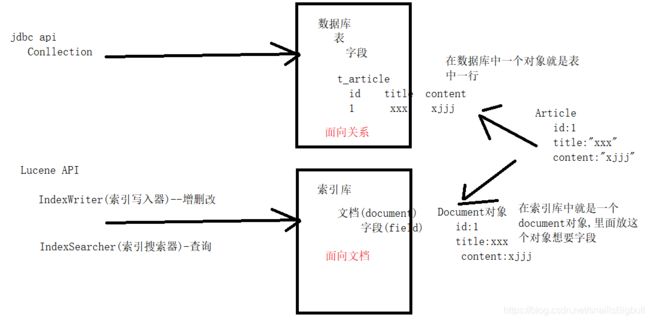
全文检索 Lucene API lucene.util 高亮(前台显示不同的颜色)
一 为什么需要全文检索-数据库模糊查询有弊端
二 全文检索介绍
2.1 什么是全文检索
对非结构化数据搜索.
先对文本数据创建全文索引,再进行搜索的方式就叫全文检索
2.2 优点
就是数据库模糊查询缺点:
1.查询效率低
2..查询效果不好
3.文本数据中没有相关度排序
4.没有摘要截取
5.关键字没有高亮
2.3 常见产品
核心:lucene--工具包
扩展:ElasticSearch,sorl-全文检索服务器
三 lucene简介
lucene 实现全文检索架构

3.1 是什么
apache提供一个全文检索工具包
3.2 核心
1)创建索引
分词–语法处理(时态,人称等处理)-排序-去重 建立单词与句子之间一一对应关系
2)搜索索引
输入查询条件–条件进行分词–分别查询得到编号—通过编号查询得到真正内容
四 lucene入门
4.1 核心api-操作的都是文档(Document)
IndexWriter:增删改
IndexSearcher:查询
4.2 步骤分析
1)创建普通java项目
2)导入jar
3)测试





①创建索引
创建IndexWriter
创建document
使用IndexWriter把document
将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
那么索引里面究竟存的什么,以及如何创建索引呢?在这通过下面的例子来解答这个问题。
首先构造三个不同的句子,有长有短:

在①处分别为3个句子加上编号,然后进行分词,把被一个单词分解出来与编号对应放在②处;在搜索的过程总,对于搜索的过程中大写和小写指的都是同一个单词,在这就没有区分的必要,按规则统一变为小写放在③处;要加快搜索速度,就必须保证这些单词的排列时有一定规则,这里按照字母顺序排列后放在④处;最后再简化索引,合并相同的单词,就得到如下结果:

通常在数据库中我们都是根据文档找到内容,而这里是通过词,能够快速找到包含他的文档,这就是文档倒排链表。
索引搜索
就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
 比如我们要搜索java world两个关键词,符合java的有1,2两个文档,符合world的有1,3两个文档,在搜索引擎中直接这样排列两个词他们之间是OR的关系,出现其中一个都可以被找到,所以这里3个都会出来。全文检索中是有相关性排序的,那么结果在是怎么排列的呢?hello java world中包含两个关键字排在第一,另两个都包含一个关键字,得到结果,hello lucene world排在第二,java在最长的句子中占的权重最低排在结果集的第三。从这里可以看出相关度排序还是有一定规则的。
比如我们要搜索java world两个关键词,符合java的有1,2两个文档,符合world的有1,3两个文档,在搜索引擎中直接这样排列两个词他们之间是OR的关系,出现其中一个都可以被找到,所以这里3个都会出来。全文检索中是有相关性排序的,那么结果在是怎么排列的呢?hello java world中包含两个关键字排在第一,另两个都包含一个关键字,得到结果,hello lucene world排在第二,java在最长的句子中占的权重最低排在结果集的第三。从这里可以看出相关度排序还是有一定规则的。
②搜索索引
1、输入搜索条件
2、封装查询条件为查询对象--通过QuerParser可以把一个字符串转换为一个查询对象
3、创建索引查询器IndexSearcher
4、通过IndexSearcher传入查询对象进行查询得到的文档编号
5、通过文档编号获取文档document
6、把document转换为article对象返回就ok了。
五 luceneAPI详见
5.1 Directory
Directory表示索引目录,里面放的索引文件,这些文件我们是看不懂的,lucene自己维护的.
本身是一个抽象类,常见的实现如下:
RAMDirectory:内存目录
FSDirectory:文件系统目录(磁盘)
SimpleFSDirectory windows
MMapDirectory 支持内存映射
NIOFSDirectory linux
正常情况来说,我们要根据运行环境选择合适Directory来使用,其实可以写代码做兼容.非常happay,lucene已经帮我们写了
public static FSDirectory open(Path path, LockFactory lockFactory) throws IOException {
if (Constants.JRE_IS_64BIT && MMapDirectory.UNMAP_SUPPORTED) {
return new MMapDirectory(path, lockFactory);
} else {
return (FSDirectory)(Constants.WINDOWS ? new SimpleFSDirectory(path, lockFactory) : new NIOFSDirectory(path, lockFactory));
}
}
5.2 Analyzer
Analyzer分词器,用来对我们文本进行分词,官方都对中文支持不友好,我们需要使用三方ikAnalyzer
1)导入jar并且拷贝配置文件
2)简单测试
3)详细测试
/**
* 配置停止词
* 配置扩展词
* @throws Exception
*/
@Test
public void test()throws Exception{
//userSmart为true走最大匹配原则,有大不要小的
//userSmart为false,默认值,细粒度匹配
testAnalyzer(new IKAnalyzer(false),str);
}
}
5.3 Document&Field
1) Document表示文档,在lucene所有的增删改查都是对Document的操作,java中对象要想保存到索引库中
就要转换为document对象,java中对象的一个属性就是document对象的一个字段(field)
Document提供的方法主要包括:
字段添加:add(Fieldable field)
字段删除:removeField、removeFields
获取字段或值:get、getBinaryValue、getField、getFields等
2) Field:IndexableField
字段,对应对象的一个属性.IndexableField是一个接口,可以用它的子类
Field,通过类型标识索引的特性
type.setStored(false); //是否存储 看最终是否拿出来使用
type.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS); //创建索引的方式 IndexOptions.NONE 把创建索引 其他都要创建索引(只是方式不同而已)
type.setTokenized(false); //是否分词 看是做精确查询还是做模糊查询
其实不直接使用 Field,再用field子类就ok,比如说StringField(不分词字符串),TextField分词字符串,LongField(id)等
5.4 DocumentCRUD
* IndexWriter的方法
* 添加:addDocument
* 删除:deleteAll deleteDocument(term,query)
* 修改:updateDocument(term,new Doc) 先删除后添加
* IndexSearcher
查询: doc(docId)
5.5 常见查询
1)单词查询
2)组合查询
Helloworld
 Lucene的索引库和数据库一样,都提供相应的API来便捷操作。
Lucene的索引库和数据库一样,都提供相应的API来便捷操作。
Lucene中的索引维护使用IndexWriter,由这个类提供添删改相关的操作;索引的搜索则是使用IndexSearcher进行索引的搜索。HelloWorld代码如下,导入两个jar包:
lucene-analyzers-common-5.5.0.jar
lucene-core-5.5.0.jar,
lucene-queryparser-5.5.0.jar


IK分词器


IK停止词。需要就到网上一搜,拷贝就好了。
![]()
扩展词
![]()

1.创建索引
步骤:
1、把文本内容转换为Document对象
2、准备IndexWriter(索引写入器)
3、通过IndexWriter,把Document添加到缓冲区并提交
//创建索引的数据 现在写死,以后根据实际应用场景
String doc1 = "hello world";
String doc2 = "hello java world";
String doc3 = "hello lucene world";
//创建一个路径
private String path ="F:/eclipse/workspace/lucene/index/hello";
@Test
public void testCreate() {
try {
//2、准备IndexWriter(索引写入器)
//索引库的位置 FS fileSystem FSDirectory 抽象类的抽象方法
Directory d = FSDirectory.open(Paths.get(path ));
//分词器
Analyzer analyzer = new SimpleAnalyzer();
//索引写入器的配置对象指定分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(d, conf);
System.out.println(indexWriter);
//1、 把文本内容转换为Document对象
//把文本转换为document对象
Document document1 = new Document();
//标题字段
document1.add(new TextField("title", "doc1", Store.YES));
document1.add(new TextField("content", doc1, Store.YES));
//添加document到缓冲区
indexWriter.addDocument(document1);
Document document2 = new Document();
//标题字段 TextField 要 分词 StringField不分词
document2.add(new TextField("title", "doc2", Store.YES));
document2.add(new TextField("content", doc2, Store.YES));
//添加document到缓冲区
indexWriter.addDocument(document2);
Document document3 = new Document();
//标题字段
document3.add(new TextField("title", "doc3", Store.YES));
document3.add(new TextField("content", doc3, Store.YES));
//3 、通过IndexWriter,把Document添加到缓冲区并提交
//添加document到缓冲区
indexWriter.addDocument(document3);
indexWriter.commit();
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
看不懂文件,用luke
![]()




2.搜索索引
1 封装查询提交为查询对象(搜索条件)
2 准备IndexSearcher
3 使用IndexSearcher传入查询对象做查询-----查询出来只是文档编号DocID
4 通过IndexSearcher传入DocID获取文档
5 把文档转换为前台需要的对象


@Test
public void testSearch() {
String keyWord = "lucene";
try {
// * 1 封装查询提交为查询对象
//通过查询解析器解析一个字符串为查询对象
String f = "content"; //查询的默认字段名,
Analyzer a = new SimpleAnalyzer();//查询关键字要分词,所有需要分词器
QueryParser parser = new QueryParser(f, a);//查询解析器解析
Query query = parser.parse("content:"+keyWord);
// * 2 准备IndexSearcher
Directory d = FSDirectory.open(Paths.get(path ));
IndexReader r = DirectoryReadder.open(d);//通过读入器读入索引库里面的内容,才能查询
IndexSearcher searcher = new IndexSearcher(r);
// * 3 使用IndexSearcher传入查询对象做查询-----查询出来只是文档编号DocID
TopDocs topDocs = searcher.search(query, 1000);//查询topn条记录 前多少条记录
System.out.println("总命中数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;//命中的所有的文档的封装(docId)
// * 4 通过IndexSearcher传入DocID获取文档
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
Document document = searcher.doc(docId);
// * 5 把文档转换为前台需要的对象 Docment----> Article
System.out.println("=======================================");
System.out.println("title:"+document.get("title")
+",content:"+document.get("content"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
Lucene API详解
1.索引目录Directory
Directory是一个对索引目录的一个抽象。索引目录用于存放lucene索引文件。直接根据一个文件夹地址来创建索引目录使用SimpleFSDirectory。
MMapDirectory : 针对64系统,它在维护索引库时,会结合“内存”与硬盘同步来处理索引。
SimpleFSDirectory : 传统的文件系统索引库。
RAMDirectory : 内存索引库
2.Document及Field

当往索引中加入内容的时候,每一条信息用一个Document来表示,Document的意思表示文档,也可以理解成记录,与关系数据表中的一行数据记录类似;
Field表示域,与关系数据表中的列类似(但是域的个数不确定/散列),每个Document也由一系列的Field组成,可以理解为数据库的动态列;

Document提供的方法主要包括:
字段添加:add(Fieldable field)
字段删除:removeField、removeFields
获取字段或值:get、getBinaryValue、getField、getFields等
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
1.Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
是否分词(tokenized)
是:作分词处理,即将Field值进行分词,分词的目的是为了索引。
比如:商品名称、商品简介等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元索引。
否:不作分词处理
比如:商品id、订单号、身份证号等
是否索引(indexed)
是:进行索引。将Field分词后的词或整个Field值进行索引,索引的目的是为了搜索。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
否:不索引。该域的内容无法搜索到
比如:商品id、文件路径、图片路径等,不用作为查询条件的不用索引。
是否存储(stored)
是:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取。
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
否:不存储Field值,不存储的Field无法通过Document获取
比如:商品简介,内容较大不用存储。如果要向用户展示商品简介可以从系统的关系数据库中获取商品简介。

Field常用类型

分词Analyzer(词法分析器)-集成ik分词器
分词器是Lucene中非常重要的一个知识点,如果你面试时说你用过Lucene面试官一定会问你用的什么分词器。
分词,也称词法分析器(或者叫语言分析器),就是指索引中的内容按什么样的方式来建立,这在全文检索中非常关键,是按英文单词建立索引,还是按中文词意建立索引;这些需要由Analyzer来指定。
建立索引分词,搜索索引添加分词
对于中文,需要采用字典分词,也叫词库分词;把中文件的词全部放置到一个词库中,按某种算法来维护词库内容;如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法。如:“我们是中国人”,效果为:“我们”、“中国人”。(可以使用SmartChineseAnalyzer,“极易分词” MMAnalyzer ,或者是“庖丁分词”分词器、IKAnalyzer。推荐使用IKAnalyzer )
在这里我们推荐IKAnalyzer。使用时需导入IKAnalyzer.jar,并且拷贝IKAnalyzer.cfg.xml,ext_stopword.dic文件,分词器测试代码如下:
public class AnalyzerTest {
//创建索引的数据 现在写死,以后根据实际应用场景
private String en = "oh my lady gaga"; // oh my god
private String cn = "迅雷不及掩耳盗铃儿响叮当仁不让";
private String str = "源代码教育FullText Search Lucene框架的学习";
/**
* 把特定字符串按特定的分词器来分词
* @param analyzer
* @param str
* @throws Exception
*/
public void testAnalyzer(Analyzer analyzer,String str) throws Exception {
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(str));
// 在读取词元流后,需要先重置/重加载一次
tokenStream.reset();
while(tokenStream.incrementToken()){
System.out.println(tokenStream);
}
}
//IK分词:从词典中查找
// 简单使用:拷贝两个配置文件,拷贝一个jar包
// 扩展词,停止词
// 注意:打开方式,不要使用其他的,直接使用eclipse的text Editor,修改以后要刷新一下让项目重新编译
/**
* 配置停止词
* 配置扩展词
* @throws Exception
*/
@Test
public void test()throws Exception{
//userSmart为true有最大匹配原则,有大不要小的
//userSmart为false,默认值,细粒度匹配
testAnalyzer(new IKAnalyzer(false),str);
}
}
}
索引的添删改
经过之前的分析,我们知道对索引的操作统一使用IndexWriter。测试代码如下
Document的CRUD
- 一个document和数据库表中一条记录对应,数据库做crud时,对应document也要唑crud
- IndexWriter的方法
- 添加:addDocument
- 删除:deleteAll deleteDocument(term,query)
- 修改:updateDocument(term,new Doc) 先删除后添加
- IndexSearcher
查询: doc(docId)
Query及Searcher
搜索是全文检索中最重要的一部分,前面HelloWorld中也发现,Query对象只是一个接口,他有很多子类的实现。在前面直接使用QueryParser的Parse方法来创建Query对象的实例,实际他会根据我们传入的搜索关键字自动解析成需要的查询类型,索引在这里我们也可以直接new一个Query实例来达到不同的搜索效
抽取结构:
// 先做一个准备工作,提供两个search方法
//一个传入搜索关键字进行搜索
public void search(String key) throws Exception{
Directory dir=new SimpleFSDirectory(new File(path));
//创建索引查询器
IndexSearcher searcher=new IndexSearcher(dir,true);
//创建查询解析器
QueryParser qp=new QueryParser(Version.LUCENE_29, "content", new SmartChineseAnalyzer(Version.LUCENE_29));
//创建查询对象
Query q=qp.parse(key);
System.out.println(“自动生成的查询对象为:”+q.getClass().getSimpleName());
//执行查询
TopDocs td=searcher.search(q, 10);
//遍历结果
for(int i=0;i<td.scoreDocs.length;i++){
//得到符合条件的内部文档对象
ScoreDoc doc=td.scoreDocs[i];
//得到文档对象
Document d=searcher.doc(doc.doc);
System.out.println("score:"+doc.score+" title: "+d.get("title")+" content:"+d.get("content"));
}
}
//传入一个查询对象
public void search(Query q) throws Exception{
System.out.println(“对应的查询语句为:”+q);
Directory dir=new SimpleFSDirectory(new File(path));
//创建索引查询器
IndexSearcher searcher=new IndexSearcher(dir,true);
//执行查询
TopDocs td=searcher.search(q, 10);
//遍历结果
for(int i=0;i<td.scoreDocs.length;i++){
//得到符合条件的内部文档对象
ScoreDoc doc=td.scoreDocs[i];
//得到文档对象
Document d=searcher.doc(doc.doc);
System.out.println("title: "+d.get("title")+" content:"+d.get("content"));
}
}
1)单词查询

2)段落搜索, 要想把多个单词当成一个整体进行搜索,使用双引号包裹
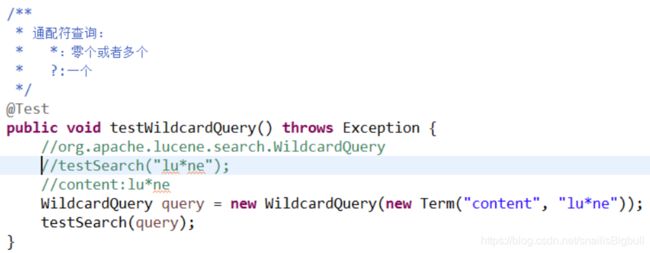
 3)通配符搜索
3)通配符搜索
 4)模糊搜索
4)模糊搜索

5)临近查询,在段落查询的基础上用“~”后面跟一个1到正无穷的正整数。代表段落中,单词与单词之间最大的间隔数
 6)组合查询
6)组合查询
 NumericRangeQuery 区间查询
NumericRangeQuery 区间查询
项目实战
.项目需求
关系型数据库对于前面有变化的文本搜索(like %keyword%),索引会失效。查询速度非常低。可以使用lucene提高速度,比如我们的部门(特别是文本数据比较多,数据量比较大都适合),可以使用lucene进行全文检索。
.项目架构
 parent
parent
bastic_util
…
basic_lucene:lucene帮助类
为什么?没有放到util
如果哪天我们不用全文检索了呢?那么这个报就废了 做到高内聚低耦合。
itsource_fullTextIndex_lucene:针对于我们项目做全文检索
合并在一起,上面就是
mvn install:install-file -Dfile=F:/workspace/ideaproject/hellolucene/lib/IKAnalyzer2012_V5.jar -DgroupId=org.wltea -DartifactId=IKAnalyzer -Dversion=2012_V5 -Dpackaging=jar
.创建项目
1.创建itsource_fullTextIndex

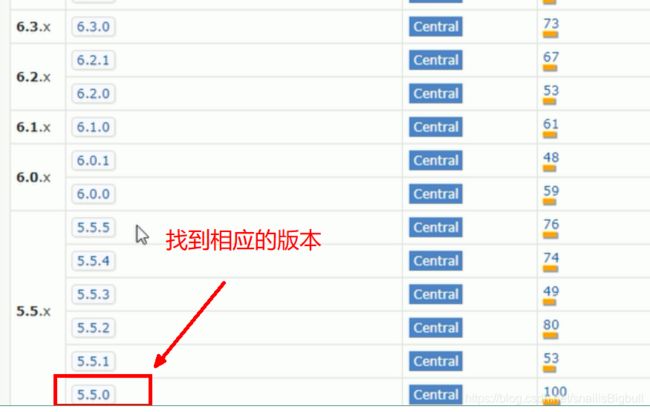






IKAnalyzer



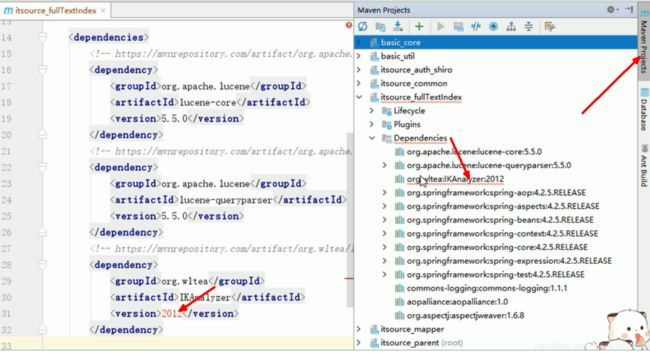
maven安装自己的jar包到本地仓库
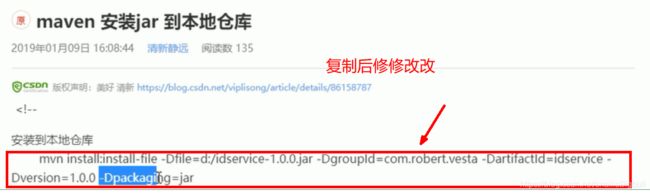
![]()
 安装方法:https://blog.csdn.net/viplisong/article/details/86158787
安装方法:https://blog.csdn.net/viplisong/article/details/86158787
需要修改的地方加粗了
mvn install:install-file -Dfile=d:/idservice-1.0.0.jar -DgroupId=com.robert.vesta -DartifactId=idservice -Dversion=1.0.0 -Dpackaging=jar
mvn install:install-file -Dfile=C:/Users/Lenovo/Desktop/新建文件夹/itsource_parent/itsource_fullTextIndex/lib/IKAnalyzer2012_V5.jar -DgroupId=org.wltea -DartifactId=IKAnalyzer -Dversion=2012_V5 -Dpackaging=jar
如果 还报红就剪切粘贴。
<dependencies>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>5.5.0version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queryparserartifactId>
<version>5.5.0version>
dependency>
<dependency>
<groupId>org.wlteagroupId>
<artifactId>IKAnalyzerartifactId>
<version>2012_V5version>
dependency>
<dependency>
<groupId>cn.itsourcegroupId>
<artifactId>itsource_commonartifactId>
<version>1.0-SNAPSHOTversion>
dependency>
dependencies>
要被service依赖

servcie要扫描IndexHelpler
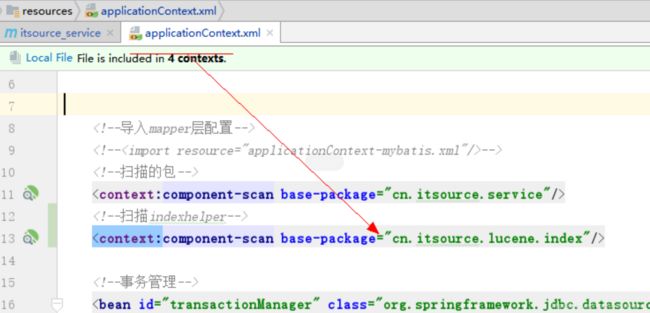
2.集成工具类
package cn.itsource.lucene.util;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.*;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class LuceneUtil {
private static final String INDEX_DIRCTORY = "F:/lucene/index";
private static Directory directory;//存放索引的目录
private static IndexWriter indexWriter;//索引写对象,线程安全
private static IndexReader indexReader;//索引读对象,线程安全
private static IndexSearcher indexSearcher;//索引查询对象,线程安全
private static Analyzer analyzer;//分词器对象
static{
try {
//如果父目录不存在,先创建父目录
File file = new File(INDEX_DIRCTORY);
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
directory = FSDirectory.open(Paths.get(INDEX_DIRCTORY));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获取IndexWriter对象
* @return
* @throws IOException
*/
public static IndexWriter getIndexWriter(){
try {
Analyzer analyzer = getAnalyzer();
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
return new IndexWriter(directory,conf);
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
/**
* 获取IndexReader
* @return
* @throws Exception
*/
public static IndexReader getIndexReader(){
try {
if(indexReader==null){
indexReader = DirectoryReader.open(directory);
}else {
//如果不为空,就使用DirectoryReader打开一个索引变更过的IndexReader类
DirectoryReader newIndexReader = DirectoryReader.openIfChanged((DirectoryReader) indexReader);
if(newIndexReader!=null){
//把旧的索引读对象关掉
indexReader.close();
indexReader = newIndexReader;
}
}
return indexReader;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
/**
* 获取IndexSearcher对象
* @return
* @throws IOException
*/
public static IndexSearcher getIndexSearcher(){
if(indexSearcher==null){
indexSearcher = new IndexSearcher(getIndexReader());
}
return indexSearcher;
}
/**
* 获取分词器对象
* @return
*/
public static Analyzer getAnalyzer() {
if(analyzer!=null){
return analyzer;
}
return new IKAnalyzer();
}
/**
* 创建QueryParser对象
* @param field
* @return
*/
public static QueryParser createQueryParser(String field){
return new QueryParser(field,getAnalyzer());
}
/**
* 创建Query对象
* @param field
* @param queryStr
* @return
*/
public static BooleanQuery createQuery(String field[],String queryStr){
BooleanQuery.Builder builder = new BooleanQuery.Builder();
for (String f : field) {
builder.add(new TermQuery(new Term(f,queryStr)), BooleanClause.Occur.SHOULD);
}
return builder.build();
}
/**
* 分页查询索引
* @param field
* @param queryStr
* @param pageNum
* @param pageSize
* @return
* @throws IOException
*/
public static List<Document> getHitDocuments(String[] field,String queryStr,int pageNum,int pageSize){
List<Document> list = new ArrayList<>();
try {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = createQuery(field,queryStr);
System.out.println(query);
// 查询数据, 结束页面自前的数据都会查询到,但是只取本页的数据
TopDocs topDocs = indexSearcher.search(query, pageNum * pageSize);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//总条目数
int totalHits = topDocs.totalHits;
int start = (pageNum-1)*pageSize;
int end = (pageNum*pageSize)>totalHits?totalHits:(pageNum*pageSize);
for(int i=start;i<end;i++){
ScoreDoc scoreDoc = scoreDocs[i];
Document document = indexSearcher.doc(scoreDoc.doc);
list.add(document);
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/**
* 总共命中的条目数
* @param field
* @param queryStr
* @return
* @throws IOException
*/
public static long totalHits(String[] field,String queryStr){
try {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = createQuery(field,queryStr);
TopDocs topDocs = indexSearcher.search(query, 10);
return topDocs.totalHits;
} catch (IOException e) {
e.printStackTrace();
return 0;
}
}
/**
* 删除索引
* @param field
* @param queryStr
* @throws IOException
*/
public static void deleteIndex(String[] field,String queryStr){
try {
IndexWriter indexWriter = getIndexWriter();
Query query = createQuery(field,queryStr);
indexWriter.deleteDocuments(query);
indexWriter.commit();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除所有索引
* @throws IOException
*/
public static void deleteAllIndex()throws IOException{
IndexWriter indexWriter = getIndexWriter();
indexWriter.deleteAll();
indexWriter.commit();
indexWriter.close();
}
/**
* 更新索引文档
* @param term
* @param document
*/
public static void updateIndex(Term term,Document document) {
try {
IndexWriter indexWriter = getIndexWriter();
indexWriter.updateDocument(term, document);
indexWriter.commit();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 更新索引文档
* @param field
* @param value
* @param document
*/
public static void updateIndex(String field,String value,Document document) {
updateIndex( new Term(field, value), document);
}
/**
* 添加索引文档
* @param document
*/
public static void addIndex(Document document) {
updateIndex(null, document);
}
/**
* 关闭资源
*/
public static void closeAll(){
try {
if (indexWriter!=null)
indexWriter.close();
if(indexReader!=null)
indexReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
配置文件
.项目实战
1.创建索引方式
1)即时同步

添加数据库的同时添加到索引库,效率变低。对于实时性不高的数据,同步需要花时间,需放到空闲时间操作。
2)定时同步
 在特定的时间,把没有同步的数据同步一次。
在特定的时间,把没有同步的数据同步一次。
3)手动同步

手动同步可以很快转换到定时同步,只需加一个定时调度就ok,我们采用的是手动同步。
2.实现步骤
1)已有数据使用测试类添加索引
@Test
public void testAddExsitDepartmentIndexs()throws Exception{
List<Department> departments = departmentService.getAll();
for (Department department : departments) {
indexHelper.save(department);
}
}
2)刚添加数据使用即时同步
添加数据库时立即创建索引
Indexhelper(IndexDb)----Mapper(DB)
IDepartmentIndexhelper—>DepartmentIndexhelper
IXxxIndexhelper—>XxxIndexhelper
IDepartmentIndexhelper
itsource_fullTextIndex
package cn.itsource.lucene.index;
import cn.itsource.basic.PageList;
import cn.itsource.domain.Department;
import cn.itsource.query.DepartmentQuery;
import java.util.Map;
/**
* 对索引库里面Department进行进行crud接口
*/
public interface IDepartmentIndexHelper {
void save(Department department);
void remove(Long id);
void update(Department department);
PageList<Department> list(DepartmentQuery query);
}
lucene.index.impl;
package cn.itsource.lucene.index.impl;
import cn.itsource.basic.PageList;
import cn.itsource.domain.Department;
import cn.itsource.domain.Employee;
import cn.itsource.domain.Tenant;
import cn.itsource.lucene.index.IDepartmentIndexHelper;
import cn.itsource.lucene.util.LuceneUtil;
import cn.itsource.query.DepartmentQuery;
import org.apache.lucene.document.*;
import org.apache.lucene.index.MergePolicy;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Component
public class DepartmentIndexHelper implements IDepartmentIndexHelper {
@Override
public void save(Department department) {
try {
Document document = department2doc(department);
LuceneUtil.addIndex(document);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void remove(Long id) {
try {
// id字段中存在id就删除
LuceneUtil.deleteIndex(new String[]{"id"},id+"");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void update(Department department) {
try{
Term term = new Term("id", department.getId() + "");
LuceneUtil.updateIndex(term,department2doc(department));
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public PageList<Department> list(DepartmentQuery query) {
String keywords = query.getKeywords();
Query indexQuery = null;
if (StringUtils.isEmpty(keywords)){
//name中包含*
indexQuery = new WildcardQuery(new Term("name","*"));
}else{
indexQuery = LuceneUtil.createQuery(
new String[]{"name","sn","companyName","pname","username"}, keywords);
}
int pageNum = query.getPage().intValue();
int pageSize = query.getPageSize().intValue();
try {
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
System.out.println(query);
//pageNum 1 pageSize 10 10(pageNum * pageSize) 1-10 (page-1)*pageSize,pageSize
//pageNum 2 pageSize 10 20 10-20
//pageNum 3 pageSize 10 30 20-30
// 查询数据, 结束页面自前的数据都会查询到,但是只取本页的数据
TopDocs topDocs = indexSearcher.search(indexQuery, pageNum * pageSize);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//总条目数
int totalHits = topDocs.totalHits;
if (totalHits<1){
return new PageList<>();
}else{
int start = (pageNum-1)*pageSize;
int end = (pageNum*pageSize)>totalHits?totalHits:(pageNum*pageSize);
List<Department> departments = new ArrayList<>();
for(int i=start;i<end;i++){
ScoreDoc scoreDoc = scoreDocs[i];
Document document = indexSearcher.doc(scoreDoc.doc);
departments.add(document2Department(document));
}
return new PageList<Department>(Long.parseLong(totalHits+""),departments);
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
private Department document2Department(Document document) {
Department department = new Department();
department.setId(Long.parseLong(document.get("id")));
department.setSn(document.get("sn"));
department.setName(document.get("name"));
department.setDirPath(document.get("dirPath"));
department.setState(Integer.parseInt(document.get("state")));
if (!StringUtils.isEmpty(document.get("mid"))){
Employee manager = new Employee(); // 部门经理 员工对象
manager.setId(Long.parseLong(document.get("mid")));
manager.setUsername(document.get("username"));
department.setManager(manager);
}
if (!StringUtils.isEmpty(document.get("pid"))){
Department parent = new Department(); // 部门经理 员工对象
parent.setId(Long.parseLong(document.get("pid")));
parent.setName(document.get("pname"));
department.setParent(parent);
}
if (!StringUtils.isEmpty(document.get("tid"))){
Tenant tenant = new Tenant(); // 部门经理 员工对象
tenant.setId(Long.parseLong(document.get("tid")));
tenant.setCompanyName(document.get("companyName"));
department.setTenant(tenant);
}
return department;
}
//关键核心的代码创建文档
private Document department2doc(Department department) {
Document document = new Document();
document.add(new LongField("id",department.getId(), Field.Store.YES));
document.add(new StringField("sn",department.getSn(), Field.Store.YES));
document.add(new TextField("name",department.getName(), Field.Store.YES));
if (department.getManager()!=null){
document.add(new LongField("mid",department.getManager().getId(), Field.Store.YES));
document.add(new TextField("username",department.getManager().getUsername(), Field.Store.YES));
}
if (department.getParent()!=null){
document.add(new LongField("pid",department.getParent().getId(), Field.Store.YES));
//TextField这个才能分词。
document.add(new TextField("pname",department.getParent().getName(), Field.Store.YES));
}
if (department.getTenant()!=null){
document.add(new LongField("tid",department.getTenant().getId(), Field.Store.YES));
document.add(new TextField("companyName",department.getTenant().getCompanyName(), Field.Store.YES));
}
document.add(new StringField("dirPath",department.getDirPath(), Field.Store.YES));
document.add(new IntField("state",department.getState(), Field.Store.YES));
return document;
}
}
service.impl;
package cn.itsource.service.impl;
import cn.itsource.basic.PageList;
import cn.itsource.basic.query.BaseQuery;
import cn.itsource.basic.service.impl.BaseServiceImpl;
import cn.itsource.domain.Department;
import cn.itsource.lucene.index.IDepartmentIndexHelper;
import cn.itsource.mapper.DepartmentMapper;
import cn.itsource.query.DepartmentQuery;
import cn.itsource.service.IDepartmentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.Serializable;
import java.util.List;
@Service
/**
* 做增删改的时候同步修改索引库
*/
public class DepartmentServiceImpl extends BaseServiceImpl<Department> implements IDepartmentService {
@Autowired
private DepartmentMapper departmentMapper;
@Autowired
private IDepartmentIndexHelper indexHelper;
@Override
public List<Department> queryDeptTree() {
return departmentMapper.loadDeptTree();
}
@Override
public void add(Department department) {
departmentMapper.save(department);
indexHelper.save(department);
}
@Override
public void del(Serializable id) {
departmentMapper.remove(id);
indexHelper.remove(Long.parseLong(id.toString()));
}
@Override
public void update(Department department) {
departmentMapper.update(department);
indexHelper.update(department);
}
//不需要到数据库查询,直接到索引库查询
@Override
public PageList<Department> query(BaseQuery query) {
DepartmentQuery departmentQuery = (DepartmentQuery) query;
return indexHelper.list(departmentQuery);
}
}
3.高亮
1)高亮知识点
① 导入jar包 lucene-highlighter-5.5.0.jar lucene-memory-5.5.0.jar
② 创建高亮器
③ 使用高亮器对查询结果进行高亮处理

2)高亮放到项目中
<el-table-column prop="state" label="状态">
<template slot-scope="scope">
<span v-if="scope.row.state!=null && scope.row.state==-1" style="color: red">停用</span>
<span v-else>正常</span>
</template>
</el-table-column>
<el-table-column prop="manager.username" label="部门经理">
<template slot-scope="scope">
<div v-if="scope.row.manager!=null" v-html="scope.row.manager.username"></div>
</template>
</el-table-column>