Hive+Spark离线数仓工业项目--ODS层及DWD层构建(1)
目标:自动化的ODS层与DWD层构建
实现
- 掌握Hive以及Spark中建表的语法规则
- 实现项目开发环境的构建
- 自己要实现所有代码注释
- ODS层与DWD层整体运行测试成功
数仓分层回顾
目标:回顾一站制造项目分层设计
实施

ODS层 :原始数据层
- 来自于Oracle中数据的采集
- 数据存储格式:AVRO
- ODS区分全量和增量
- 实现
- 数据已经采集完成

- step1:创建ODS层数据库:one_make_ods
- step2:根据表在HDFS上的数据目录来创建分区表
- step3:申明分区
DWD层
- 来自于ODS层数据
- 数据存储格式:ORC
- 不区分全量和增量的
- 实现
- step1:创建DWD层数据库:one_make_dwd
- step2:创建DWD层的每一张表
- step3:从ODS层抽取每一张表的数据写入DWD层对应的表中
Hive建表语法
目标:掌握Hive建表语法
实施

- EXTERNAL:外部表类型
- 内部表、外部表、临时表
- PARTITIONED BY:分区表结构
- 普通表、分区表、分桶表
- CLUSTERED BY:分桶表结构
- ROW FORMAT:指定分隔符
- 列的分隔符:\001
- 行的分隔符:\n
- STORED AS:指定文件存储类型
- ODS:avro
- DWD:orc
- LOCATION:指定表对应的HDFS上的地址
- 默认:/user/hive/warehouse/dbdir/tbdir
- TBLPROPERTIES:指定一些表的额外的一些特殊配置属性
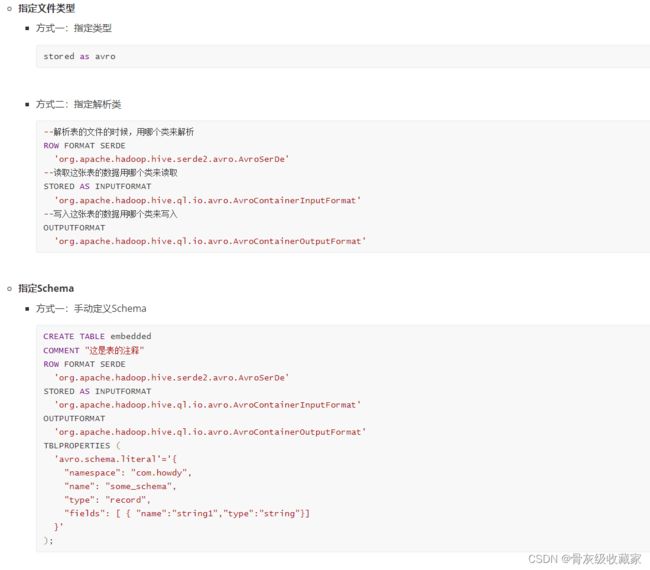
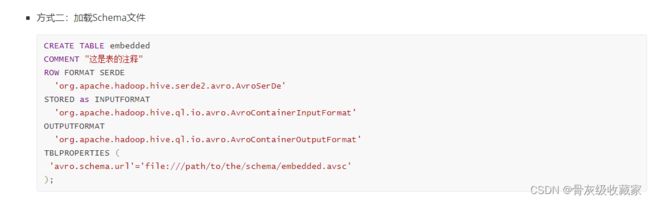
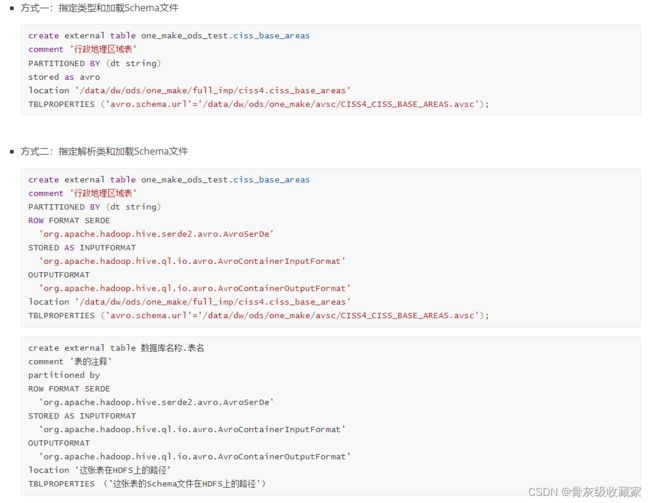
Avro建表语法
- **目标**:掌握Hive中Avro建表方式及语法
- **路径**
- step1:指定文件类型
- step2:指定Schema
- step3:建表方式
- **实施**
- Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-CreateTable
- DataBrics官网:https://docs.databricks.com/spark/2.x/spark-sql/language-manual/create-table.html
- Avro用法:https://cwiki.apache.org/confluence/display/Hive/AvroSerDe
- **指定文件类型**
建表语法
ODS层构建:需求分析
目标:掌握ODS层构建的实现需求
路径
- step1:目标
- step2:问题
- step3:需求
- step4:分析
- **实施**
- **目标**:将已经采集同步成功的101张表的数据加载到Hive的ODS层数据表中
- **问题**
- 难点1:表太多,如何构建每张表?
- 101张表的数据已经存储在HDFS上
- 建表
- 方法1:手动开发每一张表建表语句,手动运行
- 方法2:通过程序自动化建表

- 难点2:如果使用自动建表,如何获取每张表的字段信息?
- Schema文件:每个Avro格式的数据表都对应一个Schema文件
- 统一存储在HDFS上
需求:加载Sqoop生成的Avro的Schema文件,实现自动化建表
分析 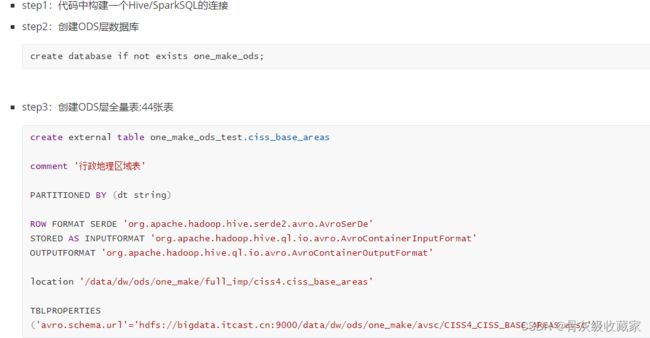
- 读取全量表表名
- 动态获取表名:循环读取文件
- 获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
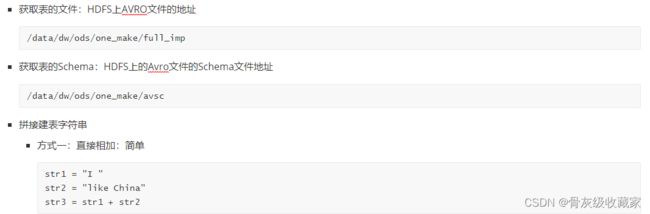
- 方式二:通过列表拼接:复杂
- 执行建表SQL语句
- step4:创建ODS层增量表:57张表
- 读取增量表表名
- 动态获取表名:循环读取文件
- 获取表的信息:表的注释
- Oracle:表的信息
- 从Oracle中获取表的注释
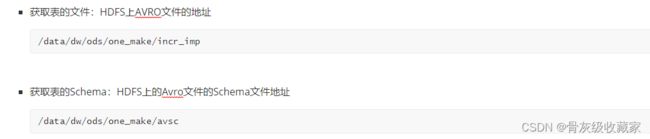
- 拼接建表字符串
- 执行建表SQL语句
ODS层构建:创建项目环境
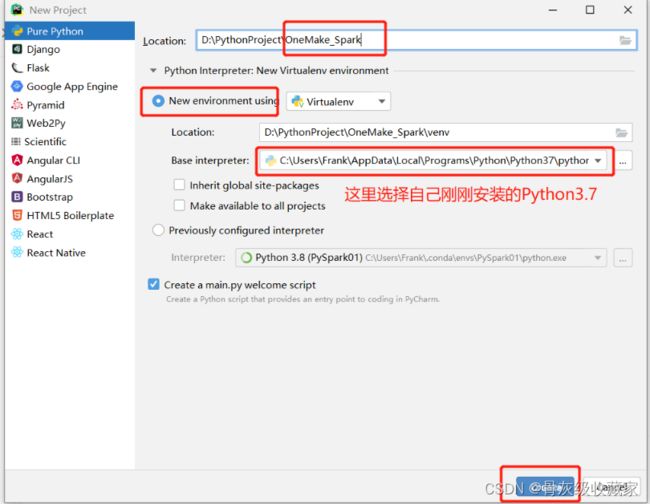
目标:实现Pycharm中工程结构的构建
实施
安装Python3.7环境

项目使用的Python3.7的环境代码,所以需要在Windows中安装Python3.7,与原先的Python高版本不冲突,正常安装即可
创建Python工程
安装PyHive、Oracle库
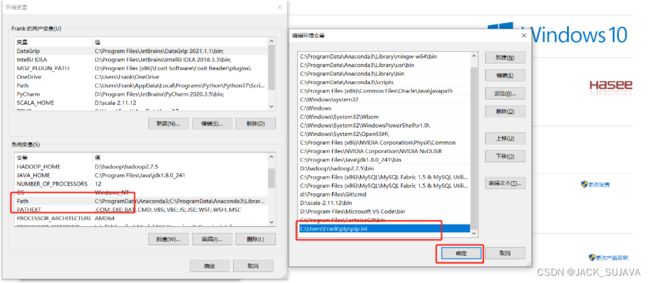
- step1:在Windows的用户家目录下创建pip.ini文件
- 例如:**C:\Users\Frank\pip\pip.ini**
- 内容:指定pip安装从阿里云下载

step2:将文件添加到Windows的**Path环境变量**中
step3:进入项目环境目录
- 例如我的项目路径是:**D:\PythonProject\OneMake_Spark\venv\Scripts**

将提供的**sasl-0.2.1-cp37-cp37m-win_amd64.whl**文件放入Scripts目录下
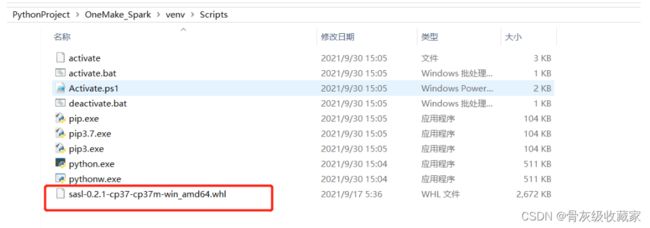 在CMD中执行以下命令,切换到Scripts目录下
在CMD中执行以下命令,切换到Scripts目录下

step4:CMD中依次执行以下安装命令

step5:验证安装结果
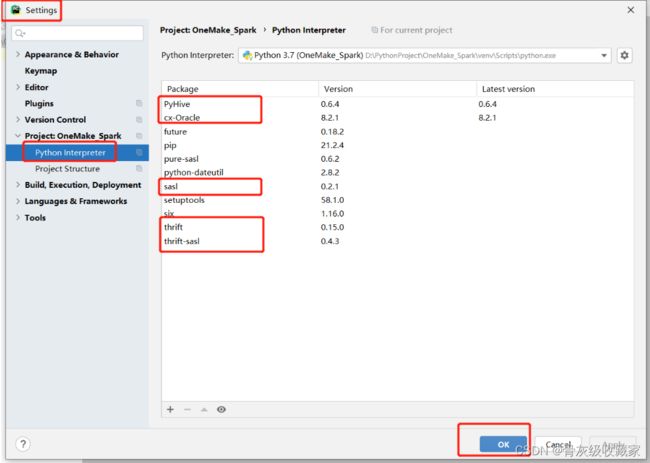
温馨提示:其实工作中你也可以通过Pycharm直接安装