多线程(虚拟地址空间)
代码展示线程
既然我们提到了,线程隶属于进程,是进程的一个执行分支
真的是这样吗?
我们还需要用代码来验证
初步思路是创建三个线程,其中main函数里面的为主线程
不断循环,并且打印相应的pid
假如它们属于不同的进程,那打印出来的pid应该不同,并且由于是属于不同的进程,所以一次应该只有一个程序被循环执行
1 #include <iostream>
2 #include <pthread.h>
3 #include <unistd.h>
4 using namespace std;
5 void* threadRun1(void* args)
6 {
7 while(true)
8 {
9 sleep(5);
10 cout << "t1 thread:" << getpid() << endl;
11 }
12 }
13 void* threadRun2(void* args)
14 {
15 while(true)
16 {
17 sleep(5);
18 cout << "t2 thread:" << getpid() << endl;
19 }
20 }
21 int main()
22 {
23 pthread_t t1,t2,t3; //创建三个线程
24 //初始化t1,t2线程
25 pthread_create(&t1,nullptr,threadRun1,nullptr);
26 pthread_create(&t2,nullptr,threadRun2,nullptr);
27
28 while(true)
29 {
30 sleep(1);
31 cout << "main thread: " << getpid() << endl;
32 }
33 return 0;
34 }
如果要创建线程成功,编译时还需要加-lpthread选项
对应的makefile内容如下:
1 mythread:mythread.cc
2 g++ -o $@ $^ -std=c++11 -lpthread
3 .PHONY:clean
4 clean:
5 rm -f mythread
下面是结果展示
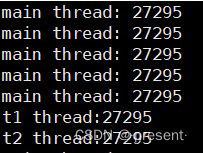
可以看到对应的线程pid都是相同的,说明它们都是隶属于一个进程,而该进程的pid是27295
在命令行窗口输入下面的命令,还可以观察到对应线程的lwp
while :; do ps -aL | head -1 && ps -aL | grep mythread ; echo "**************************"; sleep 1;done
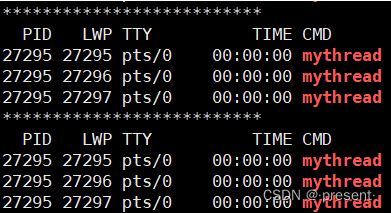
结果和预期完全相符,有一个PID和LWP相同的线程,这就是我们说的主线程,也解释了我们之前有关进程的说法是没有问题的,当只有一个PCB时,进程的PID,LWP是完全相同的
操作系统调度的时候,用PID识别进程,而用LWP来区别线程
虚拟地址空间
两个问题
现在有了初步线程的概念,我们就可以进一步深挖虚拟地址空间的概念
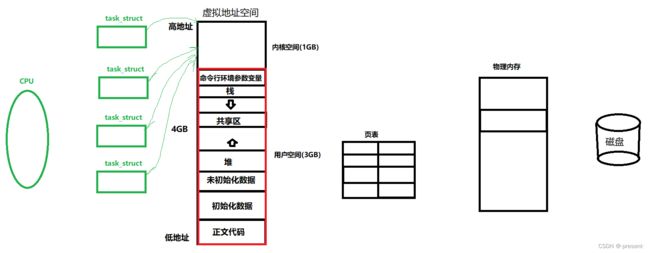
这张图片我们已经接触过很多次了,但是有两个重要的关键点,我们一直没有讲
第一点.
拿32位机器来举例子,其实就是对应的数据线有32条,那每条数据线都有0,1两个状态,总共可以表示多少个地址呢?
答案是2^32个地址 从0x0000 0000到0xFFFF FFFF 我们又知道 2 10 2^{10} 210 = 1KB,因此把 2 32 2^{32} 232
看作4 * 2 10 2^{10} 210 * 2 10 2^{10} 210 * 2 10 2^{10} 210 = 4 * 1GB = 4GB空间大小
但是这仅仅是数量的大小,地址本身也要空间来存 而虚拟地址空间需要存,真实的物理地址空间也需要存
在32位机器下,一个地址用4个字节,一个int类型来存,那总共就要8个字节,然后除了虚拟地址,真实物理地址,实际上还存在其它属性,也需要4字节
那满打满算其实总共需要48GB
那还谈什么页表?单单是页表,就已经耗费这么多的空间,还没谈地址空间里面存的数据,甚至一个虚拟物理内存也就4GB,还映射什么呢?
第二点
我们曾经提到过,物理内存的基本单位是一个字节
但是我们管理的时候,真的是按照一个字节来进行管理的吗?
过多的IO,注定了寻址会非常的频繁,磁盘是一个物理装置,也就对应着过多的机械运动,这样的效率是非常低下的!
因此,OS在和磁盘这样的设备进行IO交互的时候,绝对不是按照字节为单位,而是按照块为单位
这就好像学校最基本的单位是一个一个学生,但是举办校运会的时候,并不是为你一个人而举办,而是以班级为单位,一整块一整块的进行管理
操作系统追求的是效率,100MB的数据,我一次取100MB,和取100次1MB,这样的效率差距是非常明显的
前面在文件系统时,我们已经学习过,根据文件系统和操作系统的不同,块的大小也不同,在Linux操作系统下,一个块的大小是4KB
但是这样就结束了吗?
领导规定我们就按照小组来进行奖惩,小组整体目标完成优异,得到的奖励就多;小组整体表现很差,自然就要惩罚
这建立的基础就在于,员工都要达成一个共识——以团队为单位进行工作!
不然领导这么说,下面的人还是单打独斗,有用吗?
同样的道理,磁盘说,我会按照8格扇区为单位,4KB为一块进行划分
但是你文件系统管理数据的时候还是以1KB来取数据放到对应物理内存,那划不划分,其实区别不大,还是要取多次!
所以,所谓要按块来进行管理,必须达成两个条件
1.文件系统+编译器
两个软件管理数据的时候,都要以4KB为单位(块)进行管理
即便我们只是改一个比特位,或者只需要1KB的内存空间,我们申请的空间大小也必须以块来申请!
2.操作系统+内存
物理内存已经按照4KB进行划分好,操作系统从内存中存取数据,也要以4KB为单位(块)进行管理
所以所谓的内存管理,就是指
将磁盘中特定4KB(数据内容)放入到哪一个物理内存的4KB空间(数据保存的空间)
其中我们把物理内存划分的4KB大小的块,称之为页Page,也叫页框
磁盘划分的4KB大小的块,称之为页帧
但是,还有一个问题没有解决,物理内存和磁盘都是硬件,我说按照4KB来进行划分,难不成用水果刀一块一块切来划分吗?
所以所谓的划分,更多是指软件层面上的辅助,即存在对应的Page结构体,来描述这一个个块,而块的大小是4KB
先描述再组织
Page结构体多起来,就需要对它们进行管理
Linux采取的方式是用数组来进行管理,为一个结构体数组
为什么用数组来进行管理,其实也很好理解
因为数组有下标!有下标,每个块就有对应的块编号,有了块编号,就能和inode建立关系,这样就可以很方便的管理这一个个块!
局部性原理
但是,虽然说按照块来进行管理,那我一次性加载块这么多的数据,不会很浪费吗?
局部性原理指出的就是这个问题,它告诉我们并不会浪费!
它允许我们提前加载正在访问的数据与其附近的数据
通过预加载要访问数据的附近数据,来减少未来需要加载的次数
就像我们学习知识一样,现在看来,可能没有什么用,但是很大概率,某一天就会需要用到对应的这部分知识
现在吃亏,实际是为了未来享福
总结
以4KB为单位进行块管理数据的基础是什么?
1.IO基本单位(内核内存+文件系统)都要提供对应的支持
2.通过局部性原理,它告诉我们,以块为单位进行管理,能够提高未来命中情况,等到了相应部分,就不用再去磁盘中取,这能大大提高效率
为什么是4KB呢?
但是我们前面提到了这么多东西,还有一个问题没有解决
那就是为什么是4KB呢?不是5KB,6KB?
为了解答这个疑惑,我们还需要回归到我们一开始的问题,如果按照我们之前理解的方式来定义页表,那页表的大小不是我们能承受的
问题出在哪里呢?
中国领土非常广阔,如果只按照划分镇来管理,那镇的数目是非常庞大的
同样的,学校内部有很多的教学楼,如果按照教室进行划分,依次进行编号,那这个数目也是非常多的,而且非常混乱
但是,我们先划分省,再根据省划分市,即便镇的名字是相同的,我们也可以区分是不同的地区
无独有偶,我们先给教学楼命名,第一栋称为L1,第二栋称为L2,以此类推,则教室的编号,即便是相同的,都叫503,我们也知道这间教室的位置在哪
因此,问题的关键不是数量!而是需要将数据看作是整体使用,还是局部使用!
虚拟地址,并不是整体被使用的
对于一个有32位的虚拟地址来说
我们将它切割成10 + 10 + 12比特位的结构
用前10个比特位表征页目录,类比于书的一个个目录
中间10位表征页表项,类比于书每个目录里面的章节
页表项里面存放的就是对应物理内存中页框的起始地址
那接下来剩下的12个比特位, 刚好就是4KB大小( 2 12 2^{12} 212 = 4KB)
它记录的就是偏移量,可以类比它为章节里面具体的每一回,从对应页框的起始地址处向后进行偏移,就可以找到物理内存中某一个对应的字节数据
它的核心思想就是沿用从8086最开始设计的理念
基地址+偏移地址的方式进行寻址
只不过原来的段寻址,变为现在的页内偏移寻址
第一个页目录,总共有 2 10 2^{10} 210个表项
每个表项对应一张页表项,一个页表项,也是 2 10 2^{10} 210个表项
按照每个表项12KB来说,总共也就 2 10 2^{10} 210 * 2 10 2^{10} 210 * 12 = 12MB
这大大节省了空间
为什么能节省空间?就是因为记录的偏移量,每个页框都是相同的!
都是从0x000 - 0xFFF,每个页框的大小都是4KB
我们进行地址区分的时候,不需要将这部分偏移地址还拿出来参与地址划分啊!
就算是相同的偏移量,但是我有了前面的页目录,页表项的划分,我已经可以锁定我们所想要的字节数据!
就好像教学楼L1503和教学楼L2503,两间教室编号(偏移量)相同,但很明显不会是同一间教室
否则如果依旧参与划分,12MB * 2 12 2^{12} 212 = 48GB,就是我们原来页表的存储思路
Linux系统就是采取这样二级映射的方式+设定文件块大小为4KB,巧妙解决了页表存储空间的问题
现象
这也解释了我们以前学过的很多现象
任何一个对象或者变量,可能存在多个字节,但是你会发现,永远取地址的时候,只会拿到一个地址数字
这个地址数字是什么?就是页框的起始地址
那具体要从页框中的哪个部位取我们的数据呢?
就需要结合我们的数据的类型
int a = 10;
double d = 30.0;
我们取变量的地址&a,&d,得到的都是一个地址,也就是起始地址
我们再根据它的类型,获取对应偏移量,这样就可以获取页框中的具体数据
核心思想:基地址+偏移量
补充
MMU
上面所说的所有映射过程,都是由MMU(MemoryManagementUnit)这个硬件完成的,该硬件是集成在CPU内的
页表是一种软件映射,MMU是一种硬件映射,所以计算机进行虚拟地址到物理地址的转化采用的是软硬件结合的方式
画大饼
另外,采取虚拟地址还有一个好处,就是提前规划
我们实际在申请malloc内存的时候,OS只需要给你在虚拟地址空间上申请就行
但是只有真正访问的时候,OS才会自动给你申请或者填充页表+申请具体的物理内存
不然你说给这么多,OS给你了,但你又不使用,造成空间闲置,这并不符合操作系统追求高效率的目的
还有一点,数据是按照块一块块加载进来的,并不是一口气全部加载进来,只有用到了,操作系统才进行相应的数据加载
缺页中断
同时,我们上面也已经指出来,页表除了存地址外,其实还存有其它属性
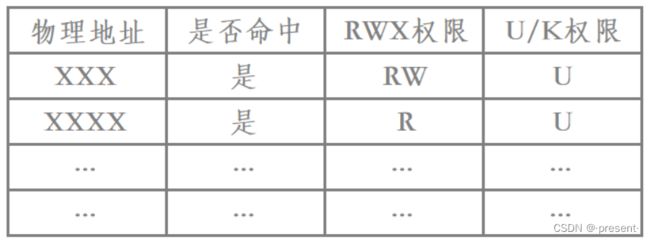
比如说是否已经被load到内存(是否命中)
是否有RWX权限,U/K权限(User or kernel)
假如没有对应的权限,而仍然执意操作,则会引发相应的缺页中断,默认中断执行方式为程序终止
比如说我们建了个常量字符串char* s = “hello world”,它对应的虚拟地址就被规划在字符常量区,s里面保存的就是指向字符的虚拟地址
此时我们对s进行修改,*s = ‘H’
既然是虚拟地址,就必定会伴随虚拟到物理转变的过程
--------->虚拟到物理转变,就必定经过页表
--------->MMU查页表的时候,会对你的操作进行权限审查,RWX中没有W
--------->发现你的操作非法
--------->MMU发生异常
--------->OS识别到异常,转换成信号,发送给目标进程
--------->在从内核态切换到用户态的时候,进行信号处理
--------->执行的默认方法就是终止进程
于是我们会看到程序报错
总结
内存管理于文件系统配合(4KB,块为单位管理) +页表(二级映射) +虚拟地址+缺页中断(保证权限正常) = 物理地址的寻址方式