华为云云耀云服务器L实例评测|在服务器上训练手写数字识别模型并部署到服务器上实现远程调用
目录
本文概述
作者介绍
第一步、购买服务器并远程登录服务器
第二步、配置环境并训练手写数字识别网络
第三步、部署手写数字识别网络到云耀云服务器L实例
第四步、启动本地客户端并进行手写数字识别
本文概述
华为云云耀云服务器L实例是一款轻量化的服务器,具有新手友好,即开即用,部署轻松等特点。今天作者就用华为新出的云耀云服务器L实例来整个活——使用云耀云服务器L实例来训练手写数字识别神经网络,并将该模型部署在云耀云服务器L实例上实现远程调用数字识别服务。测试集准确率99.3%,并提供神经网络代码、服务端代码、客户端代码
效果展示

作者介绍
作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果你觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
第一步、购买服务器并远程登录服务器
购买链接: 云耀云服务器L实例 _【最新】_轻量云服务器_轻量服务器_轻量应用服务器-华为云
这里我们选择的镜像是ubuntu22.04的系统镜像
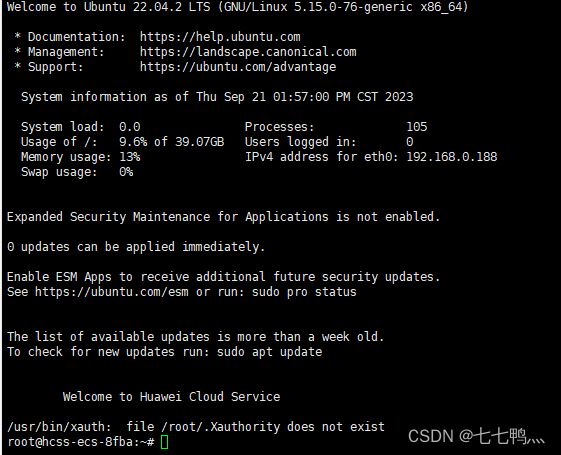
然后我们使用shell远程登录云耀云服务器
没有工具的可以看我的另一篇文章:Shell和Xftp免费版工具下载
第二步、配置环境并训练手写数字识别网络
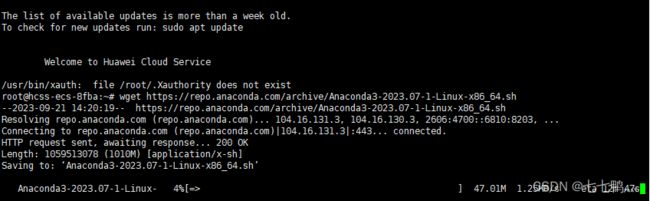
首先我们需要使用下列命令安装Anaconda,用于后面配置运行环境
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh
等待下载完成~
bash Anaconda3-2023.07-1-Linux-x86_64.sh
然后我们使用上面的命令运行Anaconda安装程序 ,具体安装过程由于篇幅原因略过
这里提示失败不用管,关闭shell重新启动会话窗口就可以了
然后我们使用下列命令创建一个conda环境来安装后续所用到的库
conda create -n dl python=3.8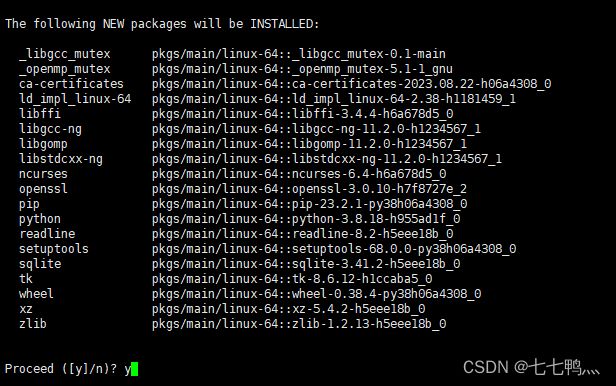
安装完后,使用下列命令,进入我们刚才创建的conda环境
conda activate dl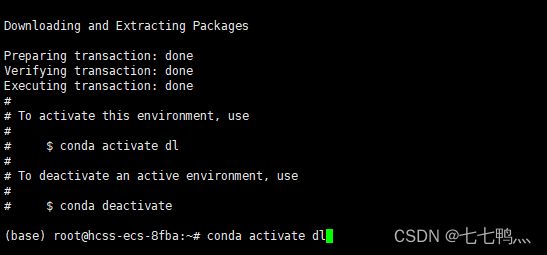
然后我们使用下列命令安装一个CPU版本的pytorch
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cpuonly -c pytorch
安装完成了,接下来我们将手写数字识别的神经网络代码上传到云耀云服务器L实例
import torch
import numpy as np
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import os
import random
import time
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
def seed_torch(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # 为了禁止hash随机化,使得实验可复现
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
class Network(torch.nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, 16, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
torch.nn.Conv2d(16, 32, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2),
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(512, 128),
torch.nn.Dropout(0.1),
torch.nn.Linear(128, 10),
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 512)
x = self.fc(x)
return x
def train(epoch,batch_size,learning_rate):
train_dataset = datasets.MNIST(root='/root/MNIST/data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='/root/MNIST/data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
model = Network()
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # lr学习率,momentum冲量
scheduler=torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.7)
running_loss = 0.0 # 这整个epoch的loss清零
train_total = 0
train_correct = 0
for ep in range(epoch):
time_start=time.time()
model.train()
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# 把运行中的loss累加起来,为了下面300次一除
# 把运行中的准确率acc算出来
_, predicted = torch.max(outputs.data, dim=1)
train_total += inputs.shape[0]
train_correct += (predicted == target).sum().item()
time_end = time.time()
train_acc=100 * train_correct / train_total
print('[%d/ %d]: train acc: %.2f %% time:%.2f s'% (ep + 1, epoch,train_acc,(time_end-time_start)))
train_total = 0
train_correct = 0
scheduler.step()
correct = 0
total = 0
model.eval()
with torch.no_grad(): # 测试集不用算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc = 100*correct / total
print('(%d / %d): test acc: %.1f %% ' % (ep+1, epoch, test_acc)) # 求测试的准确率,正确数/总数
state_dict = {"net": model.state_dict(), "optimizer": optimizer.state_dict(), "epoch": epoch,
"lr": optimizer.param_groups[0]['lr']}
if not os.path.isdir('/root//MNIST/model/'):
os.makedirs('/root//MNIST/model/')
torch.save(state_dict,
'/root//MNIST/model/' + f"model_{ep}_{train_acc}%_{test_acc}%.pth")
if __name__ == '__main__':
batch_size = 64
learning_rate = 0.001
epoch = 10
seed_torch(77)#固定随机种子,保证结果可复现
train(epoch,batch_size,learning_rate)#开始训练复制代码,然后保存为MNIST_train.py
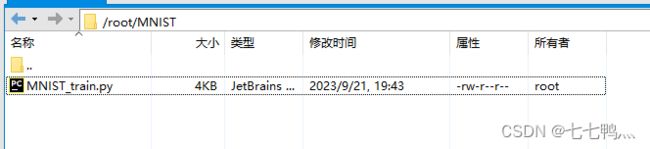
接下来使用xftp软件远程连接云耀云服务器L实例并在root目录下新建一个MNIST文件夹

然后我们将刚才的MNIST_train.py文件上传到MNIST文件夹下
然后我们使用下列命令,开始训练手写数字识别神经网络
python /root/MNIST/MNIST_train.py
如图我们已经完成的手写数字识别神经网络的训练了,从图中我们可以看到每轮训练耗时19.4S左右,这可以看出我们云耀云服务器L实例的CPU还是非常强劲的啊!!!同时我们在MNIST的测试集中正确率也达到了99.3%。
第三步、部署手写数字识别网络到云耀云服务器L实例
首先将下列服务端的代码复制并保存为MNIST_server.py然后上传到云耀云服务器L实例/root/MNIST目录下
import io
import torch
from torchvision import transforms
from PIL import Image
from flask import Flask, jsonify, request
from flask_cors import CORS
from MNIST_train import Network
app = Flask(__name__)
CORS(app, resources=r'/*')
model = Network()
checkpoint = torch.load("/root/MNIST/model/model_10_99.77666666666667%_99.3%.pth",
map_location='cpu')
model.load_state_dict(checkpoint['net'])
model.eval()
def transform(image_bytes):
Transforms = transforms.Compose([transforms.Resize(28),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
image = Image.open(io.BytesIO(image_bytes))
return Transforms(image)
def get_prediction(image_bytes):
image = transform(image_bytes=image_bytes)
image=image.reshape(1,1,28,28)
outputs = model(image)
_, predicted = outputs.max(1)
predicted_idx = str(predicted.item())
return predicted_idx
@app.route('/predict')
def predict():
if request.method == 'GET':
file = request.files['file']
img_bytes = file.read()
predict_id= get_prediction(image_bytes=img_bytes)
return jsonify({'predict_id': predict_id})
if __name__ == '__main__':
app.run(host='0.0.0.0',port=3777)上传后如下图所示

接下来为了能让客户端跟服务端通信,我们需要开放云耀云服务器L实例的3777端口(这个端口跟服务端上的相同即可)
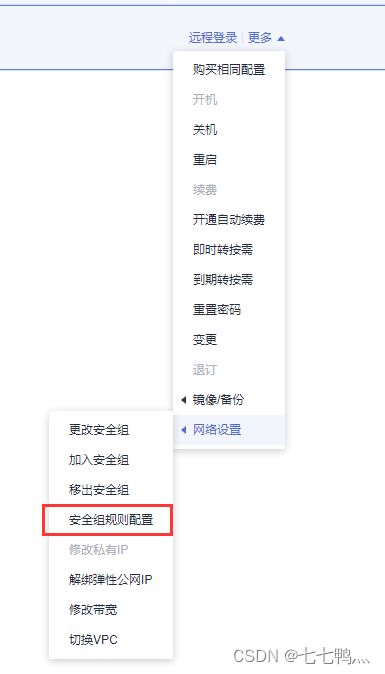



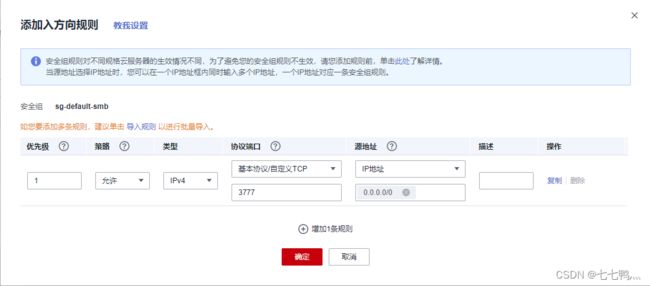
![]()
这样就是成功开放3777端口了
然后,使用下列命令在云耀云服务器L实例中安装flask、flask_cors和screen库
pip install flask -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install flask_cors -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install screen -i https://pypi.tuna.tsinghua.edu.cn/simple然后使用下列命令创建一个screen窗口,这可以让你结束远程访问云耀云服务器L实例后,让你的云耀云服务器L实例进程仍然可以运行,不会中断。
screen -S mnist
如上图所示,我们已经进入一个叫做mnist的screen窗口了。然后我们需要重新进入我们之前的conda环境,并使用下列命令运行手写数字识别的服务端程序
python /root/MNIST/MNIST_server.py如下图,我们的服务端就成功运行起来了

第四步、启动本地客户端并进行手写数字识别
手写数字识别客户端的代码如下
import tkinter as tk
from tkinter import filedialog, ttk
import requests
from PIL import Image, ImageTk
from ttkthemes import ThemedStyle
# 创建上传图像的函数
def upload_image():
file_path = filedialog.askopenfilename(filetypes=[("Image files", "*.jpg")])
print(file_path)
if file_path:
# 打开图像并显示在GUI中
image = Image.open(file_path)
image = image.resize((200, 200), Image.ANTIALIAS)
photo = ImageTk.PhotoImage(image=image)
image_label.config(image=photo)
image_label.image = photo
with open(file_path, 'rb') as image_file:
files = {'file': (image_file.name, image_file, 'image/jpeg')}
response = requests.get(f'{server_url}/predict', files=files)
if response.status_code == 200:
result = response.json()
predict_id = result.get('predict_id')
result_label.config(text=f'该图像的数字为: {predict_id}')
else:
result_label.config(text='请求失败,请检查网络是否正常。')
# 定义服务器地址和端口
server_url = 'http://120.46.178.145:3777' # 请根据您的实际服务器地址和端口进行修改
# 创建GUI窗口
root = tk.Tk()
root.title("MNIST 图像分类器")
root.geometry("300x350")
style = ThemedStyle(root)
style.set_theme("plastik")
title_label = ttk.Label(root, text="手写数字识别", font=("Helvetica", 16))
title_label.pack(pady=10)
image_label = ttk.Label(root)
image_label.pack()
# 上传按钮
upload_button = ttk.Button(root, text="上传图像", command=upload_image)
upload_button.pack(pady=10)
# 预测结果的标签
result_label = ttk.Label(root, text="", font=("Helvetica", 12))
result_label.pack()
root.mainloop()我们运行后,会出现如下界面

选择图片并上传后,会出现预测的结果

此时我们的云耀云服务器L实例也会提示状态码200

至此,我们的整个项目就完成啦~~~~~~~~~~~~
为了方便大家测试,我将MNIST的图片版数据集也上传到网盘分享出来啦~
链接:百度网盘 请输入提取码
提取码:gskb
--来自百度网盘超级会员V4的分享
总结
初次体验华为云云耀云服务器L实例,整体使用下来非常的棒,性能强,操作方便,非常适合新手入门。强烈推荐各位一定要去尝试一下。PS:后续会出更多与云耀云服务器相关的教学文章~。
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。