大众点评信息流基于文本生成的创意优化实践


数据猿导读
对于用户来说,大众点评最重要的价值是提供丰富多元化的信息,其中信息流的价值日益凸显。本文主要介绍大众点评信息流内容团队利用文本生成技术在创意优化方向上的一些思考和实践。

来源:美团技术团队丨作者:忆纯
数据猿官网 | www.datayuan.cn
今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

引言
信息流是目前大众点评除搜索之外的第二大用户获取信息的入口,以优质内容来辅助用户消费决策并引导发现品质生活。整个大众点评信息流(下文简称点评信息流)围绕个性化推荐去连接用户和信息,把更好的内容推荐给需要的用户。信息流推荐系统涉及内容挖掘、召回、精排、重排、创意等多层机制和排序。
本文主要围绕创意部分的工作展开,并选取其中重要的文本创意优化做介绍,分为三个部分:
第一部分阐述几个重点问题,包括创意优化是什么,为什么做,以及挑战在哪里;
第二部分讲述领域内的应用及技术进展;
第三部分介绍我们创意优化的实践,最后做个总结。
什么是创意优化?
创意是一个宽泛的概念,它作为一种信息载体对受众展现,可以是文本、图像、视频等任何单一或多类间的组合,如新闻的标题就是经典的创意载体。而创意优化,作为一种方法,指在原有基础上进一步挖掘和激活资源组合方式进而提升资源的价值。在互联网领域产品中,往往表现为通过优化创意载体来提升技术指标、业务目标的过程,在信息流中落地重点包括三个方向:
文本创意:在文本方面,既包括了面向内容的摘要标题、排版改写等,也包括面向商户的推荐文案及内容化聚合页。它们都广泛地应用了文本表示和文本生成等技术,也是本文的主要方向。
图像创意:图像方面涉及到首图或首帧的优选、图像的动态裁剪,以及图像的二次生成等。
其他创意:包括多类展示理由(如社交关系等)、元素创意在内的额外补充信息。
核心目标与推荐问题相似,提升包括点击率、转化率在内的通用指标,同时需要兼顾考量产品的阅读体验包括内容的导向性等。关于“阅读体验”的部分,这里不作展开。

为什么要做文本生成?
首先文本创意本身为重要的业务发展赋能。在互联网下半场,大众点评平台(下称点评平台)通过内容化去提升用户停留时长,各类分发内容类型在不停地增加,通过优化创意来提升内容的受众价值是必由之路。其次,目前很多内容类型还主要依赖运营维护,运营内容天然存在覆盖少、成本高的问题,无法完全承接需要内容化改造的场景。
最后,近几年深度学习在NLP(Natural Language Processing,自然语言处理)的不同子领域均取得了重大突破。更重要的是,点评平台历经多年,积淀了大量可用的内容数据。从技术层面来说,我们也有能力提供系统化的文本创意生成的解决方案。
对此,我们从文本创意面向对象的角度定义了两类应用形态,分别是面向内容的摘要标题,以及面向商户的推荐文案与内容化聚合页。前者主要应用信息流各主要内容场景,后者则主要应用在信息流广告等内容化场景。这里提前做下产品的简单介绍,帮助大家建立一个立体化的感知。
摘要标题:顾名思义,就是针对某条分发内容生成摘要作标题展示。点评内容源非常多样,但超过95%内容并没有原生标题,同时原生标题质量和多样性等差异也极大。
商户文案:生成有关单个商户核心卖点的描述,一般形式为一句话的短文案。
内容聚合:生成完整的内容页包括标题及多条文案的短篇推荐理由,不同于单商户文案的是,既需要考虑商户的相关性,又要保证理由的多样性。

最后需要明确的是,我们做文本创意优化最大的初心,是希望通过创意这个载体显式地连接用户、商户和内容。我们能够知道用户关注什么,知道哪些内容说什么,如何引导用户看,知道哪些商户好、好在哪里,将信息的推荐更进一步,而非为了生成而生成。
面临的挑战
文本创意优化,在业务和技术上分别面临着不同的挑战。首先业务侧,启动创意优化需要两个基础前提:
第一,衔接好创意优化与业务目标,因为并不是所有的创意都能优化,也不是所有创意优化都能带来预期的业务价值,方向不对则易蹚坑。
第二,创意优化转化为最优化问题,有一定的Gap。其不同于很多分类排序问题,本身相对主观,所谓“一千个人眼中有一千个哈姆雷特”,创意优化能不能达到预期的业务目标,这个转化非常关键。
其次,在技术层面,业界不同的应用都面临不一样的挑战,并且尝试和实践对应的解决方案。对文本创意生成来说,我们面临的最大的挑战包括以下三点:
带受限的生成,生成一段流畅的文本并非难事,关键在于根据不同的场景和目标能控制它说什么、怎么说。这是目前挑战相对较大的一类问题,在我们的应用场景中都面临这个挑战。
业务导向,生成能够提升业务指标、贴合业务目标的内容。为此,对内容源、内容表示与建模上提出了更高的要求。
高效稳定,这里有两层含义,第一层是高效,即模型训练预测的效果和效率;第二层是稳定,线上系统应用,需要具备很高的准确率和一套完善的质量提升方案。
文本生成问题综述
我们整体的技术方案演进,可以视作近两年NLP领域在深度学习推动下发展的一个缩影。所以在展开之前,先谈一谈整个领域的应用及技术进展。
相关领域应用
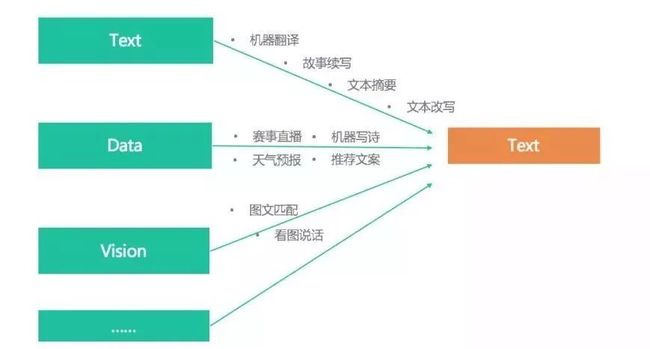
在学界相关领域,文本生成被称为NLG,其相关任务目标是根据输入数据生成自然语言的文本。而我们在NLP领域使用更多的一般是NLU(Nature Language Understanding 自然语言理解)类任务,如文本分类、命名实体识别等,NLU的目标则是将自然语言文本转化成结构化数据。NLU和NLG两者表向上是一对相反的过程,但其实是紧密相连的,甚至目前很多NLU的任务都受到了生成式模型中表示方法的启发,它们更多只在最终任务上有所区别。文本生成也是一个较宽泛的概念,如下图所示,广义上只要输出是自然语言文本的各类任务都属于这个范畴。
但从不同的输入端可以划分出多种领域应用,从应用相对成熟的连接人和语言的NMT(神经机器翻译),到2019年初,能续写短篇故事的GPT2都属于Text2Text任务。给定结构化数据比如某些信息事件,来生成文本比如赛事新闻的属于Data2Text类任务,我们的商户文案也属此类。另外还有Image2Text等,这块也逐渐在出现一些具有一定可用性又让人眼前一亮的应用,比如各种形式的看图说话。
相关技术与进展
文本生成包含文本表示和文本生成两个关键的部分,它们既可以独立建模,也可以通过框架完成端到端的训练。
文本生成
文本生成要解决的一个关键问题,是根据给定的信息如何生成一段文本句子。这是一个简单输入复杂输出的任务,问题的复杂度太大,至今在准确和泛化上都没有兼顾的非常好的方法。2014年提出的Seq2Seq Model,是解决这类问题一个非常通用的思路,本质是将输入句子或其中的词Token做Embedding后,输入循环神经网络中作为源句的表示,这一部分称为Encoder;另一部分生成端在每一个位置同样通过循环神经网络,循环输出对应的Token,这一部分称为Decoder。通过两个循环神经网络连接Encoder和Decoder,可以将两个平行表示连接起来。
另外一个非常重要的,就是Attention机制,其本质思想是获取两端的某种权重关系,即在Decoder端生成的词和Encoder端的某些信息更相关。它也同样可以处理多模态的问题,比如Image2Text任务,通过CNN等将图片做一个关键特征的向量表示,将这个表示输出到类似的Decoder中去解码输出文本,视频语音等也使用同样的方式(如下图所示)。
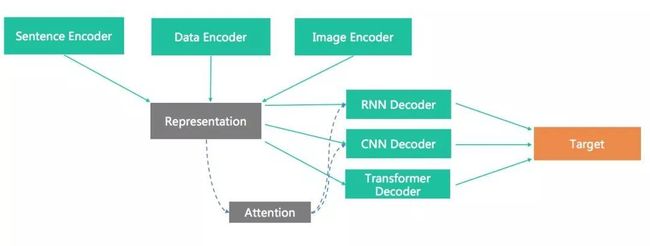
可见Encoder-Decoder是一个非常通用的框架,它同样深入应用到了文本生成的三种主流方法,分别是规划式、抽取式和生成式,下面看下这几类方法各自的优劣势:
规划式:根据结构化的信息,通过语法规则、树形规则等方式规划生成进文本中,可以抽象为三个阶段。宏观规划解决“说什么内容”,微观规划解决“怎么说”,包括语法句子粒度的规划,以及最后的表层优化对结果进行微调。其优势是控制力极强、准确率较高,特别适合新闻播报等模版化场景。而劣势是很难做到端到端的优化,损失信息上限也不高。
抽取式:顾名思义,在原文信息中抽取一部分作为输出。可以通过编码端的表征在解码端转化为多种不同的分类任务,来实现端到端的优化。其优势在于:能降低复杂度,较好控制与原文的相关性。而劣势在于:容易受原文的束缚,泛化能力不强。
生成式:通过编码端的表征,在解码端完成序列生成的任务,可以实现完全的端到端优化,可以完成多模态的任务。其在泛化能力上具有压倒性优势,但劣势是控制难度极大,建模复杂度也很高。
目前的主流的评估方法主要基于数据和人工评测。基于数据可以从不同角度衡量和训练目标文本的相近程度,如基于N-Gram匹配的BLUE和ROUGE等,基于字符编辑距离(Edit Distance)等,以及基于内容Coverage率的Jarcard距离等。基于数据的评测,在机器翻译等有明确标注的场景下具有很大的意义,这也是机器翻译领域最先有所突破的重要原因。但对于我们创意优化的场景来说,意义并不大,我们更重要的是优化业务目标,多以线上的实际效果为导向,并辅以人工评测。
另外,值得一提的是,近两年也逐渐涌现了很多利用GAN(Generative Adversarial Networks,生成对抗网络)的相关方法,来解决文本生成泛化性多样性的问题。有不少思路非常有趣,也值得尝试,只是GAN对于NLP的文本生成这类离散输出任务在效果评测指标层面,与传统的Seq2Seq模型还存在一定的差距,可视为一类具有潜力的技术方向。
文本表示
前文提到,在Encoder端包括有些模型在Decoder端都需要对句子进行建模,那如何设计一个比较好的模型做表示,既可以让终端任务完成分类、序列生成,也可以做语义推理、相似度匹配等等,就是非常重要的一个部分。那在表示方面,整个2018年有两方面非常重要的工作进展:
Contextual Embedding:该方向包括一系列工作,如最佳论文Elmo(Embeddings from Language Models),OpenAI的GPT(Generative Pre-Training),以及谷歌大力出奇迹的BERT(Bidirectional Encoder Representations from Transformers)。解决的核心问题,是如何利用大量的没标注的文本数据学到一个预训练的模型,并通过通过这个模型辅助在不同的有标注任务上更好地完成目标。传统NLP任务深度模型,往往并不能通过持续增加深度来获取效果的提升,但是在表示层面增加深度,却往往可以对句子做更好的表征,它的核心思想是利用Embedding来表征上下文的的信息。但是这个想法可以通过很多种方式来实现,比如ELMo,通过双向的LSTM拼接后,可以同时得到含上下文信息的Embedding。而Transformer则在Encoder和Decoder两端,都将Attention机制都应用到了极致,通过序列间全位置的直连,可以高效叠加多层(12层),来完成句子的表征。这类方法可以将不同的终端任务做一个统一的表示,大大简化了建模抽象的复杂度。我们的表示也经历了从RNN到拥抱Attention的过程。
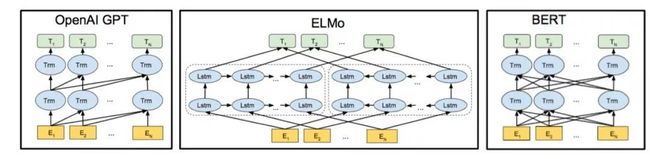
Tree-Based Embedding:另外一个流派则是通过树形结构进行建模,包括很多方式如传统的语法树,在语法结构上做Tree Base的RNN,用根结点的Embedding即可作为上下文的表征。Tree本身可以通过构造的方式,也可以通过学习的方式(比如强化学习)来进行构建。最终Task效果,既和树的结构(包括深度)有关,也受“表示”学习的能力影响,调优难度比较大。在我们的场景中,人工评测效果并不是很好,仍有很大继续探索的空间。
探索与实践
该部分介绍从2017年底至今,我们基于文本生成来进行文本创意优化的一些探索和实践。
内容源
启动文本生成,首先要了解内容本身,数据的数量和质量对我们的任务重要性无须赘述,这是一切模型的基础。目前我们使用到的数据和大致方法包括:
平台渠道:用户评价、用户笔记、Push、攻略、视频内容、榜单、团单等等。
第三方渠道:合作获取了很多第三方平台的内容来补缺,同时运营侧辅助创意撰写和标注了大量内容,他们同样贡献了可观的数据量。
标注数据:最稀缺的永远是标注数据,尤其是符合业务目标的标注。为此,我们在冷启动阶段设计了E&E(Explore and Exploit,探索与利用)机制,有意识地积累线上标注,同时尽量引入更多第三方的标注源。
但这些内容的不同特点,也带来了不同的挑战:
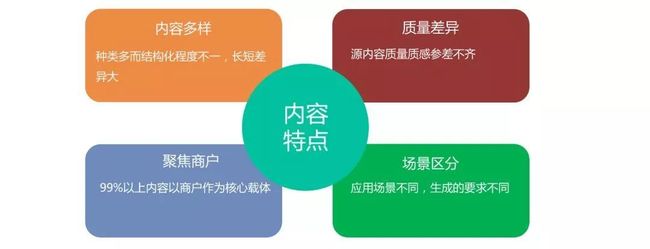
内容多样:前面提到的这些内容的结构化程度各不相同,长短差异也极大,对内容表示提出了很高的要求。
质量不一:源内容非常丰富,但事实上质量、质感远远没有达到理想的标准。尤其是占绝对大头的UGC的内容,不做好两端的质控将极大影响业务目标的优化,甚至会造成体验问题。
聚焦商户:平台99%以上的内容,都以商户作为核心载体,这个对商户的理解和表示同样提出了很高的要求,尤其是在内容化升级的场景下。
场景差异:不同的场景、不同的应用,对模型能力的侧重和优化目标不一样。比如内容和商户,前者要求要有很高的准确率,同时保证优化线上效果;后者更多的是要求有较强的泛化性,并对质感进行优化。
基础能力模块
所以,文本创意优化要在业务侧落地产生效果,还需应用到NLP领域诸多方向的技术。
下图是抽象的整个文本生成应用的基础能力模块,包括用于源和端质量控制的文本质量层,构建Context表示的文本表示层,以及面向业务优化的端到端模型层,其中很多技术应用了公司其他兄弟团队包括内容挖掘组、NLP中心、离线计算组的出色成果。如针对负面内容过滤的情感分析,多项针对性的文本分类,针对商户表示的标签挖掘等,在这里特别向他们表示感谢。
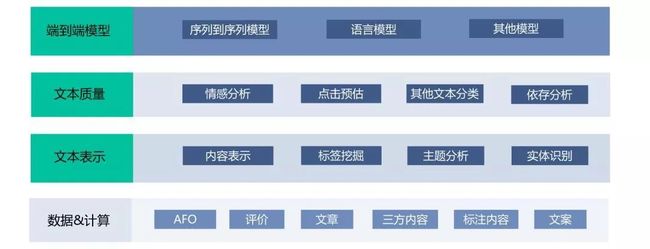
信息流标题实践
双平台的内容需要在信息流分发,在创意上最先优化的就是标题,这是用户仅能看到两个要素之一(另一个为首图),而我们超过95%的内容并没有原生标题,同时原生标题也存在诸如多样性差非场景导向等问题,还有二次优化的空间。
但是,有两点比较大的挑战,在不同任务上具象可能不一样。它们的本质并没有改变,部分也是业界难点:
两个受限条件:第一,需要以线上点击率转化率为优化目标,线上没效果,写的再好意义都不大;第二,需要与原文强相关,并且容错空间极小,一出现就是Case。
优化评估困难:第一,模型目标和业务目标间存在天然Gap;第二,标注数据极度稀缺,离线训练和线上实际预测样本数量之间,往往差距百倍。
对此,我们通过抽取式和生成式的相结合互补的方式,并在流程和模型结构上着手进行解决。
抽取式标题
抽取式方法在用户内容上有比较明显的优势:首先控制力极强,对源内容相关性好,改变用户行文较少,也不容易造成体验问题,可以直接在句子级别做端到端优化。对此,我们把整个标题建模转变为一个中短文本分类的问题,但也无法规避上文提到两个大挑战,具体表现在:
在优化评估上,首先标题创意衡量的主观性很强,线上Feeds的标注数据也易受到其他因素的影响,比如推荐排序本身;其次,训练预测数据量差异造成OOV问题非常突出,分类任务叠加噪音效果提升非常困难。对此,我们重点在语义+词级的方向上来对点击/转化率做建模,同时辅以线上E&E选优的机制来持续获取标注对,并提升在线自动纠错的能力。
在受限上,抽取式虽然能直接在Seq级别对业务目标做优化,但有时候也须兼顾阅读体验,否则会形成一些“标题党”,亦或造成与原文相关性差的问题。对此,我们抽象了预处理和质量模型,来通用化处理文本创意内容的质控,独立了一个召回模块负责体验保障。并在模型结构上来对原文做独立表示,后又引入了Topic Feature Context来做针对性控制。
整个抽取式的流程,可以抽象为四个环节+一个在线机制:
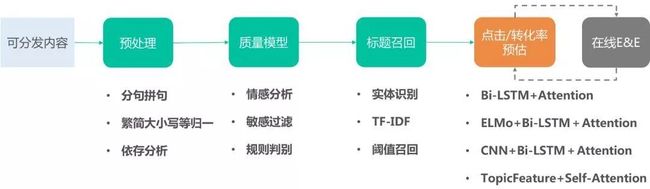
源数据在内容中台完成可分发分析后,针对具体内容,进行系统化插件式的预处理,包括分句拼句、繁简转换、大小写归一等,并进行依存分析。
而后将所有可选内容作质量评估,包括情感过滤、敏感过滤等通用过滤,以及规则判别等涉及表情、冗余字符处理与语法改写的二次基础优化。
在召回模块中,通过实体识别+TF-IDF打分等方式来评估候选内容标题基础信息质量,并通过阈值召回来保证基础阅读体验,从而避免一些极端的Bad Case。
最后,针对候选标题直接做句子级别的点击/转化率预估,负责质感、相关性及最终的业务目标的优化。为此,我们先后尝试了诸多模型结构来解决不同问题,下面重点在这方面做下介绍。
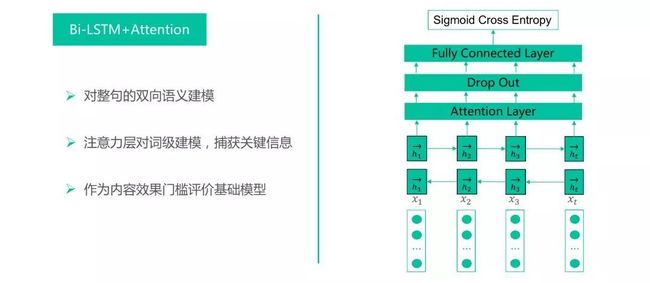
我们第一版Bi-LSTM+Attention整个结构并不复杂。我们的输入层是PreTrain的Word Embedding,经过双向LSTM给到Attention层,Dropout后全连接,套一个交叉熵的Sigmod,输出判别,但它的意义非常明显,既可以对整句序列做双向语义的建模,同时可以通过注意力矩阵来对词级进行加权。这个在线上来看,无论是对体感还是点击转化率都较召回打分的原始版本,有了巨大提升。而后,我们还在这个Base模型基础上,尝试添加过ELMo的Loss,在模型的第一层双向LSTM进行基于ELMo Loss的Pre Train作为初始化结果,在线上指标也有小幅的提升。
但是上述这个结构,将中短文本脱离原文独立建模,显然无法更好地兼顾原文受限这个条件。一个表现,就是容易出现“标题党”、原文不相关等对体验造成影响的问题。对此,我们在原文与候选标题结合的表示建模方面,做了不少探索,其中以CNN+Bi-LSTM+Attention的基模型为代表,但其在相关性建模受原文本身长度的影响较大,而且训练效率也不理想。

经过一段时间的探索分析,在原文受限问题上,最终既通过深度模型来表征深层的语义,也辅以更多的特征工程,如属性、Topic等挖掘特征我们统称为Context,来表征用户能感知到的浅层信息,“两条腿走路”才能被更好的学习,这个在文案生成和标题生成的探索中反过来为抽取式提供了借鉴。
在效率上,我们整体替换了RNN-LSTM的循环结构,采用了谷歌那时新提出的自注意力的机制,来解决原文表征训练效率和长依赖问题。采用这个结构在效果和效率上又有了较大的提升。主要问题是,我们的Context信息如何更好地建模到Self-Attention的结构中。它与生成式模型结构非常类似,在下文生成式部分有所介绍。
另外,需要说明的一点是,除非有两个点以上的巨大提升,一般我们并不会以离线评测指标来评价模型好坏。因为前面提到,我们的标注数据存在不同程度的扰动,而且只是线上预测很小的一个子集,无法避免的与线上存在一定的Gap,所以我们更关注的是模型影响的基础体验(人工检测通过率即非Bad Case率),效率表现(训练预测的时效)最重要的还是线上实际的业务效果。在我们这几个版本的迭代中,这三个方面都分别获得了不同程度的优化,尤其是包括点击率、总点击量等在内的业务指标,都累计获得了10%以上的提升。

受限生成式标题
抽取式标题在包括业务指标和基础体验上都获取了不错的效果,但仍有明显的瓶颈。第一,没有完全脱离原文,尤其在大量质量欠优内容下无法实现创意的二次优化;第二,更好的通过创意这个载体显式的连接用户、商户和内容,这个是生成式标题可以有能力实现的,也是必由之路。
生成式标题,可以抽象描述为:在给定上文并在一定受限条件下,预估下个词的概率的问题。在信息流标题场景,抽取式会面临的问题生成式全部会继承,且在受限优化上面临更大的挑战:
原文受限,首先只有表示并学习到原文的语义意图才能更好的控制标题生成,这个本身在NLU就是难点,在生成式中就更为突出;其次,标注数据稀缺,原文+标题对的数据极少,而大部分又存在于长文章。为了保证控制和泛化性,我们初期将标题剥离原文独立建模,通过Context衔接,这样能引入更多的非标数据,并在逐步完成积累的情况下,才开始尝试做原文的深度语义表示。
优化评估,受限生成式对训练语料的数量和质量要求高很多,首先要保证基础的语义学习也要保证生成端的质量;其次,生成式本质作为语言模型无法在句子层面对业务目标直接做优化,这中间还存在一道Gap。
在表示上,前面已经提到,我们经历过目标单独建模和结合原文建模的过程,主要原因还是在于仅针对Target的理解去构建Context衔接,非常容易出现原文相关性问题。所以我们在描述的泛化性方向也做了不少的尝试,比如尽可能地描述广而泛主题。诸如“魔都是轻易俘获人心的聚餐胜地”,因为只面向上海的商户,内容符合聚餐主题,泛化能力很强,但仍然不能作为一个普适的方案解决问题。
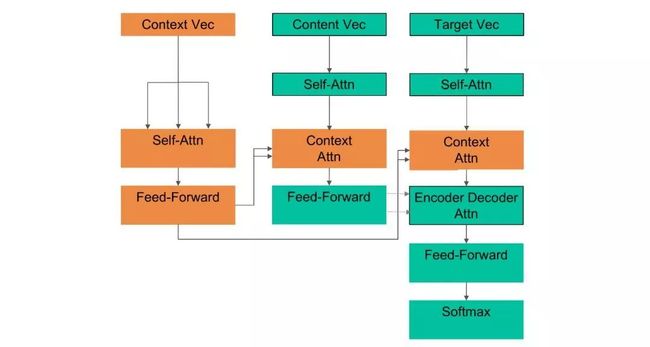
下图为我们一个有初步成效的RNN-Base的Seq2Seq模型的整体结构。Encoder端使用的是,包括前面提到的主题(包括商户信息)表示以及原文的双向语义表示,两部分的拼接构成的Context,输出给注意力层。Decoder端生成文本时,通过注意力机制学习主题和原文表示的权重关系,这个结构也完整应用到了文案生成,其中控制结构会在文案中展开介绍。
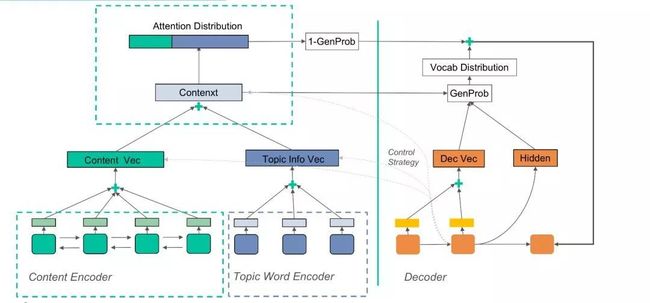
在序列建模上,我们经历了一个从RNN到自注意力的过程。简单介绍下,序列建模一个核心要点是如何建模序列间的长依赖关系。影响它的重要因素是,信号在网络正向和反向计算中传递的长度(也就是计算次数),较长的依赖关系消失越严重。而在自注意力结构中,每一层都直接与前一层的所有位置直接连接,因此依赖长度均为O(1),最大程度保留了序列间的依赖关系。
可以看到,Encoder包括两部分,一部分是Source原文,一部分是基于原文和商户理解的主题Context,两者共同组成。为此,我们借鉴了NMT的一部分研究思想,调整了Transformer的结构,在原结构上额外引入了Context Encoder,并且在Encoder和Decoder端加入了Context的Attention层,来强化模型捕捉Context信息的能力。
我们在生成式方向探索过程中,对低质内容的标题生成,在线上获得了接近10%的效果提升,但仍有很多值得进一步的尝试和深挖的空间。
抽取与生成Combine
在我们的场景中,有两种Combine的思路,一个是以业务效果为导向的偏工程化方法,另外一个是我们正在探索的一种Copy方法。
工程化的思想非常简洁,在推荐问题上扩充候选,是提升效果的一个可行途径,那生成内容即作为新增的候选集之一,参与整体的预估排序。这个方法能保证最终线上效果不会是负向的,实际上也取得了一定的提升。
另一种方法也是学业界研究的子方向之一,即Copy机制,我们也在做重点探索,这里仅作思路的介绍,不再进行展开。
使用Copy机制的原始目的,是为了解决生成式的OOV(超出词表范围)问题。但对于我们的场景来说,大部分的“内容-标题”对数据是来自于抽取式,即我们很多标题数据,其实参考了原文。那如何继承这个参考机制,针对业务目标学习何时Copy以及Copy什么,来更优雅地发挥生成式的优势,就是我们探索Copy方法的初衷。我们的方向是对Copy和Generate概率做独立建模,其中重点解决在受限情况下的“Where To Point”问题。
业务指标与生成式目标的Gap
我们知道生成式模型其本质是一个Language Model,它的训练目标是最小化Word级别的交叉熵Loss,而最终我们的需要评价的其实是业务相关的句子级别点击率,这就导致了训练目标和业务指标不一致。
解决这个问题,在我们的场景中有三个可行的方向,第一是在Context中显式地标注抽取式模型的Label,让模型学习到两者的差异;第二是在预测Decoder的Beam Search计算概率的同时,添加一个打分控制函数;第三则是在训练的Decoder中,建立一个全局损失函数参与训练,类似于NMT中增加的Coverage Loss。
考虑到稳定性和实现成本,我们最终尝试了第一和第二种方式,其中第二种方式还是从商户文案迁移过来的,也会在下文进行介绍。在线上,这个尝试并没有在Combine的基础上取得更好的效果,但同样值得更加深入的探索。
在线E&E机制
最后,介绍一下前面提到过的标题E&E(Explore and Exploit,探索与利用)机制,用来持续获取标注数据,并提升在线自动纠错的能力。我们采用了一种贪心的Epsilon Greedy策略,并做了一点修改,类似经典的Epsilon算法,区别是引入创意状态,根据状态将Epsilon分成多级。目的是将比较好的创意可以分配给较大概率的流量,而不是均分,差的就淘汰,以此来提升效率。在初期优化阶段,这种方式发挥了很大的作用。
具体我们根据标题和图片的历史表现和默认相比,将状态分成7档,从上到下效果表现依次递减,流量分配比例也依次降低,这样可以保证整个系统在样本有噪音的情况下实现线上纠偏。

商户文案实践
文案作为一个常见的创意形式,在O2O以商户为主要载体的场景下有三点需要:第一,赋予商户以内容调性,丰富创意;第二,通过内容化扩展投放的场景;最后,赋能平台的内容化升级,主要业务目标包括点击率、页面穿透率等等。
文案生成和标题生成能够通用整体的生成模型框架,可以归为Data2Text类任务,最大区别是由文案的载体"商户"所决定。不同于内容,准确性的要求低很多,复杂度也大大降低,但同时为泛化能力提出了更高的要求,也带来了与内容生成不同的问题。首先在表示上,对商户的结构化理解变得尤其关键;其次在控制上,有D2T任务特有且非常重要的控制要求。前文也提到了生成一段文本从来不是难点,重要的是如何按照不同要求控制Seq生成的同时,保证很好的泛化性。下文也会分别介绍卖点控制、风格控制、多样性控制控制等几个控制方法。实现这样的控制,也有很多不同的思路。
商户表示
商户的表示抽象为Context,如下图中所示,主要分两部分。
第一部分来源于商户的自身理解,一部分则来源于目标文本,两部分有一定交集。其中商户理解的数据为卖点或者Topic,在初期,为了挖掘商户卖点和Topic,我们主要使用成本较低、无需标注的LDA。但是它的准确性相对不可控,同时对产出的卖点主题仍需要进行人工的选择,以便作为新的标注,辅助后续扩展有监督的任务。我们通过Key和Value两个Field,来对卖点和主题进行共同表达(也存在很多只有Value的情况),比如下图这个商户“菜品”是个Key,“雪蟹”是Value,“约会”则仅是Value。随着时间的推移,后续我们逐渐利用平台商户标签和图谱信息,来扩展商户卖点的覆盖,以此丰富我们的输入信息。该部分在内容挖掘和NLP知识图谱的相关介绍中都有涉及,这里不再进行展开。
第二部分目标文本来源,特意添加这部分进入Context,主要有三方面原因:
第一,仅仅依靠商户理解的Context,在训练过程中Loss下降极慢,并且最终预测生成多样性不理想。本质原因是,目标文本内容与商户卖点、主题间的相关性远远不够。通过不同商户的集合来学习到这个表示关系,非常困难。
第二,拓宽可用数据范围,不受商户评论这类有天然标注对的数据限制,从商户衔接扩展到卖点衔接,引入更多的泛化描述数据,比如各类运营文案等等。
第三,这也是更为重要的一点,能够间接地实现卖点选择的能力,这个会在下文进行介绍。

控制端实现
控制,在解码端表现为两类,一类我们称之为Hard Constrained(强控制),即在数据端给定(或没有给定)的信息,一定要在解码端进行(或不进行)相应描述,这个适用于地域类目等不能出错的信息。比如这家商户在上海,生成时不能出现除上海以外的地域信息,否则容易造成歧义。另一类称之为Soft Constrained(弱控制),不同于NMT问题,在文案生成上即便是完全相同的输入,不同的输出都是允许的,比如同一商户,最终的文案可以选择不同的卖点去描述不同的内容。
这类同属受限优化的问题,前文提到过有两个思路方向:第一,通过构建机制来让模型自己学习到目标;第二,在Decoder的Beam Search阶段动态地加入所需的控制目标。我们使用两者相结合的方法,来完成最终的不同控制的实现。
两端机制设计:在具体机制实现上,主要依赖在Input Context和Output Decoder两端同时生效,让Context的Hard Constrained来源于Output,从而使Model能够自动学习到强受限关系;而Soft Constrained则通过贝叶斯采样的方法,动态添加进Context,从而帮助Model提升泛化能力。
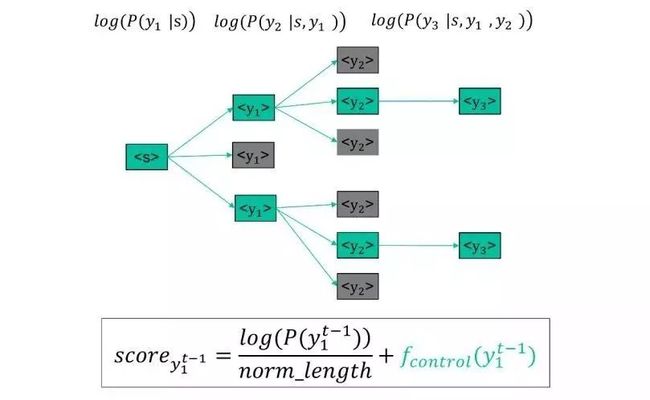
Decoder控制:简单介绍下Beam Search,前面提到过,文本生成的预测过程是按Word级进行的,每轮预测的候选是整个词汇空间,而往往一般的词表都是十万以上的量级。如果生成序列序列长度为N,最终候选序列就有十万的N次方种可能,这在计算和存储上绝不可行。这时候,就需要使用到Beam Search方法,每一步保留最优的前K(K一般为2)个最大概率序列,其他则被剪枝,本质上可以视作一个压缩版的维特比解码。
我们在预测Beam Search阶段,除了计算模型概率外,额外增加下图中绿色部分的Fuction。输入为之前已生成的序列,具体计算逻辑取决于控制目标,可以自由实现。
下面简单介绍两个重要的控制实现:
卖点控制:这是最重要的一个控制机制,我们整理了涉及到Hard Constrained的卖点和实体,重要的如地域、品类等,在目标理解过程中直接加入Context。对于Soft Constrained,我们通过卖点的共现计算一个简单的条件概率,并将卖点依此条件概率随机添加进Context中,从而让模型通过注意力学习到受限关系。最后在Decoder fuction部分,我们新增了一个Hard&Soft Constrained的匹配打分项,参与最终的概率计算。最终的实际结果,也非常符合我们的预期。
风格控制:实现方法和卖点控制非常相似,只是这里的风格,其实是通过不同内容之间的差异来间接进行实现。比如大众点评头条、PGC类的内容与UGC类的的写作风格,就存在极大的差异。那么在文案上,比如聚合页标题上可能更需要PGC的风格,而聚合页内容上则需要UGC的风格。这样的内容属性,即可作为一个Context的控制信号,让模型捕获。
内容聚合
多样性控制
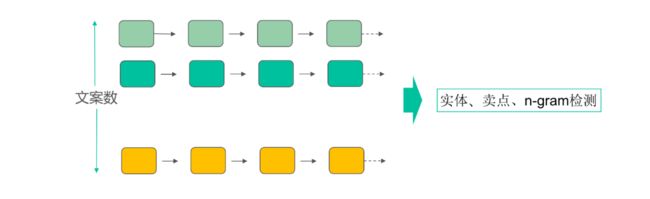
多样性,在文案生成上是一个比较重要和普遍的问题,尤其对于同一个店铺、同一个卖点或主题同时生成N条内容的聚合页来说,更为突出。本质原因是,在解码预测Beam Search时永远选择概率最大的序列,并不考虑多样性。但是如果预测时采用Decoder概率Random Search的方法,则在通顺度上会存在比较大的问题。
对此,我们直接对全局结果进行优化,在预测时把一个聚合页Context放到同一个batch中,batch_size即为文案条数,对已经生成序列上进行实体重复检测和n-gram重复检测,将检测判重的加一个惩罚性打分,这个简单的思想已经能非常好的解决多样性问题。
动态创意
目前,很多搜索推荐等排序优化场景,都会将创意信息作为特征工程一部分添加进精排或召回模型。那如果把创意优化近似为一个内容级创意排序问题,也可以无缝衔接常用的Wide&Deep、DNN、FNN等CTR预估模型。但是这之前,需要明确一点非常重要的问题,即它与推荐精排模型的差异,它们之间甚至可能会相互影响,对此,提供下我们的思考。
与精排模型的差异
第一,精排模型能否一并完成创意的排序,答案显然是肯定的。但它的复杂度决定了能Cover候选集的上限,性能上往往接受不了叉乘创意带来的倍数增长。但此非问题的关键。
第二,创意层排序在精排层之前还是之后,直接影响了创意模型的复杂度,也间接决定了其效果的上限,以及它对精排模型可能的影响程度,从而可能带来全局的影响。此没有最佳实践,视场景权衡。
第三,精排模型与创意排序业务目标一致,但实现方式不同。精排模型通过全局排序的最优化来提升业务指标,而创意优化则是通过动态提升内容受众价值来提升业务指标。 最后,我们回到用户视角,当用户在浏览信息流时,其实看到的只有创意本身(标题、图片、作者等信息),但用户却能从中感知到背后的诸多隐含信息,也就是CTR预估中的重要内容/商户类特征,诸如类目、场景、商户属性等。这个现象背后的本质在于,创意可以表征很多高阶的结构化信息。 基于这一点,在创意优化的特征工程上,方向就很明确了:强化User/Context,弱化Item/POI,通过创意表征,来间接学习到弱化的信息从而实现创意层面的最优排序。该部分工作不仅仅涉及到文本,在本文中不再展开。
用户兴趣与文本生成结合的可能性
动态创意为文本生成提供了全新的空间,也提出了更高的要求。动态创意提升受众价值,不仅仅只能通过排序来实现,在正篇介绍的最后部分,我们抛出一个可能性的问题,供各位同行和同学一起思考。也希望能看到更多业界的方案和实践,共同进步。
总结与展望
整个2018年,大众点评信息流在核心指标上取得了显著的突破。创意优化作为其中的一部分,在一些方面进行了很多探索,也在效果指标上取得了较为显著的收益。不过,未来的突破,更加任重而道远。
2018年至2019年初,NLP的各个子领域涌现了非常多令人惊喜的成果,并且这些成果已经落地到业界实践上。这是一个非常好的趋势,也预示着在应用层面会有越来越多的突破。比如2019年初,能够续写短篇小说的GPT2问世,虽然它真实的泛化能力还未可知,但让我们真切看到了在内容受限下高质量内容生成的可能性。 最后,回到初心,我们希望通过创意的载体显式地连接用户、商户和内容。我们能了解用户关注什么,知道某些内容表达什么,获知哪些商户好,好在哪里,将信息的推荐更进一步。
参考资料
[1] Context-aware Natural Language Generation with Recurrent Neural Networks. arXiv preprint arXiv:1611.09900.
[2] Attention Is All You Need. arXiv preprint arXiv:1706.03762.
[3] Universal Transformers. arXiv preprint arXiv:1807.03819.
[4] A Convolutional Encoder Model for Neural Machine Translation. arXiv preprint arXiv:1611.02344.
[5] Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. arXiv preprint arXiv:1808.08745.
[6] Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[7] ELMO:Deep contextualized word representations. arXiv preprint arXiv:1802.05365.
[8] openAI GPT:Improving Language Understanding by Generative Pre-Training.
[9] Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[10] Tensor2Tensor for Neural Machine Translation. arXiv preprint arXiv:1803.07416.
[11] A Convolutional Encoder Model for Neural Machine Translation. arXiv preprint arXiv:1611.02344.
[12] Sequence-to-Sequence Learning as Beam-Search Optimization. arXiv preprint arXiv:1606.02960.
[13] A Deep Reinforced Model For Abstractive Summarization. arXiv preprint arXiv:1705.04304.
[14] SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. arXiv preprint arXiv:1609.05473.
[15] Generating sequences with recurrent neural networks. CoRR,abs/1308.0850.
作者简介:
忆纯,2015年加入美团点评,算法专家,目前负责点评信息流内容创意工作。
杨肖,博士,2016年加入美团点评,高级算法专家,点评推荐智能中心内容团队负责人。
明海,2016年加入美团点评,美团点评研究员,点评推荐智能中心团队负责人。
众一,2016年加入美团点评,算法研发工程师,目前主要负责点评信息流创意相关算法研发工作。
扬威,2018年初加入美团点评,算法研发工程师,目前主要负责点评信息流动态创意相关算法研发工作。
凤阳,2016年加入美团点评,算法研发工程师,目前主要负责点评信息流内容运营算法优化的工作。
数据猿读者亲启:
名企&大佬专访精选
向下滑动启阅
以下文字均可点击阅读原文
跨国外企:
谷歌大中华及韩国区数据洞察与解决方案总经理郭志明丨 IBM中国区开发中心总经理吉燕勇丨微软中国CTO官韦青丨前微软中国CTO黎江丨VMware中国区研发中心总经理任道远
中国名企:
联想集团副总裁田日辉丨首汽租车COO 魏东
阿里巴巴数据经济研究中心秘书长潘永花
搜狗大数据研究院院长李刚丨易观CTO郭炜
前上海证券交易所副总裁兼CTO白硕丨携程商旅亚太区CMO 邱斐丨艾瑞集团CTO郝欣诚丨泰康集团大数据部总经理周雄志丨上海链家研究院院长陈泽帅丨蓝色光标首席数据科学家王炼
知名学者:
北大新媒体研究院副院长刘德寰丨中科院基因研究所方向东
创业明星:
地平线机器人创始人兼CEO余凯丨天工科仪董事长王世金丨ZRobot CEO乔杨丨天眼查创始人兼CEO柳超丨第四范式联合创始人兼首席架构师胡时伟丨天云大数据CEO雷涛丨Kyligence联合创始人兼CEO韩卿丨数之联创始人兼CEO周涛丨明略数据董事长吴明辉丨91征信创始人兼CEO 薛本川丨智铀科技创始人、CEO及首席科学家夏粉丨易宝支付联合创始人兼总裁余晨丨海云数据创始人兼CEO冯一村丨星环科技COO佘晖丨碳云智能联合创始人兼首席科学家李英睿
知名投资人:
前IDG创始合伙人、火山石资本创始人章苏阳
华创资本合伙人熊伟铭丨六禾创投总裁王烨
信天创投合伙人蒋宇捷丨青域基金执行总裁牟颖
蓝驰创投合伙人朱天宇
——数据猿专访部
(可上下滑动启阅)


▲向上滑动
采访/报道/投稿

商务合作

18600591561(微信)
长按右方二维码
关注我们ˉ►
