Redis八种数据类型详解
1、基本使用
-
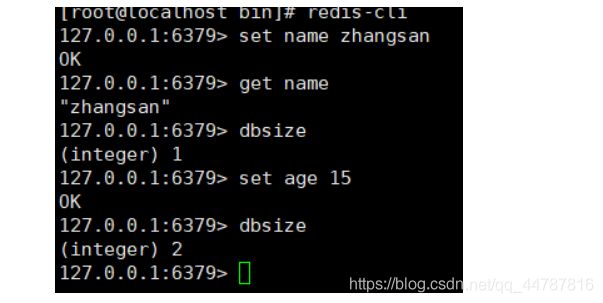
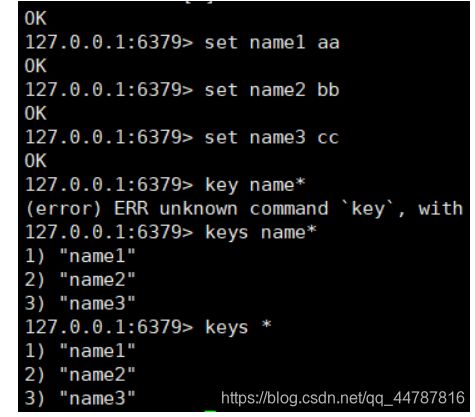
通过set 设key value 。通过get key 取对应的key 取value ,使用dbsize 查看当前数据库 数据个数。
-
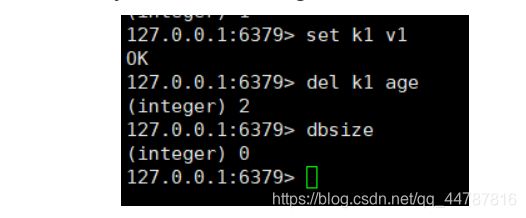
通过 del key … 可以删除多个key对应的value ,integer表示 删除成功数
-
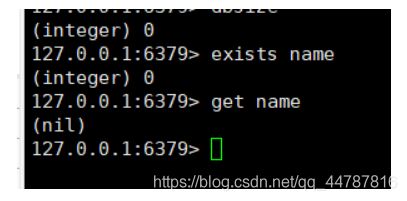
exists key 判断对应的key是否存在,nil表示null
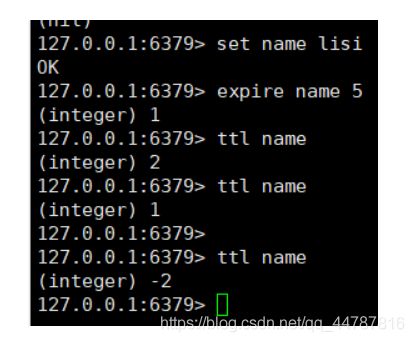
- expire key second 设置对应key的过期时间,ttl key 查看key过期没有,如果过期时间到了redis会移除过期key
- ** keys * ** 查看当前数据库中,所有的key ,keys xxx* 查看当前数据库中以xxx开头的key
-
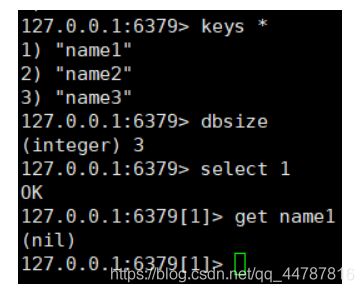
不同数据库数据是独立的,目前不能从其它数据库查数据
select 数据库编号 ## 选择数据库
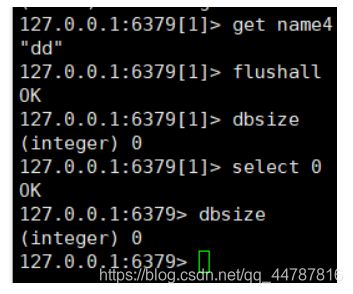
- flushall 清除所有数据库数据,flushdb清除当前数据库数据
-
move key index 将指定的key 转移到指定的数据库
move name 1 -
persist key 移除key的生存时间 使key永久生效
redis> SET mykey "Hello"
OK
redis> EXPIRE mykey 10 # 为 key 设置生存时间
(integer) 1
redis> TTL mykey
(integer) 10
redis> PERSIST mykey # 移除 key 的生存时间
(integer) 1
redis> TTL mykey
(integer) -1
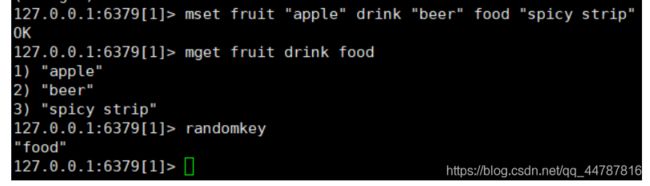
- mset 设置多个key value , mget 获取多个value,randomkey 随机取key
-
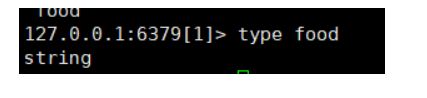
type key 返回数据的 数据类型
返回 key 的数据类型,数据类型有:
- none (key不存在)
- string (字符串)
- list (列表)
- set (集合)
- zset (有序集)
- hash (哈希表)
-
select index 切换数据库
select 1
2、字符串(String)
-
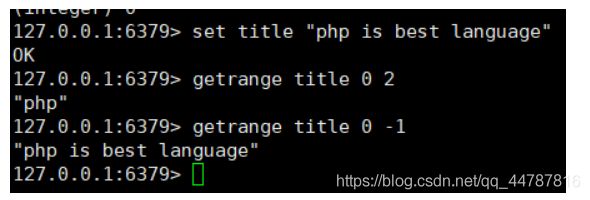
getRange key start end 获取指定key指定范围的值 注意与java不同这是 左右都是闭包【】
-
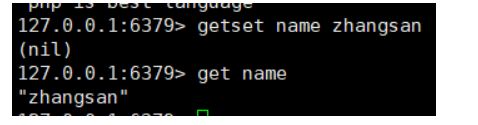
getset key value 先获取key的值,在设置value
-
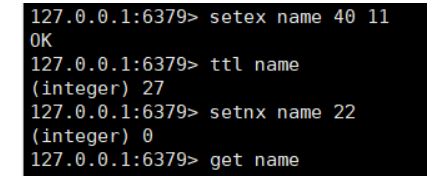
setex (expire)key second value 设置key的存在时限。**
setnx (not exists)key value** 设置一个数据库中没有的key, 如果该key存在设置失败(如果存在的,会覆盖原有的key,并给与新的生存时间)
-
setRange key index newValue 为指定key的值修改数据 从index位置开始
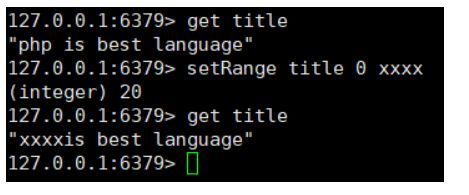
-
incr key 实现key值的自增 注意:key的值value 必须是数字,但还是以字符串保存
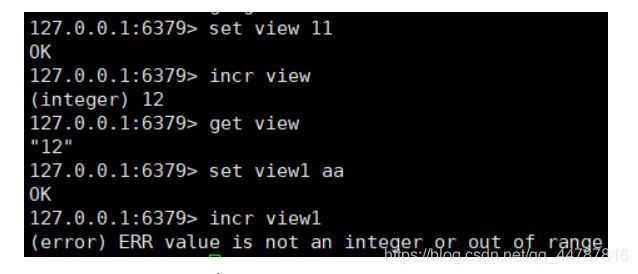
-
incrBy key increment 对key值指定增量自增 , decrBy,decr 同理
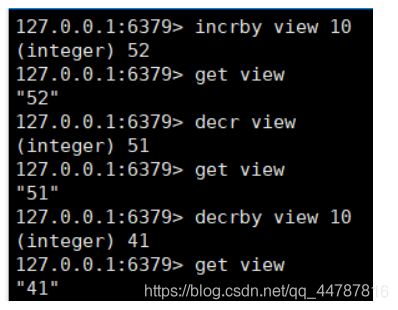
-
append 实现数据追加

-
set key value
set user:1 {username:zhangsan,age:1}
3、哈希(hash) 命令(几乎以H开头)
redis hash 是一个(String类型的)field 和 value 的一个映射表,一般用来存储对象。(一个hash表 表示一个对象,一个对象中有多个 k,v值(f,v值))
Redis 中每个 hash 可以存储 2的32次方 - 1 个键值对(40多亿)
可以将hash理解成 一张表 表有多个键值对组成
-
创建一张 hash表作为key 里面封装这多个key value
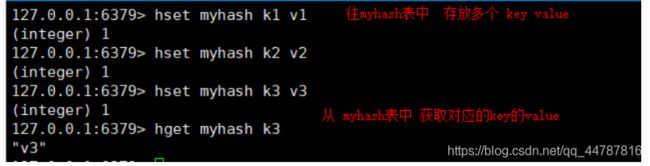
-
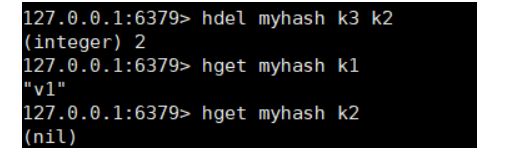
hdel key(表) field ,hget key field , hset key field value 从myhash表中删除field对应的值
-
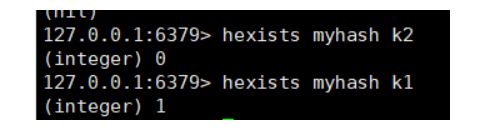
hexists key(表) field ,从hash表中 查看对应field字段是否存在,存在打印1,否则0
-
hgetAll key(表) 从hash表中 获取所有的字段 和值

-
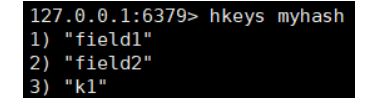
hkeys key 获取表中所有的 field
-
hLen key (表) 获取表中数据的数量

-
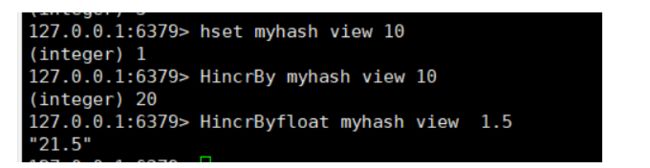
HincrBy key(表) field increment 对指定hash表中某一字段 增量相加 没有key的话会自动创建哦
HincrByFloat key field increment 对某一字段值 进行浮点增量增加
-
Hmget 获取hash表中 多个指定字段的值
Hmset 往hash表 中 设置多个值

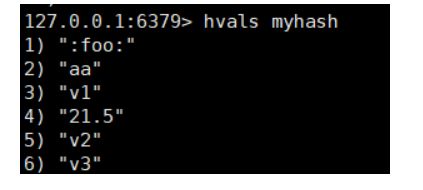
- Hvals key 返回hash表中 所有字段的值
4、列表(list) 命令(几乎以L开头)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 2的32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
注意:虽然list 本质上是一个key 但是不能用 get lists 获取list中的值
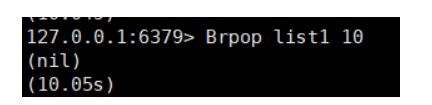
- Blpop key timeout (list表) 从列表左边中弹出一个值,并指定超时时间,若列表中没有值,会阻塞列表,直到超时后才打印nil(null)/直到有元素 进入列表

-
BRpop 同理
-
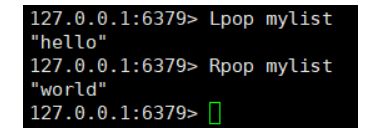
Lpush key(表) Rpush key 在表的左右两端,往表放值

- Lpop Rpop 同理 取值
- Llen key 获取list长度

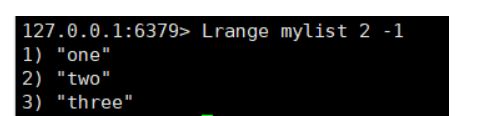
- Lrange key start end 获取指定list范围中 的 数据
- Ltrim key start end 对指定范围的数据 修剪保留
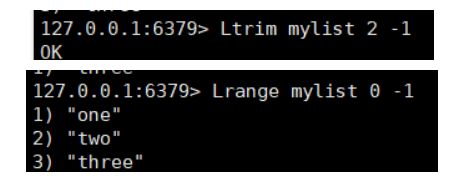
- 剩下的具体看文档
5、集合(set)(命令以S开头)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
-
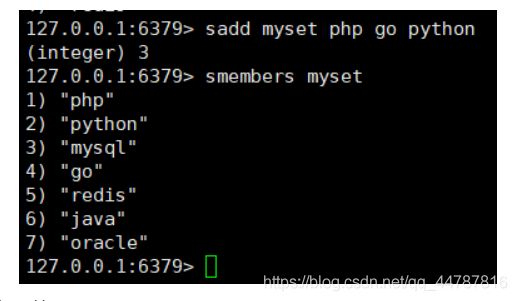
sadd key (set集)value… 往set中存放多个值 , smembers key 输出set中全部的元素
-
scard key 输出set中元素的数量

-
sdiff key1 key2 比较两个集合的差异
redis> SADD key1 "a" (integer) 1 redis> SADD key1 "b" (integer) 1 redis> SADD key1 "c" (integer) 1 redis> SADD key2 "c" (integer) 1 redis> SADD key2 "d" (integer) 1 redis> SADD key2 "e" (integer) 1 redis> SDIFF key1 key2 1) "a" 2) "b" -
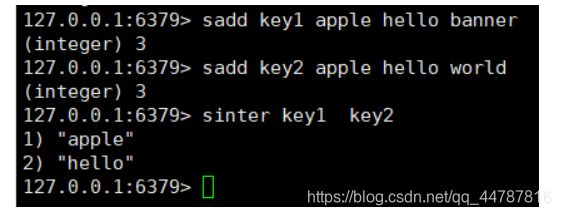
sinter key 1 key2 取两个集合的交集
-
sInterStore destination key1 key2 取两个集合的交集 存储在 destination中
redis 127.0.0.1:6379> SADD myset1 "hello" (integer) 1 redis 127.0.0.1:6379> SADD myset1 "foo" (integer) 1 redis 127.0.0.1:6379> SADD myset1 "bar" (integer) 1 redis 127.0.0.1:6379> SADD myset2 "hello" (integer) 1 redis 127.0.0.1:6379> SADD myset2 "world" (integer) 1 redis 127.0.0.1:6379> SINTERSTORE myset myset1 myset2 (integer) 1 redis 127.0.0.1:6379> SMEMBERS myset 1) "hello" -
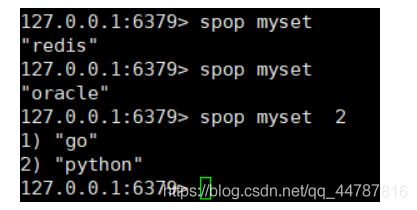
Spop key count 随机中set中取出count个 数据
-
sunion key1 key2 合并两个集合
-
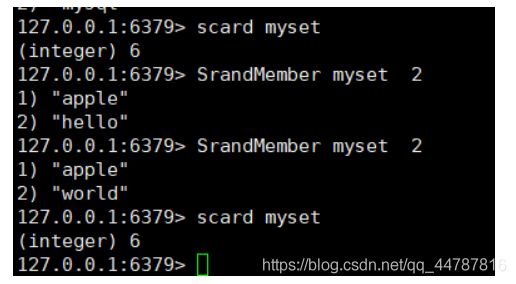
SRandMember key 【count】(可选) 随机从set中 返回几个数据 (不删除数据)
-
补充看官网
6、有序集合(sorted set) (命令以Z开头)
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
-
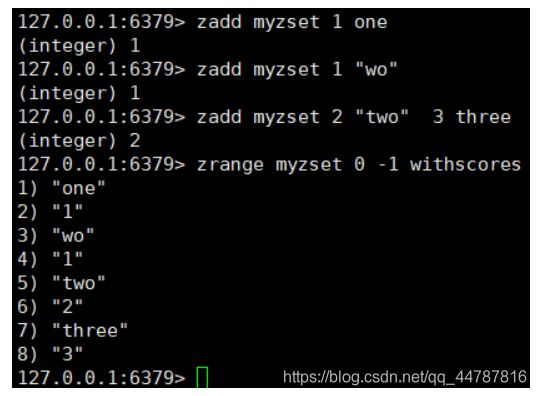
zadd key score member… 向zset集合中 插入一些值,附带double/int数(用来比较大小排序)
-
zrange key start end withScores 列出zset集合的指定位置元素 并携带分数
-
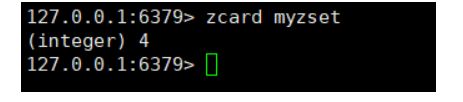
zcard key 算出zset中的集合个数
- zrem key member 移除zset集合中的指定元素
redis 127.0.0.1:6379> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
# 移除单个元素
redis 127.0.0.1:6379> ZREM page_rank google.com
(integer) 1
redis 127.0.0.1:6379> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
- 其它需求看文档
7、HyperLogLog 基数统计算法
什么是基数?(不重复的数据元素的个数)
1、比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
为什么要用hyperLogLog 算法?
-
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。(占用空间小)
-
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
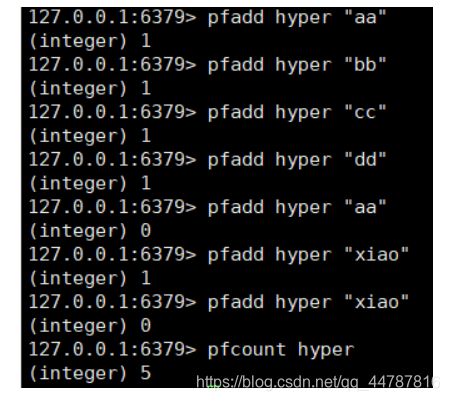
pfadd key element 往key中放元素 ,注意:不能放重复的(与set/zset类似)
pfcount key 计算key中的基数(不重复的数据个数)
pfMerge hyper hyper1 hyper2 合并多个hyperloglog 成一个hyper
8、Geospatial 地理位置
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
-
geoadd:添加地理位置的坐标。 (要使用必先 导入对应的全部地理坐哦)
-
geopos:获取地理位置的坐标。
-
geodist:计算两个位置之间的距离。
-
georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
-
georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
-
geohash:返回一个或多个位置对象的 geohash 值。
-
geoAdd 可以将一个或多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中。
往china:city 表 中添加一些城市 和经纬度
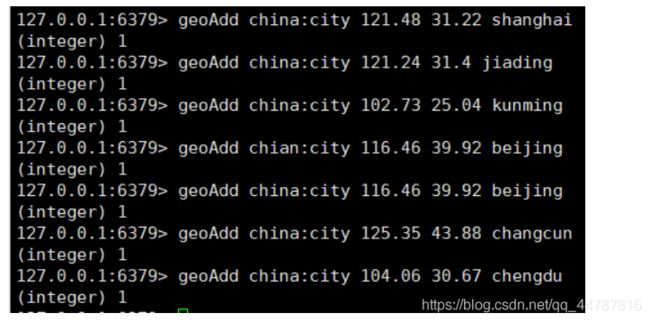
-
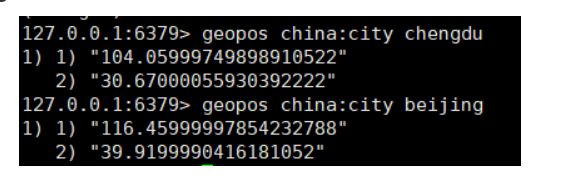
geoPos 返回 表中 指定名称的 经纬度
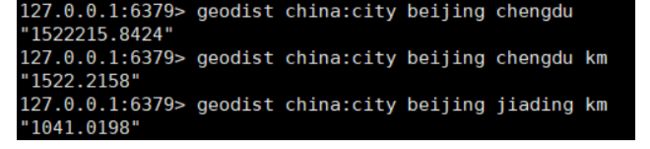
- geodist(distance) 返回表中两个地理位置的直线距离 可以指定单位
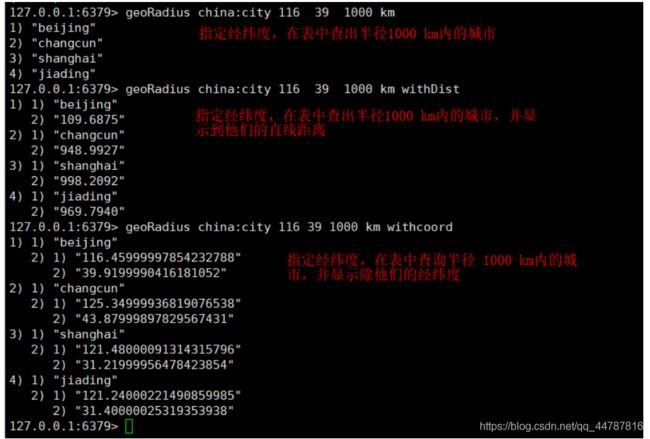
- geoRadius key 经度 纬度 半径 单位 注意:是可以写多个条件的
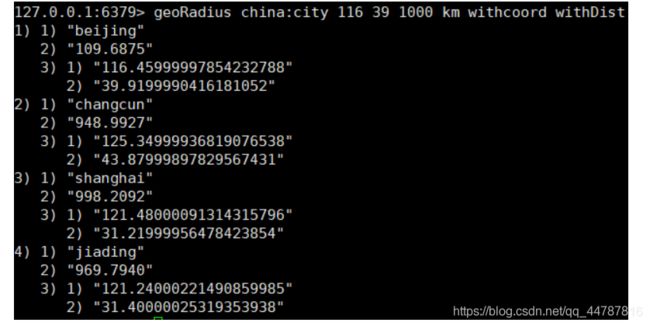
-
geoRadiusByMember 更geoRadius同样的用法 只不过不是经纬度定位中心 而是以表中成员来定位中心(不过好像不稳)
-
geospatial底层采用的是zset 因此可以用对应的zset命令来删除对应的数据
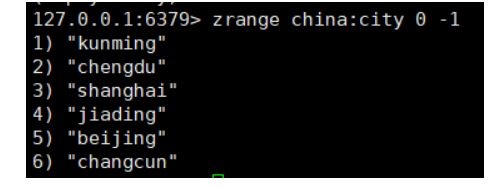
- 删除 key
9、BitMaps (位图)
-
位图一般由二进制0,1表示,常用来显示两种状态。例如:打卡,未打卡。迟到,未迟到
具体信息用时再查