MySQL(8) 优化、MySQL8、常用命令
一、MySQL优化
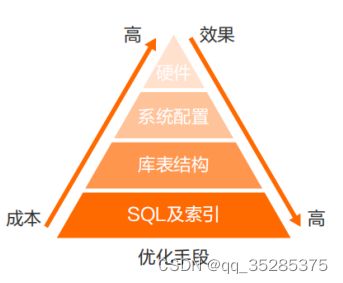
从上图可以看出SQL及索引的优化效果是最好的,而且成本最低,所以工作中我们要在这块花更多时间。
服务端参数配置;
max_connections=3000
连接的创建和销毁都需要系统资源,比如内存、文件句柄,业务说的支持多少并发,指的是每秒请求数,也就是QPS。
一个连接最少占用内存是256K,最大是64M,如果一个连接的请求数据超过64MB(比如排序),就会申请临时空间,放到硬盘上。
如果3000个用户同时连上mysql,最小需要内存3000*256KB=750M,最大需要内存3000*64MB=192G。
如果innodb_buffer_pool_size是40GB,给操作系统分配4G,给连接使用的最大内存不到20G,如果连接过多,使用的内存超过20G,将会产生磁盘SWAP,此时将会影响性能。连接数过高,不一定带来吞吐量的提高,而且可能占用更多的系统资源。
max_user_connections=2980
允许用户连接的最大数量,剩余连接数用作DBA管理。
back_log=300
MySQL能够暂存的连接数量。如果MySQL的连接数达到max_connections时,新的请求将会被存在堆栈中,等待某一连接释放资源,该堆栈数量即back_log,如果等待连接的数量超过back_log,将被拒绝。
wait_timeout=300
指的是app应用通过jdbc连接mysql进行操作完毕后,空闲300秒后断开,默认是28800,单位秒,即8个小时。
interactive_timeout=300
指的是mysql client连接mysql进行操作完毕后,空闲300秒后断开,默认是28800,单位秒,即8个小时。
innodb_thread_concurrency=64
此参数用来设置innodb线程的并发数,默认值为0表示不被限制,若要设置则与服务器的CPU核心数相同或是CPU的核心数的2倍,如果超过配置并发数,则需要排队,这个值不宜太大,不然可能会导致线程之间锁争用严重,影响性能。
innodb_buffer_pool_size=40G
innodb存储引擎buffer pool缓存大小,一般为物理内存的60%-70%。
innodb_lock_wait_timeout=10
行锁锁定时间,默认50s,根据公司业务定,没有标准值。
innodb_flush_log_at_trx_commit=1
redo log 保存策略
sync_binlog=1
binlog 保存策略
sort_buffer_size=4M
每个需要排序的线程分配该大小的一个缓冲区。增加该值可以加速ORDER BY 或 GROUP BY操作。
sort_buffer_size是一个connection级的参数,在每个connection(session)第一次需要使用这个buffer的时候,一次性分配设置的内存。
sort_buffer_size:并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统的内存资源。例如:500个连接将会消耗500*sort_buffer_size(4M)=2G。
join_buffer_size=4M
用于表关联缓存的大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
二、8.0新特性
1、新增降序索引
2、group by 不在隐式排序
3、增加隐藏索引
4、新增函数索引
5、innodb存储引擎select for update跳过锁等待
对于select ... for share(8.0新增加查询共享锁的语法)或 select ... for update, 在语句后面添加NOWAIT、SKIP LOCKED语法可以跳过锁等待,或者跳过锁定。
在5.7及之前的版本,select...for update,如果获取不到锁,会一直等待,直到innodb_lock_wait_timeout超时。
在8.0版本,通过添加nowait,skip locked语法,能够立即返回。如果查询的行已经加锁,那么nowait会立即报错返回,而skip locked也会立即返回,只是返回的结果中不包含被锁定的行
6、新增innodb_dedicated_server自适应参数
能够让InnoDB根据服务器上检测到的内存大小自动配置innodb_buffer_pool_size,innodb_log_file_size等参数,会尽可能多的占用系统可占用资源提升性能。解决非专业人员安装数据库后默认初始化数据库参数默认值偏低的问题,前提是服务器是专用来给MySQL数据库的,如果还有其他软件或者资源或者多实例MySQL使用,不建议开启该参数,不然会影响其它程序
7、undo文件不在使用系统表空间,就是不存在ibdata1文件中,有单独的undo_001文件中
8、死锁检测控制,可以不开启死锁检测,默认还是开启
9、binlog日志过期时间精确到秒
10、新增窗口函数,不用group by就能使用聚合函数
11、默认字符集由latin1变为utf8mb4
在8.0版本之前,默认字符集为latin1,utf8指向的是utf8mb3,8.0版本默认字符集为utf8mb4,utf8默认指向的也是utf8mb4。
12、系统表全部换成innodb表
13、元数据存储变动
MySQL 8.0删除了之前版本的元数据文件,例如表结构.frm等文件,全部集中放入mysql.ibd文件里
14、解决5.7自增主键的bug
5.7自增主键不持久化,每次都查询表中最大的id+1去生成,这样如果删除最大id,重启数据库,再插入记录,id会是之前有过的,还有一种情况如果修改自增主键,mysql也是感知不到的,有可能会主键冲突
5.8解决这个问题,主键值持久在redolog中,修改主键mysql也能感知到,解决了这个bug
15、DDL原子化
比如之前drop table t1,t2 执行不支持事务,也是因为5.8把系系统表都改为innodb的原因,drop可以支持事务
16、参数修改持久化
MySQL 8.0版本支持在线修改全局参数并持久化,通过加上PERSIST关键字,可以将修改的参数持久化到新的配置文件(mysqld-auto.cnf)中,重启MySQL时,可以从该配置文件获取到最新的配置参数。set global 设置的变量参数在mysql重启后会失效
三、基础SQL
(1)用户
新建用户
create user name identified by 'password';
更改密码
set password for name=password('mima');
查看用户权限
show grants for name;
给name用户test数据库的所有权限
grant select on db_name.* to name;
去除权限
revoke select on db_name.* to name;
登录到MySQL服务器
mysql -u root -p
连接到指定的MySQL服务器
mysql -u root -p datebase_name
登录到远程MySQL服务器
mysql -h remote_mysql_host_ip -u root -p
(2)数据库
查看数据库
show databases;
创建数据库
create datebase db_name;
使用数据库
use db_name;
删除数据库
drop datebase db_name;
(3)表
创建表
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`age` int(11) NOT NULL COMMENT '年龄',
`name` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `age`(`age`) USING BTREE,
INDEX `name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
复制表
create table test2 select * from test;
部分复制
create table test2 select id, name from test;
创建临时表
create temporary table test3(和创建普通表一样)
查看数据库中可用的表
show tables;
查看表结构
describe test;
show columns in test;
增
insert into test (age, name) values(1, '1'),(1,'2');
insert into test(age, name) select age, name from test;
删
delete from test where id =1;
改
update test set age = 1, name= '1' where id =1;
查
select * from test where id = 1;(where 也可以是正则表达式)
修改字段结构
alter table test modify column name varchar(32) NOT NULL COMMENT'名字';
增加字段
alter table test add column remark(512) NULL DEFAULT NULL COMMENT'备注' after name;
删除字段
alter table test drop remark;
创建索引
alter table test add unique uk_age(age);
alter table test add index idx_name(name);
删除索引
alter table test drop index index _name;
删除表
drop table if exists test;
清空表数据
truncate table test;
表重命名
alter table test rename new name;
rename table oldname to newname;
创建视图
create view test1 as select * from test where id = 1;
(4)储存过程
创建储存过程
create procedure pro(
in num int, out total int)
begin
select sum(age) into total from test where id = num;
end;
//in 为传入参数,out为返回参数, into 为保存变量
储存过程的调用
call pro(13, @total);
select @total;
显示当期的储存过程
show procedure status;
删除存储过程
drop procedure pro;
储存过程例子
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zhuge',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter;
call insert_emp();
(5)触发器
支持触发器的语句有 delete insert update
创建触发器
在MySQL中,可以使用CREATE TRIGGER语句来创建触发器。CREATE TRIGGER语句的基本语法如下:
CREATE TRIGGER trigger_name trigger_time trigger_event ON table_name FOR EACH ROW trigger_body;
其中,trigger_name是触发器的名称;trigger_time是触发器的执行时间,可以是BEFORE或AFTER;trigger_event是触发器的事件,可以是INSERT、UPDATE或DELETE;table_name是触发器所在的表名;trigger_body是触发器的SQL语句。
例如,下面的触发器在employee表上创建了一个BEFORE INSERT的触发器,当有新的员工加入时,自动将入职时间设置为当前时间:
CREATE TRIGGER set_join_date BEFORE INSERT ON employee FOR EACH ROW
BEGIN
SET NEW.join_date = NOW();
END;
(6)系统
查询MySQL系统配置
show variables like '%log_error%';