是一种做完
3.分代回收
3.1定义
新生代:相当于就是楼里面的产出垃圾立刻丢到楼下的统一垃圾桶里面。也就是频繁创建和使用时间短的对象放到新生代,并进行垃圾回收
老年代:生命周期更长,使用时间长的对象,最后在堆内存实在不够的时候才会进行清除的处理。
3.2过程
新生代的伊甸区生产新的对象,如果发现满了那么就进行minor gc,把可以幸存的对象放到to区里面,并且交换from和to的指针。到第二次满的时候再次gc,伊甸区和from区域都要把可以幸存的对象放到to,然后清除,接着还是交换from和to的指针。而且每次去到一次to生命值都会+1。如果生命周期到达老年区要去那么就去到老年代。如果老年代和from和伊甸区都没有足够大的空间,那么就要进行一次full gc全面的垃圾回收,把老年代的对象也进行一次垃圾回收。
- 新对象在伊甸园
- 新生代空间不够进行gc
- gc的时候会触发stop the world,停止用户线程,因为垃圾回收过程需要修改对象的地址。
- 生命周期越长达到阀值那么就会搬到老年代
- 老年代空间不足进行full gc
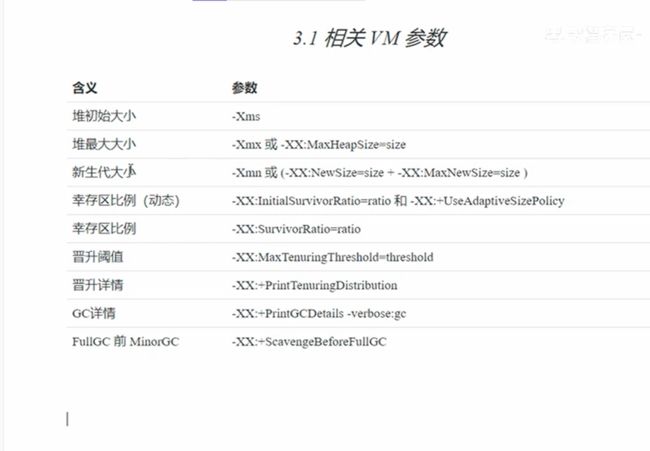
3.3GC分析
DefNew:新生代占用的内存->gc后占用的内存
新生代在加入对象不足够内存的时候,就会直接把对象塞到老年代里面去,如果老年代也内存不足,那么就会报内存溢出错误。而且一个线程导致的内存溢出是不会影响整个进程的工作的,进程仍然会执行完
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
// -Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc -XX:-ScavengeBeforeFullGC
public static void main(String[] args) throws InterruptedException {
// ArrayList list = new ArrayList<>();
// list.add(new byte[_7MB]);
// list.add(new byte[_512KB]);
// list.add(new byte[_512KB]);
// ArrayList list = new ArrayList<>();
// list.add(new byte[_8MB]);
// list.add(new byte[_8MB]);
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_8MB]);
list.add(new byte[_8MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
4.垃圾回收器
类型
①串行
- 单线程
- 堆内存小
②吞吐量优先
- 多线程
- 堆内存大,多核cpu
- 单位时间的stw时间最短 0.2 0.2 ->0.4(不计较每次垃圾回收的时间,只需要快速回收完)
③响应时间优先
- 多线程
- 堆内存大,多核cpu
- 尽可能让stw的时间短一点 每次都是0.1(每次垃圾回收时间被限制,要快速让用户线程恢复执行)
4.1串行
线程都需要执行到安全点的时候,某线程需要进行垃圾回收,那么就调用垃圾回收线程,其它线程都开始阻塞。知道垃圾回收线程执行完毕再恢复运行。其中垃圾回收器包括了Serial新生代使用的复制回收,老年代使用的是标记+整理。这里使用的回收器参数是-XX:UseSerialGC

4.2吞吐量优先
总的过程就是多个cpu线程到达安全点之后同时运行多个垃圾回收现场的线程。控制参数是UseParallelGC。其中GCTimeRatio的意思就是Gc占用的运行时间比例如果堆越大,那么需要gc的时间占比就小,但是相对的MaxGCPauseMillis的GC暂停时间变大,因为堆变大那么处理的时间也就越长。对比上一个参数意思其实就是占比时间小就是gc次数少,gc次数少就要堆大,那么就不需要频繁的gc。如果是要gc处理时间小,那么就要堆小,处理的速度才会快

4.3响应时间优先
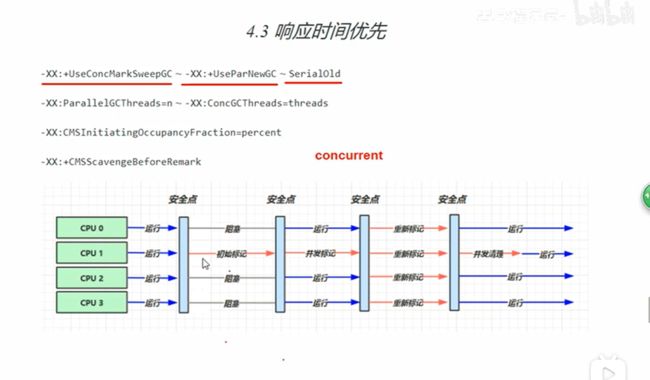
CMS(corrent mark sweep 并发,标记,清扫)
UseConcMarkSweepGC(标记清除会造成很多内存碎片)
先做初级标记,并且阻塞其它线程,然后继续让线程运行,做一次并发标记,最后就是再对所有线程做一次重新标记,防止线程修改对象的地址。然后就是其中一个线程并发处理垃圾回收。
ParallelGCThread:这个是能够并行执行的垃圾回收线程
ConcGCthreads:能够并发执行的垃圾回收线程个数
CMSInitiatingOccupancyFraction:内存占用到大什么比例需要执行垃圾回收,防止并发执行时产生垃圾无处安放
CMSScavengeBeforeRemark:新生代会引用老年代,如果这个时候新生代被垃圾回收了,那么这个查找过程就被浪费了。在重新标记之前做一次垃圾回收。防止准备变成垃圾的新生代再次查询老年代的地址。
问题:这个机制的问题就是标记清除造成很多内存碎片,如果老年代和新生代都有很多内存碎片就会导致垃圾清除失败,就需要切换成SerialOld串行单线程的整理这些内存碎片最后导致就是响应时间很慢。并发本来就是为了响应时间更快,但由于这个问题就会影响全局。
4.4G1
(1)特点
- 分区,可用于堆内存大
- 关注吞吐量、低延迟
- 整体吧标记+整理,两个区域之间使用复制。
(2)新生代:其实就是跟之前那个一样,垃圾回收会把数据放到幸存区,如果生命周期长那么可以放到老年代去。
(3)Young+CM并发加上标记:这个地方就是先初始标记那些Gc root不能被删除的对象,接着如果老年代堆内存到达阈值(45%)那么就要进行并发标记(不会STW)
E:伊甸园
S:幸存区
O:老年代

(4)Mixed Collection:主要就是对ESO进行垃圾回收,E去到幸存区,幸存区复制到另外一个幸存区,达到阈值的幸存区对象复制到老年代,部分幸存的老年代去到老年代进行垃圾回收。主要就是区域之间使用复制。这里包括了新生代回收,老年代回收,还有幸存区的回收和升级。
- 最终标记:会stw,并且是为了防止并发运行的时候产生的垃圾改变对象的引用(?)
- 拷贝存活:会stw,就是把幸存的新生代和幸存区的幸存对象复制到新的幸存区,老年代幸存的复制到空的老年代位置
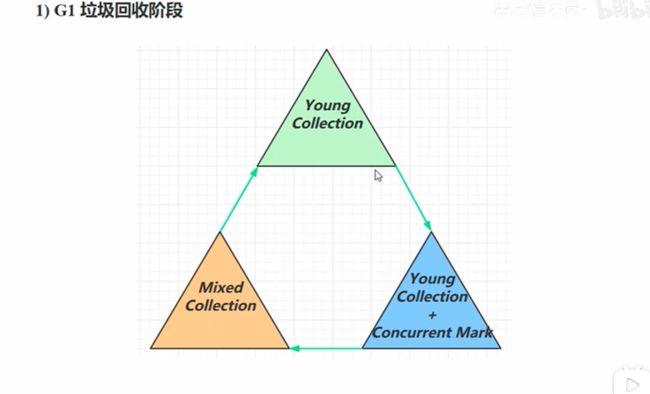
(5)总结:G1的过程就是先通过新生代的垃圾回收,如果发现空间仍然不足就会升级到新生代垃圾回收+并发标记,最后升级到混合垃圾回收最终标记+拷贝存活,总体来说就是新生代、幸存区、老年代都会进行垃圾回收机制,并且是通过复制的方式。如果最后还是并发回收失败,那么就会降级为SerialGC来征集内存空间。和CMS不同的地方就是不是全部都会进行并发标记清扫。而是先进行新生代,再逐步升级到复杂的清扫
(6)Young的跨代引用,老年代引用新生代,如果新生代需要垃圾回收那么仍然要去查询老年代谁需要引用这个对象。速度慢。解决办法可以给老年代分卡,然后每个老年代卡对应着自己需要引用新生代,如果新生代需要被回收,那么就可以通过一个线程来更新老年代的卡表。也就是对应需要引用的新生代不存在的通知和取消。

(7)Remark重新标记,其实就是如果处理完之后的对象需要重新引用白色未处理块,那么改变引用就需要把被引用的块放入引用队列,并且改变标记成灰色,标记结束之后把对应的引用块变成标记成黑色,防止这个对象被删除

(8)JDK8字符串去重
关键就是创建两个相同值的String的时候会指向不同的char[],如果开启了UseStringDeduplication那么就会查询是否有char[]相同的,如果相同那就让他们指向同一个数组。节省内存,但是消耗了cpu的时间.
(9)并发标记类卸载
其实就是那些不用的类卸载,如果类加载器的所有类都不使用那么那么就卸载掉这个加载器的所有类
(10)巨型对象回收
如果对象内存占据大于区的一半以上,那么就是巨型对象
- G1不进行拷贝
- 如果老年代的卡没有指向对应的巨型对象那么就回收
- 优先考虑回收巨型对象
(11)JDK9并发标记时间调整
为了防止回收跟不上产生垃圾速度,可以动态调整InitiatingHeapOccpancyPercent的值,也就是垃圾占比多少的时候进行垃圾回收。可以通过数据采样来决定这个值。
5垃圾回收调优
5.1区域
①内存
②锁竞争
③io
④cpu占用
5.2目标
①低延迟高吞吐量
②高吞吐量可用回收器:Parallel
③低延迟可用回收器:CMS、G1
5.3最快的GC是不发生GC
①数据是否过多:可以会用sql的limit
②数据是否太臃肿:比如对象太多,可不可以修改对象为基本类型Integer24->int4,有没有多余的对象
③内存泄露,static Map map不断添加会导致内存溢出,最好就是使用软引用或者弱引用又或者是第三方的缓存方式
5.4新生代调优
新生代特点
- TLAB线程局部内存,也就是线程的私有内存防止并发分配错误
- 回收代价0
- 对象用完基本会死,老年代的gc使用时间更长
- minorGc时间远小于fullGc
新生代是不是越大越好?
并不是,如果新生代大,那么老年代就会小,如果老年代空间不足那么就会频繁触发full gc,导致清扫时间很长。也就是如果新生代堆太大最后导致清扫时间也会相应变大,所以位置在四分之一或者是二分之一的堆内存是最好的
新生代的gc主要花费在复制上而不是标记上,但是由于用完即死的特点导致最后复制时间很短也就是实际的gc时间很短所以新生代的内存还是要尽可能的大。最好是并发量*(请求+响应)那么刚好进来这么多,用完即死,所以新生代是有足够内存处理的,比较少触发full gc
幸存区的大小?
幸存区有活跃和晋升对象,如果幸存区太小,那么晋升就要提前,如果有的对象生命周期并不是那么长就有可能一直占用老年代,等待full gc才能够清理掉。但是生命周期长的对象也要尽快晋升,而不是一直停留占用幸存区

5.5老年代调优
- CMS的老年代内存越大越好
- 通常尝试对新生代进行调优
- fullgc的时候给老年代预留空间,防止并发产生垃圾没地方放
-XX:CMSInitiatingOccupancyFraction=percent
CMS的老年代内存占比到一定比例那么就会触发fullgc。
5.6案例
1.fullgc和minor gc频繁
就会导致晋升快,老年代需要频繁fullgc,因为生命周期不长的对象也分配到老年代。这个时候老年代就需要gc。解决方法就是先把新生代内存增大,内存充裕那么gc自然就减少了
2.CMS中单次暂停时间很长
原因就是老年代引用新生代,需要进行老年代的扫描也要进行对新生代的扫描,新生代数量在高峰,这个时候可以先进行一次CMSScavengeBeforeRemark,在标记之前进行一个垃圾回收,然后再进行标记。
3.老年代充裕,但是频繁full gc(CMS JDK1.7)
原因就是jdk1.7的时候使用的是永久代,如果永久代的空间不足也是会频繁触发fullgc的,1.8是用的是os的内存也就是元空间,空间相对来说比较充足。
4.类加载和字节码
4.1类文件结构
①魔数,0-3字节
②版本 ,4-7字节

③常量池
0a表示方法,0006表示所属类,0015表示方法名。通常就是去0a也就是第十项的位置找对应的二进制提示符,通常是提示字符串的编码、长度以及内容。后面所属类和方法名都是同样的方法在常量池中寻找。如果是07或者09这种表示类型,那么后面跟着的4个字节就是需要查找的位置。

总结:常量池主要就是记录方法、类、变量等的信息
④访问标识和继承信息
class是不是公共的,在常量池中找class的全限定名和父类的全限定名等。
⑤成员变量信息
搭配着一些FieldType类型,比如B->byte,[->数组,L->引用等。

⑥方法

⑦附加属性,sourceFile->HelloWord.java
4.2字节码指令
2a调用this,然后b7预备调用,0001就是常量池的构造方法串,b1就是返回

b2 0002先准备好对象,1203准备好参数helloworld,嘴壶才是04b1调用println方法。这里的顺序其实就是先准备好对象和参数,最后才调用方法,而不是对象调用方法再加上参数。invokevirtual调用方法。

4.3运行流程
①java文件编译
②常量池加载到运行时常量池(方法区)
③把字节码指令加载到方法区
④main线程运行,分配局部变量栈帧和操作数栈帧(包括数据和字节码指令)

⑤执行指令(如果数字比较小放到指令中,如果数字很大那么就要放到常量池中)
bipush把10压入操作数栈中
istore 1把操作栈顶弹出10,放到局部变量的1号栈帧里面去。
ldc #3把常量池加载到操作数栈
istore 2把栈顶元素放到局部栈第二个位置
iload 1和2 把局部栈的1和2弹出放到操作数栈
ladd进行计算
istore 3计算的值弹栈到槽3
getstatic #4 找到堆中的对象放入栈
iload3 槽3数据放入操作栈
invokevirtual #5调用方法println,并且生成新的栈帧。


(1)分析a++ + ++a + a–的值。这个时候a=10;
实际上a++的顺序是先iload到操作数栈再在局部变量上面+1,但是++a就是在局部变量里面+1之后再压栈到操作数栈。那么结果就很明显了,因为a++没有处理就放进操作数栈所以是10,这个时候局部变量才+1,++a就是在局部变量先+1也就是现在的11+1之后再压栈,所以是12.最后a–,那么肯定就是先把12压栈之后再在局部栈中-1。最后结果肯定就是操作数栈的10+12+12=34了。
字节码分析其实就是
a++
iload a 到操作数栈后在进行iinc其实就是局部变量表的自增
但是++a就是iinc之后再压栈到操作数栈。
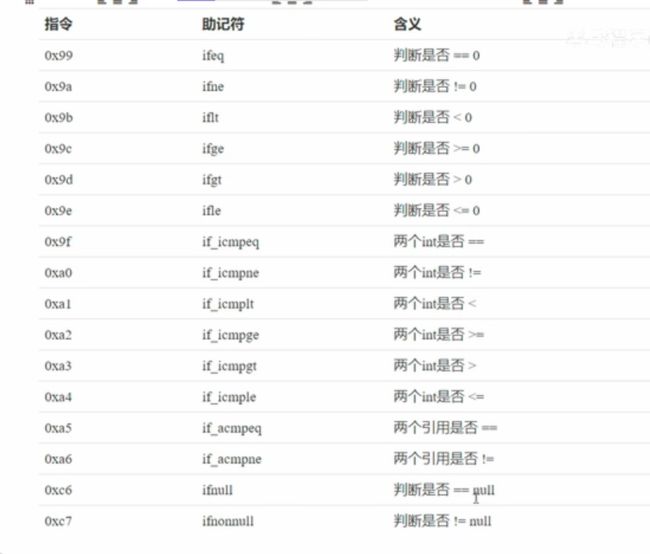
⑥条件助记符
主要是条件判断指令 ifne等常用的。
while和for循环基本上字节码相似。iconst_x赋值,之后istore到iload到操作栈,再放进去一个bipush x比较,如果成功跳转到结束为位置,如果不成功那么就往下执行,并通过goto反复比较。
byte、char、short按照int 4个字节进行处理。
(2)x++练习
这里的思路其实就是根据x++,x(0),先把0压到操作栈,然后再给局部栈的x+1,然后再给局部栈x赋值为操作栈中的0。那么x还是等于0。无论多少次循环都会是这样

(3)构造方法
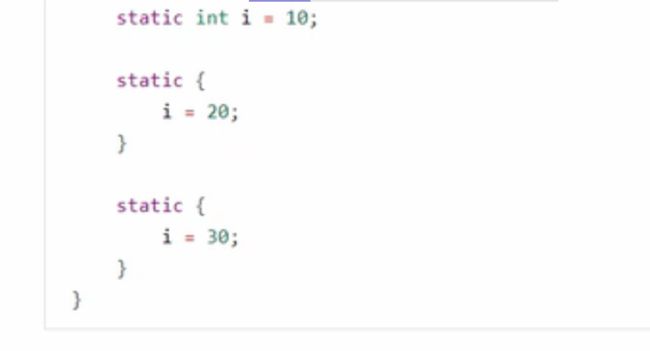
①cinit
构造方法里面的static静态代码块处理或者变量都会整理成方法< cinit >()V来从上到下排序进行处理,并且给方法区开辟空间给这个变量i。bipush之后就是putstatic #x(常量池的位置也是方法区的位置)。
②init
先把其它构造代码块从上到下重构成一个新的构造方法,最后才是把原始构造方法放进去。然后就是aload_0就是this的意思,然后就是bipush这些方法区的参数到操作栈,接着把操作栈得到的参数赋值给属性,也就是通过putfield #x也就是给this.?进行赋值,?由#x常量池得到的字符决定属性的命名。如果是原始构造方法就是slot(局部栈位置) a "值1"也就是aload_1把参数放到局部栈第一个槽,或者是slot(局部栈位置)b "值2"第二个槽,接着就是putfield给对应的属性进行赋值。


(4)方法调用
private 调用的是invokespecial
public调用的是invokevirsual
static调用的是invokestatic
当new对象的时候就会把对象放到堆内存,并且把引用压栈到操作栈里面,dup复制一份引用完成构造方法的处理。然后才把引用astore 1放到局部栈里面。接着就是aload 1放到操作栈调用对应的方法invokexx。如果是静态方法,那么就会把操作栈的引用弹出直接invokestatic方法。


(5)多态原理
它会有一个vtable里面全部是多态覆盖写的,它会根据vtable里面的方法来调用对应的覆写的方法。这个vtable在链接的时候根据方法重写规则已经写好了。接着再查表获取对应的地址。
小结
①先拿到引用找到对象
②分析对象头,找到对象的class
③根据class写好的vtable找到方法的地址
④执行这段的字节码
(6)异常
①单个异常
trycatch结构会有一个异常表监视这个try结构,如果出现对应异常,那么就会根据异常表的位置from to和出现异常之后跳转的target目标,后面还有一个异常类型,如果这个异常符合条件那么就进行跳转处理。

②多个异常与muti-catch基本相似
多个异常不同的地方就是异常表对应异常更多,并且异常引用共用一个槽位。然后再aload取出异常引用调用它的方法invokevirsual

③finally
实际上就是给try或者是catch分支赋值上一份finally需要执行的字节码,也就是给i赋值。实际上就是给bipush 30之后istore_1赋值给i。而且还有一些捕获不了的Error给他们一个引用槽,并且在这个error的分支也加上finally字节码处理。赋值之后aload_3把异常引用取出,并且athrow抛出异常

finally面试题1
这个题会返回20。因为try里面的10会被压栈到局部变量,优先执行finally的。而且如果finally出现了return,那么就会把异常吞掉。就是没有办法调用引用的异常方法或者是athrow

finally面试题2
这里的finally的i=20,最后返回的是10原因是在try里面的return会把slot0里面值放到操作栈,操作栈把它固定到slot1里面,最后再执行i=20的操作,也就是把20存入slot0而已,最后是iload_1把slot1放到操作数栈然后再返回的。

④synchronized
锁如何进行解锁?先创建对象,存入slot1,然后取出之后复制一份,存入slot2。接着就给lock对象加入到监视的锁的行列。然后如果没有出现异常,那么取出slot2的lock进行退出监视锁,相当于就是解锁。如果出现异常那么还是会调用解锁的操作。

4.4语法糖
(1)默认构造器
如果我们没有写构造器那么就会在编译成字节码的时候自动加上。
(2)自动装箱拆箱
装箱原本需要Integer.valueOf(x),拆箱是x.intValue()。在jdk5之后直接可以赋值。而不需要明面上的装箱和拆箱,它会在编译期间进行处理。
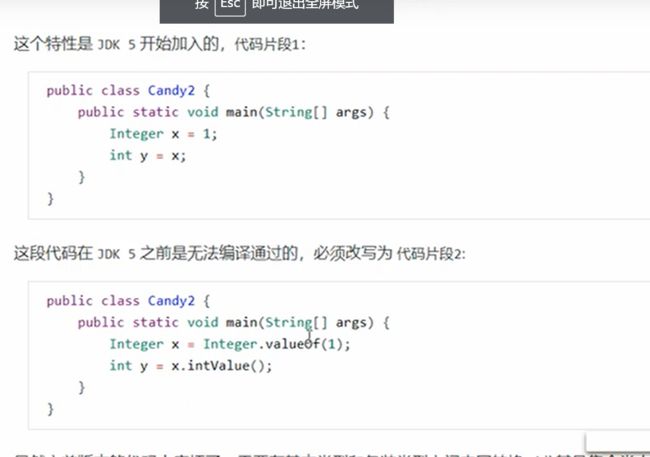
(3)List的add方法优化
实际上就是add的是Object,但是在加入之前先把数据自动装箱为Integer,在取出来的时候仍然是Object,但是可以通过checkcast来把取出来的对象转换成Integer。

(4)泛型反射
可以通过反射获取方法的参数的类型,然后再通过参数类型获取对应的泛型。这些泛型通常会放到LocalVariableTypeTable里面。
(5)可变参数
可变参数实际上就是根据参数的个数转换成数组。这个是编译器做的。
(6)foreach
数组本质就是for(int i;i 比较的是hashCode然后再比较String最后才得出x到下一个switch里面判断和执行代码。 这里的枚举类相当于就是把对应的枚举码创建一个新的合成类,并且创建一个数组,与枚举码进行对应。在switch的时候直接使用这个参数在数组取枚举码. 实际上就是一个public final class继承Enum,并且class只有有限个对象,并且存入数组中。这个数组交给了父类Enum。要取枚举类对象的时候就要去父类的数组中取,是一个hashMap的数据结构,传入class的类型和枚举类对象的name就能够获取对应的对象。 这种相当于就是自动关闭资源。实际上增加了一个trycatch,主要就是看业务代码是否出现异常,如果出现异常就给t赋值异常,并且执行finally的trycatch,这个就是为了关闭资源的关闭错误异常,如果再次出现异常那么就给t加上一个压制异常,也就是关闭异常和业务异常都不会丢掉。 实际上就是子类的返回值可以是父类返回值的子类。它的本质就是重写了返回父类返回值子类的一个方法,然后再写一个桥接方法 synthetic bridge来返回父类返回值的类型,但实际上是调用了子类重写的方法,但是把返回值类型强转成父类。 实际上就是创建一个新的类,如果有引用的参数那么就变成新的类的属性。并且通过构造方法传入进来。为什么参数是一个final?原因是创建属性的时候这个属性名是valx,这个x要保持不变才行,如果变了就没办法创建另一个新的类,因为这是在编译期中处理的。 其实就是把javamirror指向对应的java类对象,类对象存储在堆内存但是有instanceKlass(方法区中的类对象信息)的地址,如果我们创建了多个对象,那么可以通过对象头获取类对象的位置,然后访问类对象的instanceKlass的地址,找到类对象的所有信息。 在编译的时候jvm会先验证格式是否正确.如果不正确无法进行编译处理。 这里的static变量存储在类对象上,也就是存储在堆中。如果是final那么就不会进行赋值,而是现在准备阶段进行处理。如果没有final或者是new 引用类型那么就要在初始阶段进行创建赋值处理。 如果没有解析那么只是符号引用无法知道符号的位置和地址。但是解析之后就能够知道准确的类的地址和位置。new C()会处理解析,但是loadClass是不会进行解析的,仅仅只是加载 不会初始化 ①访问静态final属性 ②类对象.class在加载阶段生成 ③创建类数组 ④loadClass ⑤Class.forName第二个参数是false的时候 会初始化 ①访问静态变量或者方法 ②子类初始那么父类也会初始化,而且父类更快 ③子类访问父类,只会父类初始化 ④Class.forName 而且有main方法的类优先初始化。 练习 这里的c会自动装箱那么就会创建对象导致的E会初始化。 练习2 这个地方只有调用了内部类的静态方法或者是静态属性的时候才会初始化,不然只是初始化Singleton是没有任何作用的。 Bootstrap ClassLoader启动类加载器->/jre/lib Extension 扩展类加载器->jre/lib/ext Application ClassLoader 应用类加载器->classpath 自定义类加载器。 他们是从上到下一层一层递减,当类加载器需要加载类的时候回去问上级是否加载过,如果没有再从本类加载器里面去加载这个类 如果是启动类加载器需要手动把对应的类放到lib下,并且启动这个启动类加载器,加载类之后返回的类加载器是null。如果是Ext扩展类加载器就要放到ext目录下,然后再加载类之前app会优先去问Ext是否加载过这个类。这种模式是双亲委派模式 整个过程其实就是ServiceLoader传入线程的上下文类加载器,实际上就是appClassLoader。然后获取loader下的Iterator,这里遍历的是meta下面services的接口全限名,SPI。然后通过next()方法来用appClassLoader进行加载类。实际上调用的是lazyIterator的next再调用nextService()这里的关键方法就是Class.forName来加载这些接口的实现类。 使用情况 步骤 只要同一个类加载器和同一个类才能够被认为被加载的类是同一个。 总结:类加载相当于就是把类对象加载到堆内存里面,类对象信息加载到方法区也就是元空间上。初始化指的是真正给类对象分配内存地址和位置 加载->验证(文件是否符合解析规则)->准备(给静态变量等赋值)->解析->初始化 jvm的5种状态 ①解释器:把语句解释成字节码再解释成机器码 ②JIT即时编译器:C1不带profile ③C1带基本profile ④C1带完全profile ⑤C2 速度是解释器 其实就是如果多次调用方法并且返回值相同的时候,就会把这个返回值直接复制到输出或者使用的位置。如果后面发现使用非常多就会直接把这个返回值当成常量处理,减少了字节码的编译和解释。从而加快了速度 这里的思路其实就是如果提前把成员变量赋值给局部变量那么就能够减少直接访问成员变量的次数。局部变量的机器码被缓存,但是成员变量访问每次都要进行解释浪费很多时间。也可以自己手动优化,直接创建一个局部变量并且进行赋值。(仍然存在疑问) 如果方法反射调用多次并且大于infrationThreshold,会在运行期间修改方法访问器,加快访问的速度。实际上运行时生成的方法访问器是直接访问类里面的方法而不是通过反射了。这样可以加快速度。我们也可以调整infrationThreshold的值或者干脆不要这个值直接生成新的方法访问器来访问。但是第一次生成需要比较长的时间所以还是要看访问的次数怎么样 定义 jmm定义一套多线程读写共享数据对数据可见性有序性和原子性的保证和规则。 这里其实就是在通过抢锁,然后monitorentry进入到owner的位置才能够执行代码。其它就在entryList里面等待。主要就是保证每次只能有一个线程来执行代码块,防止并发问题。synchronize的优化可以直接框住for,而不是在for里面,如果在for里面那就要经常锁住和解锁。但是在外面的话就能够只进行一次开锁和解锁操作。 如果5000个自增和自减在不同线程执行那么结果是不是一定就是0? 答案是错的,原因就是自增和自减并不是原子性操作。那么就有可能导致字节码交错执行。有可能不同线程取出来的数字都是同样的,那么最后put进去的值就以最后一个线程put进去为准,那么这种就没办法抵消。本质上就是因为操作并不是原子性,可以交错执行(并发的原因)。这里的一个内存模型实际上就是i在主内存,线程都是通过复制一份主内存放到自己的操作栈里面处理,然后再放回去。导致交错执行可能取的是同一个i值。 下面代码就算修改了也没办法阻止线程停止。原因是线程多次循环取出run变量之后,JIT把这个run变量放到了线程的高速缓存,那么线程取的就是缓存的run,就算是主存里面的run修改,线程也并不会停止。 解决办法 ①synchronize能够保证原子性也能保证可见性,但是是重量级别性能比较差。sout里面就包含synchronize所以线程输出1是会停止的。只要是线程里面有synchronize就能够保证可见性 ②volatile保证可见性但不能保证原子性。但是轻量级性能比较高。 这里其实是指令重排导致的num=2执行在ready之后,接着就被切换到线程1那么通过之后就是0+0最后得到的答案就是0的结果。 解决方式:volatile修饰这些变量,禁止指令重排 下面这种情况的双重检查的单例仍然是会出现指令重排问题,因为初始化比较慢,所以先执行把对象地址也就是引用赋值给属性变量。但是这个时候并没有初始化。如果有另外一个线程调用了getInstance就会导致对象实际上没有完全初始化,可能导致某些方法使用失败的问题。解决办法可以给属性加上volatile来禁止指令重排 Compare and swap其实就是比较之后才能够修改结果。旧值赋值一个共享变量,如果需要修改这个旧值那么就要和共享变量对比之后才能够修改。如果不正确那么就不能修改。这个是乐观锁的机制。乐观锁用的是version。他和synchronize相比的好处就是synchronize需要阻塞其它线程然后才执行代码,接着还需要恢复其它线程的运行耗费大量的资源。但是乐观锁机制只需要进行旧值对比即可。相对效率更高。 这个案例其实就是通过offset来定位类的属性data的位置,相当于就是共享变量,然后再取出旧值,赋值给oldValue。这个时候相当于就是固定好了旧值,但是共享变量可能会被改变,这时候就要通过底层的unSafe来调用CAS指令,传入共享变量偏移定位本类属性和旧值进行对比,最后成功之后直接返回 实际上是JUC包里面的类。具体的技术就是CAS+volatile保证可视化和乐观锁防止并发问题的操作。 对象里面有对象头,包括指向class的指针和markword。markword主要包括了hashCode、分代年龄和在加锁的时候会变成标记位(这是一个什么锁) 相当于就是占座的时候用课本还是用铁栅栏。如果是课本那么就是轻量级锁,如果有人不管这课本竞争占座,那么就要铁栅栏围起来。相当于就是锁升级了。但是轻量级锁就相当于是课本这样的占座 过程 A代码块执行的时候有synchronize,那么这个时候就会把锁的mark赋值线程1的锁记录,然后把锁记录的地址交给锁的markword。那么这个时候执行B同步代码块,先把这个mark复制到线程1的锁记录,然后CAS修改锁的markword但发现失败。然后查询发现是自家的锁,可以锁重入然后继续执行。执行完之后解锁,并且把00改成01。 相当于就是线程1执行同步代码块的时候,线程2也想要执行。线程1已经用CAS给锁的mark修改成锁记录的地址,线程2修改失败之后,CAS给这个mark改成了重量级锁的指针。并且状态码改成10也就是重量级锁,并且阻塞线程2. 线程1用了重量级锁,那么这个时候线程2就要进行等待或者直接阻塞。阻塞恢复和关闭线程都需要大量资源,那么这个时候可以使用自旋锁,相当于就是while(true)旋多几次等待锁,但是如果线程1占用时间长那么自旋也会失效。通常自旋成功一次之后线程就会自适应旋多几次。而且不一定要自旋,因为如果是单核的cpu那么自旋只会占用cpu的时间,自旋通常是多核等待锁,那么才有资源运行线程。 相当于就是把线程id修改到mark去。而不是使用CAS来进行修改锁记录地址到mark,减少锁重入浪费的时间。在别的线程要用锁的时候会直接对比线程id。(7)switch
(8)switch enum

(9)枚举

(10)try() catch

(11)桥接方法
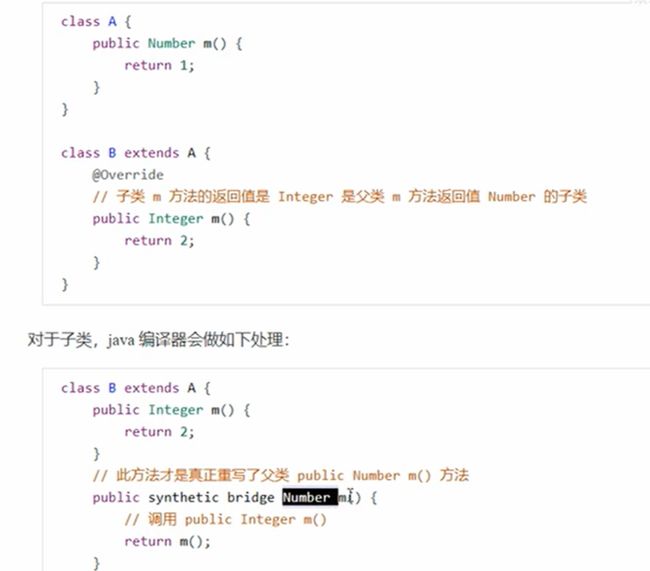
(12)匿名内部类

4.5类加载阶段
(1)加载

(2)连接
连接验证
连接准备
连接解析
(3)类初始化阶段


4.6类加载器
(1)分类
(2)双亲委派的源码分析
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
//先看这个类是否加载
Class<?> c = findLoadedClass(name);
//没有加载
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//去到上级中看看是否加载
c = parent.loadClass(name, false);
} else {
//去到启动类加载器看看是否加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
//如果都没有
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//直接在类路径找这个类并且加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
(3)打破双亲委派的Drivers
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// If the driver is packaged as a Service Provider, load it.
// Get all the drivers through the classloader
// exposed as a java.sql.Driver.class service.
// ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//使用serviceLoader来进行加载
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
//这里就是lazyIterator
Iterator<Driver> driversIterator = loadedDrivers.iterator();
/* Load these drivers, so that they can be instantiated.
* It may be the case that the driver class may not be there
* i.e. there may be a packaged driver with the service class
* as implementation of java.sql.Driver but the actual class
* may be missing. In that case a java.util.ServiceConfigurationError
* will be thrown at runtime by the VM trying to locate
* and load the service.
*
* Adding a try catch block to catch those runtime errors
* if driver not available in classpath but it's
* packaged as service and that service is there in classpath.
*/
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
//本质还是通过appClassLoader加载Driver类
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
public static <S> ServiceLoader<S> load(Class<S> service) {
//线程上下文类加载器->app
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
private class LazyIterator
implements Iterator<S>
{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
//实际上就是app加载器
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
//主要代码
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
//next调用nextService来加载接口的实现类
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
//本质在调用lazyIterator
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
(4)自定义类加载器
public class Load7 {
public static void main(String[] args) throws Exception {
MyClassLoader classLoader = new MyClassLoader();
Class<?> c1 = classLoader.loadClass("MapImpl1");
Class<?> c2 = classLoader.loadClass("MapImpl1");
System.out.println(c1 == c2);
MyClassLoader classLoader2 = new MyClassLoader();
Class<?> c3 = classLoader2.loadClass("MapImpl1");
System.out.println(c1 == c3);
c1.newInstance();
}
}
class MyClassLoader extends ClassLoader {
@Override // name 就是类名称
protected Class<?> findClass(String name) throws ClassNotFoundException {
String path = "e:\\myclasspath\\" + name + ".class";
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
Files.copy(Paths.get(path), os);
// 得到字节数组
byte[] bytes = os.toByteArray();
// byte[] -> *.class
return defineClass(name, bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
throw new ClassNotFoundException("类文件未找到", e);
}
}
}

4.7运行期优化
(1)逃逸分析
// -XX:+PrintCompilation -XX:-DoEscapeAnalysis
public static void main(String[] args) {
for (int i = 0; i < 200; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
new Object();
}
long end = System.nanoTime();
System.out.printf("%d\t%d\n",i,(end - start));
}
}
(2)方法内联
// -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:CompileCommand=dontinline,*JIT2.square
// -XX:+PrintCompilation
public static void main(String[] args) {
int x = 0;
for (int i = 0; i < 500; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
x = square(9);
}
long end = System.nanoTime();
System.out.printf("%d\t%d\t%d\n",i,x,(end - start));
}
}
private static int square(final int i) {
return i * i;
}
(3)字段优化
(4)反射优化
public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {
//方法访问到达一定的次数
if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {
MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());
this.parent.setDelegate(var3);
}
return invoke0(this.method, var1, var2);
}

5.JMM(java Memory model)
5.1JMM内存模型
(1)JMM的原子性synchronized
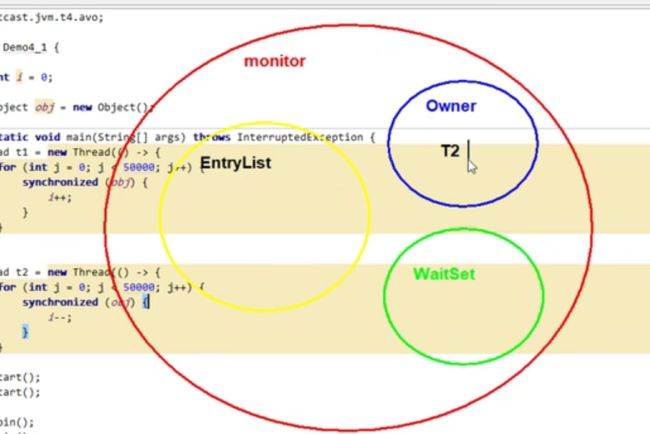

5.2可见性
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
System.out.println(1);
}
});
t.start();
Thread.sleep(1000);
run = false; // 线程t不会如预想的停下来
}

5.3有序性
(1)诡异的结果
(2)有序性的解决办法
(3)有序性的理解

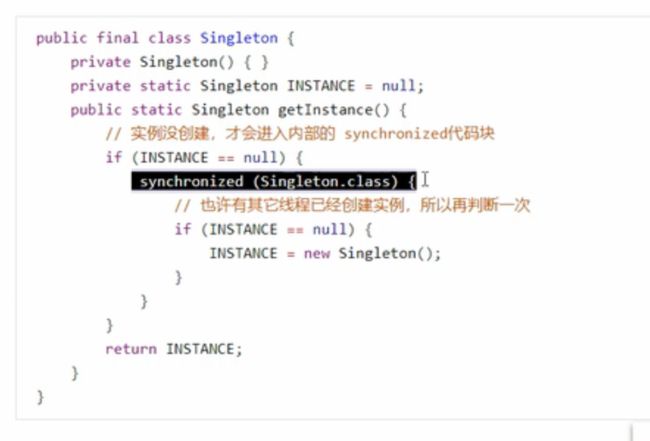
5.4CAS和原子性
(1)CAS


(2)原子操作类
5.5synchronize优化
(1)轻量级锁
(2)锁膨胀
(3)自旋锁
(4)偏向锁
(5)其它优化

