陈雨强:GPT等大模型应用落地需关注内容可信、数据安全、成本可控
近日,由《麻省理工科技评论》、清华工研院联合主办的全球青年科技领袖峰会召开,包括6位院士在内的国内外顶级学者、科技领袖展示了最具前沿科技成果及产业化进程。第四范式联合创始人、首席科学家陈雨强受邀出席活动并围绕AIGC、大模型等话题分享了创新技术在产业应用中的趋势与实践。

在起起伏伏的发展过程中,人工智能一直在朝着解决更为复杂问题的方向演进和迭代。这背后,除了外在的数据、算法、算力等三要素协同发展以外,内在的根本原因在于模型维度持续不断的提升。
业界评判模型维度的标准是VC维理论,是由早期统计学的两位创始人提出,类似于脑容量,VC维越大则模型或函数越复杂,机器智力水平就越高,学习能力越强。
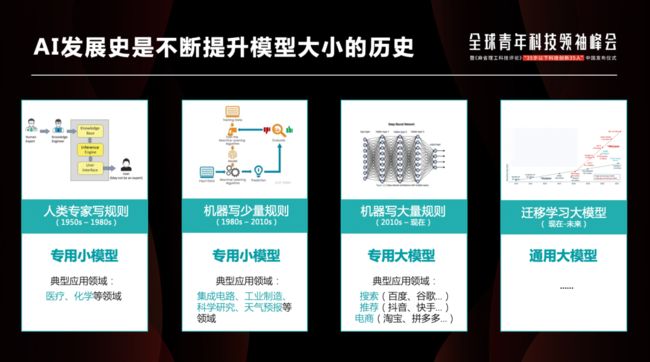
从持续不断提升VC维这一视角看,人工智能发展是不断提升模型维度和大小的历史。不管是决策类AI、视觉类AI还是NLP(自然语言处理)领域,都经历了四大阶段:
第一阶段是由人制定规则来构建专用小模型,优点是可解释、易干预,最早应用在专业领域,但随着写的规则增多会失真、失效,应用效果未能达到当时的预期。
第二阶段是让机器写少量规则,受限于机器的数据、算力、算法能力,人工智能写的规则并不多,所以模型规模仍然维持在专用小模型的阶段;
第三阶段是机器写大量规则构建了专用大模型,其背后源于深度学习、海量数据、算力水平的飞速发展,这让人工智能在视觉、语音、搜索、推荐等领域构建了千亿级专用大模型,能力逐渐达到了超越人的水平。但这些专用大模型只能解决单一问题。
第四阶段是通用大模型阶段,通过多任务学习的方式,让一个模型拥有非常多的能力,将应用于各个领域的专用大模型变成一个通用大模型。
GPT就是NLP领域的通用大模型典型代表,核心解决从海量的数据中学习人的语感。语感是学习语文的一项重要基础能力,不管是认字、组词、造句、写文章都要建立在好的语感基础上。
GPT在学习了五千亿个单词后,训练出了更加接近人的语感和生成式语言的能力。相较于传统的NLP技术,GPT可以通过更长的上下文来进行推断。

此外,光靠语感做到表达自然、逻辑通顺还不够,好的文章还需要基于事实表达正确的观点、言之有物。因此,GPT以学语文的方式学习了数学、化学、地理、写代码等众多其他学科知识。其学习方式并不是直接讲解数理化公式、历史事件背景或是代码的语法逻辑,而是通过看大量的文章、形成自有的知识库,且随着参数越大,其覆盖领域和能力范畴越来越广。
然而,拥有任何领域的知识往往意味着在任何专业领域都不够专业。GPT会因为没有看到过专业领域的数据,出现“胡编乱造”的情况。

所以,以GPT为代表的大模型技术真正应用于企业中,亟需解决内容可信、数据安全、落地成本高等三大挑战。
首先是内容可信。很多情况下,企业必须要甄别内容是不是编的,并确保生成内容真实、可靠。要解决这个问题,大模型必须要引入企业内部高质量的数据,生成的每句话都能溯源。
其次是数据安全。最近有很多企业限制员工使用ChatGPT,每一个问题都有可能泄露核心机密,所以私有部署对企业来说至关重要,确保关键信息不被泄露。
第三是成本可控。落地成本是一个重要的考虑因素,企业并不需要所有GPT的知识,可以根据企业自身的需要适当减小模型规模,以降低应用落地成本。
为此,第四范式推出了企业级生成式AI产品——式说,它在满足企业部署大模型所需的内容可信、数据安全、成本可控三大要求的同时,具备了生成式对话能力、多模态输入输出能力、企业级Copilot能力。在与企业内部应用库、私有数据打通后,自动对信息和数据进行分析,回答员工的问询或执行相关任务。
式说在门店管理中的应用实践
式说在物流管理中的应用实践
式说在工业设计中的应用实践
式说在仓库管理中的应用实践
我们深知,大模型产业应用不止于此。未来,第四范式将持续与客户携手探索更加广阔的应用场景,帮助企业享受到新技术带来的生产力提升,共同迈向AIGC时代。