数据结构-哈希表
系列文章目录
1.集合-Collection-CSDN博客
2.集合-List集合-CSDN博客
3.集合-ArrayList源码分析(面试)_喜欢吃animal milk的博客-CSDN博客
4.数据结构-哈希表_喜欢吃animal milk的博客-CSDN博客
文章目录
目录
系列文章目录
文章目录
前言
一 . 什么是哈希表?
哈希碰撞
冲突避免
冲突解决
1.闭散列
1.1线性探测
编辑
1.2 二元探测
2.开散列
二 . 代码实现
前言
大家好,今天给大家介绍一下哈希表相关内容以及模拟实现
一 . 什么是哈希表?
哈希表(Hash Table),也称为散列表,是一种根据关键码值(Key)而直接进行访问的数据结构。它通过将关键码值映射到表中的一个位置来访问记录,以加快查找的速度。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即![]() ,搜索的效率取决于搜索过程中元素的比较次数。
,搜索的效率取决于搜索过程中元素的比较次数。
哈希表的基本思想是利用哈希函数将关键码值映射到表中的一个位置,然后在该位置上进行查找或插入操作。哈希函数将关键码值映射到表中的位置时,应该尽量避免冲突,即不同的关键码值映射到同一个位置。当两个不同的关键码值映射到同一个位置时,称为哈希冲突。
解决哈希冲突的常用方法有两种:
-
开放定址法:当发生冲突时,通过一定的规则找到下一个空的位置,将冲突的元素放到该位置。常见的开放定址法有线性探测法、二次探测法和双重哈希法。
-
链地址法:将哈希表的每个位置都设置为一个链表,当发生冲突时,将冲突的元素插入到链表中。链地址法可以处理任意数量的冲突,但是需要额外的空间来存储链表。
哈希表的优点是可以快速地进行插入、删除和查找操作,平均时间复杂度为 O(1)。但是它也有一些缺点,如哈希冲突的处理和空间的浪费等。
例如:数据集合{1,7,6,4,5,9}; 哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
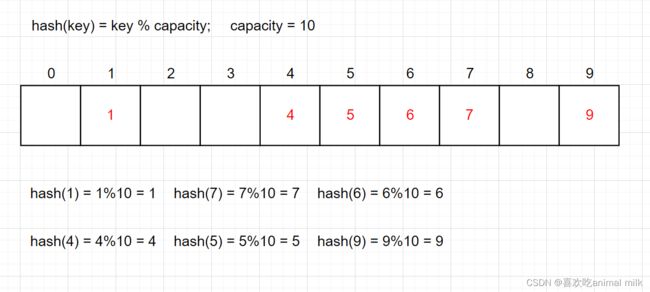
哈希碰撞
对于两个数据元素的关键字 Ki 和 Kj (i != j),有 Ki != Kj,但有:Hash(Ki ) == Hash(Kj ),即:不同关键字通过相同哈 希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
想象一下,如果在上面的哈希表中插入44 hash(44) = 44%10 = 4 这个时候该怎么解决?
还记得上面提到的解决方法吗?
冲突避免
负载因子(Load Factor)是指哈希表中已存储元素个数与哈希表大小之比。它可以用来衡量哈希表的空间利用率。
负载因子的计算公式为:负载因子 = 已存储元素个数 / 哈希表大小。
负载因子的大小会影响哈希表的性能和空间利用率。当负载因子较小时,表示哈希表中的元素较少,空间利用率较低,但是哈希表的性能可能较好,因为冲突的概率较低。当负载因子较大时,表示哈希表中的元素较多,空间利用率较高,但是哈希表的性能可能较差,因为冲突的概率较高。
通常情况下,负载因子的取值范围是 0 到 1,可以根据实际情况进行调整。一般来说,当负载因子超过某个阈值(如 0.75),就需要进行扩容操作,以保证哈希表的性能。扩容操作会重新计算哈希函数和重新分配存储空间,因此会引起一定的开销。
在实际应用中,选择合适的负载因子可以平衡哈希表的性能和空间利用率。较小的负载因子可以提高性能,但会浪费空间;较大的负载因子可以提高空间利用率,但会降低性能。因此,需要根据具体的应用场景和需求来选择合适的负载因子。
冲突解决
1.闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以 把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该 位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
1.1线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
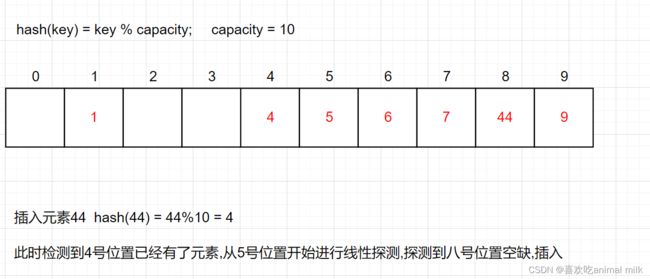
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他 元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标 记的伪删除法来删除一个元素。
1.2 二元探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨 着往后逐个去找。
二元探测步骤:
- 假设哈希表的大小为 capacity,哈希函数将关键码值映射到位置 pos = hash(key) % capacity。
- 如果位置 pos 已经被占用,即发生了哈希冲突,那么继续探测下一个位置。
- 下一个位置的计算公式为 pos = (pos + i^2) % capacity,其中 i 是探测的次数。
- 如果下一个位置仍然被占用,继续增加 i 的值,继续探测下一个位置,直到找到一个空的位置
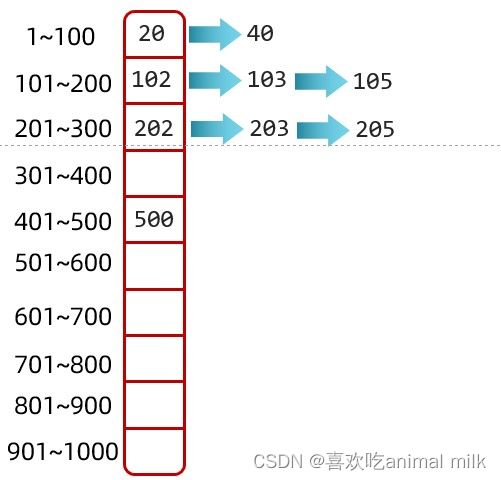
2.开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子 集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
二 . 代码实现
案例: 使用哈希表管理员工
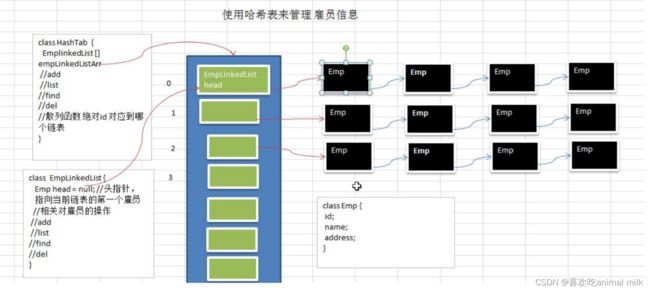
Emp
public class Emp {
public int id;
public String name;
public Emp next;// 默认为空
public Emp(int id,String name){
super();
this.id = id;
this.name = name;
}
}
EmpLikedList
// 表示链表,存放数据
public class EmpLikedList {
private Emp head;// 头指针,指向当前链表的第一个雇员
// 添加雇员
// 假定id自增长,直接尾增
public void add(Emp emp){
if(head == null){
head = emp;
return;
}
Emp cur = head;
while(cur.next != null){
cur = cur.next;
}
cur.next = emp;
}
// 遍历链表的雇员信息
public void list(int count){
if(head == null){
System.out.println("第"+count+"条链表为空");
return;
}
System.out.println("第"+count+"条链表的信息为");
Emp cur = head;
while(cur != null){
if(cur.next == null){
System.out.printf("(id = %d name = %s)\n",cur.id,cur.name);
return;
}
System.out.printf("(id = %d name = %s)=>",cur.id,cur.name);
cur = cur.next;
}
}
// 通过id查找对应的雇员
public Emp findEmp(int id){
Emp cur = head;
while(true){
if(cur == null){
System.out.println("雇员不存在");
return null;
}
if(cur.id == id){
return cur;
}
cur = cur.next;
}
}
}HashTable
// 创建 HashTable 管理多条链表
public class HashTable {
// 盛放链表的数组,即哈希表
EmpLikedList[] EmpLikedListArr;
public int capacity;
// 构造器,制定链表数量
public HashTable(int capacity){
this.capacity = capacity;
EmpLikedListArr = new EmpLikedList[capacity];
// 初始化一把,不然直接报空指针异常
for (int i = 0; i < capacity; i++) {
EmpLikedListArr[i] = new EmpLikedList();
}
}
// 添加
public void add(Emp emp){
// 根据员工id确定员工应该在哪个链表
EmpLikedListArr[HashFunction(emp.id)].add(emp);
}
// 遍历所有的链表
public void list(){
int count = 0;
while (count < capacity) {
EmpLikedListArr[count].list(count);
count++;
}
}
// 根据Id查找对应的雇员
public void findEmp(int id){
int count = HashFunction(id);
Emp emp = EmpLikedListArr[count].findEmp(id);
if(emp == null){
System.out.println("没有找到该雇员");
}else{
System.out.println("找到了该雇员,在第"+count+"条链表中"+"id = "+id);
}
}
// 散列函数 取模法
public int HashFunction(int no){
return no%capacity;
}
}