平安证券Kubernetes落地实践

在此文中,主要讲述平安证券在进行Kubernetes的落地实践中,涉及到的几点小小的经验分享:
镜像制作过程中让JAVA应用感知容器资源;
制作支持GPU的AI项目镜像;
使用Operator部署有状态应用;
Kubernetes应用指标的收集和监控。
一、Java应用中的容器配置感知

Kubernetes部署中,我们一般会定义一个容器使用CPU,内存资源的上下限。如下一个yaml文件片断:

这表示tomcat-demo:v8.55这个容器运行在Kubernetes集群中时,最低能拥有0.5核CPU,512M内存,最高不超过2核CPU,2G内存。
假想当我们把这个yaml资源声明应用到Kubernetes集群时,Kubernetes将它调度一个拥有64核CPU,128G内存的宿主机节点上。Docker容器本质是是宿主机上的一个进程,它与宿主机共享一个/proc目录,也就是说我们在容器内看到的/proc/meminfo,/proc/cpuinfo与直接在宿主机上看到的一致。也即,此容器认为自己的系统资源同样是64核CPU,128G内存。
此处,就出现了运行的容器感知的资源,与Kubernetes分配给它的资源的偏差。在早期的Java版本(JDK 8u131之前)中,这种偏差可能会导致Java应用不断的重启。
那么,为什么Pod会不断重启呢?
以刚才这个配置为例,Java应用以为这自身拥有128G内存,默认情况下,JVM的Max Heap Size是系统内存的1/4,也就是32G作为最大JVM堆内存。但是,当应用运行的总内存,超过Kubernetes的声明限制的2G时,应用就会触发Kubernetes集群定义的资源超配额限制,自动重启此应用POD。于是,我们看到的现象,就是这个应用有越来越多的restart。
如果用户运行的JDK8版本低于131,解决这个问题的办法,是需要在容器启动JAVA程序时,自行定义好与资源配额一致的-Xmx等参数。后来,随着JDK版本的升级,容器感知的功能就内置于Java应用中了,如果JDK8的版本高于191,我们就可以使用MaxRAMPercentage这种更智能化的参数来解决这个问题了。
下图是我综合网上的文档,制作的容器内的JVM参数进化史。

二、AI项目镜像对GPU的支持
随着现在AI人工智能的高速发布,深度学习,神经网络的热门,公司越来越多的项目,开始使用PyTorch、TensorFlow作为项目开发的支持库。
众所周知,深度学习库,在CPU和GPU上运行效率有巨大差异。为了更快的运行速度,我们也从去年开始了这部份的实践。本节,主要讲述的就是将一个GPU机器加入Kubernetes集群的过程。
因为我公司用的是Nvidia的Tesla系列GPU,所以我们的方案,主要是参照Nvidia的构架思路。在Docker中调用Nvidia的GPU,可以通过nvidia-docker调用,nvidia-docker是一个可以使用GPU的Docker。

这里且放过Nvidia驱动,cuda-toolkit这些不表,整个安装过程分两大步:
替换docker-runtime
1、安装nvidia-docker(CentOS)
yum install nvidia-docker2-2.0.3-3.docker18.09.6.ce.noarch.rpm
2、修改/etc/docker/daemon.json

如果这时我们使用docker info命令,会发现docker runtime已替换成了Nvidia。
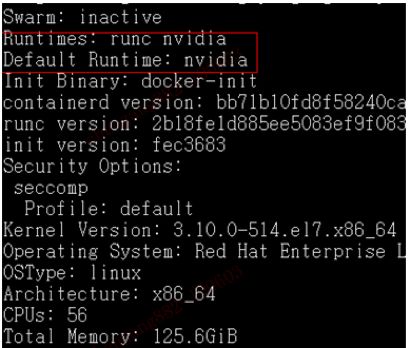
将此节点加入Kubernetes集群之后,在集群内安装Nvidia Device Plugin
1、Nvidia Device Plugin项目地址:https://github.com/NVIDIA/k8s-device-plugin
Nvidia Device Plugin的工作机制如下图(图片来自于网络):

2、在Kubernetes集群中安装好GPU之后,我们就可以在Yaml文件中,为应用分配GPU资源了。其yaml文件中的resource定义,和Kubernetes调度机制如下图(图片来自于网络):

3、经过我实测试,同样的代码,使用GPU和CPU运算的差距,起码在10位以上。


K8s已经成为一线大厂分布式平台的标配技术。你是不是还在惆怅怎么掌握它?来这里,大型互联网公司一线工程师亲授,不来虚的,直接上手实战,3天时间带你搭建K8s平台,快速学会K8s,点击下方图片可了解培训详情。

三、使用Operator部署ECK(Elastic Cloud Kubernetes)
在Kubernetes中,对于有状态的应用,有原生的StatefulSet部署支持。StatefulSet原理和ReplicaSet 和 Deployment 资源一样,StatefulSet也使用控制器的方式实现,它主要由StatefulSetController、StatefulSetControl和StatefulPodControl 三个组件协作来完成StatefulSet 的管理,StatefulSetController会同时从PodInformer和ReplicaSetInformer中接受增删改事件并将事件推送到队列中。
但StatefulSet无法解决有状态应用的所有问题,它只能做到创建集群、删除集群、扩缩容等基础操作,但比如备份、恢复等数据库常用操作,则无法实现。
基于此,CoreOS团队提出了Kubernetes Operator概念。Operator是一个自动化的软件管理程序,负责处理部署在Kubernetes有状态应用的安装和生命周期管理。它包含一个Controller和CRD(Custom Resource Definition),CRD扩展了Kubernetes API,可以将一些运维能力,作为代码封装于镜像中。其实现如下图所示(图片来自于网络):

我们公司遇到一个项目,需要使用Kubernetes集群内的Elasticsearch服务。于是,我们就使用operator部署ECK,后端使用NFS作为数据存储。这里就简要介绍一下其实现思路。
ECK官网:https://www.elastic.co/guide/en/cloud-on-k8s/,本节不讲关于ECK的一些部署,因为官网都提供了详细的说明。这里主要讲解一下,如果通过NFS 动态PVC为ECK提供网络存储,这部分内容,我在部署ECK时,并没有在网络上搜索到完全合用的文档。所以在这里作为落地实践的内容,分享给大家。
使用NFS提供动态PVC功能
GitHub项目地址:https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client
yaml文件地址:https://github.com/kubernetes-incubator/external-storage/blob/master/nfs-client/deploy/deployment.yaml
这份配置文件的注意要点,是要将StorageClass定义中的Provisioner与Deployment中的PROVISIONER_NAME这个环境变量一致。
NFS Provisioner是一个自动配置卷程序,它使用现有的和已配置的NFS服务器来支持通过持久卷声明动态配置Kubernetes持久卷。
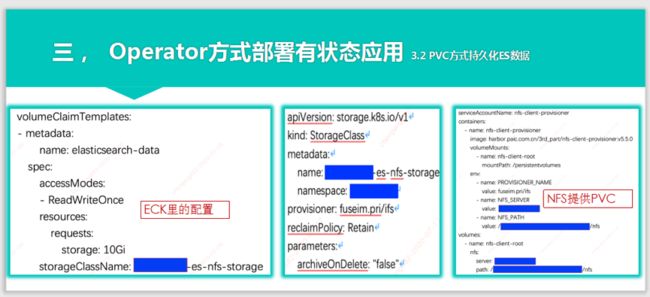
Kubernetes集群有PVC存储之后,就可以将这个StorageClass就用于ECK要求的存储中了

使用kube-prometheus收集JVM和Node.js的Metric
在Kubernetes集群里,一般是使用Prometheus作指标的收集,监控和报警。我们在早期,也是使用原生的Prometheus,配合一些Exporter来作Metric的收集。在作过几次集群的迁移和新建之后,发现每一次的部署,都很繁琐,叫苦不迭。
到后来,我们引入了Prometheus Operator项目,再过渡到Kube-prometheus项目,部署监控的流程,才变得规范和轻松起来。
kube-promehteus项目地址:https://github.com/coreos/kube-prometheus
由于时间关系,这里也不展开这个项目的具体细节,只和大家分享一下我们是如何使用Kube-prometheus的ServiceMonitor来监控Node.js应用的。
ServiceMonitor就是一种由Prometheus Operator定义的CRD,Operator会通过监听ServiceMonitor的变化来动态生成Prometheus的配置文件中的Scrape targets,并让这些配置实时生效。Operator通过将生成的Job更新到上面的prometheus-k8s这个Secret的Data的prometheus.yaml字段里,然后Prometheus这个Pod里的Sidecar容器prometheus-config-reloader。当检测到挂载路径的文件发生改变后,自动去执行HTTP Post请求到/api/-reload-路径去reload配置。该自定义资源(CRD)通过labels选取对应的Service,并让Prometheus Server通过选取的Service拉取对应的监控信息(Metric)。

在上图中,我们先定义好ServiceMonitor的Endpoint和Selector。然后,在已有的应用Service中,labels和selector对应,port的name和endpoint的port对应,如果此Node.js应用提供了path作为metric的话,Prometheus就能将这些指标定时入库了,极其方便!
JVM的监控也可以类似的方式实现。


当一切部署妥当之后,该应用的Metric就会自动的纳入Promemetheus体系中了。

Kubernetes入门与进阶实战培训
Kubernetes入门与进阶实战培训将于2020年9月18日在北京开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:Docker基础、容器技术、Docker镜像、数据共享与持久化、Docker实践、Kubernetes基础、Pod基础与进阶、常用对象操作、服务发现、Helm、Kubernetes核心组件原理分析、Kubernetes服务质量保证、调度详解与应用场景、网络、基于Kubernetes的CI/CD、基于Kubernetes的配置管理等。点击下方图片或者阅读原文链接查看详情。
