spark学习笔记
文章目录
-
-
- 1,spark架构
- 2,spark部署模式
- 3,spark单机模式
- 4,standalone模式
- 5,spark on yarn
- 6,idea写代码直接提交yarn
- 7,RDD缓存持久化
- 8,spark从mysql读写数据
- 9,spark宽依赖、窄依赖、DAG、JOB、STAGE、Pipeline、taskset
- 10,action和transformation
- 11,RDD
- 12,内存计算指的是上面
- 13,DAG 以 Shuffle 为边界划分 Stages,那 Spark 是根据什么来判断一个操作是否会引入 Shuffle 的呢?
- 14,在 Spark 中,同一 Stage 内的所有算子会融合为一个函数。这一步是怎么做到的吗?
- 15,mr的shuffle和spark的shuffle比较
- 16,stage划分和shuffle原理
- 17,spark为什么比mr快
- 18,spark设置并行度的三种方式
- 19,内存管理
- 20,任务调度
- 21,如何划分看窄依赖
- 22,读取hbase
- 24,写hbase
- 25,ds、df、rdd互转
- 26,spark sql
- 27, 批处理和流处理
- 28,spark streaming with status 1
- 29,spark stream 恢复
- 30,窗口+窗口内部排序
- 31,窗口+状态
- 32,dstream输出到mysql和hdfs
- 33,spark streaming with kafka
- 34, spark streaming的问题
- 35,structed stream source(4中source)
- 35,structed stream的输出模式
- 36,structed stream的trigger设定批次长度,类似窗口
- 37,structed stream的query name缓存
- 37,structured streaming输出
- 38,structured streaming检查点
- 39,structured streaming 全局去重
- 40,repartition和coalesce
- 41,cache和checkpoint
- 42,spark任务的执行流程
-
- 43,多字段join+select
- 44 , spark jdbc指定并发
- 45,spark cogroup
- 46,executor的日志
- 47,java spark Dataset使用Map
-
-
- 48,spark连接hive
- 49,spark定义和注册udf,使用udf
- 50,sparksql dsl为select准备字段
- 51,spark估计数据集大小
- 52,spark指定hdfs
- 53,spark sql 任意格式日期字符串格式转换
- 54,spark Row动态增加字段
- 55 ,spark版本查看
- 56,spark with hive
-
- 方式一: SparkSession + Hive Metastore
- 方式二: spark-sql CLI + Hive Metastore
- 方式三: Beeline + Spark Thrift Server
- 57,spark-sql和spark with hive的区别
- 58 spark sql切割字符串,一列变多列
-
- 总结
-
- 1,如何理解driver?
- 2,spark名词
- 3,数据尽量本地化,本地计算、本地存储。
- 4,spark容错总结
- 5,spark与mysql
- 6,spark为什么不搞流,要搞微批
- 7,job提交命令
- 8,解决数据倾斜
- 9,cache和checkpoint
- 10,如何判断代码在driver中执行还是在executor执行
- 11,预估数据集大小
- 12,按顺序写或是按名称写
-
- 13,关于任务调度的几个小问题
- 14,joinType
- 15,同一个application的job的并行还是串行
- 16,spark的数据源
- 17,在原有DF上增加字段的两种方法及其比较-java版本
- spark ui
-
-
- 1, spark读取文件是生成job
-
1,spark架构
2,spark部署模式
参考文章
- 本地模式
- 伪集群模式
- 集群模式1-自带cluster manager 的standalone client
- 集群模式2-自带cluster manager 的standalone master
- 集群模式3-on yarn client
- 集群模式4-on yarn master
client和master模式的区别:

3,spark单机模式
解压后,到bin目录,执行spark-shell.sh就可以启动一个单机模式的spark。
sc.textFile("file:///export/data/spark/words")
.flatMap(_.split(" "))
.map(_ -> 1)
.reduceByKey(_ + _)
.collect
4,standalone模式
standalone模式既独立模式,自带完整服务,可单独部署到一个集群中,无需依赖其他任何资源管理系统,只支持FIFO调度器。从一定程度上说,它是spark
on yarn 和spark on mesos
的基础。在standalone模式中,没有AM和NM的概念,也没有RM的概念,用户节点直接与master打交道,由driver负责向master申请资源,并由driver进行资源的分配和调度等等。
4.1 伪分布式:一个机器运行多个进程,Master和worker在一台机器上;
4.2 完全分布式:master和worker分布在不同机器上;
配置:修改slaves,修改spark-env.sh
启动后shell连接集群:
spark-shell --master node1:7077
4.3 高可用分布式:master和worker分布在不同机器上,有多于一个master。
第一,修改配置文件spark-env.sh
第二,启动集群
start-all.sh
第三,在node2上启动单独一个master
start-master.sh
要注意的是,spark的高可用集群不需要指定master,也不会投票选举,谁先启动,谁就是master,上面第三步启动第二个master就是备用master
5,spark on yarn
6,idea写代码直接提交yarn
6.1 代码
System.setProperty("HADOOP_USER_NAME", "root")
val conf = new SparkConf()
.setAppName("WordCount")
// 设置yarn-client模式提交
.setMaster("yarn")
// 设置resourcemanager的ip
///.set("yarn.resourcemanager.hostname","node1")
// .set("yarn.resourcemanager.scheduler.address","node1:8030")
// .set("yarn.resourcemanager.resource-tracker.address","node1:8031")
// 设置executor的个数
.set("spark.executor.instance","2")
// 设置executor的内存大小
.set("spark.executor.memory", "1024M")
//
// .set("spark.yarn.app.id","qqw")
// 设置提交任务的yarn队列
.set("spark.yarn.queue","prod")
// 设置driver的ip地址
.set("spark.driver.host","192.168.239.1")
.set("hadoop.yarn.timeline-service.enabled","false")
// 设置jar包的路径,如果有其他的依赖包,可以在这里添加,逗号隔开
.setJars(List("D:\\ideaprojects\\target\\spark-1.0-SNAPSHOT.jar"))
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val value = this.getClass.getClassLoader.loadClass("org.apache.spark.scheduler.cluster.YarnClusterManager")
val context = new SparkContext(conf)
val file = context.textFile("hdfs://node1:8020/spark/data/words")
println(file.collect())
6.2 用maven打包,将打好的包设置在配置文件中
conf.setJars(List("D:\\ideaprojects\\target\\spark-1.0-SNAPSHOT.jar"))
6.3,在resource目录下新增三个配置文件

6.4,本地要有spark的运行环境,即安装解压spark安装包。
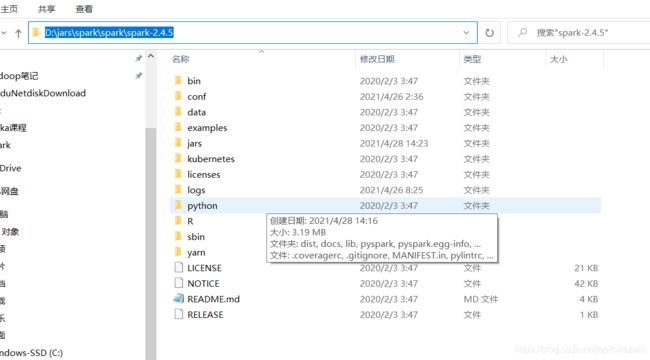
6.6 配置运行时环境变量
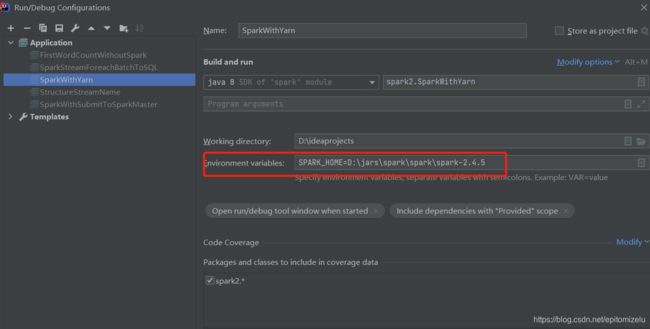
6.7 导包
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-yarn_2.11
${spark.version}
provided
7,RDD缓存持久化
7.1 RDD缓存:rdd.persist(),rdd.unpersist(),rdd.cache()
7.2 RDD持久化:rdd.checkpoint
7.3 RDD checkpoint恢复:
SparkContext有从ck路径回复的api:checkPointFile,但是这个方法时protected,不能在包外访问。
缓存的作用:如果一个作业由多个action,会触发多个job,多个job不会共享相同的父依赖,缓存之后会共享,可以节省计算资源。
package org.apache.spark
import org.apache.spark.rdd.RDD
object RddUtil {
def readFromCk[T](sc:SparkContext,path:String) = {
val value: RDD[Any] = sc.checkpointFile(path)
value.asInstanceOf[T]
}
}
package spark2
import org.apache.spark.rdd.RDD
import org.apache.spark.{RddUtil, SparkConf, SparkContext}
object RecoverFromCheckpoint {
def main(args: Array[String]): Unit = {
val name = new SparkConf().setMaster("local[*]")
.setAppName(this.getClass.getName)
val context = new SparkContext(name)
context.setLogLevel("WARN")
val value: RDD[(String, Int)]= RddUtil.readFromCk(context, "data/ck/value6/0e5f6c72-87ec-4470-b0d7-8f3fd18e3836/rdd-10")
value.foreach(println)
}
}
8,spark从mysql读写数据
persons.foreachPartition(it=>{
val url = "jdbc:mysql://192.168.88.163:3306/spark?characterEncoding=UTF-8"
val connection: Connection = DriverManager.getConnection(url, "root", "123456")
val statement: PreparedStatement = connection.prepareStatement("insert into person(id,name) value(?,?)")
it.foreach(p=>{
statement.setInt(1,p._1)
statement.setString(2,p._2)
statement.execute();
})
})
val personsFromMysql = new JdbcRDD[Person](
sc,
() => {
val url = "jdbc:mysql://192.168.88.163:3306/spark?characterEncoding=UTF-8"
DriverManager.getConnection(url, "root", "123456")
},
"select id,name from person where id >= ? and id <= ?",
19,
30,
3,//numPartitions=3
res => Person(res.getInt(1), res.getString(2))
)
注意加注释(numPartitions=3)的这样,这是分区参数,会根据id的范围进行划分,比如上面的id是[19,30],会将其均分为三个区间[19,23)[23,27)[27,31]
9,spark宽依赖、窄依赖、DAG、JOB、STAGE、Pipeline、taskset
一个action会创建一个DAG,一个action对应一个job,一个job对应什么?
task是指一个任务调度单元,可能是一组算子构成的pipeline,也可能是一个算子构成的pipeline。
stage是逻辑概念,是为了提升效率对具备某种条件的算子的整合,task是运行时概念,是基于stage而来,task由数量指标,task的数量有当前rdd的分区数决定,也可以理解为并行度。如果并行度是1,则可以认为一个stage就是一个task,当然这是为了理解stage和task的关系才这样表述。
基于同一个stage产生的所有task称之为taskset。
pipeline是stage和task的另一种状态,表示由多个算子构成的流水线,称之为管道。
spark基于宽依赖划分stage,同一个stage内的rdd的依赖关系都是窄依赖,某个宽依赖前后的依赖会被划分到两个不同的依赖中去。
判断宽窄依赖的依据是父子RDD的分区直接的关系,当且仅当父rdd的一个分区只被子rdd的一个分区依赖,称之窄依赖。
10,action和transformation
action会触发计算:sortBy/take
transformation创建RDD,但不会触发计算:map/reduceBy/
11,RDD
定义:可伸缩的分布式数据集。
5个特性:
1,每个RDD都作用在一组分区上;
2,每个RDD都使作用在分区数据的一个函数;
3,RDD之间有依赖关系:横向依赖和纵向依赖;
4,K-V格式的RDD有分区器Partitioner(HashPartitioner和RangePartitioner);
5,数据尽量本地化;
12,内存计算指的是上面
Spark 中,内存计算有两层含义:
- 第一层含义就是众所周知的分布式数据缓存
- 第二层含义是 Stage 内的流水线式计算模式
spark的计算过程中没有落盘的动作。虽然hadoop也有缓存,但是hadoop会有落盘的动作。
13,DAG 以 Shuffle 为边界划分 Stages,那 Spark 是根据什么来判断一个操作是否会引入 Shuffle 的呢?
根据前后两个RDD的分区器是否一致,如果一致不会有shuffle。只有key-value 类型的RDD才有分区器。如果一个RDD的数据来自多个父分区,说明有shuffle
用一个stage:子RDD的分区继承自父RDD,或者说子RDD的分区和父RDD的分区保持一致。
导致shuffle的算子:分区、keyBy、join
14,在 Spark 中,同一 Stage 内的所有算子会融合为一个函数。这一步是怎么做到的吗?
15,mr的shuffle和spark的shuffle比较

16,stage划分和shuffle原理
shuffle原理
stage划分
spark作业流程
17,spark为什么比mr快
mr的作业中间结果都会写入磁盘,由大量的io
spark利用DAG进行作业调度,将任务串联起来,充分利用缓存,极大的降低了磁盘io。
18,spark设置并行度的三种方式
并行度可以通过如下三种方式来设置,可以根据实际的内存、CPU、数据以及应用程序逻辑的情况调整并行度参数
- ①在会产生shuffle的操作函数内设置并行度参数,优先级最高
testRDD.groupByKey(24)
- ②在代码中配置
“spark.default.parallelism”设置并行度,优先级次之
,这种方式只对没有分区器的数据源,对于读hdfs文件,这样设置是无效的。
val conf = new SparkConf()
conf.set("spark.default.parallelism", 24)
spark.sparkContext.parallelize(Seq(),3)
- 在
“$SPARK_HOME/conf/spark-defaults.conf”文件中配置“spark.default.parallelism”的值,优先级最低
spark.default.parallelism 24
19,内存管理
spark推荐堆内存,堆外内存和对内存不能完全融合,一个task使用了堆外内存无法同时使用堆内存。
堆内存的主要问题是GC的延迟导致spark内存预估不准。
堆外内存直接使用Unsafe的allocateMemory和freeMemory,对内存的预估更准确。

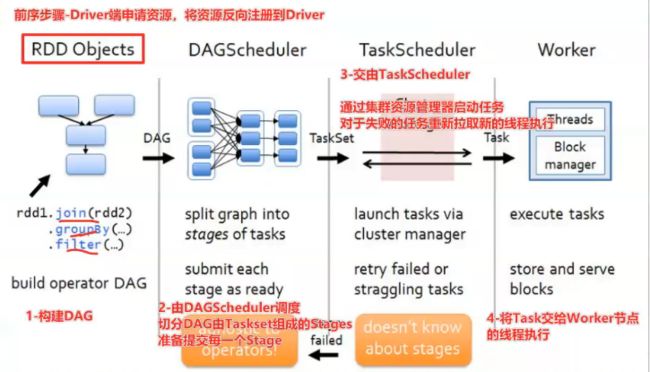
20,任务调度
spark的任务调度分为5个步骤:
1,DAGSkeduler根据用户代码生成DAG,并划分Stage;
2,DAGSkeduler根据DAG生成Task和TaskSet;
3,SkedulerBackend获取集群空闲资源并以WorkerOffer单位提供;
4,TaskSkeduler根据Stage、Task的依赖关系、优先级确定调度规划;
5,SkedulerBackend根据第四步结构向TaskExecutor提交任务。
TaskSkeduler由两种调度:FIFO、公平调度。
TaskSkeduler调度时还会考虑数据本地性,数据本地性由四种级别:进程级别、节点级别、机架级别、Any。
涉及到shuffle的很容易变成:

- Spark 调度系统的核心职责是,先将用户构建的 DAG 转化为分布式任务,结合分布式集群资源的可用性,基于调度规则依序把分布式任务分发到执行器 Executors;
- Spark 调度系统的核心原则是,尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方(Executors 或计算节点),从而最大限度地降低分布式系统中的网络开销
task是线程级别的,executor是进程级别,一个executor可以运行多个task。
1,spark数据本地性
21,如何划分看窄依赖
看算子,分类讨论。一类算子会直接记录宽窄依赖关系,另一类算子通过判断partitioner与父依赖是否一致来决定。
22,读取hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从HBase 表中读取数据,封装到RDD数据集
*/
object SparkReadHBase {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
// 读取HBase Client 配置信息
val conf: Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node1")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置读取的表的名称
conf.set(TableInputFormat.INPUT_TABLE, "htb_wordcount")
/*
def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V]
): RDD[(K, V)]
*/
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
conf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
println(s"Count = ${resultRDD.count()}")
resultRDD
.take(5)
.foreach { case (rowKey, result) =>
println(s"RowKey = ${Bytes.toString(rowKey.get())}")
// HBase表中的每条数据封装在result对象中,解析获取每列的值
result.rawCells().foreach { cell =>
val cf = Bytes.toString(CellUtil.cloneFamily(cell))
val column = Bytes.toString(CellUtil.cloneQualifier(cell))
val value = Bytes.toString(CellUtil.cloneValue(cell))
val version = cell.getTimestamp
println(s"\t $cf:$column = $value, version = $version")
}
}
// 应用程序运行结束,关闭资源
sc.stop()
}
}
24,写hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至HBase表中
*/
object SparkWriteHBase {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
// 构建RDD
val list = List(("hadoop", 234), ("spark", 3454), ("hive", 343434), ("ml", 8765))
val outputRDD: RDD[(String, Int)] = sc.parallelize(list, numSlices = 2)
// 将数据写入到HBase表中, 使用saveAsNewAPIHadoopFile函数,要求RDD是(key, Value)
// 组装RDD[(ImmutableBytesWritable, Put)]
/**
* HBase表的设计:
* 表的名称:htb_wordcount
* Rowkey: word
* 列簇: info
* 字段名称: count
*/
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = outputRDD.mapPartitions { iter =>
iter.map { case (word, count) =>
// 创建Put实例对象
val put = new Put(Bytes.toBytes(word))
// 添加列
put.addColumn(
// 实际项目中使用HBase时,插入数据,先将所有字段的值转为String,再使用Bytes转换为字节数组
Bytes.toBytes("info"), Bytes.toBytes("cout"), Bytes.toBytes(count.toString)
)
// 返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
}
// 构建HBase Client配置信息
val conf: Configuration = HBaseConfiguration.create()
// 设置连接Zookeeper属性
conf.set("hbase.zookeeper.quorum", "node1")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置将数据保存的HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, "htb_wordcount")
/*
def saveAsNewAPIHadoopFile(
path: String,// 保存的路径
keyClass: Class[_], // Key类型
valueClass: Class[_], // Value类型
outputFormatClass: Class[_ <: NewOutputFormat[_, _]], // 输出格式OutputFormat实现
conf: Configuration = self.context.hadoopConfiguration // 配置信息
): Unit
*/
putsRDD.saveAsNewAPIHadoopFile(
"datas/spark/htb-output-" + System.nanoTime(), //
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf
)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
25,ds、df、rdd互转
rdd转ds、df的前提:
1,import spark.implicits._
2,rdd的泛型是样例类或者是元组,不能是普通的bean
import spark.implicits._
val rddToDf: DataFrame= rdd.toDF()
val rddToDs: Dataset[WordCount] = rdd.toDS()
val df2dS: Dataset[WordCount] = rddToDf.as[WordCount]
val rdd1: RDD[Row] = rddToDf.rdd
val rdd2: RDD[WordCount] = df2dS.rdd
val frame: DataFrame = df2dS.toDF()
26,spark sql
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("movie")
.master("local[*]")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("warn")
val sourceDf: DataFrame = spark.read
.option("sep", "\\t")
.schema("userId int,movieId int, rating int,timestamp long")
.csv("data/input/rating_100k.data")
// top10
//import org.apache.spark.sql.functions._
val frame: DataFrame = sourceDf
.groupBy("movieId")
.agg(
avg("rating") as ("avgRating"),
count("movieId") as ("cnt")
)
.filter("cnt > 200")
.select("movieId", "avgRating", "cnt")
.orderBy(col("avgRating").desc)
frame.write.csv("data/output/movie")
// sql
sourceDf.createOrReplaceTempView("movies")
val sql =
"""select movieId,avg(rating) as avg_r,count(1) as cnt
|from movies group by movieId
|having cnt > 200
|order by avg_r desc""".stripMargin
spark.sql(sql).take(10).foreach(row=>println("sql",row))
}
27, 批处理和流处理
批处理一次把数据全部处理完
流处理是处理远远不断的大数据量
28,spark streaming with status 1
updateStateByKey 要设置checkpoint目录
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("warn")
sc.setCheckpointDir("data/ck/streamingwithstatus")
val ssc = new StreamingContext(sc,Duration(10000))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8001)
val words: DStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map(_ -> 1)
val wordsCnt: DStream[(String, Int)] = words.updateStateByKey((currentVals,hisVals)=>{
var cnt = 0
if (hisVals != null) {
hisVals.foreach(f=> cnt += f)
}
currentVals.foreach(f=> cnt += f)
Some(cnt)
})
wordsCnt.print()
ssc.start()
ssc.awaitTermination()
}
mapWithState
def main(args: Array[String]): Unit = {
val mappingFunction: (String, Option[Int], State[Int]) =>(String,Int)
= (key, value, state) => {
val cnt = value.getOrElse(0)
val old: Int = state.getOption().getOrElse(0)
state.update(cnt+old)
(key, cnt+old)
}
val spec = StateSpec.function(mappingFunction).numPartitions(10)
val wordsCnt: DStream[(String, Int)] = words
.reduceByKey(_+_)
.mapWithState(spec)
wordsCnt.print()
ssc.start()
ssc.awaitTermination()
}
29,spark stream 恢复
def main(args: Array[String]): Unit = {
val ssc = StreamingContext.getOrCreate(ckPath, createSC)
ssc.start()
ssc.awaitTermination()
ssc.stop(true,true)
}
def createSC() = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("warn")
sc.setCheckpointDir(ckPath)
val ssc = new StreamingContext(sc,Duration(3000))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8001)
val words: DStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map(_ -> 1)
val wordsCnt: DStream[(String, Int)] = words.updateStateByKey((currentVals,hisVals)=>{
var cnt = 0
if (hisVals != null) {
hisVals.foreach(f=> cnt += f)
}
currentVals.foreach(f=> cnt += f)
Some(cnt)
})
wordsCnt.print()
ssc
}
30,窗口+窗口内部排序
使用窗口函数后,窗口将多个批次合并为一个rdd,通过transform函数获取rdd,然后对rdd进行各种操作。
比如,排序,不能直接作用再stream上,而是作用在stream封装的rdd上,此时需要transform。
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("warn")
val ssc = new StreamingContext(sc,Duration(2000))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8001)
val words: DStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map(_ -> 1)
val keyValues: DStream[(String, Int)] = words
.window(Duration(8000),Duration(8000))
.reduceByKey(_+_)
// .reduceByKeyAndWindow((_:Int) + (_:Int),Duration(10000),Duration(8000))
keyValues.transform(rdd=>{
val sortedRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false)
sortedRDD.take(3).foreach(x=>println("top3:"+x))
sortedRDD
}).print()
ssc.start()
ssc.awaitTermination()
}
31,窗口+状态
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("warn")
sc.setCheckpointDir("data/ck/window")
val ssc = new StreamingContext(sc,Duration(2000))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8001)
val words: DStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map(_ -> 1)
val keyValues: DStream[(String, Int)] = words
.window(Duration(8000),Duration(8000))
.updateStateByKey((currentVals,hisVals)=>{
var cnt = 0
if (hisVals != null) {
hisVals.foreach(f=> cnt += f)
}
currentVals.foreach(f=> cnt += f)
Some(cnt)
})
keyValues.print()
ssc.start()
ssc.awaitTermination()
}
32,dstream输出到mysql和hdfs
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("warn")
sc.setCheckpointDir("data/ck/window")
val ssc = new StreamingContext(sc,Duration(2000))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8001)
val words: DStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map(_ -> 1)
val keyValues: DStream[(String, Int)] = words
.window(Duration(8000),Duration(8000))
.updateStateByKey((currentVals,hisVals)=>{
var cnt = 0
if (hisVals != null) {
hisVals.foreach(f=> cnt += f)
}
currentVals.foreach(f=> cnt += f)
Some(cnt)
})
keyValues.foreachRDD(rdd=>{
val conn = DriverManager.getConnection("jdbc:mysql://node1:3306/spark?characterEncoding=UTF-8","root","root")
val sql:String = "REPLACE INTO `person` (`id`, `name`) VALUES (?, ?);"
val ps: PreparedStatement = conn.prepareStatement(sql)
rdd.foreachPartition(it=>{
it.foreach(item=>{
ps.setInt(1, item._2)
ps.setString(2, item._1)
ps.addBatch()
})
})
ps.executeBatch()
ps.close()
conn.close()
// 存储到hdfs文件中
rdd.saveAsTextFile("hdfs://node01:8020/spark/tmp/dstream")
})
ssc.start()
ssc.awaitTermination()
33,spark streaming with kafka
val session: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()
val sparkContext: SparkContext = session.sparkContext
sparkContext.setLogLevel("warn")
val streamingContext = new StreamingContext(sparkContext, Duration(10000l))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("spark-integrate")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
rdd.foreachPartition(it => {
it.foreach(re=>{
println(s"${re.key}-${re.value}")
})
})
})
streamingContext.start()
streamingContext.awaitTermination()
34, spark streaming的问题
1,只能使用process time
2,只有低级api:很多运算要转换为rdd进行,比如保存、排序等
3,只能保证spark的一致性,不能实现端到端的一致性
4,批流api的不统一
35,structed stream source(4中source)
kafka/socket/file/rate
rate
def main(args: Array[String]): Unit = {
val spark: SparkSession = getSparkSession()
val dataFrame: DataFrame = spark.readStream
.format("rate")
.option("rowsPerSecond","10")
.option("rampUpTime","0s")
.option("numPartitions",2)
.load
dataFrame.writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()
}
file
val spark: SparkSession = getSparkSession()
val dataFrame: DataFrame = spark.readStream
.format("csv")
.option("sep",";")
.schema("name String,age int,hobby string")
.load("data/input/persons")
dataFrame.writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()
socket :测试用,不支持容错
val spark = getSparkSession()
val frame: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 8001)
.load()
frame.writeStream
.outputMode("append")
.format("console")
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()
35,structed stream的输出模式
从支不支持聚合、排序来区分
- complete
输出所有数据,支持聚合、排序
- append
输出新增加的行,适用于数据产生后不再change的场景,不支持聚合
- update
输出新增的行和update过后的行,不支持排序,支持聚合

36,structed stream的trigger设定批次长度,类似窗口
37,structed stream的query name缓存
和cache有什么区别吗
def main(args: Array[String]): Unit = {
val spark = getSparkSession()
val frame: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 8001)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val words: DataFrame = frame.toDF("words").flatMap(
row => row.getString(0).split(" ")
).toDF("word")
val wordCountDF: DataFrame = words.groupBy($"word")
.agg(
count($"word") as "wordCnt"
)
.select("word", "wordCnt")
val query: StreamingQuery = wordCountDF.writeStream
.outputMode("complete")
.format("memory")
.queryName("wordCnt")
.start()
while(true) {
Thread.sleep(1000)
spark.sql("select * from wordCnt").show()
}
query.awaitTermination()
}
37,structured streaming输出
Structed Streaming提供了几种输出的类型:
- file,保存成csv或者parquet
df
.writeStream
.format("parquet")
.option("checkpointLocation", "path/to/checkpoint/dir")
.option("path", "path/to/destination/dir")
.start()
- console,直接输出到控制台。一般做测试的时候用这个比较方便。
df
.writeStream
.format("console")
.start()
- memory,可以保存在内容,供后面的代码使用
df
.writeStream
.queryName("aggregates")
.outputMode("complete")
.format("memory")
.start()
spark.sql("select * from aggregates").show()
- foreach,参数是一个foreach的方法,用户可以实现这个方法实现一些自定义的功能。
writeStream
.foreach(...)
.start()
38,structured streaming检查点
def main(args: Array[String]): Unit = {
val spark = getSparkSession()
val frame: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 8001)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val words: DataFrame = frame.toDF("words").flatMap(
row => row.getString(0).split(" ")
).toDF("word")
val wordCountDF: DataFrame = words.groupBy($"word")
.agg(
count($"word") as "wordCnt"
)
.select("word", "wordCnt")
val query: StreamingQuery = wordCountDF.writeStream
// ******* 设置检查点路径
.option("checkpointLocation","data/output/cks")
.outputMode("complete")
.format("memory")
.queryName("wordCnt")
.start()
while(true) {
Thread.sleep(1000)
spark.sql("select * from wordCnt").show()
}
query.awaitTermination()
39,structured streaming 全局去重
dropDuplicates会引起shuffle
import org.apache.spark.SparkContext
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* Desc: 演示Spark的 全局去重算子
* {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"}
* {"eventTime": "2016-01-10 10:01:55","eventType": "browse","userID":"1"}
* {"eventTime": "2016-01-10 10:01:55","eventType": "click","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "aaa","userID":"1"}
* {"eventTime": "2016-01-10 10:02:00","eventType": "click","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"}
* {"eventTime": "2016-01-10 10:01:51","eventType": "click","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
* {"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"3"}
* {"eventTime": "2016-01-10 10:01:51","eventType": "aaa","userID":"2"}
*/
object Demo10_Deduplication {
def main(args: Array[String]): Unit = {
// 0. Init Env
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
// 测试阶段经常用这个 参数
// 参数用来设置: 在shuffle阶段 默认的分区数量(如果你不设置默认是200)
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
// 经常用到的两个隐式转换我们也写上
import spark.implicits._
import org.apache.spark.sql.functions._
val socketDF: DataFrame = spark.readStream
.format("socket") // socket 不支持容错
.option("host", "node3")
.option("port", 9999)
.load()
// DF 转 DS 用as方法 对泛型做替换
val resultDF: DataFrame = socketDF.as[String]
// 传入数据是json, 我们需要用sql中的get_json_object函数来获取json中的字段
.select(
// 默认的列名 叫做value
// 取json的列, $表示的是json的root(根)
get_json_object($"value", "$.eventTime").as("event_time"),
get_json_object($"value", "$.eventType").as("event_type"),
get_json_object($"value", "$.userID").as("user_id")
// 通过这个selec + get_json_object方法就将数据转变成了 一个3个列的df对象
)
.dropDuplicates("user_id", "event_type")
.groupBy("user_id")
.count()
resultDF.writeStream
.format("console")
.outputMode(OutputMode.Complete())
.start()
.awaitTermination()
sc.stop()
}
}
40,repartition和coalesce
repartition一定会shuffle
coalesce可以不shuffle,如果修改的分区比原分区小,比如当前rdd的分区是1000,修改后的分区是10,spark不会将这1000个分区合并为10个分区,而是分为10个组,rdd的compute在组内各个分区迭代。相当于降低父rdd的并行度。
如果父rdd的分区数是1000,要通过coalesce将分区数增大为2000,shuffle设置为false时是无效的。
41,cache和checkpoint
cache和checkpoint都是transform操作,需要action触发,所以在cache和checkpoint之后需要count一下触发action,之后会缓存和持久化。
cache不会切断DAG,checkpoint会切断DAG。
package spark
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object RDDCheckpiont {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getName)
val sc: SparkContext = new SparkContext(conf)
sc.setCheckpointDir("data/output/ck")
sc.setLogLevel("warn")
val rdd: RDD[(String, Int)] = sc
.textFile("data/input/words.txt")
.flatMap(_.split("\\s+"))
.map(
word=>{
println(word+"77777")
(word,1)
}
)
val rdd1 = rdd.cache()
rdd1.checkpoint()
rdd1.count()
rdd1.reduceByKey(_+_).collect
rdd1.aggregateByKey(0)(_ + _, _ +_).collect()
rdd1.aggregateByKey(0)(_ + _, _ +_).collect()
Thread.sleep(100000000)
}
}
42,spark任务的执行流程
43,多字段join+select
Dataset finalDS = newDS.join(oldDataSet,
oldDataSet.col(Constant.COMPANY_ID).equalTo(newDS.col(Constant.COMPANY_ID))
.and(oldDataSet.col(Constant.EVENT_TYPE).equalTo(newDS.col(Constant.EVENT_TYPE)))
.and(oldDataSet.col(Constant.EVENT_GROUP_ID).equalTo(newDS.col(Constant.EVENT_GROUP_ID)))
// .and(oldDataSet.col("index").equalTo(newDS.col("index")))
, Constant.FULL_JOIN).select(columns(oldDataSet, newDS));
private static Seq columns(Dataset oldDataSet, Dataset newDS) {
StructField[] fields = newDS.schema().fields();
List columns = new ArrayList<>();
for (StructField field : fields) {
String name = field.name();
if (Constant.EVENT_GROUP_ID.equals(name) || Constant.EVENT_TYPE.equals(name) || Constant.COMPANY_ID.equals(name)) {
Column column = functions.nanvl(newDS.col(name), oldDataSet.col(name)).as(name);
columns.add(column);
} else {
columns.add(newDS.col(name));
}
}
return JavaConverters.asScalaIteratorConverter(columns.listIterator()).asScala().toSeq();
}
44 , spark jdbc指定并发
val l = System.currentTimeMillis()
val spark = SparkUtils.sparkSession(SparkUtils.sparkConf("name"))
val sql = s"(select ${FieldToString.toStringSql} from hits_v1) tmp"
val ckDF = spark.read.format("jdbc")
.option("url", "jdbc:clickhouse://node1:8123/datasets")
.option("dbtable", sql)
.option("numPartitions", "5")
.option("partitionColumn", "WatchID")
.option("lowerBound","4611686725751467379")
.option("upperBound","9223371678237104442")
.load()
// .repartition(10)
println("ckDF.rdd.partitions.size" + ckDF.rdd.partitions.size)
println("ckDF.rdd.partitions.size" + ckDF.rdd.partitioner)
ckDF.write.format("jdbc")
.option("url", "jdbc:clickhouse://node2:8123/default")
.option("dbtable", "hits_v1")
.option("numPartitions", "2")
.option("batchSize",50000)
.mode(SaveMode.Append)
.save()
45,spark cogroup
val cgRDD3: RDD[(String, (Iterable[String], Iterable[String], Iterable[String]))] = value2.cogroup(value2, value2)
cgRDD3.reduceByKey((it1,it2)=>{
(it1._1.++(it2._1) ,it1._2.++(it2._2),it1._3)
})
46,executor的日志
1,spark ui上executor列表右边列有标准日志和错误日志的连接
2,spark目录/work/应用id/executor_id/
47,java spark Dataset使用Map
直接使用dataset的map,如果在map中有schema变化,会导致丢失schema,新生成的RDD只有一个字段value,所以这种方式行不通。
要先通过Dataset转RDD,然后RDD转Dataset。
Dataset<Row> text = spark.read().text("data/teachers.txt");
text.show();
ClassTag tag = scala.reflect.ClassTag$.MODULE$.apply(Teacher.class);
// Dataset转RDD
RDD rdd = text.rdd().map(new MyMapFunction(), tag);
// RDD转Dataset
Dataset<Row> dataFrame = spark.createDataFrame(rdd, Teacher.class);
dataFrame.printSchema();
public class Teacher implements KryoRegistrator {
private String id;
private String name;
private String age;
public Teacher(String id, String name, String age) {
this.id = id;
this.name = name;
this.age = age;
}
@Override
public void registerClasses(Kryo kryo) {
kryo.register(Teacher.class, new FieldSerializer(kryo, Teacher.class)); //在Kryo序列化库中注册自定义的类
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
}
static class MyMapFunction implements scala.Function1<Row, Teacher>,Serializable {
@Override
public Teacher apply(Row row) {
String info = row.getString(0);
String[] split = info.split(",");
return new Teacher(split[0],split[1],split[2]);
}
@Override
public <A> Function1<A, Teacher> compose(Function1<A, Row> g) {
return Function1.super.compose(g);
}
@Override
public <A> Function1<Row, A> andThen(Function1<Teacher, A> g) {
return Function1.super.andThen(g);
}
}
48,spark连接hive
JdbcDialects.registerDialect(new HiveDialet());
// 1,连接Hive
List confEntities = batchData.get(event);
BatchReadConfEntity confEntity = confEntities.get(0);
String table = EventTableRelationUtil.getTable(event);
String realTable = String.format("%s_%s_rt", odsOrDwd, table);
Dataset jdbcDF = spark.read()
.format("jdbc")
.option("url", "jdbc:hive2://10.49.2.135:7001/hudi_test?hive.resultset.use.unique.column.names=false")
.option("dbtable", realTable)
.option("user", "hadoop")
.option("header", "true")
.option("password", "HrKucX")
.option("driver", "org.apache.hive.jdbc.HiveDriver")
.load();
static class HiveDialet extends JdbcDialect {
@Override
public String quoteIdentifier(String colName) {
if(colName.contains(".")){
String colName1 = colName.substring(colName.indexOf(".")+1);
return "`"+colName1+"`";
}
return "`"+colName+"`";
}
@Override
public boolean canHandle(String url) {
return url.startsWith("jdbc:hive2");
}
}
org.apache.hive
hive-jdbc
3.0.0
49,spark定义和注册udf,使用udf
定义和注册:
private static void registerUdf(SparkSession spark, Map> sidInfoMap) {
UserDefinedFunction udfSid = functions.udf((UDF3) (companyId, countryCode, sellerId) -> {
List confEntities = sidInfoMap.get(ClickHouseUtil.composeKey4Sid(companyId, countryCode, sellerId));
if (confEntities == null || confEntities.isEmpty()) {
return "0";
}
return confEntities.get(0).getSid();
}, DataTypes.StringType);
UserDefinedFunction udfTimezone = functions.udf((UDF3) (companyId, countryCode, sellerId) -> {
List confEntities = sidInfoMap.get(ClickHouseUtil.composeKey4Sid(companyId, countryCode, sellerId));
if (confEntities == null || confEntities.isEmpty()) {
return null;
}
return confEntities.get(0).getTimezoneName();
}, DataTypes.StringType);
spark.udf().register("udfSid",udfSid);
spark.udf().register("udfTimezone",udfTimezone);
}
udf使用:
Dataset finalDs = joinedDS.selectExpr("*", "udfSid(company_id,country_code,seller_id) as sid", "udfTimezone(company_id,country_code,seller_id) as timezone_name");
50,sparksql dsl为select准备字段
private static Seq columns(Dataset oldDataSet, Dataset newDS) {
StructField[] fields = newDS.schema().fields();
List columns = new ArrayList<>();
for (StructField field : fields) {
String name = field.name();
if (Constant.EVENT_GROUP_ID.equals(name) || Constant.EVENT_TYPE.equals(name) || Constant.COMPANY_ID.equals(name)) {
Column column = functions.coalesce(newDS.col(name), oldDataSet.col(name)).as(name);
columns.add(column);
} else if (Constant.POSTED_DATE.equals(name) || Constant.POSTED_DATE_LOCALE.equals(name)){
columns.add(functions.to_timestamp(functions.regexp_replace(newDS.col(name),"T"," "),"yyyy-MM-dd HH:mm:ss").as(name));
}
else if (Constant.QUANTITY.equals(name)){
columns.add(functions.coalesce(newDS.col(name),functions.lit(0)).cast("int").as(name));
} else {
columns.add(newDS.col(name));
}
}
return JavaConverters.asScalaIteratorConverter(columns.listIterator()).asScala().toSeq();
}
51,spark估计数据集大小
val plan = df.queryExecution.logical
val estimated: BigInt = spark
.sessionState
.executePlan(plan)
.optimizedPlan
.stats
.sizeInBytes
52,spark指定hdfs
53,spark sql 任意格式日期字符串格式转换
DATE_FORMAT(CAST(UNIX_TIMESTAMP('09/2021', 'MM/yyyy') AS TIMESTAMP), 'yyyy-MM') as pricing_month
54,spark Row动态增加字段
// 打印schema
println(row.schema)
// 得到Row中的数据并往其中添加我们要新增的字段值
val buffer = Row.unapplySeq(row).get.map(_.asInstanceOf[String]).toBuffer
buffer.append("男") //增加一个性别
buffer.append("北京") //增肌一个地址
// 获取原来row中的schema,并在原来Row中的Schema上增加我们要增加的字段名以及类型.
val schema: StructType = row.schema
.add("gender", StringType)
.add("address", StringType)
// 使用Row的子类GenericRowWithSchema创建新的Row
val newRow: Row = new GenericRowWithSchema(buffer.toArray, schema)
// 使用新的Row替换成原来的Row
newRow
55 ,spark版本查看
spark-shell --version
56,spark with hive
方式一: SparkSession + Hive Metastore
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val hiveHost: String = _
// 创建SparkSession实例
val spark = SparkSession.builder()
.config("hive.metastore.uris", s"thrift://hiveHost:9083")
.enableHiveSupport()
.getOrCreate()
// 读取Hive表,创建DataFrame
val df: DataFrame = spark.sql(“select * from salaries”)
df.show
方式二: spark-sql CLI + Hive Metastore
方式三: Beeline + Spark Thrift Server
57,spark-sql和spark with hive的区别
spark-sql CLI 的集成方式多了一层限制,那就是在部署上,spark-sql CLI 与 Hive Metastore 必须安装在同一个计算节点。换句话说,spark-sql CLI 只能在本地访问 Hive Metastore,而没有办法通过远程的方式来做到这一点。
58 spark sql切割字符串,一列变多列
.select(split(col("value"),",").as("splitCol"))
.select(
col("splitcol").getItem(0).cast(IntegerType).as("id"),
col("splitcol").getItem(1).as("name"))
.createTempView("tmp")
总结
1,如何理解driver?
参考文献
2,spark名词
standalone模式下集群节点名称:master、worker
on yarn模式下:driver、AM、RM、executor
3,数据尽量本地化,本地计算、本地存储。
// =====================================================分区设置为4
val sogouRDD: RDD[String] = context.textFile("data/input/SogouQ.sample",4)
case class SoGouRecord(ts:String, userId:String,key:String, resultRank:String,clickRank:String,url:String)
val soGouRecordRDD: RDD[SoGouRecord] = sogouRDD.mapPartitions(it => {
it.filter(item => StringUtils.isNotBlank(item) && item.split("\\s+").length == 6)
.map(item => {
val columns: Array[String] = item.split("\\s+")
columns(2) = columns(2).replaceAll("\\[|\\]","")
SoGouRecord(columns(0), columns(1), columns(2), columns(3), columns(4), columns(5))
})
})
val keyCount: RDD[(String, Int)] =
soGouRecordRDD.map(record => record.userId + record.key -> 1)
.reduceByKey(_ + _)
.sortBy(_._2,false)
keyCount.take(3).foreach(println)
val value: RDD[(String, Int)] = soGouRecordRDD
.map(record => record.userId -> 1)
.reduceByKey(_ + _)
println(value.partitioner)
val userCount: RDD[(String, Int)] = value
.sortBy(_._2,false)
//========================结果保存到hdfs
userCount.saveAsTextFile("hdfs://node1:8020/spark/output2")
结果保存在hdfs上,有4个小文件。

4,spark容错总结
1,rdd容错:先cache后checkpoint,是在rdd维度上checkpoint
重启之后从checkpoint过的rdd恢复数据和计算
2,spark sql DataFrame容错:和rdd容错一致
3,spark streaming容错:有状态算子+SparkContext设置检查点路径
4,structured streaming容错:在输出DataStreamWriter设置checkpoint路径
.option("checkpointLocation","data/output/cks")
5,spark与mysql
1,rdd连接mysql
读:
val personsFromMysql = new JdbcRDD[Tuple2[Int,String]](
sc,
() => {
val url = "jdbc:mysql://192.168.88.163:3306/spark?characterEncoding=UTF-8"
DriverManager.getConnection(url, "root", "123456")
},
"select id,name from person where id >= ? and id <= ?",
19,
30,
4,//numPartitions=3
res => (res.getInt(1), res.getString(2))
)
写:
persons.foreachPartition(it=>{
val url = "jdbc:mysql://192.168.88.163:3306/spark?characterEncoding=UTF-8"
val connection: Connection = DriverManager.getConnection(url, "root", "123456")
val statement: PreparedStatement = connection.prepareStatement("insert into person(id,name) value(?,?)")
it.foreach(p=>{
statement.setInt(1,p._1)
statement.setString(2,p._2)
statement.addBatch();
})
statement.executeBatch()
statement.close()
connection.close()
})
2,spark sql连接mysql
val frame: DataFrame = spark.read
.jdbc(
"jdbc:mysql://192.168.88.163:3306/spark?characterEncoding=UTF-8",
"person",
"id",
19,
30,
3, //numPartitions=3
pro
)
frame.write.jdbc
3,spark streaming连接mysql
输入不能是mysql,输出转化为rdd
keyValues.foreachRDD(rdd=>{
val conn = DriverManager.getConnection("jdbc:mysql://node1:3306/spark?characterEncoding=UTF-8","root","root")
val sql:String = "REPLACE INTO `person` (`id`, `name`) VALUES (?, ?);"
val ps: PreparedStatement = conn.prepareStatement(sql)
rdd.foreachPartition(it=>{
it.foreach(item=>{
ps.setInt(1, item._2)
ps.setString(2, item._1)
ps.addBatch()
})
})
ps.executeBatch()
ps.close()
conn.close()
// 存储到hdfs文件中
rdd.saveAsTextFile("hdfs://node1:8020/spark/tmp/dstream")
})
4,structured streaming连接mysql
数据源不能是mysql
输出通过foreach转化为DataSet连接mysql
cntDF.writeStream
.outputMode("complete")
.foreachBatch((ds,idx)=>{
ds.write
.mode("overwrite")
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url","jdbc:mysql://node3:3306/spark?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("user","root")
.option("password","123456")
.option("dbtable","person")
.save()
})
.start()
.awaitTermination()
6,spark为什么不搞流,要搞微批
这不是技术问题,是历史问题,spark的引擎是基于RDD的,最初他就是一个离线计算引擎,后来实时计算的需求越来越多,才逐渐开始开发流处理能力,spark都是基于RDD进行封装和优化,RDD本质是批处理引擎,所以spark只能做微批处理、近实时处理。
7,job提交命令
- yarn master模式
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class cn.hello.WordCount \
hdfs://node1:8020/spark/apps/wc.jar \
hdfs://node1:8020/wordcount/input/words.txt hdfs://node1:8020/wordcount/output
- yarn client模式
spark2-submit \ # 第1行
--class com.google.datalake.TestMain \ #第2行
--master yarn \ # 第3行
--deploy-mode client \ # 第4行
--driver-memory 3g \ # 第5行
--executor-memory 2g \ # 第6行
--total-executor-cores 12 \ # 第7行
--jars /home/jars/test-dep-1.0.0.jar,/home/jars/test-dep2-1.0.0.jar,/home/jars/test-dep3-1.0.0.jar \ # 第8行
/home/release/jars/test-sql.jar \ # 第9行
para1 \ # 第10行
para2 \ # 第11行
"test sql" \ # 第12行
parax # 第13行
示例分析:
- 第1行:指定该脚本是一个spark submit脚本(spark老版本是spark-submit,新版本spark2.x是spark2-submit);
- 第2行:指定main类的路径;
- 第3行:指定master(使用第三方yarn作为spark集群的master);
- 第4行:指定deploy-mode(应用模式,driver进程运行在spark集群之外的机器,从集群角度来看该机器就像是一个client);
- 第5行:分配给driver的内存为3g,也可用m(兆)作为单位;
- 第6行:分配给单个executor进程的内存为2g,也可用m(兆)作为单位;
- 第7行:分配的所有executor核数(executor进程数最大值);
- 第8行:运行该spark application所需要额外添加的依赖jar,各依赖之间用逗号分隔;
- 第9行:被提交给spark集群执行的application jar;
- 第10~13行:传递给main方法的参数,按照添加顺序依次传入,如果某个参数含有空格则需要使用双引号将该参数扩起来;
PS:第9行是告诉第2行的入口类所在的jar包,是第一个非KV形式的参数,这个参数之前的参数全部是KV形式的,这个参数之后的参数都是单值,会被组合为一个数组传递给main函数
- standalone模式
./bin/spark-submit
–class com.spark.Test.WordCount
–master spark://node1:7077
–executor-memory 4G
–total-executor-cores 6
/home/hadoop/data/jar-test/sql-1.0-yarnCluster.jar
- 完整实例
source /test1/test2/test.sh
source $localroot/scripts/$config
appPid=0
start_process(){
spark-submit --master yarn-cluster \
--name apple.banana\
--principal $principal \
--keytab $keytab \
--num-executors 4 \
--executor-cores 2 \
--executor-memory 8G \
--driver-memory 8G \
--conf spark.locality.wait=10 \
--conf spark.kryoserializer.buffer.max=500MB \
--conf spark.serializer="org.apache.spark.serializer.KryoSerializer" \
--conf spark.streaming.backpressure.enabled=true \
--conf spark.task.maxFailures=8 \
--conf spark.streaming.kafka.maxRatePerPartition=1000 \
--conf spark.driver.maxResultSize=5g \
--conf spark.driver.extraClassPath=$localroot/config \
--conf spark.executor.userClassPathFirst=true \
--conf spark.yarn.executor.memoryOverhead=4g \
--conf spark.executor.extraJavaOptions="test" \
--conf spark.yarn.cluster.driver.extraJavaOptions="test" \
--files $localroot/config/test.properties,\
$localroot/config/test1.txt,\
$localroot/config/test2.txt,\
$localroot/config/test3.txt \
--class com.peanut.test \
--jars $SPARK_HOME/jars/streamingClient010/kafka_2.10-0.10.0.0.jar,\
$SPARK_HOME/jars/streamingClient010/kafka-clients-0.10.0.0.jar,\
$SPARK_HOME/jars/streamingClient010/spark-streaming-kafka-0-10_2.11-2.1.0.jar,\
$localroot/lib/test1.jar,\
$localroot/lib/test2.jar,\
$localroot/lib/test3.jar \
$jarpath \
$args1 \
$args2 \
$args3 &
appPid=$!
}
start_process
echo "pid is"
echo $appPid
exit`
8,解决数据倾斜
spark数据倾斜
9,cache和checkpoint
cache是为了提高计算性能,把会重复使用的rdd缓存,提升计算性能。
checkpoint是为了容错,对代价昂贵的rdd进行checkpoint,异常恢复后就直接从checkpoint处恢复,无需从头计算。
cache不会截断DAG,checkpoint会截断DAG.
10,如何判断代码在driver中执行还是在executor执行
针对RDD本身的操作在driver,本质上为了创建DAG,如foreachRDD,transform;
涉及到对数据的计算则是在executor
11,预估数据集大小
val df: DataFrame = _
df.cache.count
val plan = df.queryExecution.logical
val estimated: BigInt = spark
.sessionState
.executePlan(plan)
.optimizedPlan
.stats
.sizeInBytes
12,按顺序写或是按名称写
package com.asinking.ch.ods;
import com.asinking.utils.ConfigUtil;
import com.asinking.utils.SparkUtils;
import org.apache.spark.rdd.RDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.StructType;
import scala.collection.JavaConverters;
import scala.collection.Seq;
import scala.reflect.ClassTag;
import javax.security.auth.login.Configuration;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class WriteMysqlTest {
public static void main(String[] args) throws SQLException {
Connection connection = DriverManager.getConnection(ConfigUtil.mysqlUrl(), ConfigUtil.mysqlUser(), ConfigUtil.mysqlPwd());
PreparedStatement preparedStatement = connection.prepareStatement("insert teacher(id,name,subject) values (?,?,?)");
preparedStatement.setLong(1,6);
preparedStatement.setString(2,"zhangxxxx666");
preparedStatement.setString(3,"mmmmmmath666");
preparedStatement.execute();
preparedStatement.clearParameters();
preparedStatement.setLong(1,7);
preparedStatement.setString(2,"zhangxxxx777");
preparedStatement.setString(3,"mmmmmmath777");
preparedStatement.execute();
preparedStatement.close();
}
public static void main2(String[] args) {
SparkSession spark = SparkUtils.sparkSession(SparkUtils.sparkConf("mysqltest"));
List<Teacher> teachers = new ArrayList<>();
Teacher teacher = new Teacher();
teacher.id = 1;
teacher.name = "zhangsan";
teacher.subject = "match";
teachers.add(teacher);
Seq<Teacher> tmpSeq = JavaConverters.asScalaIteratorConverter(teachers.iterator()).asScala().toSeq();
ClassTag tag = scala.reflect.ClassTag$.MODULE$.apply(Teacher.class);
RDD<Teacher> rdd = spark.sparkContext().makeRDD(tmpSeq, 10, tag);
Dataset<Row> dataFrame = spark.createDataFrame(rdd, Teacher.class);
dataFrame.printSchema();
dataFrame.show();
dataFrame.registerTempTable("tmp");
Dataset<Row> sql = spark.sql("select 'eng1111' as subject, 'zhangsi555' as name, 2 as id from tmp");
sql.write().format("jdbc")
.mode("append")
.option("url", ConfigUtil.mysqlUrl())
.option("user",ConfigUtil.mysqlUser())
.option("password",ConfigUtil.mysqlPwd())
.option("dbtable","teacher")
.save();
}
public static class Teacher{
private int id;
private String name;
private String subject;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
}
}
13,关于任务调度的几个小问题
13.1 如果有1T数据,单机运行需要30分钟,但是使用Saprk计算需要两个小时(4node),为什么?
1)、发生了计算倾斜。大量数据给少量的task计算。少量数据却分配了大量的task。
2)、开启了推测执行机制。
3)、分片太多,shuffle太多,调度时间长,网络数据传输时间长,文件读写时间长。
13.2、对于ETL(数据清洗流程)类型的数据,开启推测执行、重试机制,对于最终的执行结果会不会有影响?
有影响,最终数据库中会有重复数据。
解决方案:
1)、关闭各种推测、重试机制。
2)、设置一张事务表。
14,joinType
joinType可以是”inner”、“left”、“right”、“full”分别对应inner join, left join, right join, full join,默认值是”inner”,代表内连接
15,同一个application的job的并行还是串行
同一个线程的多个job是串行,同一个job的不同stage是串行
不同线程的多个job在资源不足的情况下是串行,在资源充足的情况下是并行
https://blog.csdn.net/zwgdft/article/details/88349295
16,spark的数据源
16.1, sc.paralize()
16.2, 文件(csv/txt/parquet)
16.3,分布式文件系统(hdfs、s3、cos)
16.4,数据库(mysql、oracle、clickhouse、kudu、es、hbase)
16.7,消息引擎(kafka)
17,在原有DF上增加字段的两种方法及其比较-java版本
第一种方法:
1,将DS转换为RDD,使用RDD的map,将Row转换为Entity
RDD rdd = joinedDS.rdd().map(new MyMapFunction(sidInfoMap), scala.reflect.ClassTag$.MODULE$.apply(OdsSpFinanceEventsEntity.class));
2,将新生成的RDD转换为DS
Dataset newWithSidDS = spark.createDataFrame(rdd, OdsSpFinanceEventsEntity.class);
这种方法代码多,且一旦对应的数据库表字段发生变化,entity类也要随之变化。
第二种方法:
使用UDF:
1,定义udf
private static void registerUdf(SparkSession spark, Map> sidInfoMap) {
UserDefinedFunction udfSid = functions.udf((UDF3) (companyId, countryCode, sellerId) -> {
List confEntities = sidInfoMap.get(ClickHouseUtil.composeKey4Sid(companyId, countryCode, sellerId));
if (confEntities == null || confEntities.isEmpty()) {
return "0";
}
return confEntities.get(0).getSid();
}, DataTypes.StringType);
UserDefinedFunction udfTimezone = functions.udf((UDF3) (companyId, countryCode, sellerId) -> {
List confEntities = sidInfoMap.get(ClickHouseUtil.composeKey4Sid(companyId, countryCode, sellerId));
if (confEntities == null || confEntities.isEmpty()) {
return null;
}
return confEntities.get(0).getTimezoneName();
}, DataTypes.StringType);
spark.udf().register("udfSid",udfSid);
spark.udf().register("udfTimezone",udfTimezone);
}
2,使用udf
Dataset finalDs = joinedDS.selectExpr("*", "udfSid(company_id,country_code,seller_id) as sid", "udfTimezone(company_id,country_code,seller_id) as timezone_name");
spark ui
1, spark读取文件是生成job
Listing leaf files and directories for 1847 paths:
cosn://akd-flink-test-1254213275/sp/ods/ods_sp_service_fee_event/90128259979419648/impB6jVXNI1tDP4an_ax7e0NjCjcVxtSN2Ckn8CZank/.hoodie_partition_metadata, ...
InMemoryFileIndex at HoodieSparkUtils.scala:113
文件数大于32时会生成job去查询文件是否存在,避免driver压力过大。
参考