python基于轻量级卷积神经网络模型GhostNet开发构建养殖场景下生猪行为识别系统
养殖业的数字化和智能化是一个综合应用了互联网、物联网、人工智能、大数据、云计算、区块链等数字技术的过程,旨在提高养殖效率、提升产品质量以及促进产业升级。在这个过程中,养殖生猪的数字化智能化可以识别并管理猪的行为。通过数字化智能化系统,可以在猪的不同生长阶段,对其体重、饮食、运动量、繁殖能力、疾病状况等各项指标进行数据分析和监测,进而实现科学喂养和疾病预防。智能化养殖不仅提高了养殖效率,也有利于提高生猪的健康水平,对疾病的预防和治疗都有积极作用,最终能提升畜禽产品的品质和农户企业的实际收益。
国内很多厂商在养猪行业里其实很早就开始布局了,基于人工智能数字化技术手段来为传统养猪行业赋能,来提升养殖效率是比较有应用前景的赛道。本文的核心思想其实是借鉴了前面课堂行为识别模型的想法,想要基于生猪养殖数据来开发构建生猪行为识别模型,基于自动化的智能化的识别计算服务可以基于识别计算结果来做出响应,这些是可以考虑后期落地应用的点不是本文的内容。
首先来看下实例效果图:
接下来我们来看下具体的数据集:
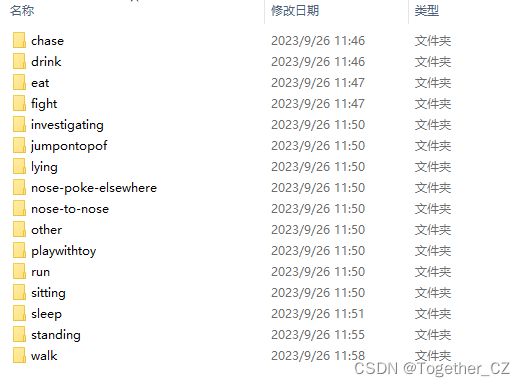
共包含猪15种主要行为,以及其他类型的行为,共有16种行为类型。
简单看下实例数据:
【打架】
【睡觉】

【玩玩具】

【进食】

GhostNet主要从深度神经网络中特征图的冗余性角度出发,以低成本高效益的方式模拟传统卷积操作的效果。GhostNet模型中的Ghost模块是传统卷积层的一个替代方案。该模块通过使用少量的传统卷积来生成部分特征图,然后对这些特征图进行简单的线性变化(作者称这种操作为廉价的线性变换),从而得到所需数量的特征图。这种操作增加了特征图的冗余性,从而在保证对输入数据全面理解的同时降低了模型的计算成本。
优点:
效率高:通过使用少量的传统卷积操作以及廉价的线性变换操作,GhostNet在保证较高识别性能的同时降低了模型的计算成本,提高了模型的运行效率。
扩展性强:由于GhostNet模型中的Ghost模块可以灵活地调整生成特征图的数量,因此该模型可以方便地扩展到其他深度神经网络结构中,具有很强的适应性。
缺点:
理论基础尚不完备:虽然GhostNet模型在基准测试中表现出色,但其理论基础尚不完备,对于其有效性以及适用范围的深入研究仍有待进一步开展。
缺乏足够的可视化支持:对于模型内部的运行机制以及特征图的具体生成过程,目前还没有详细的可视化支持,这使得模型的理解仍有待进一步加深。
在前面很多项目开发中我们使用到的轻量级的CNN模型大都是MobileNet系列的,这里我们使用的是GhostNet模型,同样是一款性能出众的模型,核心实现如下所示:
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width_mult=1.0):
super(GhostNet, self).__init__()
self.cfgs = cfgs
output_channel = _make_divisible(16 * width_mult, 4)
layers = [
nn.Sequential(
nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
)
]
input_channel = output_channel
block = GhostBottleneck
for k, exp_size, c, use_se, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4)
hidden_channel = _make_divisible(exp_size * width_mult, 4)
layers.append(
block(input_channel, hidden_channel, output_channel, k, s, use_se)
)
input_channel = output_channel
self.features = nn.Sequential(*layers)
output_channel = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)),
)
input_channel = output_channel
output_channel = 1280
self.classifier = nn.Sequential(
nn.Linear(input_channel, output_channel, bias=False),
nn.BatchNorm1d(output_channel),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x, need_fea=False):
if need_fea:
features, features_fc = self.forward_features(x, need_fea)
x = self.classifier(features_fc)
return features, features_fc, x
else:
x = self.forward_features(x)
x = self.classifier(x)
return x
def forward_features(self, x, need_fea=False):
if need_fea:
input_size = x.size(2)
scale = [4, 8, 16, 32]
features = [None, None, None, None]
for idx, layer in enumerate(self.features):
x = layer(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x
x = self.squeeze(x)
return features, x.view(x.size(0), -1)
else:
x = self.features(x)
x = self.squeeze(x)
return x.view(x.size(0), -1)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def cam_layer(self):
return self.features[-1]
这是华为研究员提出来的非常能打的模型 ,感兴趣的话可以自行去了解官方的研究工作,地址在这里。如下所示:
当然了开源社区里面也有很多对应的项目,可以选择适合自己的就行了。
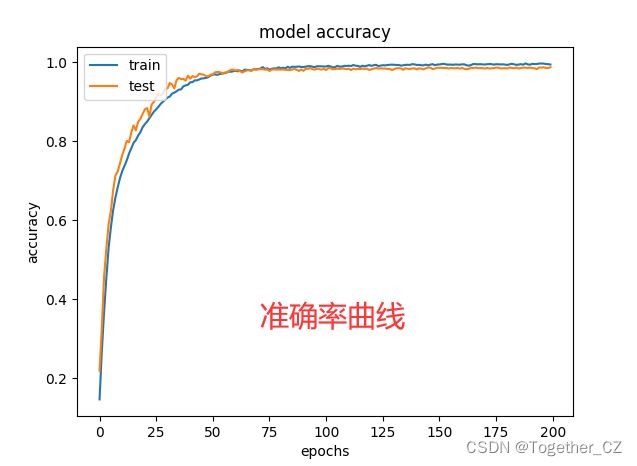
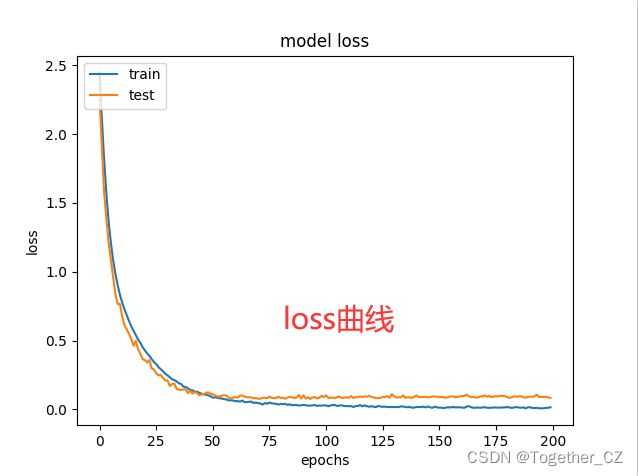
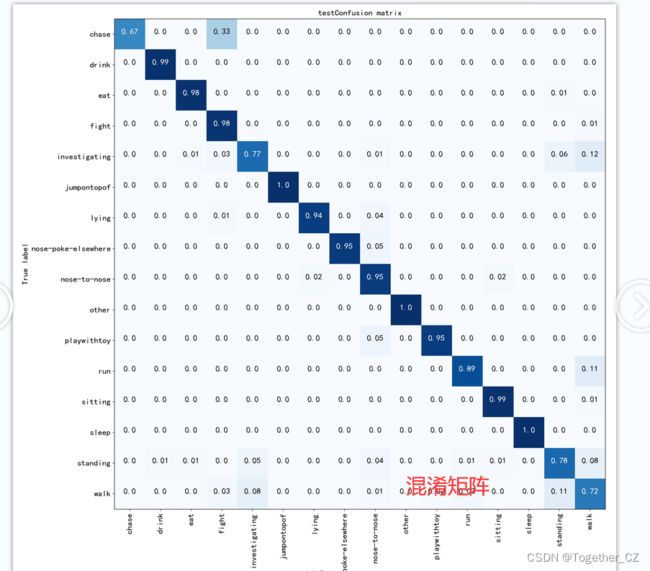
默认8:2的数据划分比例设置,默认200次epoch的迭代计算,结果详情如下所示:
【准确率曲线】
【loss曲线】
【混淆矩阵】
当然了整体项目的开发也可以直接使用或者参考前文《眼疾识别》的方式。