spring的三级缓存和循环依赖问题
循环依赖是一个老生常谈的问题,被大家所熟知。大家也都知道spring采用setter注入解决循环依赖问题。但是spring底层是怎么解决循环依赖问题的呢?
没错就是spring的三级缓存来解决循环依赖问题,今天我们就一起聊一聊spring的三级缓存,何它为什么解决循环依赖问题。
什么是Spring循环依赖呢?
spring中Bean的生命周期是什么样子的?
想聊spring的循环依赖问题,那么我们就必须清楚的理解spring中创建Bean对象的过程,不然就是高空建楼。
-
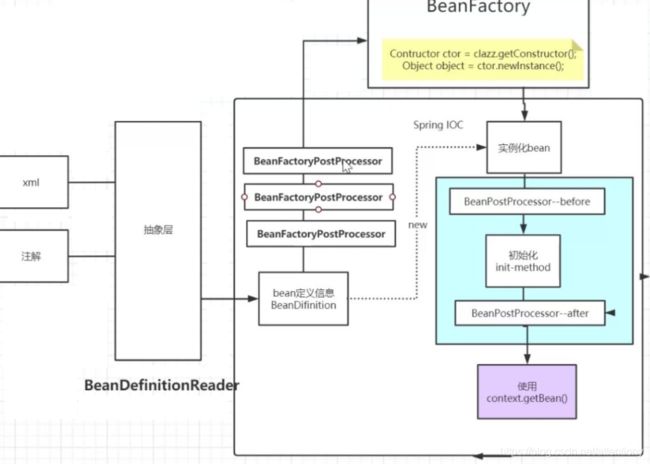
BeanFactory初始化
-
BeanDifinition加载xml、注解的创建对象所需要的配置信息(依赖注入 、属性注入过程)
-
BeanFacctoryPostProcessor 把BeanDifinition定义配置信息修改加载到BeanFactory
-
BeanFactory工厂实例化Bean对象
-
BeanFactory工厂初始化对象 (初始化分为三个步骤)
. BeanPostProcessor--- before
. init-method ---初始化方法
. BeanPostProcessor ---after
到此为止 spring创建对象的过程我们大致的了解了一下
spring创建对象的过程图解
Spring的循环依赖问题出现在spring创建过程的那一步?
bean对象初始化的过程(Spring的对象的创建过程拆分成实例化和初始化两个过程。实例化只是创建对象实例,而初始化是对象的属性资源进行填充赋值)
什么是Spring的三级缓存?
说了那么多废话,终于到正题了(也不算是废话,能帮助我们理解构成知识体系结构)。
三级缓存就是DefaultSingletonBeanRegistry类的三个hashmap
/** 一级缓存:singletonObjects:存放初始化好的bean,可以直接使用的bean*/
/** Cache of singleton objects: bean name --> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
/**二级缓存:经过一级缓存处理后的实例化bean,是singletonFactory 制造出来的 singleton 的缓存。*/
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16);
/**三级缓存:存放工厂 /
/** Cache of early singleton objects: bean name --> bean instance */
private final Map earlySingletonObjects = new HashMap(16);
常见的解决循环依赖的是setter注入,也可以采用构造器和setter方法混合使用解决循环依赖问题
循环依赖的本质解决方案是spring的DefaultSingletinBenRegistry三个map类实现的,俗称三级缓存。
在spring获取对象的时候 ,首先会在一级缓存中寻找bean对象,如果,没有那么就会去二级缓存找,然后三级缓存继续找,找不到就创建对象。
1.从缓存中。优先从一级缓存中拿,有则返回。 如果没有,则从二级缓存中获取,有则返回。 如果二级缓存中拿不到,则从三级缓存中拿,能拿到,则从三级缓存中删除,移到二级缓存。
如果三级缓存也没有,则返回null.
2. 如果是单例模式, 则走createBean 的流程,进行bean对象的实例化。
2.1 获取到该beanDefinition对应的字节码对象。
2.2 prepareMethodOverrides。 检查beanDefinition对象的每一个methodOverride的对象。如果该对象对应的同名的方法只有一个则设置为false, 默认设置为true.
2.3 调用doCreateBean 方法,进行具体的实例化过程。
3.
3.1 如果是单例的,则从bean工厂的实例缓存中获取bean对象。
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
3.2 如果获取到的为空, 则进行bean对象的实例化创建。调用createBeanInstance
if (instanceWrapper == null) {
//创建实例,,重点看,重要程度:5
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
3.3如果有FactoryMethodName属性,则通过factorymethod 方法进行对象的实例化。
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
3.4 否则,寻找当前正在实例化的bean中有@Autowired注解的构造函数
// 调用SmartInstantiationAwareBeanPostProcessor类型的beanpostProcess.determineCandidateConstructors 获取有autowired和value注解的构造器。
Constructor[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
3.5 //如果ctors不为空,就说明构造函数上有@Autowired注解, 则通过构造函数进行初始化。
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
//如果ctors不为空,就说明构造函数上有@Autowired注解
return autowireConstructor(beanName, mbd, ctors, args);
}
3.6 如果首选的构造器不为空, 则使用首选的构造器进行实例化,以及进行以来注入
// Preferred constructors for default construction?
ctors = mbd.getPreferredConstructors();
if (ctors != null) {
return autowireConstructor(beanName, mbd, ctors, null);
}
3.7 否则调用无参构造函数进行bean的实例化。
//无参构造函数的实例化,大部分的实例是采用的无参构造函数的方式实例化,并包装成一个BeanWrapper 对象进行返回。
return instantiateBean(beanName, mbd);
4. 调用applyMergedBeanDefinitionPostProcessors。主要是对实现了MergedBeanDefinitionPostProcessor接口的postProcessMergedBeanDefinition方法调用。
主要的实现类有:
4.1 AutowiredAnnotationBeanPostProcessor。在postProcessMergedBeanDefinition方法中实现对Autowired,Value注解的注解信息收集,封装到externallyManagedConfigMembers。
4.2 CommonAnnotationBeanPostProcessor。 在postProcessMergedBeanDefinition方法中实现对@PostConstrutor 和 @ PreDestory ,@Resource 注解的信息收集,封装到externallyManagedConfigMembers。
5. 检查是否允许循环依赖,以及是否是单例模式。满足条件的话,从二级缓存中移除,并且添加到三级缓存中。
6.进行属性的注入,调用populateBean 方法。
6.1 根据注入的模式,进行对应属性的字段,filed ,以及method依赖的解析。获取其依赖的对象的值。
6.2 调用实现了InstantiationAwareBeanPostProcessor接口的postProcessProperties 方法,对有autowired,value,resource 注解的属性实现属性值的注入。
在AutowiredAnnotationBeanPostProcessor中实现对autowired,value 属性的注入。
在CommonAnnotationBeanPostProcessor中实现对resource 属性的注入。
6.3 调用applyPropertyValues 方法,实现对二级缓存其实就够解决循环依赖问题,但为什么还有三级缓存?
三级缓存其实在不考虑aop代理的情况下完全时够用的 ,在循环依赖问题中,如果循环对象是代理的,三级缓存的工厂可以提前暴露代理对象来解决依赖注入。如果用二级缓存的话,那么二级缓存就必须在实例化被代理对象之后立刻代理被代理对象,这样违背了spring的设计初衷 。spring的代理都在后置处理器BeanPostProcessor中完成代理的步骤,