x265编码参数
介绍
- x265是符合 HEVC 编码标准的开源编码器;
- 可执行文件下–fullhelp 可查看全部编码参数及其解释:x265 --fullhelp。
- git仓库:https://bitbucket.org/multicoreware/x265_git.git
- x265_param_default(x265_param* param)函数内全部参数的赋值和使用;
参数详细解析
/* ----Applying default values to all elements in the param structure 将默认值应用于参数结构中的所有元素----*/
-
cpuid
x265_param_default() will auto-detect this cpu capability bitmap. it is recommended to not change this value unless you know the cpu detection is somehow flawed on your target hardware. The asm function tables are process global, the first encoder configures them for all encoders.//不推荐改变该值,可实现自动检测 cpu 能力位图param->cpuid = X265_NS::cpu_detect(false);
命令行:cpuid
-
bEnableWavefront
Enable wavefront parallel processing, greatly increases parallelism for less than 1% compression efficiency loss. Requires a thread pool, enabled by default.//wpp 技术,提高并行性,压缩效率损失小于 1%,需要线程池,默认开启波前并行技术,hevc 的并行处理技术之一;
param->bEnableWavefront = 1;
命令行:wpp
-
frameNumThreads
Number of concurrently encoded frames between 1 and X265_MAX_FRAME_THREADS or 0 for auto-detection. By default x265 will use a number of frame threads empirically determined to be optimal for your CPU core count, between 2 and 6. Using more than one frame thread causes motion search in the down direction to be clamped but otherwise encode behavior is unaffected. With CQP rate control the output bitstream is deterministic for all values of frameNumThreads greater than 1. All other forms of rate-control can be negatively impacted by increases to the number of frame threads because the extra concurrency adds uncertainty to the bitrate estimations. Frame parallelism is generally limited by the the is generally limited by the the number of CU rows When thread pools are used, each frame thread is assigned to a single pool and the frame thread itself is given the node affinity of its pool. But when no thread pools are used no node affinity is assigned.//在 1 和X265_MAX_FRAME_THREADS之间并行编码的帧数,自动检测时设置为0,一般选择 2-6 比较合适,CQP 时比特流不受帧线程数影响,其他码率控制受到一定的负面影响param->frameNumThreads = 0; //默认
tune:zerolatency模式下param->frameNumThreads = 1;
命令行:frame-threads
-
logLevel
The level of logging detail emitted by the encoder. X265_LOG_NONE to X265_LOG_FULL, default is X265_LOG_INFO//编码器发出的详细日志信息级别,默认 INFO 级别param->logLevel = X265_LOG_INFO;//默认
命令行:log-level/log
-
csvLogLevel
Level of csv logging. 0 is summary, 1 is frame level logging, 2 is frame level logging with performance statistics//cvs 日志级别,0 是摘要,1 是帧级别,2 是带有性能统计的帧级别param->csvLogLevel = 0;
命令行:csv-log-level
-
csvfn
filename of CSV log. If csvLogLevel is non-zero, the encoder will emit per-slice statistics to this log file in encode order. Otherwise the encoder will emit per-stream statistics into the log file when x265_encoder_log is called (presumably at the end of the encode)//cvs 日志文件名,依靠csvLogLevel的值或x265_encoder_log函数是否被调用param->csvfn = NULL;
命令行 :csv
-
lambdaFileName
specify a text file which contains MAX_MAX_QP + 1 floating point values to be copied into x265_lambda_tab and a second set of MAX_MAX_QP + 1 floating point values for x265_lambda2_tab. All values are separated by comma, space or newline. Text after a hash (#) is ignored. The lambda tables are process-global, so these new lambda values will affect all encoders in the same process.//指定文本文件,主要关于lambda的存储,属于码率控制模块的参数param->rc.lambdaFileName = NUL;
命令行:lambda-file
-
bLogCuStats(已弃用)
Enable analysis and logging distribution of CUs. Now deprecated.//CU 的分析和日志分发,已经弃用param->bLogCuStats = 0;
命令行:cu-stats
-
decodedPictureHashSEI
Enable the generation of SEI messages for each encoded frame containing the hashes of the three reconstructed picture planes. Most decoders will validate those hashes against the reconstructed images it generates and report any mismatches. This is essentially a debugging feature. Hash types are MD5(1), CRC(2), Checksum(3). Default is 0, none//产生包含哈希的SEI 信息,解码器会根据这些哈希验证重建图并报告错误,本质是 debug 特点,哈希类型有: MD5(1)、CRC(2)、Chechsum(3),默认是0,不产生哈希SEIparam->decodedPictureHashSEI = 0;
命令行:hash
/* ------------------Quality Measurement Metrics 质量评价度量------------------------*/
-
bEnablePsnr
Enable the measurement and reporting of PSNR. Default is enabled //计算并打印 PSNR,默认是关闭(代码备注写打开,写错了)param->bEnablePsnr = 0;
命令行:psnr
-
bEnableSsim
Enable the measurement and reporting of SSIM. Default is disabled //计算并打印 SSIM,默认关闭param->bEnableSsim = 0;
命令行:ssim
/* ------------Source specifications 源规范--------------------------*/
-
internalBitDepth
Internal encoder bit depth. If x265 was compiled to use 8bit pixels (HIGH_BIT_DEPTH=0), this field must be 8, else this field must be 10. Future builds may support 12bit pixels. //内部编码器位深度,如果 x265 被编译使用 8bit,该字段必须为 8,否则为 10,未来会支持 12bit 像素param->internalBitDepth = X265_DEPTH;
命令行:bitdepth
-
sourceBitDepth
Input sequence bit depth. It can be either 8bit, 10bit or 12bit.//输入序列位深度,可以是 8bit、10bit、12bitparam->sourceBitDepth = 8;
-
internalCsp
Color space of internal pictures, must match color space of input pictures. //内部图像的颜色空间,必须匹配输入图像的颜色空间param->internalCsp = X265_CSP_I420;
命令行:input-csp
-
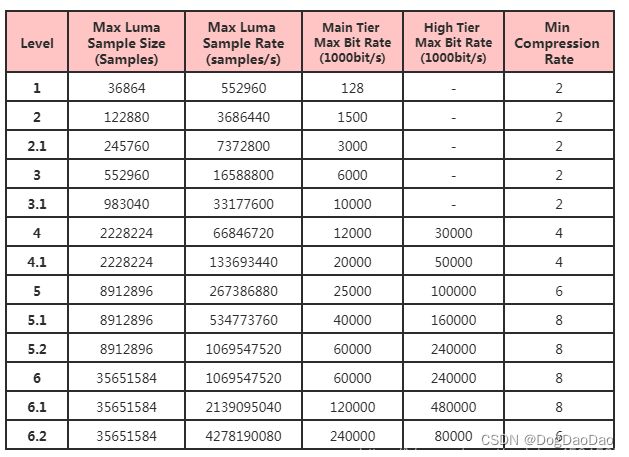
levelIdc(水平 level)
Minimum decoder requirement level. Defaults to 0, which implies auto-detection by the encoder. If specified, the encoder will attempt to bring the encode specifications within that specified level. If the encoder is unable to reach the level it issues a warning and emits the actual decoder requirement. If the requested requirement level is higher than the actual level, the actual requirement level is signaled. The value is an specified as an integer with the level times 10, for example level “5.1” is specified as 51, and level “5.0” is specified as 50.//最小解码器要求级别,默认 0,表示由编码器自动检测;该值以整数形式指定水平(Level) 指出了一些对解码端负载和内存占用影响较大的关键参数的约束,这些参数主要包括有:采样频率、分辨率、码率的最大值,压缩率的最小值、解码图形缓冲区(DPB)的容量、编码图像缓冲区(CPB)的容量;水平中还约束了每帧中垂直和水平方向的tile的最大数量,以及每秒最大的tile数量。
HEVC共有13个水平:1, 2, 2.1, 3,3.1, 4, 4.1, 5, 5.1, 5.2, 6,6.1, 6.2。
param->levelIdc = 0; //Auto-detect level
命令行:level-idc
-
uhdBluray
Enable UHD Blu-ray compatibility support. If specified, the encoder will attempt to modify/set the encode specifications. If the encoder is unable to do so, this option will be turned OFF.//UHD 蓝光兼容支持,如果指定,编码器将试图修改编码规范,如果编码器不支持,则该选择被设置成 OFFparam->uhdBluray = 0;
命令行:uhd-bd
-
bHighTier(等级 tier)
if levelIdc is specified (non-zero) this flag will differentiate between Main (0) and High (1) tier. Default is Main tier (0)//如果 levelldc 被指定,即非零,这个标志将在Main(0) 和High(1) 之间区分,默认是 0,【实际代码里默认是 1】HEVC 提出的新技术,规定每个 level(水平)的码率高低,对于同一水平,按照最大码率和缓存容量的不同,HEVC设置了两个档等级,分别为高等级High tier和主等级Main tier。
param->bHighTier = 1; //Allow high tier by default
命令行:high-tier
-
interlaceMode
Interlace type of source pictures. 0 - progressive pictures (default). 1 - top field first, 2 - bottom field first. HEVC encodes interlaced content as fields, they must be provided to the encoder in the correct temporal order.//源图像的交错类型,0-逐行/渐进图像(默认),1-顶场优先,2-底场优先,hevc 编码交错内容作为场,必须提供给编码器正确的时间顺序图像的交错类型,主要分为逐行扫描 progressive和隔行扫描interlaced两种方式,主要还是用逐行扫描方式。
param->interlaceMode = 0;
命令行:interlace
-
bField
Enable field coding//场编码param->bField = 0;
命令行:field
-
bAnnexB
Flag indicating whether the encoder should generate start codes (Annex B format) or length (file format) before NAL units. Default true, Annex B. Muxers should set this to the correct value//标志指出编码器是否在每个 NAL 单元前产生起始码(附件 B 格式)或长度(文件格式),默认 true,采用 Annex B 格式分割 NAL 主要有两种方式 AnnexB 和 AVCC;AnnexB 使用 start code 分割 NAL(start code 未三字节或四字节,0x000001 或 0x00000001),SPS、PPS 按照流的方式写在头部;AVCC 使用 NALU (固定字节,通常为4 字节)长度分隔NAL,在头部包含 extradata (或sequence header)的结构体,extradata 包含分割的字节数、SPS 和 PPS。
param->bAnnexB = 1;
命令行:annexb
-
bRepeatHeaders
Flag indicating whether VPS, SPS and PPS headers should be output with each keyframe. Default false//标志指出在每个关键帧前都附带 VPS、SPS、PPS 头,默认 falseparam->bRepeatHeaders = 0;
命令行:repeat-headers
-
bEnableAccessUnitDelimiters
Flag indicating whether the encoder should emit an Access Unit Delimiter NAL at the start of every access unit. Default false//标志指出编码器在每个访问单元是否发出访问单元分隔符,默认 falseAU 分隔符,AU全称Access Unit,它是一个或者多个NALU的集合,代表了一个完整的帧, 在 HEVC 中NALU type = 9。
param->bEnableAccessUnitDelimiters = 0;
命令行:aud
-
bEnableEndOfBitstream
Flag indicating whether the encoder should emit an End of Bitstream NAL at the end of bitstream. Default false//标志指出编码器是否在流结束发出流结束 NAL,默认 falseparam->bEnableEndOfBitstream = 0;
命令行:eob
-
bEnableEndOfSequence
Flag indicating whether the encoder should emit an End of Sequence NAL at the end of every Coded Video Sequence. Default false //标志指出编码器是否在每个被编码视频序列结束发出序列结束 NAL,默认 falseparam->bEnableEndOfSequence = 0;
命令行:eos
-
bEmitHRDSEI
Enables the buffering period SEI and picture timing SEI to signal the HRD parameters. Default is disabled//缓冲周期 SEI 和图像定时 SEI通知 HRD 参数,默认 disabledHRD 即Hypothetical Reference Decoder,假想参考解码器,HRD是视频编码标准的一部分。码率控制生成的码流须符合HRD的要求。HDR有三个关键的参数:R、B、F。R是信道传输速率,B是解码缓冲区的容量,F是初始解码缓冲区充盈度(initial decoder buffer fullness)。F在不同的文献中有两种不同的含义。例如,在高引论文“A Generalized Hypothetical Reference Decoder for H.264/AVC”中,F是初始缓冲区占用量(occupancy),单位是比特,取值范围是[0, B],且编解码缓冲区在任意时刻互补(和为B),包括初始编解码缓冲区:Fe+Fd=B。而在提案JVT-GO12中,F是初始缓冲区占用量占整个缓冲区容量B的比例,取值范围是[0, 1]。当然,两种含义是等价的;但如果从单词fullness的语义上来说,第二种含义更合理。
鉴于实际应用中的重要性,从 H.264/AVC 开始,基于漏桶缓冲器的视频解码器模型就被定义在了 MPEG 系列的国际视频编码标准中,即 HRD。这些标准中的 HRD 一致性定义有两种类型:Type I HRD 的输入码流只考虑视频编码层单元 VCL (Video Coding Layer) units (即包含实际编码视频帧的数据单元) 和填充单元 filler units 这两类网络抽象层单元 NAL (Network Abstraction Layer) units 的编码数据;而 Type II HRD 则会考虑所有类型的网络抽象层单元 NAL units 数据, 比如除 VCL 和 filler units 之外的 SPS (Sequence Parameter Set),PPS (Picture Parameter Set), SEI (Supplemental Enhancement Information) 消息等所有类型的数据单元。同时,HRD 定义了 CBR 和 VBR 两种模式。CBR HRD 由平均码率、缓冲器大小,和初始移除延时(initial removal delay)三个参数定义。VBR HRD 也是由类似的三个参数定义,只是其中的平均码率换成了最大输入码率(即输入码率是可变的,可以是零到最大码率之间的任何值)。
跟 vbv buffer 其实是相似功能,作用是平滑编码器的输出码流,防止码流抖动过大,通常是和码率控制模块结合使用。
param->bEmitHRDSEI = 0;
命令行:hrd
-
bEmitInfoSEI
Enables the emission of a user data SEI with the stream headers which describes the encoder version, build info, and parameters. This is very helpful for debugging, but may interfere with regression tests. Default enabled//能发出数据流头里带有描述编码器版本、构建信息和参数的用户数据 SEI,对调试很有帮助,但可能干扰回归测试,默认 enabledparam->bEmitInfoSEI = 1;
命令行:info
-
bEmitHDRSEI(已弃用)
Enables the emitting of HDR SEI packets which contains HDR-specific params. Auto-enabled when max-cll, max-fall, or mastering display info is specified. Default is disabled. Now deprecated.//使发出包含 HDR 特别参数的HDR SEI 包;默认 disabled,现在已经废弃param->bEmitHDRSEI = 0; /Deprecated/
-
bEmitHDR10SEI
Enables the emitting of HDR10 SEI packets which contains HDR10-specific params. Auto-enabled when max-cll, max-fall, or mastering display info is specified. Default is disabled //使发出包含 HDR10 特别参数的 HDR10 包,默认 disabledparam->bEmitHDR10SEI = 0;
命令行:hdr/DEPRECATED/或hdr10
-
bEmitIDRRecoverySEI
Enables the emission of a Recovery Point SEI with the stream headers at each IDR frame describing poc of the recovery point, exact matching flag and broken link flag. Default is disabled.//使发出恢复点 SEI,在每个 IDR 帧描述恢复点的 poc,精确匹配标志,断开链接标志,默认 disabledparam->bEmitIDRRecoverySEI = 0;
命令行:idr-recovery-sei
*--------CU definitions 编码单元CU 定义-------------- */
-
maxCUSize
Maximum CU width and height in pixels. The size must be 64, 32, or 16. The higher the size, the more efficiently x265 can encode areas of low complexity, greatly improving compression efficiency at large resolutions. The smaller the size, the more effective wavefront and frame parallelism will become because of the increase in rows. default 64 All encoders within the same process must use the same maxCUSize, until all encoders are closed and x265_cleanup() is called to reset the value.//以像素为单位的最大 CU 宽度和高度,大小为 64、32、16。尺寸越大,低复杂度区域的压缩效率越高。默认 64param->maxCUSize = 64;
preset=ultrafast 时32,preset=superfast 时32
命令行:ctu
-
minCUSize
Minimum CU width and height in pixels. The size must be 64, 32, 16, or 8. Default 8. All encoders within the same process must use the same minCUSize.//以像素为单位的最小 CU 的宽和高,取值必须是 64、32、16、8,默认是 8,同一进程内所有编码器必须使用相同的 minCUSize。param->minCUSize = 8;
preset=ultrafast 是 16
命令行:min-cu-size
-
tuQTMaxInterDepth
The additional depth the residual quad-tree is allowed to recurse beyond the coding quad-tree, for inter coded blocks. This must be between 1 and 4. The higher the value the more efficiently the residual can be compressed by the DCT transforms, at the expense of much more compute//在编码四叉树之外允许残差四叉树的额外深度,对于帧间编码块,取值 1 到 4 之间,值越高,dct 变换对残差压缩效率更高,但需要更多的计算量,默认是 1。param->tuQTMaxInterDepth = 1;
preset=slower 时3,preset=veryslow 时3,preset=placebo 时4
命令行:tu-inter-depth
-
tuQTMaxIntraDepth
The additional depth the residual quad-tree is allowed to recurse beyond the coding quad-tree, for intra coded blocks. This must be between 1 and 4. The higher the value the more efficiently the residual can be compressed by the DCT transforms, at the expense of much more compute//在编码四叉树之外允许残差四叉树的额外深度,对于帧间编码块,取值 1 到 4 之间,值越高,dct 变换对残差压缩效率更高,但需要更多的计算量,默认是 1。param->tuQTMaxIntraDepth = 1;
preset=slower 时3,preset=veryslow 时3,preset=placebo 时4
命令行:tu-intra-depth
-
maxTUSize
Maximum TU width and height in pixels. The size must be 32, 16, 8 or 4. The larger the size the more efficiently the residual can be compressed by the DCT transforms, at the expense of more computation//以像素为单位的最大 TU 的宽和高,尺寸是 32、16、8、4,尺寸越大,残差被dct 变换压缩更有效率,但复杂度也越高,默认 32。param->maxTUSize = 32;
命令行:max-tu-size
/* ---------Coding Structure 编码结构------------ */
-
keyframeMin
Scene cuts closer together than this are coded as I, not IDR. //比这更接近的场景切换被编码成 I 帧,而不是 IDR 帧,默认 0 即自动检测说的再明白一点,如果编码当前帧的时候,通过某种方式(比如场景切换检测),确定它的类型是I帧,那么还需要再根据min-keyint这个值决定,要不要把它编成IDR帧,因为最后码流里面的两个IDR帧的间隔,不能小于min-keyint。
在 x264 中,如果我们在编码器参数配置时,没有特别指定i_min_keyint值的话(默认),编码器内部会取i_keyint_max/10和帧率fps的较小者。而且,最后i_min_keyint的取值会限制到[1,i_keyint_max/2+1]。
param->keyframeMin = 0;
命令行:min-keyint
-
keyframeMax
Maximum keyframe distance or intra period in number of frames. If 0 or 1, all frames are I frames. A negative value is casted to MAX_INT internally which effectively makes frame 0 the only I frame. Default is 250//最大关键帧距离,如果是 0 或 1,则所有帧都是 I 帧,负值被强制转换为 MAX_INT,默认 250.param->keyframeMax = 250;
命令行:keyint
-
gopLookahead
Number of frames for GOP boundary decision lookahead.If a scenecut frame is found within this from the gop boundary set by keyint, the GOP will be extented until such a point, otherwise the GOP will be terminated as set by keyint//GOP 边界决定 lookahead 的帧数,如果在 keyint 设置的 GOP 边界内找到一个场景帧,则 GOP 将被扩展到该点,否则根据 keyint 设置的范围终止,默认是 0param->gopLookahead = 0;
命令行:gop-lookahead
-
bOpenGOP
Enable open GOP - meaning I slices are not necessarily IDR and thus frames encoded after an I slice may reference frames encoded prior to the I frame which have remained in the decoded picture buffer. Open GOP generally has better compression efficiency and negligible encoder performance impact, but the use case may preclude it. Default true//开发式 GOP,I 帧之后的图像也可以参考 I 帧之前的帧,有更好的压缩性能,性能可忽略,默认 trueparam->bOpenGOP = 1;
命令行:open-gop
-
bframes
Maximum consecutive B frames that can be emitted by the lookahead. When b-adapt is 0 and keyframMax is greater than bframes, the lookahead emits a fixed pattern ofbframesB frames between each P. With b-adapt 1 the lookahead ignores the value of bframes for the most part. With b-adapt 2 the value of bframes determines the search (POC) distance performed in both directions, quadratically increasing the compute load of the lookahead. The higher the value, the more B frames the lookahead may possibly use consecutively, usually improving compression. Default is 3, maximum is 16//B 帧的最大个数,会搭配 b-adapt 参数一起使用,提高压缩,默认 3(代码默认是 4),最大 16B 帧会增加延迟,在 RTC 场景中一般不使用 B 帧。
param->bframes = 4;
preset=ultrafast时 3,superfast 时 3,slower 时8,veryslow 时 8,placebo 时 8
tune=zerolatency 时0,animation 时候 4 或 6
命令行:bframes
-
lookaheadDepth
The number of frames that must be queued in the lookahead before it may make slice decisions. Increasing this value directly increases the encode latency. The longer the queue the more optimally the lookahead may make slice decisions, particularly with b-adapt 2. When cu-tree is enabled, the length of the queue linearly increases the effectiveness of the cu-tree analysis. Default is 40 frames, maximum is 250 //lookahead 帧数,该值会增加编码延迟,特别是在 b-adapt 等于 2 的时候;当开启 cu-tree 时,lookahead 队列的长度线性地增加了 cu-tree 分析的有效性,默认是 40(代码里其实是 20),最大 250param->lookaheadDepth = 20;
preset=ultrafast时 5,superfast 时 10,veryfast、faster、fast 时15,slow 时25、slower、veryslow 时 40,placebo 时 60
tune=zerolatency 时0
命令行:rc-lookahead
-
bFrameAdaptive
Sets the operating mode of the lookahead. With b-adapt 0, the GOP structure is fixed based on the values of keyframeMax and bframes. With b-adapt 1 a light lookahead is used to chose B frame placement. With b-adapt 2 (trellis) a viterbi B path selection is performed //lookahead 的操作模式,b-adapt =0时,GOP 结构根据 keyframeMax 和 bframes 的值固定,b-adapt=1 时,轻微lookahead 被用来选择 B 帧位置,b-adapt=2 时,执行viterbi B 的路径选择,默认是 2param->bFrameAdaptive = X265_B_ADAPT_TRELLIS;
preset=ultrafast、superfast 、veryfast、faster、fast 时 0
tune=zerolatency 时0
命令行:b-adapt
-
bBPyramid
When enabled, the encoder will use the B frame in the middle of each mini-GOP larger than 2 B frames as a motion reference for the surrounding B frames. This improves compression efficiency for a small performance penalty. Referenced B frames are treated somewhere between a B and a P frame by rate control. Default is enabled.//启用时,编码器在超过两个 B 帧的 mini-gop 中间使用 B 帧作为周围 B 帧的运动参考,以很小的性能代价提升压缩效率,被参考的 B 帧将放在 B 帧和 P 帧之间通过码率控制,默认 enabledparam->bBPyramid = 1;
命令行:b-pyramid
-
scenecutThreshold
An arbitrary threshold which determines how aggressively the lookahead should detect scene cuts for cost based scenecut detection. The default (40) is recommended.//任意的阈值,决定了基于成本的场景切换检测中,场景检测的积极程度,建议使用默认值 40param->scenecutThreshold = 40; /* Magic number pulled in from x264 */
preset=ultrafast 时0
tune=zerolatency 时0
命令行:scenecut
-
bHistBasedSceneCut
Enables histogram based scenecut detection algorithm to detect scenecuts. Default disabled //基于直方图的场景切换检测,默认 disabledparam->bHistBasedSceneCut = 0;
tune=zerolatency 时0
命令行:hist-scenecut
-
lookaheadSlices
Use multiple worker threads to measure the estimated cost of each frame within the lookahead. When bFrameAdaptive is 2, most frame cost estimates will be performed in batch mode, many cost estimates at the same time, and lookaheadSlices is ignored for batched estimates. The effect on performance can be quite small. The higher this parameter, the less accurate the frame costs will be (since context is lost across slice boundaries) which will result in less accurate B-frame and scene-cut decisions. Default is 0 - disabled. 1 is the same as 0. Max 16//多个工作线程度量带有 lookahead 每帧的估计代价,和bFrameAdaptive搭配使用,该值越高,对帧代价估计越不准确,因为上下文在片边界上丢失了,导致B 帧和场景切换决策准确性降低,默认是 0-disabled(实际代码默认是 8),1 和 0 一样,最大 16param->lookaheadSlices = 8;
preset=slow 时 4,slower、veryslow、placebo 时0
命令行:lookahead-slices
-
lookaheadThreads
Use multiple worker threads dedicated to doing only lookahead instead of sharing the worker threads with Frame Encoders. A dedicated lookahead threadpool is created with the specified number of worker threads. This can range from 0 up to half the hardware threads available for encoding. Using too many threads for lookahead can starve resources for frame Encoder and can harm performance. Default is 0 - disabled//使用多线程仅在 lookahead,而不与帧编码共享工作线程,指定的 lookahead 线程池被创建在特定数量线程池,可以设置 0-一半的硬件线程可用编码,太多的该线程会耗尽编码器资源,损害性能,默认 0-disabledparam->lookaheadThreads = 0;
命令行:lookahead-threads
-
scenecutBias
This value represents the percentage difference between the inter cost and intra cost of a frame used in scenecut detection. Default 5.//该参数表示在场景切换检测中使用帧内代价和帧间代价的百分比差异,默认 5param->scenecutBias = 5.0;
命令行:scencut-bias
-
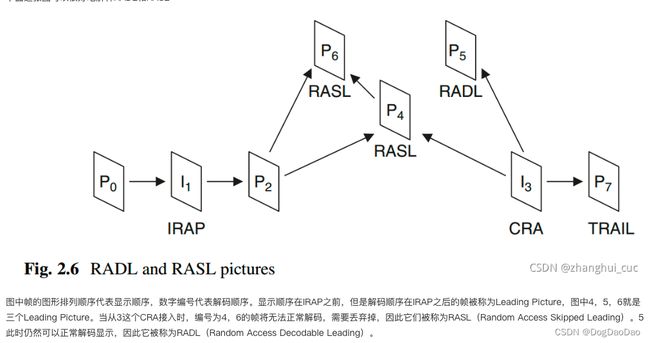
radl
Number of RADL pictures allowed in front of IDR//在 IDR 帧前面 RADL 图像的数量RADL 是随机接入可解码前置图像,
param->radl = 0;
命令行:radl
参考:https://cloud.tencent.com/developer/article/1952678
-
chunkStart
First frame of the chunk. Frames preceeding this in display order will be encoded, however, they will be discarded in the bitstream. Default 0 (disabled).//数据块的第一帧。在这个显示顺序之前的帧将被编码,但是,它们将在比特流中被丢弃。默认为0(禁用)。param->chunkStart = 0;
命令行:chunk-start
-
chunkEnd
Last frame of the chunk. Frames following this in display order will be used in taking lookahead decisions, but, they will not be encoded. Default 0 (disabled). //数据块的最后一帧,在显示顺序中遵循此顺序的帧将用于进行前瞻性决策,但是,它们不会被编码。默认为0(禁用)。param->chunkEnd = 0;
命令行:chunk-end
-
bEnableHRDConcatFlag
Set concantenation flag for the first keyframe in the HRD buffering period SEI. //为 HRD 缓冲周期 SEI 的第一个关键帧设置连接标志param->bEnableHRDConcatFlag = 0;
命令行: hrd-concat
-
bEnableFades
Detect fade-in regions. Enforces I-slice for the brightest point. Re-init RC history at that point in ABR mode. Default is disabled.//检测渐入区域,对最亮的点强制 I Slice,在 ABR 模式中重新初始化 RC 历史值,默认 disabledparam->bEnableFades = 0;
命令行:fades
-
bEnableSceneCutAwareQp
It reduces the bits spent on the inter-frames within the scenecutWindow before and / or after a scenecut by increasing their QP in ratecontrol pass2 algorithm without any deterioration in visual quality.0 - Disabled (default).1 - Forward masking.2 - Backward masking.3 - Bi-directional masking.//在 pass2 算法中增加QP 来减少场景切换之前或之后场景窗口内帧间花费的比特,不会导致视觉质量的任意恶化,默认0-disabled,1-前向屏蔽,2-反向掩蔽,3-双向屏蔽param->bEnableSceneCutAwareQp = 0;
命令行:scenecut-aware-qp
-
fwdMaxScenecutWindow
The duration(in milliseconds) for which there is a reduction in the bits spent on the inter-frames after a scenecut by increasing their QP, when bEnableSceneCutAwareQp is 1 or 3. Default is 500ms.//当bEnableSceneCutAwareQp为1或3时,通过增加帧间QP来减少场景切换之后花在帧间的比特数的持续时间(以毫秒为单位)。默认值是500ms(实际代码是 1200ms)param->fwdMaxScenecutWindow = 1200;
命令行:fwd-scenecut-window
-
bwdMaxScenecutWindow
The duration(in milliseconds) for which there is a reduction in the bits spent on the inter-frames before a scenecut by increasing their QP, when bEnableSceneCutAwareQp is 2 or 3. Default is 100ms//当bEnableSceneCutAwareQp为2或3时,通过增加帧间QP来减少场景切换之前花费在帧间的比特的持续时间(以毫秒为单位)。默认为100ms(实际代码是 600ms)param->bwdMaxScenecutWindow = 600;
命令行:bwd-scenecut-window
-
fwdScenecutWindow[6]/fwdRefQpDelta[6]/fwdNonRefQpDelta[6]/bwdScenecutWindow[6]/bwdRefQpDelta[6]/bwdNonRefQpDelta[6]
这些参数都是用来调节场景切换之前/之后通过调整 QP 来减少帧间比特数的持续时间相关参数
/* ---------------Intra Coding Tools 帧内编码工具----------------------- */
-
bEnableConstrainedIntra
Enable constrained intra prediction. This causes intra prediction to input samples that were inter predicted. For some use cases this is believed to me more robust to stream errors, but it has a compression penalty on P and (particularly) B slices. Defaults to disabled//启用受限制帧内预测,这将导致帧内预测输入采样被帧间预测,对于某些 case,对流错误而言,鲁棒性更高,但对P 和 B Slice 有压缩损失,默认 disabledparam->bEnableConstrainedIntra = 0;
命令行:constranined-intra、cip
-
bEnableStrongIntraSmoothing
Enable strong intra smoothing for 32x32 blocks where the reference samples are flat. It may or may not improve compression efficiency, depending on your source material. Defaults to disabled//对 32x32 块使用强帧内平滑,参考样本是平坦的,可能会也可能不会提高压缩效率,依赖原材料,默认 disabled(实际代码是1)param->bEnableStrongIntraSmoothing = 1;
preset= ultrafast、superfast、veryfast、faster、fast时1
命令行:strong-intra-smoothing
-
bEnableFastIntra
Use a faster search method to find the best intra mode. Default is 0 //使用快速搜索方法找到最佳帧内模式,默认是 0实现的算法就是跳过帧内 DCT 过程
param->bEnableFastIntra = 0;
preset=ultrafast、superfast、veryfast、faster、fast 时1
命令行:fast-intra
-
bEnableSplitRdSkip
Enable skipping split RD analysis when sum of split CU rdCost larger than none split CU rdCost for Intra CU //在帧内 CU 时,当分割 CU 的总 rd 代价大于不分割 CU 的 rd 代价时候,可以跳过分割 rd 分析param->bEnableSplitRdSkip = 0;
命令行:splitrd-skip
/* --------------Inter Coding tools 帧间编码工具---------------- */
-
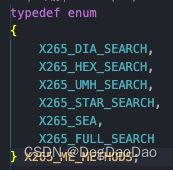
searchMethod
ME search method (DIA, HEX, UMH, STAR, SEA, FULL). The search patterns (methods) are sorted in increasing complexity, with diamond being the simplest and fastest and full being the slowest. DIA, HEX, UMH and SEA were adapted from x264 directly. STAR is an adaption of the HEVC reference encoder’s three step search, while full is a naive exhaustive search. The default is the star search, it has a good balance of performance and compression efficiency //ME 搜索方法(DIA、HEX、UMH、STAR、SEA、FULL),排序越来越复杂,其中 DIA、HEX、UMH、SEA 直接改编自 x264,默认是 star 搜索(实际代码里是 HEX 搜索),性能和压缩效率更好的平衡。param->searchMethod = X265_HEX_SEARCH;
preset=ultrafast 时X265_DIA_SEARCH,slow 、slower、veryslow、placebo时X265_STAR_SEARCH
命令行:me
-
subpelRefine
A value between 0 and X265_MAX_SUBPEL_LEVEL(最大是7) which adjusts the amount of effort performed during sub-pel refine. Default is 5 //介于 0-X265_MAX_SUBPEL_LEVEL的取值,用来调整亚像素细化的工作量,默认是 5(实际代码里默认是 2)param->subpelRefine = 2;
preset=ultrafast 时 0,superfast、veryfast 时1,slow 时3,slower、veryslow 时4,placebo 时5
命令行:subme
-
searchRange
The maximum distance from the motion prediction that the full pel motion search is allowed to progress before terminating. This value can have an effect on frame parallelism, as referenced frames must be at least this many rows of reconstructed pixels ahead of the referencee at all times. (When considering reference lag, the motion prediction must be ignored because it cannot be known ahead of time). Default is 60, which is the default max CU size (64) minus the luma HPEL half-filter length (4). If a smaller CU size is used, the search range should be similarly reduced//运动预测重整像素运动搜索在终止前的最大距离,该值可能会对帧并行产生影响,默认值是 60(实际代码是 57),最大 CU 尺寸(64)减去亮度半像素滤波长度(4),如果使用较小的 CU 尺寸,该值相应的减少param->searchRange = 57;
preset=placebo 时92
命令行:merange
-
maxNumMergeCand
The maximum number of merge candidates that are considered during inter analysis. This number (between 1 and 5) is signaled in the stream headers and determines the number of bits required to signal a merge so it can have significant trade-offs. The smaller this number the higher the performance but the less compression efficiency. Default is 3 //整个帧间分析过程中 merge 候选最大数量,取值1-5在数据流头里被给出信号,同时决定了发出 merge 信号的比特数,该值越小,性能越高,但压缩效率越低,默认 3param->maxNumMergeCand = 3;
preset=ultrafast、superfast、veryfast、faster、fast 时 2,slower时4,veryslow、palcebo 时5
命令行:max-merge
-
limitReferences
Limit the motion references used for each search based on the results of previous motion searches already performed for the same CU: If 0 all references are always searched. If X265_REF_LIMIT_CU all motion searches will restrict themselves to the references selected by the 2Nx2N search at the same depth. If X265_REF_LIMIT_DEPTH the 2Nx2N motion search will only use references that were selected by the best motion searches of the 4 split CUs at the next lower CU depth. The two flags may be combined//根据先前对相同CU 执行的运动搜索的结果,限制每次搜索的运动参考;0 表示所有参考都被搜索,X265_REF_LIMIT_CU(2)表示所有的运动搜索都被限制在参考相同的深度 2Nx2N 搜索;如果X265_REF_LIMIT_DEPTH(1),2Nx2N 运动搜索仅仅使用下一个较低深度的四叉树 CU 的最佳运动搜索作为参考,这两个标志可能被合并。param->limitReferences = 1;
preset=ultrafast、superfast时0,veryfast、faster、fast、slow时3,veryslow、placebo 时0
命令行:limit-refs
-
limitModes
Limit modes analyzed for each CU using cost metrics from the 4 sub-CUs//通过使用 4 个子 CU 的代价指标限定每个 CU 模式分析param->limitModes = 0;
preset=slow、slower时1,veryslow时0
命令行:limit-modes
-
bEnableWeightedPred
Enable weighted prediction in P slices. This enables weighting analysis in the lookahead, which influences slice decisions, and enables weighting analysis in the main encoder which allows P reference samples to have a weight function applied to them prior to using them for motion compensation. In video which has lighting changes, it can give a large improvement in compression efficiency. Default is enabled//加权预测 P 帧,在 lookahead 中加权分析会影响 片决定;在有光照变化的视频里,将极大的提升压缩效率,默认 enabled
param->bEnableWeightedPred = 1;
preset=ultrafast、superfast时0
tune=fastdecode 时0
命令行:weightp
-
bEnableWeightedBiPred
Enable weighted prediction in B slices. Default is disabled//B 帧的加权预测,默认 disabledparam->bEnableWeightedBiPred = 0;
preset=slower 、veryslow、placebo时1
tune=fastdecode 时0
命令行:weightb
-
bEnableEarlySkip
Enable early skip decisions to avoid analysing additional modes in likely skip blocks. Default is disabled //启用提前跳过决策避免在 skip 块中分析其他模式,默认 disabled(实际代码是 1)param->bEnableEarlySkip = 1;
preset=fast 、slow、slower、veryslow、placebo时0
命令行:early-skip
-
recursionSkipMode
Enable early CU size decisions to avoid recursing to higher depths. Default is enabled//启用提前 CU 尺寸决定避免递归到更高的深度,默认 enabledparam->recursionSkipMode = 1;
preset=palcebo 时0
tune=gain 时0
命令行:rskip
-
edgeVarThreshold
Edge variance threshold for quad tree establishment.//四叉树边缘方差阈值param->edgeVarThreshold = 0.05f;
命令行:rskip-edge-threshold
-
bEnableAMP
Enable asymmetrical motion predictions. At CU depths 64, 32, and 16, it is possible to use 25%/75% split partitions in the up, down, right, left directions. For some material this can improve compression efficiency at the cost of extra analysis. bEnableRectInter must be enabled for this feature to be used. Default disabled//启用不对称运动预测,在 CU 深度为 64、32、16 时,可以在上、下、右、左方向上使用 25%/75%的分割位置,对于一些场景视频能提高压缩效率,但会有额外的分析代价,使用此功能bEnableRectInter必须开启,默认 disabledparam->bEnableAMP = 0;
preset=slower、veryslow、placebo 时1
命令行:amp
-
bEnableRectInter
Enable rectangular motion prediction partitions (vertical and horizontal), available at all CU depths from 64x64 to 8x8. Default is disabled //启用矩形运动预测分区(水平和垂直),可以用于 64x64 到 8x8的所有 CU 深度,默认 disabledparam->bEnableRectInter = 0;
preset=slow、slower、veryslow、placebo 时1
命令行:rect
-
rdLevel
A value between 1 and 6 (both inclusive) which determines the level of rate distortion optimizations to perform during mode and depth decisions. The more RDO the better the compression efficiency at a major cost of performance. Default is 3//决定率失真优化的等级,取值 1~6,RDO 越多,压缩效率越好,牺牲性能代价,默认是 3param->rdLevel = 3;
preset=ultrafast、superfast、veryfast、faster、fast 时2,slow 时4、slower 、veryslow、placebo时6
命令行 :rd
-
rdoqLevel
Set the amount of rate-distortion analysis to use within quant. 0 implies no rate-distortion optimization. At level 1 rate-distortion cost is used to find optimal rounding values for each level (and allows psy-rdoq to be enabled). At level 2 rate-distortion cost is used to make decimate decisions on each 4x4 coding group (including the cost of signaling the group within the group bitmap). Psy-rdoq is less effective at preserving energy when RDOQ is at level 2. Default: 0//在量化中设置率失真分析的数量。0表示没有率失真优化,1 表示率失真代价被用来找到最优舍入值,2 表示率失真代价被使用决定每个 4x4 编码组,当 RDOQ 是级别 2 时,Psy-rdoq 在保持能量方面效果较差,默认是 0param->rdoqLevel = 0;
preset=slow、slower、veryslow、placebo时2
命令行:rdoq、rdoq-level
-
bEnableSignHiding
Enable the implicit signaling of the sign bit of the last coefficient of each transform unit. This saves one bit per TU at the expense of figuring out which coefficient can be toggled with the least distortion. Default is enabled//启用每个变换单元的最后一个系数的符号位的隐式信令,节省了每个 TU 的一个比特,代价是找出哪个系数可以以最小的失真切换为代价,默认 enabledparam->bEnableSignHiding = 1;
preset=ultrafast时0
命令行:signhide
-
bEnableTransformSkip
○ Allow intra coded blocks to be encoded directly as residual without the DCT transform, when this improves efficiency. Checking whether the block will benefit from this option incurs a performance penalty. Default is disabled//允许帧内编码块直接编码,残差不需要 DCT 变换,提升效率,检查块是否会从该选项中受益会导致性能损失,默认 disabled
○ param->bEnableTransformSkip = 0;
○ preset=placebo 时1
○ 命令行:tskip -
bEnableTSkipFast
Enable a faster determination of whether skipping the DCT transform will be beneficial. Slight performance gain for some compression loss. Default is enabled//启用快速确定跳过 DCT 变换是否有益,轻微性能增益,有一些压缩损失,默认 enabled(实际代码 0)param->bEnableTSkipFast = 0;
命令行:tskip-fast
-
maxNumReferences
The maximum number of L0 references a P or B slice may use. This influences the size of the decoded picture buffer. The higher this number, the more reference frames there will be available for motion search, improving compression efficiency of most video at a cost of performance. Value must be between 1 and 16, default is 3//P 或 B 片 L0 参考的最大数量影响到解码图像缓存 DPB 的大小,数字越高,运动搜索可参考帧越多,以性能为代价提高大多数视频的压缩效率,取值 1~16,默认 3param->maxNumReferences = 3;
preset=ultrafast、superfast时1,veryfast、faster时2,fast时3,slow时4,slower、veryslow 、placebo时5
命令行:ref
-
bEnableTemporalMvp
Enable availability of temporal motion vector for AMVP, default is enabled //启用 AMVP 时域运动矢量可用性,默认 enabledparam->bEnableTemporalMvp = 1;
命令行:temporal-mvp
-
bEnableHME
○ Enable 3-level Hierarchical motion estimation at One-Sixteenth, Quarter and Full resolution. Default is disabled//在 1/16、1/4、全像素启用 3 级分层运动估计,默认 disabledparam->bEnableHME = 0;
命令行:hme
-
hmeSearchMethod[3]
3 级分层运动估计的搜索方法,依赖bEnableHMEparam->hmeSearchMethod[0] = X265_HEX_SEARCH;
param->hmeSearchMethod[1] = param->hmeSearchMethod[2] = X265_UMH_SEARCH;
-
hmeRange[3]
3级分层运动估计的搜索范围,依赖bEnableHMEparam->hmeRange[0] = 16;
param->hmeRange[1] = 32;
param->hmeRange[2] = 48;
-
bSourceReferenceEstimation
Enable source pixels in motion estimation. Default is disabled//在运动估计中启用源像素,默认 disabledparam->bSourceReferenceEstimation = 0;
命令行:analyze-src-pics
-
limitTU
Enable early exit decisions for inter coded blocks to avoid recursing to higher TU depths. Default: 0 //为帧间块启用提前退出决策,避免递归到更深的 TU 深度,默认 0param->limitTU = 0;
preset = slower 时4,veryslow 时0
命令行:limit-tu
-
dynamicRd
Increase RD at points where bitrate drops due to vbv. Default 0//在码率因vbv 而下降的地方增加 RD,默认 0param->dynamicRd = 0;
命令行:dynamic-rd
/* --------Loop Filter 环路滤波、SAO Loop Filter 样点自适应偏移环路滤波----------- */
-
bEnableLoopFilter
Enable the deblocking loop filter, which improves visual quality by reducing blocking effects at block edges, particularly at lower bitrates or higher QP. When enabled it adds another CU row of reference lag, reducing frame parallelism effectiveness. Default is enabled//启用去块环路滤波,通过减少块边界的块效应提升视觉质量,特别是在低码率或高 QP 时;当启用时将增加另外一个 CU 行参考滞后,降低了帧并行性的有效性;默认enabledparam->bEnableLoopFilter = 1;
tune=fastdecode 时0
命令行:lft
-
bEnableSAO
Enable the Sample Adaptive Offset loop filter, which reduces distortion effects by adjusting reconstructed sample values based on histogram analysis to better approximate the original samples. When enabled it adds a CU row of reference lag, reducing frame parallelism effectiveness. Default is enabled//启用样点自适应偏移环路滤波,通过调整基于直方图分析的重建样点值来减少失真影响,更好的近似原始样点;当启用时,增加了一个 CU 行参考滞后,降低了帧并行性的有效性,默认 enabledparam->bEnableSAO = 1;
preset=ultrafast 、superfast、时0
tune=fastdecode、gain 时0
命令行:sao
-
bSaoNonDeblocked
Select the method in which SAO deals with deblocking boundary pixels. If disabled the right and bottom boundary areas are skipped. If enabled, non-deblocked pixels are used entirely. Default is disabled//选择 SAO 处理去块边界像素的方法,如果 disabled,则右、底边界区域被跳过,如果 enabled,完全使用未去块的像素,默认disabledparam->bSaoNonDeblocked = 0;
命令行:sao-non-deblock
-
bLimitSAO
Limit Sample Adaptive Offset filter computation by early terminating SAO process based on inter prediction mode, CTU spatial-domain correlations, and relations between luma and chroma//基于帧间预测模式、CTU 空域相关性以及亮度和色度关系,通过提前终止 SAO 过程来限制 SAO 滤波param->bLimitSAO = 0;
命令行:limit-sao
-
selectiveSAO
Select tune rate in which SAO has to be applied. 1 - Filtering applied only on I-frames(I) [Light tune] 2 - No Filtering on B frames (I, P) [Medium tune] 3 - No Filtering on non-ref b frames (I, P, B) [Strong tune]//选择 SAO 必须被应用的调优速率,1-滤波仅应用到 I 帧[微调],2-不滤波 B 帧[中调],3-不过滤非参考 B 帧(I、P、B)[强调]param->selectiveSAO = 0;
命令行:selective-sao