HTTP 协议的定义,工作原理,Fiddler的原理和使用,请求的内容
文章目录
- 一. HTTP协议是什么?
- 1.HTTP工作原理
- 2.HTTP协议格式
-
- 2.1抓包工具的原理
- 2.2抓包工具的使用
- 2.3 HTTP协议的内容
-
- 请求
-
- 首行
- 请求头(header)
- 空行
- 正文(body)
一. HTTP协议是什么?
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议.

"超文本"是指什么?
文本=>字符串
"超"文本 => 除了能传输字符串, 还能传输其他的, 例如图片, 字体, 视频, 音频…
1.HTTP工作原理
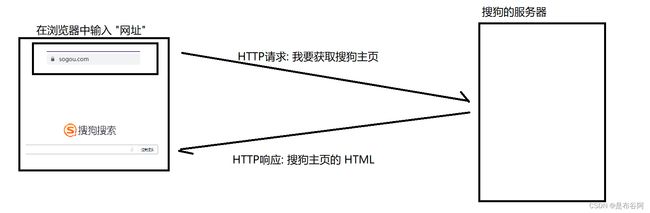
当我们在浏览器输入一个网址, 这个网址就会被DNS解析成一个IP地址, 再进一步构造成一个HTTP请求, 发送给对应服务器, 服务器就会根据请求, 返回一个HTTP显影, 这个相应的内容, 主体往往是一个html.

2.HTTP协议格式
HTTP 是一个文本格式的协议. 可以通过 Chrome 开发者工具或者 Fiddler 抓包, 分析 HTTP 请求/响应的细节.
2.1抓包工具的原理
抓包工具相当于一个代理
浏览器访问 sogou.com 时, 就会把 HTTP 请求先发给 抓包工具, 抓包工具再把请求转发给 sogou 的服务器. 当 sogou 服务器返回数据时, 抓包工具拿到返回数据, 再把数据交给浏览器.
因此 抓包工具对于浏览器和 sogou 服务器之间交互的数据细节, 都是非常清楚的.
代理客户端的, 叫正向代理; 代理服务器的, 叫反向代理.
2.2抓包工具的使用
这里介绍的是fiddler. 下载链接 Download Fiddler Web Debugging Tool for Free by Telerik
一路next后安装成功, 打开究竟是如下界面

左边是当前机器上有哪些HTTP数据报在交互(不仅仅能抓浏览器, 能住到所有程序) 双击一个之后, 右边就能看到详细信息.
右上角显示的是请求的详情:

右下角显示的是相应的内容:

刚装好fiddler之后, 默认值能抓到http的数据, 抓不到https(网络上现在https是主流), 可以设置一下, 让fiddler能抓到https


期间会弹出几个会话框, 都点yes.

然后在重启fiddler.
但有些东西可能会影响fiddler的正确运行
- https要勾选正确, 证书安装正确.
- 有些代理程序可能和fiddler冲突, 确保使用fiddler的时候关闭其他代理
- 有些浏览器插件, 也可能和fiddler冲突
如果不是以上几种情况, 那就再重启几次fiddler.
此时就能捕捉到了HTTPS的数据报
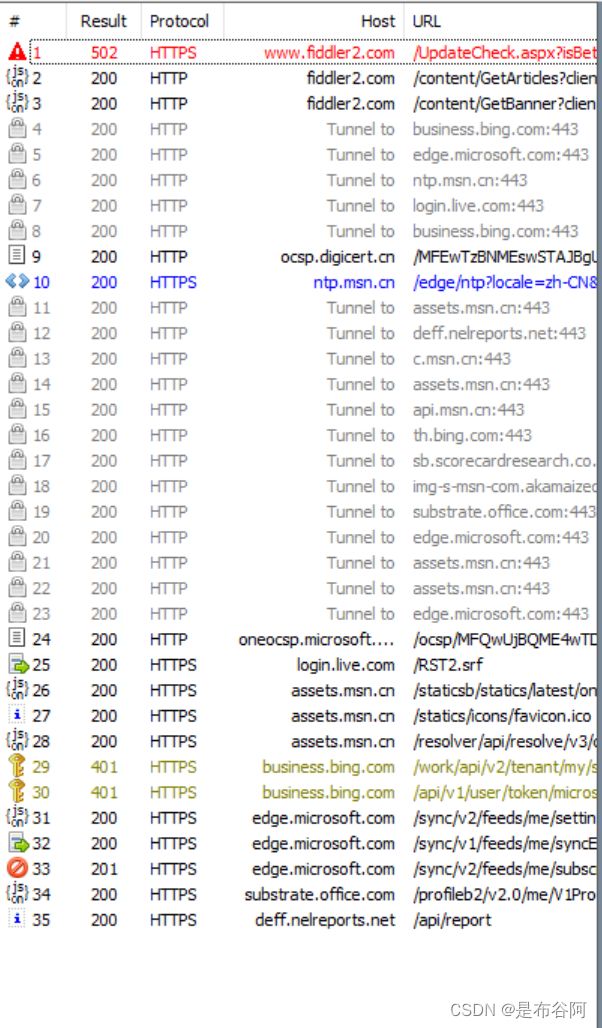
当我们打开搜狗搜索, 以下就是抓取搜狗主页, 交互过程
![]()
双击后, 右上角这些标签页, 都是站在不同的视角来解析请求的, 最主要是用的方式是Raw
![]()
点击Raw后, 会出现HTTP协议的原始数据内容
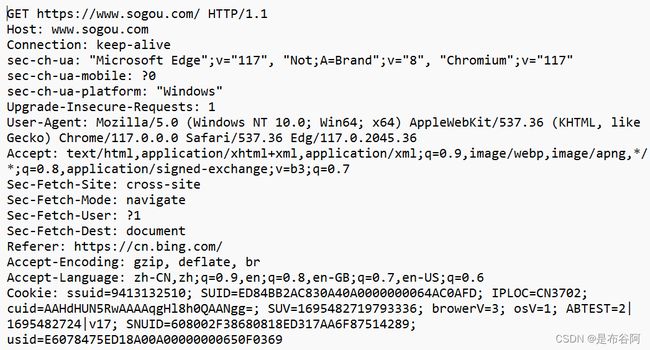
这样就能看出, HTTP是(行)文本协议, 而IP, TCP, UDP是二进制协议.
打开下面的响应解析
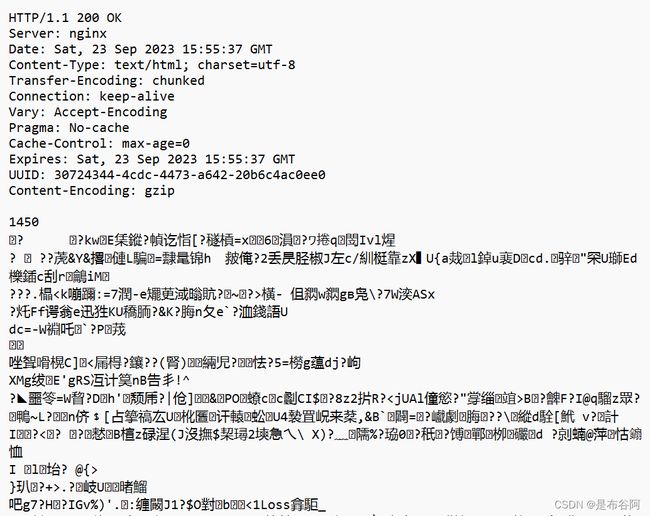
为什么会出现乱码? HTTP不是文本协议吗?
当前HTTP相应, 经常会进行压缩, 节省带宽
点击一下按钮, 就会解压缩
![]()
这里就是全部的相应内容了

2.3 HTTP协议的内容
HTTP相应的内容通常是HTML, CSS, JS, 也可以是JSON, 图片, 字体, 视频, 音频…
浏览器显示的网页其实是从服务器下载下来的, 然后才能显示.
请求
请求的四个部分:首行, 请求头(header), 空行, 正文(body)

首行
GET https://www.sogou.com/ HTTP/1.1
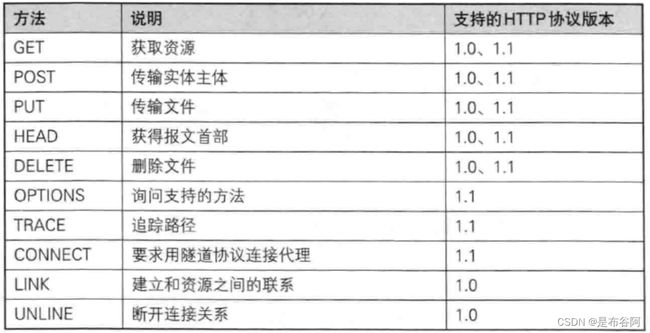
(1)GET: method. 方法描述的是"语义", 说明这次请求要干什么
-
GET和POST是比较常用的方法.
-
GET请求一般没有正文(body);
-
POST最常见的场景: 登录, 上传. 一般有正文.
- 登录的时候, 涉及到用户名密码, 属于比较敏感的信息, 直接展示在URL中会给用户造成一种"不太安全"的错觉.
- 上传的时候, 涉及到的内容比较长, 直接放在URL中会显得很难看.
-
GET和POST最主要的区别就在于, GET是把一些自定义的数据放到query string里, body通常是空的; POST是把一些自定义的数据放到body里, query string通常是空的. 但其实本质上是没有区别的, 因为放哪都是放, 都要传输给服务器, 所以两者经常也可以相互替代
-
GET和POST没有本质区别.
-
下列说法要注意:
-
GET和POST语义不同: 设计者最初是赋予了不同的语义, 但是设计中不一定完全遵守.
-
GET是幂等的, POST不是幂等的(相同输入后输出每次都相同, 就是幂等; 相同输入后输出不相同, 就是不幂等), 这是设计建议, 但不一定要遵守.
-
GET请求可以被缓存, POST不能被缓存. 缓存的前提是幂等.
-
-
其他方法:
- PUT 与 POST 相似,只是具有幂等特性,一般用于更新
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
(2)https://www.sogou.com/: URL, 描述访问的服务器, 以及服务器的资源
-
URL, jdbc唯一资源定位符, 用来描述网络上的资源.

https: 协议方案名. 常见的有 http 和 https, 也有其他的类型.user:pass: 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了. 一般都会省略www.example.jp: 服务器地址, 可以是域名, 也可以是IP地址, 此处是一个 “域名”. 如果省略, 相当于是访问当前服务器的地址.80: 服务器端口号, 区分应用程序.如果省略了, 浏览器会根据协议类型自动决定使用哪个端口.dir/index.htm: 带层次的文件路径: 表示访问服务器上的哪个资源. 如果省略了, 相当于访问的就是根目录, 也就是服务器的主页uid=1: 查询字符串: 描述访问资源时, 带上的参数. 可省略.- 查询字符串是键值对格式, 以
?开始; 键和值之间, 使用=分割; 键值对之间, 使用&符号分割. - 键和值的含义都是程序员自定义的.
ch1: 片段标识符: 不常见, 主要在文档类的网站中能看见.主要用于页面内跳转. - 查询字符串是键值对格式, 以
(3)HTTP/1.1: 版本号
请求头(header)
header 的整体的格式也是 “键值对” 结构. 每个键值对占一行. 键和值之间使用: 分割. header中的键值对有些是标准规定的, 有些事自定义的.
报头的种类有很多, 这里介绍几个常见的
(1)Host
- 表示服务器主机的地址和端口.
通常情况下, Host里的内容和URL是一致的, 但是也有例外, 比如如果使用了代理, 就不一定了
(2)Content-Length
-
表示 body 中的数据长度.
-
请求中有body的, 必须有这个字段, 否则就是非法请求; 若是请求中没有body, 这个字段可以没有.
-
body从空行开始, 数Content-Length个长度, body就结束了
-
为什么要设置这样一个字段? 其实就是为了解决粘包问题.
- HTTP基于TCP, 当浏览器连续给服务器发起多个HTTP请求, 或者服务器返回多个HTTP响应时, 服务器和浏览器如何区分, 从哪到哪是一个完整的HTTP数据呢?(粘包问题)
- 使用分隔符. 如果是GET, 没有body, 那么空行就代表结束标志.
- 使用长度. 如果是POST, 有body, 则使用长度来判断结尾.
- HTTP基于TCP, 当浏览器连续给服务器发起多个HTTP请求, 或者服务器返回多个HTTP响应时, 服务器和浏览器如何区分, 从哪到哪是一个完整的HTTP数据呢?(粘包问题)
(3) Content-Type
-
表示请求的 body 中的数据格式.
-
有三种常见格式:
-
application/x-www-form-urlencoded格式形如:
title=test&content=hello和query string一样
-
multipart/form-data通常用于提交图片/文件.
body 格式形如:
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="text" title ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png PNG ... content of chrome.png ... ------WebKitFormBoundaryrGKCBY7qhFd3TrwA-- -
application/json数据为 json 格式, body 格式形如:
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16a861fa2bddfdcd15"} -
通过Content-Type 就可以区分出body的数据格式是什么, 尤其是浏览器需要根据不同的格式来决定如何处理
空行
相当于一个分隔符, 分割了header和body, 描述了body是从哪里开始的
正文(body)
body里的格式是可以有很多种.