“流量劫持” 目前还没有成为一个学术性的词汇,它可能是一个安全话题,也可能是一个网络话题。
从网络视角出发,我们劫持流量通常是为了做审计、路由、流量治理等方面的事情,本文就从这个角度来分析和整理一下目前比较常见的流量劫持技术及其应用场景,希望读者能从五花八门的技术中,选出最合适自己的那一款。
首先我们来看一下 Linux Network Stack,大致如图:
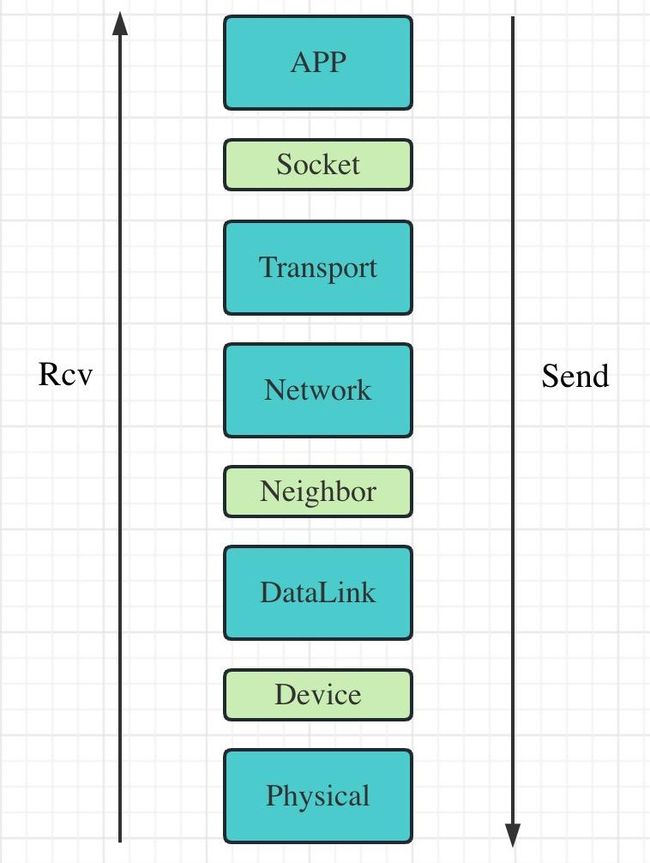
蓝色是 TCP/IP 五层模型,绿色与模型无关,而是 Linux 实现相关。
一个更完整的图,可以看这里 https://kccncna19.sched.com/event/Uae7/understanding-and-trou...
这个 Stack 由上至下,流量劫持相关的技术及其应用场景场景有:
代理
代理,是用户主动配置,将流量(ingress and/or egress)委托(主动被劫持)给特定的 proxy,这个方式我们可以认为工作在 Application Layer。
代理一般有正向代理和反向代理。
前者典型的有浏览器代理配置(如 Chrome SwitchyOmega plugin)、curl --porxy 等等。
后者典型就是 Nginx。
ebpf/msg_redirect_hash
这个技术应用场景由 Cilium 提出,主要目的是 service mesh 场景中的 sidecar 的流量劫持(单节点流量)。
我们知道,sidecar 最开始由 iptables 完成流量劫持(下一小节阐述),如下图
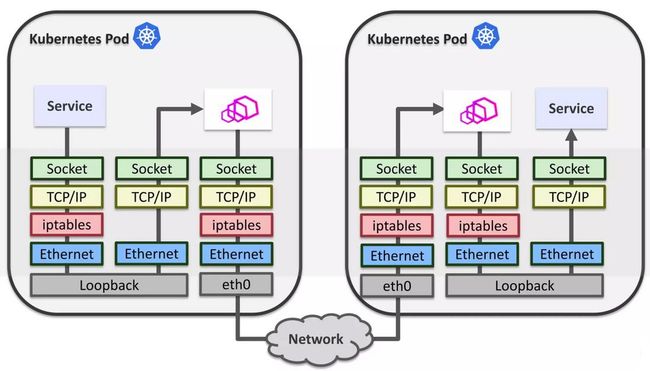
但事实上,我们是在一个单节点的环境中,也不用考虑报文丢失,所以没必要走协议栈,因此下图诞生了

主要原理:
- 通过 ebpf/sockops 程序监听内核的 socket 事件并维护 socket hash map
- 通过 ebpf/sk_msg 程序监听内核的网络发送事件,并将数据直接塞到(msg_redirect_hash)对应的目标 socket (map 中查询)的 rx queue 中
- cgroup 决定以上两个步骤的影响范围,在程序的 attach 阶段配置
所以这个技术直接在 Socket Layer 劫持了流量,避免了数据包走到下层协议栈,提升了性能。
netfilter/iptables
netfilter 是内核提供的一个网络框架,主要运行在 Network Layer,它可以按照一定得规则完成包过滤、包日志、NAT 等功能。通常,我们利用 iptables 来管理这些规则。
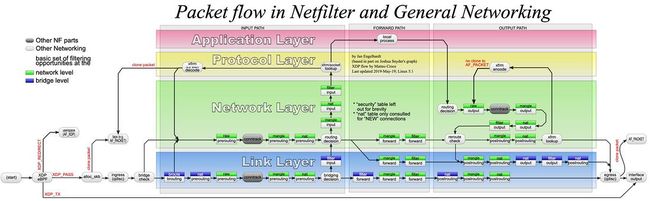
istio/sidecar
如前一节所提,istio sidecar 最初(也是主流)的流量劫持方式,就是通过 iptables 实现的。
iptables 有许多表,劫持流量主要用到了 NAT 表,istio 在 init container 中会注入 iptables 规则,大致完成两件事:
- 将所有入栈流量(sidcar 本身业务除外,比如metrics 和 xDs)转发给 inbound handler (sidecar 端口 1),sidecar拦截到流量并处理后,交给业务容器
- 将所有出栈流量转发给 outbound handler (sidecar 端口 2),sidecar拦截到流量并处理后,交给协议栈进行路由转发
虽然 istio 使用的 iptables 规则比较复杂,但是核心原理就像下面:
iptables -t nat -A PREROUTING -p tcp -j REDIRECT --to-port 8080
这条命令执行后,你在 pod 内发出的任意流量都会被转发到 8080 端口
k8s/service
k8s 在 userspace(本模式现已废弃) 模式下,是通过 iptables 把所有流量都拦截到 proxy 中,由 proxy 决定如何路由。假设 proxy 监听 12345 端口,由两个 servcie 分别是 10.1.23.2:80 和 10.1.23.4:8080。则每个节点都会有如下类似的规则(实际情况可能会有一些自定义链,以及 conntrack 相关参数):
iptables -t nat -A PREROUTING/OUTPUT -p tcp -d 10.1.23.2 --dport 80 -j REDIRECT --to-port 12345
iptables -t nat -A PREROUTING/OUTPUT -p tcp -d 10.1.23.4 --dport 8080 -j REDIRECT --to-port 12345k8s 在 iptables 模式下,是通过 iptables nat 来完成服务发现和负载均衡,假设有个 service 10.1.1.12:8090,其有两个对应的 pod 172.168.1.3:80 和 172.168.1.4:80,则每个节点都会有如下类似的规则(实际情况会有一些自定义链,以及 conntrack 相关参数):
iptables -t nat -A PREROUTING/OUTPUT -d 10.1.1.12 -p tcp --dport 8090 -m statistic --mode random --probability 0.5 -j DNAT --to-destination 172.168.1.3:80
iptables -t nat -A PREROUTING/OUTPUT -d 10.1.1.12 -p tcp --dport 8090 -j DNAT --to-destination 172.168.1.4:80由于 iptables 实现,负载均衡算法只支持随机/比例,上述配置为两个 backend 各自 50% 的流量。
由于 service 既要能被 pod 访问,又要能被 node 访问,所以需要配置 PREROUTING 和 OUTPUT 两个 hook。
iptables 模式比 userspace 模式好在,数据包少了 kube-proxy 引起的额外的 内核/用户数据拷贝。
注: iptables 本身比较复杂,这里只是简化描述,能让读者领会意图即可,不追求真实场景和绝对正确。
路由表
路由表工作在 Neighbor Sub-System Layer。我们可以通过设置路由表,来将某些流量路由到特定的(虚拟)接口。命令可以是 ip route add 10.0.0.0/8 dev wg0,含义:目的地址匹配 10.0.0.0/8 的 ip 包要被路由到 wg0 接口去。
通常的应用场景是 ,按照路由完成后的处理逻辑,主要分为两种:
tun/tap
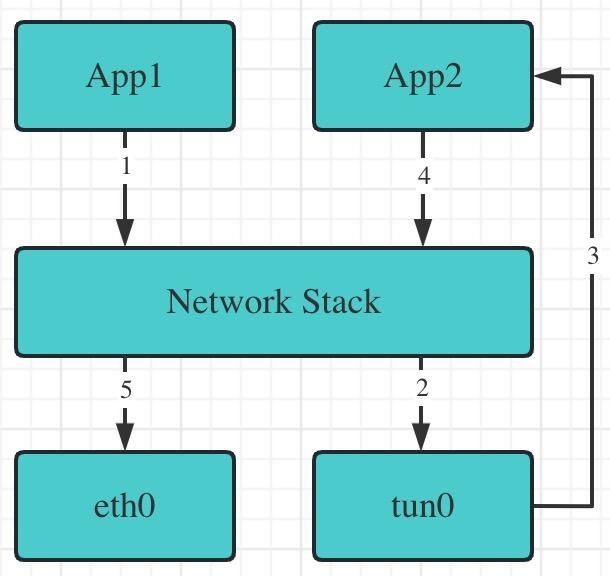
App1(普通应用)通过 1 发出的数据没有直接从 5 流出本机,而是被路由表引导至 2。2 的特性导致数据被引导至 App2(VPN 应用),App2 对数据进行处理(比如压缩、加密)并重新通过 4 发送至内核,并通过 5 流出本机。
wireguard
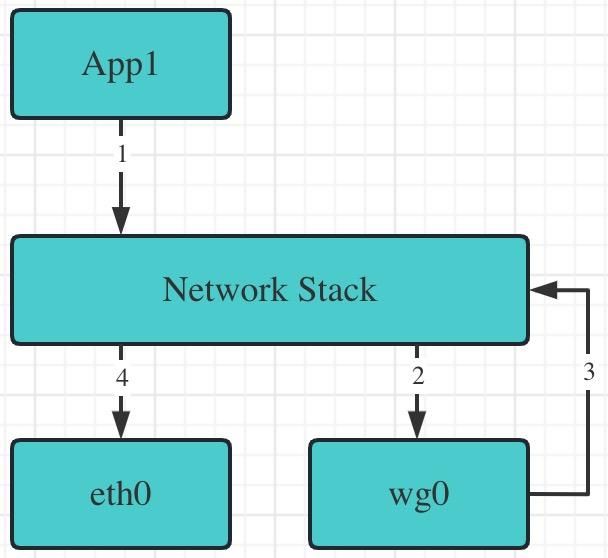
App1(普通应用)通过 1 发出的数据没有直接从 4 流出本机,而是被路由表引导至 2。数据在 wg0 被处理后,重新封装为一个新的数据报文(wireguard 场景是 udp)然后重新回到协议栈,可以看到相比 tun/tap,数据从始至终只在内核打转,没有多余的内核/用户态的数据拷贝,这也是 wireguard 比 open 性能更好的重要原因之一。
ebpf/tc
ebpf/tc 工作在 Datalink Layer,目前主要用于加速跨节点容器网络。
我们知道,传统的容器网络基于 bridge+veth 实现,典型的容器收包路径如图:

采用 bpf_redirect 后,流量被直接转发(劫持)到 lxc0,绕过了 路由、bridge 等相关操作,如图:

进一步的,采用 bpf_redirect_peer 后,甚至可以绕过 lxc0,将流量直接转发(劫持)到容器网络空间的 ve0,如图:

后记
本文分析了众多流量劫持技术的大致原理和应用场景,后续会从实战角度出发,展示这些应用场景,对这个话题感兴趣的同志们记得持续关注~
另外,受限于笔者的视野,整理可能会有些纰漏,也欢迎大家留言补充,我们一起把这个图补充完整。
参考
- https://www.slideshare.net/ThomasGraf5/accelerating-envoy-and...
- https://github.com/cilium/cilium/pull/6013/files#diff-032b298e586cbd370e386a68b564ce180ed74c3cb16b3d56301d4a0481d91757
- wikipedia Netfilter
- https://jimmysong.io/blog/envoy-sidecar-injection-in-istio-se...
- https://v1-23.docs.kubernetes.io/docs/concepts/services-netwo...
- https://www.kernel.org/doc/Documentation/networking/tuntap.txt
- https://www.wireguard.com/papers/wireguard.pdf
- https://mp.weixin.qq.com/s/slJFVkPK4GEMNQYmtCmw_g
- https://docs.cilium.io/en/stable/bpf/progtypes/
- https://man.archlinux.org/man/bpf-helpers.7.en
- https://elixir.bootlin.com/linux/v6.1.11/source/net/core/dev....