【AI视野·今日Robot 机器人论文速览 第四十二期】Wed, 27 Sep 2023
AI视野·今日CS.Robotics 机器人学论文速览
Wed, 27 Sep 2023
Totally 48 papers
上期速览✈更多精彩请移步主页

Interesting:
***Tactile Estimation of Extrinsic Contact,基于触觉的外部接触估计与稳定放置 (from 三菱电机)


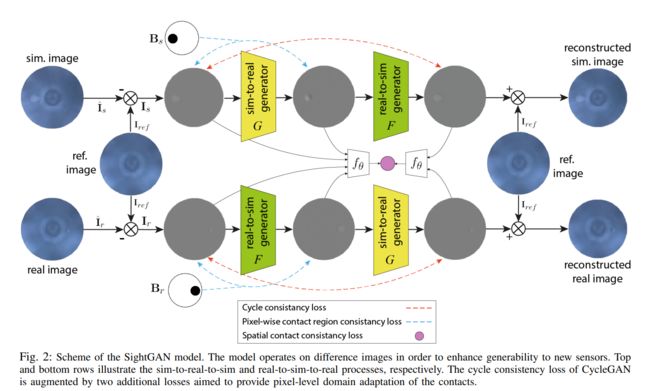
充气型柔性触觉传感器, 气囊型触觉传感器用于直肠癌早期息肉肿块检测(from University of Texas at Austin.)


触觉仿真器, (from Tel-Aviv University)

Daily Robotics Papers
| Towards High Efficient Long-horizon Planning with Expert-guided Motion-encoding Tree Search Authors Tong Zhou, Erli Lyu, Jiaole Wang, Guangdu Cen, Ziqi Zha, Senmao Qi, Max Q. H. Meng 自动驾驶有望提高安全性、优化交通管理并将交通便利性提升到新水平。 |
| Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding Authors Christina Kassab, Matias Mattamala, Lintong Zhang, Maurice Fallon 多功能和自适应语义理解将使自主系统能够理解周围环境并与之交互。现有的固定类别模型限制了室内移动和辅助自主系统的适应性。在这项工作中,我们介绍了 LEXIS,这是一种实时室内同步定位和地图 SLAM 系统,它利用大型语言模型法学硕士的开放词汇性质来创建场景理解和地点识别的统一方法。该方法首先使用视觉惯性里程计构建环境的拓扑 SLAM 图,并将对比语言图像预训练 CLIP 特征嵌入到图节点中。我们使用这种表示形式进行灵活的房间分类和分割,作为以房间为中心的位置识别的基础。这使得闭环搜索能够定向到语义相关的位置。我们提出的系统使用公共、模拟数据和现实世界数据进行评估,涵盖办公室和家庭环境。它成功地对具有不同布局和尺寸的房间进行分类,并且优于最先进的 SOTA。对于位置识别和轨迹估计任务,我们实现了与 SOTA 相同的性能,所有这些任务也都使用相同的预训练模型。 |
| Near Real-Time Position Tracking for Robot-Guided Evacuation Authors Mollik Nayyar, Alan Wagner 在建筑物疏散过程中,引导机器人可以快速准确地跟踪人类疏散人员,以提高疏散的有效性 1, 2 。本文介绍了一种为疏散机器人量身定制的近实时人体位置跟踪解决方案。使用姿势检测器,我们的系统首先近乎实时地识别相机帧中的人体关节,然后通过简单的校准过程将这些像素的位置转换为现实世界坐标。我们在室内实验室环境中对该系统进行了多次试验,结果表明,与地面实况相比,该系统可以达到 0.55 米的精度。该系统还可以实现平均每秒 3 帧的 FPS,这足以满足我们对机器人引导人员疏散的研究。 |
| When Prolog meets generative models: a new approach for managing knowledge and planning in robotic applications Authors Enrico Saccon, Ahmet Tikna, Davide De Martini, Edoardo Lamon, Marco Roveri, Luigi Palopoli Department of Information Engineering and Computer Science, Universit di Trento, Trento, Italy 在本文中,我们提出了一种基于Prolog语言的面向机器人的知识管理系统。我们的框架取决于知识库的特殊组织,它能够:1.使用基于大型语言模型的半自动化程序从自然语言文本中高效填充,2.通过一系列转换为多机器人系统无扰生成时间并行计划, 3. 将计划自动翻译为可执行的形式主义行为树。 |
| Modeling Evacuee Behavior for Robot-Guided Emergency Evacuation Authors Mollik Nayyar, Alan Wagner 本文考虑了在机器人引导的紧急疏散过程中开发合适的人类疏散人员行为模型的问题。我们描述了我们最近开发的撤离人员行为模型的研究以及这些模型的未来潜在用途。 |
| Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild Authors Hongjie Fang, Hao Shu Fang, Yiming Wang, Jieji Ren, Jingjing Chen, Ruo Zhang, Weiming Wang, Cewu Lu 虽然人类可以使用手臂以外的部分进行收集和支撑等操作,但机器人是否能够有效地学习和执行相同类型的操作仍然相对未经探索。由于这些操作需要关节水平控制来调节机器人的完整姿势,因此我们开发了 AirExo,这是一种低成本、适应性强的便携式双臂外骨骼,用于远程操作和演示采集。由于收集远程操作数据既昂贵又耗时,我们进一步利用 AirExo 在野外大规模演示中收集廉价数据。在我们的野外学习框架下,我们表明,只需 3 分钟的远程操作演示,再加上 AirExo 收集的多样化和广泛的野外数据,机器人就可以学习一种与远程操作中学到的策略相当甚至更好的策略。示威持续20多分钟。实验表明,我们的方法使模型能够在任务的各个阶段学习更通用、更稳健的策略,即使存在干扰,也能提高任务完成的成功率。 |
| Integration of Large Language Models within Cognitive Architectures for Autonomous Robots Authors Miguel . Gonz lez Santamarta, Francisco J. Rodr guez Lera, ngel Manuel Guerrero Higueras, Vicente Matell n Olivera 最近,大型语言模型法学硕士的使用量有所增加,这不仅是因为其准确性的显着提高,还因为使用了量化功能,可以在没有强烈硬件要求的情况下运行这些模型。结果,法学硕士数量激增。它意味着创建各种各样具有不同能力的法学硕士。通过这种方式,本文提出将法学硕士集成到自主机器人的认知架构中。具体来说,我们介绍了 llama ros 工具的设计、开发和部署,该工具允许在基于 ROS 2 的环境中轻松使用和集成 LLM,然后与最先进的认知架构 MERLIN2 集成,以更新基于 PDDL 的规划器系统。 |
| Virtual Reality as a Tool for Studying Diversity and Inclusion in Human-Robot Interaction: Advantages and Challenges Authors Andr Helgert, Sabrina C. Eimler, Carolin Stra mann 本文探讨了虚拟现实 VR 作为研究人类机器人交互 HRI 背景下的多样性和包容性特征的研究工具的潜力。讨论了在 HRI 中使用 VR 的一些独特优势,例如可控环境、操纵与机器人和人机交互相关的变量的可能性、机器人和环境设计的灵活性以及相关的先进测量方法,例如机器人和人机交互。眼球追踪和生理数据。同时,描述了在 HRI 中研究多样性和包容性的挑战,特别是在开发 VR 环境时的可访问性、网络病和偏见方面。 |
| Interaction-Aware Sampling-Based MPC with Learned Local Goal Predictions Authors Walter Jansma, Elia Trevisan, lvaro Serra G mez, Javier Alonso Mora 在紧凑、交互丰富且混合的人类机器人环境中,自主机器人的运动规划具有挑战性。最先进的方法通常将预测和规划分开,首先预测其他智能体的轨迹,然后规划自我智能体在剩余自由空间中的运动。然而,代理人缺乏对自己对他人影响的认识,可能会导致机器人冻结问题。我们以交互感知模型预测路径积分 IA MPPI 控制为基础,并将其与基于学习的轨迹预测相结合,从而减轻了其对其他代理传达的短期目标的依赖。我们将此框架应用于在城市运河中航行的自主水面船舶 ASV。通过在阿姆斯特丹运河的真实部分生成人工数据集,调整和训练我们领域的预测模型,并提出启发式方法来提取本地目标,我们可以在规划中实现有效的合作。 |
| Verifiable Learned Behaviors via Motion Primitive Composition: Applications to Scooping of Granular Media Authors Andrew Benton, Eugen Solowjow, Prithvi Akella 由于系统灵活性增强,能够根据自然语言输入实时可靠地生成行为的机器人行为模型将大大加快工业机器人的采用。为了促进这些努力,我们构建了一个框架,其中由自然语言抽象器创建的学习行为可以通过构造进行验证。利用运动原语和概率验证方面的最新进展,我们构建了一个自然语言行为抽象器,它通过在提供的运动原语上合成有向图来生成行为。如果这些组件运动基元是根据我们指定的标准构建的,则所产生的行为在概率上是可验证的。 |
| A Passive Variable Impedance Control Strategy with Viscoelastic Parameters Estimation of Soft Tissues for Safe Ultrasonography Authors Luca Beber 1 , Edoardo Lamon 2,3 , Davide Nardi 2 , Daniele Fontanelli 1 , Matteo Saveriano 1 , Luigi Palopoli 2 , 1 Department of Industrial Engineering, Universit di Trento, Trento, Italy, 2 Department of Information Engineering and Computer Science, Universit di Trento, Trento, Italy, 3 Human Robot Interfaces and Interaction, Istituto Italiano di Tecnologia, Genoa, Italy 在远程医疗的背景下,机器人方法已被证明是偏远地区亲自就诊的宝贵解决方案,可以降低患者的成本和感染风险。特别是在超声检查中,机器人有潜力重现获取高质量图像所需的技能,同时减少超声检查人员的体力劳动。在本文中,我们解决了探头与患者身体相互作用的控制,这是确保安全有效超声检查的关键方面。我们引入了一种基于可变阻抗控制的新颖方法,允许在超声过程中实时优化兼容的控制器参数。这种优化被表述为二次规划问题,并结合了从粘弹性参数估计导出的物理约束。还集成了安全和被动约束(包括能量罐),以最大程度地减少人机交互过程中的潜在风险。 |
| Seafloor Classification based on an AUV Based Sub-bottom Acoustic Probe Data for Mn-crust survey Authors Umesh Neettiyath, Harumi Sugimatsu, Blair Thornton 本文研究了自动分类从自主水下机器人收集的高频海底声学反射的可能性。在富钴锰结壳锰结壳的现场调查中,现有方法依赖于通过海底探测器的图像和厚度测量对海底进行目视确认。使用这些视觉分类结果作为基本事实,训练自动编码器从捆绑的声学反射中提取潜在特征。然后训练支持向量机分类器对潜在空间进行分类,以识别海底类别。 |
| A Wearable Robotic Hand for Hand-over-Hand Imitation Learning Authors Dehao Wei, Huazhe Xu 通过模仿学习进行灵巧操作在机器人研究中引起了广泛关注。使用模仿学习时,收集高质量的专家数据至关重要。获取专家数据的现有方法通常涉及利用数据手套来捕获手部运动信息。然而,这种方法存在局限性,因为由于自由度或结构的差异,收集到的信息无法直接映射到机器人手。此外,在演示过程中无法准确捕捉手与物体之间的力反馈信息。为了克服这些挑战,本文提出了一种可穿戴灵巧手形式的新颖解决方案,即Hand over hand模仿学习可穿戴机器人手HIRO Hand,它集成了专家数据收集并能够实施灵巧操作。这款 HIRO Hand 使操作员能够利用自己的触觉反馈来确定适当的力、位置和动作,从而更准确地模仿专家的动作。 |
| Graph Neural Network Based Method for Path Planning Problem Authors Xingrong Diao, Wenzheng Chi, Jiankun Wang 基于采样的路径规划是机器人技术中广泛使用的方法,特别是在高维状态空间中。在路径规划的整个过程中,碰撞检测是最耗时的操作。在本文中,我们提出了一种基于学习的路径规划方法,旨在减少碰撞检测的数量。我们开发了一种基于图神经网络 GNN 的高效神经网络模型,并使用环境图作为输入。该模型根据输入和当前顶点信息输出每个邻居的权重,用于指导规划器避开障碍物。我们分别通过模拟随机世界和现实世界实验评估所提出方法的效率。 |
| Realtime Motion Generation with Active Perception Using Attention Mechanism for Cooking Robot Authors Namiko Saito, Mayu Hiramoto, Ayuna Kubo, Kanata Suzuki, Hiroshi Ito, Shigeki Sugano, Tetsuya Ogata 为了支持人类的日常生活,机器人需要自主学习、适应物体和环境并执行适当的动作。我们解决了用真材实料炒鸡蛋的任务,其中机器人需要感知鸡蛋的状态并实时调整搅拌动作,同时鸡蛋被加热,状态不断变化。在之前的工作中,处理变化的物体被发现具有挑战性,因为感觉信息包括动态的、重要的或噪声的信息,以及每次都应该关注变化的模态,使得实时感知和运动生成变得困难。我们提出了一种具有注意机制的预测循环神经网络,可以权衡传感器输入,区分每种模态的重要性和可靠性,从而实现快速高效的感知和运动生成。该模型通过从演示中学习来进行训练,并使机器人能够获得类似人类的技能。我们使用机器人 Dry AIREC 验证了所提出的技术,并且通过我们的学习模型,它可以用未知成分烹饪鸡蛋。机器人可以根据鸡蛋的状态改变搅拌的方式和方向,一开始是在整个锅里搅拌,随后,当鸡蛋开始加热后,它开始针对特定区域进行翻转和分裂运动,尽管 |
| A Structured Prediction Approach for Robot Imitation Learning Authors Anqing Duan, Iason Batzianoulis, Raffaello Camoriano, Lorenzo Rosasco, Daniele Pucci, Aude Billard 我们提出了一种通过演示进行机器人模仿学习的结构化预测方法。在机器人模仿学习的各种工具中,监督学习被认为具有突出的作用。结构化预测是监督学习的一种形式,使学习模型能够在具有复杂结构的输出空间上运行。通过结构化预测的镜头,我们展示了机器人如何学习模仿不仅属于欧几里得空间而且属于黎曼流形的轨迹。利用信息论的思想,我们提出了一类基于 f 散度的损失函数来测量演示和再现的概率轨迹之间的信息损失。不同类型的f散度会导致不同的策略,我们称之为模仿模式。此外,我们的方法能够结合空间和时间轨迹调制,这对于机器人适应工作条件的变化是必要的。我们在轨迹再现和适应方面将我们的算法与最先进的方法进行了基准测试。定量评估表明,我们的方法在准确性和效率方面均优于其他算法。 |
| Less Is More: Robust Robot Learning via Partially Observable Multi-Agent Reinforcement Learning Authors Wenshuai Zhao, Eetu Aleksi Rantala, Joni Pajarinen, Jorge Pe a Queralta 在许多多智能体和高维机器人任务中,控制器可以集中式或分散式设计。相应地,可以使用单智能体强化学习 SARL 或多智能体强化学习 MARL 方法来学习此类控制器。然而,这两种范式之间的关系仍在文献中进行研究。这项工作探讨了 SARL 和 MARL 方法对同一任务的稳健性和性能方面的研究问题,以便深入了解最合适的方法。我们首先分析地展示了在全状态观察假设下这两种范式之间的等价性。然后,我们确定了 textit Dec POMDP 任务的一个广泛子类,其中代理弱交互或部分交互。在这些任务中,我们表明对每个智能体的部分观察足以做出接近最优的决策。此外,我们建议利用这种部分可观察的 MARL 来提高机器人在发生关节或代理故障时的鲁棒性。 |
| Volumetric Semantically Consistent 3D Panoptic Mapping Authors Yang Miao, Iro Armeni, Marc Pollefeys, Daniel Barath 我们引入了一种在线 2D 到 3D 语义实例映射算法,旨在生成适合非结构化环境中自主代理的全面、准确且高效的语义 3D 地图。所提出的方法基于最近算法中使用的体素 TSDF 表示。它引入了在映射过程中集成语义预测置信度的新方法,生成语义和实例一致的 3D 区域。通过基于语义标记和实例细化的图优化实现了进一步的改进。所提出的方法在公共大规模数据集上实现了优于现有技术的准确性,改进了许多广泛使用的指标。 |
| Learning to Assist Different Wearers in Multitasks: Efficient and Individualized Human-In-the-Loop Adaption Framework for Exoskeleton Robots Authors Yu Chen, Gong Chen, Jing Ye, Chenglong Fu, Bin Liang, Xiang Li 使用下肢外骨骼机器人的典型目的之一是根据给定的任务和人类运动意图,通过支撑佩戴者的体重并增强其身体能力来为佩戴者提供帮助。机器人在多个任务中跨不同佩戴者的通用性对于确保机器人能够在实际实施中提供正确有效的帮助非常重要。然而,大多数下肢外骨骼机器人仅表现出有限的通用性。因此,本文提出了一种用于外骨骼机器人的人在环学习和适应框架,以提高其在各种任务和不同佩戴者中的性能。为了适应不同的佩戴者,使用动态运动原语和贝叶斯优化在线生成个性化的行走轨迹。为了适应各种任务,使用神经网络构建任务翻译器以将轨迹推广到更复杂的场景。这些泛化技术被集成到统一的可变阻抗模型中,该模型可以调节外骨骼以在确保安全的同时提供帮助。此外,还开发了异常检测网络来定量评估佩戴者的舒适度,这在轨迹学习过程中得到考虑,有助于缓解阻抗控制中的冲突。所提出的框架很容易实现,因为它只需要本体感受传感器来执行和部署数据高效的学习方案。这使得外骨骼可以在复杂的场景中部署,适应不同的行走模式、习惯、任务和冲突。 |
| On The Effects of The Variations In Network Characteristics In Cyber Physical Systems Authors G za Szab , S ndor R cz, J zsef Pet , Rafael Roque Aschoff 流行的机器人模拟器 Gazebo 缺乏模拟控制延迟影响的功能,而这一功能使其成为成熟的网络物理系统 CPS 模拟器。我们要测量的 CPS 是通过速度命令远程控制的机械臂 UR5。主要目标是在模拟环境中的各种网络条件下测量控制质量 QoC 相关的 KPI。我们提出了一个 Gazebo 插件,通过使 Gazebo 能够延迟内部控制和状态消息,并与外部网络模拟器连接以获得更先进的网络效果,从而使上述测量变得可行。 |
| DriveSceneGen: Generating Diverse and Realistic Driving Scenarios from Scratch Authors Shuo Sun, Zekai Gu, Tianchen Sun, Jiawei Sun, Chengran Yuan, Yuhang Han, Dongen Li, Marcelo H. Ang Jr 大量真实且多样化的交通场景对于自动驾驶系统的开发和验证至关重要。然而,由于数据收集过程中存在诸多困难以及对密集注释的依赖,现实世界的数据集缺乏足够的数量和多样性来支持不断增长的数据需求。这项工作介绍了 DriveSceneGen,这是一种数据驱动的驾驶场景生成方法,可以从现实世界的驾驶数据集中学习并从头开始生成整个动态驾驶场景。 DriveSceneGen 能够生成新颖的驾驶场景,这些场景与现实世界的数据分布保持一致,具有高保真度和多样性。与现实世界数据集相比,5k 生成场景的实验结果突出了生成质量、多样性和可扩展性。 |
| Field Testing of a Stochastic Planner for ASV Navigation Using Satellite Images Authors Philip Yizhou Huang, Tony Qiao Wang, Florian Shkurti, Timothy D. Barfoot 我们推出了用于自主水面船舶 ASV 的多传感器导航系统,旨在监测淡水湖的水质。我们的任务规划器使用卫星图像作为事先地图,离线制定 ASV 全球导航的任务级策略,并通过本地感知和本地规划模块实现自主在线执行。由于风、水生植被、浅水区和水位波动等环境影响,卫星图像和真实湖泊之间的可通行性估计不一致,带来了重大挑战。因此,我们专门将这些可穿越性不确定性建模为图中的随机边,并针对任务级策略进行优化,以最大限度地减少预期总行驶距离。为了执行该策略,我们提出了一种现代本地规划器架构,该架构可处理传感器输入并规划路径,以在不确定的可遍历性条件下执行高级策略。我们的系统在安大略省北部的湖泊上进行了三公里规模的任务测试,证明我们的 GPS、视觉和声纳启用的 ASV 系统可以有效地执行任务级策略并消除随机边缘的可穿越性的歧义。 |
| Probabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter Authors Hsu kuang Chiu, Chien Yi Wang, Min Hung Chen, Stephen F. Smith 目前最先进的自动驾驶车辆主要依靠每个单独的传感器系统来执行感知任务。这种框架的可靠性可能会受到遮挡或传感器故障的限制。为了解决这个问题,最近的研究建议使用车辆对车辆的 V2V 通信来与其他人共享感知信息。然而,大多数相关工作仅关注协作检测,而使协作跟踪成为尚未开发的研究领域。最近的一些数据集(例如 V2V4Real)提供了 3D 多对象协作跟踪基准。然而,他们提出的方法主要使用协作检测结果作为基于标准单传感器卡尔曼滤波器的跟踪算法的输入。在他们的方法中,可能无法正确估计来自不同联网自动驾驶车辆 CAV 的不同传感器的测量不确定性,以利用基于卡尔曼滤波器的跟踪算法的理论最优性特性。在本文中,我们提出了一种通过可微分多传感器卡尔曼滤波器实现自动驾驶的新型 3D 多目标协作跟踪算法。我们的算法学习估计每次检测的测量不确定性,从而可以更好地利用基于卡尔曼滤波器的跟踪方法的理论特性。 |
| Ambient-Aware LiDAR Odometry in Variable Terrains Authors Mazeyu Ji, Wenbo Shi, Yujie Cui, Chengju Liu, Qijun Chen 同时定位和建图 SLAM 算法在各种环境中的灵活性一直是一个重大挑战。为了解决激光雷达里程计在高噪声环境下的漂移问题,集成聚类方法过滤掉不稳定特征已成为SLAM框架的有效模块。然而,减少点云数据量可能会导致潜在的信息丢失和可能的退化。因此,本研究提出了一种可以动态评估点云可靠性的激光雷达里程计。该算法旨在通过选择对环境退化水平敏感的重要特征点来提高在不同环境中的适应性。首先,提出一种基于距离图像的快速自适应欧氏聚类算法,结合深度聚类,提取环境的主要结构点,定义为环境骨架点。然后,通过骨架点的密集法线特征计算环境退化级别,并相应地动态调整点云清理。 |
| Neural Informed RRT* with Point-based Network Guidance for Optimal Sampling-based Path Planning Authors Zhe Huang, Hongyu Chen, Katherine Driggs Campbell 基于采样的规划算法(例如快速探索随机树 RRT)在解决路径规划问题方面具有多种用途。 RRT 提供渐近最优性,但需要在自由空间上均匀地生长树,这为效率提高留下了空间。为了加速收敛,知情方法在迭代期间由当前路径成本确定的搜索空间的椭圆体子集中采样状态。基于学习的替代方案对搜索空间的拓扑进行建模,并推断接近最佳路径的状态以指导规划。我们结合双方的优势,提出了带有基于点的网络指导的神经通知 RRT。我们引入基于点的网络来推断引导状态,并将网络集成到 Informed RRT 中以进行引导状态细化。我们使用 Neural Connect 来构建指导状态集的连接,并进一步提高具有挑战性的规划问题的性能。我们的方法在路径规划基准方面超越了以前的工作,同时保持了概率完整性和渐近最优性。 |
| Learning Vision-Based Bipedal Locomotion for Challenging Terrain Authors Helei Duan, Bikram Pandit, Mohitvishnu S. Gadde, Bart Jaap van Marum, Jeremy Dao, Chanho Kim, Alan Fern 用于双足运动的强化学习 RL 最近仅使用本体感觉传感在中等地形上展示了稳健的步态。然而,这种盲人控制器在机器人必须预测并适应当地地形(这需要视觉感知)的环境中会失败。在本文中,我们提出了一个完全学习的系统,该系统允许双足机器人对当地地形做出反应,同时保持命令的行进速度和方向。我们的方法首先使用机器人局部坐标系中表示的高度图在模拟中训练控制器。接下来,在模拟中收集数据以训练高度图预测器,其输入是深度图像和机器人状态的历史记录。我们证明,通过适当的域随机化,这种方法可以成功地从模拟到真实的传输,而无需明确的姿态估计,也无需使用真实世界数据进行微调。 |
| HeLiPR: Heterogeneous LiDAR Dataset for inter-LiDAR Place Recognition under Spatial and Temporal Variations Authors Minwoo Jung, Wooseong Yang, Dongjae Lee, Hyeonjae Gil, Giseop Kim, Ayoung Kim 位置识别对于同步定位和建图 SLAM 中的机器人定位和闭环至关重要。最近,激光雷达因其强大的传感能力和测量一致性而受到欢迎,即使在光照变化的环境中,也比传统成像传感器具有优势。旋转激光雷达在多种类型中被广泛接受,而非重复扫描模式最近已在机器人应用中使用。除了范围测量之外,一些 LiDAR 还提供额外的测量,例如反射率、近红外 NIR 和速度(例如 FMCW LiDAR)。尽管取得了这些进步,但数据集的明显缺乏全面反映了针对地点识别而优化的广泛 LiDAR 配置。为了解决这个问题,我们的论文提出了 HeLiPR 数据集,该数据集专门用于异构 LiDAR 系统的地点识别,体现了时空变化。据我们所知,HeLiPR 数据集是第一个异构 LiDAR 数据集,旨在支持非重复和旋转 LiDAR 之间的 LiDAR 位置识别,适应不同视场 FOV 和不同数量的光线。它包含独特的激光雷达配置,在一个月内捕获从城市景观到高动态高速公路的各种环境,旨在增强跨不同场景的地点识别的适应性和鲁棒性。值得注意的是,HeLiPR 数据集还包括与 MulRan 并行序列的轨迹,强调了其在异构 LiDAR 位置识别和长期研究中的实用性。 |
| Integrating Higher-Order Dynamics and Roadway-Compliance into Constrained ILQR-based Trajectory Planning for Autonomous Vehicles Authors Hanxiang Li, Jiaqiao Zhang, Sheng Zhu, Dongjian Tang, Donghao Xu 本文讨论了自动乘用车 APV 道路轨迹规划方面的进展。轨迹规划旨在考虑车辆动力学、约束和检测到的障碍物等各种因素,为 APV 生成全局最优路线。传统技术涉及采样方法和优化算法的组合,前者确保全局意识,后者针对局部最优进行细化。值得注意的是,最近出现了约束迭代线性二次调节器 CILQR 优化算法,适用于 APV 系统,强调提高安全性和舒适性。然而,利用车辆自行车运动学模型的现有实现可能无法保证可控轨迹。我们通过合并高阶项(包括曲率和纵向加加速度的一阶和二阶导数)来增强该模型。这种包含有助于在我们的成本和约束设计中提供更丰富的表示。我们还解决道路合规性问题,强调遵守车道边界和方向,而过去的工作经常忽视这一点。最后,我们采用宽松的对数障碍函数来解决 CILQR 对可行初始轨迹的依赖。 |
| Tactile Estimation of Extrinsic Contact Patch for Stable Placement Authors Kei Ota, Devesh K. Jha, Krishna Murthy Jatavallabhula, Asako Kanezaki, Joshua B. Tenenbaum 接触交互的精确感知对于机器人的细粒度操作技能至关重要。在本文中,我们介绍了机器人的反馈技能设计,这些机器人必须学会将复杂形状的物体堆叠在一起。为了设计这样的系统,机器人应该能够通过非常温和的接触交互来推断放置的稳定性。我们的结果表明,可以根据物体与其环境之间形成接触期间的触觉读数来推断物体放置的稳定性。特别是,我们使用力和触觉观察来估计所抓取的物体与其环境之间的接触面,以估计接触形成期间物体的稳定性。接触面可用于估计释放抓握时物体的稳定性。 |
| Fall Prediction for Bipedal Robots: The Standing Phase Authors M. Eva Mungai, Gokul Prabhakaran, Jessy W. Grizzle 本文提出了一种双足机器人跌倒预测的新方法,特别针对由突然、初期和间歇性故障引起的站立时潜在跌倒的检测。利用一维卷积神经网络 CNN,我们的方法旨在最大化跌倒预测的提前时间,同时最小化误报率。所提出的算法独特地集成了各种故障类型的检测并估计潜在跌倒的提前时间。我们的贡献包括开发一种能够检测全尺寸机器人突然、初期和间歇性故障的算法,使用人形机器人的模拟和硬件数据实现该算法,以及一种估计交付时间的方法。评估指标,包括误报率、交付时间和响应时间,证明了我们方法的有效性。 |
| Motions in Microseconds via Vectorized Sampling-Based Planning Authors Wil Thomason, Zachary Kingston, Lydia E. Kavraki 现代基于采样的运动规划算法通常需要数百毫秒到数十秒才能找到高自由度问题的无碰撞运动。本文提出的性能比现有技术提高了 500 倍以上,将规划时间提高到微秒范围,将求解速率提高到千赫兹范围,而无需专门的硬件。我们的主要见解是如何在基于采样的规划器中利用细粒度并行性,为任何此类规划器提供通用性保留算法改进,并显着加速关键子例程,例如正向运动学和碰撞检查。我们针对 7 到 14 自由度的复杂机器人,针对一系列具有挑战性的现实问题展示了我们的方法。此外,我们还通过在低功耗单板计算机上进行评估来表明我们的方法不需要高功率硬件。 |
| HEROES: Unreal Engine-based Human and Emergency Robot Operation Education System Authors Anav Chaudhary, Kshitij Tiwari, Aniket Bera 由于缺乏现实且易于使用的测试设施,针对大规模伤亡事件 MCI 的培训和准备急救人员和人道主义机器人通常会带来挑战。虽然此类设施可以在 MCI 后提供真实场景,为急救人员和人道主义机器人提供培训和教育目的,但由于后勤限制,它们通常很难进入。为了克服这一挑战,我们推出了 HEROES 一款多功能虚幻引擎模拟器,用于为此类城市搜索和救援行动的人类和应急机器人设计新颖的训练模拟。所提出的 HEROES 模拟器能够为用于训练机器人导航的机器学习管道生成合成数据集。这项工作解决了机器人社区中综合培训平台的必要性,确保为现实世界的紧急情况做好务实、高效的准备。我们的模拟器的优势在于其适应性、可扩展性以及促进机器人开发人员和急救人员之间协作的能力,从而促进在 MCI 中制定有效的搜索和救援行动策略方面的协同作用。 |
| FurNav: Development and Preliminary Study of a Robot Direction Giver Authors Bruce W. Wilson, Yann Schlosser, Rayane Tarkany, Meriam Moujahid, Birthe Nesset, Tanvi Dinkar, Verena Rieser 当给迷路的游客指路时,您会首先参考街道名称、主要方向、地标,还是简单地告诉他们朝一个方向步行 500 米,然后左转 根据具体情况,可以合理地利用以下任何一种方法这些方向给出了风格。然而,对机器人指导的研究通常不会考虑这些不同的指导风格如何影响机器人智能的感知,也没有考虑用户先前的倾向如何影响评分。在这项工作中,我们着眼于使用为 Furhat 机器人创建的系统生成两种导航风格的自然语言,然后在一项小型初步研究 N 7 中测量感知的智力和活泼性以及用户对机器人的先前倾向。我们的结果证实了之前的研究结果,即之前对机器人的负面态度与信任机器人的倾向呈负相关,并且还为未来的研究提出了途径。例如,需要更多数据来探索感知智力和指挥风格之间的联系。 |
| DefGoalNet: Contextual Goal Learning from Demonstrations For Deformable Object Manipulation Authors Bao Thach, Tanner Watts, Shing Hei Ho, Tucker Hermans, Alan Kuntz 形状伺服是一种致力于将物体控制为所需目标形状的机器人任务,是一种有前途的可变形物体操纵方法。然而,由于对球门形状规格的依赖,出现了一个问题。这个目标要么通过费力的领域知识工程过程来实现,要么通过手动将物体操纵成所需的形状并在特定时刻捕获目标形状来实现,这两种方法在各种机器人应用中都是不切实际的。在本文中,我们通过开发一种新颖的神经网络 DefGoalNet 来解决这个问题,该网络直接从少量的人类演示中学习可变形的目标目标形状。我们在模拟和物理机器人上展示了我们的方法在各种机器人任务上的有效性。值得注意的是,在手术牵开任务中,即使只进行了 10 次演示训练,我们的方法也能达到近 90 的中位成功率。 |
| Self-Recovery Prompting: Promptable General Purpose Service Robot System with Foundation Models and Self-Recovery Authors Mimo Shirasaka, Tatsuya Matsushima, Soshi Tsunashima, Yuya Ikeda, Aoi Horo, So Ikoma, Chikaha Tsuji, Hikaru Wada, Tsunekazu Omija, Dai Komukai, Yutaka Matsuo Yusuke Iwasawa 通用服务机器人GPSR能够在各种环境下执行多种任务,需要系统具有较高的通用性以及对任务和环境的适应性。在本文中,我们首先基于多个基础模型为 2023 年 RoboCup Home 全球比赛开发了顶级 GPSR 系统。该系统既可推广到变化,又可通过提示每个模型进行自适应。然后,通过分析所开发系统的性能,我们发现在更现实的GPSR应用设置中信息不足、计划生成不正确和计划执行失败三种类型的故障。然后,我们提出自我恢复提示管道,它探索必要的信息并修改其提示以从故障中恢复。我们通过实验证实,具有自我恢复机制的系统可以通过解决各种故障情况来完成任务。 |
| Exploring Robot Morphology Spaces through Breadth-First Search and Random Query Authors Jie Luo 进化机器人技术为设计和进化机器人形态提供了强大的框架,特别是在模块化机器人的背景下。然而,查询机制在基因型到表型映射过程中的作用在很大程度上被忽视了。这项研究通过对模块化机器人脑体协同进化中的查询机制进行比较分析来解决这一差距。本研究使用两种不同的查询机制(广度优先搜索 BFS 和随机查询),在使用 CPPN 进化机器人形态和使用张量的机器人控制器的背景下,并在拉马克系统和达尔文系统这两个进化框架中对其进行测试,调查它们对进化结果的影响和性能。研究结果证明了两种查询机制对模块化机器人身体的进化和性能的影响,包括形态智能、多样性和形态特征。这项研究表明,BFS 在生产高性能机器人方面更加有效和高效。 |
| Integration of Polyimide Flexible PCB Wings in Northeastern Aerobat Authors Yizhe Xu 本硕士论文的主要目的是通过折纸技术推动东北飞行器膜翼结构的优化,增强其在有限空间内安全悬停的能力。仿生无人机提供独特的功能,为创新应用铺平道路,包括野生动物监测、精准农业、搜索和救援行动以及增强住宅安全。事实证明,鸟类和昆虫进化的降噪机制对于用于监视和野生动物观察等任务的无人机是有利的,可确保操作不受干扰。配备旋转翼或固定翼的传统飞行无人机在狭窄路径上航行时会遇到明显的限制。虽然旋转翼和固定翼系统通常用于监视和侦察,但微型飞行器 MAV 中机载传感器套件的集成引起了人们对警惕监测住宅环境中危险场景的兴趣。尽管四旋翼飞行器等系统在苛刻条件下表现出敏捷性和值得称赞的容错能力,但其不灵活的机身结构阻碍了碰撞容错能力,需要无碰撞的操作空间。近年来,将柔软且柔韧的材料集成到此类系统设计中的热潮兴起,然而,对空气动力学效率的追求限制了转子叶片或螺旋桨过度柔性材料的使用。 |
| Doduo: Learning Dense Visual Correspondence from Unsupervised Semantic-Aware Flow Authors Zhenyu Jiang, Hanwen Jiang, Yuke Zhu 密集的视觉对应在机器人感知中起着至关重要的作用。这项工作的重点是在捕捉经历重大变换的动态场景的一对图像之间建立密集的对应关系。我们引入 Doduo 来从野外图像和视频中学习一般的密集视觉对应,而无需地面实况监督。给定一对图像,它估计密集流场,该密集流场编码一个图像中每个像素相对于另一图像中对应像素的位移。 Doduo 使用基于流的扭曲来获取训练的监控信号。 Doduo 将语义先验与自监督流训练相结合,生成准确的密集对应,对场景的动态变化具有鲁棒性。 Doduo 在野外视频数据集上进行训练,证明了在点级对应估计方面优于现有自监督对应学习基线的性能。我们还将 Doduo 应用于关节估计和零射击目标条件操作,强调了其在机器人技术中的实际应用。 |
| DistillBEV: Boosting Multi-Camera 3D Object Detection with Cross-Modal Knowledge Distillation Authors Zeyu Wang, Dingwen Li, Chenxu Luo, Cihang Xie, Xiaodong Yang 基于从多摄像头鸟瞰 BEV 中学习到的表示的 3D 感知正在成为趋势,因为摄像头对于自动驾驶行业的大规模生产来说具有成本效益。然而,多摄像头 BEV 和基于 LiDAR 的 3D 物体检测之间存在明显的性能差距。一个关键原因是 LiDAR 可以捕获准确的深度和其他几何测量结果,而仅从图像输入推断此类 3D 信息是非常具有挑战性的。在这项工作中,我们建议通过训练基于多摄像头 BEV 的学生检测器模仿训练有素的基于 LiDAR 的教师检测器的特征来增强其表示学习。我们提出了有效的平衡策略,以强制学生专注于从老师那里学习关键特征,并将知识转移到具有时间融合的多尺度层。我们对多摄像头纯电动汽车的多个代表性型号进行了广泛的评估。 |
| Recurrent Hypernetworks are Surprisingly Strong in Meta-RL Authors Jacob Beck, Risto Vuorio, Zheng Xiong, Shimon Whiteson 由于样本效率低下,深度强化学习 RL 的部署非常不切实际。当相关任务的分布可用于元训练时,元强化学习通过学习执行少量样本学习来直接解决样本效率低下的问题。虽然已经提出了许多专门的元强化学习方法,但最近的研究表明,端到端学习与现成的序列模型(例如循环网络)相结合,是一个令人惊讶的强大基线。然而,由于支持证据有限,这种说法一直存在争议,特别是考虑到之前的工作恰恰相反。在本文中,我们进行了实证研究。虽然我们同样发现循环网络可以实现强大的性能,但我们证明超网络的使用对于最大限度地发挥其潜力至关重要。 |
| Towards a Neuronally Consistent Ontology for Robotic Agents Authors Florian Ahrens, Mihai Pomarlan, Daniel Be ler, Thorsten Fehr, Michael Beetz, Manfred Herrmann 日常活动科学工程合作研究中心CRC EASE旨在使机器人能够以接近人类的能力执行环境交互任务。因此,它采用共享本体来模拟两种智能体的活动,使机器人能够从人类经验中学习。为了正确地描述这些人类经历,本体论将极大地受益于神经元信息处理特征的结合,而这些特征是仅从行为角度无法获得的。因此,我们建议对人类神经影像数据进行分析,以评估和验证大多数 CRC 项目背后的本体模型中定义的概念和事件。在一项探索性分析中,我们对来自参与者的功能磁共振成像 fMRI 数据采用了独立成分分析 ICA,这些参与者在不同的环境和背景下被呈现与机器人和人类代理相同的复杂活动视频刺激。然后,我们将派生组件所代表的大脑网络的活动模式与本体模型定义的注释事件类别的时间相关联。目前的结果表明,公共网络的一个子集对于特定事件类别和组具有稳定的相关性和特异性,与环境和背景因素相关。 |
| Semantic Map Learning of Traffic Light to Lane Assignment based on Motion Data Authors Thomas Monninger, Andreas Weber, Steffen Staab 了解哪个交通灯控制哪条车道对于安全通过十字路口至关重要。自动驾驶车辆通常依赖于高清地图,其中包含有关交通灯到车道分配的信息。手动提供此信息非常繁琐、昂贵且不可扩展。为了解决这些问题,我们的新颖方法从交通灯状态和相应的车辆交通运动模式中得出分配。这是一种自动化的方式,并且独立于几何排列。我们通过实施和评估基于模式的贡献方法来展示基本统计方法对于此任务的有效性。此外,我们新颖的拒绝方法包括通过利用统计假设检验来进行安全考虑。最后,我们提出了一种数据集转换,以重新利用可用的运动预测数据集进行语义地图学习。 |
| ADU-Depth: Attention-based Distillation with Uncertainty Modeling for Depth Estimation Authors Zizhang Wu, Zhuozheng Li, Zhi Gang Fan, Yunzhe Wu, Xiaoquan Wang, Rui Tang, Jian Pu 单目深度估计由于其固有的模糊性和不适定性质而具有挑战性,但它对许多应用来说非常重要。虽然最近的工作通过设计日益复杂的网络来从单个 RGB 图像中提取具有有限空间几何线索的特征来实现有限的精度,但我们打算通过训练利用左右图像对作为输入的教师网络并传输学习的 3D 几何来引入空间线索了解单眼学生网络的知识。具体来说,我们提出了一种新颖的知识蒸馏框架,名为 ADU Depth,其目标是利用训练有素的教师网络来指导学生网络的学习,从而借助额外的空间场景信息来提高精确的深度估计。为了实现领域适应并确保从教师到学生的有效且顺利的知识转移,我们在训练阶段应用了注意力适应特征蒸馏和焦点深度适应响应蒸馏。此外,我们对深度估计的不确定性进行显式建模,以指导特征空间和结果空间中的蒸馏,从而更好地从单目观察中生成 3D 感知知识,从而增强对难以预测图像区域的学习。 |
| CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration Authors Shuhao Kang, Youqi Liao, Jianping Li, Fuxun Liang, Yuhao Li, Fangning Li, Zhen Dong, Bisheng Yang 图像到点云 I2P 配准是机器人导航和移动测绘领域的一项基本任务。现有的 I2P 配准工作估计点到像素级别的对应关系,忽略全局对齐。然而,没有全局约束的高级指导的 I2P 匹配可能很容易收敛到局部最优。为了解决这个问题,本文提出了CoFiI2P,一种新颖的I2P注册网络,它以从粗到细的方式提取对应关系以获得全局最优解。首先,将图像和点云输入连体编码器解码器网络以进行分层特征提取。然后,设计一个从粗到细的匹配模块来利用特征并建立弹性特征对应关系。具体来说,在粗匹配块中,采用新颖的 I2P 转换器模块来捕获图像和点云中的同质和异构全局信息。利用判别描述符,估计粗略的超点到超像素匹配对。在精细匹配模块中,通过超点对超像素对应监督建立点对像素对。最后,基于匹配对,使用EPnP RANSAC算法估计变换矩阵。在 KITTI 数据集上进行的大量实验表明,CoFiI2P 的相对旋转误差 RRE 为 2.25 度,相对平移误差 RTE 为 0.61 米。这些结果表明,与当前最先进的 SOTA 方法相比,RRE 显着提高了 14,RTE 显着提高了 52。 |
| UniBEV: Multi-modal 3D Object Detection with Uniform BEV Encoders for Robustness against Missing Sensor Modalities Authors Shiming Wang, Holger Caesar, Liangliang Nan, Julian F. P. Kooij 多传感器物体检测是自动驾驶领域的一个活跃的研究课题,但是这种检测模型针对传感器输入模态丢失(例如由于传感器突然故障)而丢失的鲁棒性是一个仍在研究中的关键问题。在这项工作中,我们提出了 UniBEV,这是一种端到端多模态 3D 对象检测框架,旨在针对缺失模态的鲁棒性 UniBEV 可以在 LiDAR 加摄像头输入上运行,也可以在仅 LiDAR 或仅摄像头输入上运行,无需重新训练。为了方便其探测器头处理不同的输入组合,UniBEV 的目标是从每种可用模态创建良好对齐的鸟瞰 BEV 特征图。与之前基于 BEV 的多模态检测方法不同,所有传感器模态都遵循统一的方法将特征从本机传感器坐标系重新采样到 BEV 特征。我们还研究了各种融合策略的稳健性。缺少常用的特征串联模式,但也缺少通道平均,以及称为通道归一化权重的加权平均的概括。为了验证其有效性,我们在所有传感器输入组合上将 UniBEV 与 nuScenes 上最先进的 BEVFusion 和 MetaBEV 进行比较。在此设置中,UniBEV 在所有输入组合上平均达到 52.5 mAP,比 BEVFusion 平均 43.5 mAP、MetaBEV 平均 48.7 mAP 的基线显着提高。消融研究表明,通过加权平均进行融合相对于常规串联以及在每种模态的 BEV 编码器之间共享查询具有鲁棒性优势。 |
| Interaction-Aware Decision-Making for Autonomous Vehicles in Forced Merging Scenario Leveraging Social Psychology Factors Authors Xiao Li, Kaiwen Liu, H. Eric Tseng, Anouck Girard, Ilya Kolmanovsky 了解周围交通中车辆的意图对于自动驾驶汽车在高速公路强制并道等复杂交通场景中成功完成驾驶任务至关重要。在本文中,我们考虑了一种行为模型,该模型结合了交互驾驶员的社会行为和个人目标。利用该模型,我们开发了一种基于后退地平线控制的决策策略,该策略使用贝叶斯过滤在线估计其他驾驶员的意图,并结合在不确定意图下对附近车辆行为的预测。 |
| AiAReSeg: Catheter Detection and Segmentation in Interventional Ultrasound using Transformers Authors Alex Ranne, Yordanka Velikova, Nassir Navab, Ferdinando Rodriguez y Baena 迄今为止,血管内手术是使用荧光镜检查的黄金标准进行的,该标准使用电离辐射来可视化导管和脉管系统。长时间的透视暴露对患者和临床医生都是有害的,并且可能导致严重的术后后遗症,例如癌症的发展。与此同时,介入超声的使用因其空间占用小、数据采集快和组织对比度图像更高等众所周知的优点而受到欢迎。然而,超声图像很难解释,也很难定位其中的血管、导管和导丝。这项工作提出了一种解决方案,使用最先进的机器学习变压器架构来检测和分割轴向介入超声图像序列中的导管。该网络架构受到 Attention in Attention 机制、时间跟踪网络的启发,并引入了一种新颖的 3D 分割头,可以跨时间执行 3D 反卷积。为了促进这种深度学习网络的训练,我们引入了一种新的数据合成管道,该管道使用基于物理的导管插入模拟,以及卷积射线投射超声模拟器来生成血管内干预的合成超声图像。所提出的方法在保留验证数据集上进行了验证,从而证明了对超声噪声和大范围扫描角度的鲁棒性。它还对从硅基主动脉模型收集的数据进行了测试,从而证明了其从模拟转化为真实的潜力。 |
| Continuous-time control synthesis under nested signal temporal logic specifications Authors Pian Yu, Xiao Tan, Dimos V. Dimarogonas 信号时序逻辑 STL 在机器人领域广受欢迎,用于表达可能涉及时序要求或截止日期的复杂规范。虽然文献中已经研究了不带嵌套时间运算符的 STL 规范的控制综合,但嵌套时间运算符的情况更具挑战性,需要新的理论进展。在这项工作中,我们提出了一种嵌套 STL 规范下的非线性系统的高效连续时间控制综合框架。该框架基于信号时序逻辑树 sTLT 和控制屏障函数 CBF 的概念。特别是,我们详细介绍了从给定的 STL 公式和连续时间动力系统构建 sTLT、sTLT 语义(即满足条件 )以及 sTLT 和 STL 之间的等价或近似关系。利用 sTLT 的满足条件本质上是在特定时间间隔内将状态保持在特定集合内这一事实,它为 CBF 设计提供了明确的指导。最终的控制器是通过利用基于在线CBF的程序加上事件触发方案来在线更新每个CBF的激活时间间隔而获得的,通过该方案可以通过构建来确定系统行为的正确性。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com