Solr配置文件详解
1 概述
Solr配置文件位于solr/conf目录下,因各个版本的solr目录不太一致,所以下面以solr5.x或者以上版本来说明相关配置文件的参数及一些相关作用。
2 目录结构说明
官网下载solr之后解压:

目录说明:
bin:Solr控制台管理工具存在该目录下。如:solr.cmd等。
contrib:该文件包含大量关于Solr的扩展。分别如下:
analysis-extras:该目录下面包含一些相互依赖的文本分析组件。
clustering:该目录下有一个用于集群检索结果的引擎。
dataimporthandler:DIH是Solr中一个重要的组件,该组件可以从数据库或者其他数据源导入数据到Solr中。
dataimporthandler-extras:这里面包含了对DIH的扩展。
extraction:集成Apache Tika,用于从普通格式文件中提取文本。
langid:该组件使得Solr拥有在建索引之前识别和检测文档语言的能力。
map-reduce:提供一些和Hadoop Map-Reduce协同工作的工具。
morphlines-cell:为Solr Cell类型的功能提供KiteMorphlines的特性。
morphlines-core:为Solr提供Kite Morphlines的特性。
uima:该目录包含用于集成ApacheUIMA的库。
velocity:包含一个基于Velocity模板语言简单检索UI框架。
dist:在这里能找到Solr的核心JAR包和扩展JAR包。当我们试图把Solr嵌入到某个应用程序的时候会用到核心JAR包。
docs:该文件夹里面存放的是Solr文档,离线的静态HTML文件,还有API的描述。
example:包含Solr的简单示例。在其中的exampledocs子文件夹下存放着前面提到过的用于在Windows环境下发送文档到Solr的工具post.jar程序。
licenses:各种许可和协议。
server:Solr Core核心必要文件都存放在这里,分别如下:
contexts:启动Solr的Jetty网页的上下文配置。
etc:Jetty服务器配置文件,在这里可以把默认的8983端口改成其他的。
lib:Jetty服务器程序对应的可执行JAR包和响应的依赖包。
logs:默认情况下,日志将被输出到这个文件夹。
modules:http\https\server\ssl等配置模块。
resources:存放着Log4j的配置文件。这里可以改变输出日志的级别和位置等设置。
scripts:Solr运行的必要脚本。
solr:运行Solr的配置文件都保存在这里。solr.xml文件,提供全方位的配置;zoo.cfg文件,使用SolrCloud的时候有用。子文件夹/configsets存放着Solr的示例配置文件。每创建一个核心Core都会在server目录下生成相应的core名称目录。
solr-webapp:Solr的平台管理界面的站点就存放在这里。
tmp:存放临时文件。
3 配置文件说明
主要说明core中的配置文件,目录在server/solr/core name xxx/conf/目录下;
core name xxx目录下会产生两个目录,如下:

Data为数据索引目录;
Conf为相关配置文件;
Core.properties是描述信息;
3.1 solrconfig.xml配置
solrconfig.xml配置文件主要定义了solr的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置。相当于是基础配置文件。
3.1.1 dataDir
定义了索引数据和日志文件的存放位置
3.1.2 directoryFactory
索引存储方案,共有以下存储方案
1、solr.StandardDirectoryFactory,这是一个基于文件系统存储目录的工厂,它会试图选择最好的实现基于你当前的操作系统和Java虚拟机版本。
2、solr.SimpleFSDirectoryFactory,适用于小型应用程序,不支持大数据和多线程。
3、solr.NIOFSDirectoryFactory,适用于多线程环境,但是不适用在windows平台(很慢),是因为JVM还存在bug。
4、solr.MMapDirectoryFactory,这个是solr3.1到4.0版本在linux64位系统下默认的实现。它是通过使用虚拟内存和内核特性调用
mmap去访问存储在磁盘中的索引文件。它允许lucene或solr直接访问I/O缓存。如果不需要近实时搜索功能,使用此工厂是个不错的方案。
5、solr.NRTCachingDirectoryFactory,此工厂设计目的是存储部分索引在内存中,从而加快了近实时搜索的速度。
6、solr.RAMDirectoryFactory,这是一个内存存储方案,不能持久化存储,在系统重启或服务器crash时数据会丢失。且不支持索引复制
3.1.3 luceneMatchVersion
5.5.4 Solr版本
3.1.4 codecFactory
编解码工厂允许使用自定义的编解码器。例如:如果想启动per-field DocValues格式, 可以在solrconfig.xml里面设置SchemaCodecFactory:
docValuesFormat="Lucene42":这是默认设置,所有数据会被加载到堆内存中。
docValuesFormat="Disk":这是另外一个实现,将部分数据存储在磁盘上。
docValuesFormat="SimpleText":文本格式,非常慢,用于学习。
3.1.5 indexConfig
用于设置索引的低级别的属性
1000 //IndexWriter等待解锁的最长时间(毫秒)。
8 //
false //solr默认为false。如果为true,索引文件减少,检索性能降低,追求平衡。
100 //缓存
1000 //同上。两个同时定义时命中较低的那个。
10
10
//合并策略。
10 //合并因子,每次合并多少个segments。
${solr.lock.type:native} //锁工厂。
false //是否启动时先解锁。
128 //Luceneloads terms into memory 间隔
true //重新打开,替代先关闭-再打开。
//提交删除策略,必须实现org.apache.lucene.index.IndexDeletionPolicy
1
0
30MINUTES OR 1DAY
false //相当于把创建索引时的日志输出。
${solr.lock.type:native} 设置索引库的锁方式,主要有三种:
1.single:适用于只读的索引库,即索引库是定死的,不会再更改
2.native:使用本地操作系统的文件锁方式,不能用于多个solr服务共用同一个索引库。Solr3.6 及后期版本使用的默认锁机制。
3.simple:使用简单的文件锁机制
3.1.6 updateHandler
${solr.autoCommit.maxTime:15000}
false
设置索引库更新日志,默认路径为solrhome下面的data/tlog。随着索引库的频繁更新,tlog文件会越来越大,所以建议提交索引时采用硬提交方式
3.1.7 query
设置boolean 查询中,最大条件数。在范围搜索或者前缀搜索时,会产生大量的 boolean 条件,
如果条件数达到这个数值时,将抛出异常,限制这个条件数,可以防止条件过多查询等待时间过长。
3.1.8 requestDispatcher
请求转发器
3.1.9 requestHandler
请求处理器:
explicit
10
text
3.2 managed-schema配置
managed_schema是在使用solr建立core时的配置(core连接配置和索引库),solr根据它确定如何对文档建立索引到索引库中,每个core在建立前都需要设计好managed_schema。其中包含一些节点配置,常见节点如下:
3.2.1 常用配置
在solr和lucene中,每个文档可以解析成一个document,document有field集合组成,field的形式可以为多种,比如filed可以为作者,标题,内容等,field也可以为时间,长度等,document是一系列描述全文的field的集合。Lucene便是将docement进行建立索引的java库,solr为使用lucene实现的一个服务程序,可以说solr是lucene的一个封装。
当我们有一系列documents时,我们想要对每个docement中需要建立索引的部分进行自定义设定,比如当我们有一篇论文,它可以分成<题目,作者,时间,关键字,地址,内容>这样的field集合,其中作者和关键字这样的field可以包含多个值,作者一般包含学生名字和导师名字。现在,我们想要对该片论文建立全文索引,我们希望可以通过某个field中的值能够搜索到它,比如题目,或者某个关键字,但我不希望通过某些field比如地址搜索到该论文,
所以想要建立索引的第一个问题为:你希望哪些field可以用于检索?当检索到该文档后,我们希望看见该文档中的题目,地址,内容等属性,
那么想要建立索引的第二个问题为:你希望哪些属性可以展示给大家看?同时某个field可能包含多个值,比如关键字,
所以建立索引的第三个问题为:我想指定某个field为多值。
当想要建立索引时,首先考虑上面三个问题,在solr中,这些问题都可以按照你的设计运行,那就是对managed_schema进行配置。如以下内容:
说明:
name指定field名;
type指定该field的内容的类型,需要与managed_schema后面的
indexed表明该属性是否进行检索,也就是是否需要建立索引,它的值域为{“true”,“false”}当值为true时则建立索引;
stored的值域也为{“true”,”false”},该选项确定该属性是否用于展示,当设置为”true”时,该field的值将写入索引库中,在检索时,该选项用于返回展示,如果为false则不存储该field并且不做展示。需要申明的是一个值可以同时检索和展示即indexed选项和stored选项可以同时为”true”。
Required值域为”true”时,每个上传到该索引库的文档都要求包含本field,如果需要建立的文档中并不包含该field则拒绝对其建立索引。
multiValued配置是否为多值选项,如果值为”true”则为多值,多值如下图所示:
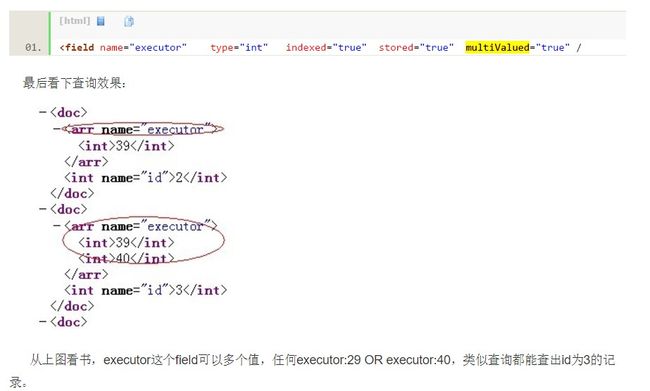
managed-schema文档的格式如下:
常用的是指定field数据类型,分词方式,检索等。fileds用于配置field的名字,filed类型,是否检索,是否存储,是否多值等信息。
3.2.2 FieldType(类型)
首先需要在types结点内定义一个FieldType子结点,包括name,class,positionIncrementGap等等一些参数,name就是这个FieldType的名称,class指向org.apache.solr.schema包里面对应的class名称,用来定义这个类型的行为。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。例如:
1)常用域(字段类型)
StrField: 这是一个不分词的字符串域,它支持 docValues域,但当为其添加了docValues域,则要求只能是单值域且该域必须存在或者该域有默认值
BoolField : boolean域,对应true/false
TrieIntField, TrieFloatField, TrieLongField,TrieDoubleField 这几个都是默认的数字域, precisionStep属性一般用于数字范围查询, precisionStep值越小,则索引时该域的域值分出的 token个数越多,会增大硬盘上索引的体积,但它会加快数字范围检索的响应速度, positionIncrementGap属性表示如果当前域是多值域时,多个值之间的间距,单值域,设置此项无意义。
TrieDateField :显然这是一个日期域类型,不过遗憾的是它支持 1995-12-31T23:59:59Z这种格式的日期,比较坑爹,为此我自定义了一个 TrieCNDateField域类型,用于支持国人比较喜欢的 yyyy-MM-dd HH:mm:ss格式的日期。源码请参见我的上一篇博客。
BinaryField :经过 base64编码的字符串域类型,即你需要把 binary数据进行base64编码才能被 solr进行索引。
RandomSortField :随机排序域类型,当你需要实现伪随机排序时,请使用此域类型。
TextField :是用的最多的一种域类型,它需要进行分词,所以它一般需要配置分词器。至于具体它如何配置 IK分词器:一般索引使用最小粒度分词,搜索使用最大分词,
2)属性说明
(1)、field type是对field类型的详细描述:
● name:类型的名称,对应field中的type
● class:类型对应的Java对象, solr默认提供大概20多种类型
● positionIncrementGap:当field设置multValued为true时,用来分隔多个值之间的间隙大小
● autoGeneratePhraseQueries:有点类似找近义词或者自动纠错的设置,例如可以将 wi fi自动转为 wifi或wi-fi,如果不设置这个属性则需要在查询时强制加上引号,例如 ‘wi fi’
(2)、fieldType元素还有一些额外的属性也需要注意下,比如sortMissingFirst,sortMissingLast等:
● sortMissingLast 表示如果域值为 null,在根据当前域进行排序时,把包含 null值的document 排在最后一位;
● sortMissingFirst :与 sortMissingLast对应的,相反;
● docValues :表示是否为 docValues域,一般排序, group,facet时会用到docValues域。
在index的analyzer中使用 solr.WhitespaceTokenizerFactory这个分词包,就是空格分词,
然后使用 solr.StopFilterFactory,solr.WordDelimiterFilterFactory,solr.LowerCaseFilterFactory,solr.EnglishPorterFilterFactory,solr.RemoveDuplicatesTokenFilterFactory这几个过滤器。
在向索引库中添加text类型的索引的时候,Solr会首先用空格进行分词,然后把分词结果依次使用指定的过滤器进行过滤,最后剩下的结果才会加入到索引库中以备查询。Solr的analysis包并没有带支持中文分词的包
3.2.3 Fields(字段)
定义具体的字段(类似数据库中的字段),就是filed,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
例:
说明:
1. name:属性的名称,这里有个特殊的属性“version”是必须添加的。
2. type:字段的数据结构类型,所用到的类型需要在fieldType中设置。
3. default:默认值。
4. indexed:是否创建索引只有index=true 的字段才能做facet.field的字段,同时只有index=true该字段才能当做搜索的内容,当然store=true或者false没关系,将不需要被用于搜索的,而只是作为结果返回的field的indexed设置为false
5. stored:是否存储原始数据(如果不需要存储相应字段值,尽量设为false),表示是否需要把域值存储到硬盘上,方便你后续查询时能再次提取出来原样显示给用户
6. docValues:表示此域是否需要添加一个 docValues 域,这对 facet 查询, group 分组,排序, function 查询有好处,尽管这个属性不是必须的,但他能加快索引数据加载,对 NRT 近实时搜索比较友好,且更节省内存,但它也有一些限制,比如当前docValues 域只支持strField,UUIDField,Trie*Field 等域,且要求域的域值是单值不能是多值域
8. multValued:是否有多个值,比如说一个用户的所有好友id。(对可能存在多值的字段尽量设置为true,避免建索引时抛出错误)
9. omitNorms:此属性若设置为 true ,即表示将忽略域值的长度标准化,忽略在索引过程中对当前域的权重设置,且会节省内存。只有全文本域或者你需要在索引创建过程中设置域的权重时才需要把这个值设false, 对于基本数据类型且不分词的域如intFeild,longField,Stre, 否则默认就是 false.
10. required:添加文档时,该字段必须存在,类似MySQL的not null
11. termVectors: 设置为 true 即表示需要为该 field 存储项向量信息,当你需要MoreLikeThis 功能时,则需要将此属性值设为 true ,这样会带来一些性能提升。
12. termPositions: 是否存储 Term 的起始位置信息,这会增大索引的体积,但高亮功能需要依赖此项设置,否则无法高亮
13. termOffsets: 表示是否存储索引的位置偏移量,高亮功能需要此项配置,当你使用SpanQuery 时,此项配置会影响匹配的结果集
field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置 multiValued属性为true,避免建索引是抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。
3.2.4 copyField字段
建议建立了一个拷贝字段,将所有的全文字段复制到一个字段中,以便进行统一的检索:
并在拷贝字段结点处完成拷贝设置:
注:“拷贝字段”就是查询的时候不用再输入:userName:张三 and userProfile:张三的个人简介。直接可以输入”张三”就可以将“名字”含“张三”或者“简介”中含“张三”的又或者“名字”和“简介”都含有“张三”的查询出来。他将需要查询的内容放在了一个字段中,并且默认查询该字段设为该字段就行了。
3.2.5 dynamicField(动态)字段
除此之外,还可以定义动态字段,动态字段就是不用指定具体的名称,只要定义字段名称的规则,
例如:定义一个 dynamicField,name为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。