【我的创作纪念日】使用pix2pixgan实现barts2020数据集的处理(完整版本)
使用pix2pixgan (pytorch)实现T1 -> T2的基本代码
使用 https://github.com/eriklindernoren/PyTorch-GAN/ 这里面的pix2pixgan代码进行实现。
进去之后我们需要重新处理数据集,并且源代码里面先训练的生成器,后训练鉴别器。
一般情况下,先训练判别器而后训练生成器是因为这种训练顺序在理论和实践上更加稳定和有效。我们需要改变顺序以及一些代码:
以下是一些原因:
- 判别器的任务相对简单:判别器的任务是将真实样本与生成样本区分开来。这相对于生成器而言是一个相对简单的分类任务,因为它只需要区分两种类型的样本。通过先训练判别器,我们可以确保其具有足够的能力来准确识别真实和生成的样本。
- 生成器依赖于判别器的反馈:生成器的目标是生成逼真的样本,以尽可能地欺骗判别器。通过先训练判别器,我们可以得到关于生成样本质量的反馈信息。生成器可以根据判别器的反馈进行调整,并逐渐提高生成样本的质量。
- 训练稳定性:在GAN的早期训练阶段,生成器产生的样本可能会非常不真实。如果首先训练生成器,那么判别器可能会很容易辨别这些低质量的生成样本,导致梯度更新不稳定。通过先训练判别器,我们可以使生成器更好地适应判别器的反馈,从而增加训练的稳定性。
- 避免模式崩溃:在GAN训练过程中,存在模式坍塌的问题,即生成器只学会生成少数几种样本而不是整个数据分布。通过先训练判别器,我们可以提供更多样本的多样性,帮助生成器避免陷入模式崩溃现象。
尽管先训练鉴别器再训练生成器是一种常见的做法,但并不意味着这是唯一正确的方式。根据特定的问题和数据集,有时候也可以尝试其他训练策略,例如逆向训练(先训练生成器)。选择何种顺序取决于具体情况和实验结果。
数据集使用的是BraTs2020数据集,他的介绍和处理方法在我的知识链接里面。目前使用的是个人电脑的GPU跑的。然后数据也只取了前200个训练集,并且20%分出来作为测试集。
并且我们在训练的时候,每隔一定的batch使用matplotlib将T1,生成的T1,真实的T2进行展示,并且将生成器和鉴别器的loss进行展示。
通过比较可以发现使用了逐像素的L1 LOSS可以让生成的结果更好。
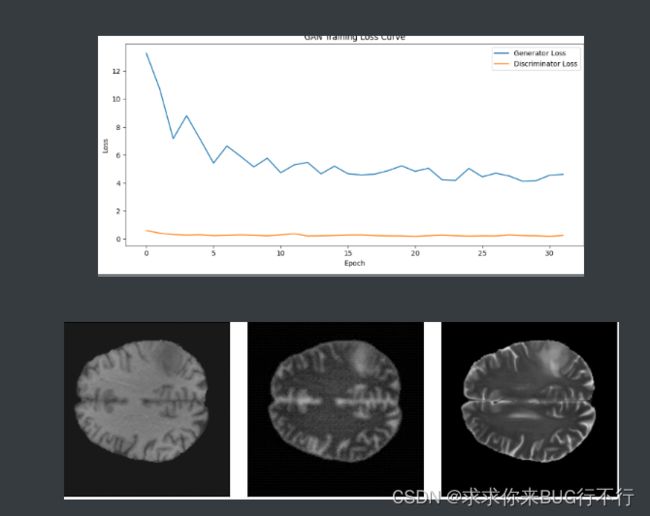
训练10个epoch时的结果图:

此时的测试结果:
PSNR mean: 21.1621928375993 PSNR std: 1.1501189362634836
NMSE mean: 0.14920212 NMSE std: 0.03501928
SSIM mean: 0.5401535398016223 SSIM std: 0.019281408927679166
代码:
dataloader.py
# dataloader for fine-tuning
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torchvision.utils import save_image
import torch.utils.data as data
import numpy as np
from PIL import ImageEnhance, Image
import random
import os
def cv_random_flip(img, label):
# left right flip
flip_flag = random.randint(0, 2)
if flip_flag == 1:
img = np.flip(img, 0).copy()
label = np.flip(label, 0).copy()
if flip_flag == 2:
img = np.flip(img, 1).copy()
label = np.flip(label, 1).copy()
return img, label
def randomCrop(image, label):
border = 30
image_width = image.size[0]
image_height = image.size[1]
crop_win_width = np.random.randint(image_width - border, image_width)
crop_win_height = np.random.randint(image_height - border, image_height)
random_region = (
(image_width - crop_win_width) >> 1, (image_height - crop_win_height) >> 1, (image_width + crop_win_width) >> 1,
(image_height + crop_win_height) >> 1)
return image.crop(random_region), label.crop(random_region)
def randomRotation(image, label):
rotate = random.randint(0, 1)
if rotate == 1:
rotate_time = random.randint(1, 3)
image = np.rot90(image, rotate_time).copy()
label = np.rot90(label, rotate_time).copy()
return image, label
def colorEnhance(image):
bright_intensity = random.randint(7, 13) / 10.0
image = ImageEnhance.Brightness(image).enhance(bright_intensity)
contrast_intensity = random.randint(4, 11) / 10.0
image = ImageEnhance.Contrast(image).enhance(contrast_intensity)
color_intensity = random.randint(7, 13) / 10.0
image = ImageEnhance.Color(image).enhance(color_intensity)
sharp_intensity = random.randint(7, 13) / 10.0
image = ImageEnhance.Sharpness(image).enhance(sharp_intensity)
return image
def randomGaussian(img, mean=0.002, sigma=0.002):
def gaussianNoisy(im, mean=mean, sigma=sigma):
for _i in range(len(im)):
im[_i] += random.gauss(mean, sigma)
return im
flag = random.randint(0, 3)
if flag == 1:
width, height = img.shape
img = gaussianNoisy(img[:].flatten(), mean, sigma)
img = img.reshape([width, height])
return img
def randomPeper(img):
flag = random.randint(0, 3)
if flag == 1:
noiseNum = int(0.0015 * img.shape[0] * img.shape[1])
for i in range(noiseNum):
randX = random.randint(0, img.shape[0] - 1)
randY = random.randint(0, img.shape[1] - 1)
if random.randint(0, 1) == 0:
img[randX, randY] = 0
else:
img[randX, randY] = 1
return img
class BraTS_Train_Dataset(data.Dataset):
def __init__(self, source_modal, target_modal, img_size,
image_root, data_rate, sort=False, argument=False, random=False):
self.source = source_modal
self.target = target_modal
self.modal_list = ['t1', 't2']
self.image_root = image_root
self.data_rate = data_rate
self.images = [self.image_root + f for f in os.listdir(self.image_root) if f.endswith('.npy')]
self.images.sort(key=lambda x: int(x.split(image_root)[1].split(".npy")[0]))
self.img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(img_size)
])
self.gt_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(img_size, Image.NEAREST)
])
self.sort = sort
self.argument = argument
self.random = random
self.subject_num = len(self.images) // 60
if self.random == True:
subject = np.arange(self.subject_num)
np.random.shuffle(subject)
self.LUT = []
for i in subject:
for j in range(60):
self.LUT.append(i * 60 + j)
# print('slice number:', self.__len__())
def __getitem__(self, index):
if self.random == True:
index = self.LUT[index]
npy = np.load(self.images[index])
img = npy[self.modal_list.index(self.source), :, :]
gt = npy[self.modal_list.index(self.target), :, :]
if self.argument == True:
img, gt = cv_random_flip(img, gt)
img, gt = randomRotation(img, gt)
img = img * 255
img = Image.fromarray(img.astype(np.uint8))
img = colorEnhance(img)
img = img.convert('L')
img = self.img_transform(img)
gt = self.img_transform(gt)
return img, gt
def __len__(self):
return int(len(self.images) * self.data_rate)
def get_loader(batchsize, shuffle, pin_memory=True, source_modal='t1', target_modal='t2',
img_size=256, img_root='data/train/', data_rate=0.1, num_workers=8, sort=False, argument=False,
random=False):
dataset = BraTS_Train_Dataset(source_modal=source_modal, target_modal=target_modal,
img_size=img_size, image_root=img_root, data_rate=data_rate, sort=sort,
argument=argument, random=random)
data_loader = data.DataLoader(dataset=dataset, batch_size=batchsize, shuffle=shuffle,
pin_memory=pin_memory, num_workers=num_workers)
return data_loader
# if __name__=='__main__':
# data_loader = get_loader(batchsize=1, shuffle=True, pin_memory=True, source_modal='t1',
# target_modal='t2', img_size=256, num_workers=8,
# img_root='data/train/', data_rate=0.1, argument=True, random=False)
# length = len(data_loader)
# print("data_loader的长度为:", length)
# # 将 data_loader 转换为迭代器
# data_iter = iter(data_loader)
#
# # 获取第一批数据
# batch = next(data_iter)
#
# # 打印第一批数据的大小
# print("第一批数据的大小:", batch[0].shape) # 输入图像的张量
# print("第一批数据的大小:", batch[1].shape) # 目标图像的张量
# print(batch.shape)
models.py
import torch.nn as nn
import torch.nn.functional as F
import torch
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# U-NET
##############################
class UNetDown(nn.Module):
def __init__(self, in_size, out_size, normalize=True, dropout=0.0):
super(UNetDown, self).__init__()
layers = [nn.Conv2d(in_size, out_size, 4, 2, 1, bias=False)]
if normalize:
layers.append(nn.InstanceNorm2d(out_size))
layers.append(nn.LeakyReLU(0.2))
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
def __init__(self, in_size, out_size, dropout=0.0):
super(UNetUp, self).__init__()
layers = [
nn.ConvTranspose2d(in_size, out_size, 4, 2, 1, bias=False),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True),
]
if dropout:
layers.append(nn.Dropout(dropout))
self.model = nn.Sequential(*layers)
def forward(self, x, skip_input):
x = self.model(x)
x = torch.cat((x, skip_input), 1)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64, normalize=False)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512, dropout=0.5)
self.down5 = UNetDown(512, 512, dropout=0.5)
self.down6 = UNetDown(512, 512, dropout=0.5)
self.down7 = UNetDown(512, 512, dropout=0.5)
self.down8 = UNetDown(512, 512, normalize=False, dropout=0.5)
self.up1 = UNetUp(512, 512, dropout=0.5)
self.up2 = UNetUp(1024, 512, dropout=0.5)
self.up3 = UNetUp(1024, 512, dropout=0.5)
self.up4 = UNetUp(1024, 512, dropout=0.5)
self.up5 = UNetUp(1024, 256)
self.up6 = UNetUp(512, 128)
self.up7 = UNetUp(256, 64)
self.final = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)
def forward(self, x):
# U-Net generator with skip connections from encoder to decoder
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
d6 = self.down6(d5)
d7 = self.down7(d6)
d8 = self.down8(d7)
u1 = self.up1(d8, d7)
u2 = self.up2(u1, d6)
u3 = self.up3(u2, d5)
u4 = self.up4(u3, d4)
u5 = self.up5(u4, d3)
u6 = self.up6(u5, d2)
u7 = self.up7(u6, d1)
return self.final(u7)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, normalization=True):
"""Returns downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 4, stride=2, padding=1)]
if normalization:
layers.append(nn.InstanceNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*discriminator_block(in_channels * 2, 64, normalization=False),
*discriminator_block(64, 128),
*discriminator_block(128, 256),
*discriminator_block(256, 512),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1, bias=False)
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.model(img_input)
pix2pix.py
import argparse
import os
import numpy as np
import math
import itertools
import time
import datetime
import sys
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from dataloader import *
import torch.nn as nn
import torch.nn.functional as F
import torch
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="basta2020", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=2, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_height", type=int, default=256, help="size of image height")
parser.add_argument("--img_width", type=int, default=256, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument(
"--sample_interval", type=int, default=500, help="interval between sampling of images from generators"
)
parser.add_argument("--checkpoint_interval", type=int, default=10, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
os.makedirs("images/%s" % opt.dataset_name, exist_ok=True)
os.makedirs("saved_models/%s" % opt.dataset_name, exist_ok=True)
cuda = True if torch.cuda.is_available() else False
# Loss functions
criterion_GAN = torch.nn.MSELoss()
criterion_pixelwise = torch.nn.L1Loss()
# Loss weight of L1 pixel-wise loss between translated image and real image
lambda_pixel = 100
# Calculate output of image discriminator (PatchGAN)
patch = (1, opt.img_height // 2 ** 4, opt.img_width // 2 ** 4)
# Initialize generator and discriminator
generator = GeneratorUNet(in_channels=1, out_channels=1)
discriminator = Discriminator(in_channels=1)
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/%s/generator_%d.pth" % (opt.dataset_name, opt.epoch)))
discriminator.load_state_dict(torch.load("saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, opt.epoch)))
else:
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# Configure dataloaders
transforms_ = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
dataloader = get_loader(batchsize=4, shuffle=True, pin_memory=True, source_modal='t1',
target_modal='t2', img_size=256, num_workers=8,
img_root='data/train/', data_rate=0.1, argument=True, random=False)
# dataloader = DataLoader(
# ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_),
# batch_size=opt.batch_size,
# shuffle=True,
# num_workers=opt.n_cpu,
# )
# val_dataloader = DataLoader(
# ImageDataset("../../data/%s" % opt.dataset_name, transforms_=transforms_, mode="val"),
# batch_size=10,
# shuffle=True,
# num_workers=1,
# )
# Tensor type
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# def sample_images(batches_done):
# """Saves a generated sample from the validation set"""
# imgs = next(iter(val_dataloader))
# real_A = Variable(imgs["B"].type(Tensor))
# real_B = Variable(imgs["A"].type(Tensor))
# fake_B = generator(real_A)
# img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
# save_image(img_sample, "images/%s/%s.png" % (opt.dataset_name, batches_done), nrow=5, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
# 创建空列表用于保存损失值
losses_G = []
losses_D = []
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# Model inputs
real_A = Variable(batch[0].type(Tensor))
real_B = Variable(batch[1].type(Tensor))
# print(real_A == real_B)
# Adversarial ground truths
valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Real loss
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B.detach(), real_A)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_D = 0.5 * (loss_real + loss_fake)
loss_D.backward()
optimizer_D.step()
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad()
# GAN loss
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
# Pixel-wise loss
loss_pixel = criterion_pixelwise(fake_B, real_B)
# Total loss
loss_G = loss_GAN + lambda_pixel * loss_pixel # 希望生成的接近1
loss_G.backward()
optimizer_G.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch,
opt.n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
mat = [real_A, fake_B, real_B]
if (batches_done + 1) % 200 == 0:
plt.figure(dpi=400)
ax = plt.subplot(131)
for i, img in enumerate(mat):
ax = plt.subplot(1, 3, i + 1) #get position
img = img.permute([0, 2, 3, 1]) # b c h w ->b h w c
if img.shape[0] != 1: # 有多个就只取第一个
img = img[1]
img = img.squeeze(0) # b h w c -> h w c
if img.shape[2] == 1:
img = img.repeat(1, 1, 3) # process gray img
img = img.cpu()
ax.imshow(img.data)
ax.set_xticks([])
ax.set_yticks([])
plt.show()
if (batches_done + 1) % 20 ==0:
losses_G.append(loss_G.item())
losses_D.append(loss_D.item())
if (batches_done + 1) % 200 == 0: # 每20个batch添加一次损失
# 保存损失值
plt.figure(figsize=(10, 5))
plt.plot(range(int((batches_done + 1) / 20)), losses_G, label="Generator Loss")
plt.plot(range(int((batches_done + 1) / 20)), losses_D, label="Discriminator Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("GAN Training Loss Curve")
plt.legend()
plt.show()
# # If at sample interval save image
# if batches_done % opt.sample_interval == 0:
# sample_images(batches_done)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/%s/generator_%d.pth" % (opt.dataset_name, epoch))
torch.save(discriminator.state_dict(), "saved_models/%s/discriminator_%d.pth" % (opt.dataset_name, epoch))
processing.py 数据预处理
import numpy as np
from matplotlib import pylab as plt
import nibabel as nib
import random
import glob
import os
from PIL import Image
import imageio
def normalize(image, mask=None, percentile_lower=0.2, percentile_upper=99.8):
if mask is None:
mask = image != image[0, 0, 0]
cut_off_lower = np.percentile(image[mask != 0].ravel(), percentile_lower)
cut_off_upper = np.percentile(image[mask != 0].ravel(), percentile_upper)
res = np.copy(image)
res[(res < cut_off_lower) & (mask != 0)] = cut_off_lower
res[(res > cut_off_upper) & (mask != 0)] = cut_off_upper
res = res / res.max() # 0-1
return res
def visualize(t1_data, t2_data, flair_data, t1ce_data, gt_data):
plt.figure(figsize=(8, 8))
plt.subplot(231)
plt.imshow(t1_data[:, :], cmap='gray')
plt.title('Image t1')
plt.subplot(232)
plt.imshow(t2_data[:, :], cmap='gray')
plt.title('Image t2')
plt.subplot(233)
plt.imshow(flair_data[:, :], cmap='gray')
plt.title('Image flair')
plt.subplot(234)
plt.imshow(t1ce_data[:, :], cmap='gray')
plt.title('Image t1ce')
plt.subplot(235)
plt.imshow(gt_data[:, :])
plt.title('GT')
plt.show()
def visualize_to_gif(t1_data, t2_data, t1ce_data, flair_data):
transversal = []
coronal = []
sagittal = []
slice_num = t1_data.shape[2]
for i in range(slice_num):
sagittal_plane = np.concatenate((t1_data[:, :, i], t2_data[:, :, i],
t1ce_data[:, :, i], flair_data[:, :, i]), axis=1)
coronal_plane = np.concatenate((t1_data[i, :, :], t2_data[i, :, :],
t1ce_data[i, :, :], flair_data[i, :, :]), axis=1)
transversal_plane = np.concatenate((t1_data[:, i, :], t2_data[:, i, :],
t1ce_data[:, i, :], flair_data[:, i, :]), axis=1)
transversal.append(transversal_plane)
coronal.append(coronal_plane)
sagittal.append(sagittal_plane)
imageio.mimsave("./transversal_plane.gif", transversal, duration=0.01)
imageio.mimsave("./coronal_plane.gif", coronal, duration=0.01)
imageio.mimsave("./sagittal_plane.gif", sagittal, duration=0.01)
return
if __name__ == '__main__':
t1_list = sorted(glob.glob(
'../data/BraTS2020_TrainingData/MICCAI_BraTS2020_TrainingData/*/*t1.*'))
t2_list = sorted(glob.glob(
'../data/BraTS2020_TrainingData/MICCAI_BraTS2020_TrainingData/*/*t2.*'))
data_len = len(t1_list)
train_len = int(data_len * 0.8)
test_len = data_len - train_len
train_path = '../data/train/'
test_path = '../data/test/'
os.makedirs(train_path, exist_ok=True)
os.makedirs(test_path, exist_ok=True)
for i, (t1_path, t2_path) in enumerate(zip(t1_list, t2_list)):
print('preprocessing the', i + 1, 'th subject')
t1_img = nib.load(t1_path) # (240,140,155)
t2_img = nib.load(t2_path)
# to numpy
t1_data = t1_img.get_fdata()
t2_data = t2_img.get_fdata()
t1_data = normalize(t1_data) # normalize to [0,1]
t2_data = normalize(t2_data)
tensor = np.stack([t1_data, t2_data]) # (2, 240, 240, 155)
if i < train_len:
for j in range(60):
Tensor = tensor[:, 10:210, 25:225, 50 + j]
np.save(train_path + str(60 * i + j + 1) + '.npy', Tensor)
else:
for j in range(60):
Tensor = tensor[:, 10:210, 25:225, 50 + j]
np.save(test_path + str(60 * (i - train_len) + j + 1) + '.npy', Tensor)
testutil.py
#-*- codeing = utf-8 -*-
#@Time : 2023/9/23 0023 17:21
#@Author : Tom
#@File : testutil.py.py
#@Software : PyCharm
import argparse
from math import log10, sqrt
import numpy as np
from skimage.metrics import structural_similarity as ssim
def psnr(res,gt):
mse = np.mean((res - gt) ** 2)
if(mse == 0):
return 100
max_pixel = 1
psnr = 20 * log10(max_pixel / sqrt(mse))
return psnr
def nmse(res,gt):
Norm = np.linalg.norm((gt * gt),ord=2)
if np.all(Norm == 0):
return 0
else:
nmse = np.linalg.norm(((res - gt) * (res - gt)),ord=2) / Norm
return nmse
test.py
#-*- codeing = utf-8 -*-
#@Time : 2023/9/23 0023 16:14
#@Author : Tom
#@File : test.py.py
#@Software : PyCharm
import torch
from models import *
from dataloader import *
from testutil import *
if __name__ == '__main__':
images_save = "images_save/"
slice_num = 4
os.makedirs(images_save, exist_ok=True)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = GeneratorUNet(in_channels=1, out_channels=1)
data_loader = get_loader(batchsize=4, shuffle=True, pin_memory=True, source_modal='t1',
target_modal='t2', img_size=256, num_workers=8,
img_root='data/test/', data_rate=1, argument=True, random=False)
model = model.to(device)
model.load_state_dict(torch.load("saved_models/basta2020/generator_0.pth", map_location=torch.device(device)), strict=False)
PSNR = []
NMSE = []
SSIM = []
for i, (img, gt) in enumerate(data_loader):
batch_size = img.size()[0]
img = img.to(device, dtype=torch.float)
gt = gt.to(device, dtype=torch.float)
with torch.no_grad():
pred = model(img)
for j in range(batch_size):
a = pred[j]
save_image([pred[j]], images_save + str(i * batch_size + j + 1) + '.png', normalize=True)
print(images_save + str(i * batch_size + j + 1) + '.png')
pred, gt = pred.cpu().detach().numpy().squeeze(), gt.cpu().detach().numpy().squeeze()
for j in range(batch_size):
PSNR.append(psnr(pred[j], gt[j]))
NMSE.append(nmse(pred[j], gt[j]))
SSIM.append(ssim(pred[j], gt[j]))
PSNR = np.asarray(PSNR)
NMSE = np.asarray(NMSE)
SSIM = np.asarray(SSIM)
PSNR = PSNR.reshape(-1, slice_num)
NMSE = NMSE.reshape(-1, slice_num)
SSIM = SSIM.reshape(-1, slice_num)
PSNR = np.mean(PSNR, axis=1)
print(PSNR.size)
NMSE = np.mean(NMSE, axis=1)
SSIM = np.mean(SSIM, axis=1)
print("PSNR mean:", np.mean(PSNR), "PSNR std:", np.std(PSNR))
print("NMSE mean:", np.mean(NMSE), "NMSE std:", np.std(NMSE))
print("SSIM mean:", np.mean(SSIM), "SSIM std:", np.std(SSIM))