IO虚拟化 - virtio介绍及代码分析【转】
1. 概述
Virtio是linux平台下一种IO半虚拟化框架,virtio 由 Rusty Russell 开发,他当时的目的是支持自己的虚拟化解决方案 lguest。而在KVM中也广泛使用了virtio作为半虚拟化IO框架。本文主要介绍virtio的设计及在kvm中的实现。
Virtio的好处:
- virtio作为一种Linux内部的API,提供了多种前端驱动模块
- 框架通用,方便模拟各种设备
- 使用半虚拟化可以大大减少VMEXIT次数,提高性能
1.1 框架介绍
VirtIO由 Rusty Russell 开发,他当时的目的是支持自己的虚拟化解决方案 lguest。VirtIO 是对准虚拟化 hypervisor 中的一组通用模拟设备IO的抽象。它是一种框架,通过它hypervisor 导出一组通用的模拟设备,并通过一个通用的应用编程接口(API)让它们在虚拟机中变得可用。它构造了一种虚拟化环境所独有的存储设备,因此需要在虚拟机内部安装特定的驱动程序才能正常驱使该设备进行工作。通常我们称虚拟机内部的驱动为前端驱动,称负责实现其功能模拟的程序(KVM平台下即为qemu程序)为后端程序,半模拟技术也常常被叫做前后端技术。采用半摸拟技术后,配合前端驱动,虚拟化设备完全可以采用全新的事件通知和数据传递机制进而大幅提升性能,例如在virtio-blk磁盘中,采用io_write函数将virtqueue的编号写到相应的寄存器,导致虚拟机退出,进行前端到后端通知,采用中断注入方式实现后端到前端的通知,并通过IO环(vring)进行数据的共享,IO模型也随之发生变化(如下图所示)
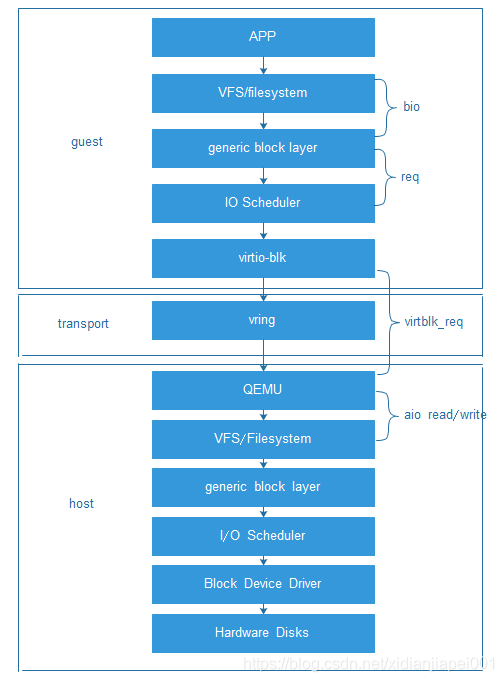
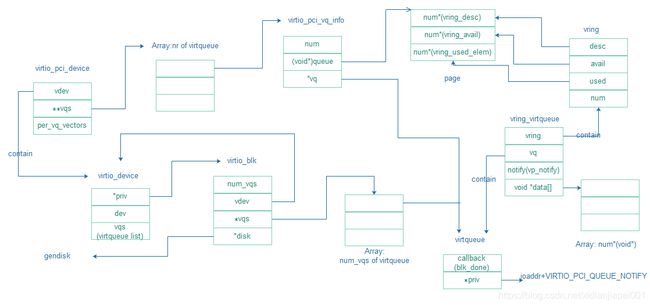
2. 主要数据结构
2.1 前端设备相关的数据结构
struct virtio_device {
/*virtio bus中的唯一表示*/
int index;
/*设备对象*/
struct device dev;
/*设备类型唯一标识,用于识别设备driver*/
struct virtio_device_id id;
/*设备配置操作函数指针*/
struct virtio_config_ops *config;
/*设备virtio_queue,一个设备可以多个,用于数据传输*/
struct list_head vqs;
/*设备和driver支持的特性*/
unsigned long features[1];
/*供driver使用的私有指针*/
void *priv;
};
struct virtio_driver {
/*driver对象*/
struct device_driver driver;
/*driver id*/
const struct virtio_device_id *id_table;
/*这个设备支持的特性列表,以数组形式存在这个表中*/
const unsigned int *feature_table;
/*特性表长度*/
unsigned int feature_table_size;
/*设备发现时调用,0成功,-errono错误*/
int (*probe)(struct virtio_device *dev);
/*设备删除时调用*/
void (*remove)(struct virtio_device *dev);
/*在设备配置发生改变时调用*/
void (*config_changed)(struct virtio_device *dev);
};
static struct bus_type virtio_bus = {
.name = "virtio",
.match = virtio_dev_match,
.dev_attrs = virtio_dev_attrs,
.uevent = virtio_uevent,
.probe = virtio_dev_probe,
.remove = virtio_dev_remove,
};
2.2 传输相关的数据结构
struct virtqueue {
/*设备的vq链表头,一个设备可以有多个vq*/
struct list_head list;
/*当buffer被使用后调用这个callback函数进行通知*/
void (*callback)(struct virtqueue *vq);
const char *name;
/*vq对应的设备*/
struct virtio_device *vdev;
/*私有指针*/
void *priv;
};
struct vring {
unsigned int num;
/*描述符数组*/
struct vring_desc *desc;
/*guest提供给设备的描述符*/
struct vring_avail *avail;
/*指向host使用过的buffers*/
struct vring_used *used;
};
struct vring_desc {
/* Address (guest-physical). */
__u64 addr;
/* Length. */
__u32 len;
/* The flags as indicated above. */
__u16 flags;
/* We chain unused descriptors via this, too */
__u16 next;
};
struct vring_avail {
__u16 flags;
__u16 idx;
__u16 ring[];
};
struct vring_used_elem {
/* Index of start of used descriptor chain. */
__u32 id;
/* Total length of the descriptor chain which was used (written to) */
__u32 len;
};
struct vring_used {
__u16 flags;
__u16 idx;
struct vring_used_elem ring[];
};
struct vring_virtqueue
{
struct virtqueue vq;
/*用于存储数据的数据结构*/
struct vring vring;
/*host是否支持indirect方式*/
bool indirect;
unsigned int free_head;
/*上次同步之后添加的个数*/
unsigned int num_added;
/*最近一次使用的index*/
u16 last_used_idx;
void (*notify)(struct virtqueue *vq);
/*callback函数需要用到的入参*/
void *data[];
};
两个生产者-消费者模型:
前端驱动可以看做请求的生产者和响应的消费者;
后端驱动看做请求的消费者和响应的生产者

2.3 后端相关的数据结构
//proxy类似于前端驱动virtio-pci,框架结构
typedef struct {
PCIDevice pci_dev; //包含虚拟PCI设备信息
VirtIODevice *vdev; //virtio子设备信息
MemoryRegion bar; //IO内存基地址结构
...
VirtIOBlkConf blk; //virtio块设备信息
NICConf nic;
uint32_t host_features; //主机设备信息
...
virtio_serial_conf serial; //串口、网络、scsi等配置信息
...
} VirtIOPCIProxy;
//virtio子设备信息
struct VirtIODevice
{
const char *name; //设备名,块中为virtio-blk
uint8_t status; //设备状态
uint8_t isr; //中断请求
uint16_t queue_sel; //所选队列号
uint32_t guest_features; //客户机特征
size_t config_len; //配置信息长度
...
uint16_t config_vector; //矢量配置
...
uint32_t (*get_features)(VirtIODevice *vdev, uint32_t requested_features);
... //一系列设备状态/配置处理函数
VirtQueue *vq; //虚拟队列,块设备只有一个
const VirtIOBindings *binding; //virtio ops
void *binding_opaque;
...
};
typedef struct VirtIOBlockReq
{
VirtIOBlock *dev;
VirtQueueElement elem; //队列中的散列表元素
//以下三个域与guest中定义对应
struct virtio_blk_inhdr *in;
struct virtio_blk_outhdr *out;
struct virtio_scsi_inhdr *scsi;
QEMUIOVector qiov;
struct VirtIOBlockReq *next; //单链表指针
BlockAcctCookie acct; //统计信息
} VirtIOBlockReq;
struct VirtQueue
{
VRing vring;
/*请求的消费者*/
uint16_t last_avail_idx;
/*队列中正在处理的请求数目*/
int inuse;
...
void (*handle_output)(VirtIODevice *vdev, VirtQueue *vq);
VirtIODevice *vdev;
};
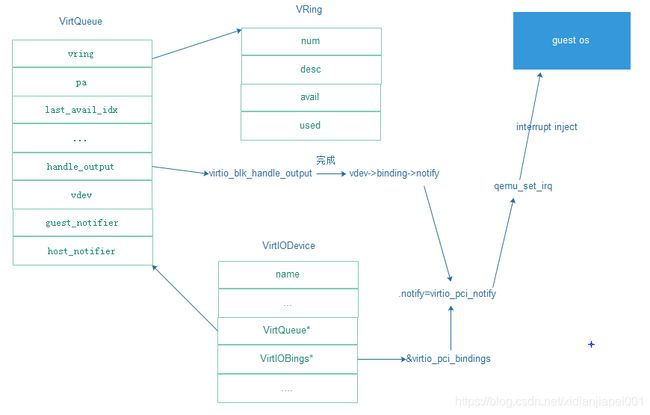
3. 初始化
3.1 前端初始化
Virtio设备遵循linux内核通用的设备模型,bus类型为virtio_bus,对它的理解可以类似PCI设备。设备模型的实现主要在driver/virtio/virtio.c文件中。
- 设备注册
int register_virtio_device(struct virtio_device *dev)
-> dev->dev.bus = &virtio_bus; //填写bus类型
-> err = ida_simple_get(&virtio_index_ida, 0, 0, GFP_KERNEL);//分配一个唯一的设备index标示
-> dev->config->reset(dev); //重置config
-> err = device_register(&dev->dev); //在系统中注册设备
- 驱动注册
int register_virtio_driver(struct virtio_driver *driver)
-> driver->driver.bus = &virtio_bus; //填写bus类型
->driver_register(&driver->driver); //向系统中注册driver
- 设备匹配
virtio_bus. match = virtio_dev_match
//用于甄别总线上设备是否与virtio对应的设备匹配,
//方法是查看设备id是否与driver中保存的id_table中的某个id匹配。
- 设备发现
virtio_bus. probe = virtio_dev_probe
// virtio_dev_probe函数首先是
-> device_features = dev->config->get_features(dev); //获得设备的配置信息
-> // 查找device和driver共同支持的feature,设置dev->features
-> dev->config->finalize_features(dev); //确认需要使用的features
-> drv->probe(dev); //调用driver的probe函数,通常这个函数进行具体设备的初始化,
例如virtio_blk驱动中用于初始化queue,创建磁盘设备并初始化一些必要的数据结构
当virtio后端模拟出virtio_blk设备后,guest os扫描到此virtio设备,然后调用virtio_pci_driver中virtio_pci_probe函数完成pci设备的启动。
注册一条virtio_bus,同时在virtio总线进行注册设备。当virtio总线进行注册设备register_virtio_device,将调用virtio总线的probe函数:virtio_dev_probe()。该函数遍历驱动,找到支持驱动关联到该设备并且调用virtio_driver probe。
virtblk_probe函数调用流程如下:
- virtio_config_val:得到硬件上支持多少个segments(因为都是聚散IO,segment应该是指聚散列表的最大项数),这里需要注意的是头部和尾部个需要一个额外的segment
- init_vq:调用init_vq函数进行virtqueue、vring等相关的初始化设置工作。
- alloc_disk:调用alloc_disk为此虚拟磁盘分配一个gendisk类型的对象
- blk_init_queue:注册queue的处理函数为do_virtblk_request
static int __devinit virtblk_probe(struct virtio_device *vdev)
{
...
/* 得到硬件上支持多少个segments
(因为都是聚散IO,这个segment应该是指聚散列表的最大项数),
这里需要注意的是头部和尾部个需要一个额外的segment */
err = virtio_config_val(vdev, VIRTIO_BLK_F_SEG_MAX,offsetof(struct virtio_blk_config, seg_max),&sg_elems);
...
/* 分配vq,调用virtio_find_single_vq(vdev, blk_done, "requests");
分配单个vq,名字为”request”,注册 的通知函数是blk_done */
err = init_vq(vblk);
/* 调用alloc_disk为此虚拟磁盘分配一个gendisk类型的对象,
对象指针保存在virtio_blk结构的disk 中*/
vblk->disk = alloc_disk(1 << PART_BITS);
/* 分配request_queue结构,从属于virtio-blk的gendisk结构下
初始化gendisk及disk queue,注册queue 的处理函数为do_virtblk_request,
其中queuedata也设置为virtio_blk结构。*/
q = vblk->disk->queue = blk_init_queue(do_virtblk_request, NULL);
...
add_disk(vblk->disk); //使设备对外生效
}
init_vq完成virtqueue和vring的分配,设置队列的回调函数,中断处理函数,流程如下:
-->init_vq
-->virtio_find_single_vq
-->vp_find_vqs
-->vp_try_to_find_vqs
-->setup_vq
-->vring_new_virtqueue
-->request_irq
分配vq的函数init_vq:
static int init_vq(struct virtio_blk *vblk)
{
...
vblk->vq = virtio_find_single_vq(vblk->vdev, blk_done, "requests");
...
}
struct virtqueue *virtio_find_single_vq(struct virtio_device *vdev,vq_callback_t *c, const char *n)
{
vq_callback_t *callbacks[] = { c };
const char *names[] = { n };
struct virtqueue *vq;
/* 调用find_vqs回调函数(对应vp_find_vqs函数,
在virtio_pci_probe中设置)进行具体的设置。
会将相应的virtqueue对象指针存放在vqs这个临时指针数组中 */
int err = vdev->config->find_vqs(vdev, 1, &vq, callbacks, names);
if (err < 0)
return ERR_PTR(err);
return vq;
}
static int vp_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[],
vq_callback_t *callbacks[],
const char *names[])
{
int err;
/* 这个函数中只是三次调用了vp_try_to_find_vqs函数来完成操作,
只是每次想起传送的参数有些不一样,该函数的最后两个参数:
use_msix表示是否使用MSI-X机制的中断、per_vq_vectors表示是否对
每一 个virtqueue使用使用一个中断vector */
/* Try MSI-X with one vector per queue. */
err = vp_try_to_find_vqs(vdev, nvqs, vqs, callbacks, names, true, true);
if (!err)
return 0;
err = vp_try_to_find_vqs(vdev, nvqs, vqs, callbacks, names,true, false);
if (!err)
return 0;
return vp_try_to_find_vqs(vdev, nvqs, vqs, callbacks, names,false, false);
}
Virtio设备中断,有两种产生中断情况:
- 当设备的配置信息发生改变(config
changed),会产生一个中断(称为change中断),中断处理程序需要调用相应的处理函数(需要驱动定义)- 当设备向队列中写入信息时,会产生一个中断(称为vq中断),中断处理函数需要调用相应的队列的回调函数(需要驱动定义)
三种中断处理方式:
1). 不用msix中断,则change中断和所有vq中断共用一个中断irq。
中断处理函数:vp_interrupt。
vp_interrupt函数中包含了对change中断和vq中断的处理。
2). 使用msix中断,但只有2个vector;一个用来对应change中断,一个对应所有队列的vq中断。
change中断处理函数:vp_config_changed
vq中断处理函数:vp_vring_interrupt
3). 使用msix中断,有n+1个vector;一个用来对应change中断,n个分别对应n个队列的vq中断。每个vq一个vector。
static int vp_try_to_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[],
vq_callback_t *callbacks[],
const char *names[],
bool use_msix,
bool per_vq_vectors)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
u16 msix_vec;
int i, err, nvectors, allocated_vectors;
if (!use_msix) {
/* 不用msix,所有vq共用一个irq ,设置中断处理函数vp_interrupt*/
err = vp_request_intx(vdev);
} else {
if (per_vq_vectors) {
nvectors = 1;
for (i = 0; i < nvqs; ++i)
if (callbacks[i])
++nvectors;
} else {
/* Second best: one for change, shared for all vqs. */
nvectors = 2;
}
/*per_vq_vectors为0,设置处理函数vp_vring_interrupt*/
err = vp_request_msix_vectors(vdev, nvectors, per_vq_vectors);
}
for (i = 0; i < nvqs; ++i) {
if (!callbacks[i] || !vp_dev->msix_enabled)
msix_vec = VIRTIO_MSI_NO_VECTOR;
else if (vp_dev->per_vq_vectors)
msix_vec = allocated_vectors++;
else
msix_vec = VP_MSIX_VQ_VECTOR;
vqs[i] = setup_vq(vdev, i, callbacks[i], names[i], msix_vec);
...
/* 如果per_vq_vectors为1,则为每个队列指定一个vector,
vq中断处理函数为vring_interrupt*/
err = request_irq(vp_dev->msix_entries[msix_vec].vector,
vring_interrupt, 0,
vp_dev->msix_names[msix_vec],
vqs[i]);
}
return 0;
}
setup_vq完成virtqueue(主要用于数据的操作)、vring(用于数据的存放)的分配和初始化任务:
static struct virtqueue *setup_vq(struct virtio_device *vdev, unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,u16 msix_vec)
{
struct virtqueue *vq;
/* 写寄存器退出guest,设置设备的队列序号,
对于块设备就是0(最大只能为VIRTIO_PCI_QUEUE_MAX 64) */
iowrite16(index, vp_dev->ioaddr + VIRTIO_PCI_QUEUE_SEL);
/*得到硬件队列的深度num*/
num = ioread16(vp_dev->ioaddr + VIRTIO_PCI_QUEUE_NUM);
...
/* IO同步信息,如虚拟队列地址,会调用virtio_queue_set_addr进行处理*/
iowrite32(virt_to_phys(info->queue) >> VIRTIO_PCI_QUEUE_ADDR_SHIFT,
vp_dev->ioaddr + VIRTIO_PCI_QUEUE_PFN);
...
/* 调用该函数分配vring_virtqueue对象,该结构中既包含了vring、又包含了virtqueue,并且返回 virtqueue对象指针*/
vq = vring_new_virtqueue(info->num, VIRTIO_PCI_VRING_ALIGN,
vdev, info->queue, vp_notify, callback, name);
...
return vq;
}
IO同步信息,如虚拟队列地址,会调用virtio_queue_set_addr进行处理:
virtio_queue_set_addr(vdev, vdev->queue_sel, addr);
--> vdev->vq[n].pa = addr; //n=vdev->queue_sel,即同步队列地址
--> virtqueue_init(&vdev->vq[n]); //初始化后端的虚拟队列
--> target_phys_addr_t pa = vq->pa; //主机vring虚拟首地址
--> vq->vring.desc = pa; //同步desc地址
--> vq->vring.avail = pa + vq->vring.num * sizeof(VRingDesc); //同步avail地址
--> vq->vring.used = vring_align(vq->vring.avail +
offsetof(VRingAvail, ring[vq->vring.num]),
VIRTIO_PCI_VRING_ALIGN); //同步used地址
其中,pa是由客户机传送过来的物理页地址,在主机中就是主机的虚拟页地址,赋值给主机中对应vq中的vring,则同步了主客机中虚拟队列地址,之后vring中的当前可用缓冲描述符avail、已使用缓冲used均得到同步。
分配vring_virtqueue对象由vring_new_virtqueue函数完成:
struct virtqueue *vring_new_virtqueue(unsigned int num,
unsigned int vring_align,
struct virtio_device *vdev,
void *pages,
void (*notify)(struct virtqueue *),
void (*callback)(struct virtqueue *),
const char *name)
{
struct vring_virtqueue *vq;
unsigned int i;
/* We assume num is a power of 2. */
if (num & (num - 1)) {
dev_warn(&vdev->dev, "Bad virtqueue length %u\n", num);
return NULL;
}
/* 调用vring_init函数初始化vring对象,
其desc、avail、used三个域瓜分了上面的
setup_vp函数第一步中分配的内存页面 */
vring_init(&vq->vring, num, pages, vring_align);
/*初始化virtqueue对象(注意其callback会被设置成virtblk_done函数*/
vq->vq.callback = callback;
vq->vq.vdev = vdev;
vq->vq.name = name;
vq->notify = notify;
vq->broken = false;
vq->last_used_idx = 0;
vq->num_added = 0;
list_add_tail(&vq->vq.list, &vdev->vqs);
/* No callback? Tell other side not to bother us. */
if (!callback)
vq->vring.avail->flags |= VRING_AVAIL_F_NO_INTERRUPT;
/* Put everything in free lists. */
vq->num_free = num;
vq->free_head = 0;
for (i = 0; i < num-1; i++) {
vq->vring.desc[i].next = i+1;
vq->data[i] = NULL;
}
vq->data[i] = NULL;
/*返回virtqueue对象指针*/
return &vq->vq;
}
调用vring_init函数初始化vring对象:
static inline void vring_init(struct vring *vr, unsigned int num, void *p,
unsigned long align)
{
vr->num = num;
vr->desc = p;
vr->avail = p + num*sizeof(struct vring_desc);
vr->used = (void *)(((unsigned long)&vr->avail->ring[num] + align-1)& ~(align - 1));
}
3.2 后端初始化
后端驱动的初始化流程实际是后端驱动的数据结构进行初始化,设置PCI设备的信息,并结合到virtio设备中,设置主机状态,配置并初始化虚拟队列,为每个块设备绑定一个虚拟队列及队列处理函数,并绑定设备处理函数,以处理IO请求。
virtio-block后端初始化流程:
type_init(virtio_pci_register_types)
--> type_register_static(&virtio_blk_info) // 注册一个设备结构,为PCI子设备
--> class_init = virtio_blk_class_init,
--> k->init = virtio_blk_init_pci;
static int virtio_blk_init_pci(PCIDevice *pci_dev)
{
VirtIOPCIProxy *proxy = DO_UPCAST(VirtIOPCIProxy, pci_dev, pci_dev);
VirtIODevice *vdev;
...
vdev = virtio_blk_init(&pci_dev->qdev, &proxy->blk);
...
virtio_init_pci(proxy, vdev);
/* make the actual value visible */
proxy->nvectors = vdev->nvectors;
return 0;
}
调用virtio_blk_init来初始化virtio-blk设备,virtio_blk_init代码如下:
VirtIODevice *virtio_blk_init(DeviceState *dev, VirtIOBlkConf *blk)
{
VirtIOBlock *s;
static int virtio_blk_id;
...
/* virtio_common_init初始化一个VirtIOBlock结构,
这里主要是分配一个VirtIODevice 结构并为它赋值,
VirtIODevice结构主要描述IO设备的一些配置接口和属性。
VirtIOBlock结构第一个域是VirtIODevice结构,VirtIOBlock结构
还包括一些其他的块设备属性和状态参数。*/
s = (VirtIOBlock *)virtio_common_init("virtio-blk", VIRTIO_ID_BLOCK,
sizeof(struct virtio_blk_config),
sizeof(VirtIOBlock));
/* 对VirtIOBlock结构中的域赋值,其中比较重要的是对一些virtio
通用配置接口的赋值(get_config,set_config,get_features,set_status,reset),
如此,virtio_blk便 有了自定义的配置。*/
s->vdev.get_config = virtio_blk_update_config;
s->vdev.set_config = virtio_blk_set_config;
s->vdev.get_features = virtio_blk_get_features;
s->vdev.set_status = virtio_blk_set_status;
s->vdev.reset = virtio_blk_reset;
s->bs = blk->conf.bs;
s->conf = &blk->conf;
s->blk = blk;
s->rq = NULL;
s->sector_mask = (s->conf->logical_block_size / BDRV_SECTOR_SIZE) - 1;
/* 初始化vq,virtio_add_queue为设置vq的中vring处理的最大个数是128,
注册 handle_output函数为virtio_blk_handle_output(host端处理函数)*/
s->vq = virtio_add_queue(&s->vdev, 128, virtio_blk_handle_output);
/* qemu_add_vm_change_state_handler(virtio_blk_dma_restart_cb, s);
设置vm状态改 变的处理函数为virtio_blk_dma_restart_cb*/
qemu_add_vm_change_state_handler(virtio_blk_dma_restart_cb, s);
s->qdev = dev;
/* register_savevm注册虚拟机save和load函数(热迁移)*/
register_savevm(dev, "virtio-blk", virtio_blk_id++, 2,
virtio_blk_save, virtio_blk_load, s);
...
return &s->vdev;
}
//初始化vq,调用virtio_add_queue:
VirtQueue *virtio_add_queue(VirtIODevice *vdev, int queue_size,
void (*handle_output)(VirtIODevice *, VirtQueue *))
{
...
vdev->vq[i].vring.num = queue_size; //设置队列的深度
vdev->vq[i].handle_output = handle_output; //注册队列的处理函数
return &vdev->vq[i];
}
初始化virtio-PCI信息,分配bar,注册接口以及接口处理函数;设备绑定virtio-pci的ops,设置主机特征,调用函数virtio_init_pci来初始化virtio-blk pci相关信息:
void virtio_init_pci(VirtIOPCIProxy *proxy, VirtIODevice *vdev)
{
uint8_t *config;
uint32_t size;
...
/* memory_region_init_io():初始化IO内存,
并设置IO内存操作和内存读写函数 virtio_pci_config_ops*/
memory_region_init_io(&proxy->bar, &virtio_pci_config_ops, proxy,"virtio-pci", size);
/*将IO内存绑定到PCI设备,即初始化bar,给bar注册pci地址*/
pci_register_bar(&proxy->pci_dev, 0, PCI_BASE_ADDRESS_SPACE_IO,
&proxy->bar);
if (!kvm_has_many_ioeventfds()) {
proxy->flags &= ~VIRTIO_PCI_FLAG_USE_IOEVENTFD;
}
/*绑定virtio-pci总线的ops并指向设备代理proxy*/
virtio_bind_device(vdev, &virtio pci_bindings, proxy);
proxy->host_features |= 0x1 << VIRTIO_F_NOTIFY_ON_EMPTY;
proxy->host_features |= 0x1 << VIRTIO_F_BAD_FEATURE;
proxy->host_features = vdev->get_features(vdev, proxy->host_features);
}
其中,virtio-pic读写操作为virtio_pci_config_ops:
static const MemoryRegionPortio virtio_portio[] = {
{ 0, 0x10000, 2, .write = virtio_pci_config_writew, },
...
{ 0, 0x10000, 2, .read = virtio_pci_config_readw, },
};
在设备注册完成后,qemu调用io_region_add进行io端口注册:
static void io_region_add(MemoryListener *listener,MemoryRegionSection *section)
{
...
/*io端口信息初始化*/
iorange_init(&mrio->iorange, &memory_region_iorange_ops,
section->offset_within_address_space, section->size);
/*io端口注册*/
ioport_register(&mrio->iorange);
}
ioport_register调用register_ioport_read及register_ioport_write将io端口对应的回调函数保存到ioport_write_table数组中:
int register_ioport_write(pio_addr_t start, int length, int size,IOPortWriteFunc *func, void *opaque)
{
...
for(i = start; i < start + length; ++i) {
/*设置对应端口的回调函数*/
ioport_write_table[bsize][i] = func;
...
}
return 0;
}
内存操作函数:

virtio_bind_device

4. IO处理流程
4.1 前端驱动的IO流程
在物理机中,用户空间发起一个IO请求,会经过文件系统层、通用块层和IO调度层,最后到达块设备驱动层,由驱动层处理请求队列,读取磁盘数据。在虚拟机中,IO请求的过程大致相同,在virtio前端驱动中,request_fn是virtio-blk模块的do_virtblk_request方法。
![]()
GuestOS来了一个IO请求后,会调用IO队列的处理函数do_virtblk_request,流程如下:
do_virtblk_request
--> blk_peek_request
--> do_req
--> sg_set_buf
--> blk_rq_map_sg
--> virtqueue_add_buf
--> vring_add_indirect
--> virtqueue_kick
--> virtqueue_kick_prepare
--> virtqueue_notify
--> vq_notify
--> iowrite16
do_virtblk_request代码如下:
static void do_virtblk_request(struct request_queue *q)
{
struct virtio_blk *vblk = q->queuedata;
struct request *req;
unsigned int issued = 0;
/* 在while循环中blk_peek_request从队列中取一个请求,
然后do_req函数进行请求处 理,blk_start_request从队列
中删除请求并生效时钟(用于请求超时计时) */
while ((req = blk_peek_request(q)) != NULL) {
/* 在IO队列处理函数中调用do_req,它做的主要工作是把IO请求解析后,
放到一个vq的结构体里面,这个vq指的是virtio_queue */
if (!do_req(q, vblk, req)) {
blk_stop_queue(q);
break;
}
...
}
if (issued)
virtqueue_kick(vblk->vq);
}
do_req函数,将req中bio链表中的bio_vec指向的内存页面,转为由vblk中的sg指向,并且初始化virtblk_req结构;它做的主要工作是把IO请求解析后,放到一个vq的结构体里面:
static bool do_req(struct request_queue *q, struct virtio_blk *vblk,struct request *req)
{
unsigned long num, out = 0, in = 0;
struct virtblk_req *vbr;
/* 设置vbr的out_hdr对象(该对象用来向后端描述这次请求),
需要根据request对象的cmd_flags, cmd_type来决定如何设置
out_hdr存放在desc table中的第一项 */
vbr->req = req;
if (req->cmd_flags & REQ_FLUSH) {
vbr->out_hdr.type = VIRTIO_BLK_T_FLUSH;
vbr->out_hdr.sector = 0;
vbr->out_hdr.ioprio = req_get_ioprio(vbr->req);
} else {
switch (req->cmd_type) {
case REQ_TYPE_FS://文件系统请求
vbr->out_hdr.type = 0;
vbr->out_hdr.sector = blk_rq_pos(vbr->req);
vbr->out_hdr.ioprio = req_get_ioprio(vbr->req);
break;
case REQ_TYPE_BLOCK_PC: //scsi命令
vbr->out_hdr.type = VIRTIO_BLK_T_SCSI_CMD;
vbr->out_hdr.sector = 0;
vbr->out_hdr.ioprio = req_get_ioprio(vbr->req);
break;
case REQ_TYPE_SPECIAL:
vbr->out_hdr.type = VIRTIO_BLK_T_GET_ID;
vbr->out_hdr.sector = 0;
vbr->out_hdr.ioprio = req_get_ioprio(vbr->req);
break;
default:
/* We don't put anything else in the queue. */
BUG();
}
}
/* sg_set_buf函数对vblk->sg(scatterlist)进行赋值,
out_hdr中记录着request的总扇区数,IO类型和优先级,
存在散列表的第一个位置 */
sg_set_buf(&vblk->sg[out++], &vbr->out_hdr, sizeof(vbr->out_hdr));
/* 此函数负责从bio构建出一个scatterlist,因为一个request可以对应多个bio,
所以这里处理的不仅仅是传入的bio,还会继续它的下一个bio直到末尾,
将request的bvec映射到散列表 */
num = blk_rq_map_sg(q, vbr->req, vblk->sg + out);
...
/*在散列表的最后一个位置存放request的状态信息vbr->status。*/
sg_set_buf(&vblk->sg[num + out + in++], &vbr->status,sizeof(vbr->status));
if (num) {
if (rq_data_dir(vbr->req) == WRITE) {
vbr->out_hdr.type |= VIRTIO_BLK_T_OUT;//往外送数据
out += num;
} else {
vbr->out_hdr.type |= VIRTIO_BLK_T_IN;//从外部读入数据
in += num;
}
}
/*把发送到消息缓存写到virtqueue队列*/
if (virtqueue_add_buf(vblk->vq, vblk->sg, out, in, vbr) < 0) {
mempool_free(vbr, vblk->pool);
return false;
}
return true;
}
Guest将sg中的内容转由vring_virtqueue中的vring结构来保存,把发送到消息缓存写到virtqueue队列,调用virtqueue_add_buf函数:
int virtqueue_add_buf(struct virtqueue *_vq,struct scatterlist sg[],
unsigned int out,unsigned int in,void *data)
{
struct vring_virtqueue *vq = to_vvq(_vq);
unsigned int i, avail, head, uninitialized_var(prev);
/* 如果支持indirect descriptor table,并且本次需要加入vring的
有超过1个的scatterlist表项,并且vring 中还有空闲的descriptor,
则调用alloc_indirect函数分配一个indirect descriptor table,
将sg中的段存放 到间接描述符表中 */
if (vq->indirect && (out + in) > 1 && vq->num_free) {
head = vring_add_indirect(vq, sg, out, in);
if (head != vq->vring.num)
goto add_head;
}
...
vq->num_free -= out + in;
head = vq->free_head;
/* 这个是将scatterlist中的out和in方向的数据分别添加到desc表中,
其中addr域是数据所在的内存地址,flags= VRING_DESC_F_NEXT
表示这不是表中的最后一项,后面还有值存在,若未设置这个位,
表示这是表中最后一项 */
for (i = vq->free_head; out; i = vq->vring.desc[i].next, out--) {
vq->vring.desc[i].flags = VRING_DESC_F_NEXT;
vq->vring.desc[i].addr = sg_phys(sg); //存放guest中物理地址
vq->vring.desc[i].len = sg->length;
prev = i;
sg++;
}
for (; in; i = vq->vring.desc[i].next, in--) {
vq->vring.desc[i].flags = VRING_DESC_F_NEXT|VRING_DESC_F_WRITE;
vq->vring.desc[i].addr = sg_phys(sg);
vq->vring.desc[i].len = sg->length;
prev = i;
sg++;
}
vq->vring.desc[prev].flags &= ~VRING_DESC_F_NEXT;
/* 调整vring_virtqueue的free_head:根据是否使用indirect
进行调整、调整的幅度肯定不同 */
vq->free_head = i;
add_head:
vq->data[head] = data; //将vbr请求存放在vq->data[head]中
/* 接着把avail表中的下一个idx位置设置为这次填充的数据头部
(即第一个在desc表中的位置)这表示这些数据可以被对端使用了 */
avail = (vq->vring.avail->idx + vq->num_added++) % vq->vring.num;
//更新ring指向刚刚加入的请求
vq->vring.avail->ring[avail] = head;
/* If we're indirect, we can fit many (assuming not OOM). */
if (vq->indirect)
return vq->num_free ? vq->vring.num : 0;
return vq->num_free;
}
如果do_req返回真,调用virtqueue_kick通知后端数据已更新:
void virtqueue_kick(struct virtqueue *vq)
{
if (virtqueue_kick_prepare(vq))
virtqueue_notify(vq);
}
调用virtqueue_kick_prepare看是否需要kick,这个函数主要检查两个条件,一个是flags是否设置为VRING_USED_F_NO_NOTIFY(设置了不通知),另一个是vq->event是否大于0,如果大于0判断是否需要kick,判断函数vring_need_event(__u16 event_idx, __u16 new_idx, __u16 old),event_idx由对端设置在这个里面(used表决定),主要用于批量kick,new_idx - event_idx -1要小于这一批add的总次数才触发kick。
bool virtqueue_kick_prepare(struct virtqueue *_vq)
{
struct vring_virtqueue *vq = to_vvq(_vq);
u16 new, old;
bool needs_kick;
...
old = vq->vring.avail->idx;
new = vq->vring.avail->idx = old + vq->num_added;
vq->num_added = 0;
...
if (vq->event) {
needs_kick = vring_need_event(vring_avail_event(&vq->vring),
new, old);
} else {
needs_kick = !(vq->vring.used->flags & VRING_USED_F_NO_NOTIFY);
}
END_USE(vq);
return needs_kick;
}
如果需要kick则调用virtqueue_notify,这个函数直接调用vq->notify(_vq)来通知对端:
void virtqueue_notify(struct virtqueue *_vq)
{
...
vq->notify(_vq);
}
static void vq_notify(struct virtqueue *vq)
{
...
iowrite16(info->queue_index, vp_dev->ioaddr + VIRTIO_PCI_QUEUE_NOTIFY);
}
4.2 KVM中截获IO
QEMU运行在用户空间,KVM运行在内核空间,客户机运行在KVM内部,QEMU通过IOCTL与KVM进行交互,从这里可以看出,KVM直接与客户机进行交互。所以客户机的IO操作,KVM先得到,可以进行拦截,这个也是我们能实现拦截的前提条件。
虚拟机的VMCS中的设置可以控制一旦执行某个IO指令,立刻发生VMExit。VMExit后返回到vcpu_enter_guest,这个函数接着调用vmx_handle_exit对VMExit进行处理。
static int (*kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_EXCEPTION_NMI] = handle_exception,
[EXIT_REASON_EXTERNAL_INTERRUPT] = handle_external_interrupt,
[EXIT_REASON_TRIPLE_FAULT] = handle_triple_fault,
[EXIT_REASON_NMI_WINDOW] = handle_nmi_window,
[EXIT_REASON_IO_INSTRUCTION] = handle_io,
...
};
static int handle_io(struct kvm_vcpu *vcpu)
{
unsigned long exit_qualification;
int size, in, string;
unsigned port;
++vcpu->stat.io_exits;
exit_qualification = vmcs_readl(EXIT_QUALIFICATION); //获取exit qualification
string = (exit_qualification & 16) != 0; //判断是否为string io (ins, outs)
if (string) {
if (emulate_instruction(vcpu, 0) == EMULATE_DO_MMIO)
return 0;
return 1;
}
size = (exit_qualification & 7) + 1; //大小
in = (exit_qualification & 8) != 0; //判断io方向,是in还是out
port = exit_qualification >> 16; //得到端口号
skip_emulated_instruction(vcpu);
return kvm_emulate_pio(vcpu, in, size, port);
}
int kvm_emulate_pio(struct kvm_vcpu *vcpu, int in, int size, unsigned port)
{
vcpu->run->exit_reason = KVM_EXIT_IO;
vcpu->run->io.direction = in ? KVM_EXIT_IO_IN : KVM_EXIT_IO_OUT;
vcpu->run->io.size = vcpu->arch.pio.size = size;
vcpu->run->io.data_offset = KVM_PIO_PAGE_OFFSET * PAGE_SIZE;
vcpu->run->io.count = vcpu->arch.pio.count = vcpu->arch.pio.cur_count = 1;
vcpu->run->io.port = vcpu->arch.pio.port = port;
vcpu->arch.pio.in = in;
vcpu->arch.pio.string = 0;
vcpu->arch.pio.down = 0;
vcpu->arch.pio.rep = 0;
val = kvm_register_read(vcpu, VCPU_REGS_RAX);
memcpy(vcpu->arch.pio_data, &val, 4);
/* 如果在kmod中能完成io的话,就完成处理,不需要再返回qemu了 */
if (!kernel_pio(vcpu, vcpu->arch.pio_data)) {
complete_pio(vcpu);
return 1;
}
return 0;
}
static int kernel_pio(struct kvm_vcpu *vcpu, void *pd)
{
if (vcpu->arch.pio.in)
r = kvm_io_bus_read(&vcpu->kvm->pio_bus, vcpu->arch.pio.port,
vcpu->arch.pio.size, pd);
else
r = kvm_io_bus_write(&vcpu->kvm->pio_bus, vcpu->arch.pio.port,
vcpu->arch.pio.size, pd);
return r;
}
int kvm_io_bus_read(struct kvm_io_bus *bus, gpa_t addr, int len, void *val)
{
int i;
for (i = 0; i < bus->dev_count; i++)
if (!kvm_iodevice_read(bus->devs[i], addr, len, val))
return 0;
return -EOPNOTSUPP;
}
static inline int kvm_iodevice_read(struct kvm_io_device *dev,gpa_t addr, int l, void *v)
{
return dev->ops->read ? dev->ops->read(dev, addr, l, v) : -EOPNOTSUPP;
}
如果此IO指令可以在内核模式就模拟出来(比如内核模拟PIT和PIC),kernel_pio返回真,就不用切换到用户模式,模拟完成后重新调用vcpu_enter_guest;如果不能在内核空间模拟,就一路返回,直到切换到用户模式,在qemu-kvm的kvm_run函数中调用kvm_handle_io进行IO指令模拟,完成后再次用ioctl(KVM_RUN)请求恢复guest运行。
对IO操作会返回到Qemu的线程上下文中。实际上就是kvm_handle_io这个函数里面。整个拦截过程的流程图:

4.3 QEMU处理IO
KVM虚拟机的设备模拟是在QEMU中实现的,而KVM实现的实质上只是IO的拦截。换句话说,真正的虚拟设备IO地址注册是在QEMU代码里面实现的。
在QEMU中,在初始化我们的硬件设备的时候需要注册我们的IO空间,每种设备都需要注册自己的io指令处理函数到Qemu。在这里有下面两种IO注册方法:
- PIO(port IO) 端口IO
- MMIO(memory may IO)内存映射IO
void ioport_register(IORange *ioport)
{
register_ioport_read(ioport->base, ioport->len, 1,
ioport_readb_thunk, ioport);
register_ioport_read(ioport->base, ioport->len, 2,
ioport_readw_thunk, ioport);
register_ioport_read(ioport->base, ioport->len, 4,
ioport_readl_thunk, ioport);
register_ioport_write(ioport->base, ioport->len, 1,
ioport_writeb_thunk, ioport);
register_ioport_write(ioport->base, ioport->len, 2,
ioport_writew_thunk, ioport);
register_ioport_write(ioport->base, ioport->len, 4,
ioport_writel_thunk, ioport);
ioport_destructor_table[ioport->base] = iorange_destructor_thunk;
}
int register_ioport_write(pio_addr_t start, int length, int size,
IOPortWriteFunc *func, void *opaque)
{
int i, bsize;
if (ioport_bsize(size, &bsize)) {
hw_error("register_ioport_write: invalid size");
return -1;
}
for(i = start; i < start + length; ++i) {
ioport_write_table[bsize][i] = func;
if (ioport_opaque[i] != NULL && ioport_opaque[i] != opaque)
hw_error("register_ioport_write: invalid opaque for address 0x%x", i);
ioport_opaque[i] = opaque;
}
return 0;
}

通过这个函数,实际上把io指令处理函数登记到一个全局的数组(在virtio_portio中设置了各种读写函数)。
切换到用户态后,在kvm_cpu_exec函数中分析退出的原因是由于I/O事件后,调用kvm_handle_io进行处理,再分析kvm_handle_io的流程:
static void kvm_handle_io(uint16_t port, void *data, int direction, int size,uint32_t count)
{
...
for (i = 0; i < count; i++) {
if (direction == KVM_EXIT_IO_IN) {
switch (size) {
case 1:
stb_p(ptr, cpu_inb(port));
break;
}
ptr += size;
}
}
对于退出原因是KVM_EXIT_IO_IN的情况,调用cpu_inb处理。cpu_inb是个封装函数,它的作用就是调用ioport_read.
uint8_t cpu_inb(pio_addr_t addr)
{
uint8_t val;
val = ioport_read(0, addr);
trace_cpu_in(addr, val);
LOG_IOPORT("inb : %04"FMT_pioaddr" %02"PRIx8"\n", addr, val);
return val;
}
static uint32_t ioport_read(int index, uint32_t address)
{
static IOPortReadFunc * const default_func[3] = {
default_ioport_readb,
default_ioport_readw,
default_ioport_readl
};
//初始化pci设备时设置
IOPortReadFunc *func = ioport_read_table[index][address];
if (!func)
func = default_func[index];
return func(ioport_opaque[address], address);
}
void cpu_outb(pio_addr_t addr, uint8_t val)
{
...
ioport_write(0, addr, val);
}
static void ioport_write(int index, uint32_t address, uint32_t data)
{
...
IOPortWriteFunc *func = ioport_write_table[index][address];
...
func(ioport_opaque[address], address, data);
}
static uint32_t ioport_readw_thunk(void *opaque, uint32_t addr)
{
IORange *ioport = opaque;
uint64_t data;
ioport->ops->read(ioport, addr - ioport->base, 2, &data);
return data;
}
const IORangeOps memory_region_iorange_ops = {
.read = memory_region_iorange_read,
.write = memory_region_iorange_write,
.destructor = memory_region_iorange_destructor,
};
static void memory_region_iorange_write(IORange *iorange,
uint64_t offset,
unsigned width,
uint64_t data)
{
MemoryRegionIORange *mrio
= container_of(iorange, MemoryRegionIORange, iorange);
MemoryRegion *mr = mrio->mr;
offset += mrio->offset;
if (mr->ops->old_portio) {
const MemoryRegionPortio *mrp = find_portio(mr, offset - mrio->offset,width, true);
if (mrp) {
mrp->write(mr->opaque, offset, data);
} else if (width == 2) {
mrp = find_portio(mr, offset - mrio->offset, 1, true);
assert(mrp);
mrp->write(mr->opaque, offset, data & 0xff);
mrp->write(mr->opaque, offset + 1, data >> 8);
}
return;
}
access_with_adjusted_size(offset, &data, width,
mr->ops->impl.min_access_size,
mr->ops->impl.max_access_size,
memory_region_write_accessor, mr);
}
static void access_with_adjusted_size(target_phys_addr_t addr,
uint64_t *value,unsigned size,unsigned access_size_min,
unsigned access_size_max,void (*access)(void *opaque,
target_phys_addr_t addr,uint64_t *value,unsigned size,unsigned shift,
uint64_t mask),void *opaque)
{
uint64_t access_mask;
unsigned access_size;
unsigned i;
if (!access_size_min) {
access_size_min = 1;
}
if (!access_size_max) {
access_size_max = 4;
}
access_size = MAX(MIN(size, access_size_max), access_size_min);
access_mask = -1ULL >> (64 - access_size * 8);
for (i = 0; i < size; i += access_size) {
/* FIXME: big-endian support */
access(opaque, addr + i, value, access_size, i * 8, access_mask);
}
}
static void memory_region_write_accessor(void *opaque,
target_phys_addr_t addr,
uint64_t *value,
unsigned size,
unsigned shift,
uint64_t mask)
{
MemoryRegion *mr = opaque;
uint64_t tmp;
tmp = (*value >> shift) & mask;
mr->ops->write(mr->opaque, addr, tmp, size);
}
以virtio_pci_config_writew为例,调用IO端口注册时,将端口的回调函数保存在ioport_write_table数组中。回调写函数virtio_ioport_write:
static void virtio_ioport_write(void *opaque, uint32_t addr, uint32_t val)
{
VirtIOPCIProxy *proxy = opaque;
VirtIODevice *vdev = proxy->vdev;
target_phys_addr_t pa;
switch (addr) {
...
case VIRTIO_PCI_QUEUE_PFN:
pa = (target_phys_addr_t)val << VIRTIO_PCI_QUEUE_ADDR_SHIFT;
if (pa == 0) {
virtio_pci_stop_ioeventfd(proxy);
virtio_reset(proxy->vdev);
msix_unuse_all_vectors(&proxy->pci_dev);
}
else
virtio_queue_set_addr(vdev, vdev->queue_sel, pa);
break;
...
case VIRTIO_PCI_QUEUE_NOTIFY:
if (val < VIRTIO_PCI_QUEUE_MAX) {
//通过val可得到相应的virtio设备的队列
virtio_queue_notify(vdev, val);
}
break;
...
}
}
IO内存基址由主机分配,virtio中主要有24byte的控制字段,根据对应的控制字段进行相应的操作。VIRTIO_PCI_QUEUE_NOTIFY控制字段,对应的操作virtio_queue_notify(vdev, val)(vdev是虚拟设备,val是虚拟队列的序号0)
void virtio_queue_notify(VirtIODevice *vdev, int n)
{
virtio_queue_notify_vq(&vdev->vq[n]);
}
void virtio_queue_notify_vq(VirtQueue *vq)
{
if (vq->vring.desc) {
...
vq->handle_output(vdev, vq);
}
}
static void virtio_blk_handle_output(VirtIODevice *vdev, VirtQueue *vq)
{
VirtIOBlock *s = to_virtio_blk(vdev);
VirtIOBlockReq *req;
/* 处理写请求的时候会用到MultiReqBuffer结构,
这个接口将多个request放入一个数组中一次进行处理,
当不超过32个请求时,handle_write仅仅对这个结构进行填充操作,
当存满32个之后,调用 virtio_submit_multiwrite对请求进行处理 */
MultiReqBuffer mrb = {
.num_writes = 0,
};
/* 在while循环中首先通过virtio_blk_get_request函数来取得请求,
然后调用virtio_blk_handle_request函数来处理请求,
这个函数中根据不同的情况会对作出不同的处理 */
while ((req = virtio_blk_get_request(s))) {
virtio_blk_handle_request(req, &mrb);
}
/*没有连续的32个请求,将传入的参数mrb中缓存的请求提交出去 */
virtio_submit_multiwrite(s->bs, &mrb);
}
在virtio_blk_handle_output中,将经过如下流程,最终调用pread/pwrite来完成IO:
virtio_blk_handle_output
--> virtio_blk_get_request
--> virtio_blk_handle_request
--> virtio_blk_handle_write
--> virtio_submit_multiwrite
--> bdrv_aio_multiwrite
--> multiwrite_merge
--> bdrv_aio_writev
--> bdrv_co_aio_rw_vector
--> bdrv_co_do_rw
--> bdrv_co_do_writev
--> drv->bdrv_co_writev
--> raw_co_writev
--> bdrv_co_writev_em
--> bdrv_co_io_em
--> bs->drv->bdrv_aio_writev
--> raw_aio_writev
--> raw_aio_submit
--> paio_submit
--> qemu_paio_submit
--> spawn_thread();
--> qemu_bh_schedule
--> spawn_thread_bh_fn
--> do_spawn_thread
--> thread_create
--> aio_thread
--> handle_aiocb_rw
--> handle_aiocb_rw_linear
--> pwrite/pread
从vq中取出请求,调用函数virtio_blk_get_request:
static VirtIOBlockReq *virtio_blk_get_request(VirtIOBlock *s)
{
if (req != NULL) {
if (!virtqueue_pop(s->vq, &req->elem)) {
g_free(req);
return NULL;
}
}
return req;
}
调用virtqueue_pop函数从vring中取出一个请求,这个请求中的信息将传递到req的elem域中:
int virtqueue_pop(VirtQueue *vq, VirtQueueElement *elem)
{
unsigned int i, head, max;
target_phys_addr_t desc_pa = vq->vring.desc;
max = vq->vring.num;
if (!virtqueue_num_heads(vq, vq->last_avail_idx))
return 0;
/* When we start there are none of either input nor output. */
elem->out_num = elem->in_num = 0;
max = vq->vring.num;
/*取出要处理的第一个head,同时递加last_avail_idx */
i = head = virtqueue_get_head(vq, vq->last_avail_idx++);
if (vring_desc_flags(desc_pa, i) & VRING_DESC_F_INDIRECT) {
/* 间接表的长度是存放在 vring_desc_len(desc_pa, i) */
max = vring_desc_len(desc_pa, i) / sizeof(VRingDesc);
desc_pa = vring_desc_addr(desc_pa, i);
i = 0;
}
/* Collect all the descriptors */
do {
struct iovec *sg;
/* 如果设置了VRING_DESC_F_WRITE,
则对于guest来说这是一片用来接收数据的区域
(比如说read时候指定一些内存片段用来接收数据),
将该片段的地址(此处应该是转换了之后的Guest的物理地址gpa)
存放在in_addr中、该片段的长度放在in_sg中;
否则将该片段的地址放在out_addr中、长度 放在out_sg中 */
if (vring_desc_flags(desc_pa, i) & VRING_DESC_F_WRITE) {
elem->in_addr[elem->in_num] = vring_desc_addr(desc_pa, i);
sg = &elem->in_sg[elem->in_num++];
} else {
elem->out_addr[elem->out_num] = vring_desc_addr(desc_pa, i);
sg = &elem->out_sg[elem->out_num++];
}
sg->iov_len = vring_desc_len(desc_pa, i);
} while ((i = virtqueue_next_desc(desc_pa, i, max)) != max);
/* 此时放在iov_base中的地址是Qemu的虚拟地址(hva),
该函数中会调用cpu_physical_memory_map函数从上面的gpa得到对应的hva */
virtqueue_map_sg(elem->in_sg, elem->in_addr, elem->in_num, 1);
virtqueue_map_sg(elem->out_sg, elem->out_addr, elem->out_num, 0);
/* 取出要处理的第一个head 记录当前正在处理的请求 */
elem->index = head;
/* 正在请求的处理数加1 */
vq->inuse++;
return elem->in_num + elem->out_num;
}
调用virtio_blk_handle_request处理从vq中取出的请求:
static void virtio_blk_handle_request(VirtIOBlockReq *req,MultiReqBuffer *mrb)
{
uint32_t type;
req->out = (void *)req->elem.out_sg[0].iov_base;
req->in = (void *)req->elem.in_sg[req->elem.in_num - 1].iov_base;
type = ldl_p(&req->out->type);
if (type & VIRTIO_BLK_T_FLUSH) {
virtio_blk_handle_flush(req, mrb);
} else if (type & VIRTIO_BLK_T_SCSI_CMD) {
virtio_blk_handle_scsi(req);
} else if (type & VIRTIO_BLK_T_GET_ID) {
VirtIOBlock *s = req->dev;
/*填写内容并完成请求(这个主要获取设备id)*/
strncpy(req->elem.in_sg[0].iov_base,
s->blk->serial ? s->blk->serial : "",
MIN(req->elem.in_sg[0].iov_len, VIRTIO_BLK_ID_BYTES));
virtio_blk_req_complete(req, VIRTIO_BLK_S_OK);
g_free(req);
} else if (type & VIRTIO_BLK_T_OUT) {
/* 通过type判断读请求还是写请求之后,分别使用读写请求
的sg设置req的QEMUIOVector对象(不包括hdr头和status尾)*/
qemu_iovec_init_external(&req->qiov, &req->elem.out_sg[1],req->elem.out_num - 1);
virtio_blk_handle_write(req, mrb);
} else {
qemu_iovec_init_external(&req->qiov, &req->elem.in_sg[0],req->elem.in_num - 1);
virtio_blk_handle_read(req);
}
}
对于写请求,调用virtio_blk_handle_write进行处理:
static void virtio_blk_handle_write(VirtIOBlockReq *req, MultiReqBuffer *mrb)
{
BlockRequest *blkreq;
uint64_t sector;
/* 对应写操作,如果磁盘块连续,最多可以对32个写请求进行合并,
合并后再提交到QEMU的通用块 */
if (mrb->num_writes == 32) {
virtio_submit_multiwrite(req->dev->bs, mrb);
}
blkreq = &mrb->blkreq[mrb->num_writes];
blkreq->sector = sector;
blkreq->nb_sectors = req->qiov.size / BDRV_SECTOR_SIZE; //将长度转换为扇区
blkreq->qiov = &req->qiov;
blkreq->cb = virtio_blk_rw_complete;
blkreq->opaque = req;
blkreq->error = 0;
mrb->num_writes++;
}
当所有队列处理完毕,或者msr达到一次处理请求的上限(32个写请求),则合并qiov指向的sg,将合并的sg缓冲区调用virtio_submit_multiwrite进行处理。
static void virtio_submit_multiwrite(BlockDriverState *bs, MultiReqBuffer *mrb)
{
int i, ret;
...
ret = bdrv_aio_multiwrite(bs, mrb->blkreq, mrb->num_writes);
...
mrb->num_writes = 0;
}
请求完成的回调函数virtio_blk_rw_complete:
static void virtio_blk_rw_complete(void *opaque, int ret)
{
VirtIOBlockReq *req = opaque;
/* 正常完成的请求则调用virtio_blk_req_complete将请求
push进vq(填充used表),然后调用virtio_notify触发中断通知对端,
在host返回到guest时中断会被inject到guest */
virtio_blk_req_complete(req, VIRTIO_BLK_S_OK);
bdrv_acct_done(req->dev->bs, &req->acct);
g_free(req);
}
virtio-blk数据处理完成,把结果放入队列中,
static void virtio_blk_req_complete(VirtIOBlockReq *req, int status)
{
VirtIOBlock *s = req->dev;
trace_virtio_blk_req_complete(req, status);
stb_p(&req->in->status, status); //更新请求的status域
virtqueue_push(s->vq, &req->elem, req->qiov.size + sizeof(*req->in));
/* 宿主机发送中断通知客户机 */
virtio_notify(&s->vdev, s->vq);
}
调用virtqueue_push环形缓存解映射,设置vring.used:
void virtqueue_push(VirtQueue *vq, const VirtQueueElement *elem,unsigned int len)
{
/* 取消内存映射,更新 ring[idx]中的 id 和 len 字段 */
virtqueue_fill(vq, elem, len, 0);
/* 更新 vring_used 中的 idx */
virtqueue_flush(vq, 1);
}
void virtqueue_fill(VirtQueue *vq, const VirtQueueElement *elem,
unsigned int len, unsigned int idx)
{
unsigned int offset;
int i;
for (i = 0; i < elem->in_num; i++) {
size_t size = MIN(len - offset, elem->in_sg[i].iov_len);
cpu_physical_memory_unmap(elem->in_sg[i].iov_base,
elem->in_sg[i].iov_len,
1, size);
offset += elem->in_sg[i].iov_len;
}
for (i = 0; i < elem->out_num; i++)
cpu_physical_memory_unmap(elem->out_sg[i].iov_base,
elem->out_sg[i].iov_len,
0, elem->out_sg[i].iov_len);
idx = (idx + vring_used_idx(vq)) % vq->vring.num;
/* Get a pointer to the next entry in the used ring. */
vring_used_ring_id(vq, idx, elem->index);
vring_used_ring_len(vq, idx, len);
}
void virtqueue_flush(VirtQueue *vq, unsigned int count)
{
uint16_t old, new;
...
old = vring_used_idx(vq);
new = old + count;
vring_used_idx_set(vq, new);
vq->inuse -= count;
...
}
调用virtio_notify通知客户端描述符已经可用,virtio_notify流程:
virtio_notify
--> virtio_notify_vector
--> vdev->binding->notify
--> virtio_pci_notify
--> qemu_set_irq //注入中断
void virtio_notify(VirtIODevice *vdev, VirtQueue *vq)
{
...
vdev->isr |= 0x01; //开中断isr=1
virtio_notify_vector(vdev, vq->vector);
}
static void virtio_notify_vector(VirtIODevice *vdev, uint16_t vector)
{
/* virtio_pci_notify */
if (vdev->binding->notify) {
vdev->binding->notify(vdev->binding_opaque, vector);
}
}
主机处理完IO请求后,会通过生成并注入中断的形式通知客户机,再次进入客户机之后,会相应中断请求。
static void virtio_pci_notify(void *opaque, uint16_t vector)
{
VirtIOPCIProxy *proxy = opaque;
if (msix_enabled(&proxy->pci_dev))
msix_notify(&proxy->pci_dev, vector);
else
qemu_set_irq(proxy->pci_dev.irq[0], proxy->vdev->isr & 1); //注入中断
}
4.4 Guest中接收到中断,进行处理
根据不同的中断方式有3种对应的中断处理函数,分别是vp_interrupt、vp_vring_interrupt、vring_interrupt。
vp_interrupt 函数
- ioread8(vp_dev->ioaddr + VIRTIO_PCI_ISR):读中断状态寄存器,判断是否有中断,并清空中断位
- 没有中断,返回IRQ_NONE
- 如果是配置信息改变,则调用vp_config_changed,否则,调用vp_vring_interrupt,调用vring_interrupt进行处理
vring_interrupt 函数
- More_used:判断是否有处理完成的结果返回,如果没有,则返回IRQ_NONE
- 调用请求完成回调函数blk_done
主机处理完IO请求后,会通过生成并注入中断的形式通知客户机,再次进入客户机之后,会响应中断请求。在前端驱动模块初始化时,就已经指定了virtio-pci的中断处理函数,处理过程如下:
vring_interrupt
--> more_used
--> blk_done
--> virtqueue_get_buf
--> detach_buf
--> __blk_end_request_all
请求回调函数blk_done:
static void blk_done(struct virtqueue *vq)
{
struct virtio_blk *vblk = vq->vdev->priv;
struct virtblk_req *vbr;
unsigned int len;
unsigned long flags;
spin_lock_irqsave(vblk->disk->queue->queue_lock, flags);
while ((vbr = virtqueue_get_buf(vblk->vq, &len)) != NULL) {
switch (vbr->status) {
case VIRTIO_BLK_S_OK:
error = 0;
break;
...
}
//结束一个请求,0表示成功结束请求,非0表示不能成功结束请求
__blk_end_request_all(vbr->req, error);
mempool_free(vbr, vblk->pool);
}
/* In case queue is stopped waiting for more buffers. */
blk_start_queue(vblk->disk->queue);
spin_unlock_irqrestore(vblk->disk->queue->queue_lock, flags);
}
void *virtqueue_get_buf(struct virtqueue *_vq, unsigned int *len)
{
struct vring_virtqueue *vq = to_vvq(_vq);
void *ret;
unsigned int i;
/* 首先调用more_used函数,判断是否有处理完成的结果返回,如果没有,返回NULL */
if (!more_used(vq)) {
pr_debug("No more buffers in queue\n");
END_USE(vq);
return NULL;
}
/*取出对应要释放描述符表的head*/
i = vq->vring.used->ring[vq->last_used_idx%vq->vring.num].id;
*len = vq->vring.used->ring[vq->last_used_idx%vq->vring.num].len;
...
/* detach_buf clears data, so grab it now. */
ret = vq->data[i];
/*释放描述符*/
detach_buf(vq, i);
vq->last_used_idx++; //更新vq->last_used_id,指向下一个需要释放的返回结果
...
return ret;
}
detach_buf 释放buffer在表中占用的资源;解除desc表中的链表关系,如果是VRING_DESC_F_INDIRECT的,还需要释放INDIRECT表;同时要更新空闲desc表的表头和个数。
static void detach_buf(struct vring_virtqueue *vq, unsigned int head)
{
unsigned int i;
/* Clear data ptr. */
vq->data[head] = NULL;
/* Put back on free list: find end */
i = head;
/* Free the indirect table */
if (vq->vring.desc[i].flags & VRING_DESC_F_INDIRECT)
kfree(phys_to_virt(vq->vring.desc[i].addr));
while (vq->vring.desc[i].flags & VRING_DESC_F_NEXT) {
i = vq->vring.desc[i].next;
vq->num_free++;
}
vq->vring.desc[i].next = vq->free_head;
vq->free_head = head;
/* Plus final descriptor */
vq->num_free++;
}
- __blk_end_request_all:结束一个请求,0表示成功结束请求,非0表示不能成功结束请求
- blk_start_queue:重启一个暂停的queue
5. IO环的同步
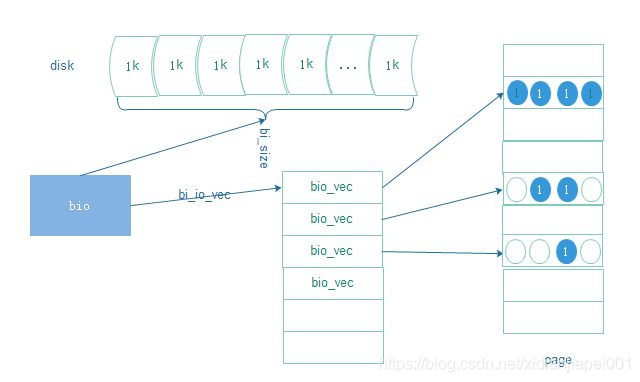
Vring主要由一个128项的描述符表,available ring和used ring构成,描述符表的目的就是为了存放scatterlist指向数据的地址和长度,描述符表中只存数据在guest中的物理地址,不存数据,且地址指向的长度不超过4K。例如, 一个7K的bio:
对于聚散IO,可以在一次调用过程中将多个缓冲区的数据写入到一个数据流,或者从一个数据读取数据到多个缓冲区。聚散是指从多个缓冲区中收集数据,或者向多个缓冲区散发数据的过程。
单个bio请求的在物理扇区上一定是连续的,但是在内存中不一定是连续的。一个bio包含多个bio_vec,每个bio_vec指向一个page中的部分和全部数据。
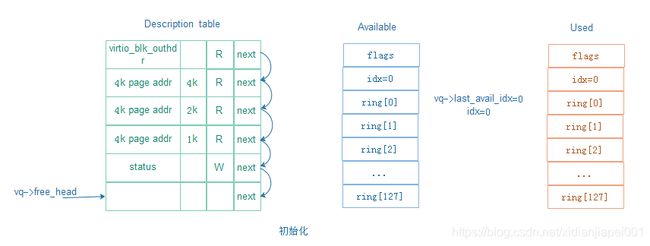
初始化的IO流程图解:

5.1 virtqueue_add_buf
提交一个8KB的写请求后:
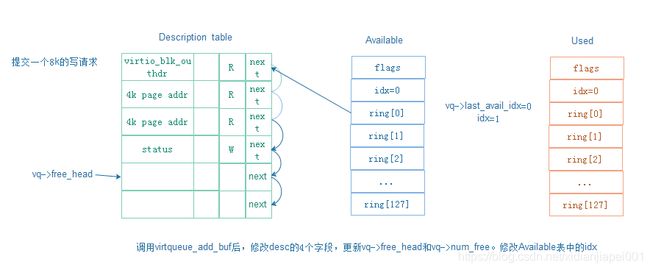
5.2 virtqueue_pop
Qemu中将vq中的写请求取出:
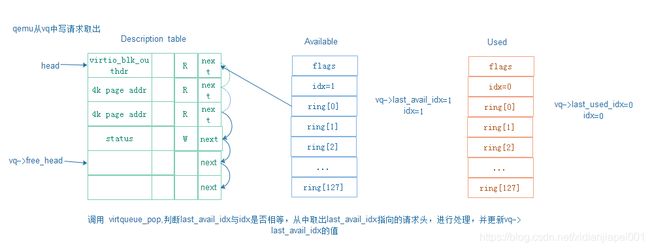
5.3 virtqueue_push
Qemu将取出的写请求发送到底层磁盘进行处理完成后,更新vring:
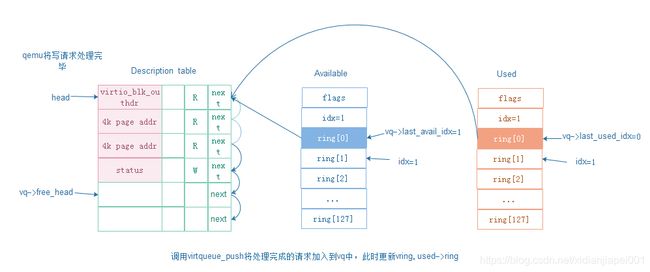
5.4 virtqueue_get_buf
处理完成请求后,通过注入中断通知guest请求完成,

