秋招的披荆斩棘之路
这篇文章记录了秋招的准备过程中记录的一些东西,大多数都是以Q&A的方式记录,我觉得这是一个比较好的思考和学习方式,通过自问自答的方式来查漏补缺。内容主要分为:计算机网络、操作系统、数据库(可以忽略不计,秋招的时候时间不够,果断选择弃车保帅)、设计模式、C/C++语言基础、算法与数据结构、面经。主要可以给准备找工作的同学提供一个参考,这里附上了PDF的下载地址。
Q&A.pdf
计算机网络
绪论
-
Q:阐述一下电路交换与分组交换
A:电路交换:网络资源按照TDM或FDM分片,为呼叫分配片,资源独享。但建立时间长,无法较好地应对突发性通信,资源浪费较多;分组交换:以分组为单位进行存储-转发,传输时使用全部带宽,资源共享,按需使用。但存在排队、延迟和丢失问题。
-
Q:数据报分组交换网络的特点:
A:无需建立连接即可通信,每个分组的路由都相互独立,网络不维护主机之间的通信状态。
-
Q:分组的延时包括哪些部分?
A:

-
Q: 说一说服务与协议之间的区别和联系?
A:区别:服务是低层实体向上层实体提供它们之间通信的能力,通过层间接口来实现的,是垂直的。协议是同一层的实体之间在相互通信的过程中需要遵循的规则集合,是水平的。联系:本层协议的实现需要下层提供的服务实现,本层实体通过协议为上层提供更好的服务。
-
Q:整个网络的吞吐量取决于什么?
A:通信链路上最小的传输速率。
-
Q:各层的 PDU 形态?
A:网络层的 datagram,链路层的 frame,传输层的 segment,应用层的 message。
-
Q:为什么说 TCP 是面向连接的,而不是有连接的?
A:因为下层的网络层实体路由器不维护主机之间的通信,数据报网络是无连接的分组交换方式。
应用层
-
Q:UDP存在的必要性?
A:能够将 IP提供的端到端服务细分为进程到进程的服务,进行多路复用和解复用;无需建立连接,不做可靠性的保障工作例如检错重发,适合事务性的应用;没有拥塞控制和流量控制,应用能够按照设定的速度发数据;识别报文边界,减轻应用层的负担;头部开销小。
-
Q:P2P模式下是否存在专门的服务器?
A:可以存在,例如P2P文件分发协议中的Tracker服务器用于获取peer节点列表。
-
Q:一个 TCP 连接中 HTTP 请求发送可以一起发送么?
A:
HTTP/1.1不可以并行,HTTP2提供了 Multiplexing 多路传输特性,可以在一个TCP连接中同时完成多个HTTP请求,可以并行。由于HTTP/1.1采用的是文本传输,因此必须按照文本的顺序进行传输,也就导致无法并行;而HTTP2采用的是字节流进行传输,客户端收到数据后按照序列合并到来的数据。 -
Q:说一说Cookies?
A:Cookies通常用于维护客户端在门户网站的站点活动,当客户端向服务器发起请求时,服务器会在响应报文中产生一个唯一的ID,
set-cookie: cookie_num发送给客户端,并由浏览器进行维护,服务器维护一个后端数据库。 -
Q:说一说WebCache?
A:让服务器的资源离用户更近点,用户发起的
HTTP请求报文先发给缓存,如果在代理服务器中击中的话,直接返回对象,否则WebCache会请求原始服务器,然后再将对象返回给客户端。 -
Q:说一说FTP协议?
A:FTP协议采用数据连接与控制连接分开的做法,且控制连接采用的是“带外传输”,由TCP的
URG标志位来实现带外传输,每次只能收发一个字节,不容易阻塞。 -
Q:SMTP与HTTP的区别?
A:SMTP属于“pull”协议,而HTTP属于“push”协议,HTTP的每个对象都封装在各自的响应报文中,而SMTP则将多个对象封装在同一个报文中。
-
Q:DNS的主要作用?
A:DNS是运行在UDP之上端口号为
53的应用服务。实现主机名到IP地址的转换type: A,邮件服务器别名到正规名字type: MX,主机别名到规范名字type: CN,域名到权威域名服务器的域名type: NS;负载均衡。 -
Q:讲一讲域名?
A:层次化命名域名、分布式解析和维护域名;域遵从组织界限,而不是物理网络;域的划分是逻辑的,而不是物理的;
-
Q:DNS记录主要有哪些字段?
A:
Name | Value | Type | TTL,TTL: 如果维护的是权威域名服务器则是长期的,否则是短期的(为了保持一致性) -
Q:DNS的查询方式?
A:DNS的查询方式分为迭代查询和递归查询两种方式,两者的差别在于迭代查询是Response直接返回给查询方,也就是整条查询链路上只有
One Hop;当DNS服务器收到其他服务器的DNS应答时,会将应答中的信息缓存至本地服务器。 -
Q:攻击DNS的方式?
A:①对根服务器发送大量的Ping,未能成功:根服务器设置了流量过滤器、防火墙,本地域名服务器缓存了大量的顶级域服务器的IP地址,因此无需查询根服务器;②劫持DNS报文,伪造应答。
-
Q:如何加入Torrent?
A:通过搜索匹配文件描述符;下载torrent文件获取目标文件的tracking server信息;向tracking server发送请求,获取peer节点列表;与peer节点建立连接。 -
Q:说一说流媒体的工作流程?
A:服务器将视频文件分割成多个块,每个块独立存储且拥有多个码率编码的版本,客户端会先从服务器上获取告示文件,了解资源块的URL,然后经历URL➡️本地DNS➡️服务器权威DNS➡️本地DNS➡️CDN的DNS,最终将URL解析为资源所在CDN缓存的IP地址,最终客户端与资源所在的CDN缓存建立连接。
-
Q:TCP Socket的通信流程:
A:
Server: server_socket = socket(AF_INET, SOCK_STREAM) server_socket.bind((SERVER_ADDR, SERVER_PORT)) server_socket.listen(MAX_UNACCPETED) connection_socket, client_addr = server_socket.accept() message = connection_socket.recv(MAX_RECV_BUFSIZE) connection_socket.send(response) server_socket.close() Client: client_socket = socket(AF_INET, SOCK_STREAM) client_socket.connect((SERVER_ADDR, SERVER_PORT)) client_socket.send(message) response = client_socket.recv(MAX_RECEIVE_BUFSIZE) client_socket.close() -
Q:Web缓存包括哪些形式?
A:代理服务器缓存、CDN缓存、浏览器缓存(网页回退)等。
-
Q:如果Web缓存没有击中的话,访问时间会变小吗?
A:会,因为击中的内容避免访问原始服务器,减少了接入网的负载以及未击中的资源的延时。
-
Q:说一说SSL是如何强化TCP的?
A:总共有三个环节:握手、密钥导出和数据传输;首先在建立TCP连接后,A向B发送hello,B则通过自己的证书进行响应,证书中还包含B的公钥,A通过证书了解了B的真实性,并将主密钥MS通过B的公钥加密然后发送给B,B通过自己的私钥解密获得主密钥MS,从而双方都具有了SSL会话的主密钥。
-
Q:HTTP的状态码?
状态码 具体含义 1XX 提示信息,表示目前是中间状态 2XX 成功 3XX 重定向,资源位置发生变动,需要重新请求 4XX 客户端错误,请求报文有误 5XX 服务器错误,服务器在处理请求时内部发生了错误 -
Q:GET和POST方法是安全和幂等的吗?(安全是指是否会破坏服务器上的资源,幂等是指多次执行相同的操作结果是否是相同的)
A:GET是,POST不是。
-
Q:GET和POST的区别?
A:POST可以通过Request Body向服务器提交表单或者信息;GET如果想要向服务器提交表单则需要使用拓展URL,在请求行的URL中添加字段;GET相比POST的来说更不安全,因为请求参数都暴露在URL中了;GET的请求记录会被完整保留在浏览器历史记录中;请求与发送的数据包不一致:GET将header和data一起发送,服务器响应200,POST先发header再发data,共两次请求与响应;
-
Q:无状态通信的优缺点?
A:好处:减轻服务器的负担;坏处:完成一系列的关联性的操作会非常麻烦
-
Q:HTTP和HTTPS的区别
A:HTTP属于明文传输;HTTPS则加入了SSL/TLS安全协议,建立连接后需要协商SSL参数以及向CA申请数字证书。
-
Q:HTTPS为什么采用混合加密的方式?
A:对称加密只用一个密钥,运算速度快。密钥必须保密,无法做到安全的密钥交换;非对称加密使用两个密钥,解决了密钥交换安全问题但运算速度慢。
-
Q:HTTP的演变过程都发生了什么变化?
A:
演变 内容 HTTP/1.0→HTTP/1.1 使用长连接改善性能开销;支持管道网络传输; HTTP/1.1→HTTP/2 可以进行头部压缩,消除重复请求相同的头部;是通过二进制信息而非纯文本;每个请求和回应的数据包要求按照数据流的格式收发;多路复用,拒绝队头阻塞;服务器可以主动推送静态资源; HTTP/2→HTTP/3 使用UDP协议,防止因为一个TCP连接中某个HTTP请求丢包了导致整个HTTP请求都被重传一次响应; -
Q:如何优化HTTP/HTTPS?
A:缓存;减少请求次数(减少重定向请求次数、合并请求、按需请求、延迟发送请求);减少HTTP响应的数据大小(数据压缩编码);使用Session ID来缓存会话密钥;
-
Q:说一说Session、Token和Cookie的区别?
A:
- Session:用于服务器区分客户端,Session由服务器生成,客户端每次向服务器发请求的时候都带上。
- Token:客户端可以通过Token进行身份验证,具体而言客户端先通过密码和用户名验证,服务器给客户端返回签名的Token,客户端存储Token并用于后续请求验证。
- Cookie:Cookie指的是客户端的浏览器存储的一些站点活动信息。
运输层
-
Q:TCP 为什么需要建立连接,建立连接的好处?
A:维护通信双方的通信参数,例如序列号、收发窗口、IP号、端口号等。
-
Q:TCP与UDP的区别?
A:
| TCP | UDP | |
|---|---|---|
| 多路复用/解复用 | 将(SIP, SPort, DIP, DPort)四元组作为标识 | 将(DIP, DPort)二元组作为标识 |
| 工作特性 | 拥塞控制、流量控制、超时重传、滑动窗口、字节流 | 数据报 |
| 是否建立连接 | 面向连接 | 无连接 |
| 头部大小 | 最小20字节 | 8字节 |
-
Q:GoBackN协议和SR协议的不同点
A:
GBN SR 接收窗口尺寸为1,只能按顺序接收 接收窗口尺寸大于1,可以乱序接收 若 Seq=x失效,重传Seq=x,x+1,x+2...x+n若 Seq=x失效,重传Seq=x累计ACK,只需设定一个定时器 非累计ACK,需要为每个未确认的分组设置定时器 -
Q:TCP如何设置定时器?
A:比RTT略长,通常是估计的RTT+4*估计RTT方差
E s t i m a t e d R T T = ( 1 − α ) ∗ E s t i m a t e d R T T + α ∗ S a m p l e R T T D e v R T T = ( 1 − β ) ∗ D e v R T T + β ∗ ∣ S a m p l e R T T − E s t i m a t e d R T T ∣ T i m e O u t = E s t i m a t e d R T T + 4 ∗ D e v R T T EstimatedRTT = (1 - \alpha)*EstimatedRTT + \alpha*SampleRTT \\ DevRTT = (1-\beta) * DevRTT + \beta * |SampleRTT-EstimatedRTT| \\ TimeOut = EstimatedRTT + 4*DevRTT EstimatedRTT=(1−α)∗EstimatedRTT+α∗SampleRTTDevRTT=(1−β)∗DevRTT+β∗∣SampleRTT−EstimatedRTT∣TimeOut=EstimatedRTT+4∗DevRTT
-
Q:TCP会去估计重传的分组的RTT吗?为什么?
A:因为可能存在老的分组ACK可能在重传后才到达,发送方不能辨识该ACK是新发的分组的ACK还是老的ACK,导致RTT估计错误。
-
Q:TCP如何保证数据可靠传输?
A:ACK、Seq、超时重传、检验和、检错重传、滑动窗口。
-
Q:TCP为什么要用滑动窗口协议?
A:建立缓冲区域,实现流量控制以及拥塞控制。
-
Q:TCP如何实现流量控制?,如果接收方缓存满了怎么办?
A:接收方在发ACK的同时在TCP分组头部的
rwnd字段通告空闲buffer大小,发送方限制已发送未确认的字节数,保证接收方不会被淹没。接收方会在出现空闲窗口时发送一个window update的一个“纯ACK”,但是由于“纯ACK”是不包含任何数据的,因此可靠性较差,如果window update丢失则会出现死锁的情况,所以除此之外,发送方持续发送只有1字节数据的TCP分组也就是window prob,直至收到的分组中rwnd > 0。 -
Q:三次握手做了什么工作?
A:通信双方同意建立连接,同意连接参数。解决了接收方建立半连接浪费资源的问题,以及防止老数据误用的情况发生。
-
Q:网络拥塞不加以控制会出现什么后果?
A:当分组的到达速率接近链路容量时,分组会经历巨大的排队延时;重传以补偿因缓存溢出而丢弃的分组;会大出现大量没必要的重传,链路中包含多个分组的拷贝(没有丢失,经历时间较长);
-
Q:TCP如何实现拥塞控制?
A:维持一个拥塞窗口的值
CongWin,发送端限制已发送但是未确认的数据,从而粗略地控制端到端地发送速率;TCP使用乘性减加性增的方式控制拥塞窗口,当CongWin < Threshold时,CongWin指数型增长,否则线性增长,当感知到拥塞时,Threshold = CongWin/2,轻微拥塞CongWin = Threshold + 3,拥塞CongWin = 1。 -
Q:为什么说TCP是友好的?
A:由于TCP拥塞控制的AIMD原则(线性增加乘性减少),导致多个会话最终享有相等的拥塞窗口以及发送速率。
-
Q:怎么解决数据传输过程中发生的“连包”和“断包”问题?
A:固定传输的包的大小或者使用特殊字符作为分隔符。
-
Q:说一下CA签发证书以及客户端的验证过程?
A:
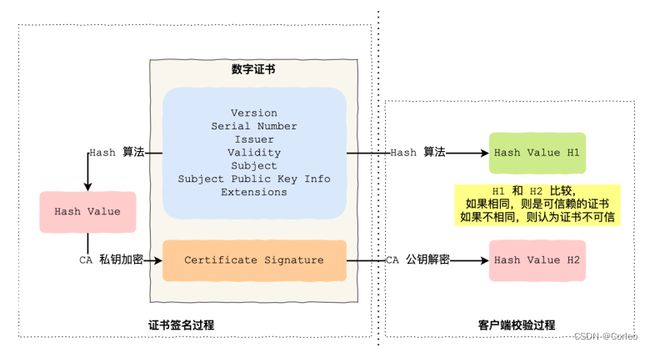
-
Q:说一下SSL/TLS的四次握手?
A:
- C→S:ClientHello(随机数 R a n d C Rand_C RandC 、支持的密码套件列表、TLS版本号)
- S→C:ServerHello(随机数 R a n d S Rand_S RandS、选择的密码套件 [签名算法、密钥交换算法、对称加密算法、摘要算法]、确认支持的TLS版本、数字证书)
- C→S:Change Cipher Key Exchange:(①S的公钥加密后的随机数 R a n d m a s t e r Rand_{master} Randmaster ,②使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
- S→C:Change Cipher Key Exchange:(使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
-
Q:在TCP连接过程中如果
recvbuf还有数据的话这时候socket选择关闭连接,这时候会发生什么?sendbuf呢?A:
recvbuf还有数据的话,socket会清空缓冲区,并向对方发一个RST并断开此次连接;如果sendbuf还有数据的话会将缓冲队列最后一个分组的FIN置位,并将sendbuf中的数据全部发出去。 -
Q:说一说QUIC协议?
A:
- 无队头阻塞:协议中的流相互独立;在TCP中由于队头出错引发拥塞控制,导致该链接中的其他HTTP流被阻止
- 建立连接速度快:底层使用的是UDP协议,并且QUIC分组中包含了TLS1.3的内容,只需一次RTT
- 连接迁移:协议使用连接ID来保存连接信息,例如密钥、数字证书等,可以在双方IP地址更换的情况下依旧可以直接根据连接ID建立连接。连接ID保存在服务端,无论来源是什么,连接ID都指明了唯一的连接,这种优点使得QUIC协议在网络切换时,不必经历超时、重新建立连接等过程。
-
Q:在TCP通信过程中,如果服务器直接杀掉进程会怎么样?如果宕机了呢?如果进程crash掉了呢?
A:如果OS有能力向进程发SIGKILL信号,则服务端会发一个FIN,OS否则发RST。因此答案为:发FIN;客户端重传次数过多出错;发RST
网络层
-
Q:网络层的两大功能?
A:路由和转发。转发功能位于数据平面,是局部功能;路由功能位于控制平面,是全局功能。
-
Q:实现网络层的两种方式?
A:
- 传统方式:路由给出路由表,转发根据路由表转发分组,是基于目标的转发。
- SDN方式:控制器决定流表以及相应的动作,通用的转发,基于头部字段的任意集合。
-
Q:说一说IP的分片和重组?
A:网络链路层有最大传输单元,因此在下发给链路层之前需要对大的IP数据报进行分片。一个数据报被分割成若干个小的数据报,具有相同的ID号,不同的偏移量,且最后一个分片标记为0,重组的工作放在了最终的目标主机上进行。
-
Q:对于无类别IP分组方式,有哪几种特殊的IP地址?
A:
- 子网部分:全为 0—本网络
- 主机部分:全为0—本主机
- 主机部分:全为1–广播地址,这个网络的所有主机
-
Q:怎么获取IP地址?
A:
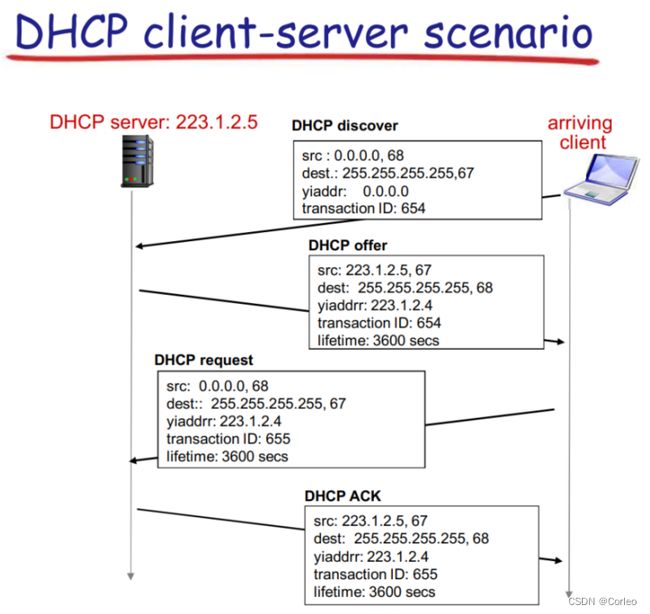
DHCP协议运行在UDP端口上,用于获取IP地址、子网掩码、本地DNS服务器地址。
-
Q:你了解NAT吗?NAT的优点是什么?
A:利用NAT实现本地网络对外只用一个有效IP地址。 NAT的优点:不需要从ISP分配地址,只用一个IP,可以在局域网内更改网络拓扑结构无需通知外界,可以更改ISP地址,局域网内部对外不可见。
利用 NPort来映射 (SIP, SPort),外网需要利用“NAT穿越”来于内网建立连接。
NAT穿越:静态配置、允许外网访问或增加映射、中继。 -
Q:说一说SDN?
A:SDN通过南向接口与RC通信,上报状态与接收流表,路由器可根据不同字段(IP地址、端口、TCP字段等)实现转发、泛洪、拦截、更改字段等动作,这样ISP只需要部署一种设备然后在RC上面跑不同的应用就可以实现路由器、交换机、防火墙、负载均衡等功能。
-
Q:IPv6和IPv4的区别?
A:IPv6将地址长度增加至128位,固定的40字节头部,数据报传输过程中,不允许分片,移除了Checksum。IPv4地址长度为32位,头部大小不固定,大于等于20字节。
-
Q:如何实现IPv4到IPv6的平移?
A:在IPv4路由器之间传输携带IPv6数据报的IPv4数据报,利用IPv4报文段来封装IPv6报文段。
-
Q:你了解哪些路由算法,各自有什么特点?
A:链路状态算法,所有路由器拥有完整的拓扑和边的代价信息;距离矢量算法,路由器只知道到邻居路由器的代价,迭代地与邻居交换路由信息。
链路状态算法 距离矢量算法 原理 所有路由器拥有完整的拓扑和边的代价信息 路由器只知道到邻居路由器的代价,迭代地与邻居交换路由信息。 流程 广播路由自身信息→测量相邻节点信息→广播信息→通过Dijkstra算法找出最短路径 本地链路代价发生变化→通告邻居→从邻居发来了距离矢量的更新消息→通过动态规划算法找到最短路径 优缺点 消息复杂度高,收敛快,健壮性较好。 消息复杂度低,收敛慢,健壮性差 应用协议 OSPF RIP -
Q:你了解层次路由吗?
A:层次路由将互联网分成一个个AS(路由器区域),AS内部路由运行相同的协议,AS间运行AS间路由协议。层次路由解决了规模问题以及管理问题,AS内部规模可控,AS之间的路由可拓展,各个AS可运行不同的内部网关协议,同时对外屏蔽自己网络的细节。
-
Q:内部网关协议和外部网关协议有何不同?
A:

其他
-
Q:说一说RSA公开密钥算法?
A:
- 选择两个素数 p , q p, q p,q,计算 n = p ∗ q , z = ( p − 1 ) ∗ ( q − 1 ) n=p*q, z= (p-1)*(q-1) n=p∗q,z=(p−1)∗(q−1)
- 选择 e < n , g c d ( e , z ) = = 1 e
- 公钥 K B + = ( n , e ) K_B^+=(n,e) KB+=(n,e),私钥 K B − = ( n , d ) K_B^-=(n,d) KB−=(n,d)
- 加密: c = m e m o d n c=m^e \ mod \ n c=me mod n,解密: m = ( m e m o d n ) d m o d n = m e d m o d n = m ( e d m o d z ) m o d n = m m o d n = m m=(m^e \ mod \ n)^d \ mod \ n=m^{ed} mod\ n=m^{(ed \ mod \ z)}\ mod \ n=m\ mod\ n=m m=(me mod n)d mod n=medmod n=m(ed mod z) mod n=m mod n=m
-
Q:对称加密和非对称加密?
A:在对称加密系统中,收发双发的密钥是相同的并且是秘密的;非对称加密系统中,有一个公钥是公开的,一个私钥是只有接收方才知道的。
-
Q:IP包中的校验和和TCP/UDP包中的校验和有何不同?
A:IP包只对头部进行校验和,而TCP/UDP报文段对整个报文段进行校验和。
-
操作系统
操作系统结构
-
Q:说一下CPU执行程序的过程?
A:①CPU读取程序计数器的值,然后CPU的控制单位操作地址总线指定要访问的内存地址,接着通知内存准备数据,然后通过数据总线将指令数据传给CPU,CPU收到内存传来的数据后将指令数据存入指令寄存器。②CPU 分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给逻辑运算单元运算;如果是存储类型的指令,则交由控制单元执⾏。③CPU 执⾏完指令后,程序计数器的值⾃增,指向下⼀条指令。
-
Q:64位CPU相比相比32位CPU的优势在哪?
A:CPU计算的数字可以更大,寻址范围可以更广。
-
Q:CPU缓存的原理?
A:CPU缓存分为三级缓存,L1为数据缓存与指令缓存,L1和L2是每个CPU独有的,L3是多个CPU共享的。CPU缓存使用的SRAM,离CPU核心更近,访问更快。
-
Q:CPU读取数据的顺序?
A:寄存器➡️CPU缓存➡️内存
-
Q:如何提高缓存命中率?
A:在访问或者使用内存时尽量按照内存顺序访问,提高数据缓存的命中率;当有多个同时执⾏计算密集型的线程,为了防⽌因为切换到不同的核⼼,⽽导致缓存命中率下降的问题,我们可以把线程绑定在某⼀个 CPU 核⼼上。
-
Q:为了保证缓存与内存的数据一致性,CPU在什么时候会将缓存中的数据写回内存?
A:写直达,无论数据是否在缓存中,每次写操作都会写回到内存;写回,当发⽣写操作时,新的数据仅仅被写⼊缓存⾥,只有当修改过的缓存被替换时才需要写到内存中 。
-
Q:说一下Linux的中断处理?
A:为了避免由于中断处理程序执⾏时间过⻓,⽽影响正常进程的调度, Linux 将中断处理程序分为上半部和下半部:上半部,对应硬中断,由硬件触发中断,⽤来快速处理中断;下半部,对应软中断,由内核触发中断,⽤来异步处理上半部未完成的⼯作 。
-
Q:系统调用时都发生了什么?例如调用
read(fd, buffer, nbtyes)A:①逆序将参数
nbtytes, buffer, fd,压入堆栈②调用read,将系统调用编码放入寄存器③调用TRAP指令,陷入内核态④内核代码检查系统调用编码,分派给正确的系统调用处理器⑤系统调用处理器运行完成,返回用户态⑥增加堆栈指针,以便清除压入的参数。 -
Q:C/C++程序中的
main(int argc, char** argv)的含义?A:
argc表示的是参数的个数,argv表示的是参数的名字。
内存管理
-
Q:说一说内存分段和内存分页的区别?
A:内存分段通过段基址以及段内偏移量来指向一段内存,分段的好处是能够产生连续的内存空间,但是会出现内存碎片和内存交换的空间太大的问题。内存分页将将整个虚拟和物理内存空间切成一段段固定尺寸的大小,在Linux下每一页大小为
4kB,利用页号和页内偏移量来进行映射,多级页表解决页表过大的问题,TLB(页表缓存)解决页表访问速度缓慢的问题; -
Q:说一说缺页中断?
A:当进程访问的虚拟地址在页表中查不到时,系统会产⽣⼀个缺⻚异常,OS进⼊系统内核空间分配物理内存、更新进程⻚表,最后再返回⽤户空间,恢复进程的运⾏。
当发生缺页中断时,硬件陷入内核态,然后在堆栈中保存程序计数器,汇编例程保存通用寄存器以及其他易失信息;OS尝试发现缺页中断发生虚拟地址(硬件寄存器或者程序计数器),检查地址是否有效,如果无效,则杀掉进程或发送信号,否则寻找一个新的页面(页面置换算法,找到脏的页框,安排该页框写入磁盘,挂起缺页中断的进程,进行上下文切换);当页框干净了之后,装入页表所在磁盘位置,装入完成后发生磁盘中断,表示该页已经装入;程序计数器重新指向这条指令,汇编例程恢复寄存器和其他状态信息,返回用户态继续执行程序。
线程与进程
-
Q:操作系统是如何管理进程的?
A:OS通过进程控制块(PCB)来管理进程,PCB包括进程描述信息(进程标识号,用户标识号),进程控制和管理信息(进程当前状态、进程优先级),资源分配清单,CPU相关信息。PCB通过链表的方式进行组织,将所有相同状态的进程连在一起,组成各种队列。
-
Q:进程上下文、线程上下文、中断上下文各指的是什么?
A:
任务类型 上下文内容 上下文切换场景 进程 上下文切换发生在内核态,包括虚拟内存、栈、全局变量等用户资源,还包括内核堆栈、寄存器等内核空间的资源。 时间片耗尽、挂起(资源不足、主动挂起)、中断 线程 栈、寄存器 同上 中断 程序计数器、寄存器 中断 -
Q:线程的优缺点?
A:优点:一个进程可以同时维护多个线程,各个线程可以并发执行并共享地址空间和文件资源;缺点:当进程中的一个线程崩溃时,可能会导致该进程内的所有线程崩溃。
-
Q:进程和线程的区别?
A:
- 进程是资源(包括内存、打开的⽂件等)分配的单位,线程是 CPU 调度的单位;
- 进程拥有⼀个完整的资源平台,⽽线程只独享必不可少的资源,如寄存器和栈;
- 线程同样具有就绪、阻塞、执⾏三种基本状态,同样具有状态之间的转换关系;
- 线程能减少并发执⾏的时间和空间开销;
- 进程间的通信需要通过IPC的方式,而同一进程内的线程可以通过内存通信
-
Q:用户线程的缺点?
A:
- 由于操作系统不参与线程的调度,如果⼀个线程发起了系统调⽤⽽阻塞,那进程所包含的⽤户线程都不能执⾏了。
- 当⼀个线程开始运⾏后,除⾮它主动地交出 CPU 的使⽤权,否则它所在的进程当中的其他线程⽆法运⾏,因为⽤户态的线程没法打断当前运⾏中的线程,它没有这个特权,只有操作系统才有,但是⽤户线程不是由操作系统管理的。
-
Q:进程通信有什么特点?
A:每个进程的⽤户地址空间都是独⽴的,⼀般⽽⾔是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。
-
Q:说一说各种进程通信方式的特点和场景
A:
通信方式 特点 管道 传输数据是单向的;数据实际上是缓存在内核中的;对于匿名管道,通信范围只存在于父子关系的进程中,只存在于内存,不存于⽂件系统中,生命周期随进程;简单且易知道收发双方是否完成数据收发;无格式的字节流数据;不适合进程间频繁交换数据; 消息队列 保存在内核中的消息链表,每个消息都是固定大小的存储块,生命周期跟随内核;通信不及时,消息队列大小受限;存在用户态和内核态之间的数据拷贝开销。 共享内存 拿出一块虚拟地址空间来映射到相同的物理内存中;不需要陷⼊内核态或者系统调⽤; 信号量 相当于一个整形计数器,用于进程间的互斥和同步;如果信号量初始化为1,则使得两个进程互斥访问共享内存,例如:A: P->访问内存->V,B: P->访问内存->V;如果初始化为0,则使两个进程同步,例如:A: 写内存->V,B: P->读内存。 信号 用于来通知进程发生异常;唯一的异步通信机制;信号事件来源:硬件来源、软件来源。 套接字 跨网络与不同主机上的进程之间通信。 -
Q:控制信号量的两种方式?
A:
- ⼀个是 P 操作,这个操作会把信号量减去 1,相减后如果信号量 < 0,则表明资源已被占⽤,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使⽤,进程可正常继续执行。
- 另⼀个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运⾏;相加后如果信号量 > 0,则表明当前没有阻塞中的进程。
-
Q:生产者和消费者问题?
A:
sem_t bufferHole;; sem_t bufferHeadcount; sem_t mtx; void init() { sem_init(&bufferHole, 0, N); sem_init(&bufferHeadcount, 0, 0); sem_init(&mtx, 0, 1); } void consumer() { sem_wait(&bufferHeadcount); sem_wait(&mtx); consume something; sem_post(&mtx); sem_post(&bufferHole); } void producer() { sem_wait(&bufferHole); sem_wait(&mtx); produce something; sem_post(&mtx); sem_post(&bufferHeadcount); } -
Q:哲学家进餐
class DiningPhilosophers { public: DiningPhilosophers() { } void wantsToEat(int philosopher, function -
Q:交替打印字符串
class FooBar { // 使用条件变量 private: int n; public: FooBar(int n) { this->n = n; } void foo(functionlck(mtx); cv.wait(lck, [&] {return !fooDone;}); // printFoo() outputs "foo". Do not change or remove this line. printFoo(); fooDone = true; cv.notify_all(); } } void bar(function lck(mtx); cv.wait(lck, [&]{return fooDone;}); // printBar() outputs "bar". Do not change or remove this line. printBar(); fooDone = false; cv.notify_all(); } } private: condition_variable cv; mutex mtx; bool fooDone = false; }; class FooBar { // 使用原子变量来作为标识位 private: int n; atomic foo_done = false; public: FooBar(int n) { this->n = n; } void foo(function class FooBar { private: int n; sem_t foo_done, bar_done; public: FooBar(int n) : n(n) { // sem_init(sem_t *sem, int pshared, int value), pshared为0表示线程间共享,否则进程间共享 sem_init(&foo_done, 0 , 0); sem_init(&bar_done, 0 , 1 ); } void foo(function -
Q:什么时候会出现死锁?如何解决?
A:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。那么避免死锁问题就只需要破环其中⼀个条件就可以,最常⻅的并且可⾏的就是使⽤资源有序分配法,来破环环路等待条件。
-
Q:互斥锁和自旋锁的区别?如何选择锁?
A:
-
互斥锁加锁失败后,线程阻塞会释放 CPU ,给其他线程;
-
⾃旋锁加锁失败后,线程会忙等待,直到它拿到锁;
如果等待时间较短则使用自旋锁,避免两次上下文切换带来的时间消耗。中断只能用自旋锁,因为互斥锁获取锁失败后会切换上下文,导致中断程序结束没法继续运行,后并且中断程序的时间较短。
-
-
Q:说一说同步、异步、阻塞和非阻塞
A:
IO 模型 概念 阻塞 接收请求后,响应方直至准备就绪才告知请求方 非阻塞 接收请求后,响应方告知请求方没有准备就绪或者已准备好 同步 发送请求后,请求方一直等待准备就绪 异步 发送请求后,请求方切换到其他事务 -
Q:如何检测死锁?
A:资源持有形成环路。可以间隔性检测死锁或者在CPU的使用率在阈值以下时检测死锁。
-
Q:如何从死锁中恢复?
A:抢占资源;回滚;杀死环路中的某一个进程
-
Q:线程共享哪些内容?
A:
进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID
其他
-
Q:说一说IO复用?
A:
原因:由于阻塞IO会频繁切换线程上下文,因此我们引入非阻塞IO,调用时会立即返回错误或成功,因此可以在一个线程中轮询多个文件描述符是否就绪,但是每次轮询都需要一次系统调用,故引入IO多路复用,通过一次系统调用,检查多个文件描述符的状态。
具体调用:进程通过select、poll、epoll发起IO多路复用的系统调用,系统调用是同步阻塞的:如果传入的多个文件描述符中有描述符就绪,则返回就绪的描述符,否则就阻塞进程。
int select(int nfds, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict errorfds, struct timeval *restrict timeout); /* select遍历每个集合的前nfds个描述符,分别找到就绪的描述符, 找到子集替换参数中的集合,返回就绪描述符的总数。 select缺点: 1.性能开销大。调用 select 时会陷入内核,这时需要将参数中的 fd_set 从用户空间拷贝到内核空间。 2.同时能够监听的文件描述符数量太少。受限于 sizeof(fd_set) 的大小。 */ int poll(struct pollfd *fds, nfds_t nfds, int timeout); /* poll中fds指定了目标描述符以及检查的事件和返回的事件指针。 poll在用户态通过数组方式传递文件描述符,在内核会转为链表方式存储,没有最大数量的限制。 */ int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); /* epoll 是对 select 和 poll 的改进,避免了“性能开销大”和“文件描述符数量少”两个缺点。 1.使用红黑树存储文件描述符集合 2.使用链表存储就绪的文件描述符 3.每个文件描述符只需在添加时传入一次;通过事件更改文件描述符状态 epoll的使用流程 1.epoll_create创建epoll实例epfd 2.epoll_ctl会监听文件描述符fd上发生的event事件 3.epoll_wait等待epfd上的io事件,最多返回maxevents事件 */触发方式:水平触发,当文件描述符就绪时,会触发通知,如果没有处理该事件,下次还会发出信号进行通知;边缘触发:仅当描述符变为就绪时,通知一次,如果不处理该事件之后调用都不会有通知,因此需要读取或写入直至返回
EWOULDBLOCK.对比:在 select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,select/poll只通知有IO事情发生了,而epoll事先通过epoll_ctl来注册一 个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait时便得到通知。epoll只有在使用边缘触发时才是 O ( 1 ) O(1) O(1)的。
RFE1,REF2
-
Q:epoll在使用边缘触发时为什么要将文件描述符设置为非阻塞式?
A:因为一旦设置为阻塞式,且文件描述符又来了新数据,但是epoll又没发出通知,那么接收方则会等待通知,如果发送方等着接收方给回应的话,则会造成死锁。
-
Q:说一下五种IO模型
A:
IO模型 描述 阻塞IO模型 IO进程未准备就绪告知用户需要等待 非阻塞IO IO进程告知用户目前没有准备就绪 IO多路复用 IO进程可以处理多个IO操作 信号驱动 IO进程通过信号告知用户已经准备就绪 异步 IO进程主动告知用户已经准备就绪,通过状态、通信、回调函数等方式 -
Q:中断、异常和系统调用之间的区别?
A:
- 中断是CPU中断当前任务并保留上下文去执行中断程序,中断程序完成后再恢复上下文继续进行之前的任务
- 中断可以分为三类:CPU外部引起的中断(IO中断、磁盘中断、时钟中断),CPU内部引起的或者程序执行过程中引起的中断(整数溢出、非法访问)/ 异常,程序中使用了请求系统服务的系统调用而引发的过程(TRAP)
- REF
-
Q:实现互斥的硬件指令,原子指令
A:
TSL RX, LOCK将内存字LOCK读到寄存器中,读和写操作分开,执行TSL将锁住内存总线,以禁止其他CPU在本指令结束前访问内存XCHG REG, LOCK交换内存字LOCK和寄存器REG的内容
-
Q:你知道屏障吗?
A:为所有进程的末尾设置一个屏障,只有当所有进程都达到了屏障,进程才会被放行。例如:矩阵运算
-
Q:CPU调度发生的时机?
A:
- 创建新进程的时候,是运行父进程还是子进程
- 在进程退出的时候必须调度,如果就绪队列是空的则运行一个OS提供的空闲的进程
- 进程阻塞
- IO中断
-
Q:什么时候会进入内核态?
A:系统调用、中断、异常
数据库
redis
MySQL
-
Q:说说你对MySQL索引的理解?
A:MySQL除了维护数据本身之外,还维护满足特定查找算法的数据结构,这种数据结构就是索引。索引一般很大,以索引文件的形式存储再磁盘上。
-
Q:为什么MySQL索引要用B+树实现而不是二叉树?
A:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ssVlHJh7-1676711588441)(C:\Users\sfpotato\AppData\Roaming\Typora\typora-user-images\image-20210819215020939.png)]
-
非叶子节点只存储键值信息,降低树的深度
-
所有叶节点之间都有一个链指针
-
数据都记录在叶节点中
-
设计模式
-
Q:一些设计模式原则
A:
- 开闭原则:软件实体应对扩展开放,对修改关闭
- 里氏替换原则:所有引用基类的地方必须能够透明地使用其子类对象
- 依赖倒置原则:高层模块不应依赖于低层模块,它们都应该依赖于抽象
单例模式
class Singleton
{
public:
static Singleton* getInstance(){
if (instance == NULL){
instance = new Singleton();
}
return instance;
}
private:
Singleton(){}
static Singleton* instance;
};
/*
1.构造函数私有
2.对象指针和获取函数为静态的
*/
// 线程安全的单例
static Singleton* getInstance() {
if (instance == nullptr) {
mtx.lock();
if (instance == nullptr) {
instance = new Singleton();
}
mtx.unlock();
}
return instance;
}
工厂模式
class AbstractProduct
{
public:
AbstractProduct() {}
Abstract Method ;
};
class ConcreteProduct : public AbstractProduct
{
pulic:
ConcreteProduct () {}
Concrete Method ;
};
// 产品具有抽象层面以及具体层面
class Factory
{
public:
AbstractProduct* getConcreteProduct(params) {
return new SomeoneConcreteProduct;
}
};
// Factory根据传入参数来生产具体的产品,对外屏蔽产品生产细节
Q:简单的工厂模式在需要增加产品时违背了“开闭原则”(需要修改工厂类的生产代码),怎么处理?
A:使得每一个产品都有自己的生产工厂
Q:抽象工厂模式有何不同?
A:抽象工厂的工厂类也有抽象和具体之分,抽象工厂可以生产多个产品。
代理模式
class Subject
{
// 抽象主体
public:
virtual void method() = 0;
};
class RealSubject : public Subject
{
// 实际主体
public:
void method() {}
};
class Proxy : public Subject
{
public:
void method() {
real_instance->method();
}
private:
RealSubject *real_instance;
};
Q:代理模式的优缺点?
A:
优点:
- 代理模式能够协调调用者和被调用者,降低系统耦合度
- 客户端针对抽象角色编程,可以选择增加或者替换代理类,无需修改源码,符合开闭原则
缺点:
- 增加了代理对象,可能会使得系统响应变慢
适应环境:远程代理、虚拟代理、保护代理、缓冲代理
观察者模式
/*
观察者模式定义对象之间的一对多的依赖关系,使得每当一个对象状态发生改变时,其相关
依赖对象都得到通知并被自动更新。
*/
// 观察者
class Observer
{
public:
virtual void response() = 0;
};
class ConcreteObserver : public Observer
{
public:
void response() {}
};
// 观察对象
class Subject
{
public:
void attach(Observer* obs) {} // 增加观察者
void detach(Observer* obs) {} // 移除观察者
virtual void notify() = 0;
protected:
list obsList;
};
class ConcreteSubject : public Subject
{
public:
void notify() {}
};
Q:观察者的优缺点?
A:
优点:
- 实现了稳定的消息更新和传递机制
- 支持广播通信,简化了一对多设计的难度
- 符合开闭原则
缺点:
- 观察者和观察目标相互引用,存在循环依赖
- 观察者的通知时间会耗费大量时间
C/C++语言基础
基础语法
-
Q:在
main函数执行前后发生了什么?A:执行前:设置栈指针,初始化静态变量和全局变量,初始化全局对象,
__attribute__((constructor)),将argc, argv传递给main。执行后:全局对象的析构函数,__attribute__((destructor)) -
Q:C++生成可执行文件需要哪几个步骤?
A:预处理→编译→汇编→链接
-
Q:字节对齐?
A:自然对齐的两个原则:①初始地址的偏移量要是变量大小的整数倍②整个对象的大小要是对象内最大变量的大小整数倍。
struct alignas(2) info { uint8_t a; uint16_t b; uint8_t c; }; sizeof(info) : 6BytesC++11新引入的
alignof计算对齐字节数,alignas调整对齐字节数,但是参数需要大于自然对齐的最小单位,否则使用#pragma pack(1)单字节对齐。 -
Q:指针和引用的区别?
A:
- 指针是一个变量,存储的是一个地址,引用跟原来的变量实质上是同一个东西,是原变量的别名
- 指针可以有多级,引用只有一级
- 指针可以为空,引用不能为NULL且在定义时必须初始化
- 指针在初始化后可以改变指向,而引用在初始化之后不可再改变
- 引用在声明时必须初始化为另一变量,指针声明和定义可以分开,可以先只声明指针变量而不初始化,等用到时再指向具体变量
- 作为函数参数传递时在函数栈帧中存的地址不一样
-
Q:堆和栈的区别?
A:
堆 栈 管理方式 堆的资源由程序员来申请和释放,是动态分配的 编译器自动管理,是静态分配的 内存管理机制 系统维护一个记录空闲地址的链表 编译器维护一个栈空间 空间大小 堆是不连续的内存区域,比较灵活,4G 连续的内存空间,2M 碎片问题 频繁的 new/delete会产生大量碎片栈保持进出一致,所以不会产生碎片 生长方向 由低地址向高地址生长 由高地址向低地址生长 -
Q:堆和栈哪个更快一些?
A:栈。操作系统会有专门的寄存器存放栈的地址,出栈进栈操作也有专门的指令。而堆首先需要寻找合适的内存指针,然后再根据内存指针来访问指向的内存空间。
-
Q:
malloc和new的区别?A:
new malloc 本质 运算符 函数 申请内存空间 自由存储区 堆 返回类型 具体数据类型指针 void* 申请失败 抛出bad_alloc异常 返回NULL 是否调用构造函数 是 否 是否需要声明Size 否 是 malloc和free是标准库函数,支持覆盖;new和delete是运算符,不重载。malloc仅仅分配内存空间,free仅仅回收空间,不具备调用构造函数和析构函数功能,用malloc分配空间存储类的对象存在风险;new和delete除了分配回收功能外,还会调用构造函数和析构函数。malloc和free返回的是void类型指针(必须进行类型转换),new和delete返回的是具体类型指针。malloc在堆区申请内存,而new在自由存储区申请内存
REF
-
Q:
define宏定义和const的区别?A:
define是在编译的预处理阶段起作用,而const是在编译、运行的时候起作用define只做替换,const会检查类型define不会分配内存空间,const会
-
Q:
static关键字作用?A:限制全局变量和全局函数的作用域 | 静态成员变量 | 静态成员函数不能访问非静态的成员变量以及非静态成员函数 | 默认初始化为0
-
Q:说一说顶层
const和底层const?A:顶层
const:指的是const修饰的变量本身是一个常量,无法修改。底层const:指的是const修饰的变量所指向的对象是一个常量。 -
Q:说一说C++为了实现类型安全都做了哪些工作?
A:
new返回的是具体类的指针而不是void*const代替宏定义dynamic_cast使得转换过程更加安全
-
Q:重载、重写和隐藏的区别?
A:
-
重载:重载是指在同一范围定义中的同名成员函数才存在重载关系。主要特点是函数名相同,参数类型和数目有所不同;
-
重写:类继承时重写基类的函数体,要求基类函数必须是虚函数。
-
隐藏:派生类中的函数屏蔽了基类中的同名函数(非虚函数)。
-
-
Q:继承权限?
A:公有:保持原有状态;保护:基类的所有公有成员和保护成员都成为派生类的保护成员,并且只能被它的派生类成员函数或友元函数访问。私有:所有公有成员和保护成员都成为派生类的私有成员,基类的成员只能由自己派生类访问,无法再往下继承。
-
Q:什么时候会调用拷贝构造函数?
A:用类的一个实例化对象去初始化另一个对象;函数参数值传递。
-
Q:类成员初始化方式?
A:赋值初始化,通过在函数体内进行赋值初始化;列表初始化,在冒号后使用初始化列表进行初始化。
这两种方式的主要区别在于:
对于在函数体中初始化,是在所有的数据成员被分配内存空间后才进行的,在进入函数体之前,成员变量会调用一次默认构造函数。
列表初始化是给数据成员分配内存空间时就进行构造并初始化。REF
Class A { Type mem; A(Type mem_) : mem(mem_) {} /* 1. mem.copy_constructor 2. mem_.destructor */ A(Type mem_) { this->mem = mem_; } /* 1. mem_.default_constructor 2. assign operation 3. mem_.destructor */ // Above method is equal to A(Type mem_): mem() { this->mem = mem_; } } -
Q:什么时候必须使用列表初始化?
A:非静态的常量,因为该常量会被折叠到编译器维护的符号表中,没有单独分配内存;引用成员;没有默认构造函数的对象;
-
Q:什么是内存泄漏?
A:一般我们常说的内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定)内存块,使用完后必须显式释放的内存。应用程序般使用malloc、new等函数从堆中分配到块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用,我们就说这块内存泄漏了。
-
Q:
push_back和emplace_back的区别?A:使用
push_back需要调用拷贝构造函数或者转移构造函数,而使用emplace_back插入的元素原地构造,不需要触发拷贝构造函数和转移构造函数。 -
Q:说一下四种强制类型转换?
A:
强制转换 作用 reinterpret_cast (exp) type_id必须是指针、引用、算术类型,强制转换类型 const_cast (exp) 修改类型的const或volatile属性,例如常量引用转换为非常量引用 static_cast (exp) 用于基类和派生类之间的指针和引用转换,基本数据类型转换,指针和 void*之间的转换dynamic_cast (exp) 和static_cast作用一样,多了类型检查的功能 -
Q:说一下移动构造函数
A:移动构造函数可以避免新的空间分配,直接使用传入的右值或左值的空间。
-
Q:说说左值和右值的区别?
A:左值和右值是根据等式的左右来命名的。如果一个表达式返回一个临时的对象则视为右值,例如函数返回局部变量;右值就是我们常用的变量;右值引用是用来创建移动构造函数以及移动赋值操作符的,避免函数值传递时产生深拷贝。move可以将左值转化为右值。
string gen() { string w = "hello"; return w; } string&& rval_ref = gen(); // OK string& lval_ref = gen(); // NOT OK const string & const_lval_ref = gne(); // OKREF
-
Q:说一说静态绑定和动态绑定
A:静态绑定:所对应的函数或属性依赖于对象的静态类型,发生在编译期,非虚函数一般是静态绑定;动态绑定:所对应的函数或属性依赖于对象的动态属性,发生在运行期,虚函数一般是动态绑定以实现多态。
-
Q:传引用和传指针有何区别?
A:传引用:形参作为局部变量在函数栈中开辟了内存空间,存放的是实参的地址,对形参的任何操作都会被间接寻址至实参;传指针:实质上就是传值,传入的是实参所对应的地址值。从编译角度上讲,符号表中会存放形参的变量名以及变量所对应的地址,
arg&存放的是实参的地址,arg*存放的是该指针的地址,而不是所指向的地址,也就是指针值。 -
Q:#define和typedef的区别?
A:执行时间不同(预处理|编译) | 功能不同(替换|类型别名) | 作用域不同(全局|本文件)
-
Q:函数调用过程栈的变化?
A:
- 把被调函数的形参从右至左依次压入栈中
- 使用call指令调用被调函数,并将call的下一条指令的地址当成返回值压入栈中
- 被调函数保存调用者函数的栈底地址和栈顶地址
-
Q:cout和printf的区别?
A:cout是有缓冲输出的;printf无缓冲输出,有输出时立即输出。
-
Q:如何防止一个类被实例化?
A:将构造函数设为private;将类定义为抽象基类(存在纯虚函数)。
-
Q:静态链接和动态链接有何不同?
A:
-
静态链接在将多个目标文件链接成可执行文件时,连接器从库中复制这些函数和数据并它们和应用程序的其它模块组合起来创建最终的可执行文件,造成空间浪费、更新困难。
-
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,多个程序共享同一副本,但存在性能耗损,每次执行程序都需要进行链接。
-
-
Q:内联函数有什么作用?
A:直接在内联函数的调用处复制代码,节省了函数调用的开销。
-
Q:STL中的
resize和reserve的区别?A:
reserve改变的是容量,resize改变的是大小。
内存管理
-
Q:类的对象存储空间?
A:非静态成员的数据类型大小之和,编译器加上的额外成员变量,例如指向虚函数表的指针,为了对齐加入的padding。
-
Q:简要说明C++的内存分区?
A:包括堆、栈、全局静态存储区、常量存储区和代码区(存放函数)。
-
Q:关于this指针?
A:
- this指针只在非静态成员函数中使用,在全局函数、静态成员函数中不能使用
- this指针指向对象的首地址
- this指针并不是对象本身的一部分
- this指针的生命周期只存在于被调用的非静态成员函数中
-
Q:如果在析构函数中调用
delete this会发生什么?A:会导致堆栈溢出。因为
delete this会调用类的析构函数,相当于析构函数内又调用了一次析构函数,形成无穷递归调用。 -
Q:C++重载的原理是什么?
A:在重载解析开始之前,将通过名称查找和模板参数推断选择的函数组合起来,形成候选函数集。如果任何候选函数是成员函数(静态或非静态)而不是构造函数,则将其视为具有一个额外的形参(隐式对象形参),该形参表示调用候选函数的对象,并出现在第一个实际形参之前。
C++11新标准
-
Q:C++11有哪些新特性?
A:
- 利用nullptr替代NULL
- 引入auto和decltype实现类型推导
- 范围for循环
- 初始化列表
- Lambda表达式
- 右值引用和Move语义
- 智能指针
-
Q:智能指针
A:
- shared_ptr: 采用引用计数器的方法,允许多个智能指针指向同一个对象,当计数为0的时候会自动释放动态分配的资源。
- unique_ptr: 一个非空的unique_ptr总是拥有它所指向的资源。转移一个unique_ptr将会把所有权全部从源指针转移给目标指针,源指针被置空;所以unique_ptr不支持普通的拷贝和赋值操作,不能用在STL标准容器中。unique_ptr是一个封装的指针,大小和普通指针一样,而shared_ptr则是两倍普通指针大小(分别指向申请的内存以及引用计数区域)。
- weak_ptr: 为了解决shared_ptr引用计数引起的环形引用问题,weak_ptr没有所有权,与shared_ptr联合使用区分资源持有者和所有者。
- auto_ptr: 为了解决“有异常抛出时发生内存泄漏”的问题,创建时能取得某个对象的控制权,在析构时会释放该对象。auto_ptr构造函数是explicit的,析构函数内部使用的是delete,故不能管理数组。(已被C++11弃用)REF
-
Q:constexpr的作用?
A:与#define类似,但是可以递归,并且在运行前就能直接计算出函数运行返回的值。
constexpr usigned long long factorial (unsigned short n) { return n > 1 ? n * factorial(n – 1) : 1; }
其他
-
Q:一些关键字的作用
A:
关键字 作用 final 不希望某个类或者成员函数被继承或重写 explicit 防止发生隐式类型转换,只能作用于单参数构造函数 volatile 阻止编译器对该变量进行优化,系统总是从所在内存读取数据,而不是寄存器 -
Q:为什么析构函数一般写成虚函数?
A:由于类的多态性,一般情况下基类析构函数要定义为虚函数 。可以通过基类指针来释放派生类对象,如果不写成虚函数,则导致编译器静态绑定,在删除基类指针时只会调用基类析构函数,导致派生类对象析构不完全,造成内存泄漏。
-
Q:为什么构造函数不定义为虚函数?
A:
- 创建一个对象时需要确定对象的类型,而虚函数是在运行时动态确定其类型的。
- 虚函数的调用需要虚函数表指针vptr,而该指针存放在对象的内存空间中,虚函数表vtable在编译时构造,存储在全局静态区。若构造函数声明为虚函数,那么由于对象还未创建,还没有内存空间,更没有地址用来存储vptr了。
-
Q:你觉得为什么析构函数这类虚函数怎么实现再次调用基类的虚函数?
A:派生类的析构函数返回的是基类以及其他成员变量的析构函数。
-
Q:如何处理哈希冲突?
A:线性探测: n p o s = h a s h _ f u n c ( h a s h _ f u n c ( k e y ) + d i ) , d i = 1 , 2 , 3.. npos=hash\_func(hash\_func(key)+d_i),d_i=1,2,3.. npos=hash_func(hash_func(key)+di),di=1,2,3..;开链表;再次散列: n p o s = h a s h _ f u n c 1 ( h a s h _ f u n c 2 ( k e y ) ) npos=hash\_func1(hash\_func2(key)) npos=hash_func1(hash_func2(key));二次探测;
-
Q:move语义
A:move表示一个对象的资源是从另外一个对象搬过来了的,完全等同于
static_cast// 作用是去除T的引用属性,例如int&, int&&变为int move可以接受
xvalue,即任意可以转移资源的对象,返回右值引用REF1,REF2
-
Q:拷贝构造函数与拷贝赋值函数
A:
class A { public: // Simple constructor that initializes the resource. explicit A(size_t length) : mLength(length), mData(new int[length]) { std::cout << "A(size_t). length = " << mLength << "." << std::endl; } // Destructor. ~A() { std::cout << "~A(). length = " << mLength << "."; if (mData != NULL) { std::cout << " Deleting resource."; delete[] mData; // Delete the resource. } std::cout << std::endl; } // Copy constructor. A(const A& other) : mLength(other.mLength), mData(new int[other.mLength]) { std::cout << "A(const A&). length = " << other.mLength << ". Copying resource." << std::endl; std::copy(other.mData, other.mData + mLength, mData); } // Copy assignment operator. A& operator=(const A& other) { std::cout << "operator=(const A&). length = " << other.mLength << ". Copying resource." << std::endl; if (this != &other;) { delete[] mData; // Free the existing resource. mLength = other.mLength; mData = new int[mLength]; std::copy(other.mData, other.mData + mLength, mData); } return *this; } // Move constructor. A(A&& other) : mData(NULL), mLength(0) { std::cout << "A(A&&). length = " << other.mLength << ". Moving resource.\n"; // Copy the data pointer and its length from the // source object. mData = other.mData; mLength = other.mLength; // Release the data pointer from the source object so that // the destructor does not free the memory multiple times. other.mData = NULL; other.mLength = 0; } // Move assignment operator. A& operator=(A&& other) { std::cout << "operator=(A&&). length = " << other.mLength << "." << std::endl; if (this != &other;) { // Free the existing resource. delete[] mData; // Copy the data pointer and its length from the // source object. mData = other.mData; mLength = other.mLength; // Release the data pointer from the source object so that // the destructor does not free the memory multiple times. other.mData = NULL; other.mLength = 0; } return *this; } // Retrieves the length of the data resource. size_t Length() const { return mLength; } private: size_t mLength; // The length of the resource. int* mData; // The resource. }; -
Q:delete和delete[]的区别?
A:delete用于释放单个对象的内存,delete[]用于释放申请的数组的内存
算法与数据结构
基础
-
Q:堆的底层实现?
A:
void insert(int x) { if (current_size == arr.size() - 1) arr.resize(2 * arr.size()); int hole = ++current_size; for ( ; hole > 1 and x > arr[hole / 2]; hole >>= 1) { arr[hole] = arr[hole / 2]; } arr[hole] = x; } void percolateDown(int hole) { int tmp = arr[hole]; int child; for ( ; 2 * hole <= current_sie; hole = child) { child = 2 * hole; if (child < current_sie && arr[child] > arr[child + 1]) ++child; if (tmp > arr[child]) arr[hole] = arr[child]; else break ; } arr[hole] = tmp; } void deleteMin() { if (arr.empty()) throw UnderFlowException(); arr[1] = arr[current_size--]; percolateDown(1); } void buildHeap(vector& other) { // put other in cache and make one offset . for (int i = current_size / 2; i > 0; --i) percolateDown(i); } -
Q:中缀表达式转后缀表达式
A:
stackops; for (auto & v : expr) { if (v.is_ops()) { while (not ops.empty() and ops.top().isNotLower(v)) { cout << ops.top(); ops.pop(); } } else { cout << v; } } -
Q:插入排序
A:
void insertSort(const iterator& begin. const iterator& end) { iterator j; for (iterator p = begin + 1; p != end; ++p) { Object tmp = *p; for (j = p; j != begin and tmp < *(j - 1); --j) *j = *(j - 1); *j = tmp; } } -
Q:快速排序
A:
void quickSort(vector& arr, int left, int right) { if (left + lenTh < right) { int pivot = median(arr, left, right); int i = left, j = right - 1; while (true) { while (a[++i] < pivot) ; while (pivot < a[--j]) ; if (i < j) swap(a[i], a[j]); else break ; } swap(a[i], a[right - 1]); quickSort(a, left, i - 1); quickSort(a, i + 1, right); } else { insertSort(arr, left, right); } } void median(vector & arr, int left, int right) { int mid = (left + right) / 2; if (arr[left] > arr[mid]) swap(arr[left], arr[mid]); if (arr[left] > arr[right]) swap(arr[left], arr[right]); if (arr[mid] > arr[right]) swap(arr[right], arr[mid]); swap(arr[mid], arr[]right - 1); return arr[right - 1]; }
进阶
-
Q:例举全排列
A:
void dfs(vector& arr, int first, int last) { if (first == last) { print arr; return ; } for (int k = first; k <= last; ++k) { swap(arr[k], arr[first]); dfs(arr, first + 1, last); swap(arr[k], arr[first]); } } -
Q:获取非空子集
A:
for (int subset = set; subset; subset = (subset – 1) & set) -
Q:最小生成树
A:
viod kruskal() { sortByEdge(); for (e in G) { if (find(u) != find(v)) { merge(u, v); R.push(e); } } return R; }// 贪心地去将边权最小的边加入到树中 void prim() { for(node in G) dis(node) = inf; rest.push(V); dis(root) = 0; while (!rest.empty) { cur = rest.top(); rest.pop(); R.push(cur); ans += dis(cur); for (node in cur.childs) dis(node) = min(dis(node), g(cur, node)); } return ans; }// 每次添加离树最近的一个节点,并且更新每个节点与树的距离 -
Q:KMP算法
A:
void getNext() { int i = 0, j = -1; next[i] = j; while (i < p.size()) { if (j == -1 or p[i] == p[j]) next[++i] = ++j; else j = next[j]; } } void KMP() { int i = 0, j = 0; while (i < s.size() and j < p.size()) { if (j == -1 or s[i] == p[j]) { ++i; ++j; if (j == p.size()) { // find a match substr j = 0; } } else j = next[j]; } } // z函数 void getZFunction() { // z[i]表示s和s[i....n - 1]的最长前缀 // [l,r]维护最右端的匹配序列 for (int i = 1, l = 0, r = 0; i < n; ++i) { z[i] = max(0, min(r - i + 1, z[i - l])); while (z[i] + i < n && s[z[i]] == s[z[i] + i]) ++z[i]; if (r < z[i] + i - 1) { r = z[i] + i - 1; l = i; } } } -
Q:马拉车算法
A:
vectord(n); // d[i]表示以s[i]为中心的最大回文串的半径 for (int i = 0, l = 0, r = -1; i < n; ++i) { int k = 1; if (i <= r) k = min(d[l + r - i], r - i + 1); while (0 <= i - k && i + k < n && s[i - k] == s[i + k]) ++k; d[i] = k--; if (i + k > r) { l = i - k; r = i + k; } } -
Q:并查集
A:
void merge(int u, int v) { f[findFa(u)] = findFa(v); } int findFa(int v) { if (v != f[v]) return f[v] = findFa(f[v]); else return f[v]; } -
Q:常用图论知识点
A:
Question Solution 有向图查找强连通分量 Tarjan算法 无向图查找双连通分量/割点 Tarjan算法 单源最短路径算法 有权:Dijskstra算法 / 无权:BFS算法 所有点对的最短路径 Floyd算法 有向图判断是否存在环 拓扑排序(BFS) / DFS算法(判断是否存在后向边) 无向图判断是否存在环 DFS算法 /*dfn[v]表示v在dfs过程中的时间戳low[v]表示v的dfs搜索子树中最小的时间戳, 可能包含邻接的后向边bridge[v]表示桥的个数,桥表示删除该边后, 会生成两个不连通的子图branch表示强连通分支*/ tarjan(int u) { dfn[u] = low[n] = ++dfsInter; branch.push(u); for (int k = h[u]; k; n = next[k]) { int v = to[u]; if (!dfn[v]) { tarjan(v); if (low[v] >= dfn[u]) ++bridge[u]; low[u] = min(low[u], low[v]); } else { low[u] = min(low[u], dfn[v]); } } if (dfn[u] == low[n]) { vectorb; while (not branch.empty() and branch.top() != u) { b.push(branch.top()); branch.pop(); } b.push_back(u); // b是一个强连通分量 } } void addEdge(int u, int v) { to[idx] = v, next[idx] = h[u], h[u] = idx++; } void floyd() { for (k = 1; k <= n; k++) { for (x = 1; x <= n; x++) { for (y = 1; y <= n; y++) { f[x][y] = min(f[x][y], f[x][k] + f[k][y]); } } } } vector topsort() { queue q; for (int k = 1; k <= n; ++k) if (!inDeg[k]) q.push(k); vector sortedG; while (not q.empty()) { auto t = q.front(); q.pop(); sortedG.push(t); for (int k = h[t]; k; k = next[k]) { inDeg[k]--; if (!inDeg[k]) q.push(k); } } return soretdG; } void dijkstra(int src, int n, vector > heap; heap.push(make_pair(0, src)); vector dis(n); while (not heap.empty()) { auto t = heap.top(); heap.pop(); int v = t.second; if (vis[v]) continue ; vis[v] = true; for (auto & u : edges[v]) { if (dis[u] > dis[v] + w[u][v]) { dis[u] = dis[v] + w[u][v]; q.push(make_pair(dis[u], u)); } } } } -
Q:树状数组
A:
const int N = arr.size() + 5; int bitArr[N]; void build() { for (int i = 0; i < arr.size(); ++i) bitArr[i + 1] = arr[i]; for (int i = 1; i < N; ++i) { int j = i + (i & -i); if (j < N) bitArr[j] += bitArr[i]; } } void update(int idx, int d) { idx += 1; while (idx < N) { bitArr[idx] += d; idx = idx + (idx & -idx); } } int prefixSum(int idx) { idx += 1; int res = 0; while (idx > 0) { res += bitArr[idx]; idx = idx - (idx & -idx); } return res; } -
Q:线段树
A:
const int N = 2e5 + 5; int a[N]; int lidx[4*N], ridx[4*N]; LL val[4*N], delta[4*N]; void pushdown(int idx) { val[idx << 1] += delta[idx], delta[idx << 1] += delta[idx]; val[idx << 1 | 1] += delta[idx], delta[idx << 1 | 1] += delta[idx]; delta[idx] = 0; } void pushup(int idx) { val[idx] = min(val[idx << 1], val[idx << 1 | 1]); } void buildSeg(int iL, int iR, int idx) { lidx[idx] = iL; ridx[idx] = iR; if (iL == iR) { val[idx] = a[iL]; return ; } int iM = (iL + iR) / 2; buildSeg(iL, iM, idx * 2); buildSeg(iM + 1, iR, idx * 2 + 1); pushup(idx); } LL querySeg(int iL, int iR, int idx) { if (lidx[idx] == iL and ridx[idx] == iR) return val[idx]; pushdown(idx); int iM = (lidx[idx] + ridx[idx]) / 2; if (iR <= iM) return querySeg(iL, iR, idx * 2); else if (iL > iM) return querySeg(iL, iR, idx * 2 + 1); else return min(querySeg(iL, iM, idx * 2), querySeg(iM + 1, iR, idx * 2 + 1)); } void addSeg(int iL, int iR, int idx, int d) { if (lidx[idx] == iL and ridx[idx] == iR) { val[idx] += d; delta[idx] += d; return ; } pushdown(idx); int iM = (lidx[idx] + ridx[idx]) / 2; if (iR <= iM) addSeg(iL, iR, idx * 2, d); else if (iL > iM) addSeg(iL, iR, idx * 2 + 1, d); else { addSeg(iL, iM, idx * 2, d); addSeg(iM + 1, iR, idx * 2 + 1, d); } pushup(idx); } -
Q:AVL树通过自旋来保证树的平衡,红黑树通过哪些措施来减少开销?
A:红黑树不保证树的严格平衡性。
-
Q:说一说“跳表”这个数据结构
A:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AlTb8uZG-1676711588441)(C:\Users\sfpotato\AppData\Roaming\Typora\typora-user-images\image-20210820202404283.png)]
其他
-
Q:说一说布隆过滤器
A:布隆过滤器是一个比特向量或者比特数组,它本质上是一种概率型数据结构,用来查找一个元素是否在集合中,支持高效插入和查询某条记录。常作为针对超大数据量下高效查找数据的一种方法。
工作原理:布隆过滤器维护一个比特向量和若干个哈希函数,对每个数据用所有的哈希函数计算哈希,得到哈希值,然后将向量中相应的位设为1。在查询某个数据是否存在的时候,对这个数据用k个哈希函数得到k个哈希值,再在比特向量中相应的位查找是否为1,如果某一个相应的位不为1,那这个数据就肯定不存在。但是如果全找到了,则这个数据有可能存在。 -
STL技巧
advance(it, k); // 将迭代器it后移k位 prev(it); // it前一个迭代器 distance(itLeft, itRight); // 两个迭代器之间的距离 next(it); // it后一个迭代器
面经
虎牙
一面 AUG 19th
- 自我介绍
- 给定任意整数数组,三个数乘积和最大是多少
- 找到最长不重复子串
- 设计LRU的Get和Insert接口,你会用什么数据结构实现
- 有没有了解过Redis这类数据库
- “跳表”有没有了解过
- C++的智能指针有了解过吗
- 说一说static关键字的作用,请你设计一个单例模式
- 协程与线程有什么区别?线程切换时要做什么操作
- 说一说TCP的三次握手和四次握手
- 为什么挥手需要四次挥手
- I/O多路复用有了解吗?epoll,select,poll这些
- Linux的操作有用吗?GDB有用过吗?
- 平时比较擅长哪一块内容?
- UDP是不可靠的,如果想要让UDP可靠,你会从哪些角度去设计、考虑
- 说一说超时重传和快速重传?为什么是三次ACK
- 说一下TCP如何实现拥塞控制算法
- 说一说如何设计前缀树
- 你一般是怎么学习的
- 反问环节
二面 AUG 23th
-
自我介绍
-
指针和引用的区别
-
子类的构造函数中new一块内存,我们用父类指针指向实例化对象,那么能通过该指针delete掉该内存吗?
-
构造函数能否访问虚函数,该虚函数有具体实现,虚函数表是什么时候生成的?
- 由于类的构造次序是由基类到派生类,所以在构造函数中调用虚函数,虚函数是不会呈现出多态的
- 类的析构是从派生类到基类,当调用继承层次中某一层次的类的析构函数时意味着其派生类部分已经析构掉,所以也不会呈现多态
- 虚函数表是编译时生成的,是类层面的,为所有实例共享
-
进程和线程拥有的线程资源区别
-
数据库有学过吗?
-
在实际工程当中,大的项目编译时间往往会比较久,改动了一点点就需要很长时间的重新编译,如何缩短编译时间?
- 减少编译时不必要的依赖,头文件中,能使用前置声明的,就不使用include。
- 采用debug模式编译选项,这个选项下关闭不必要的影响编译时间的选项。
-
怎么优化代码读取磁盘文件速度?
-
有用过卡尔曼滤波器吗?卡尔曼滤波器做预测有什么用?
-
解释一下傅里叶变换,讲一讲傅里叶变换有什么用处?
-
讲一讲5G和4G的区别?你觉得6G方向会往哪些方面发展
-
网页访问速度有时候快有时候慢,你能讲一讲原因吗?
-
你玩游戏的时候有时候快有时候慢,你能讲一讲原因吗?
-
哪门课程学的比较好,说一说你的学习经验
-
课外学了什么计算机相关的课程
字节跳动
一面 AUG 19th
-
自我介绍
-
项目介绍
-
指针和引用的区别
-
main函数执行之前会执行什么操作
-
怎么在main函数执行后再执行一些操作
-
写一个Python装饰器
from functools import wrapsdef log(func): @wraps(func) def config(*args, **kwargs) do something return fun(*args, **kwargs) return config -
使用列表切片将数组反转
arr = arr[::-1] -
进程和线程的区别,在内存上怎么分配?
-
CPU线程越多越好吗?怎么去规划线程?
- 区分IO密集型和CPU密集型
-
常用的Linux的命令行,如何察看目前的资源状况以及正在执行的进程?
ps, top -
判断有向图中是否存在环路?,事件复杂度是多少?
- 拓扑排序或者DFS查看是否存在后向边
-
**⼀群⼈开舞会,每⼈头上都戴着⼀顶帽⼦。帽⼦只有⿊⽩两种,⿊的⾄少有⼀顶。每个⼈都
能看到其它⼈帽⼦的颜⾊,却看不到⾃⼰的。主持⼈先让⼤家看看别⼈头上戴的是什⺓帽
⼦,然后关灯,如果有⼈认为⾃⼰戴的是⿊帽⼦,就打⾃⼰⼀个⽿光。第⼀次关灯,没有声
⾳。于是再开灯,⼤家再看⼀遍,关灯时仍然鸦雀⽆声。⼀直到第三次关灯,才有劈劈啪啪
打⽿光的声⾳响起。问有多少⼈戴着⿊帽⼦? **
一面 SEP 06th
-
自我介绍
-
什么是计算机编码,常见的计算机编码方式?Unicode和UTF-8之间的关系?
- Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。UTF-8 是 Unicode 的实现方式之一。
-
进程、线程的含义以及它们之间的区别?如果我们要去开发一个程序的话,怎么去选取多线程和多进程的方式?
-
Python是一个多进程的还是单进程的?
-
进程常见的状态?一般导致进程进入阻塞状态的原因有哪些?
-
什么是用户态和内核态?为什么设计操作系统要区分内核态和用户态?
-
动态链接库和静态链接库的区别?程序怎么找到函数所在动态链接库位置?
- 程序链接时的查找顺序:指定的查找路径、GCC的环境变量、默认路径、如果存在文件名相同的库则默认是同动态链接库。
-
数组、链表、栈的区别,什么时候用数组/链表?
-
简述一下TCP/IP协议层?每一层都有哪些协议?ICMP协议是哪一层的?
- 网络层。
-
地址解析协议是怎么工作的?
- ARP协议只为同一子网下的路由器和主机进行地址解析,每台主机或者路由器都会维护一个ARP表,如果表内找不到目的IP的话,会在子网内广播一个ARP查询分组。而如果想要寻址外部子网的主机,则需要将数据帧交给本子网的路由器,由路由器转发给外部的子网。
-
详细说一下TCP的三次握手?在发送SYN握手包的时候可以指定端口号吗?如果对方没有监听目标端口号会发生什么情况?
-
TCP和UDP的主要区别?说一下TCP保证可靠传输的几个措施的具体过程?
-
请描述一下DNS解析的过程?如果是访问
a.b.c.d.baidu.com,具体的迭代查询过程?每次查询返回的记录类型? -
HTTP和HTTPS的区别?简述一下TLS的密钥交换过程?
- C→S:ClientHello(随机数 R a n d C Rand_C RandC 、支持的密码套件列表、TLS版本号)
- S→C:ServerHello(随机数 R a n d S Rand_S RandS、选择的密码套件 [签名算法、密钥交换算法、对称加密算法、摘要算法]、确认支持的TLS版本、数字证书)
- C→S:Change Cipher Key Exchange:(S的公钥加密后的随机数 R a n d m a s t e r Rand_{master} Randmaster ,使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
- S→C:Change Cipher Key Exchange:(使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
-
C++中要用到C里面的函数要什么额外的声明?
-
1.引用头文件前需要加上 extern “C”
extern “C”{ #include “A.h” #include “B.h” #include “C.h” #include “D.h” };2.C++调用C函数的方法,将用到的函数全部重新声明一遍
extern “C”{ extern void A_app(int); extern void B_app(int); extern void C_app(int); extern void D_app(int); };
-
-
C++中的struct和class的区别?
- 默认属性
- 默认继承级别
- class可以使用模板,而struct不能
-
算法题:查询一个树是否存在一条路径,路径上节点的值和等于 s u m sum sum
阿里云
一面 AUG 23th
- 计算机相关课程
- 项目
- 程序加载完成后,到main函数执行之前,OS需要准备什么东西?
- 静态链接和动态链接在生成exe之前都会将库拷进去吗?
- C++11有哪几类智能指针?weak_ptr有什么用
- 你理解的面向对象和面向过程的理解是什么?
- 说一说生产者和消费者这个问题,怎么实现?当存在多个消费者和生产者时,消费者和消费者之间有限制吗?用什么数据结构存生产者的数据?用栈行吗?数组行吗?
- REF, REF, REF
- C++的数据结构API你用过哪些?有序的map是怎么保证有序的?如果让你用无序map来实现有序map,你会怎么实现?
- 链表实现插入时间的有序性,红黑树保证
key的有序性
- 链表实现插入时间的有序性,红黑树保证
- 一个8G的文件,每一行都存一个int类型的数字,给你一个2G内存的计算机,找出重复的数字
- 算法题:检查一个字符串使用括号是否符合规范
二面 AUG 27th
-
项目
-
为什么要字节对齐,除了内存碎片问题和内存利用之外还有什么区别?
- 影响到CPU的读取速度,以32位CPU为例,如果不采取4字节对齐的话,在读取
0x00000003-0x00000005时就需要寻址两次。
- 影响到CPU的读取速度,以32位CPU为例,如果不采取4字节对齐的话,在读取
-
volatile的关键字的作用,什么场景下用volatile,举个例子?
- 多任务下的共享变量需要声明为volatile;存储器映射的硬件寄存器通常也要加voliate,因为每次对它的读写都可能有不同意义;
-
用过共享内存吗?和普通内存的区别,使用这块内存的线程全死掉后这块内存还在吗?
- 需要相应的系统调用才能销掉这块内存。
-
静态链接和动态链接的本质区别,优缺点?
-
程序有很多源代码文件,文件中有很多全局变量,全局变量初始化的顺序?按照符号表的顺序还是链接的顺序?
- 按照链接顺序进行初始化。
-
用过数据库吗?上过数据库的课程吗?平时怎么了解内存是否泄漏?
-
编写
my_malloc, my_free函数,使得返回的地址是N字节对齐的void* my_malloc(size_t size) { size_t tot_size = N + sizeof(int) + size; void* hptr = malloc(tot_size); void* ret_ptr = (int*)(hptr + sizeof(int) + (hptr + sizeof(int)) % N); int* record_ptr = (int*)(ret_ptr - sizeof(int)); *record_ptr = hptr; return ret_ptr; } void my_free(void* ptr) { int* record_ptr = (int*)(ptr + sizeof(int)); free(*record_ptr); }
小红书后端开发
一面 AUG 28th
- 手撕算法题:给定 n ∗ n n*n n∗n 的网格进行涂色,你可以每次涂一行或者涂一列,要求涂色结束后需要 k k k个已上色的格子,问有多少种涂法?
- C++程序生成exe文件的过程,每个环节做些什么事情?
- 预编译:宏定义替换,删除注释,预编译指令
#include文件内容替换 - 编译:词法分析,语义分析,代码优化
- 汇编:将汇编代码翻译成机器码
- 链接:将不同源文件产生的目标文件进行链接
- 预编译:宏定义替换,删除注释,预编译指令
- **编译可以编译出
.a, binary, .so, .i,它们之间有什么区别? **.o是目标文件,相当于windows中的.obj文件 也就是未链接前的机器码文件.so为共享库,是shared object,用于动态连接的,相当于windows下的dll.a为静态库,是好多个.o合在一起,用于静态连接,相当于windows下的lib
- C++的内存区域,堆和栈有什么区别,为什么栈需要有大小限制,可以修改吗?
- 减少程序维护的工作;防止不合理的递归函数;用户态内存有限;
- 怎么申请堆区的内存,
malloc和new的区别? - 介绍一下C++11新特性,智能指针说一下,
unqiue_ptr和shared_ptr能够相互转换吗?shared_ptr是怎么实现的?引用计数是怎么实现的?-
所有引用同一个对象的shared_ptr都共用一个_M_pi指针,指向相同资源的所有 shared_ptr 共享“引用计数管理区域”,并采用原子操作保证该区域中的引用计数值被互斥地访问。
-
REF
-
- C++有哪几种强制转换,
dynamic_cast会在哪些场景应用?如果static_cast应用于基类与派生类之间的转换会出现什么问题? - 解释一下
select和epoll的差别?说一下 它们的优势? - 在TCP连接的过程中如果出现了大量的
time_wait的状态,请你解释一下这种现象?- 存在大量的TCP短连接
- 影响:必须为每一个请求对象建立全新的连接,客户端和Web服务器都需要维护TCP通信变量以及缓冲区,服务器负担加重;每个请求对象的响应时间为 2 ∗ R T T 2*RTT 2∗RTT ,交付时延长。
- 解决办法:
time_wait状态下的socket复用;打开connection: keep alive;减少time_wait的时间
- 有没有可能直接进入
closed状态,而不进入time_wait的状态?- 当处于被动关闭时就不存在
time_wait的状态
- 当处于被动关闭时就不存在
keep alive解决什么问题?
二面 SEP 24th
- 说一说进程、线程和协程
- 一般怎么去创建进程,
Fork的流程?- 通过调用
clone系统调用赋值父进程的PCB的信息,然后为新进程创建一个内核栈,为了将父进程与子进程区分开来,将进程描述符中的许多成员设置为初始值,并分配一个有效的PID,最终唤醒子进程。
- 通过调用
- 数据库了解过吗?
- 算法题:反转目标区间的链表
- C++中STL中Vector的push_back时间复杂度是多少?均摊呢?
- O(1)
- 查看代码片段,找bug
小马智行
一面 AUG 30th
- 自我介绍
- 项目
- 给定数组 A A A以及正整数 t t t,长度为 n n n,找到下标满足 1 < = l < = r < = n 1 <= l <= r <= n 1<=l<=r<=n,使得 ∑ l r A m o d t = 0 \sum_{l}^{r} A \ mod \ t\ = \ 0 ∑lrA mod t = 0,问总共有多少对下标满足要求
- 给定数字 a , b < = 1 0 18 a, b <= 10^{18} a,b<=1018,你可以将 a a a 进行数字对调,对调后的数字中不包含前导0,并且返回的对调后的数字 c c c满足 c < = b c<=b c<=b,请你找到最大 c c c ,所给数据一定存在解。
- TCP和UDP的区别,UDP的应用场景?这些场景的共性是什么?
二面 SEP 04th
- 算法题:给你一个二叉树,请判断该二叉树是否是有效的?有效的定义是:根的深度为0,如果节点的深度是奇数的话,那么节点的值必须是偶数,并且对于深度相同的节点,从左到右依次递增;如果节点的深度是偶数的话,那么节点的值必须要是偶数,并且对于深度相同的节点,从左到右依次递减,分别使用BFS和DFS来解决该问题?
- 聊聊项目经历,为什么不去实习?
- 反问环节
三面 SEP 04th
- 项目中遇到的难点
- C++的新特性有去关注吗?
- C++的转换语法会在哪些场景用,如果
dynamic_cast失败的话会发生什么?- 如果要转的是指针,返回空指针;如果是引用,抛
std::bad_cast
- 如果要转的是指针,返回空指针;如果是引用,抛
- C++的智能指针,哪些场景会用到?背后的作用原理以及动机,会不会有循环引用的问题?怎么解决?
- 平常有没有写什么多线程的项目?
new和malloc的区别?如果内存不够,申请失败的话,这两个会怎么做?- 对于malloc方式申请的内存,失败则返回NULL,通过是否是零指针区别;
- 对于new方式申请的内存,失败则抛出 b a d _ a l l o c bad\_alloc bad_alloc异常,通过C++异常机制处理;
- 说一下C++的多态怎么实现的?
- 算法题:给你一个二叉树,二叉树的节点值为整数,求最大路径和?最大路径乘积呢?
四面 SEP 17th
- 项目介绍
- 说一说智能指针
- 说一下vector的各个操作的时间复杂度,说一下vector的扩容?
- 首先vector会申请一块2倍大小的内存,然后调用拷贝构造函数将数据拷贝进来,并且析构掉原来的元素。
- class和struct的区别?
- class有哪些访问控制符?
friend是什么意思?三种继承级别的区别? - redis了解吗?是个什么东西?与MySQL有什么区别?
- 有涉及过web的开发吗?
- 算法题:给定一个字符串 s s s 和两个空字符串 u , t u, t u,t,你可以进行两个操作:把 s s s的第一个字符移动到 t t t的末尾,把 t t t的最后一个字符移动到 u u u 的末尾。你可以以任意顺序执行这两种操作直至 s , t s, t s,t均为空,请你返回字典序最小的 u u u。
- 内存虚拟地址说一下你的理解,如果两个进程需要去修改同一个文件怎么做?
- Linux中的用户态和内核态的区别?**怎么进入内核态?**为什么会有内核态和用户态之分?
- 系统调用、异常、中断
- 数据库设计的几个原则分别指的是什么?
- 四层网络模型和七层网络模型?
- TCP和UDP的区别?TCP怎么保证可靠传输?
- OS和算法数据结构是你自学的吗?
腾讯
一面 SEP 01th
-
求 10000 ! 10000! 10000!
-
给定柱体的高度 a 1 , a 2 , . . . a n a_1, a_2, ...a_n a1,a2,...an,求能够围成容积最大的容器
-
给定字符串 s s s,要求将单词反转,例如 $legends\ never \ die.\ $反转成 d i e . n e v e r l e g e n d s die.\ never \ legends die. never legends
-
如果C++中定义了一个类,里面没有定义任何东西,对它进行 s i z e o f sizeof sizeof 大小是多少,如果添加了构造函数和析构函数呢?如果析构函数是虚函数呢?
-
以下代码执行结果
struct A{ void f(){cout << __FUNCTION__ << endl;} virtual void vf(){cout << __FUNCTION__ << endl;} } int main(){ A*p = NULL; p->f(); p->vf(); }p->f()可以执行,因为代码区有f()的地址;p->vf()不能执行,因为p中没有指向虚函数表的指针,找不到vf()的地址。
-
左值引用和右值引用有什么区别?右值引用作用场景?完美转发
std::forward被称为完美转发,它的作用是保持原来的值属性不变。如果原来的值是左值,经std::forward处理后该值还是左值;如果原来的值是右值,经std::forward处理后它还是右值。
-
TCP是如何保证可靠传输的?
-
TCP中有一个
time_wait状态,为什么会有这种状态?如果一台服务器上有许多time_wait状态,会有什么影响?有可能是什么原因造成的? -
讲一下协程和线程的区别?什么情况下会发生协程切换?
- 时间片是对协程是透明的,当发生IO阻塞或者协程主动放弃运行的时候,线程中就会发生协程切换。
二面 SEP 03th
-
自我介绍,转码是怎么规划学习计划?为什么本科的时候没转?未来的职业规划?
-
SQL和一般的高级编程语言有什么区别?
-
HTTPS的通信的全过程?
-
TLS是怎么建立的?
- C→S:ClientHello(随机数 R a n d C Rand_C RandC 、支持的密码套件列表、TLS版本号)
- S→C:ServerHello(随机数 R a n d S Rand_S RandS、选择的密码套件 [密钥交换算法、签名算法、对称加密算法、摘要算法]、确认支持的TLS版本、数字证书)
- C→S:Change Cipher Key Exchange:(S的公钥加密后的随机数 R a n d m a s t e r Rand_{master} Randmaster ,使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
- S→C:Change Cipher Key Exchange:(使用 R a n d m a s t e r Rand_{master} Randmaster加密所有握手数据的摘要,保证握手过程中未被修改)
-
说一下加密和解密?为什么非对称加密会复杂一些?验证身份的流程?
非对称加密除了身份验证之外,还存在非对称加密算法的运算复杂度本身就比非对称加密算法复杂度高。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-brBm5q2j-1676711588441)(C:\Users\sfpotato\AppData\Roaming\Typora\typora-user-images\image-20210827154636736.png)]
-
进程、线程和协程有什么区别?什么情况下会考虑使用多线程?为什么CPU密集型使用多线程意义不大?
-
算法题:给定长度为 n n n 的数组,要求每次从数组中选取两个数 a , b a, b a,b,从数组中移除这两个数,然后将 a ∗ b + 1 a*b + 1 a∗b+1 加入到数组当中去,直到只剩下一个数为止。
( ( a ∗ b + 1 ) ∗ c + 1 ) ∗ d + 1 = a ∗ b ∗ c ∗ d + c ∗ d + d + 1 ((a *b + 1)*c+1)*d + 1=a*b*c*d + c*d+d+1 ((a∗b+1)∗c+1)∗d+1=a∗b∗c∗d+c∗d+d+1,所以只要让大的数尽可能参与到每一个乘积项的运算即可。
一面 SEP 09th
- 算法题:给一个循环序列 a a a和一个整数 k k k,问是否存在长度为 k k k 的子序列使得序列中的元素唯一
- 算法题:给定一系列的数字号码长度小于等于10,问是否存在两个序列 a , b a, b a,b 使得 a a a是 b b b的前缀
- 算法题:给一个数字 n n n,请你返回由 ‘0’ 和 ‘1’ 合法的字符串个数,合法的字符串内任意两个 ‘1’ 不相邻
- TCP中为什么要有 t i m e _ w a i t time\_wait time_wait 状态?如果把 t i m e _ w a i t time\_wait time_wait 设置得比较小会发生什么?
- 保证对方接收到了ACK,连接正常断开;保证网络中滞留的分组能够正常过期;
- t i m e _ w a i t time\_wait time_wait 设置为 2 ∗ M S L 2*MSL 2∗MSL, M S L MSL MSL 为报文最大存活时间
二面 SEP 18th
-
算法题:给定长度为 n n n数组,数组元素在 [ 1 , n ] [1,n] [1,n]内,有些元素出现两次,其他元素出现一次,请使用时间复杂度为 O ( n ) O(n) O(n)且空间复杂度为 O ( 1 ) O(1) O(1)的算法找出所有出现两次的元素
-
算法题: 给你一个数组 a a a, a [ i ] a[i] a[i]表示从 i i i可以向前跳的最大步数,请判断是否能从 1 1 1跳到 n n n
-
C++的编译过程
-
堆和栈的区别
-
全局变量定在头文件中会有什么影响
- 出现重复定义
-
为什么要使用内存对齐?为什么内存对齐能够提高内存寻址效率?
-
智能指针有哪些?原理是什么?
unique_ptr通过什么函数来转移所有权的?使用智能指针有什么问题?- 应尽量使用unique_ptr,unique_ptr更轻量,更容易避免出现重复销毁的情况发生
- 使用shared_ptr时应该保证线程安全
- 尽量使用make_shared来创建shared_ptr,而不是原始指针
- 尽量不要使用get函数来获取原始指针,避免访问冲突
- 如果使用unique_ptr
.release释放指针,则必须手动delete掉返回的原始指针
REF
-
说一下虚函数实现的机制
-
单继承和多继承的虚函数表会有什么区别?多重继承会出现什么情况?
- 多重继承会有多个虚函数表,几重继承,就会有几个虚函数表。这些表按照派生的顺序依次排列,如果子类改写了父类的虚函数,那么就会用子类自己的虚函数覆盖虚函数表的相应的位置,如果子类有新的虚函数,那么就添加到第一个虚函数表的末尾。
- 会出现命名冲突和数据冗余问题。使用虚继承或者声明冲突变量来自哪个继承的基类。
-
C++类的初始化顺序?
- 成员变量的初始化次序是根据变量在内存中次序有关,也就是成员变量在类中声明顺序
-
编译期多态和运行时多态的区别?
-
编译时多态 运行时多态 判断标准 指针类型、引用类型 指针指向对象 类型 函数重载、模板具体化 虚函数
-
-
TCP的流量控制和拥塞控制的区别?
-
select和epoll的区别?水平触发和边缘触发有什么区别?分别适合什么场景?
-
说一下DNS域名解析?
-
算法题说思路:给定一个二叉树的两个节点,请你找出深度最大的公共父节点?
美团
一面 SEP 02th
-
虚函数实现什么功能?实现的基本原理?假设基类的析构函数没有声明成虚函数会发生什么?
-
进程间的通信方式?哪种效率最高?
-
快排的空间复杂度以及时间复杂度?是稳定的排序算法吗?快排的最坏的情况下时间复杂度?什么时候会导致最坏情况?
-
讲一讲项目,C++11的新特性,Move语义用于解决什么问题?
-
智能指针的实现原理?
-
除了刷题之外,还写过啥大项目吗?
-
算法题:复杂指针的深拷贝
struct ComPtr { T val; ComPtr* nxt; // 指向下一个节点 ComPtr* other; // 随机指向任何一个节点 };
亚马逊
一面 SEP 08th
- C++的 s t r i n g string string 中的运算符 + + + 的重载
- C++中的重载和重写的区别,假设输入参数和函数名都一样,但是返回参数不一样,这是被允许的吗?
- 重载:重载是指在同一范围定义中的同名成员函数才存在重载关系。主要特点是函数名相同,参数类型和数目有所不同;
- 重写:类继承时重写基类的函数体,要求基类函数必须是虚函数。
- 在try-catch中如果try中发生了异常并且在catch中也发生了异常会发生什么?
- 行为表上像没有catch语句一样,异常向上查找是否存在优先级更高的catch语句,如果没有则程序会失败。
- 你常用的设计模式有哪些?用C++实现一个单例模式?
- UML中常用的关系有哪些?
- 实现:类与接口的关系,表示类是接口所有特征和行为的实现。
- 泛化:类之间的继承。
- 关联:关联是一种拥有关系,一个类可以调用另一个类的公有的属性和方法。在类中以成员变量的方式表示。比如老师有自己的学生。
- 依赖:是一种使用的关系,即一个类的实现需要另一个类的协助,常用于类方法的局部变量、方法参数等。
- 组合:整体与部分的关系,部分离开整体后不可以单独存在,代表整体的对象负责代表部分的对象的生命周期。常用于类的成员变量。
- 聚合:整体与部分的关系,部分离开整体后可以单独存在。常用于类的成员变量 。
- 贪心算法一定能取得最优解吗?除了贪心算法之外,还了解哪些算法?动态规划的常用例子?
- 工作中有没有碰到一个棘手的例子,你是怎么解决的?
- 考虑什么样的职业发展?找什么样的公司?
- 英语交流
二面 SEP 08th
- 算法题:反转链表,以三个节点为一组进行反转
- 算法题:给一个完全二叉树,请用算法复杂度小于 O ( n ) O(n) O(n)的程序计算二叉树的节点个数
三七互娱
二面 SEP 16th
- 项目
- 解释一下OSI七层协议
- 写过Web的开发接口吗?HTTP的传输方式?
GET和POST有什么区别? - HTTP和HTTPS的区别?HTTPS的优点和缺点?多了TLS会在哪方面多出些消耗?CPU还是IO?有什么方式来降低应用层的消耗吗?
- 减少请求次数(减少重定向请求次数、合并请求、按需请求延迟发送请求)
- 使用长连接
- 如果使用基于UDP的QUIC协议,会存在什么不足吗?
华为
一面SEP 16th
- 算法题:合并有序链表
- 算法题说思路:笔试题第一题,给定一个二叉树,树的节点有正有负,找到一个节点,将以该节点为根的子树从二叉树中拿去,重新生成一棵树,使得两颗树的和之间的差值绝对值最大。
- 得过什么奖项?
- 讲一下TCP的建立连接和断开连接
- HTTP码302的意义?
- 临时重定向
- 讲一讲DNS?作用?DNS怎么实现负载均衡?DNS怎么知道哪个服务器主机的负载比较小?
- 通过轮询的方式得到每台服务器的响应时间。
- 实习和项目?
二面 SEP 18th
- 进程间的通信方式
- 数据结构中常见的树结构以及它们的特点,B+树常用于哪些场景,为什么要用B+树?
- 图的几种遍历方式
- 给定一个字符矩阵 M a t r i x Matrix Matrix和一个字符串 w o r d word word,请判断是否存在一条路径使得,该路径上的字符能够组成 w o r d word word
网易互娱
一面 SEP 26th
-
算法题:有一个花园,有 有一个花园,有 n n n 朵花,这些花都有一个用整数表示的美观度。这些花被种在一条线上。给定一个长度为 n n n 的整数类型数组 f l o w e r s flowers flowers,每一个 f l o w e r s [ i ] flowers[i] flowers[i] 表示第 i i i 朵花的美观度。
一个花园满足下列条件时,该花园是有效的。
花园中至少包含两朵花。
第一朵花和最后一朵花的美观度相同。
作为一个被钦定的园丁,你可以从花园中去除任意朵花(也可以不去除任意一朵)。你想要通过一种方法移除某些花朵,使得剩下的花园变得有效。花园的美观度是其中所有剩余的花朵美观度之和。
返回你去除了任意朵花(也可以不去除任意一朵)之后形成的有效花园中最大可能的美观度。
-
算法题:合并 K K K个有序数组?空间复杂度小一点的?时间复杂度?
-
C++多态怎么实现的?虚函数低层是怎么实现的?虚函数表是每一个类有一张表?
- 每一个父类有自己的虚函数表,子类的成员函数被放到父类虚函数的位置
- 没有覆盖的虚函数放到第一个虚函数表中(多重继承)
-
类的构造和析构顺序?在父类的构造函数中调用虚函数,在创建子类时,会调用哪个虚函数?
-
析构函数声明为virtual的意义是啥?不声明的话会发生什么?
-
delete和free的区别?
-
unordered_map和map的区别?底层?使用场景的区别?
-
说一下vector?一下代码会发生什么?
vectora; a.push_back(0); int& b = a[0]; a.resize(2); cout << b << endl; -
说一下左值引用和右值引用有什么区别?
-
返回值优化?
- 在函数中创建对象时,编译器会将调用者函数的栈帧地址传给构造函数,因此会只调用一次构造函数。
-
线程和进程的区别?线程之间的同步方式有哪些?介绍一下条件变量?会使用哪些多线程的东西?
-
如何使用
atomic?-
什么样的数据类型可以使用atomic?
- 拷贝不变的数据:没有用户自定义的拷贝构造函数、移动构造函数、拷贝赋值函数、移动赋值函数、析构函数;没有虚函数或者虚基类;使用的是连续内存,可以使用memcpy。
-
atomic变量不可以使用赋值构造函数以及赋值操作符
-
常用函数
// general store load exchange compare_exchange(expected, desired) // /* automically do this: [ if (atomicX == expected) { atomicX = desired; return true; } else { expected = atomicX; return false; } ] code: auto oldX = g_atomicX.load(); while (!g_atomicX.compare_exchange_strong(odX, f(oldX))) ; */
-
-
图形学了解的怎么样?怎么做轮廓检测?滤波器的本质是什么?
-
数学题:给定一个法线向量和入射光向量,求反射光向量?
-
S = − I . N ∣ N ∣ 2 N 入射光在法线上的投影向量 P = I + S R = 2 ∗ P − I = 2 ∗ S + I = I − 2 ( I . N ) N S=-\frac{I.N}{|N|^2}N \ \ \ 入射光在法线上的投影向量 \\ P=I+S \ \ \ R = 2*P-I=2*S+I=I-2(I.N)N S=−∣N∣2I.NN 入射光在法线上的投影向量P=I+S R=2∗P−I=2∗S+I=I−2(I.N)N
-
REF
-
二面 OCT 14th
- C++的虚表是怎么实现的?
- 多继承有什么优势和劣势?怎么去解决劣势?
- 场景题:如果现在有一个NPC的类,如果现在需要构造一个能够打架的NPC,需要继承怪物的属性,如果采用多继承的方式继承NPC和怪物两个类会出现什么问题?
- ordered_map和unordered_map的区别?
- 如果发生hash冲突了怎么解决?如果是你你会选择哪种方式?开链表有什么不好的地方?优势呢?
- 什么情况下需要进行hash扩容?怎么进行扩容?
- REF,使用渐进式Rehash
- 怎么构造一个随机置换数组?拓扑排序说一下?复杂度是多少?
- 给定一个图,如何找到图中的孤岛?
- 遇到链接错误?如果发生的链接错误的函数本身能够找到怎么解决?
- windows的IO多路复用API是什么?讲一讲IO多路复用?
- 你了解L1 Cache,L2 Cache吗?它们之间有什么区别?
- 什么样的代码是Cache有友好的?介绍一下内存分区?堆区和栈区的区别?
深信服
一面 SEP 26th
- 介绍项目
- 算法题:给定两个链表,判断两个链表是否存在相交节点
- 怎么判断是否过拟合?怎么评估模型的有效性?无监督学习使用过吗?
- 学习一个新东西怎么去规划?
二面 OCT 9th
-
介绍项目
-
算法题:给定一个链表,删除其中的重复元素,例如
1->2->2->3->3->4转换为1->4
VIVO
一面 SEP 26th
-
说一下堆和栈的区别?
-
虚拟内存空间了解吗?怎么进行虚拟内存和物理内存之间的映射?如果映射不到会怎么样?
-
内核空间的内存分配有哪些方法?
- REF
-
智能指针说一下?RAII了解吗?
- 创建即初始化,例如智能指针,
lock_guard提供了一个封装的mutex,在构造函数调用后会lock,析构会unlock,保证在抛出异常时会正确解锁,同样unique_lock也有同样的设计动机。
- 创建即初始化,例如智能指针,
-
**友元了解吗?**为什么会有这个设计,不是破坏了类的封装特性吗?
- 如果存在类A需要访问类B的私有成员,则要么使用共有的setter或则getter函数,这种情况下会使得外部所有对象都可以访问某个私有成员,而友元可以限定某个类或者某个函数可以访问。但是友元则会使得友元函数和友元类能够访问所有私有成员变量。所以友元在某种程度上是保证了封装性。
-
左值引用和右值引用的区别是什么?
-
多线程编程有了解吗?多线程要注意什么?加锁一般都有哪些锁?读写锁?
-
原子变量了解吗?对内存序有了解吗?
-
几种执行顺序
- sequential consistency:同一个线程中的语句顺序保持不变
- happens-before:声明两个线程中的某些语句的相对执行顺序
- synchronizes-with:实现两个线程之间的happens-before
-
三种主要的memory_order
```c++ typedef enum memory_order { memory_order_relaxed, // relaxed, code in one thread can be reordered. memory_order_consume, // consume memory_order_acquire, // acquire memory_order_release, // release memory_order_acq_rel, // acquire/release memory_order_seq_cst // sequentially consistent, in a thread order is sequential. } memory_order; ``` seq_cst提供total order和synchronization relaxed啥也不提供 acquire, release只提供synchronization-
relaxed ordering:不提供任何跨线程同步,仅仅保证load和store是原子操作,例如程序计数器。
-
release-acquire ordering:
在这种模型下,
store()使用memory_order_release,而load()使用memory_order_acquire。这种模型有两种效果,第一种是可以限制 CPU 指令的重排:-
在
store()之前的所有读写操作,不允许被移动到这个store()的后面。 -
在
load()之后的所有读写操作,不允许被移动到这个load()的前面。 -
// Thread1: unique_lockul(mtx); gTag = true; gData = getData(); ul.unlock(); gCv.notify_all(); // Thread2: unique_lock ul; gCv.wait(ul, [] {return gTag;}); data = gData; /* 第5行与第10行保持同步,也就是第5行前的代码不能放到后面,第10行后面的代码不能放到前面,保证第11行是有效的。其实也就是lock(release),unlock(acquire) */
-
-
-
-
算法题:快速排序
虾皮
一面 SEP 28th
- 从浏览器中输入URL发发生什么?
- 三次握手?为什么不是两次或者四次?
- Linux中查看一个文档的后十行
tail -n 10 test.txt
- 悲观锁和乐观锁,适用于什么场景?
- 读写操作的占比
- 如何判断一个链表存在环
- 说一下HTTP码?
- 说一下C++的内存空间都有哪些,分别存放什么资源?
- 算法题:LRU、合并有序链表
二面 OCT 12th
- Linux用过哪些指令?
awk,grep用过吗? - 从URL到页面显示资源的过程?
- C++的makefile用过吗?
- 场景题:如果两个人在传输文件,内存会存在几次拷贝?网卡和内存是怎么交互的?
- 说一下TCP的四次挥手,ACK的意义,
time_wait的作用? - 如果服务器上存在大量的
time_wait会是什么原因? - 中间件了解过吗?研究生的专业方向?自学了哪些东西?
- 算法题:给定一个正整数 n n n表示括号对数,输出所有有效的括号表示。
- 研究院实习学到了什么东西?如果与他人存在意见分歧会怎么处理?
- 现在拿到了哪些offer?
米哈游
一面 SEP 28th
-
算法题:反转链表、二叉树层序遍历、最大数、回文数字
-
C++函数的参数传递有几种做法?它们之间的区别是什么?
-
define和const常量有啥区别?
-
C++的抽象类?子类析构时会调用父类的析构函数吗?
-
死锁是怎么产生的?
-
进程的几种状态?
-
TCP和UDP的区别?三次握手?
微软
一面 OCT 18th
- 算法题:计算链表的节点值的总和,如果存在环呢?
二面 OCT 20th
-
项目介绍
-
算法题:给定长度为 n n n 的非负整数数组 a a a和一个正整数 k k k,你可以给数组中的每个元素赋上正号或者负号,请问存在多少种方式使得赋上正负号后的和为 k k k, n < = 20 , ∑ a < = 2000 n<=20, \sum{a} <= 2000 n<=20,∑a<=2000
-
把函数代码改得更规范一些
三面 OCT 22th
- 自我介绍、项目介绍
- 算法题:给定一个数组,你可以交换一次数组元素,请你找到最长的连续子数组使得子数组中的元素相同
- 插入排序