2022年终Java编程技术总结
目录
00 总体脑图
第一章、基础篇
01 计算机基础 ## 1.1 操作系统
1.1.1 基本知识
略
1.1.2 常见Linux命令
| 目录 | 文件 | 内容 | 搜索 | 系统类 | 网络 | 权限 | |
|---|---|---|---|---|---|---|---|
| cd | cp/scp | vi/vim | find: find . -name xx | kill | netstat -an | chmod | |
| ls | mv | cat | grep: ps -ef | grep xx | lsof: lsof-i:port | ||
| mkdir | rm | tail | whereis | top | |||
| pwd | tar/gzip/unzip | which | su | ||||
| ll | uname | ||||||
| df |
02 计算机网络
1、HTTP
1.1、 URL长度的限制由浏览器规定的,而不是HTTP协议。
| 编号 | 浏览器 | 长度(字节) |
|---|---|---|
| 1 | IE | 2048 |
| 2 | 360 | 2118 |
| 3 | Firfox | 65536 |
| 4 | Safari | 80000 |
| 5 | Opera | 190000 |
| 6 | Chrome | 8182 |
1.2、HTTP Method
| 请求方法 | 说明 | 数据库操作 |
|---|---|---|
| post | 新增 | C |
| get | 查询 | R |
| put | 更新 | U |
| delete | 删除 | D |
1.3、 Http Code
| code | 描述 |
|---|---|
| 以1开头(1xx) | 服务器处收到请求的过程中 |
| 以2开头(2xx) | 请求成功 |
| 以3开头(3xx) | 重定向 |
| 以4开头(4xx) | 客户端状态码(由于客户端这边的问题,服务器无法处理。如客户端这边的数据格式不对、给的资源路径 不对、权限不足等) |
| 以5开头(5xx) | 服务端状态码(服务器处理出错,服务端内部业务异常或系统异常) |
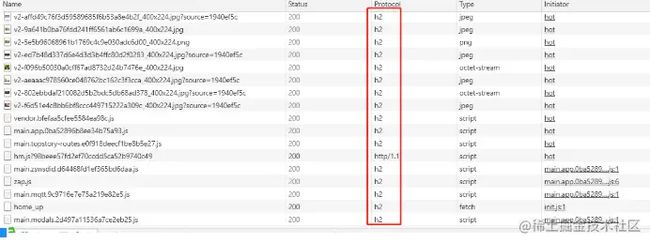
2、 Http2.0
- 相对HTTP1.x性能上有所提升,采用了二进制分帧、多路复用、头部压缩等提升性能技术
- 目前很多平台已开始使用HTTP2.0,如 知乎、淘宝、百度、谷歌、 github、掘金 等,可以打开F12看到协议这列为"h2"
3、HTTPS
几个概念
1、文中的使用非对称加密对称密钥就是数字信封技术
2、https通讯全过程
TCP三次握手->建立SSL连接(验证双方证书身份、获取对称密钥)->建立https连接(使用对称密钥加密通讯)
3、https单向身份认证一般来说就是客户端验证服务器https证书是否是合法有效的。https双方身份认证就是客户端验证服务器身份,服务器也验证客户端的身份,一般在安全要求 比较高的双方接口对接时,验证双向的身份。
3.1、HTTPS单向身份认证

1)客户端向服务器发送https请求,基本包括SSL证书版本等信息给服务器端建立连接。
2)服务器端确认SSL证书版本、服务器公钥证书返回给客户端。
3)客户端校验服务器端证书是否合法(通过CA证书来验证服务器身份)。验证通过就继续下一步,验证不通过警告提示(如浏览器的警告提示)。一般CA证书的验证包括:证书信任链验证、证书有效期验证、证书是否吊销等。
4)客户端发送可支持的对称加密方案到服务器端供其选择。
5)服务器端将选择好的加密方案(算法)以明文方式发给客户端。
6)客户端收到采用的加密算法后,产生随机码作为对称加密的密钥。
7)客户端把对称密钥使用服务器端的公钥(非对称加密)加密后发送到服务器端。
8)服务器端使用私钥(非对称加密)解密后获得对称加密的密钥。
9)双方通过对称加密密钥(随机数)进行加密通讯。
以下是浏览器通过https访问百度服务器的具体实例:

3.2、HTTPS双向身份认证

1)客户端通过发送Client Hello报文开始SSL通信。报文中包含客户端支持的SSL的指定版本、加密组件列表、所使用的加密算法及密钥长度、随机数Random-A等。
2)服务器可进行SSL通信时,会以Server Hello报文作为应答。和客户端一样,在报文中包含SSL版本以及加密组件(客户端支持中筛选)、服务器生成的随机数Random-B、服务器公钥证书PublicKey-B。
3)客户端校验服务器端证书PublicKey-B是否合法(通过CA证书来验证服务器身份)。验证通过就继续下一步,验证不通过警告提示(如浏览器的警告提示)。一般CA证书的验证包括:证书信任链验证、证书有效期验证、证书是否吊销等。
4)客户端将自己的公钥证书PublicKey-A发送给服务器端,供服务器验证客户端身份。客户端事先也需申请相应的SSL证书。
5)服务器校验客户端证书PublicKey-A是否合法(通过CA证书来验证服务器身份)。验证通过就继续下一步,验证不通过警告提示(如浏览器的警告提示)。一般CA证书的验证包括:证书信任链验证、证书有效期验证、证书是否吊销等。
6)客户端发送可支持的对称加密方案到服务器端供其选择。
7)服务器端将选择好的加密方案(算法)发送给客户端,报文使用客户端公钥PublicKey-A进行非对称加密。
8)客户端使用自己的私钥PrivateKey-A解密报文,并通过Random-A、Random-B推算出Random-C,也就是对称加密的密钥。
9)客户端使用服务器公钥PublicKey-B非对称加密对称密钥Random-C,发送给服务器。
10)服务器使用自己的私钥PrivateKey-B解密报文,解决出对称密钥Random-C。
11)双方完成身份验证,并使用对称密钥Random-C进行加密通讯。
4、TCP协议

【问题1】为什么需要三次握手?
相对UDP,TCP是可靠的通讯协议,是全双工通信。TCP三次握手的关键在于,序列号seq的交换确认,因为对于客户端和服务端来说,双方序列号的确认是可靠传输的关键。1、2步握手只能确定发送方发和收正常,并不能确定接收方也是发和收正常,增加了第3次握手,才能保证接收方也是发和收都正常。
【问题2】为什么连接的时候是三次握手,关闭的时候却是四次挥手?
由于服务器端回复已经响应完毕,此时客户端并不是立刻就收完了,所以服务器处于半关闭状态,等服务器完全处理完,客户端收到通知后才完全关闭,固为4次。
【问题3】怎么简单描述三次握手?
就像是小明与小红发微信一样
小明:我要给你发数据了
小红:好的,我准备好了,你发吧
小明:好的,收到
【问题4】为什么是四次挥手
小红:我的数据发完了。
小明:好的,收到,我看看收完了没。
小明:好的,已经收完了,你关闭吧。
小红:好的,我关闭了。
5、 WebSocket
一般客户端向服务器发送请求后服务器会回应响应。但服务器不会主动向客户端发送请求。响应式的方式可以解决此类问题。当然传统的方式也可以达到相同的效果比如:轮询、http长连接。
| 方式 | 实现 | 说明 |
|---|---|---|
| 轮询 | js+ajax定时轮询 | 每次轮询都是一对request+response,消耗资源、不实时 |
| http长连接 | keep-alived | http每次请求均是一对request+response,keep-alived类似把多个request放在同一个连接发送,当然每个request都会有自己对应的response,实际上也是多次的请求与响应,且keep-alived本身是不可控的 |
| comet | comet http长连接的另一种方式,类似hack的方式,但实际上还是发送一个request连接,服务器不是立即返回,等到服务器有相应的结果再返回。这个连接不能被重复使用 | |
| websocket | websocket协议 | websocket类似tcp是全双工通信,在协议本身上(请求头、二进制帧)网络开销更小、速度更快、更及时。 |
6、OSI七层与协议

03 JAVA基础
1 HashMap
| JDK1.7 | JDK1.8 | |
|---|---|---|
| 存储 | 数组+链表 | 数组+链表+红黑树 |
| 位置算法 | h & (length-1) | h & (length-1) |
| 链表超过8 | 链表 | 红黑对(链表超过8且数组长度超64) |
| 节点结构 | Entry |
Node |
| 插法 | 头插法(扩容环化造成死循环) | 尾插法 |
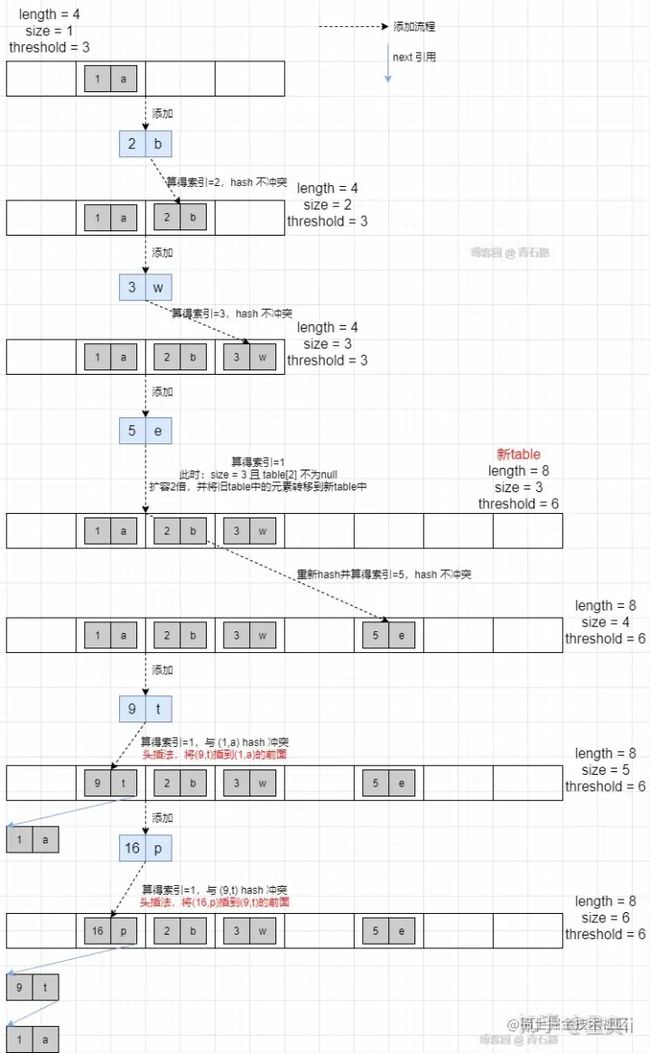
JDK1.7
使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode取模后的结果相同,那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表;这样数据遍历时间就过长。1.7中hashmap链表插入的方式是使用头插法。
JDK1.8
使用一个Node数组来存储数据,但是这个Node可能是链表结构,也可能是红黑树结构;如果插入的元素key的hashcode值相同,那么这些key也会被定位到Node数组的同一个格子里,如果不超过8个使用链表存储,超过8个且Node数组长度超过64,会将链表转换为红黑树。1.8中hashmap链表插入的方式是使用尾插法。
【相关问题】
问题一:为什么jdk1.8后改为尾插法?
主要是因为头插法在多线程扩容情况下会引起链表环。那什么是链表环呢?
引用一张图片(来源blog.csdn.net/weixin_3142…):
2 ConcurrentHashMap
主要是支持安全的多线程的读写
| JDK1.7 | JDK1.8 | |
|---|---|---|
| 实现 | segment+hashentry | Node+CAS+Synchronized |
| 锁 | Segment继承ReetrantLock | Synchronized |
| 存储 | 数组+链表 | 数组+链表+红黑树 |
| 链表超过8 | 数组 | 红黑树 |
| 插法 | 头插法 | 尾插法 |
3 equals(值相等) ==(引用相等)
equals源代码中可以看到:
JDK自带的equals有两种,针对Object对象及String对象
1、String中的equals
==判断是否相等,相等直接返回true->再判断是否为string类型,否直接返回false->是则继续判断对象length->循环判断char是否相等(jdk8使用的是char,高版本的jdk已使用效率更高的byte)
2、Object中的equals
直接return (this == obj),一般业务对象比较要改造equals方法
p.s.自定义对象需要重写equals
**
4 String线程安全问题
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
-
操作少量的数据: 适用 String
-
单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
-
多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
5 深拷贝、浅拷贝、引用拷贝
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝 :深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
上面的结论没有完全理解的话也没关系,我们来看一个具体的案例!
浅拷贝
浅拷贝的示例代码如下,我们这里实现了 Cloneable 接口,并重写了 clone() 方法。
clone() 方法的实现很简单,直接调用的是父类 Object 的 clone() 方法。
public class Address implements Cloneable {
private String name; // 省略构造函数、Getter&Setter方法
@Override
public Address clone() {
try {
return (Address) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
public class Person implements Cloneable {
private Address address;
// 省略构造函数、Getter&Setter方法
@Override
public Person clone() {
try {
Person person = (Person) super.clone();
return person;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
复制代码测试 :
Person person1=new Person(new Address("武汉"));
Person person1Copy=person1.clone(); // true
System.out.println(person1.getAddress()==person1Copy.getAddress());
复制代码从输出结构就可以看出, person1 的克隆对象和 person1 使用的仍然是同一个 Address 对象。
深拷贝
这里我们简单对 Person 类的 clone() 方法进行修改,连带着要把 Person 对象内部的 Address 对象一起复制。
@Override
public Person clone(){
try{
Person person=(Person)super.clone();
person.setAddress(person.getAddress().clone());
return person;
}catch(CloneNotSupportedException e){
throw new AssertionError();
}
}
复制代码测试 :
Person person1 = new Person(new Address("武汉"));
Person person1Copy = person1.clone(); // false
System.out.println(person1.getAddress() == person1Copy.getAddress());
复制代码从输出结构就可以看出,虽然 person1 的克隆对象和 person1 包含的 Address 对象已经是不同的了。
6 Spring Bean加载过程
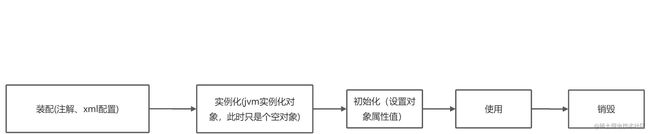
启动spring容器(创建beanfactory)->加载配置(注解、xml)->实例化bean(执行构造方法)->注入属性(设置bean属性)->初始化bean(设置属性值)->使用->销毁
7 多线程CAS
CAS(Compare and swap 比较并交换) 一种CPU指令级的操作,保证数据一致性。A B线程更新变量值,A B线程先获取变量值,然后生成新值,变量值放在内存V中、预期原值为A(备份值)、新值为B。如果V=A 更新新值。在多线程情况下保证值的一致性。主要是保证线程当时取的值,在要更新的时候内存还是那个值没有被其它线程改变了。
8 命名规范
- 类 一般使用名词
- 接口 一般使用形容词
-
方法 一般使用动词
9 String
- String 不可变
- Stringbuilder 可变 线程不安全 适合单线程大量请求
- Stringbuffer 可变 线程安全 适合多线程
效率方面
StringBulider > StringBuffer > String
10 常用注解
- 常规
@SpringbootApplication @SpringBootConfiguration @Configuration @AutoWired
- controller层
@Controller @RestController @Component @RequestMapping @GetMapping
- servcie层
@Service @Resource
11 Java IO
04 JAVA进阶 # 1 JVM
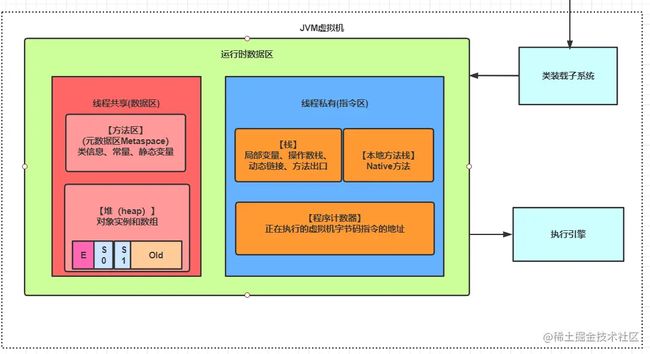
1.1 jvm内存模型
为了屏蔽各种硬件和操作系统对内存访问的差异,Java定义了JVM内存模型

主内存->工作内存->线程
java内存模型和java运行时数据区的关系:主内存对应着java堆和方法区,工作内存对应着java栈。
1.2 jvm运行时数据区
1.3 GC
1.3.1 GC过程
1)判断是否是垃圾
可以通过引用计数算法和可达性分析算法不判断,由于引用计数算法无法解决循环引用的问题,所以目前使用的都是可达性分析算法
2)遍历并回收垃圾
可以通过垃圾收集器(Serial/Parallel/CMS/G1)来回收垃圾,垃圾收集器使用的算法标记清除算法、标记整理算法、复制回收算法和分代回收算法。
1.3.2 GC种类

| Minor | [maɪnə] | Eden |
|---|---|---|
| Young | Eden+S0+S1 | |
| Major | [ˈmeɪdʒə(r)] | Old |
| Full | Eden+S0+S1+Old |
1.3.3 GC三种收集方法:
标记清除:先标记,标记完毕之后再清除,效率不高,会产生碎片
标记整理:标记完毕之后,让所有存活的对象向一端移动
复制算法:Eden区S0、S1 区比例为8:1:1 ,就是上面谈到的 YGC使用的就是复制回收算法。
1.3.4 GC收集器
1.3.4.1 收集器
1)Serial收集器
一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程直到它收集结束。
特点:CPU利用率最高,停顿时间即用户等待时间比较长。
适用场景:小型应用
通过JVM参数-XX:+UseSerialGC可以使用串行垃圾回收器。
2)Parallel收集器(jdk8默认收集器)
采用多线程来通过扫描并压缩堆
特点:停顿时间短,回收效率高,对吞吐量要求高。
适用场景:大型应用,科学计算,大规模数据采集等。
通过JVM参数 XX:+USeParNewGC 打开并发标记扫描垃圾回收器。
3)CMS收集器
采用“标记-清除”算法实现,使用多线程的算法去扫描堆,对发现未使用的对象进行回收。
(1)初始标记
(2)并发标记
(3)并发预处理
(4)重新标记
(5)并发清除
(6)并发重置
特点:响应时间优先,减少垃圾收集停顿时间
适应场景:服务器、电信领域等。
通过JVM参数 -XX:+UseConcMarkSweepGC设置
4)G1收集器(jdk17默认收集器)
在G1中,堆被划分成 许多个连续的区域(region)。采用G1算法进行回收,吸收了CMS收集器特点。
特点:支持很大的堆,高吞吐量
--支持多CPU和垃圾回收线程
--在主线程暂停的情况下,使用并行收集
--在主线程运行的情况下,使用并发收集
实时目标:可配置在N毫秒内最多只占用M毫秒的时间进行垃圾回收
通过JVM参数 –XX:+UseG1GC 使用G1垃圾回收器
1.3.4.2 收集器对比
| 收集器 | CMS | G1 |
|---|---|---|
| 回收算法 | 标记清除 | 标记整理 |
| 回收区域 | 老年代 | 新生代+老年代 |
| 内存布局 | 传统 | 将新生代、老年代切一起分成一个个Region |
| 内存碎片 | 产生碎片空间 | 碎片空间小 |
| 并发 | 并发 | 并发 |
| JDK使用 | JDK8默认(Parallel) | JDK9默认 |
| 停顿时间 | 最短停顿时间 | 可预测停顿时间 |
1.3.5 GC小结
- 相关的概念
| 名称 | 说明 | 备注 |
|---|---|---|
| GC | Garbage Collection 垃圾回收 | |
| GC种类 | MinorGC、MajorGC、YongGC、OldGC | |
| GC收集算法 | 标记清除算法、标记整理算法、复制回收算法 | |
| GC收集器 | Serial、Parallel、CMS、G1、ZGC | |
| 存活判断算法 | 引用计数算法、可达性分析算法 |
- 总结
在Java虚拟机中GC是一个重要的部分,我们可以看到在GC中有不少概念GC种类、GC收集算法、GC收集器、引用计数算法、可达性分析算法。原本就比较难懂这概念一多就有点乱了。下面一个图从总体上梳理了一下它们之间的相互关系。
1)整个垃圾回收可以分成两步:1、先判断对象是否存活;2、再回对象。

2)在整个垃圾回收各概念之间的关系
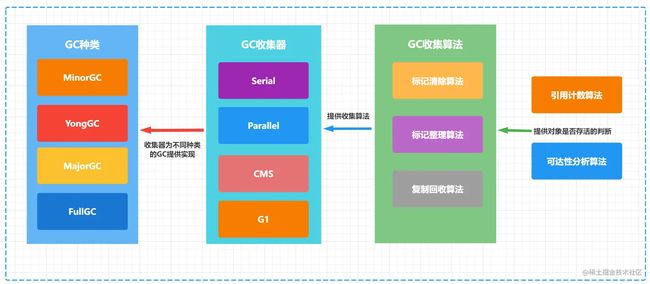
-
GC收集器核心是GC收集算法
-
GC收集算法一般先要判断对象是否存活就会用到引用计数算法或可达性分析算法
-
引用计数算法解决不了循环引用的情况,所以目前使用的都是可达性分析算法
-
GC分为4个种类,作用在内存的不同区域(新生代Eden/S0/S1、老年代)。这时GC收集器会相互组合完成不同种类的GC,从而达到JVM GC的功能
1.4 类加载全过程

1.5 常见参数
- Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时间变慢
- Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常
- Xss 是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程大约需要占用多少内存,可能会有多少线程同时运行等
- -Xmn、-XX:NewSize/-XX:MaxNewSize、-XX:NewRatio
-
- 高优先级:-XX:NewSize/-XX:MaxNewSize
- 中优先级:-Xmn(默认等效 -Xmn=-XX:NewSize=-XX:MaxNewSize=?)
- 低优先级:-XX:NewRatio
- 如果想在日志中追踪类加载与类卸载的情况,可以使用启动参数 -XX:TraceClassLoading -XX:TraceClassUnloading
1.6 常见问答
1、全局变量与局部变量在内存中的区别?
- 局部变量存储在栈中
- 全局变量(java中无全局变量概念,java中叫成员变量),成员变量均存储在方法区中,JVM只是定义了方法这个概念,并没有定义它的具体组成
1、jdk1.7方法区(习惯上把永久代叫方法区)
2、jdk1.8方法区(由元数据区+堆组成),其中字符串常量池被放在堆中
jdk1.7的永久代在jdk1.8中去掉并换成元数据区
2 多线程
2.1 数据共享
1、多线程如何共享数据
- 线程代码相同,即runnable中的代码一致,这样可以直接共享
/**
* 卖票处理
* @author yang
*/
public class SellTicket {
//卖票系统,多个窗口的处理逻辑是相同的
public static void main(String[] args) {
Ticket t = new Ticket();
new Thread(t).start();
new Thread(t).start();
}
}
/**
* 将属性和处理逻辑,封装在一个类中
* @author yang
*/
class Ticket implements Runnable{
private int ticket = 10;
public synchronized void run() {
while(ticket>0){
ticket--;
System.out.println("当前票数为:"+ticket);
}
}
}
作者:那时年少轻狂
链接:https://www.imooc.com/article/17112?block_id=tuijian_wz
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
复制代码- 线程代码不相同,即runnable中的代码不一致,Runnable1 Runnable2,利用一个对象,把runnable中的方法封装到这个对象中去,数据也在这个对象中
public class MultiThreadShareData {
public static void main(String[] args) {
ShareData data = new ShareData();
new Thread(new MyRunnable1(data)).start();
new Thread(new MyRunnable2(data)).start();
}
}
class MyRunnable1 implements Runnable {
private ShareData data;
public MyRunnable1(ShareData data) {
this.data = data;
}
public void run() {
data.decrement();
}
}
class MyRunnable2 implements Runnable {
private ShareData data;
public MyRunnable2(ShareData data) {
this.data = data;
}
public void run() {
data.increment();
}
}
class ShareData {
private int j = 10;
public synchronized void increment() {
j++;
System.out.println("线程:" + Thread.currentThread().getName() + "加操作之后,j = " + j);
}
public synchronized void decrement() {
j--;
System.out.println("线程:" + Thread.currentThread().getName() + "加操作之后,j = " + j);
}
}
作者:那时年少轻狂
链接:https://www.imooc.com/article/17112?block_id=tuijian_wz
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
复制代码2、父子线程如果共享数据
通过 InteritableThreadLocal实现共享
2.2 synchronized与Lock区别
| 类别 | synchronized | Lock |
|---|---|---|
| 形态 | java关键字、jvm层次 | 类 |
| 释放 | 1、自动释放2、执行完同步代码或异常 | 1、手动释放unlock()2、在finally里必须释放,不然会死锁 |
| 类型 | 悲观锁/非公平锁 | 悲观锁/公平锁、非公平锁 |
| 状态 | 无法判断 | 可判断tryLock() |
| 性能 | 少量同步 | 大量同步 |
总结:建议使用synchronized,在jdk1.5之前Lock优于synchronized,但在jdk1.5之后对synchronized进行了优化,后面在性能方面基本与Lock一样且使用简单(有作者说"synchronized是亲生的,jdk还是会一直优化他不会让Lock优于它")。
2.3 线程池
2.3.1 为什么要用线程池
- 降低资源消耗。通过重复利用已创建的线程降低线程创建、销毁线程造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配、调优和监控
2.3.2 ThreadPoolExecutor线程池类参数详解
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数量,线程池维护线程的最少数量 |
| maximumPoolSize | 线程池维护线程的最大数量 |
| keepAliveTime | 线程池除核心线程外的其他线程的最长空闲时间,超过该时间的空闲线程会被销毁 |
| unit | keepAliveTime的单位,TimeUnit中的几个静态属性:NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS |
| workQueue | 线程池所使用的任务缓冲队列 |
| threadFactory | 线程工厂,用于创建线程,一般用默认的即可 |
| handler | 线程池对拒绝任务的处理策略 |
当线程池任务处理不过来的时候(什么时候认为处理不过来后面描述),可以通过handler指定的策略进行处理,ThreadPoolExecutor提供了四种策略:
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常;也是默认的处理方式。
- ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
可以通过实现RejectedExecutionHandler接口自定义处理方式。
2.3.3 线程池任务执行
1)添加执行任务
- submit() 该方法返回一个Future对象,可执行带返回值的线程;或者执行想随时可以取消的线程。Future对象的get()方法获取返回值。Future对象的cancel(true/false)取消任务,未开始或已完成返回false,参数表示是否中断执行中的线程
- execute() 没有返回值。
2) 线程池任务提交过程
一个线程提交到线程池的处理流程如下图

- 核心线程数(正式员工)
- 等待队列(外包员工)
- 最大线程数(全体员工)
- 如果此时线程池中的数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
- 如果此时线程池中的数量等于corePoolSize,但是缓冲队列workQueue未满,那么任务被放入缓冲队列。
- 如果此时线程池中的数量大于等于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
- 如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。
- 当线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止。这样,线程池可以动态的调整池中的线程数。
总结即:处理任务判断的优先级为 核心线程corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
注意:
- 当workQueue使用的是无界限队列时,maximumPoolSize参数就变的无意义了,比如new LinkedBlockingQueue(),或者new ArrayBlockingQueue(Integer.MAX_VALUE);
- 使用SynchronousQueue队列时由于该队列没有容量的特性,所以不会对任务进行排队,如果线程池中没有空闲线程,会立即创建一个新线程来接收这个任务。maximumPoolSize要设置大一点。
- 核心线程和最大线程数量相等时keepAliveTime无作用.
3)线程池关闭
- shutdown() 不接收新任务,会处理已添加任务
- shutdownNow() 不接受新任务,不处理已添加任务,中断正在处理的任务
2.3.4 常用队列介绍
- ArrayBlockingQueue: 这是一个由数组实现的容量固定的有界阻塞队列.
- SynchronousQueue: 没有容量,不能缓存数据;每个put必须等待一个take; offer()的时候如果没有另一个线程在poll()或者take()的话返回false。
- LinkedBlockingQueue: 这是一个由单链表实现的默认无界的阻塞队列。LinkedBlockingQueue提供了一个可选有界的构造函数,而在未指明容量时,容量默认为Integer.MAX_VALUE。
队列操作:
| 方法 | 说明 |
|---|---|
| add | 增加一个元索; 如果队列已满,则抛出一个异常 |
| remove | 移除并返回队列头部的元素; 如果队列为空,则抛出一个异常 |
| offer | 添加一个元素并返回true; 如果队列已满,则返回false |
| poll | 移除并返回队列头部的元素; 如果队列为空,则返回null |
| put | 添加一个元素; 如果队列满,则阻塞 |
| take | 移除并返回队列头部的元素; 如果队列为空,则阻塞 |
| element | 返回队列头部的元素; 如果队列为空,则抛出一个异常 |
| peek | 返回队列头部的元素; 如果队列为空,则返回null |
2.3.5 Executors线程工厂类
- Executors.newCachedThreadPool();
说明: 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.
内部实现:new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue()); - Executors.newFixedThreadPool(int);
说明: 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
内部实现:new ThreadPoolExecutor(nThreads, nThreads,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue()); - Executors.newSingleThreadExecutor();
说明:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照顺序执行。
内部实现:new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue()) - Executors.newScheduledThreadPool(int);
说明:创建一个定长线程池,支持定时及周期性任务执行。
内部实现:new ScheduledThreadPoolExecutor(corePoolSize)
【附】阿里巴巴Java开发手册中对线程池的使用规范
1.【强制】创建线程或线程池时请指定有意义的线程名称,方便出错时回溯。
正例:
public class TimerTaskThread extends Thread {
public TimerTaskThread(){
super.setName("TimerTaskThread");
...
}
}
- 【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明: 使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资
源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者
“过度切换”的问题。 - 【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2) CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE, 可能会创建大量的线程,从而导致 OOM。
2.3.6 总结
ThreadPoolExecutor通过几个核心参数来定义不同类型的线程池,适用于不同的使用场景;其中在任务提交时,会依次判断corePoolSize, workQueque, 及maximumPoolSize,不同的状态不同的处理。
2.4 常用线程类用法
1)主线程判断所有子线程是否执行完成
- CountDownLatch
- CompletableFuture
jdk8增加的类,可以代替CountDownLatch
3 设计模式
3.1 概述
可以发现,设计模式好像都是类似的。越看越感觉都着不多。其实都是类似面向接口编程的一种体现,只不过侧重点不一样或者说要体现的结果不一样。
3.2 使用场景
问题一:应对可能变化的对象实现
方案:间接创****建
模式:工厂模式
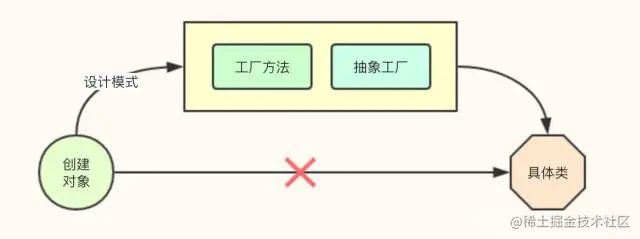
问题二:为请求指定相应的操作(类似请假审批,不同时长对应不同职位的审批人)
方案:程序根据请求动态选择操作
模式:责任链模式
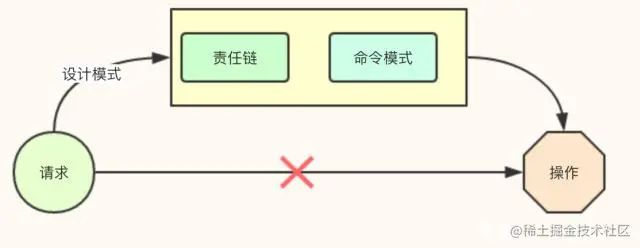
3.3 具体说明
3.3.1 策略模式
- 策略模式说明

一个行为型模式,包含多个行为或职责的业务,通过策略模式简化
public class StrategyContext {
Strategy strategy;
public StrategyContext(Strategy strategy) {
this.strategy = strategy;
}
/**
*
*/
public int context(int a, int b) {
return strategy.operator(a,b);
}
}
复制代码策略模式的核心为StrategyContext上下文类,持有strategy对象,在context完成操作。
- 策略模式实践
如何使用策略模式解决大量使用if else 或大量switch问题,策略模式+反射。
策略模式后好像使用都还是要用if else来决定调用哪个类,所以在引入策略模式后,在上下文类还要增加反射。
public class StrategyContext {
Strategy strategy;
public StrategyContext(String type) throws Exception {
Class clazz = Class.forName(type);
this.strategy = (Strategy) clazz.newInstance();
}
/**
*
*/
public int context(int a, int b) {
return strategy.operator(a,b);
}
复制代码当然这里的type可以用个枚举来解决。感觉代价非常大是不是没必要,不过代码的可读性还是增强了。
p.s. 在框架里策略模式中的Context一般不会直接出现,类似spring中直接在使用时就通过注解给设置了
3.3.2、装饰器模式
描述:原接口Shape不变,方法数量不变,在方法实现中增加修饰
场景:
场景一:一个类功能简单,满足不了我们的需求
场景二:给原方法增加日志功能,不改变原方法,新的实现类去实现此功能,带入的对象为接口对象

特点
- 原接口Shape不动,增加新的装饰类ShapeDecorator
- 原方法名不变,只是增加或修饰此方法体
- ColorShapeDecorator装饰类持有原对象,只是增加了修饰
public class ColorShapeDecorator extends ShapeDecorator {
public ColorShapeDecorator(Shape shape) {
super(shape);
}
@Override
public void draw() {
setColor();
shape.draw();
}
private void setColor() {
//设置画图颜色
}
}
复制代码3.3.3 代理模式
设置一个中间代理来控制访问原目标对象,达到增强原对象的功能和简化访问方式的目的
场景:
场景一:不改变原方法,对原方法增加耗时的计算
场景二:rpc远程调用,client端进行动态代理类似耗时计算一样,用户不用关心client的具体实现
分类
- 静态代理模式
- 动态代理模式
说明

- 静态代理模式
/**
* 与适配器模式的区别,适配器模式主要改变所考虑对象的接口,
* 而代理模式不能改变所代理类的接口。与装饰器模式的区别,
* 装饰器模式是为了增强功能,代理模式是为了加以控制
*/
public class ProxySigntureService implements SigntureService {
private SigntureService signatureService;
/**
* Default constructor
*/
public ProxySigntureService(SigntureService signatureService) {
this.signatureService = signatureService;
}
public void sign() {
//控制对这个对象的访问
// 实现电子签名
}
}
复制代码- 动态代理模式
public class DynamicProxySignatureService implements InvocationHandler {
private Object obj;
public DynamicProxySignatureService(Object obj) {
this.obj = obj;
}
@Override
public Object invoke(Object proxyObj, Method method, Object[] objects)
throws Throwable {
return method.invoke(obj,objects);
}
}
复制代码参考文章:blog.csdn.net/liujiahan62…
3.3.4 适配器模式
描述: 原接口不变,增加方法数量
场景:
场景一:原接口不变,在基础上增加新的方法。
场景二:接口的抽象方法很多,不想一一实现,使用适配器模式继承原实现类,再实现此接口

- 适配器模式适合需要增加一个新接口的需求,在原接口与实现类基础上需要增加新的接口及方法。类似原接口只能method01方法,需求是增加method02方法,同时不再使用之前接口类。
新接口
public interface Targetable {
/**
*
*/
public void method01();
/**
*
*/
public void method02();
}
复制代码原接口实现类
public class Source {
public void method01() {
// TODO implement here
}
}
复制代码适配器类,用于实现新接口。继承原实现类,同时实现新接口。
public class Adapter extends Source implements Targetable {
/**
*
*/
public void method02() {
// TODO implement here
}
}
复制代码测试类
public class AdapterTest {
public static void main(String[] args) {
Targetable targetable = new Adapter();
targetable.method01();
targetable.method02();
}
}
复制代码3.3.5 单例模式
保证被创建一次,节省系统开销。
1)单例实现方式
- 饿汉式
- 懒汉式
- 懒汉式+synchronized
- 双重校验
- 静态内部类
- 枚举(推荐方式)
2)实现代码
- 饿汉式
package com.hanko.designpattern.singleton;
/**
* 饿汉式 (饿怕了,担心没有吃,所以在使用之前就new出来)
*优点:实现简单,安全可靠
*缺点:在不需要时,就已实例化了
* @author hanko
* @version 1.0
* @date 2020/9/14 18:50
*/
public class HungrySingleton {
//特点一 静态私有变量 直接初始化
private static HungrySingleton instance = new HungrySingleton();
//特点二 构造函数私有
private HungrySingleton(){
}
public static HungrySingleton getInstance(){
return instance;
}
public void doSomething(){
//具体需要实现的功能
}
}
复制代码- 懒汉式
package com.hanko.designpattern.singleton;
/**
* 懒汉式(非常懒,所以在要使用时再去new)
*优点:简单
*缺点:存在线程安全问题
* @author hanko
* @version 1.0
* @date 2020/9/14 18:50
*/
public class SluggardSingleton {
//特点一 静态私有变量,先不初始化
private static SluggardSingleton instance;
//特点二 构造函数私有
private SluggardSingleton(){
}
//特点三 null判断,没有实例化就new
public static SluggardSingleton getInstance(){
if(instance == null){
instance = new SluggardSingleton();
}
return instance;
}
public void doSomething(){
//具体需要实现的功能
}
}
复制代码- 懒汉式+Synchronized
package com.hanko.designpattern.singleton;
/**
* 懒汉式(非常懒,所以在要使用时再去new)
*优点:简单
*缺点:存在线程安全问题
* @author hanko
* @version 1.0
* @date 2020/9/14 18:50
*/
public class SluggardSingleton {
//特点一 静态私有变量,先不初始化
private static SluggardSingleton instance;
//特点二 构造函数私有
private SluggardSingleton(){
}
//特点三 null判断,没有实例化就new
public static synchronized SluggardSingleton getInstance(){
if(instance == null){
instance = new SluggardSingleton();
}
return instance;
}
public void doSomething(){
//具体需要实现的功能
}
}
复制代码- 双重校验
package com.hanko.designpattern.singleton;
/**
* 双重校验
*对懒汉式单例模式做了线程安全处理增加锁机制
* volatile变量级
* synchronized 类级
* @author hanko
* @version 1.0
* @date 2020/9/15 9:53
*/
public class DoubleCheckSingleton {
//特点一 静态私有变量,增加volatile变量级锁
private static volatile DoubleCheckSingleton instance;
//特点二 构造函数私有
private DoubleCheckSingleton(){
}
//特点三 双重null判断 synchronized类级锁
public static DoubleCheckSingleton getInstance(){
if (instance == null){
synchronized(DoubleCheckSingleton.class){
if (instance == null){
instance = new DoubleCheckSingleton();
}
}
}
return instance;
}
}
复制代码- 静态内部类
package com.hanko.designpattern.singleton;
/**
* 内部静态类方式
*优点:静态内部类不会在InnerStaticSingleton类加载时加载,
* 而在调用getInstance()方法时才加载
*缺点:存在反射攻击或者反序列化攻击
* @author hanko
* @version 1.0
* @date 2020/9/15 10:03
*/
public class InnerStaticSingleton {
//特点一:构造函数私有
private InnerStaticSingleton(){
}
//特点二:静态内部类
private static class InnerSingleton{
private static InnerSingleton instance = new InnerSingleton();
}
public InnerSingleton getInstance(){
return InnerSingleton.instance;
}
public void doSomething(){
//do Something
}
}
复制代码- 枚举(推荐方式)
package com.hanko.designpattern.singleton;
/**
* 枚举实现单例简单安全
*
* @author hanko
* @version 1.0
* @date 2020/9/14 19:01
*/
public enum EnumSingleton {
INS;
private Singleton singleton;
EnumSingleton() {
singleton = new Singleton();
}
public void doSomething(){
singleton...
//具体需要实现的功能
}
}
EnumSingleton.INS.doSomething();
复制代码3.3.6 工厂模式
(简单工厂、抽象工厂):解耦代码。
简单工厂:用来生产同一等级结构中的任意产品,对于增加新的产品,无能为力。
工厂方法:用来生产同一等级结构中的固定产品,支持增加任意产品。
抽象工厂:用来生产不同产品族的全部产品,对于增加新的产品,无能为力;支持增加产品族。
参考文章:zhuanlan.zhihu.com/p/248497545
3.3.7 观察者模式
定义了对象之间的一对多的依赖,这样一来,当一个对象改变时,它的所有的依赖者都会收到通知并自动更新。
3.3.8 外观模式
提供一个统一的接口,用来访问子系统中的一群接口,外观定义了一个高层的接口,让子系统更容易使用。
3.3.9 状态模式
允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。与策略模式类似,策略模式侧重点在一个事的不同实现方式抽离出来,而状态模式是一个事的不同状态抽离出来(开始、进行中、结束),每次状态完成自己的业务逻辑。
3.4 总结:
- 适配器模式(原功能不变,增加新功能)、装饰器模式(装饰原功能)、代理模式(控制原功能)
- 策略模式侧重点在一个事的不同实现方式抽离出来,而状态模式是一个事的不同状态抽离出来(开始、进行中、结束),每次状态完成自己的业务逻辑。
4 Java新特性
Java8
- Lambda表达式
- 函数式接口
- Stream
Java17
- Sealed Classes(密封类)
sealed class 密封类允许描述哪个类或接口可以扩展或实现这个类或接口。简而言之,我们可以限制谁可以使用这个类或接口。假设我们有一个学生抽象类,如果我们将其设为一个密封类,并且只允许ScienceStudent和CommerceSudent扩展该类,那么只有这些类才能扩展该Student,而其他类如果试图扩展该类,则会出错。
public abstract sealed class Student permits ScienceStudent , CommerceStudent { ... }
这提供了一种比访问修饰符更具声明性的方法来限制超类的使用。
Java19
- 虚拟线程
类似 Go 语言的协程。它是轻量级线程,可显著减少编写、维护和观察高吞吐量并发应用程序的工作量。其目标包括以简单的请求线程样式编写的服务器应用程序,使得能够接近最佳的硬件利用率,现有代码能够以最小的更改采用虚拟线程,并启用故障排除、调试和使用现有 JDK 工具分析虚拟线程。
第二章、存储篇
1 缓存基础
1.1 缓存类型
- 本地缓存
- 分布式缓存
- 多级缓存(本地+分布式)
1.2 淘汰策略
- FIFO淘汰最早数据
- LRU最近最少使用(存的最久、用的最少)
使用LinkedHashMap实现LRU
1)LinkedHashMap被get过的元素会自动放在尾项
2)LinkedHashMap链表被删除不用补位
- LFU
1.3 缓存实现
- LRUCache(通过LinkedHashMap本地实现)
- Memcache
- Redis
- MongoDB
1.4 缓存穿透、击穿、雪崩
1、缓存穿透 (缓存、DB均无,穿透)
- 简述
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
- 解决方案
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
布隆过滤器缺点就是只能存不能直接删除,最近出来一个布谷鸟过滤器。
2、缓存击穿(缓存无、DB有,击穿)
- 简述
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 解决方案
1)使用mutex key(互斥锁)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候,不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key(对缓存的逻辑加锁),当操作返回成功时,再进行load db的操作并回设缓存。
2) "提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。伪代码如下:
3) "永远不过期":
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
3、缓存雪崩(一批过期的key)
- 简述
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
- 解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。一个简单方案就是将缓存失效时间分散开(过期时间错开) ,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
2 Redis
1、数据类型
String Hash List Set ZSet
- 大多数我们会把数据序列化成json也就是string存储
- zset可以实现排行榜
2、分布式锁
1)Redis实现分布式锁面临的主要问题
就是能否保证分布式锁的原子性,主要体现在以下两点:
- 未释放
- 误释放
2)详细说明
a、未释放
- 过期未释放
b、误释放
- 业务未完成,由于过时被释放
- 被其它线程释放
3)实现方案
- 手动实现(setnx-expire) 如果不存在写入,如果存在就不写
- 手动实现升级版(set ex px nx)
- Redisson
- Springboot LockRegistry(推荐)
p.s. 手动实现方案需程序解决以上两问题,使用第三方的客户端或组件一般自带解决以上问题
3、常见问题
1)单线程的redis为什么快(目前redis已出多线程版本)
- 内存读写
- 单线程无线程切换
- 采用了非阻塞I/O多路复用机制
2)持久化
- AOF原理
AOF记录的是操作命令,并非数据。恢复时需要执行全是命令
- RDB原理
rdb记录的是数据。恢复时只需恢复对应的数据。
3 MySQL
3.1 MySql调优
先引用一张图片

目录图

1、SQL语句优化
- 开启慢查询功能
vim /etc/my.cnf
[mysqld]
slow-query-log = on # 开启慢查询功能
slow_query_log_file = /data/slow-query.log # 慢查询日志存放路径与名称
long_query_time = 5 # 查询时间超过5s的查询语句
log-queries-not-using-indexes = on # 列出没有使用索引的查询语句
复制代码1)查看所有日志状态: show variables like '%quer%';
2)查看慢查询状态:show variables like 'show%'
- 分析SQL语句
MySql内部函数explain(查询sql的执行计划),explain返回各列的含义
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。
从最好到最差的连接类型为const、eq_reg、ref、range、index 和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。
key:实际使用的索引。如果为NULL,则没有使用索引。
keyjen:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows: MYSQL认为必须检查的用来返回请求数据的行数
复制代码- 子查询优化
子查询尽量不用或改成join
- group by 优化
group by 尽量使用索引字段
- limit 优化
给查询语句增加limit
2、索引优化
- 重复索引
- 冗余索引
- 检查重复及冗余索引的工具
- 删除不用的索引
3、数据库结构优化
- 选择合适的数据类型
- 表的范式化
- 表的反范式化的使用
- 表的垂直拆分(列拆分)
- 表的水行拆分(行拆分)
4、配置优化
- 操作系统配置
1)缓存池大小
2)打开文件限制
- MySQL配置
1)innodb缓冲池内存占用大小
2)innodb_buffer_pool_instances 缓冲池个数
3)innodb_log_buffer_size 缓冲的大小
4)innodb IO配置
5、服务器硬件优化
- CPU 多核
- 硬盘 raid0 raid1 raid5增加硬盘IO速度
3.2 数据库调优步骤
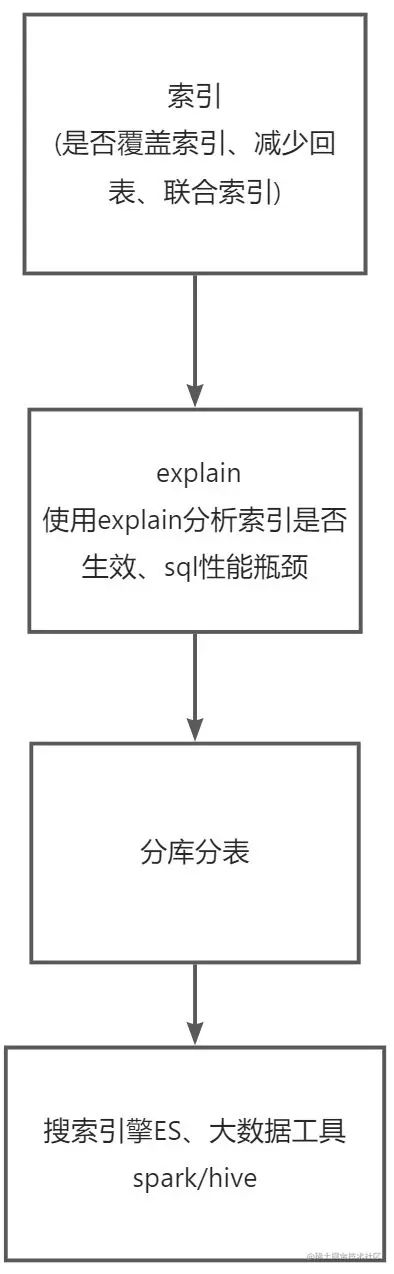
3.3 MySql相关问题
1、InnoDB myisam区别
- innodb支持事务、myisam不支持事务
- innodb不支持全文索引、myisam支持全文索引,查询性能较快
- innodb行级锁、myisam表级锁
2、怎么处理MySQL的慢查询?
开启慢查询->explain分析SQL->横纵向分表
3、Myisam和Innodb的区别?
| 全文索引 | 事务 | 锁 | |
|---|---|---|---|
| Innodb | 无 | 有 | 行 |
| Myisam | 有 | 无 | 表 |
4、Mysql中索引类型有哪些?
-
普通索引:允许被索引的数据列包含重复的值
-
唯一索引:可以保证数据记录的唯一性
-
主键索引:是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识一条记录,使用关键字primary key来创建
-
全文索引:通过建立倒排索引,可以极大的提升检索效率,解决判断字段是否包含的问题,是目前搜索引擎使用的一种关键技术索引可以极大地提高数据的查询速度
5、为什么用自增主键
数据库使用的是B+Tree,非自增会出现要插入到节点与节点中间,会发生节点分裂。
6、为什么用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。
第三章、性能篇
1 Java项目性能调优
1.1 jvm自带命令
- jstat -gcutil pid jstat统计jvm运行情况信息(内存 gc)
- jstack -l pid 线程堆栈情况
- jmap -dump:format=b,file=heap.hprof pid jvm实例及占用内存情况
- jmap -histo pid 堆内存使用(占用)详情
1.2 Arthas
- jvm调优
top查内存->thread查cpu/死锁->dashboard内存
heapdump 查dump****
- java程序调试
trace跟踪代码->watch查函数参数与返回值
1.2.1 常用命令
- cpu占用过高 thread
- 死锁 thread -b
- 内存泄漏 dashboard
- 方法耗时及跟踪 trace
- 看源代码 jad
- 查看函数的参数/返回值/异常信息 watch com.Welfare batchQuerySku "{params}"
- 发现异常并查看异常 tt -t com.UserServiceImpl check //记录方法调用信息
tt -i 1001 //上面指令发现异常后,查看异常
tt -i 1001 -p //重新调用,重现异常
- 查看、更新类成员变量值
ognl '@com.Arthas@hashSet' //查看
ognl '@[email protected]("test")' //更新
1.2.2 项目实战
- 针对web项目,可以跟踪servlet类
trace org.springframework.web.servlet.DispatcherServlet *
复制代码- 跟踪后通过watch查看出入参(发现执行的controller类)
watch org.springframework.web.method.support.InvocableHandlerMethod doInvoke "{params,returnObj}"
复制代码- 记录方法调用信息
tt -t com.wdbyte.arthas.service.UserServiceImpl mysql
复制代码![]()
- 通过tt -t 查看到index,然后通过index重复调用
tt -i 1001 -p
复制代码- 最后通过tt -i 与 trace重复配合,定位出性能消耗
1.3 Xrebel
直接在Idea plugins里搜索xrebel

安装后重启,在Idea上可以看到多出一些工具按钮

点击用xreble启动项目,控制台日志显示xrebel地址,打开后试用或破解

然后随便访问项目的URL,发现

把每个被调用或执行的类的方法耗时都显示出来,同时不同颜色标明耗时情况。
1.4 线程调优实战
CPU占用过高排查流程 (进程->线程列表->线程堆栈)

相关命令:
#1、查询占用CPU情况
top shift+p(cpu排序) shift+m(内存排序)
#2、通过进程pid,查询对应的线程列表
top -Hp pid
#3、线程id转为十六进制
printf '%x\n' id
#4、jstack查出线程堆栈,现用第3步搜索对应线程进行分析
jstack -l pid
#5.1、jstack具体分析-业务线程(堆栈可定位到类的代码行)
#线程死锁
#线程阻塞
#线程死循环
#5.2、jstack具体分析-GC线程
#jstat -gcutil pid 1000查询是否是频繁gc占用内存
复制代码内存占用过高排查流程 (进行->jvm内存)

相关命令:
#1、查询占用内存情况
top shift+p(cpu排序) shift+m(内存排序)
#2、查询GC情况
jstat -gcutil pid 1000 #分析年轻代、老年代占用内存情况
#3、jmap查询堆内存使用情况
jmap -histo pid #实例数与内存占用
jmap -dump #与histo类似
jmap -heap #jvm内存占用详情
复制代码源代码地址:
gitee.com/hankzhousan…
2 性能指标

第四章、安全篇
1 接口安全
1 微信公众号接口认证方案
1.1 认证流程

安全API接口认证方案 | ProcessOn免费在线作图,在线流程图,在线思维导图 |
1)官方配置Token验证
- Token不在网络中传递
2)开发一个Token验证接口
- Token及其它参数拼接并字典排序再做sha摘要计算
- 微信定期调用此接口来验证身份正确性
- 通过摘要验证判断请求来源微信(Token配置在微信平台,固而判断来源)
3)通过appid secret获取access_token
4)所有业务URL直接拼接access_token
5)针对报文安全可以设置加密模式,使用在平台配置的AESkey进行加密
1.2 参考代码
private function checkSignature()
{
$signature = $_GET["signature"];
$timestamp = $_GET["timestamp"];
$nonce = $_GET["nonce"];
$token = TOKEN;
$tmpArr = array($token, $timestamp, $nonce);
sort($tmpArr, SORT_STRING);
$tmpStr = implode( $tmpArr );
$tmpStr = sha1( $tmpStr );
if( $tmpStr == $signature ){
return true;
}else{
return false;
}
}
复制代码微信公众平台开发概述 | 微信开放文档
1.3 小结
安全核心在于:
1、定时的Token验证
2、全部接口在https基础下请求
3、access_token具有时效性
4、AES增加安全系数
2 微信支付接口认证方案
2.1 认证流程
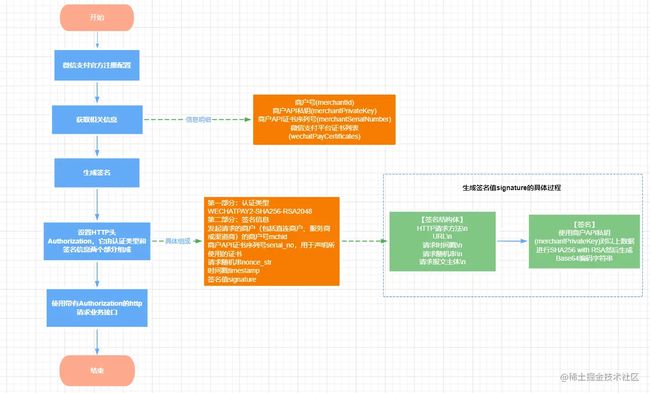
微信公众平台开发概述 | 微信开放文档
1)在微信官方配置并获取
a、appid mchid(商户id)
b、api key(API v3密钥)即AES-256-GCM 对称加密密钥。
c、商户API证书
d、微信支付平台证书即平台的公钥证书用于加密业务接口的敏感报文。
2)生成签名值
a、签名结构体
HTTP请求方法\n
URL\n
请求时间戳\n
请求随机串\n
请求报文主体\n
复制代码b、使用商户API私钥(merchantPrivateKey)对以上数据进行SHA256 with RSA然后生成
Base64编码字符串。
3)生成HTTP头中的Authorization数据,Authorization由认证类型和签名信息两个部分组成
a、认证类型,目前为WECHATPAY2-SHA256-RSA2048
b、签名信息
-
- 发起请求的商户(包括直连商户、服务商或渠道商)的商户号mchid
- 商户API证书序列号serial_no,用于声明所使用的证书
- 请求随机串nonce_str
- 时间戳timestamp
- 签名值signature
4)使用带Authorization的HTTP请求,调用业务接口
2.2 参考代码
import okhttp3.HttpUrl;
import java.security.Signature;
import java.util.Base64;
String schema = "WECHATPAY2-SHA256-RSA2048";
HttpUrl httpurl = HttpUrl.parse(url);
String getToken(String method, HttpUrl url, String body) {
String nonceStr = "your nonce string";
long timestamp = System.currentTimeMillis() / 1000;
String message = buildMessage(method, url, timestamp, nonceStr, body);
String signature = sign(message.getBytes("utf-8"));
return "mchid="" + yourMerchantId + "","
+ "nonce_str="" + nonceStr + "","
+ "timestamp="" + timestamp + "","
+ "serial_no="" + yourCertificateSerialNo + "","
+ "signature="" + signature + """;
}
String sign(byte[] message) {
Signature sign = Signature.getInstance("SHA256withRSA");
sign.initSign(yourPrivateKey);
sign.update(message);
return Base64.getEncoder().encodeToString(sign.sign());
}
String buildMessage(String method, HttpUrl url, long timestamp, String nonceStr, String body) {
String canonicalUrl = url.encodedPath();
if (url.encodedQuery() != null) {
canonicalUrl += "?" + url.encodedQuery();
}
return method + "\n"
+ canonicalUrl + "\n"
+ timestamp + "\n"
+ nonceStr + "\n"
+ body + "\n";
}
复制代码wechatpay-api.gitbook.io/wechatpay-a…
3 Oauth2认证方案
略
4 HTTPS双向身份认证过程
1、客户端发送clienthello+随机数A
2、服务器发送serverhello+随机数B
3、服务器发送服务器证书B
4、客户端验证服务器证书B
5、客户端利用AB生成新的随机数C,同时使用服务器公钥加密
6、服务器收到密文后,使用服务器私钥解密取得随机数C即对称加密的密钥
zhuanlan.zhihu.com/p/579964062
2 认证授权
SpringSecurity+Oauth2
3 数据脱敏
- select concat(left(phone,3),'********')
- mybatis插件方式:mybatis.net.cn/configurati…
第五章、架构篇
1 微服务架构
- 第一代微服务架构
springcloud dubbo - 第二代微服务架构
service mesh
未来的微服务架构与技术栈

1.1 SpringCloud
1.1.1 SpringCloud架构
网关 zuul/gateway
服务注册发现 eureka/nacos/consul
配置中心 configserver/nacos/apollo
熔断限流降级 hystrix/sentinel
监控 springbootadmin
链路器 sleuth+zipkin
1.1.2 SpringBoot自动装配
www.yuque.com/hanko-yzlxl…
1.2 Dubbo
- 支持哪些协议
http dubbo rmi hessian[ˈhesiən] webservice
- dubbo的几种角色


p.s.Consumer Provider定时向Monitor发送信息。
- 注册中心
zookeeper
- dubbo有哪几种配置方式
xml 注解 properties API
- 序列化
hessian dubbo fastjson java自带序列化
1.3 单体服务、SOA、微服务区别
正式版本:
- 单体服务: 传统的、复杂的、高度耦合的单体系统
- SOA: 面向服务架构,把原本单体业务服务化
- 微服务: 把原本庞大、复杂的系统进行拆分,强调的是业务系统需要彻底的组件化和服务化
大白话版本:
- 单体服务: 比如一个企业刚创业也就2~3个人,大家在一个办公区座着办公。
- SOA: 当企业发展到一定时期,人员多了大概有100来人了,这时大家再座在一个办公区座着办公就比较乱了,特别是销售部门、财务部门、人事部门很多见不了光得关在小房间去,这样就出现一个个隔离的办公室,把职能不同的岗位分离出来。
- 微服务: 当企业进一步发展,人员扩充到上千人,这时就得开分公司了,并且分公司可能分布在全国各地;
第六章、分布式篇
1 概念
从系统的部署纬度上讲,把应用分布到不同的节点通过网络连接。与集中式对比。
2 分布式事务
2.1 基于XA协议
2.1.1 两阶段提交协议(2PC)
两阶段提交协议用于保证分布式事务的原子性,即所有的参与节点或者全部都执行或者全部不执行,其执行过程主要分为两个阶段:
第一阶段,准备阶段;第二阶段,提交阶段。

1)准备阶段
协调者为每个参与者都发送prepare消息,每个参与者进行表决,返回同意或取消。预执行本地事务,资源阻塞,但不提交事务。
2)提交阶段
协调者基于每个参与者准备阶段的表决,当且仅当所有参与者同意提交,协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。
2.1.2 三阶段提交协议(3PC)
三阶段提交协议在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段拆分成了两步:询问,然后再锁资源,最后真正提交。

(1)三个阶段的执行
1.CanCommit阶段
协调者向参与者发送CanCommit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
2.PreCommit阶段
协调者根据参与者的反应情况来决定是否可以继续事务的PreCommit操作。
3.DoCommit阶段
协调者基于每个参与者PreCommit阶段的反馈结果,决定真正提交事务,还是中断事务。
2.1.3 2PC与3PC对比
| 2PC | 3PC | |
|---|---|---|
| 超时 | 协调者可设置超时 | 协调者、参与者均可设置超时 |
| 阻塞 | 进入询问后阻塞所有节点 | 第一阶段缓冲,通过后第二阶段才阻塞 |
| 一致性 | 节点异常会发生不一致性 | 节点异常会发生不一致性 |
2.2 TCC编程模式(补偿事务)
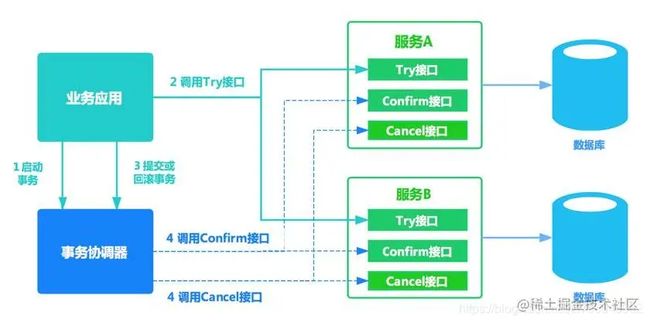
核心思想是:
针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。分为三个阶段:
-
Try 阶段:主要是对业务系统做检测(一致性)及资源预留(准隔离性)
-
Confirm 阶段:主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。(Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。)
-
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。(Cancel 操作满足幂等性)
相关问题:
如何发现某个服务的Cancel或者Confirm一直没成功,会不停的重试调用他的Cancel或者Confirm逻辑,务必要他成功!
2.3 MQ+最终一致性
- Rocketmq的事务消息(半消息)
- Rocketmq监听器定期扫描半消息并执行本地事务,当半消息超时通过checkLocalTransaction反查发送者
2.4 中间件
- seata(事务模式:TCC AT(零侵入))
seata处理事务的原理是二阶段提交,二阶段强依赖数据库XA,seata在基础上做了改造,封装了TM的database。

- LCN(事务模式:TCC LCN)
3 搜索引擎
3.1 倒排索引
- 何为倒排索引?
一般索引: 数据由数据索引、数据内容组成,正常情况是通过数据索引来定位内容就像sql查询一样。
倒排索引: 倒排索引是先通过分散的内容片段定位到相视度高的内容,再由内容定位到这条记录,所以称为倒排索引,带有倒排索引的文件称为倒排文件。通俗的讲倒排索引就好比书的目录,通过目录咱们可以准确的找到相应的数据。下面对lucene倒排索引的结构与算法进行介绍。
- 使用场景
倒排索引服务于es查询操作,对数据的聚合,排序则需要使用正排索引,下面我们介绍正排索引。
3.2 ES
Elasticsearch
3.3 热点分析(词频统计)
方案一、基于ElasticSearch方式
方案二、基于Spark方式
方案三、基于Python方式
复制代码方案一、基于ElasticSearch方式
详见文章,里面列举了各种ElasticSearch的实现样例。主要是通过ES的fielddata做聚合或调取termvector两种方式实现,当然调用方式比较多http requset、highclient、springboot data repository、elasticsearch resttemplate等调用方式
zhuanlan.zhihu.com/p/315888125
方案二、基于Spark方式
Spark是基于内存的分布式计算组件,Spark官方提供了JavaWordCount的demo,详见以下文章
zhuanlan.zhihu.com/p/329967589
方案三、基于Python方式
如果你只能实现简单的数据词频统计,python是最的方式,几行代码就可以搞定
text = "http requset highclient springboot"
data = text.lower().split()
words = {}
for word in data:
if word not in words:
words[word] = 1
else:
words[word] = words[word] + 1
result = sorted(words.items(), reverse=True)
print(result)
复制代码参考文章 :zhuanlan.zhihu.com/p/333358727
4 消息队列
4.1 RabbitMQ
消息队列如何保证不丢失,考虑的几个方面
- 生产者
- 消费者
- 集群节点
- 落盘
4.1.1 消息模式
- 点对点模式 Direct 绑定一个queue
- 扇形模式 Fanout 绑定多个queue
- 主题模式 Topic 绑定多个queue,同时增加topic 通配符 * #
4.1.2 有序性
单个queue有序
4.1.3 ACK
- basicAck 手动确认
- basicReject 重新放回队列
4.1.4 事务
- TransactionMQProducer
4.2 RocketMQ
4.2.1 消息模式
- 集群消费模式(默认模式) 同一group+topic 多个消费者,通过负载均衡策略消费
- 广播模式 topic通配符
RocketMq在topic基础上可以增加tag进一步筛选
4.2.2 有序性
同一个Queue中有序,原理就是使用MessageQueueSelector(两种实现随机与哈希)
-
生产者
rocketMQTemplate.syncSendOrderly
设置相同的hashKey使消息发送至同一个queue中,保证消息有序
-
消费者
consumeMode设置成ConsumeMode.ORDERLY
@Component
@RocketMQMessageListener(topic = "topic-lcf1", selectorExpression = "tag1",
consumerGroup = "luchunfeng1",consumeMode = ConsumeMode.ORDERLY)
public class Consumer implements RocketMQListener {
private static final Logger logger = LoggerFactory.getLogger(Consumer.class);
@Override
public void onMessage(String s) {
logger.info(s);
}
}
复制代码 4.2.3 ACK
//CONSUME_SUCCESS 消费成功
//RECONSUME_LATER 消费失败,需要稍后重新消费
ConsumeConcurrentlyStatus.RECONSUME_LATER
4.2.4 事务
- RabbitTransactionManager
4.2.5 ACL
ACL是access control list的简称,俗称访问控制列表。访问控制,基本上会涉及到用户、资源、权限、角色等
4.3 Kafka
4.3.1 消息模式
- 点对点模式
- 发布/订阅模式
4.3.2 有序性
单个partition有序,生产者发送消息指定partition
4.3.3 ACK
生产者到kafka服务器
- ack=1,producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。
- ack=0,producer发送一次就不再发送了,不管是否发送成功。
- ack=-1,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
消费者手动提交
consumer.commitSync()
4.3.4 事务
- 用户只需要在 Producer 的配置中配置
transactional.id,通过initTransactions()初始化事务状态信息,再通过beginTransaction()标识一个事务的开始,然后通过commitTransaction()或abortTransaction()对事务进行 commit 或 abort
4.4 常见问题
4.4.1 kafka通讯过程
broker服务器节点
producer->broker->topic->partition->consumer
4.4.2 消息丢失
从三个方向考虑
- 生产阶段--生产者发送 (手动ACK)
- 存储阶段--中间件存储
-
- broker之间同步复制
- broker本身同步刷盘
- 消费阶段--消费者接收(手动ACK)
4.4.3 消息积压
分析原因,正常情况下应该是不会积压,积压要不就是发送端突然变大了,要不就是消费端出问题了
- 监控分析发送端情况
- 监控分析消费端情况
-
- 如果正常情况,消费者水平扩容
- 不正常情况,分析性能问题
4.4.4 消息重复消费
消费幂等,方法有以下几种
- 消费主健唯一性限制
- 记录消息ID的消费状态
5 分布式日志
2、分布式日志
1、filebeat logstash区别
- filebeat轻量级日志收集
- logstash日志过滤分析
2、ELK增加kafka
缓冲(filebeat->kafka->logstash->elasticsearch->kibana)
第七章、大数据篇

数据源(结构化数据、非结构化)
- 日志
- 流量
- cookie
- 关系型数据库
- 爬虫
- 埋点
采集层
- flume
- datahub
- logstash
- sqoop
- spark
传输层
- kafka
分析计算层
- spark
- flink
- hive
- kylin
- presto
存储层
- redis
- mysql
- hbase
- es
- hadoop
展示层
- kibana
- clickhouse
第八章、运维篇
1 部署、集成
- Jekins
- Sonarquber
- Docker
- Podman
- K8s
2 灾备
第九章、热点问题篇
1 SpringCloud vs Dubbo
- 协议方面:基于http的rest api vs 基于tcp的rpc
- 生态方面:springcloud完整生态 vs 并不完整
- 2014微服务概念慢慢火起来,2012年dubbo已经被国内一些企业使用,但在后面的几年dubbo没落,在2017年重启dubbo负责人为刘军,刘军说“dubbo与springcloud不是竞争关系,dubbo会融入springcloud生态”,springcloudalibaba进入spring孵化,现在也已经出现了dubbo springcloud项目(对外使用rest api对内使用rpc)。
2 微服务 vs 中台
- 微服务:前端、后端均为开发语言且主要是后端分成微服务。
- 中台:前台、中台、后台均指的是系统。
- 中台分为:业务中台、组织中台、数据中台、技术中台 。
- springcloud为中台服务的一种实现技术 。
3 微服务技术
- 网关:zuul gateway
- 注册中心:eureka nacos consul
- 配置中心:configserver nacos apollo
- 监控中心:springbootadmin
- 链路跟踪:sleuth+zipken
- 熔断降级:Hystrix sentinel
- 事务处理:seata
4 架构方面
1、传统架构改造成微服务架构
- 微服务拆分时,数据库问题
问题说明:微服务拆分后,对应的数据库也会进行拆分。也就是原本很简单功能一个查询就解决,拆分后就得跨多个微服务查询。如果其中一张表数据较少可以代码循环的方式解决,如果每个微服务的数据都比较多就比较麻烦。
方案一:使用视图,通过视图把两个库的中表进行强关联。当然这样也就违避微服务的解耦
方案二:临时表或缓存,通过临时表或缓存构建临时关联数据,使用完就清理
方案三:数据冗余,牺牲空间换时间。类似索引,牺牲索引空间换查询速度。
建议使用方案三(尽量不要使用共享数据库),数据同步的问题可以借助MQ来实现
- 微服务拆分粒度
微服务粒度问题,多次讨论拆分架构。拆分是一个迭代的过程,别试着一步到位拆成很细,一开始千万别拆太细。一般微服务划分越细,那么模块之前的集成就越复杂
5 技术点方面
- PDF签名从RAS变为SM2
技术问题:itextpdf本身不支持SM2算法及数据结构
解决方案:通过分析源代码,通过继承或实现的方式改造itext
- PDF插件开发
技术问题:adobereader不支持自定义签名验证
解决方案:adober官方文档分析
- springboot1.x相关的坑
项目中2018年使用springboot1.5.3版本,SpringBoot上传使用的是MultiPartFile,原理是上传文件先存放在tomcat容器层临时目录,再传给springboot的servlet层面,再给到MultiPartFile对象。tomcat临时目录被Linux删除、无法上传文件。(1.5.20就已经修复此bug,当临时目录不存在什么自动生成)。
- mysql开启慢查询影响性能
mysql cpu 内存都飚的比较高,后面发现是mysql开启了慢查询
6 项目管理方面
- 编码不统一问题
idea阿里插件(p3c)+sonarqube
- 各微服务间的开发各扫自家门前雪
微服务后大家只管自己的服务,当需要增加或调整对方业务时,整个业务协调方面困难,研发组长变业务专家(共性技术下沉,转向关注业务)
7 项目职责
项目经理(兼架构师)
- 明确项目目标
- 制定项目计划及人员安排
- 设计项目架构及关键技术攻关
- 跟踪项目质量、进度
8 代码审查
1.为什么要代码审查
反面:
- 业务需求大,工作时间紧张,没必要
- 项目小,协作的人少,没必要
正面:
- 提升代码水平
- 降低维护成本
- 降低生产风险
- 审查并不是完全找问题,还是在发观优秀代码的方式
2.如何做代码审查
1. 管理方面
- 案例风险分析
- 基于讨论
- 计入工作量
- 选择试点
2. 技术方面
- 自动检查,利用第三方代码检查工具e.g. sonarqube
- 人工审核+代码走查(分析代码是否有业务逻辑上的问题。e.g. and写成or)
- 提高提交的原子性、定义提交模板
"不做code review基本上就是背着定时炸弹前进:什么时候炸了都不知道"
第十章、项目实战
1 排行榜
- 方案一:mysql order by
互联网用户数据过大,排行榜性能较差
- 方案二:redis
redis zset 数据结构为 id、score、member。下面是具体实现的步骤
1)插入数据
zadd game 90 tom
zadd game 92 sam
zadd game 95 hanko
复制代码2)获取范围内的排名
zrange game 0 -1 withscores //开始到集合结束的从小到大列表,-1代表结束
zrevrange game 0 -1 withscores //开始到集合结束的从大到小列表
3)获取某用户的排名
zrank game hanko
zrevrank game hanko
10.2 秒杀系统
10.2.1 秒杀系统特点
- 秒杀时大量用户会在同一时间同时进行抢购,网站瞬时访问流量激增。
- 秒杀一般是访问请求数量远远大于库存数量,只有少部分用户能够秒杀成功。
- 秒杀要附防止超卖(库存锁定及解锁)。
10.2.2 秒杀系统设计理念
1、策略
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。
削峰: 对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件等技术。
p.s. 削峰主要是把并行请求变为串行请求
2、具体方案
1)削峰
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
2)限流
网关限流
3)缓存
秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
10.2.3 具体方案
-
前端

- 后台

后台技术选型

10.3 抢红包

第十一章、管理篇
1 团队管理
目标(目标清晰)、计划( 凡事预则立,不预则废 )、职责(职责明确)、制度(赏罚分明)
1.1 木桶法则
注重团队中的薄弱环节
一只沿口不齐的木桶,它盛水的多少,不在于木桶上那块最长的木板,而在于木桶上最短的那块木板。要使木桶多盛水(提高水桶的整体效应),需要的不是去增加最长的那块木板长度,而是下工夫依次补齐木桶上最短的那些木板,这就是管理上有名的“木桶”法则。企业管理也是如此,要提高企业的效益,就必须狠抓薄弱环节,否则单位的整体工作就会受到影响。人们常说“取长补短”,即取长的目的是为了补短,只取长而不补短,就很难提高工作的整体效应。项目管理者联盟
1.2 羊群效应
提升自己的判断力,不盲目跟风
羊群效应是指人们经常会收到多数人的影响,而跟从大众的思想或行为,也被称为“从众效应”。羊群是一种很散乱的组织,平时在一起也是盲目地左冲右撞,一旦有一头羊动起来,其他的养也会不假思索地一哄而上,全然不顾前面可能有狼或者不远处有更好的草。因此,就是比喻人都有一种从众心理,从众心理很容易导致盲从,而盲从往往会使人陷入骗局或遭到失败。
1.3 “热炉”法则
规章制度面前人人平等
“ 热炉”法则不仅形象地阐述了规章制度的权威性,而且活灵活现地描述了惩处所需掌握的原则:(1)热炉火红,不用手去摸也知道炉子是热的,是会灼伤人的,这就是惩处的警告性原则。领导者要经常对下属进行规章制度教育,警告或劝戒不要触犯规章制度,否则会受到惩处。(2)每当碰到热炉,肯定会被火灼伤,这就是规章制度的权威性。也就是说只要触犯单位的规章制度,就一定会受到惩处。(3)当你碰到热炉时,立即就被灼伤,这就是惩处的即时性原则。惩处必须在错误行为发生后立即进行,决不拖泥带水,决不能有时间差,以达到及时改正错误行为的目的。(4)不管是谁碰到热炉,都会被灼伤,这就是规章制度的公平性原则。
1.4“金鱼缸”法则
增加管理的透明度
金鱼缸是玻璃做的,透明度很高,不论从哪个角度观察,里面的情况都一清二楚,这就是管理上的“金鱼缸”法则。“金鱼缸”法则运用到管理中,就是要求领导者必须增加规章制度和各项工作的透明度。各项规章制度和工作有了透明度,领导者的行为就会置于员工的监督之下,就会有效地防止领导者滥用权力,从而强化领导者的自我约束机制。同时,员工在履行监督义务的同时,自身的主人翁意识和责任感得到极大的提升,而敬业、爱岗和创新的精神也必将得到升华。
1.5 “南风”法则
真诚温暖员工
也称“温暖”法则,源于法国作家拉封丹写过的一则寓言:北风和南风比威力,看谁能把行人身上的大衣脱掉。北风首先吹得人寒冷刺骨,结果行人为了抵御北风的侵袭,便把大衣裹得紧紧的。南风则徐徐吹动,顿时风和日丽,行人觉得温暖如春,随之开始解开纽扣,继而脱掉大衣,最终南风获得了胜利。这则寓言形象地说明一个道理:温暖胜于严寒、柔性胜于刚性。领导者在管理中运用“南风”法则,就是要尊重和关心员工,以员工为本,多点“人情味”,少点官架子,尽力解决员工日常生活中的实际困难,使员工真正感觉到领导者给予的温暖,从而激发他们工作的积极性。
1.6“刺猬”法则
保持适当的距离更有利于管理
“ 刺猬”法则讲的是:两只困倦的刺猬,由于寒冷而拥在一起。可因为各自身上都长着刺,刺得对方怎么也睡不舒服。于是它们离开了一段距离,但又冷得受不了,于是凑到一起。几经折腾,两只刺猬终于找到了一个合适的距离,既能互相获得对方的温暖又不致于被扎。“刺猬”法则就是管理和人际交往中的“心理距离效应”。心理学研究认为:领导者要搞好工作,就应该与员工保持亲密关系,这样做可以获得他们的尊重。与员工保持一定的心理距离,不仅可以避免员工之间的嫉妒和紧张,而且可以减少他们的恭维、奉承、行贿等行为,防止与员工称兄道弟、吃喝不分,并在工作中丧失原则。事实上,雾里看花,水中望月,给人的是“距离美”的感觉,管理上也是如此。一个原本很受员工敬佩的领导者,往往由于与员工“亲密无间”,就会使自己的缺点显露无遗,结果在不知不觉中丧失了严肃性,不利于对其更进一步的管理。另外,“刺猬”法则还启示我们,彼此间的亲密协作是必不可少的,员工之间、管理者与员工之间、管理者之间,尽管每个人都有其特点和个性,但各自为战在工作中却是不可取的,“独木难成林”、众人划桨开大船就是这个道理。线务局的工作千头万绪,各位局领导、中层干部、管理人员,各区域局、各部室都要各司其职、各负其责、立足本岗、发挥作用,同时也要注意分工不分家、补台不包办、到位不越位,切实形成合力、发挥团队作用。
1.7“青蛙原理”
时刻保持危机意识
关于“问题管理”有个著名的“青蛙原理”,说的是如果把一只青蛙扔进沸水中,青蛙肯定会马上跳出来。但是如果把一只青蛙放入冷水中逐渐加温,青蛙则会在不知不觉中丧失跳出去的能力,直至被热水烫死。这个原理是用来形容企业中存在的两种性质的问题,即显性问题和隐性问题。人们对显性问题的反应就如同青蛙对沸水的反应一样,会马上采取相应的措施,及时地将其扼杀在萌芽状态;而隐性问题由于自身的隐匿性,不易被发现,往往是等到发现时,已经对企业酿成了严重的损失。这就启示我们,很多线路障碍都是一些不起眼的小问题日积月累的结果,有客观的,但是也有主观的,跟我们的部分线务员在巡回或随工配合中的麻痹大意有关,听任一些小问题长期自由发展,最终酿成了影响线路通畅的大祸。“冰冻三尺,非一日之寒”,因此我们要时刻关注潜在的问题,而不是等小问题变大了、危机降临了再临时抱佛脚。
1.8 鲶鱼效应
竞争是提高效率的法宝
“ 鲶鱼效应”来自一个古老的传说:一个小渔村的渔民靠到深海捕捉沙丁鱼(一种比较懒的鱼)为生。但由于捕鱼点距离陆地比较远,渔民捕的鱼运回渔村时,往往死掉大半,很难卖出好价钱。只有一个渔翁,他运回陆地的鱼,都是活的,总能卖出好价钱,但是他从来不让人看他的鱼舱。直到他死后,好奇的村民才发现,原来他的鱼舱里总是放着一条鲶鱼。由于鲶鱼是以捕食沙丁鱼为生,所以鲶鱼在鱼舱里会不停地追逐沙丁鱼,结果一些老弱的沙丁鱼被吃掉,但其他的沙丁鱼由于总在不停游动,所以都活着到岸。而其他渔船所捕的沙丁鱼静止不动,结果一大半都会死掉。这个传说告诉我们一个浅显的道理:“生于忧患、死于安乐”,如果一个企业缺少活力与竞争意识,没有生存的压力,就如同“沙丁鱼”一样,在“鱼舱”里混吃混喝,必然会被日益残酷的市场竞争所淘汰。一个员工也是如此,长期安于现状、不思进取,必然会成为时代的弃儿。
领导者要成为“鲶鱼”, 有句俗话叫“兵熊熊一个,将熊熊一窝”。一家公司或一个部门,如果领导缺乏激情,要想手下的人有激情,那是白日做梦。最常见的情况是,领导工作不在状态,员工必然上行下效,人浮于事,缺乏创新和主动性,日复一日,年复一年,必然成了一潭死水。反之则是“强将手下无弱兵”。如果领导者本身是一条充满活力的“鲶鱼”,那么,通过整顿纪律,规范制度,改造流程,合理配置岗位和人、财、物,就能将那些无能的“沙丁鱼”吃掉、赶走,使有能耐的“沙丁鱼”得到正面的激励,从而使整个机构呈现欣欣向荣的景象。因此,作为领导者,如果自己的公司没有激情,首先不要怪员工,而是要去反思自己是不是有激情。只有自己先成为“鲶鱼”,才能影响员工,才能使整个组织的活力都被调动起来,从而使集体的力量更加强大,克敌制胜。
1.9“走动式”管理
这种管理方式属于最典型的柔性管理,目的很明确,就是要求企业的管理层要经常深入到基层和员工群众中去,体察民意、了解实情,与员工打成一片,从而增强领导层的亲和力和企业的凝聚力,激发员工的自豪感、自信心,起到上下一心、团结一致、共同进步的理想效果。“走动式”管理启示我们:一个整天忙忙碌碌、足不出户的领导决不是好领导,而事无巨细、事必躬亲的领导也不是好领导,只有削掉“椅子背儿”,从办公室中解放出来、深入基层与员工群众中去,才能取得事半功倍的效果。
1.10 破窗效应
及时矫正和补救正在发生的问题
一个房子如果窗户破了,没有人去修补,隔不久,其它的窗户也会莫名其妙的被人打破 ; 一面墙,如果出现一些涂鸦没有清洗掉,很快的,墙上就布满了乱七八糟,不堪入目的东西。一个很干净的地方,人会不好意思丢垃圾,但是一旦地上有垃圾出现之后,人就会毫不犹疑的抛,丝毫不觉羞愧 。这真是很奇怪的现象
1.11 马云的管理之道
“目标清晰(目标量化+计划),职责明确,赏罚分明(制度),超越伯乐。”
第十二章、前端篇
第十三章、测试篇
第十四章、其它
1 技术栈
1、微服务:SpringCloud/Dubbo、Gateway、Eureka/Nacos/Consul、Config/Apollo、Hystrix/Sentinel
2、分布式:SLB、LVS、KeepAlived、LCN/Seata、ELK/ES等;
3、缓存:Java本地缓存、Memcached、Redis、MongoDB;
4、消息:RabbitMQ、RocketMQ、Kafka等
5、存储:Minio/Fastdfs、 MySQL(MybatisPlus)、Oracle、DB2、SQL Server
6、测试:Jmeter、Loadrunner、JUnit、Mockjs
7、监控:Arthas、XRebel、Jconsole、Jvisualvm、MAT
8、自动化:Jenkins、Nexus、GIT、Sonaqube、Maven、Gradle;
9、项目管理:TAPD(敏捷)、Redmine、禅道、Jira、Worktile(OKR)等;
10、设计:常用设计模式、UML、PowerDesinger
11、前端:JavaScript、Jquery、Ajax、Nodejs、Vue 等;
12、后台:SpringSecurity/Shiro、Oauth2、okHttp、Swagger/Knife4j
13、大数据:熟悉 Spark、Hive、Hadoop(hdfs、hbase);
14、容器:Docker/Podman;
15、其它:Python、Activiti、区块链技术、对称/非对称加密(RSA、SM2)
2 其它
可用性(SLA)、可靠性()
- 可用性
可用性指系统在给定时间内可以正常工作的概率,通常用SLA(服务等级协议,service level agreement)指标来表示。
这是这段时间的总体的可用性指标。
| 通俗叫法 | 可用性级别 | 年度宕机时间 | 周宕机时间 | 每天宕机时间 |
|---|---|---|---|---|
| 1个9 | 90% | 36.5天 | 16.8小时 | 2.4小时 |
| 2个9 | 99% | 87.6小时 | 1.68小时 | 14分钟 |
| 3个9 | 99.9% | 8.76小时 | 10.1分钟 | 86秒 |
| 4个9 | 99.99% | 52.6分钟 | 1.01分钟 | 8.6秒 |
| 5个9 | 99.999% | 5.26分钟,315.36秒 | 6.05秒 | 0.86秒 |
- 可靠性
可靠性相关的几个指标如下:
MTBF(Mean Time Between Failure)
即平均无故障时间,是指从新的产品在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。
MTBF越长表示可靠性越高,正确工作能力越强 。
MTTR(Mean Time To Repair)
即平均修复时间,是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。
MTTR越短表示易恢复性越好。
MTTF(Mean Time To Failure)
即平均失效时间。系统平均能够正常运行多长时间,才发生一次故障。
系统的可靠性越高,平均无故障时间越长。