Hadoop期末复习
hadoop期末复习整理
第一章 大数据概述
1、两大核心技术:HDFS和MapReduce。
2、大数据计算模式及其代表产品
批处理计算:MapReduce、Spark
流计算:Storm、Flume
图计算:PowerGraph
查询分析计算:Hive、Cassandra

3、云计算、大数据和物联网的联系
云计算为大数据提供技术基础,大数据为云计算提供用户之地;
云计算为物联网提供海量数据存储能力,物联网为云计算提供广阔的应用空间;
物联网是大数据的重要来源,大数据为物联网数据分析提供支撑。
========================================================
第二章 Hadoop体系结构
1、Hadoop集群部署方式有独立模式、伪分布式模式、完全分布式模式。
2、SSH是什么
SSH是Secure Shell的缩写,建立在应用层和传输层的安全协议。
SSH是目前比较可靠、专为远程登录会话和其他网络服务提供安全性的协议。
3、配置SSH的原因
Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登录来实现。
4、Hadoop的配置文件位于/usr/local/hadoop/etc/hadoop中。
5、伪分布式需要修改2个配置文件,core-site.xml和hdfs-site.xml。
6、伪分布式安装配置的实验步骤:
- 修改配置文件:hadoop-env.sh, core-site.xml, yarn-site.xml, hdfs-site.xml, mapred-site.xml;
- 初始化文件系统hadoop namenode -format;
- 启动所有进程start-all.sh。
在hadoop-env.sh中修改JAVA_HOME设置;
在core-site.xml中设置HDFS的默认名称(fs.default.name);
在yarn-site.xml中配置YARN。
7、Hadoop集群的部署模式
独立模式:称为单机模式,所有程序都在单个JVM执行。
伪分布式模式:Hadoop的守护程序运行在一台节点上。
完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上。
========================================================
第三章 分布式文件系统HDFS
1、分布式文件系统节点分为两类:一类叫主节点(Master Node),也称为名称节点(NameNode),另一类叫从节点(Slave Node),也称为数据节点(DataNode)。
2、Apache2.7.3HDFS默认一个块128MB,一个文件被分为多个块,以块作为存储单位。
3、NameNode负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即FsImage(文件系统镜像文件)和EditLog(编辑日志文件)。
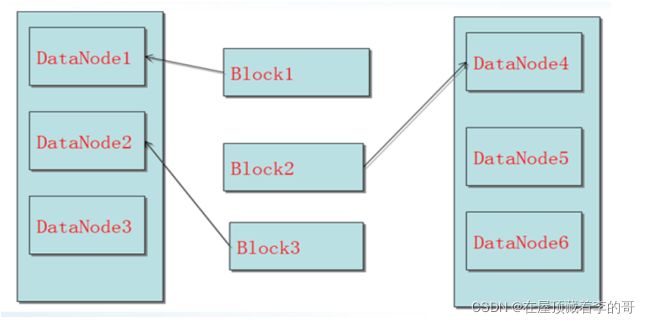
4、DataNode负责记录每个文件中各个块所在数据节点的位置信息。
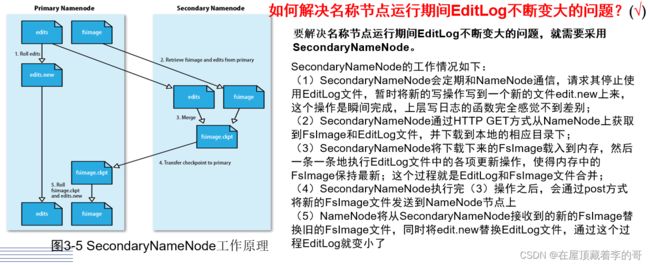
5、SecondaryNameNode是HDFS架构中的一个组成部分,它用来保存节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。
6、如何解决NameNode运行期间EditLog不断变大的问题?
7、DataNode是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者NameNode的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
8、HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括了一个NameNode和若干个DataNode。
9、数据存放。
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:与第一个副本相同机架的其他结点上
更多副本:随机结点
10、数据出错可以分为3种情形:名称节点出错、数据节点出错和数据出错。
11、名称节点出错:HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。
12、数据节点出错:每个数据节点会定期向名称节点发送心跳信息,向名称节点报告自己的状态。
13、 
14、 
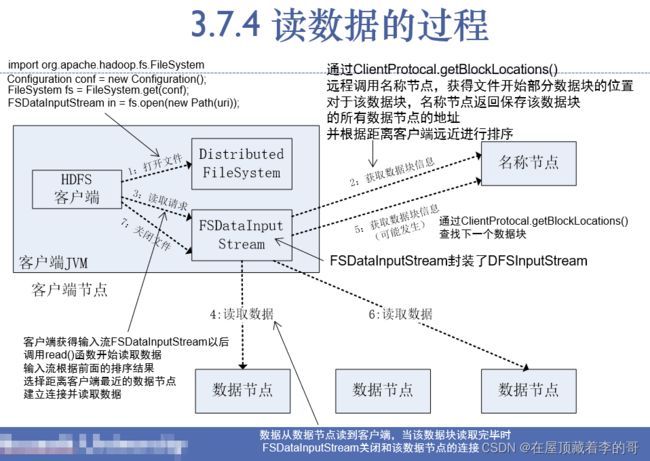
15、HDFS读数据的原理
- 客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
- NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
- 客户端会选取排序靠前的DataNode来依次读取Block块(如果客户端本身就是DataNode,那么将从本地直接获取数据),每一个Block都会进行CheckSum(完整性验证),若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
- 客户端会把最终读取出来所有的Block块合并成一个完整的最终文件。
========================================================
第四章 MapReduce技术
1、MapReduce采用分而治之的思想。
2、MapReduce框架采用Master/Slave架构,包括一个Master和若干个Slave。Master上与新JobTracker,Slave上运行TaskTracker。
3、Hadoop框架是用Java实现的,但MapReduce程序不一定要用Java写。
4、 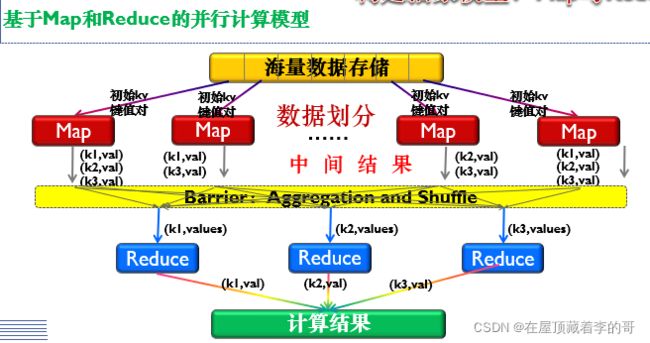
5、MRv2主要包括以下三种(选择题):ResourceManager、NodeManager、ApplicationMaster。
6、MapReduce工作流程概述:
-
不同的Map任务之间不会进行通信
-
不同的Reduce任务之间也不会进行信息交换
-
用户不能显示地从一台机器向另一台机器发送消息
-
所有数据交换都是通过MapReduce框架自身实现的
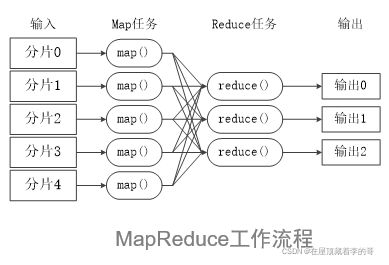
7、关于Split(分片):HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。
8、splitSize=max{minSize, min{maxSize, blockSize}}
9、Shuffle过程:sort(排序)、combine(合并)、partition(分片)。
10、Shuffle设置溢写比例0.8(mapreduce.map.sort.spill.percent)。
11、Map端的shuffle
 ========================================================
========================================================
第六章 大数据应用
单标关联和倒排索引
========================================================
第七章 Hive数据仓库
1、数据仓库是一个面向主题的、集成的、随时间变化的,但信息本身相对稳定的数据集合。
2、前端工具主要包含各种数据分析工具、报表工具、查询工具、数据挖掘工具以及各种基于数据仓库或数据集市开发的应用。
3、Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。
4、元数据存储系统(Metastore)默认存在自带的Derby数据库中。
5、Hive建立在Hadoop系统之上,因此Hive底层工作依赖于Hadoop服务。
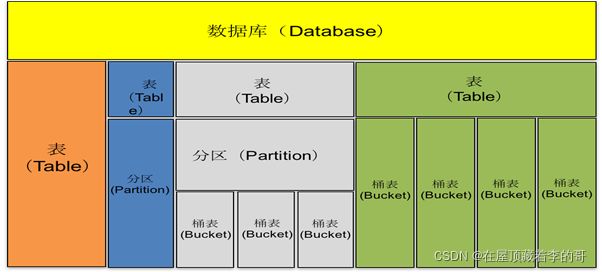
6、Hive中所有数据都存储在HDFS中,包含数据库、表、分区表、桶表四种数据类型。
7、Hive三种安装模式:嵌入模式、本地模式和远程模式。
8、本地模式和远程模式安装配置方式,本质上是将Hive默认的元数据存储介质由自带的Derby数据库替换为MySQL数据库。
9、Hive的MAP数据类型:一组无序键值对。键的类型必须是原子类型,值可以是任意类型,同一个映射的键的类型必须相同,值的类型也必须相同。
10、Hive内部表和外部表的区别
- 外部表创建表的时候,不会移动数据到数据仓库目录(/user/hive/warehouse),只会记录表数据存放的路径;内部表会把数据复制或剪切到表的目录下
- 外部表在删除表的时候只会删除表的元数据信息不会删除表数据,内部表删除时会将元数据信息和表同时删除
11、Hive桶表:根据某个属性字段把数据分成几个桶(一般设置为4,默认值是-1,可自定义)。
12、
开启分桶功能
set hive.enforce.bucketing = true;
set mapreduce.job.reduces = 4;
创建桶表
create table stu_buck(Sno int ,Sname string, Sex string, Sage int, Sdept string)
clustered by (Sno) into 4 buckets
row format delimited fields terminated by ‘,’;
创建临时表
create table student_tmp(Sno int, Sname string, Sex string, Sage int, Sdept string)
row format delimited
fields terminated by ‘,’;
加载数据至临时表
load data local inpath ‘/hivedata/student.txt’
into table student_tmp
将临时数据表中数据导入桶表
insert overwrite talbe stu_buck
select * from student_tmp cluster by (Sno);





