一周技术思考(第19期)-没有度量就没有管理
大家好,这里记录,我每周读到的技术书籍、专栏、文章以及遇到的工作上的技术经历的思考,不见得都对,但开始思考总是好的。
你认为一个服务的度量指标有哪些
人们一般还是比较喜欢做度量的,而且度量在我们日常工作中司空见惯,比如你的上下班时间,工作时长,一个部门有多少个应用数量,每周上线多少个需求,这些需求的交付周期又是怎样的,这些都是在做度量。
著名管理大师德鲁克有句名言,“没有度量就没有管理”。
我们跑在线上生产环境中的每一个服务,也需要管理,我们需要管理它们的运行情况,需要知道一个服务进程的CPU资源占用情况,也需要知道线程的数量,还需要知道一段时间内有无响应错误,错误码最多的场景数量又是多少,等等。
你看,这些都是管理,当然德鲁克说的是偏重于人和行政上的管理,但是道理都是想通的,没有度量就没有管理,因此我们的服务也需要度量。
那我们应该从哪些层面或者角度去来度量我们的服务呢。
首先,要让我们看一下我们熟常说的一个服务都是有哪些层来组成的,人们爱度量,其实人们也爱分层,分层的渊源,一般可以追溯到计算机操作系统那里,想想那个四层或者七层网络分层。
因为分层的好处在于,一是,可以分而治之,分离关注点,大家各自处理好自己层内的事情。二是,越往上层,所需要关注的内容越收敛,想想有了底层的网络通讯层,是不是我们在开发http请求服务的时候就只需要关注业务层面就可以了。
同样,人们对一个服务进行分层,也是这两个目的,现在一个服务常用的四层模型,如下图所示这样。
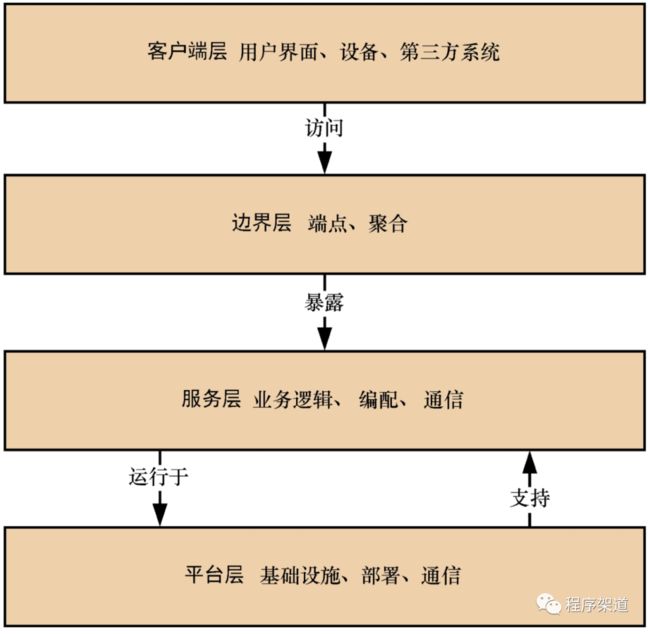
图自《微服务实战》3.4
这张四层服务模型图,最下面的平台层,我们也可以理解成是基础设施层,这些是任何服务运行的基础;服务层和边界层,我们也可以理解成是应用程序层,也就是跑在基础设施层上的具体服务;最上层的客户端层,我们也可以理解成是业务层,这里的”业务“特指距离用户最近的操作。
这样分下来,从上到下我们就有业务层、应用程序层和基础设施层。
好了,我们再回到这一块的主题上来,继续谈服务度量指标。
那么,其实在我们对一个服务分好层以后,再来看我们需要什么样的指标,就可以进入每一层来看了,我列了一张下面的图,从图中可以一目了然的来看到每一层都应该关注哪些指标。

对于我们技术研发人员来讲,这些跟技术相关的指标,我们都已经非常熟悉了,比如CPU使用率,系统负载,网络延时及丢包等等。
这里,我挑选基础设施层的两个指标来简单介绍,CPU的使用率和系统负载,因为,有些时候,有的同学会对这两个指标产生混淆,比如CPU使用率高的时候系统负载一定高吗?
看CPU使用率,我们一般用top命令:

这个记录里面的第3行就是我们想要的CPU使用百分比,当然此时这台机器”比较清闲“,我们在计算CPU使用率的时候,会将用户(us)、系统(sy)、改变过优先级的进程(ni)、硬件中断(hi)和软件中断(si),把这些数据进行求和,大家都是0所以得出结论说这台机器比较清闲,
看负载的命令,我们常常使用uptime命令:

从记录上来看,具有一个CPU核心的系统上显示负载为1,也就是刚好有一个进程在等待,这是正常的情况,一般来讲,每个核心上的负载为1,是完全可以接受的。
注:上述命令的部分内容参考了《监控运维实践》第8章节内容。
所谓系统负载,就是等待CPU的任务数,或者精确点说就是进程数。所以从这个定义上来讲,上面的问题,”cpu使用率高的时候系统负载一定高吗“,很显然它们之间并没有直接的因果关系,比如你写了一个先天计算敏感型的程序,就一个线程在跑,cpu使用率也会很高,但是负载就不会高啊。
如果这个时候有一位同事跑来告诉我,某台服务器的CPU使用率很高,问我怎么办。
我就会告诉他:“这台服务器是不是还在做它该做的事?”
然后他告诉我:“是的”
“那就没什么问题,对不对?”
对于操作系统相关的告警指标,我们要能够做到不告则以,一告即触,怎么个意思呢,就是对于告警来说,这些操作系统相关的指标警示一旦通知到你,就要立刻给予高度关注,具体做法就是设置好科学的报警阈值。说的再通俗点讲,就是不能让其因为阈值设置不合理而导致频繁的报警,以免产生报警疲惫。
狼来了的故事你应该听过。
以上我们说了技术上的两个指标,也是作为技术人员的我们,非常熟悉的指标。另外,大家会发现,这张表里面最上层是业务层面的指标,技术人员对于这些业务指标往往比较陌生或者关心程度及不上那些技术指标。
那,我们需要了解吗,技术人员了解业务上的指标有用吗,当然有用。
你做了一个服务,上了线,这个服务所承载的业务功能被用户使用的情况,你是要了解的,而且,对于一个技术人员的未来发展,如果是要能够时刻关注线上用户情况,那是非常关键的,这个话题如果说下去会有点偏离我们今天的主题,暂且不表了。
业务层的指标比较多,不同的业务所需要关注的KPI(Key Performance Indicator,关键业务指标)也不同,你比如说,如果是京东这样的电商系统,就侧重关注订单数、销售额等;如果是一个腾讯视频这样的网站系统就要看DAU(Daily Action User,每日活跃用户)、新增视频数等。
这里参考《微服务之道度量驱动开发》这本讲度量的书籍内容,给大家一些关注业务指标时候的思考方法建议,这本书按照我们经常用的4W1H思考方法,给了我们些重点关注项:
1、Who-对用户进行多维度和各类的细分,哪一类用户对哪些功能有所好恶?
2、What-哪些功能点用量大,比较受欢迎,反之如何?
3、Where-用户的地理分布;
4、When-使用服务的波峰和波谷,旺季和淡季,业务的趋势是什么?
5、How-用户的使用行为分析,有哪些关键的影响因素;
总之,在度量一个服务的时候,作为一名技术人员一定要记得时刻想着关注业务上的运行指标。
另外,你要学着去理解的关键业务指标也能够像你作为一名技术人员所熟悉的应用程序和基础设施的性能指标那样,告诉你应用程序运行如何,关键业务指标也会告诉你业务的表现如何。如果你学着更进一步,不是经常老板都这样说么,你要站在他的角度去思考问题。
那就是下面这样的角度:
客户能不能正常使用应用程序或者服务?
公司是在盈利么?
公司是在壮大、萎缩还是停滞不前?
利润有多少?是在提高、降低还是维持现状?
客户满意吗?
当然,有些数据有时候并不是你我能看到的,我只是举这些方向性的例子,也就是我们要努力的在业务上朝着这些方向去思考,去认知。
以上我们讲了如何做服务或者一个系统的度量,其实有时候度量跟监控也是相邻的两个事物,那接下来,让我们看看跟运维监控相关的一些内容。
关于SRE的一些书籍
本周,我称它为618周,对于京东的每个研发人员都是较为重要的一周。
大概是为了应景,也或许是心中总有备战这件事,这周还是逢见空闲时间翻看了三本关于SRE的书籍,分别是《SRE Google运维解密》、《SRE生存指南》、《监控运维实践 原则与策略》,这些是目前比较好的SRE书籍,摘抄了一些“金句”给大家看一看。
1、”故障是常态,正常才是异常”,面对故障,我们更多的应该是从中进行学习和改进,把故障作为提升系统性能的切入点,而不是故障之后的相互指责和推诿扯皮。
2、测试表明缺陷的存在,而不是不存在。
3、软件世界的测试不同于普通的科学测试的地方在于,你不是试图弄清楚某些东西是如何工作的,而是试图验证这些东西是否在按照你希望的方式工作。
4、事故响应建立在使用监控构建的数据之上,并借助反馈循环,来帮助我们加强对服务的监控。
5、目标是将50%的时间用于编写代码,30%的时间用于与人打交道,20%的时间用于应对紧急情况。
6、在软件的生命周期里,20%的时间用于创建,80%的时间用于维护。
--《SRE生存指南》
《SRE生存指南》和《SRE Google运维解密》这两本书呢,其实都跟Google有关系,前一本是一名Google的SRE工程师做撰写的,另外这两本书,它们俩更像是姊妹篇,前一本相对后一本更像是第二本的入门读物,第二本更厚重些,大家可以结合着来读。
《SRE生存指南》这本书让人值得称赞的是,整体写作思路非常清晰,全书就是围绕下面这个叫做Mikey金字塔的模型展开来讲的。
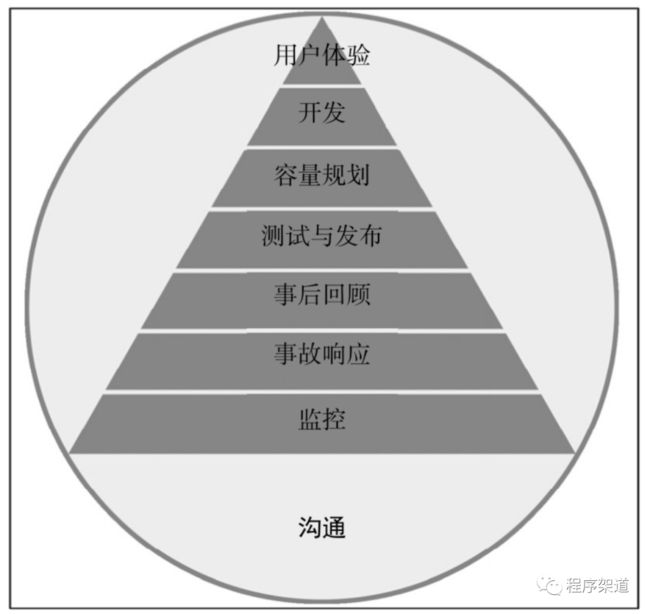
Mikey金字塔 图自《SRE生存指南》
这个七层金字塔围绕着沟通来构建,每一层都是建立在前一层的基础之上。它被沟通所包围,因为每一层都需要沟通才能成功。
一共七层,书中也是按照这七层,从底往上依次逐个介绍,从监控开始,到用户体验结束,因为是讲关于SRE的,肯定离不开监控,因为所有的过程都是为了用户利益,到最后肯定还是离不开用户体验。
关于SRE的书籍目前市面上比较好的,我个人接触到的大概有以上三本,那么其实还有一本跟SRE没有直接名字相关,但内容相近的书籍,就是这本《阿里云运维架构实践秘籍》,大家有时间也可以将它们放在一起翻阅。
本周最后,我们一起聊聊架构设设计的关系。
架构(Architecture)和设计(Design)到底有什么区别
我这周在写一个TRD模板框架,很久以来在敏捷的指挥下,一些优良的传统习惯给“敏捷”掉了,你会发现当codereview的时候,当评估设计方案的时候,一上来就是干代码,没有代入感的情况下,很要花费些精力才能探入到上下文中。
什么是TRD呢,刚开始我想定义D为Design,这样可以紧贴设计的味道,后来参照BRD和PRD还是将其定义为Document,那么TRD的全称便是Technology Requirement Document,翻译过来也就是技术要求文档。再直白点讲就是给技术研发人员提要求的文档,不过今天我倒不打算继续聊这份TRD的作用,而是我在编写TRD模板框架的这个过程中一直思考一个问题,架构和设计是不是一回事。
当你说到架构的时候,你首先会感觉一种宏大、高大,反正就是战略高、思维也高、着地点就是很大,比如六边形架构,C4架构、DDD架构、微服务架构,都是这样“高层”感觉的。
当你说到设计的时候呢,你首先会感觉细微、粒度小、比如一个方法怎么设计、大一点可能也就是到类怎么设计,或者是一个表怎么设计的,都这样“底层”感觉的。
但是,从你作为一名架构师那天起,仔细想想你工作的内容,显然又不是这样的,按照上面那样区分根本不成立。
来了一个需求,作为一名架构师你要描述这个需求所在的代码系统位置,还要描述系统之间的通信关系,如果这个需求在工程内部涉及到多个类,你还要有类图,类图里面有属性和方法,你看,这样其实已经有“高层”和“底层”了,其实并没有一条清晰的分界线。
架构与设计,二者并没有任何区别。
关于这两者的定义,在《架构整洁之道》这本书里面,作者为我们举了一个例子:
以给我设计新房子的建筑设计师要做的事情为例。新房子当然是存在着既定架构的,但这个架构具体包含哪些内容呢?首先,它应该包括访问的形状、外观设计、垂直高度、房间的布局,等等。
这是“高层”的,对吧。
但是,如果查看建筑设计师使用的图纸,会发现其中也充斥着大量的设计细节。譬如,我们可以看到每个插座、开关以及每个电灯具体的安装位置,同时也可以看到某个开关与所控制的电灯的具体连接信息。
你看,这些又是“底层”的。
"底层设计细节和高层架构信息是不可分割的。它们组合在一起,共同定义了整个软件系统,缺一不可。所谓的底层和高层本身就是一系列决策组成的连续体,并没有清晰的分界线。"
另外,再说些感受。
有时候我们工作上经常讲架构,说要对一个系统做好架构,大部分情况下,潜台词里面都没有包括代码,这是不对的,尽管你没有通过表达让人知道你没有关注代码,但是,潜意识里面只有你谈到到架构的时候没有想到要包括代码的设计,也是不对的。
你可以先宏观架构在微观架构,有个顺序是对的,但只要你够不到代码,就不对,因为我们已经讲了架构和设计其实就是一回事,没有区别,就要有”高层“的东西,又要有“底层”的东西。
无论高层或底层,都是在干一件事:软件设计。
所有软件设计动作的终极目标都是一样的:
用最小的人力成本来满足构建和维护系统的需求。
恭喜你,又完成一次思考。
忆往期:
架构六大思维养成记
你好,我是前台,再给你引荐下XY台
工作十几年,开了上千个会,该说说了
一个年老代程序员午后谈谈架构和架构师
如何让软件姓“软”
一文一点 | 给你一份实现业务复用的指南
这个假期我通过【得到】得到了什么
一文一点 | 什么才是复用的最高等级
一文一点 | 系统从高可用到高不可用都经历了什么
4000字8分钟带你理解Serverless架构
考虑系统扩展性时仅仅理解AKF立方体是不够的
全面详解互联网企业开放API的 “守护神”
从HTTP/1.1到HTTP/2,让WEB性能更上一层楼
我的第6个京东618
上班十年后我发现可以这样边工作边学习
