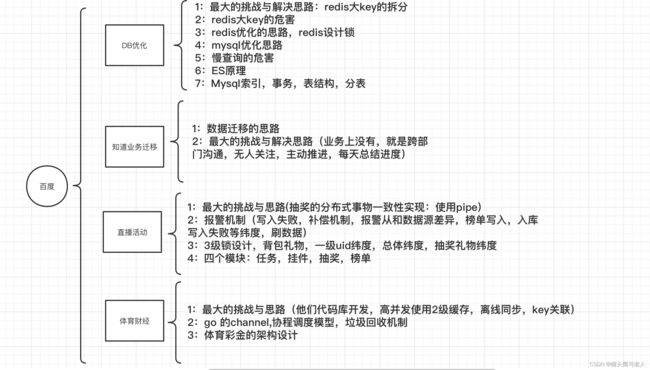
面试必胜宝典
1:redis大key的危害:
参考:面试官:大key和大value的危害,如何处理? - Code2020 - 博客园
内存不均,阻塞请求,阻塞网络
1.内存不均:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
2.阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
3.阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用。
- 大key和大value的危害是一致的:内存不均、阻塞请求、阻塞网络。
- key由于比value需要做更多的操作如hashcode、链表中比较等操作,所以会比value更多一些内存相关开销。
解决办法:
1:拆分成多个key-value,mget获取
2:hash的话,通过hash维护一个field和key的关系,通过field获取新的key再取数据
答题思路:key大和value大,key有hash的多余步奏,危害:内存不均负载均衡,请求阻塞,网络阻塞,解决:拆分多个key,hash可以用质数997取余,通过field获取新key处理
2:redis设置分布式锁:
setnx:
过期时间:防止当前进场的服务宕机,或者redis宕机,锁没有取消
随机数:获取锁,进程超时,锁自动过期,其他进程获取锁,又被之前进程处理掉
3:为什么单线还程快:
参考:Redis为什么是单线程还这么快?_XingXing_Java的博客-CSDN博客_为什么redis单线程还这么快
1:基于内存,瓶颈是内存大小或者网络带宽
2:单线程,省去了上下文切换线程的时间,不用考虑锁
3:多路复用,可以处理并发的连接。非阻塞IO 内部实现采用epoll,epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间,减少了线程切换时上下文的切换和竞争。处理客户端请求不会阻塞主线程
4:数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
5:还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路I/O,复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
4:redis优化思路:
参考:Redis 性能优化思路,写的非常好!_emprere的博客-CSDN博客
1:redis的瓶颈是内存和网络贷款,可以优化redis存储,减少内存消耗,增加集群机器,网络带宽可以使用pipeline或者multy等减少网络请求次数
2:合理使用过期,分散过期时间,防止大量过期占用主线程,或者设置异步过期修改redis.conf
3:合理是用数据结构,zset时间复杂度longn,还有hash会有ziplist的情况,有其他方案可以不使用
4:持久化带来的开销:减少rdb的频率,aof的话合理选择方式:always,everysec,no
-
always:当把 appendfsync 设置为 always,fsync 会和客户端的指令同步执行,因此最可能造成延时问题,但备份及时性最好。
-
everysec:每秒钟异步执行一次 fsync,此时 redis 的性能表现会更好,但是 fsync 依然可能阻塞 write,算是一个折中选择。
-
no:redis 不会主动出发 fsync (并不是永远不 fsync,那是不太可能的),而由 kernel 决定何时 fsync
持久化参考:redis的 rdb 和 aof 持久化的区别,性能对比_sinat_35821285的博客-CSDN博客_redis 恢复aof数据速度快
关键词:rdb从分片,aof重写,宕机一个个回复,不然主压力大,
5:使用cluser集群:把一些慢指令,或者rdb等持久化放到请求较少的从分片上
5:redis过期机制:
其中一种删除 keys 的方式是,每秒 10 次的检查一次有设置过期时间的 keys,这些 keys 存储在一个全局的 struct 中,可以用 server.db->expires 访问。
检查的方式是:
-
从中随机取出 20 个 keys
-
把过期的删掉。
-
如果刚刚 20 个 keys 中,有 25% 以上(也就是 5 个以上)都是过期的,Redis 认为,过期的 keys 还挺多的,继续重复步骤 1,直到满足退出条件:某次取出的 keys 中没有那么多过去的 keys。
这里对于性能的影响是,如果真的有很多的 keys 在同一时间过期,那么 Redis 真的会一直循环执行删除,占用主线程。
对此,Redis 作者的建议[10]是警惕 EXPIREAT 这个指令,因为它更容易产生 keys 同时过期的现象。我还见到过一些建议是给 keys 的过期时间设置一个随机波动量。最后,redis.conf 中也给出了一个方法,把 keys 的过期删除操作变为异步的,即,在 redis.conf 中设置 lazyfree-lazy-expire yes。
6:mysql的优化思路
多个查询时使用联合索引,联合索引生效的规则,聚簇索引与非聚簇索引的区别,回行,索引的长度。 innodb的次索引指向对主键的引用, myisam的次索引和主键都指向物理行。几个概念聚簇索引,索引覆盖,回行,叶子分裂。索引类型,不要对索引列进行函数的操作,在join操作中(需要从多个数据表提取数据时),mysql只有在主键和外键的数据类型相同时才能使用索引,否则及时建立了索引也不会使用。缩短索引的长度。like,not in,!等的使用。
索引建立在where且识别度高的列,不要太多所以,减少冗余索引。
优化思路:观看性能是否有周期性变化,是不是缓存失效,或者高峰引起(加缓存或则会修改缓存失效策略,3-9小时的随机失效时间,查询mysql建立缓存,设置一个redis锁,有锁才可创建缓存)=》出现不规则的延迟-〉show processlist或者开启慢查询找到sql->explain分析扫描效果或者profiling分析语句-》1:等待的时间长(缓存区线程数调大)2:语句执行时间长(表关联多,设计不合理,索引优化,语句优化)
7:慢查询的危害:
- 影响用户体验。慢sql的执行时间过长,则会导致用户的等待时间过长,直接影响用户体验。
- 造成数据库幻读、不可重复读。假设该慢sql是一个更新操作的sql,则会可能出现幻读、不可重复读这种数据库并发事务导致的问题。
- InnoDB的慢查会造成DDL操作阻塞。
- 慢查可能导致占用mysql的大量内存导致mysql服务直接挂掉导致整个系统瘫痪。
- 慢查sql可能执行时间过长导致应用的进程被kill无法返回结果给到客户端。
解决办法:
1、对数据库中执行时间较长的Select进行监控,并及时报警
2、如果允许的话,写脚本,发现较长的select语句,直接kill,并记录日志中
1,DDL:数据定义语言
创建库,创建表,修改表结构等操作,这些操作和数据无关和数据结构有关
好比java中声明类,声明方法
2,DML:数据库操作语言
增删改查数据
因为数据库最多的操作其实是查询,有人把数据库的查询语句单独列出来,DQL ,Date Query language。
3,DCL :数据库控制语言
例如:权限的授权与回收,事务的提交与回滚
8:ES原理
Elasticsearch倒排索引结构 - 废物大师兄 - 博客园
传统的mysql根据id等索引定位到具体的数据。但是如果根据内容模糊查找数据,就需要全表查找了。效率就会大幅下降。但是es不会。因为es在数据插入时会建立倒排索引。会对内容可进行分词,然后建立索引。比如like 北大,我们就可以通过查找内容定位到具体的数据。那么分词的倒排索引是怎么实现的?
倒排索引的查找,不是遍历,也不是二分查找,和数据库的索引查找不同。es的索引使用的是term index.索引存的是前缀,比如te:后面可以定位到:tea,tee,teddvd等。然后还会对term index进行压缩。这个压缩主要是利用技术对索引进行映射转化,比如teeea的索引通过算法,压缩后就只有1,这样就是的term index可以直接加载到内存中。然后找到前缀的,在顺序查找到指定分词,找到对应分词的内容。
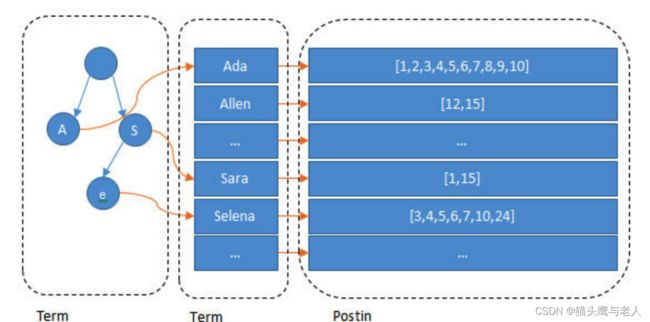
所以mysql的索引都是存在磁盘的,然后一层一层的加载到内存,但是es可以存到内存
Term index可以加载到内存中,然后term directory是有序的可以二分查找到指定的词。
1:多节点集群,并发性能好
2:乐观的并发,认为没有冲突,最后利用_version进行检测,没有阻塞
3:分段式存储,基本不需要锁
4:倒排索引的建立
5:插入快是因为写入数据先写入内存,然后1s定时把缓存数据保存
6:索引通过各种算法进行压缩(term index索引结构保存前缀,fst压缩就是比如qqqq很长他用1很短就可以建立对应关系)
9:Mysql相关:
mysql:update执行流程:
1:连接器连接数据库
2:有缓存直接返回,表有更新缓存会失效,8.0已取消
3:分析器,优化器,执行器处理结果返回客户端
redo log:更新的时候,如果直接更新磁盘,每次更新都有磁盘I/O消耗,所以增加redo log,更新直接写入redo log,然后更新内存。在系统空闲时间,再把redo log写入磁盘。redolog 是一个循环,顺序写,满了就从头开始替换,宕机后还能继续执行,保证一致性和持久性
binlog server层,redo log引擎层
更新:查数据,更新数据,更新到内存,写入redo log,处于prepare阶段,写binlog ,提交事务commit.两阶段提交,就是为了保证redo log 和 binlog都写入成功。
undo log 提供回滚和多版本控制,回滚保证原子性,全部成功或者失败。mvcc当读到某一个版本锁定了,可以读其他版本
流程:事务开始之前生成undo log,用于回滚,同时也会写入redo log保证undo 的可靠性,事务开始之后记录redo log,之后prepare, 写入binglon ,最后commit。
原子性,一致性,持久性,隔离性
binlog :数据备份恢复,主从同步,ES同步数据
undo:记录修改前的日志,用于事务回滚,保证原子性
redo:记录修改的日志,宕机或者重启后能继续执行操作,保证事务持久性和一致性
??事务还没执行完数据库挂了,重启的时候会发生什么
8.将redo log刷新到磁盘
9.commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
??Mvcc:多版本并发控制。
对数据库的任何修改的提交都不会直接覆盖之前的数据,而是产生一个新的版本与老版本共存,使得读取时可以完全不加锁。这样读某一个数据时,事务可以根据隔离级别选择要读取哪个版本的数据。过程中完全不需要加锁。
基本特征:每一行都有版本号控制,类似于乐观锁,最后commit时判断下版本号,无冲突就提交否则回滚。
当前读:最新版本需要加锁例如for update
快照读:不加锁,提高并发。不保证最新数据,
mvcc就是对并发读写避免加锁的一种实现
Read view就是进行快照读的一个读视图,当读取数据时,可以根据需要判断读书最新版本还是Undo版本里的数据。read view记录了三部分数据,当前活跃的事务id,最小事务id和下一个待分配的事务ID。通过对比数据库的当前事务id和快照读的事务id显示具体数据。实现不同的隔离级别
??事务的四个级别:
Read uncommitted:读得到别的事务未提交的记录,脏读,不可重复读,幻读
Read commited:读的到别的事务已经提交的(问题?开始1后面读别人提交的变成了2),不可重复读,幻读
Read repeaded :可重复读(事务开启前后到结束,读取的数据都是一致的,但是幻读没有解决,幻读就是开始一条记录现在多出一条新的),幻读
串行化:读写都加锁。
一致性读视图,解决读可提交和可重复读。
在可重复读情况下,读取的是针对整库的一个快照,但是并不是对整个库做一个备份。
数据库的每行数据都可能有多个版本,对应一个事务id和要回滚的数据id
脏读:A读取B,B回滚,A就是读的错误数据
幻读:比如select查到不存在id=10,但是插入的时候发现记录已经存在,导致无法成功写入。
解决:select增加行锁,select for update,存在就加行锁,不存在加间隙锁。这样其他事务就不会插入数据。gap锁,范围锁,不存在10,就锁定两个值之间的间隙。next-key lock行锁,与间隙锁组合。
参考:MySQL教程(四)---MySQL 幻读与 InnoDB 间隙锁(Gap Lock) | 指月小筑|意琦行的个人博客
间隙锁导致的死锁:
1:间隙锁不会冲突。比如ab,都是select id = 9 for update.,ab都是(5,10)的间隙锁。然后同时插入,9.b的被a的间隙锁锁住,a的被b的间隙锁锁住,但是innodb会马上检查出来,返回a失败。
10:数据迁移思路:
历史数据同步binlog-》双写-》切读-》切写-》数据一致性校验
数据一致性校验分为2步(存储纬度和业务纬度),新老表数据校验,用户看到数据校验。大型系统校验6个9,即100万错误少于1
历史数据迁移问题:1:迁移写入,但是写入过程原表执行了删除操作,新表没有数据导致删除失败。可以增加redis锁,迁移未完成原表不能写,或者记录到中间表,记录失败的操作,时候重复执行。
先部分迁移,进行一致性校验,校验通过后再全量迁移。
11:分布式事务一致性
重试+幂等+报警+脚本检测修复
不确定先后带上时间戳
牺牲强一致性换取性能,实现最终一致性,最终的时间根据业务控制在合理的范围。
比如a-b
A先给b发注备消息确保连接正常,并记录在准备表
成功后a开始执行本地事物,成功后告知b,研究b的返回
B返回成功则更新准备表的状态未成功
B返回失败,则回滚a事物,标记准备表为失败
B不返回则增加重试机制,同时因为不确定b到底是成功还是失败,所以增加定时任务获取准备状态中的任务,确定b的状态,进行成功或者回滚a的操作。
参考支付宝支付接口,异步接受支付宝回调,成功更改并返回success支付宝才会停止回调,不然时间内一直重试(RocketMQ)
最后失败发邮件报警,人工介入
12:GO相关
参考于:Golang GMP调度模型_qq_37858332的博客-CSDN博客_gmp golang
??垃圾回收机制:
计数引用:存在引用就加1,为0就清理,循环引用的情况会尝试减1,如果为0就恢复,不为0就清理
- 引用计数(reference counting)每个对象维护一个引用计数器,当引用该对象的对象被销毁或者更新的时候,被引用对象的引用计数器自动减 1,当被应用的对象被创建,或者赋值给其他对象时,引用 +1,引用为 0 的时候回收,思路简单,但是频繁更新引用计数器降低性能,存在循环以引用(php,Python所使用的)
- 标记清除(mark and sweep)就是 golang 所使用的,从根变量来时遍历所有被引用对象,标记之后进行清除操作,对未标记对象进行回收,缺点:每次垃圾回收的时候都会暂停所有的正常运行的代码,系统的响应能力会大大降低,各种 mark&swamp 变种(三色标记法),缓解性能问题。
- 分代搜集(generation)jvm 就使用的分代回收的思路。在面向对象编程语言中,绝大多数对象的生命周期都非常短。分代收集的基本思想是,将堆划分为两个或多个称为代(generation)的空间。新创建的对象存放在称为新生代(young generation)中(一般来说,新生代的大小会比 老年代小很多),随着垃圾回收的重复执行,生命周期较长的对象会被提升(promotion)到老年代中(这里用到了一个分类的思路,这个是也是科学思考的一个基本思路)。
13:redis集群的实现
参考:redis集群原理及三种模式解析_aichojie的博客-CSDN博客_redis集群三种方式
主从:高可用问题
哨兵:可以自动切换,但是存在短板效应
cluser:卡槽,分配给3个主从的集群
14:Tidb相关
参考:TIDB理解_aichojie的博客-CSDN博客
tidb server
pd cluser
tikv
二、事务更新机制不同
1、tidb数据库:tidb数据库采用乐观锁机制来保证事务更新的一致性和持久性。
2、mysql:mysql采用redo log机制来保证事务更新的一致性和持久性。
三、事务方式不同
1、tidb数据库:tidb数据库使用的是扁平事务。
2、mysql:mysql使用的是分布式事务。
水平伸缩
陷阱:硬盘要求高,不支持GBK,不支持表别名,存储过程
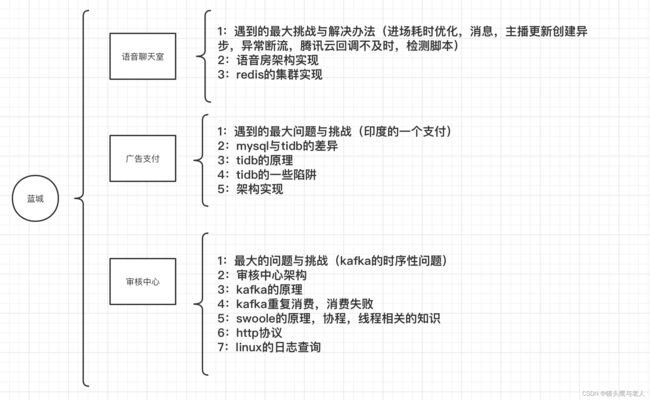
15:kafka相关
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
参考:https://mp.csdn.net/mp_blog/creation/editor
参考:Kafka(一)Kafka的简介与架构 - Frankdeng - 博客园
优点:解耦,缓解高并发,一个partation保证排序,异步通信,可恢复
常用mq
rabbitMq:重量级支持多重协议
redis:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
kafka:快速持久化,分布式,负载均衡,轻量级
1 broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
3 Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
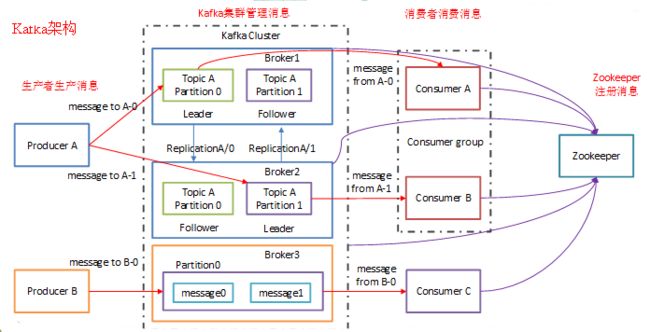
一个典型的Kafka集群中包含若干Producer,若干broker,若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
kafka保证顺序消费:如果AB顺序,A写入失败,B成功,A重试成功,这种影响,可以通过设置max.in.flight.requests.per.connection=1,生产者在接收服务端响应前,可以发送多少消息。但是这样会降低吞吐,或者在消费端进行业务判断,增加失败标记的字段。
可以通过设置message key ,比如userId,一个user id只会到一个partition,发送消息可以指定三个参数:topic,partition, key。
16:swoole相关:
参考:Swoole 的底层架构及运行原理 - 知乎
Swoole的协程在底层实现上是单线程的,因此同一时间只有一个协程在工作,协程的执行是串行的。这与线程不同,多个线程会被操作系统调度到多个CPU并行执行。
一个协程正在运行时,其他协程会停止工作。当前协程执行阻塞IO操作时会挂起,底层调度器会进入事件循环。当有IO完成事件时,底层调度器恢复事件对应的协程的执行。
对CPU多核的利用,仍然依赖于Swoole引擎的多进程机制。
因为协程是用户自己来编写调度逻辑的,对于我们的CPU来说,协程其实是单线程,所以CPU不用去考虑怎么调度、切换上下文,这就省去了CPU的切换开销,所以协程在一定程度上又好于多线程。
-
无需系统内核的上下文切换,减小开销;
-
无需原子操作锁定及同步的开销,不用担心资源共享的问题;
-
单线程即可实现高并发,单核 CPU 即便支持上万的协程都不是问题,
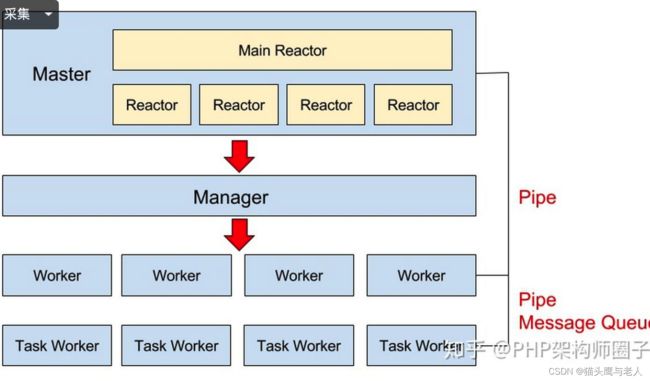
Swoole 官方对 Reactor、Worker、Task Worker有一个形象的比喻,如果把基于 Swoole 的 Web 服务器比作一个工厂,那么 Reactor 就是这个工厂的销售员,Worker 是负责生产的工人,销售员负责接订单,然后交给工人生产,而 Task Worker 可以理解为行政人员,负责提工人处理生产以外的杂事,比如订盒饭、收快递,让工人可以安心生产。
master进程,主reactor线程管理多个reactor线程,监听读写,通过主manager worker进程,维护多个子worker进程,处理具体逻辑。
Task Worker:功能和 Worker 进程类似,同样以多进程方式运行,但仅用于任务分发,当 Worker 进程将任务异步分发到任务队列时,Task Worker 负责从队列中消费这些任务(同步阻塞方式处理),处理完成后将结果返回给 Worker 进程。
17:http相关
??http 和 https 的区别
连接方式和端口都不相同,http无状态更简单,但是不安全,https采用ssl加密,需要证书和费用更加安全适合密码等敏感信息传递
204 No Content:成功但是无资源返回
301 永久重定向
302 临时性重定向,后面可能还会变
400 表示请求报文中存在语法错误;
401 未经许可,需要通过HTTP认证;
403 服务器拒绝该次访问(访问权限出现问题)
404 Not Found
502已经与后端建立了连接,但超时;504与后端连接未建立,超时。
??54.七层网络模型中,常用的协议:
物树网传会表应
物理层:通过物理媒介数据传输
数据链路层:封装解封ip报文
网络层:找到目标主机ip
传输层:tcp,udp传输
会话层表示层:无协议,建立会话格式转码
应用层:文件传输,为用户提供程序
Udp:不面向连接的不需要握手,目的只是给接收方方发数据,不管成功失败。对数据链路层的豹纹不进行组装拆分,在头部标示udp,记录源端口目标端口。更高效。支持一对一一对多,多对多。但是不可靠。
Tcp:传输协议是面向连接的,可靠的流协议。面向连接,仅支持点对点传播,面向字节流,不像udp直接传输报文,而是以字节流的形式无边界的传输
为什么三次握手,
避免报文丢失,造成服务资源的浪费。防止出现失败的客户端请求,导致服务端接收错误数据。
四次挥手
四次挥手为什么要有 close_wait 状态
1:防止超时,可以重试
2:防止比服务端关闭的早
18:linux查日志:
netstate 查看网络状态 -anp
netstat -plant 查看端口号。| grep 9000(查找指定端口号)
??a.log 每一行是 uri params ip 统计 IP出现次数前10的IP
uniq -c 计算有多少个
wc -l显示多少行
格式:awk [options] '{pattern + action}' {filenames}
awk -F ":" 'NR>=2 && NR<=6{print NR,$1}' /etc/passwd2
NR>=2 && NR<=6:这部分表示模式,是一个条件,表示取第2行到第6行。
{print NR,$1}:这部分表示动作,表示要输出NR行号和$1第一列。
awk 'NR>22 && NR<31' /etc/services 取出文件/etc/services的23~30行
awk -F "[ /]+" '$1~/^(ssh)$|^(http)$|^(https)$|^(mysql)$|^(ftp)$/{print $1,$2}' /etc/services |sort|uniq 取出常用服务端口号
内置变量
$0 当前行整行
$1 当前行被分割符划分成N段,$1表示第一个字段,$2标识第二个字段,$NF当前行被分割后的最后一列(字段)
NF 当前行被分割符划分成8段 NF=8
日志格式如下:
2013-10-29 10:26:09, INFO, send [email protected],templateId=23,titleId=11,type=3,[email protected],ip=10.3.22.134,mailType=4,emailId=526f1bd8c8f2a90213662a67
cat testawk.txt | awk -F ',' '{print $8}'| sort -n|uniq -c | sort -k 1 -n -r | head -10
sort -k 1 -n -r,按照第一列数字倒序排列
??给一个文件,一行内容:uri、response_time、code 统计 qps 最大的 uri 使用 Linux 命令统计、后来改用PHP统计使用awk
cat file | awk -F “:” ‘{print $1}’ | sort -n | unqi -c | sort -k 1 -n -r | head -10
awk -F ',' '{print $8}'| sort -n|uniq -c | sort -k 1 -n -r | head -10
file_get_content,explod(‘:’,$a)转换成数组,然后统计
统计文件中单词出现的频率,并按照次数排序 sort | uniqu -c | sort -t '' -k 1,4nr
19:php相关
??PHP 处理请求的过程?我修改代码,但是没有生效什么原因?opcache?
客户端请求通过网络协议,进行dns解析,数据传输,找到服务器地址,把信息给webserver,->遵循fastCgi协议把请求和数据给php解析器-》php处理再遵循协议返回。
webserver(apache|nginx)会根据cgi协议,把请求的url,数据,header等信息发给php解析器,php解析器会解析php.ini,初始化执行环境,处理请求,然后以cgi规定的方式返回处理的结果,退出进程,webserver再把数据返回给浏览器。
因为cgi每次请求都会初始化配置结束再关闭服务,这样效率非常低下,所以诞生了fast-cgi.他在开始启动一个master进程,解析配置文件,初始化还行环境,然后启动多个worker,把请求分配给不同的worker进程,master会根据需要动态的增减worker进程,而且只用进行一次解析配置和初始化环境,所以效率很高。
php-fpm是一个换门针对php实现fast-cgi协议的程序,实际上就是php fast-cgi进程管理器,负责管理进程池,调度php解析器来处理请求。
Cgi和fast-cgi是一种协议,定义了比如nginx应该把请求的什么数据给php解析器,php应该以什么样的格式返回。
php-cgi和php-fpm都是fast-cgi的具体实现,是他们处理请求,调度解析器处理请求。
缺点多进程占用内存,php-fpm能平滑启动.ini配置,php-cgi不能。
查看phpinfo是不是开启了opcache(默认开启)走的是缓存,需要重新启动php-fpm可以解决。
??php设置过期时间
Max_execution_time
php代码:int_set(‘max_execution_time’,300);
Set_time_limit(0);无限时,超时会清零,重新计算
以上仅仅是php脚本执行的时常,在php-fpm,cgi中不会生效。
Php-fpm.conf:
Request_terminate_timeout
Ngnix中的fastcgi 请求时间控制
fastcgi_connect_timeout
测试中,如果是php-fpm中的超时
Request_terminate_timeout
将显示 502 Bad Gateway
如果是nginx中cgi配置超时
fastcgi_read_timeout
将显示 504 Gateway Time-out
20:为什么要离职:
之前是因为觉得可能和yy有一些整合,但是直播重心转义,我们这里只是一个过度,需求比较少,感觉成长的比较慢。我们一些内部的调整,明年可能会在内部或者外面找一些新的机会
21:自我介绍:
22:GO-面试考点总结_aichojie的博客-CSDN博客
23:PHP相关?
php-fpm:8G内存一般100个,占用一个G内存,如果机器只有1.5个G就改成10个
pm:表示使用那种方式,有两个值可以选择,就是static(静态)或者dynamic(动态)。
在更老一些的版本中,dynamic被称作apache-like。这个要注意看配置文件的说明。
下面4个参数的意思分别为:
pm.max_children:静态方式下开启的php-fpm进程数量
pm.start_servers:动态方式下的起始php-fpm进程数量
pm.min_spare_servers:动态方式下的最小php-fpm进程数
pm.max_spare_servers:动态方式下的最大php-fpm进程数量
24:redis相关?
当前使用4.0
4.0:RDB和aof混合持久化,增加cluster,优化主从节点切换 需要全量复制
3.2:从节点过期数据保证一致性,加速RDB的加载速度
3.0:incr性能提升,lru算法提升
2.8:优化redis sentinel
2.6:建过期增加毫秒,从节点提供只读
25:GO处理web请求?
go:http client 和 http server
http client :可以发送请求
http server:可以接收请求和处理请求
web请求包含:请求头,请求行,请求体。
在Go语言中,使用http.Request结构来处理http请求的数据,根据content-type,获取请求头,参数,表单信息。
go main函数的执行流程?
初始化包,按照import的顺序,如果存在递归引用,比如a->b->c,加载就是c->b->a,main总是最后初始化,避免出现循环引用。init可以用于任何包重复定义,main只能有一个。调用顺序同上面,无递归顺序,有递归里面逆序。在同一个文件中,常量、变量、init()、main() 依次进行初始化。
所有 init 函数都在同⼀个 goroutine 内执⾏。
所有 init 函数结束后才会执⾏ main.main 函数。
26:http报文有什么?
请求方式(GET)路径http版本
header信息
body:请求参数信息
https:防劫持
通过对称加密和非对称加密,对称加密解密一个算法,非对称用公钥加密,私钥解密。常用算法:RSA
27:redis Zset数据结构?
[score,value]键值对数量少于128个;- 每个元素的长度小于64字节;
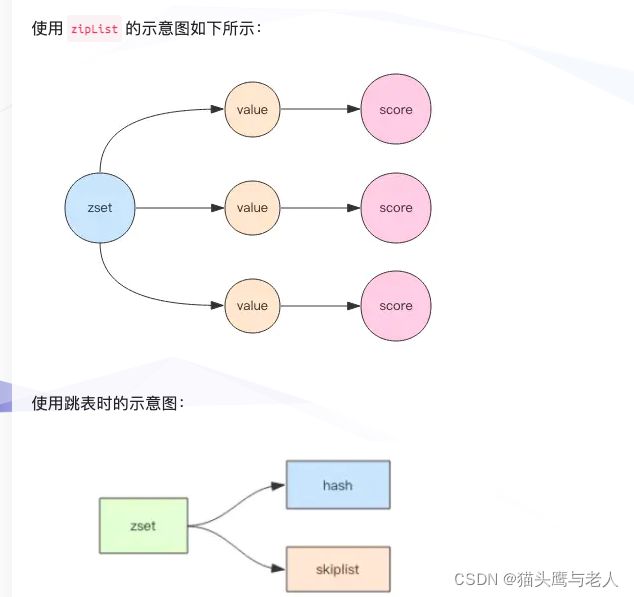
header:指向跳表的头节点,通过这个指针可以直接找到表头,时间复杂度为O(1);
tail:指向跳表的尾节点,通过这个指针可以直接找到表尾,时间复杂度为o(1);
length:记录跳表的长度,即不包括头节点,整个跳表中有多少个元素;
level:记录当前跳表内,所有节点中层数最大的level;
zskiplist的示意图如下所示

28:Http 请求的方法 HEAD?OPTION?PATCH,什么是 restful?
head:类似get,响应没有具体内容,用于获取报头
option:允许客户端查看服务器性能
Patch:更新部分字段,没有不会创建
put:取代,没有会床娟,put幂等,post不幂等
rest:是一种思想描述状态转变,是一种架构风格
sestful:就是一个符合rest架构风格的实现,是一种架构的规范和约束
原则有:
1:网络上的资源都有一个资源标识
2:对资源操作不会改变标识
3:同一资源有多种形式,xml,json
4:所有操作都是无状态的