中级Android面试总结之Android篇
本文已独家授权微信公众号:鸿洋(hongyangAndroid)在微信公众号平台原创首发
update time 2021年04月27日19:50:07,文章版本:V 1.4,阅读时间40分钟,建议先收藏后阅读,注意以点学面,面试问法千变万化但是答案就那些。 主要收集在面试过程中普遍问到的基础知识(面试收集 主要来自于bilibili 嵩恒 蚂蚁金服 2345 趣头条 平安等互联网公司)
由于总结的东西很多很乱,所以知识点并没有深入探讨,很多小标题的东西都可以写成一篇单独的总结,这里偷懒直接放在一起汇总了。
中级Android面试总结之网络、Java基础篇 链接
Android
启动
启动模式
- standard 标准模式
- singleTop 栈顶复用模式 (例如:推送点击消息界面)
- singleTask 栈内复用模式 (例如:首页)
- singleInstance 单例模式 (单独位于一个任务栈中,例如:拨打电话界面)
App启动流程
启动流程参考文章
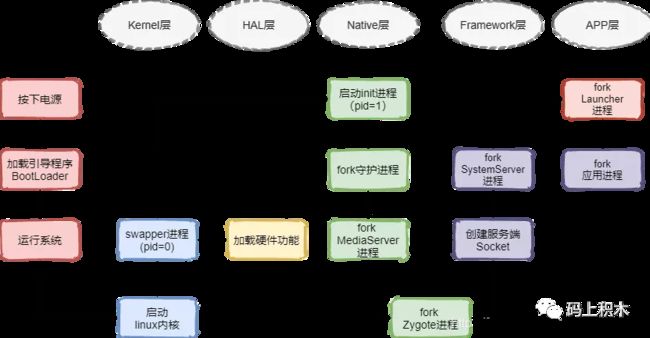
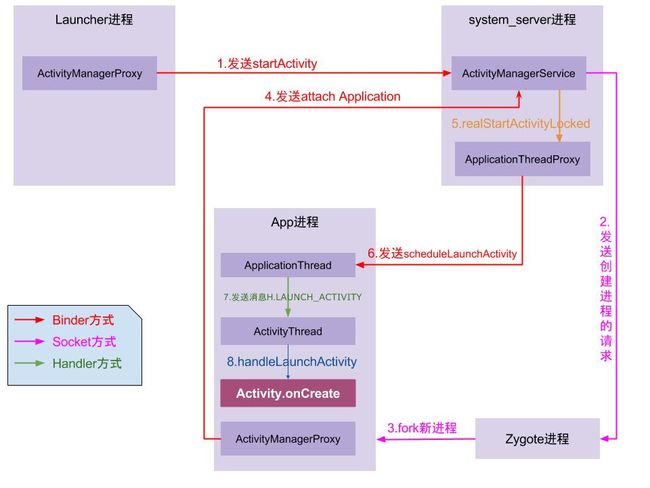 在Android 层 第一步就是 fork Zygote 进程(1. 创建服务端Socket,为后续创建进程通信做准备 2. 加载虚拟机 3.fork了System Server进程,负责启动和管理Java Framework层,包括ActivityManagerService,PackageManagerService,WindowManagerService、binder线程池等 )。
在Android 层 第一步就是 fork Zygote 进程(1. 创建服务端Socket,为后续创建进程通信做准备 2. 加载虚拟机 3.fork了System Server进程,负责启动和管理Java Framework层,包括ActivityManagerService,PackageManagerService,WindowManagerService、binder线程池等 )。
wanandroid 有一个经典的问题 : Activity启动流程中,大部分都是用Binder通讯,为啥跟Zygote通信的时候要用socket呢?
- ServiceManager (初始化binder线程池的地方)不能保证在zygote起来的时候已经初始化好,所以无法使用Binder。
- Binder工作依赖于多线程,但是fork的时候是不允许存在多线程的,多线程情况下进程fork容易造成死锁,所以就不用Binder了。
多线程fork为什么会死锁
-
线程里的doit()先执行.
-
doit执行的时候会给互斥体变量mutex加锁.
-
mutex变量的内容会原样拷贝到fork出来的子进程中(在此之前,mutex变量的内容已经被线程改写成锁定状态).
4.子进程再次调用doit的时候,在锁定互斥体mutex的时候会发现它已经被加锁,所以就一直等待,直到拥有该互斥体的进程释放它(实际上没有人拥有这个mutex锁).
5.线程的doit执行完成之前会把自己的mutex释放,但这是的mutex和子进程里的mutex已经是两份内存.所以即使释放了mutex锁也不会对子进程里的mutex造成什么影响.
Binder
直观的说,Binder是一个类,实现了IBinder接口。
从IPC(进程间通信)角度来说,Binder是Android中一种跨进程通信方式。
还可以理解为一种虚拟的物理设备,它的设备驱动是/dev/binder。
从Android FrameWork角度来说,Binder是ServiceManager连接各种Manager(ActivityManager,WindowManager等等)和响应ManagerService的桥梁。
从Android应用层来说,Binder是客户端和服务端进行通信的媒介。
以AIDL为例子,客户端在请求服务端通信的时候,并不是直接和服务端的某个对象联系,而是用到了服务端的一个代理对象,通过对这个代理对象操作,然后代理类会把方法对应的code、传输的序列化数据、需要返回的序列化数据交给底层,也就是Binder驱动。然后Binder驱动把对应的数据交给服务器端,等结果计算好之后,再由Binder驱动把数据返回给客户端。
如果想要更加详细的资源 -> Binder设计与实现
ServiceManager
ServiceManager其实是为了管理系统服务而设置的一种机制,每个服务注册在ServiceManager中,由ServiceManager统一管理,我们可以通过服务名在ServiceManager中查询对应的服务代理,从而完成调用系统服务的功能。所以ServiceManager有点类似于DNS,可以把服务名称和具体的服务记录在案,供客户端来查找。

ServiceManager本身也运行在一个单独的线程,本身也是一个服务端,客户端其实是先通过跨进程获取到ServiceManager的代理对象,然后通过ServiceManager代理对象再去找到对应的服务。所以每个APP程序都可以通过binder机制在自己的进程空间中创建一个ServiceManager代理对象。
所以通过ServiceManager查找系统服务并调用方法的过程是进行了两次跨进程通信。
序列化
- Serializable : Java 序列化方式,适用于存储和网络传输,serialVersionUID 用于确定反序列化和类版本是否一致,不一致时反序列化回失败
- Parcelable :Android 序列化方式,适用于组件通信数据传递,性能高,
java中的序列化方式Serializable效率比较低,主要有以下原因:
- Serializable在序列化过程中会创建大量的临时变量,这样就会造成大量的GC。
- Serializable使用了大量反射,而反射操作耗时。
- Serializable使用了大量的IO操作,也影响了耗时。
所以Android就像重新设计了IPC方式Binder一样,重新设计了一种序列化方式,结合Binder的方式,对上述三点进行了优化,一定程度上提高了序列化和反序列化的效率。
进程
IPC 进程通讯方式
- Intent 、Bundle : 要求传递数据能被序列化,实现 Parcelable、Serializable ,适用于四大组件通信。
- 文件共享 :适用于交换简单的数据实时性不高的场景。
- AIDL:AIDL 接口实质上是系统提供给我们可以方便实现 BInder 的工具
- Messenger:基于 AIDL 实现,服务端串行处理,主要用于传递消息,适用于低并发一对多通信
- ContentProvider:基于 Binder 实现,适用于一对多进程间数据共享(通讯录 短信 等)
- Socket:TCP、UDP,适用于网络数据交换
进程保活
进程被杀原因:1.切到后台内存不足时被杀;2.切到后台厂商省电机制杀死;3.用户主动清理
保活方式:
- Activity 提权:挂一个 1像素 Activity 将进程优先级提高到前台进程
- Service 提权:启动一个前台服务(API>18会有正在运行通知栏)
- 广播拉活 (监听 开机 等系统广播)
- Service 拉活
- JobScheduler 定时任务拉活 (android 高版本不行)
- 双进程拉活
- 监听其他大厂 广播 (tx baidu 全家桶互相拉)
Hook
Hook android 使用
Hook 的选择点:静态变量和单例,因为一旦创建对象,它们不容易变化,非常容易定位。
Hook 过程:
寻找 Hook 点,原则是静态变量或者单例对象,尽量 Hook public 的对象和方法。
选择合适的代理方式,如果是接口可以用动态代理。
偷梁换柱——用代理对象替换原始对象。
多数插件化 也使用的 Hook技术
内存泄漏
- 构造单例的时候尽量别用Activity的引用;
- 静态引用时注意应用对象的置空或者少用静态引用;
- 使用静态内部类+软引用代替非静态内部类;
- 及时取消广播或者观察者注册;耗时任务、属性动画在Activity销毁时记得cancel;
- 文件流、Cursor等资源及时关闭;
- Activity销毁时WebView的移除和销毁。
ANR
参考文章 今日头条技术团队
ANR原理
ANR 全称 Applicatipon No Response;Android 设计 ANR 的用意,是系统通过与之交互的组件(Activity,Service,Receiver,Provider)以及用户交互(InputEvent)进行超时监控,以判断应用进程(主线程)是否存在卡死或响应过慢的问题,通俗来说就是很多系统中看门狗(watchdog)的设计思想。
以有序广播为例(因为无序广播没有超时限制),在客户端进程中,Binder 线程接收到 AMS 服务发送过来的广播消息之后,会将此消息进行封装成一个 Message,然后将 Message 发送到主线程消息队列 (插入到消息队列当前时间节点的位置,也正是基于此类设计导致较多消息调度及时性的问题)
正常情况下,很多广播请求都会在客户端及时响应,然后通知到系统 AMS 服务取消本次超时监控。但是在部分业务场景或系统场景异常的情况下,发送的广播未及时调度,没有及时通知到系统服务,便会在系统服务侧触发超时,判定应用进程响应超时。
避免产生ANR
不同的组件发生ANR的时间不一样,Activity是阻塞5秒,BroadCastReceiver是阻塞10秒,Service是阻塞20秒
平时代码中要注意几点:
- 避免在主线程各种做耗时操作(访问网络,Socket通信,查询大量SQL 语句,复杂逻辑计算等)
- 慎用Thread.wait()或者Thread.sleep()来阻塞主线程。
- Activity的onCreate和onResume回调中尽量避免耗时的代码。
BroadcastReceiver中onReceive代码也要尽量减少耗时,建议使用IntentService处理。
View
Window WindowManager WMS
-
Window :抽象类 不是实际存在的,而是以 View 的形式存在,通过 PhoneWindow 实现 (PhoneWindow = DecorView = Title + ContentView)
-
WindowManager:外界访问 Window 的入口 管理Window 中的View , 内部通过 Binder 与 WMS IPC 进程交互
-
WMS:管理窗口 Surface 的布局和次序,作为系统级服务单独运行在一个进程
-
SurfaceFlinger:将 WMS 维护的窗口按一定次序混合后显示到屏幕上
个人源码文章
View 工作流程
通过 SetContentView(),调用 到PhoneWindow ,后实例DecorView ,通过 LoadXmlResourceParser() 进行IO操作 解析xml文件 通过反射 创建出View,并将View绘制在 DecorView上,这里的绘制则交给了ViewRootImpl 来完成,通过performTraversals() 触发绘制流程,performMeasure 方法获取View的尺寸,performLayout 方法获取View的位置 ,然后通过 performDraw 方法遍历View 进行绘制。
事件分发
一个 MotionEvent 产生后,按 Activity -> Window -> DecorView(ViewGroup) -> View 顺序传递,View 传递过程就是事件分发(可以理解为责任链设计模式),因为开发过程中存在事件冲突,所以需要熟悉流程:
- dispatchTouchEvent:用于分发事件,只要接受到点击事件就会被调用,返回结果表示是否消耗了当前事件
- onInterceptTouchEvent:用于判断是否拦截事件(只有ViewGroup中存在),当 ViewGroup 确定要拦截事件后,该事件序列都不会再触发调用此 ViewGroup 的 onIntercept
- onTouchEvent:用于处理事件,返回结果表示是否处理了当前事件,未处理则传递给父容器处理。(事件顺序是:OnTouchListener -> OnTouchEvent -> OnClick)
View.post
参考博客1
参考博客2
想要在 onCreate 中获取到View宽高的方法有:
- ViewTreeObserver 监听界面绘制事件,在layout时调用,使用完毕后记得removeListener
- 就是View.post
源码分析:
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
getRunQueue().post(action);
return true;
}
View.post(runable) 通过将runable 封装为HandlerAction对象,如果attachInfo为null 则将Runnable事件 添加到等待数组中, attachInfo初始化是在 dispatchAttachedToWindow 方法,置空则是在detachedFromWindow方法中,所以在这两个方法生命周期中,调用View.post方法都是直接让 mAttachInfo.handler 执行。
ViewRootImpl.class
mAttachInfo = new View.AttachInfo(mWindowSession, mWindow, display, this, mHandler, this,
context);
final ViewRootHandler mHandler = new ViewRootHandler();
通过查找 mAttachInfo.handler 是在主线程中声明的,没有传参则 Looper 为主线程Looper,所以在View.post中可以更新UI。
但是为什么可以再View.post()中获取控件尺寸呢?
android 运行是消息驱动,通过源码 可以看到 ViewRootImpl 中 是先将 TraversalRunnable添加到 Handler 中运行的 之后 才是 View.post()
ViewRootImpl.class
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
// 该方法之后才有 view.post()
performTraversals();
...
}
}
因此,这个时候Handler正在执行着TraversalRunnable这个Runnable,而我们post的Runnable要等待TraversalRunnable执行完才会去执行,而TraversalRunnable这里面又会进行measure,layout和draw流程,所以等到执行我们的Runnable时,此时的View就已经被measure过了,所以获取到的宽高就是measure过后的宽高。
动画
- 帧动画 :AnimationDrawable 实现,在资源文件中存放多张图片,占用内存多,容易OOM
- 补间动画 :作用对象只限于 View 视觉改变,并没有改变View 的 xy 坐标,支持 平移、缩放、旋转、透明度,但是移动后,响应时间的位置还在 原处,补间动画在执行的时候,直接导致了 View 执行 onDraw() 方法。补间动画的核心本质就是在一定的持续时间内,不断改变 Matrix 变换,并且不断刷新的过程。
- 属性动画 :ObjectAnimator、ValuetAnimator、AnimatorSet 可以是任何View,动画选择也比较多,其中包含 差速器,可以控制动画速度,节奏。类型估值器 可以根据当前属性改变的百分比计算改变后的属性值 。因为ViewGroup 在 getTransformedMotionEvent方法中通过子 View 的 hasIdentityMatrix() 来判断子 View 是否经过位移之类的属性动画。调用子 View 的 getInverseMatrix() 做「反平移」操作,然后判断处理后的触摸点是否在子 View 的边界范围内。
提升动画 可以打开 硬件加速,使GPU 承担一部分CPU的工作。
Android 进程通讯方式
-
bundle : 由于Activity,Service,Receiver都是可以通过Intent来携带Bundle传输数据的,所以我们可以在一个进程中通过Intent将携带数据的Bundle发送到另一个进程的组件。(bundle只能传递三种类型,一是键值对的形式,二是键为String类型,三是值为Parcelable类型)
-
ContentProvider :ContentProvider是Android四大组件之一,以表格的方式来储存数据,提供给外界,即Content Provider可以跨进程访问其他应用程序中的数据
-
文件 :两个进程可以到同一个文件去交换数据,我们不仅可以保存文本文件,还可以将对象持久化到文件,从另一个文件恢复。要注意的是,当并发读/写时可能会出现并发的问题。
-
Broadcast :Broadcast可以向android系统中所有应用程序发送广播,而需要跨进程通讯的应用程序可以监听这些广播。
-
AIDL :AIDL通过定义服务端暴露的接口,以提供给客户端来调用,AIDL使服务器可以并行处理。
-
Messager :Messenger封装了AIDL之后只能串行运行,所以Messenger一般用作消息传递
-
Socket
Android 线程通信
Handler 和 AsyncTask (AsyncTask:异步任务,内部封装了Handler)
Handler线程间通信
作用:线程之间的消息通信
流程:主线程默认实现了Looper (调用loop.prepare方法 向sThreadLocal中set一个新的looper对象, looper构造方法中又创建了MsgQueue) 手动创建Handler ,调用 sendMessage 或者 post (runable) 发送Message 到 msgQueue ,如果没有Msg 这添加到表头,有数据则判断when时间 循环next 放到合适的 msg的next 后。Looper.loop不断轮训Msg,将msg取出 并分发到Handler 或者 post提交的 Runable 中处理,并重置Msg 状态位。回到主线程中 重写 Handler 的 handlerMessage 回调的msg 进行主线程绘制逻辑。
问题:
- Handler 同步屏障机制:通过发送异步消息,在msg.next 中会优先处理异步消息,达到优先级的作用
- Looper.loop 为什么不会卡死:为了app不挂掉,就要保证主线程一直运行存在,使用死循环代码阻塞在msgQueue.next()中的nativePollOnce()方法里 ,主线程就会挂起休眠释放cpu,线程就不会退出。Looper死循环之前,在ActivityThread.main()中就会创建一个 Binder 线程(ApplicationThread),接收系统服务AMS发送来的事件。当系统有消息产生(其实系统每 16ms 会发送一个刷新 UI 消息唤醒)会通过epoll机制 向pipe管道写端写入数据 就会发送消息给 looper 接收到消息后处理事件,保证主线程的一直存活。只有在主线程中处理超时才会让app崩溃 也就是ANR。
- Messaage复用: 将使用完的Message清除附带的数据后, 添加到复用池中 ,当我们需要使用它时,直接在复用池中取出对象使用,而不需要重新new创建对象。复用池本质还是Message 为node 的单链表结构。所以推荐使用Message.obation获取 对象。
- Looper、messageQuene、Handler关系线程:handle =1:多
,线程:Looper =1:1,线程:messagequeue=1:1
WebView
参考文章
优化:单独新起一个进程维护WebView,为了应对 webview 持续增加的内存使用。(牵扯到进程间通讯 可以参考上述链接 配置aidl 通讯)
WebView native和js通信
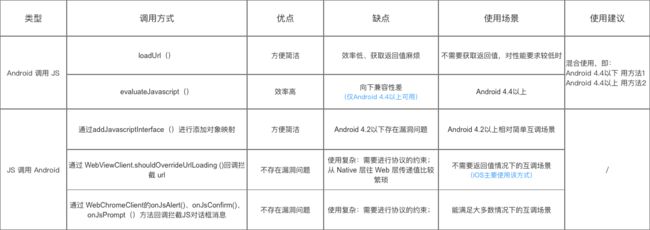
参考文章 webview js通讯
app优化 (项目中处理的一些难点)
主要分为 启动优化,布局优化 ,打包优化 等
内存优化参考文章
启动优化
- 闪屏页 优化,设置theme 默认欢迎背景
- 懒加载 第三方库,不要都放在application 中初始化(关于多个启动任务 有顺序的话,可以使用有向无环 BFS算法进行排序启动)
- 如果项目中有 webview ,可以提前在app空闲时间加载 webview 的内核,如果多处使用 可以创建缓存池,缓存webview,
- 如果android 5.0- 在applicaton 的 attchbaseContext() 中加载MultiDex.install 会更加耗时,可以采用 子线程(子线程加载 需要担心ANR 和ContentProvider 未加载报错的问题)或者单独开一个进程B,进程B开启子线程运行MultiDex.install ,让applicaton 进入while 循环等待B进程加载结果。
MultiDex 优化,apk打包分为 android 5.0 + 使用 ART虚拟机 不用担心
布局UI优化
看过布局绘制源码流程后,可以知道 setContextView中 在ViewRootImpl 中使用 pull 的方法(这里可以扩展xml读取方式 SAX :逐行解析、dom:将整个文件加载到内存 然后解析,不推荐、pull:类似于 SAX 进行了android平台的优化,更加轻量级 方便)迭代读取 xml标签,然后对view 进行 measure,layout 和draw 的时候都存在耗时。通常优化方式有:
- 减少UI层级、使用merge、Viewstub标签 优化重复的布局
- 优化 layout ,尽量多使用ConstraintLayout,因为 relalayout 和 linearlayout 比重的情况下都存在多次测量
- recyclerView 缓存 ( 可扩展 说明 rv的缓存原理 )
- 比较极端的 将 measure 和 layout 放在子线程,在主线程进行draw。或者 子线程中 加载view 进行IO读取xml,通过Handler 回调主线程 加载view(比如android 原生类 AsyncLayoutInflate )
- 将xml直接通过 第三方工具(原理 APT 注解 翻译xml)直接将xml 转为 java代码
更多UI优化文章
打包优化
Analyze APK 后可以发现代码 和 资源其实是 app包的主要内存
- res 文件夹下 分辨率下的图片 国内基本提供 xxhdpi 或者 xhdpi 即可,android 会分析手机分辨率到对应分辨率文件夹下加载资源
- res中的 png 图片 都可以转为 webg 或者 svg格式的 ,如果不能转 则可以通过 png压缩在减少内存
- 通过在 build.gradle 中配置 minifyEnabled true(混淆)shrinkResources true (移除无用资源)
- Assests 中的 mp4 /3 可以在需要使用的时候从服务器上下载下来,字体文件 使用字体提取工具FontZip 删除不用的文字格式,毕竟几千个中文app中怎么可能都使用
- lib 包如果 适配机型大多为高通 RAM ,可以单独引用abiFilters “armeabi-v7a”
- build文件中 resConfigs “zh” 剔除掉 官方中或者第三方库中的 外国文字资源
第三方库 源码总结
LeakCanary 原理
参考博客
通过 registerActivityLifecycleCallbacks 监听Activity或者Fragment 销毁时候的生命周期(如果不想那个对象被监控则通过 AndroidExcludedRefs 枚举,避免被检测)
public void watch(Object watchedReference, String referenceName) {
if (this == DISABLED) {
return;
}
checkNotNull(watchedReference, "watchedReference");
checkNotNull(referenceName, "referenceName");
final long watchStartNanoTime = System.nanoTime();
String key = UUID.randomUUID().toString();
retainedKeys.add(key);
final KeyedWeakReference reference =
new KeyedWeakReference(watchedReference, key, referenceName, queue);
ensureGoneAsync(watchStartNanoTime, reference);
}
然后通过弱引用和引用队列监控对象是否被回收(弱引用和引用队列ReferenceQueue联合使用时,如果弱引用持有的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。即 KeyedWeakReference持有的Activity对象如果被垃圾回收,该对象就会加入到引用队列queue)
void waitForIdle(final Retryable retryable, final int failedAttempts) {
// This needs to be called from the main thread.
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override public boolean queueIdle() {
postToBackgroundWithDelay(retryable, failedAttempts);
return false;
}
});
}
IdleHandler,就是当主线程空闲的时候,如果设置了这个东西,就会执行它的queueIdle()方法,所以这个方法就是在onDestory以后,一旦主线程空闲了,就会执行一个延时五秒的子线程任务,任务:检测到未被回收则主动 gc ,然后继续监控,如果还是没有回收掉,就证明是内存泄漏了。 通过抓取 dump文件,在使用 第三方 HAHA 库 分析文件,获取到到达泄露点最近的线路,通过 启动另一个进程的 DisplayLeakService 发送通知 进行消息的展示。
OkHttp
参考博客
☆平头哥 博客链接
同步和异步 网络请求使用方法
// 同步get请求
OkHttpClient okHttpClient=new OkHttpClient();
final Request request=new Request.Builder().url("xxx").get().build();
final Call call = okHttpClient.newCall(request);
try {
Response response = call.execute();
} catch (IOException e) {
}
//异步get请求
OkHttpClient okHttpClient=new OkHttpClient();
final Request request=new Request.Builder().url("xxx").get().build();
final Call call = okHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
// 异步post 请求
OkHttpClient okHttpClient1 = new OkHttpClient();
RequestBody requestBody = new FormBody.Builder()
.add("xxx", "xxx").build();
Request request1 = new Request.Builder().url("xxx").post(requestBody).build();
okHttpClient1.newCall(request1).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
同步请求流程:
通过OkHttpClient new生成call实例 Realcall
Dispatcher.executed() 中 通过添加realcall到runningSyncCalls队列中
通过 getResponseWithInterceptorChain() 对request层层拦截,生成Response
通过Dispatcher.finished(),把call实例从队列中移除,返回最终的response
异步请求流程:
生成一个AsyncCall(responseCallback)实例(实现了Runnable)
AsyncCall通过调用Dispatcher.enqueue(),并判断maxRequests (最大请求数)maxRequestsPerHost(最大host请求数)是否满足条件,如果满足就把AsyncCall添加到runningAsyncCalls中,并放入线程池中执行;如果条件不满足,就添加到等待就绪的异步队列,当那些满足的条件的执行时 ,在Dispatcher.finifshed(this)中的promoteCalls();方法中 对等待就绪的异步队列进行遍历,生成对应的AsyncCall实例,并添加到runningAsyncCalls中,最后放入到线程池中执行,一直到所有请求都结束。
责任链模式 和 拦截器
责任链
源码跟进 execute() 进入到 getResponseWithInterceptorChain() 方法
Response getResponseWithInterceptorChain() throws IOException {
//责任链 模式
List interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
return chain.proceed(originalRequest);
}
chain.proceed() 方法核心代码。每个拦截器 intercept()方法中的chain,都在上一个 chain实例的 chain.proceed()中被初始化,并传递了拦截器List与 index,调用interceptor.intercept(next),直接最后一个 chain实例执行即停止。
//递归循环下一个 拦截器
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
Interceptor interceptor = interceptors.get(index);
Response response = interceptor.intercept(next);
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Call call = realChain.call();
EventListener eventListener = realChain.eventListener();
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
while (true) {
...
// 循环中 再次调用了 chain 对象中的 proceed 方法,达到递归循环。
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
...
}
}
拦截器
- RetryAndFollowUpInterceptor :重连并跟踪 拦截器。
- BridgeInterceptor : 将用户请求构建为网络请求(hander cooker content-type 等) 并发起请求 。
- CacheInterceptor : 缓存拦截器 负责从缓存中返回响应和把网络请求响应写入缓存。
- ConnectInterceptor : 与服务端 建立连接,并且获得通向服务端的输入和输出流对象。
OkHttp 流程
- 采用责任链方式的拦截器,实现分成处理网络请求,可更好的扩展自定义拦截器(采用GZIP压缩,支持http缓存)
- 采用线程池(thread pool)和连接池(Socket pool)解决多并发问题,同时连接池支持多路复用(http2才支持,可以让一个Socket同时发送多个网络请求,内部自动维持顺序.相比http只能一个一个发送,更能减少创建开销))
- 底层采用socket和服务器进行连接.采用okio实现高效的io流读写
ButterKnife
参考文章
butterKnife 使用的是 APT 技术 也就是编译时注解,不同于运行时注解(在运行过程中通过反射动态地获取相关类,方法,参数等信息,效率低耗时等缺点),编译时注解 则是在代码编译过程中对注解进行处理(annotationProcessor技术),通过注解获取相关类,方法,参数等信息,然后在项目中生成代码,运行时调用,其实和直接手写代码一样,没有性能问题,只有编辑时效率问题。
ButterKnife在Bind方法中 获取到DecorView,然后通过Activity和DecorView对象获取xx_ViewBinding类的构造对象,然后通过构造方法反射实例化了这个类 Constructor。
在编写完demo之后,需要先build一下项目,之后可以在build/generated/source/apt/debug/包名/下面找到 对应的xx_ViewBinding类,查看bk 帮我们做的事情,
# xx_ViewBinding.java
@UiThread
public ViewActivity_ViewBinding(ViewActivity target, View source) {
this.target = target;
target.view = Utils.findRequiredView(source, R.id.view, "field 'view'");
}
# Utils.java
public static View findRequiredView(View source, @IdRes int id, String who) {
View view = source.findViewById(id);
if (view != null) {
return view;
}
String name = getResourceEntryName(source, id);
throw new IllegalStateException("Required view ...."}
通过上述上述代码 可以看到 注解也是帮我们完成了 findviewbyid 的工作。
butterknife 实现流程
- 扫描Java代码中所有的ButterKnife注解
- 发现注解, ButterKnifeProcessor会帮你生成一个Java类,名字<类名>$$ViewBinding.java,这个新生成的类实现了Unbinder接口,类中的各个view 声明和添加事件都添加到Map中,遍历每个注解对应通过JavaPoet生成的代码。
未来
Gradle插件升级到5.0版本之后ButterKnife将无法再被使用,R文件中的 id将添加final标识符,虽然 jake大神通过生成R2文件的方式,尝试避开版本升级带来的影响。但是随着官方ViewBinding等技术的出现,身为开发也要不断学习新技术才是正途。
我们这里说下 被final修饰的基础类型和String类型为什么不能被反射?
答:由于JVM 内联优化的机制,编译器将指定的函数体插入并取代每一处调用该函数的地方(就是在方法编译前已经进行了赋值),从而节省了每次调用函数带来的额外时间开支。
Glide
Glide基础流程
- with 流程 (anctivity fragment application 不同参数 不同的流程 )隐藏fragment 获取activity 生命周期
- load 流程 (Engine数据的封装、 缓存key准备 、EngineJob配合 第三部 into的使用)
- into 流程 (只讨论普通的bitmap:开始进行网络请求,设置 loading 状态 或者 err状态根据状态显示不同的已经设置的图片,根绝请求结果获取inputsteam,转为 bitmap 封装成Resource,通过回调 返回给主线程 handler,更新界面ui)
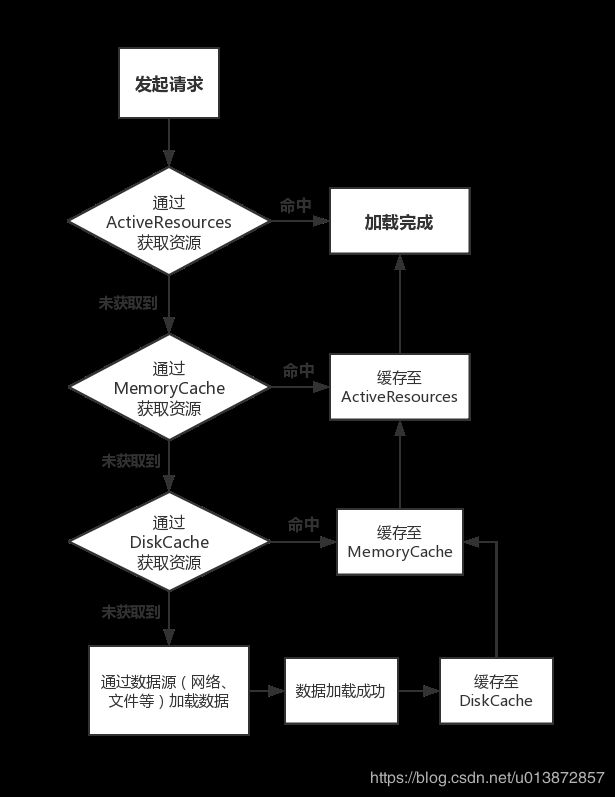
Glide 缓存
-
内存缓存 : ( ActiveResources(弱引用对象WeakReference HashMap )中去获取,如果没有去 LruCache中查找 。(lruCache 如果缓存达到LinkedHashMap设置最大数目,清除最少使用的缓存 。) Glide 中正在使用中的图片使用弱引用来进行缓存,不在使用中的图片使用LruCache来进行缓存)
-
硬盘缓存 :
放一个图片方便理解
Glide创建源码
//Map弱引用 glide 一级缓存 (储存当前正在活动/可见的资源)
Map<Key, WeakReference<EngineResource<?>>> activeResources
//根据当前机器参数计算需要设置的缓存大小
MemorySizeCalculator calculator = new MemorySizeCalculator(context);
//创建 Bitmap 池
if (bitmapPool == null) {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.HONEYCOMB) {
int size = calculator.getBitmapPoolSize();
//Bitmap复用
bitmapPool = new LruBitmapPool(size);
} else {
bitmapPool = new BitmapPoolAdapter();
}
}
//创建内存缓存 基于lruCache 实现二级缓存 (储存 不可见的资源)
if (memoryCache == null) {
memoryCache = new LruResourceCache(calculator.getMemoryCacheSize());
}
//创建磁盘缓存 三级缓存
if (diskCacheFactory == null) {
diskCacheFactory = new InternalCacheDiskCacheFactory(context);
}
-
一级缓存
activeResources 在构建时会和 ReferenceQueue 进行绑定,当弱引用被移除的时候 ReferenceQueue就可以知道弱引用是否被移除掉。
ReferenceQueue 会通过 addIdleHandler 的方式 添加到MessageQueue 中一个IdleHandler 对象,Handler在空闲的时候会调用该方法,在方法中检查是否gc。 -
Bitmap复用
LruBitmapPool策略模式,主要实现都在 LruPoolStrategy(主要实现类:SizeConfigStrategy) 中,和二级缓存一样,也是使用的Lru算法来维护的BitmapPool(Glide自定义了这里的数据结构,详情查阅下文的 Glide缓存参考文章) -
二级内存缓存
内存缓存同样使用 LRU 算法 (可以参考Java中的 LinkedHashMap,在HashMap的基础上,将Value 串成一个双向链表,根据访问修改操作,调整链表顺序) -
三级磁盘缓存
Glide磁盘缓存都放在getCacheDir()下的image_manager_disk_cache文件中,文件名称是通过图片多个配置生成的,保证唯一性。在向磁盘写入文件时(put 方法)会使用重入锁来同步代码(可以理解为 :ReentrantLock),磁盘缓存也是使用的Lru算法,不过是基于 journal 日志,记录图片的添加删除和读取操作。
Glide 缓存 参考文章