基于Web安全的Python编程(1)
目录
一、http协议基础知识介绍
1、http协议分类
2、请求方法
3、什么是URL
4、请求头
5、响应状态码
二、常用Python库、函数、操作
三、http常用请求方法
1、不带参请求
2、带参数请求(get和post存在细微区别)
四、http响应属性获取
1、获取状态码
2、获取响应文本
3、获取响应头和请求头
5、修改请求头
一、http协议基础知识介绍
1、http协议分类
http 1.0 一次一个连接;http 1.1 多次可以一个连接(都是明文传输,不安全,默认都在80端口)
https (加密传输,更安全,默认在443端口)
2、请求方法
http 1.0:get,post,head
http 1.1:支持文件上传与删除等更多的方法(put,delete,trace,patch)
3、什么是URL
url:协议://主机名.域名/文件夹/文件?参数=值
比如:https://www.baidu.com/xxx/xx?id=1
4、请求头
user-agent:浏览器版本信息
accept-encoding:浏览器接受的编码
referer:当前网页从哪里跳转过来的
cookie:cookie信息
location:跳转到哪里
set-cookie:设置cookie信息(响应头)
www-Authenticate:用于身份验证(http basic等)
5、响应状态码
1xx:信息提示
2xx:成功
3xx:重定向
4xx:客户端错误
5xx:服务端错误
二、常用Python库、函数、操作
1、必须装的一个库:requests
使用前需要先导入该库:import requests
2、常用函数
str():将结果转为字符串
strip():去除空行
print():输出
3、常用操作
选中 ctrl+/:多行注释
使用+:连接字符串
三、http常用请求方法
1、不带参请求
这个比较简单,直接调用get或者post函数传入url即可
用法:
requests.get(url)
requests.post(url)定义一个变量r,用来接收我们的请求
使用 r.url 可以获取请求的url(这个我们后面会细讲)
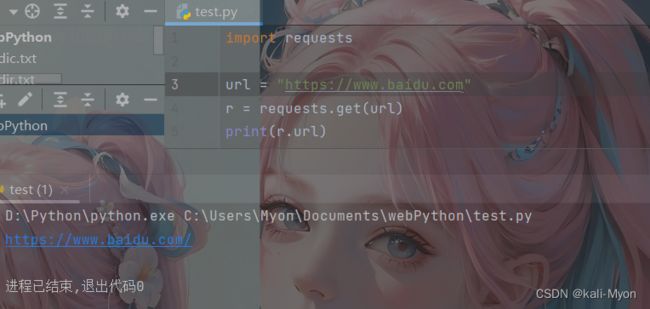
以get为例,测试代码:
import requests
url = "https://www.baidu.com"
r = requests.get(url)
print(r.url)运行结果:
2、带参数请求(get和post存在细微区别)
用法:
requests.get(url,params={"key1":"value1","key2":"value2",...}) #get方式请求
requests.get(url,data={"key1":"value1","key2":"value2",...}) #post方式请求这里要注意下:除了传入url,还需要传入params或者data,传入的参数名和值使用大括号包裹;
参数名与值之间使用冒号,每组参数间使用逗号分割;
参数名和值都需要用单引号或者双引号引起来。(Python中单引号和双引号效果相同)
为了方便,我们一般会定义一个payload,然后再将这个payload传给params
这里找了个网站给大家演示一下:

抓包之后发现是post请求
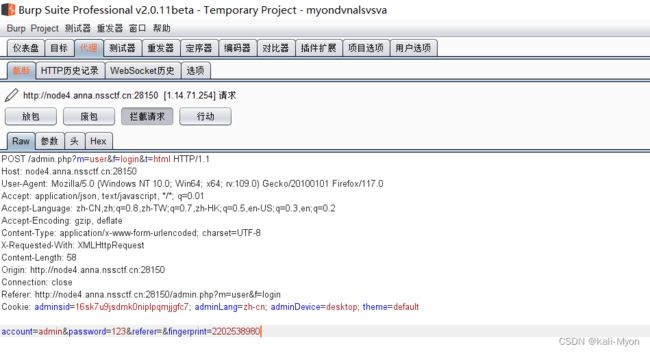
测试代码:
import requests
url = "http://node4.anna.nssctf.cn:28150/admin.php?m=user&f=login"
payload = {"account":"admin","password":"900af8acf068e543e2f3f406d5407043"}
r = requests.get(url,data=payload)
print(r.url)
print(r.status_code)
print(r.text)其中的密码传入后会进行编码,这里直接传入编码后的内容
三个print函数,分别输出请求的url,响应状态码,网页源代码(在后面会细讲)
运行结果:
四、http响应属性获取
1、获取状态码
用法:
r.status_code测试代码:
import requests
url1 = "https://www.baidu.com"
r1 = requests.get(url1)
print(r1.status_code)
url2 = "https://baidu.com/vavgaeg"
r2 = requests.get(url2)
print(r2.status_code)运行结果:

访问存在的页面,返回状态吗:200
访问不存在的页面,返回状态码:404
2、获取响应文本
用法:
r.content #返回二进制数据
r.text #返回源代码测试代码:
import requests
url = "https://www.baidu.com"
r = requests.get(url)
print(r.content)
print("*"*60) #用于分割输出结果
print(r.text)运行结果:
可以看到上半部分是网页的二进制数据,下半部分是网页的源代码
3、获取响应头和请求头
用法:
r.headers #获取响应头
r.request.headers #获取请求头测试代码:
import requests
url = "https://www.baidu.com"
r = requests.get(url)
print(r.headers) #获取响应头
print("*"*160)
print(r.request.headers) #获取请求头运行结果:
可以看到上半部分是响应头,下半部分是请求头
4、获取请求url和cookie
用法:
r.url #获取请求url
r.cookies #获取cookie测试代码:
import requests
url = "https://www.baidu.com"
r = requests.get(url)
print(r.url)
print("*"*100)
print(r.cookies)运行结果:
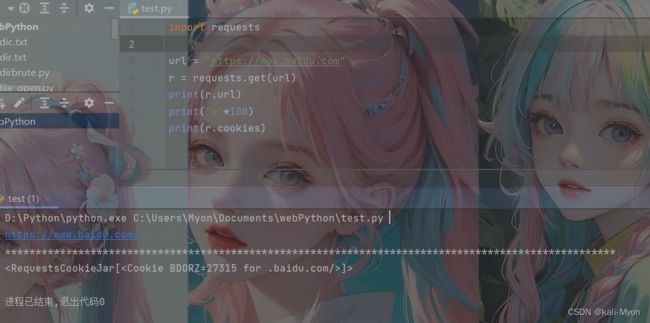
可以看到上半部分是我们请求的url,下半部分是cookie的相关信息
5、修改请求头
用法:
headers={"User-Agent":"XXX"} #XXX为我们想要设置的内容
测试代码:
import requests
url = "https://www.baidu.com"
r=requests.get(url)
print(r.request.headers)
headers={"User-Agent":"kali_Myon"}
r=requests.get(url,headers=headers)
print(r.request.headers)运行结果:
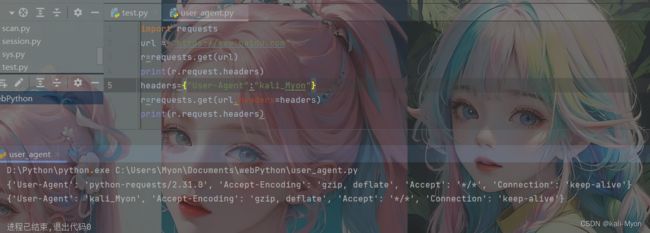
这里分别输出了修改前和修改后的请求头
后续会继续更新Python在Web安全领域的编程,以及关于常见web扫描工具的脚本编写
创作不易,喜欢的可以点赞关注支持一下,我是Myon,我们下期再见!